作者简介:徐增林(1980 − ),男,博士,教授,主要从事机器学习及其在社会网络分析、互联网、计算生物学、信息安全等方面的研究.
【摘要】
知识图谱技术是人工智能技术的重要组成部分,其建立的具有语义处理能力与开放互联能力的知识库,可在智能搜索、智能问答、个性化推荐等智能信息服务中产生应用价值。该文在全面阐述知识图谱定义、架构的基础上,综述知识图谱中的知识抽取、知识表示、知识融合、知识推理四大核心技术的研究进展以及一些典型应用。该文还将评论当前研究存在的挑战。
关键词
知识融合(knowledge fusion); 知识图谱技术(knowledge graph techniques); 知识表示(knowledge representation); 开放互联(open interconnection); 语义处理(semantic processing)
伴随着Web技术的不断演进与发展,人类先后经历了以文档互联为主要特征的“Web 1.0”时代与数据互联为特征的“Web 2.0”时代,正在迈向基于知识互联的崭新“Web 3.0”时代[1]。知识互联的目标是构建一个人与机器都可理解的万维网,使得人们的网络更加智能化。然而,由于万维网上的内容多源异质,组织结构松散,给大数据环境下的知识互联带来了极大的挑战。因此,人们需要根据大数据环境下的知识组织原则[2],从新的视角去探索既符合网络信息资源发展变化又能适应用户认知需求的知识互联方法[3],从更深层次上揭示人类认知的整体性与关联性[4]。知识图谱(knowledge graph)以其强大的语义处理能力与开放互联能力,可为万维网上的知识互联奠定扎实的基础,使Web 3.0提出的“知识之网”愿景成为了可能。
[1] SHETH A, THIRUNARAYAN K. Semantics empowered Web 3.0:managing enterprise, social, sensor, and cloud-based data and service for advanced applications[M]. San Rafael, CA: Morgan and Claypool, 2013. (语义授权Web3.0:为高级应用程序管理企业、社会、传感器和基于云的数据和服务)
[2] 王知津, 王璇, 马婧. 论知识组织的十大原则[J]. 国家图书馆学刊, 2012, 21(4): 3-11. WANG Zhi-jin, WANG Xuan, MA Jing. The ten principles of knowledge organization[J]. Journal of The National Library of China, 2012, 21(4): 3-11.
[3] 索传军. 网络信息资源组织研究的新视角[J]. 图书馆情报工作, 2013, 57(7): 5-12. SUO Chuan-jun. A new perspective for web resource organization research[J]. Library and Information Service, 2013, 57(7): 5-12.
[4] 钟翠娇. 网络信息语义组织及检索研究[J]. 图书馆学研究, 2010, 75(17): 68-71. ZHONG Cui-jiao. Research on semantic organization of web information and retrieval[J]. Research on Library Science, 2010, 75(17): 68-71.
知识图谱并非是一个全新的概念,早在2006年, 文献[5]就提出了语义网的概念,呼吁推广、完善使用本体模型来形式化表达数据中的隐含语义,RDF (resource description framework)模式(RDF schema) 和万维网本体语言(Web ontology language,OWL) 的形式化模型就是基于上述目的产生的。随后掀起了一场语义网研究的热潮,知识图谱技术的出现正是基于以上相关研究,是对语义网标准与技术的一次扬弃与升华。
[5] BERNERS-LEE T, HENDLER J, LASSILA O. The semantic Web[J]. Scientific American Magazine, 2008, 23(1): 1-4.(语义网)
知识图谱于2012年5月17日被Google正式提出[6],其初衷是为了提高搜索引擎的能力,增强用户的搜索质量以及搜索体验。目前,随着智能信息服务应用的不断发展,知识图谱已被广泛应用于智能搜索、智能问答、个性化推荐等领域。尤其是在智能搜索中,用户的搜索请求不再局限于简单的关键词匹配,搜索将根据用户查询的情境与意图进行推理,实现概念检索。与此同时,用户的搜索结果将具有层次化、结构化等重要特征。例如,用户搜索的关键词为梵高,引擎就会以知识卡片的形式给出梵高的详细生平、艺术生涯信息、不同时期的代表作品,并配合以图片等描述信息。知识图谱能够使计算机理解人类的语言交流模式,从而更加智能地反馈用户需要的答案[7]。与此同时,通过知识图谱能够将Web上的信息、数据以及链接关系聚集为知识,使信息资源更易于计算、理解以及评价,并且形成一套Web语义知识库。
[6] AMIT S. Introducing the knowledge graph[R]. America: Official Blog of Google, 2012. (介绍知识图)
[7] 曹倩, 赵一鸣. 知识图谱的技术实现流程及相关应用[J]. 情报理论与实践(ITA), 2015, 12(38): 127-132. CAO Qian, ZHAO Yi-ming. The realization process and related applications of knowledge graph[J]. Information Studies: Theory & Application(ITA), 2015, 12(38): 127- 132.
