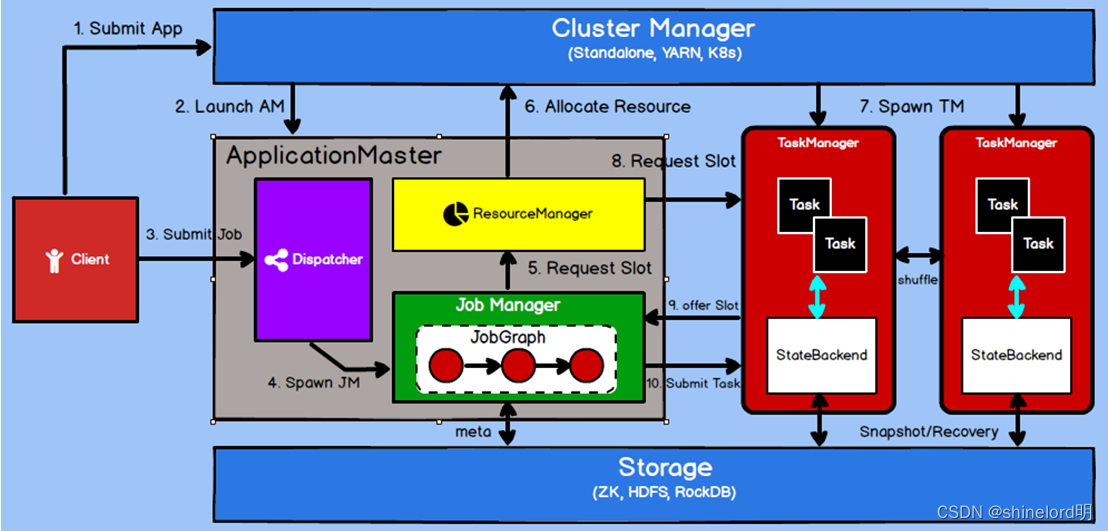
架构简介
Flink 是一个分布式流处理和批处理计算框架,具有高性能、容错性和灵活性。下面是 Flink 的架构概述:
-
JobManager:JobManager 是 Flink 集群的主节点,负责接收和处理用户提交的作业。JobManager 的主要职责包括:
- 解析和验证用户提交的作业。
- 生成执行计划,并将作业图分发给 TaskManager。
- 协调任务的调度和执行。
- 管理作业的状态和元数据信息。
-
TaskManager:TaskManager 是 Flink 集群的工作节点,负责执行具体的任务。每个 TaskManager 可以运行多个任务(子任务),每个子任务运行在一个单独的线程中,共享 TaskManager 的资源。TaskManager 的主要职责包括:
- 接收并执行 JobManager 分配的任务。
- 负责任务的数据处理、状态管理、故障恢复等操作。
- 将处理结果返回给 JobManager。
-
StateBackend:StateBackend 是 Flink 的状态管理机制,用于保存和恢复任务的状态信息,确保任务在失败后可以进行故障恢复。Flink 提供了多种 StateBackend 实现,包括内存、文件系统、RocksDB 等。
-
DataStream API / DataSet API:Flink 提供了两种不同的编程接口,用于流处理和批处理:
- DataStream API:面向流式计算,支持实时数据流的处理和分析。它提供了丰富的操作符(例如 map、filter、window、join 等)和窗口函数,以便进行数据转换和聚合操作。
- DataSet API:面向批处理,适用于有界数据集的处理。它提供了类似于 Hadoop MapReduce 的操作符(例如 map、reduce、join 等),用于对数据集进行转换和计算。
-
Connectors:Flink 提供了多种连接器,用于与外部系统进行数据交互。常见的连接器包括 Kafka、Hadoop、Elasticsearch、JDBC 等,可以用于读取和写入外部数据源。
-
资源管理器:Flink 可以与各种集群管理工具(如 YARN、Mesos、Kubernetes)集成,以实现资源的动态分配和任务调度。
Flink 的架构使得它能够实现高性能的流处理和批处理,同时具备良好的容错性和可伸缩性。它广泛应用于实时数据处理、数据湖分析、事件驱动应用等场景。
组件模块
大数据流处理框架 Flink 和 Aflink 的技术架构主要包括以下组件:
- JobManager:负责接收 Job 图,并将其分发给 TaskManager。
- TaskManager:负责执行任务,包括数据源、数据计算、数据汇总等操作。
- StateBackend:用于保存状态信息,支持容错和恢复。
- DataStream API:用于定义数据流处理逻辑,包括窗口函数、聚合操作等。
- Connector:用于连接外部数据源,如 Kafka。
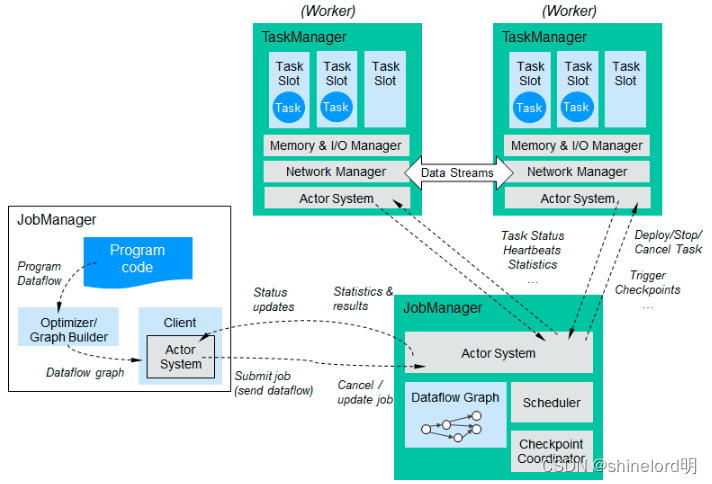
JobManager 和 TaskManager 之间的通信方式主要有两种:心跳机制和RPC(远程过程调用)。
-
心跳机制:JobManager 和 TaskManager 通过心跳机制保持连接和通信。具体流程如下:
- JobManager 定期向所有的 TaskManager 发送心跳信号,确认 TaskManager 是否存活。
- TaskManager 接收到心跳信号后,回复确认信号给 JobManager,表示自己还活着。
- 如果 JobManager 在一段时间内没有收到 TaskManager 的心跳信号,就会认为该 TaskManager 失效,并进行相应的处理。
-
RPC:JobManager 和 TaskManager 使用 RPC 机制进行通信,以传递任务和数据等信息。具体流程如下:
- JobManager 将任务调度图发送给 TaskManager。这包括任务的执行计划、数据源、算子操作等。
- TaskManager 接收到任务调度图后,根据指令执行任务,处理数据流。
- TaskManager 在处理过程中将结果返回给 JobManager,以便进行状态更新和后续处理。
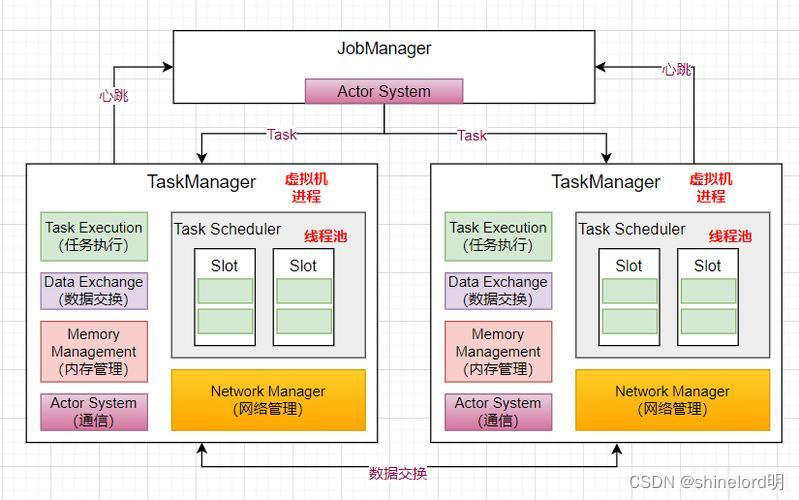
需要注意的是,JobManager 和 TaskManager 的通信是基于网络的,它们可以部署在不同的机器上。在一个 Flink 集群中,通常会有一个 JobManager 和多个 TaskManager,它们通过上述的通信方式协同工作,实现数据流的处理和任务调度。
与其他大数据集成
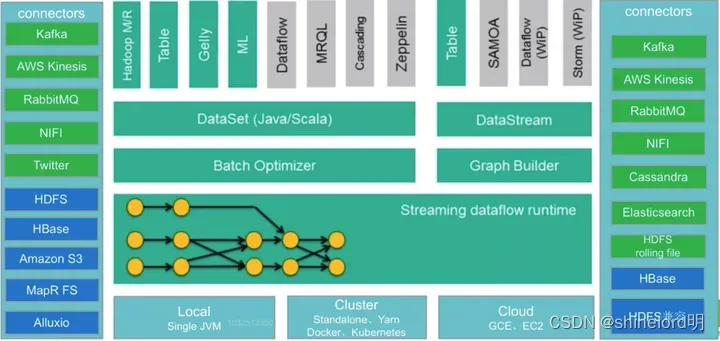
流式计算和窗口函数原理