本文的第一部分将沿着前面叙述,进一步剖析知识图谱的定义与架构;第二部分将以开放链接知识库、垂直行业知识这两类主要的知识库类型为代表,简要介绍其中的几个知名度较高的大规模知识库;第三部分将以知识图谱中的关键技术为重点,详细阐述知识获取、知识表示、知识融合、知识推理技术中的相关研究以及若干技术细节;第四部分将介绍知识图谱在智能搜索、深度问答、社交网络以及垂直行业中的典型应用;第五部分将介绍知识图谱所面临的一些困难与挑战;第六部分将对全文的内容进行总结。
1 知识图谱的定义与架构
本文的第一部分将沿着前面叙述,进一步剖析知识图谱的定义与架构;
1.1 知识图谱的定义
在维基百科的官方词条中:知识图谱是Google 用于增强其搜索引擎功能的知识库[8]。本质上,知 识图谱是一种揭示实体之间关系的语义网络,可以对现实世界的事物及其相互关系进行形式化地描述。现在的知识图谱已被用来泛指各种大规模的知识库。
[8] Wikipedia. Knowledge graph[EB/OL]. [2016-05-09]. https://en.wikipedia.org/wiki/Knowledge_Graph.(知识图谱)
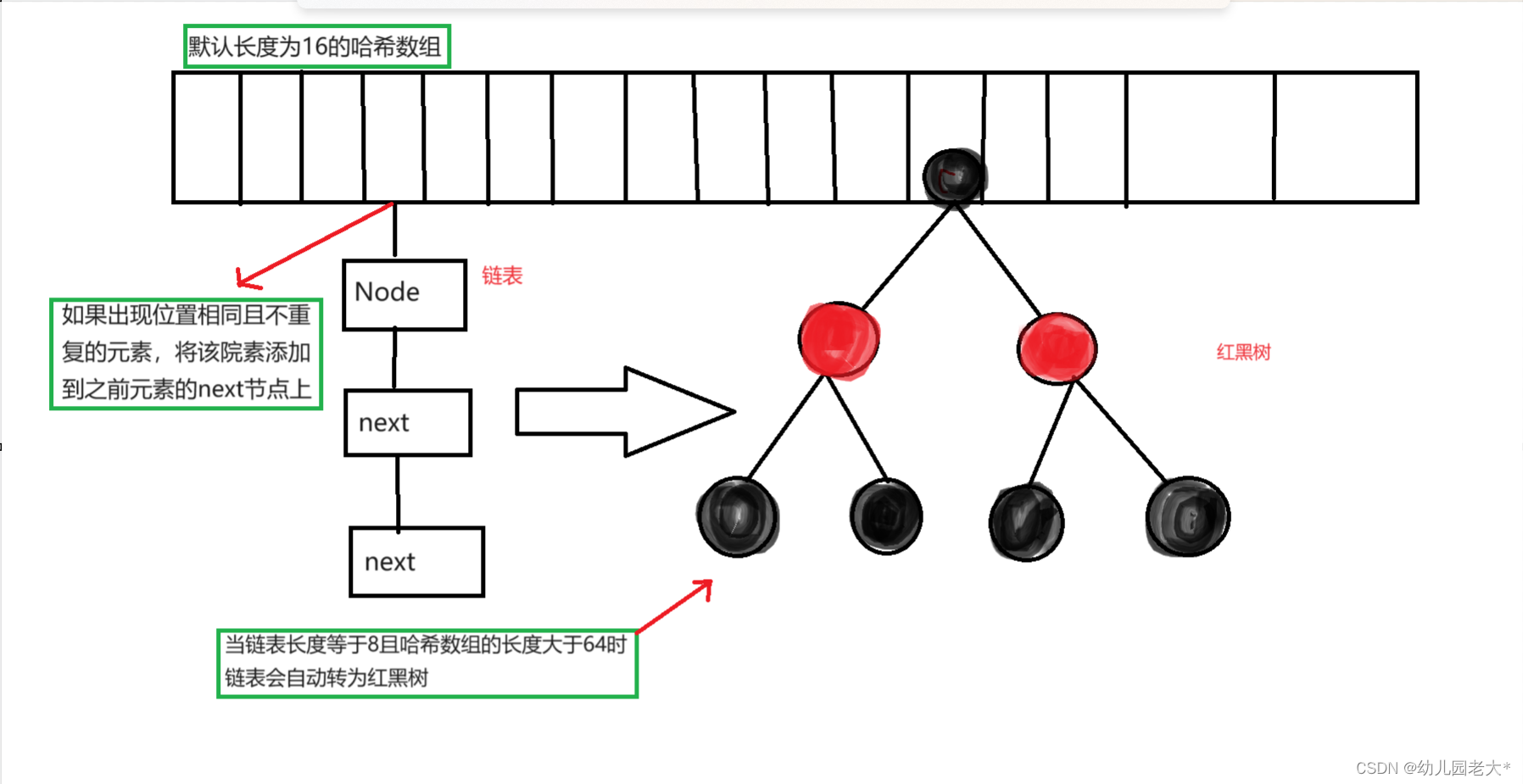
三元组是知识图谱的一种通用表示方式,即,其中
是知识库中的实体集合,共包含|E| 种不同实体;
是知识库中的关系集合,共包含|R| 种不同关系;
代表知识库中的三元组集合。三元组的基本形式主要包括实体1、关系、实体2和概念、属性、属性值等,实体是知识图谱中的最基本元素,不同的实体间存在不同的关系。概念主要指集合、类别、对象类型、事物的种类,例如人物、地理等;属性主要指对象可能具有的属性、特征、特性、特点以及参数,例如国籍、生日等;属性值主要指对象指定属性的值,例如中国、1988-09-08等。每个实体(概念的外延)可用一个全局唯一确定的ID来标识,每个属性-属性值对(attribute-value pair,AVP) 可用来刻画实体的内在特性,而关系可用来连接两个实体,刻画它们之间的关联。
就覆盖范围而言,知识图谱也可分为通用知识图谱和行业知识图谱。通用知识图谱注重广度,强 调融合更多的实体,较行业知识图谱而言,其准确度不够高,并且受概念范围的影响,很难借助本体库对公理、规则以及约束条件的支持能力规范其实体、属性、实体间的关系等。通用知识图谱主要应用于智能搜索等领域。行业知识图谱通常需要依靠特定行业的数据来构建,具有特定的行业意义。行业知识图谱中,实体的属性与数据模式往往比较丰富,需要考虑到不同的业务场景与使用人员。
1.2 知识图谱的架构
知识图谱的架构主要包括自身的逻辑结构以及体系架构,分别说明如下。
1) 知识图谱的逻辑结构
知识图谱在逻辑上可分为模式层与数据层两个层次,数据层主要是由一系列的事实组成,而知识 将以事实为单位进行存储。如果用(实体1,关系,实体2)、(实体、属性,属性值)这样的三元组来表达事实,可选择图数据库作为存储介质,例如开源的Neo4j[9]、Twitter的FlockDB[10]、sones的GraphDB[11]等。模式层构建在数据层之上,主要是通过本体库来规范数据层的一系列事实表达。本体是结构化知识库的概念模板,通过本体库而形成的知识库不仅层次结构较强,并且冗余程度较小。
[9] Shenshouer. Neo4j[EB/OL]. [2016-05-09]. http://neo4j. com/. (Neo4j)