- 流式计算:Flink 和 Aflink 是流式计算框架,能够实时处理无界数据流。流式计算基于事件驱动的模型,能够处理实时数据并支持低延迟计算。
- 窗口函数:窗口函数用于对数据流进行分组聚合操作,常见的窗口类型包括滚动窗口、滑动窗口和会话窗口。窗口函数允许用户在有限的数据集上执行计算操作。
窗口类型
Flink 框架提供了多种窗口函数,用于对数据流进行分组聚合操作。以下是一些常见的窗口函数:
-
滚动窗口(Tumbling Window):将数据流划分为固定大小的、不重叠的窗口。每个窗口包含相同数量的元素,并且窗口之间没有重叠。可以通过
window(Tumble.over())方法来定义滚动窗口。 -
滑动窗口(Sliding Window):将数据流划分为固定大小的、可能重叠的窗口。每个窗口包含指定数量的元素,并且窗口之间可以有重叠。可以通过
window(Slide.over())方法来定义滑动窗口。 -
会话窗口(Session Window):根据事件之间的时间间隔将数据流划分为不固定长度的会话窗口。如果在指定时间间隔内没有新事件到达,则会话窗口关闭。可以通过
window(Session.withGap())方法来定义会话窗口。 -
全局窗口(Global Window):将整个数据流视为一个窗口,不进行数据切分。适用于需要计算整个数据流的聚合结果的场景。可以通过
window(Global())方法来定义全局窗口。 -
自定义窗口函数:Flink 还支持自定义窗口函数,以便满足特定需求。您可以实现
WindowFunction接口来定义自己的窗口函数,并通过apply()方法来处理窗口中的元素。
这些窗口函数可以和其他操作符(例如 groupBy()、reduce()、aggregate() 等)一起使用,以实现各种数据流处理和聚合操作。
不同类型的窗口函数适用于不同的业务场景,具体选择哪种窗口函数取决于您的需求和数据流的特点。
窗口函数都有其特定的使用场景,下面我会简要介绍每种窗口函数的典型应用场景,并提供 Java 和 Python 代码示例。
滚动窗口(Tumbling Window)
- 使用场景:适用于需要对固定大小的数据范围进行聚合计算的场景,例如统计每5分钟内的数据总和。
- Java 代码示例:
DataStream<Tuple2<String, Integer>> input = ... ;
// 输入数据流
DataStream<Tuple2<String, Integer>> result = input .keyBy(0) .window(TumblingEventTimeWindows.of(Time.minutes(5))) .sum(1);- Python 代码示例:
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.datastream.window import TumblingEventTimeWindows
from pyflink.common import WatermarkStrategy env = StreamExecutionEnvironment.get_execution_environment()
input_stream = ...
# 输入数据流
result_stream = input_stream.key_by(lambda x: x[0]).window(TumblingEventTimeWindows.of('5 minutes')).sum(1)滑动窗口(Sliding Window)
- 使用场景:适用于需要对数据流进行连续且重叠的窗口计算的场景,例如统计每5分钟计算一次数据总和,并且每次计算时包含前一个窗口的部分数据。
- Java 代码示例:
DataStream<Tuple2<String, Integer>> input = ... ;
// 输入数据流
DataStream<Tuple2<String, Integer>> result = input .keyBy(0) .window(SlidingEventTimeWindows.of(Time.minutes(10), Time.minutes(5))) .sum(1);- Python 代码示例:
from pyflink.datastream.window import SlidingEventTimeWindows
result_stream = input_stream .key_by(lambda x: x[0]).window(SlidingEventTimeWindows.of('10 minutes', '5 minutes')).sum(1)会话窗口(Session Window)
- 使用场景:适用于需要基于活动之间的间隔时间来划分窗口的场景,例如用户在网站上的一系列操作之间的时间间隔作为窗口的划分条件。
- Java 代码示例:
DataStream<Tuple2<String, Integer>> input = ... ;
// 输入数据流