[10] FlockDB Official. FlockDB[EB/OL]. [2016-05-09]. http:// webscripts.softpedia.com/script/Database-Tools/FlockDB- 66248.html. (FlockDB)
[11] Graphdb Official. Graphdb[EB/OL]. [2016-05-09]. http:// www.graphdb.net/. (Graphdb)
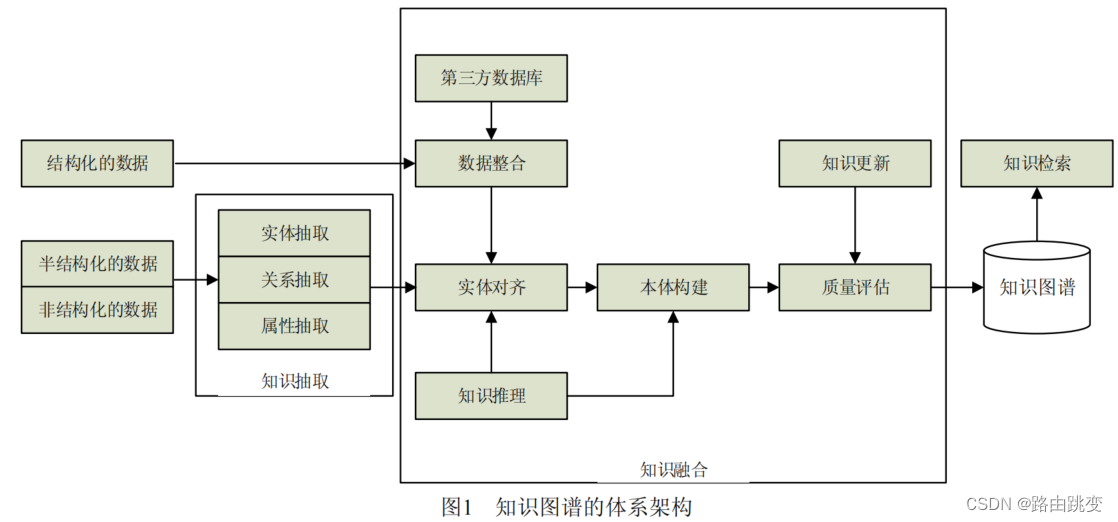
2) 知识图谱的体系架构
知识图谱的体系架构是其指构建模式结构,如图1所示。其中虚线框内的部分为知识图谱的构建过 程,该过程需要随人的认知能力不断更新迭代。知识图谱主要有自顶向下(top-down)与自底向上(bottom-up)两种构建方式。自顶向下指的是先为知识图谱定义好本体与数据模式,再将实体加入到知识库。该构建方式需要利用一些现有的结构化知识库作为其基础知识库,例如Freebase项目就是采用这种方式,它的绝大部分数据是从维基百科中得到的。自底向上指的是从一些开放链接数据中提取出实体,选择其中置信度较高的加入到知识库,再构建顶层的本体模式[12]。目前,大多数知识图谱都采用自底向上的方式进行构建,其中最典型就是Google的Knowledge Vault[13]。
[12] 刘峤, 李杨, 杨段宏, 等. 知识图谱构建技术综述[J]. 计算机研究与发展, 2016, 53(3): 582-600. LIU Qiao, LI yang, YANG Duan-hong, et al. Knowledge graph construction techniques[J]. Journal of Computer Research and Development, 2016, 53(3): 582-600.
[13] DONG X, GABRILOVICH E, HEITZ G, et al. Knowledge vault: a web-scale approach to probabilistic knowledge fusion[C]//Proc of the 20th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. New York: ACM, 2014. (知识库:一种实现概率知识融合的网络规模方法)
2 大规模知识库
第二部分将以开放链接知识库、垂直行业知识这两类主要的知识库类型为代表,简要介绍其中的几个知名度较高的大规模知识库;
随着语义Web资源数量激增、大量的RDF数据被发布和共享、LOD(linked open data)等项目的全面展开[14],学术界与工业界的研究人员花费了大量的精力构建各种结构化的知识库。下面将以开放链接知识库、行业知识库这两类主要的知识库类型为代表,详细说明其中的几个知名度较高的大规模知识库。
[14] BIZER C, Al E. Linked data-the story so far[J]. International Journal on Semantic Web & Information System, 2009, 5(3): 1-22.(到目前为止链接数据的故事)
2.1 开放链接知识库
在LOD项目的云图中,Freebase、Wikidata、DBpedia、YAGO这4个大规模知识库处于绝对核心 的地位,它们中不仅包含大量的半结构化、非结构化数据,是知识图谱数据的重要来源。而且具有较高的领域覆盖面,与领域知识库存在大量的链接关系。
1) Freebase
Freebase知识库[15]早期由Metaweb公司创建,后来被Google收购,成为Google知识图谱的重要组成部分。Freebase中的数据主要是由人工构建,另外一部分数据则主要来源于维基百科、IMDB、Flickr等网站或语料库。截止到2014年年底,Freebase已经包含了6 800万个实体,10亿条关系信息,超过24亿条事实三元组信息,在2015年6月,Freebase整体移入至WikiData。
[15] BOLLACKER K, COOK R, TUFTS P. Freebase: a shared database of structured general human knowledge[C]//Proc of the 22nd AAAI Conf on Artificial Intelligence. Menlo Park, CA: AAAI, 2007: 1962-1963. (自由数据库:一个包含结构化的一般人类知识的共享数据库)
2) Wikidata
Wikidata[16]是维基媒体基金会主持的一个自由的协作式多语言辅助知识库,旨在为维基百科、维 基共享资源以及其他的维基媒体项目提供支持。它是Wikipedia、Wikivoyage、Wikisource中结构化数据的中央存储器,并支持免费使用[17]。Wikidata中的数据主要以文档的形式进行存储,目前已包含了超过1 700万个文档。其中的每个文档都有一个主题或一个管理页面,且被唯一的数字标识。
[16] WMF. Wikidata[EB/OL]. [2015-11-11]. https://www. wikidata.org/wiki/Wikidata:Main_Page. (WMF. Wikidata)
[17] Wikipedia. Data revolution for Wikipedia[EB/OL]. (2012-03-30). https://www.wikimedia.org/. (维基百科。一部基于互联网维基百科的数据革命)
3) DBpedia
DBpedia[18]是由德国莱比锡大学和曼海姆大学的科研人员创建的多语言综合型知识库,在LOD项 目中处于最核心的地位。DBpedia是从多种语言的维基百科中抽取结构化信息,并且将其以关联数据的形式发布到互联网上,提供给在线网络应用、社交网站以及其他在线知识库。由于DBpedia的直接数据来源覆盖范围广阔,所以它包含了众多领域的实体信息。截止至2014年年底,DBpedia中的事实三元组数量已经超过了30亿条。除上述优点外,DBpedia还能够自动与维基百科保持同步,覆盖多种语言。
[18] BIZER C, LEHMANN J, KOBILAROV G, et al. DBpedia—a crystallization point for the Web of data[J]. Web Semantics Science Services & Agents on the World Wide Web, 2009, 7(3): 154-165. (DBpedia——数据网络的一个结晶点)
4) YAGO