DataStream<Tuple2<String, Integer>> result = input .keyBy(0).window(EventTimeSessionWindows.withGap(Time.minutes(10))) .sum(1);- Python 代码示例:
from pyflink.datastream.window import EventTimeSessionWindows
result_stream = input_stream .key_by(lambda x: x[0]).window(EventTimeSessionWindows.with_gap('10 minutes')).sum(1)全局窗口(Global Window)
- 使用场景:适用于对整个数据流进行聚合计算的场景,例如统计全天的数据总和。
- Java 代码示例:
DataStream<Tuple2<String, Integer>> input = ... ;
// 输入数据流
DataStream<Tuple2<String, Integer>> result = input .keyBy(0) .window(GlobalWindows.create()) .trigger(CountTrigger.of(1)) .sum(1);
- Python 代码示例:
from pyflink.datastream.window import GlobalWindows
from pyflink.datastream.trigger import CountTrigger
result_stream = input_stream .key_by(lambda x: x[0]).window(GlobalWindows.create()) .trigger(CountTrigger(1)).sum(1)读取 Kafka 数据并计算指标
以下是一个简单的示例代码,使用 Java 和 Python 分别演示读取 Kafka 数据并计算指标的过程:
Java 代码示例:
// 创建 Flink 程序入口
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 从 Kafka 中读取数据
FlinkKafkaConsumer<String> kafkaConsumer = new FlinkKafkaConsumer<>("topic", new SimpleStringSchema(), properties);
DataStream<String> stream = env.addSource(kafkaConsumer);
// 对数据流进行处理,计算指标
DataStream<Result> resultStream = stream .flatMap(new UserAccessFlatMapFunction()) .keyBy("userId") .timeWindow(Time.minutes(5)) .apply(new UserAccessWindowFunction());
// 执行任务
env.execute("User Access Analysis");Python 代码示例:
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.table import StreamTableEnvironment, EnvironmentSettings
from pyflink.table.descriptors import Schema, Kafka
# 创建 Flink 环境
env = StreamExecutionEnvironment.get_execution_environment()
env.set_parallelism(1) t_env = StreamTableEnvironment.create( env, environment_settings=EnvironmentSettings.new_instance().in_streaming_mode().use_blink_planner().build())
# 从 Kafka 读取数据
t_env.connect( Kafka() .version("universal") .topic("topic") .property("zookeeper.connect", "localhost:2181") .property("bootstrap.servers", "localhost:9092") .start_from_earliest() .finish() ).with_format( Json() ).with_schema( Schema() .field("user_id", DataTypes.STRING()) .field("timestamp", DataTypes.TIMESTAMP(3)) ).create_temporary_table("MySource")