YAGO[19]是由德国马普所(max planck institute,MPI)的科研人员构建的综合型知识库。YAGO整合了维基百科、WordNet[20]以及GeoNames等数据源,特别是将维基百科中的分类体系与WordNet的分类体系进行了融合,构建了一个复杂的类别层次结构体系。第一个版本包含了超过100万的实体以及超过500万的事实。2012年,发布了它的第二个版本,在YAGO的基础上进行了大规模的扩展,引入了一个新的数据源GeoNames[21],被称为YAG02s。包含了超过1 000万的实体以及超过1.2亿的事实。
[19] SUCHANEK F M, KASNECI G, WEIKUM G. YAGO: a large ontology from wikipedia and wordnet[J]. Web Semantics Science Services & Agents on the World Wide Web, 2007, 6(3): 203-217. (YAGO:一个来自维基百科和文字网的大型本体论)
[20] MILLER G A. WordNet: a lexical database for English[J]. Communications of the ACM, 1995, 38(11): 39-41. (一个英语词汇数据库)
[21] MAEDCHE A, STAAB S. The text-to-onto ontology learning environment[C]//Software Demonstration at ICCS-2000-Eight International Conference on Conceptual Structures. [S.l.]: [s.n.], 2000. (从文本到本体的学习环境)
2.2 垂直行业知识库
行业知识库也可称为垂直型知识库,这类知识库的描述目标是特定的行业领域,通常需要依靠特 定行业的数据才能构建,因此其描述范围极为有限。下面将以MusicBrainz、IMDB、豆瓣等为代表进行说明。
1) IMDB
IMDB(internet movie database)[22]是一个关于电影演员、电影、电视节目、电视明星以及电影制作的资料库。截止到2012年2月,IMDB共收集了2 132 383部作品资料和4 530 159名人物资料。IMDB中的资料是按类型进行组织的。对于一个具体的条目,又包含了详细的元信息[23]。
[22] IMDB Official. IMDB[EB/OL]. [2016-02-27]. http://www. imdb.com. (IMDB官方)
[23] 百度百科 . IMDB[EB/OL]. [2016-02-27]. http://baike. baidu.com/view/785720.htm?fromtitle=IMDB&fromid=925061&type=syn. Baidu Bake. IMDB[EB/OL]. [2016-02-27]. http://baike. baidu.com/view/785720.htm?fromtitle=IMDB&fromid=925061&type=syn.
2) MusicBrainz
MusicBrainz[24]是一个结构化的音乐维基百科,致力于收藏所有的音乐元数据,并向大众用户开放。任何注册用户都可以向网站中添加信息或投稿。由于Last.fm、GrooveShark、Pandora、Echonest等音乐服务网站的数据均来自于 MusicBrainz , 故MusicBrainz可通过数据库或Web服务两种方式将数据提供给社区。对于商业用户而言,MusicBrainz提供的在线服务可为用户提供本地化的数据库与复制包[25]。
[24] MetaBrainz Foundation. Musicbrainz[EB/OL]. [2016-06-06]. http://musicbrainz.org/. (MetaBrainz基金会。Musicbrainz)
[25] 全球网站库. Musicbrainz[EB/OL]. (2013-05-20). http:// www.0430.com/us/web7028. Global Web Sites. Musicbrainz[EB/OL]. (2013-05-20). http://www.0430.com/us/web7028.
3) ConceptNet
ConceptNet[26]是一个语义知识网络,主要由一系列的代表概念的结点构成,这些概念将主要采用 自然语言单词或短语的表达形式,通过相互连接建立语义联系。ConceptNet包含了大量计算机可了解的世界的信息,这些信息将有助于计算机更好地实现搜索、问答以及理解人类的意图。ConceptNet 5[27] 是基于ConceptNet的一个开源项目,主要通过GPLv3 协议进行开源。
[26] OSCHINA. ConceptNet[EB/OL]. [2016-01-09]. http://www.oschina.net/p/conceptnet.
[27] CONCEPTNET5. ConceptNet5[EB/OL]. [2014-04-06]. http://conceptnet5.media.mit.edu/.
3 知识图谱的关键技术
第三部分将以知识图谱中的关键技术为重点,详细阐述知识获取、知识表示、知识融合、知识推理技术中的相关研究以及若干技术细节;
大规模知识库的构建与应用需要多种智能信息处理技术的支持。通过知识抽取技术,可以从一些 公开的半结构化、非结构化的数据中提取出实体、关系、属性等知识要素。通过知识融合,可消除实体、关系、属性等指称项与事实对象之间的歧义,形成高质量的知识库。知识推理则是在已有的知识库基础上进一步挖掘隐含的知识,从而丰富、扩展知识库。分布式的知识表示形成的综合向量对知识库的构建、推理、融合以及应用均具有重要的意义。接下来,本文将以知识抽取、知识表示、知识融合以及知识推理技术为重点,详细说明其中的相关研究。
3.1 知识抽取
知识抽取主要是面向开放的链接数据,通过自动化的技术抽取出可用的知识单元,知识单元主要 包括实体(概念的外延)、关系以及属性3个知识要素,并以此为基础,形成一系列高质量的事实表达,为上层模式层的构建奠定基础。
3.1.1 实体抽取
早期的实体抽取也称为命名实体学习(named entity learning) 或命名实体识别 (named entity recognition),指的是从原始语料中自动识别出命名实体。由于实体是知识图谱中的最基本元素,其抽取的完整性、准确率、召回率等将直接影响到知识库的质量。因此,实体抽取是知识抽取中最为基础与关键的一步。
文献[28]将实体抽取的方法分为3种:基于规则与词典的方法、基于统计机器学习的方法以及面向 开放域的抽取方法。基于规则的方法通常需要为目标实体编写模板,然后在原始语料中进行匹配;基于统计机器学习的方法主要是通过机器学习的方法对原始语料进行训练,然后再利用训练好的模型去识别实体;面向开放域的抽取将是面向海量的Web语料[12,29]。
[28] 孙镇, 王惠临. 命名实体识别研究进展综述[J]. 现代图书情报技术, 2010(6): 42-47. SUN Zhen, WANG Hui-lin. Overview on the advance of the research on named entity recognition[J]. New Technology of Library and Information Service, 2010(6): 42-47.
[29] 赵军, 刘康, 周光有, 等. 开放式文本信息抽取[J]. 中文信息学报, 2011, 25(6): 98-110.ZHAO Jun, LIU Kang, ZHOU Guang-you, et al. Open information extraction[J]. Journal of Chinese Information Processing, 2011, 25(6): 98-110.
1) 基于规则与词典的实体抽取方法
早期的实体抽取是在限定文本领域、限定语义单元类型的条件下进行的,主要采用的是基于规则 与词典的方法,例如使用已定义的规则,抽取出文本中的人名、地名、组织机构名、特定时间等实 体[30]。文献[31]首次实现了一套能够抽取公司名称的实体抽取系统,其中主要用到了启发式算法与规则模板相结合的方法。然而,基于规则模板的方法不仅需要依靠大量的专家来编写规则或模板,覆盖的领域范围有限,而且很难适应数据变化的新需求。
[30] CHINCHOR N, MARSH E. Muc-7 information extraction task definition[C]//Proc of the 7th Message Understanding Conf. Philadelphia: Linguistic Data Consortium, 1998: 359-367. (Muc-7信息提取任务定义)
[31] RAU L F. Extracting company names from text[C]//Proc of the 7th IEEE Conf on Artificial Intelligence Applications. Piscataway, NJ: IEEE, 1991: 29-32.(从文本中提取公司名称)
2) 基于统计机器学习的实体抽取方法
随后,研究者尝试将机器学习中的监督学习算法用于命名实体的抽取问题上。例如文献[32]利用 KNN算法与条件随机场模型,实现了对Twitter文本数据中实体的识别。单纯的监督学习算法在性能上不仅受到训练集合的限制,并且算法的准确率与召回率都不够理想。相关研究者认识到监督学习算法的制约性后,尝试将监督学习算法与规则相互结合,取得了一定的成果。例如文献[33]基于字典,使用最大熵算法在Medline论文摘要的GENIA数据集上进行了实体抽取实验,实验的准确率与召回率都在70%以上。
[32] LIU Xiao-hua, ZHANG Shao-dian, WEI Fu-ru, et al.Recognizing named entities in tweets[C]//Proc of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg, PA: ACL, 2011: 359-367. (识别推文中的命名实体)