# 计算指标
t_env.from_path("MySource") \ .window(Tumble.over("5.minutes").on("timestamp").alias("w")) \ .group_by("user_id, w") \ .select("user_id, w.end as window_end, count(user_id) as pv, count_distinct(user_id) as uv") \ .execute_insert("MySink")加载数据湖进行 AI 模型训练
Flink 和 Aflink 可以用于加载数据湖中的大规模数据集,进行 AI 模型训练。通过流式处理和批处理相结合,可以有效处理图片、音频、文本等多媒体数据,用于风控等场景。
当使用 Flink 进行机器学习时,通常会使用 Flink 的批处理和流处理 API 结合机器学习库(如 Apache Flink ML、Apache Mahout 等)来实现各种机器学习任务。这里我将为您提供一个简单的示例,演示如何在 Flink 中使用批处理 API 来进行线性回归的训练。
首先,让我们看一下 Java 代码示例:
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.ml.common.LabeledVector; import org.apache.flink.ml.regression.MultipleLinearRegression;
public class LinearRegressionExample {
public static void main(String[] args) throws Exception {
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// 创建带标签的向量数据集
DataSet<LabeledVector> trainingData = ... ;
// 从数据源加载带标签的向量数据集
// 初始化线性回归模型
MultipleLinearRegression mlr = new MultipleLinearRegression();
mlr.setStepsize(0.5);
// 设置步长
mlr.setIterations(100);
// 设置迭代次数
// 训练线性回归模型
mlr.fit(trainingData);
// 获取训练后的模型参数
double[] weights = mlr.weights();
double intercept = mlr.intercept();
// 打印模型参数
System.out.println("Weights: " + Arrays.toString(weights));
System.out.println("Intercept: " + intercept);
}
}Python 代码示例:
from pyflink.dataset import ExecutionEnvironment
from pyflink.datastream import LabeledVector
from pyflink.ml.preprocessing import Splitter
from pyflink.ml.regression import MultipleLinearRegression env = ExecutionEnvironment.get_execution_environment()
# 创建带标签的向量数据集
training_data = ...
# 从数据源加载带标签的向量数据集
# 初始化线性回归模型
mlr = MultipleLinearRegression() mlr.set_step_size(0.5) #
设置步长 mlr.set_max_iterations(100)
# 设置最大迭代次数 # 训练线性回归模型
mlr.fit(training_data)
# 获取训练后的模型参数
weights = mlr.weights_ intercept = mlr.intercept_
# 打印模型参数
print("Weights: ", weights) print("Intercept: ", intercept)在 Flink 中使用批处理 API 进行线性回归模型的训练。实际上,在 Flink 中进行更复杂的机器学习任务时,可能需要结合更多的预处理、特征工程、模型评估等步骤,以及更丰富的机器学习算法和模型库。
Flink Table API
Flink Table API 是 Apache Flink 提供的一种用于处理结构化数据的高级 API,它提供了一种类 SQL 的声明性编程方式,使用户可以通过类 SQL 的语法来操作流式和批处理数据。使用 Table API,用户可以方便地进行数据查询、转换、聚合等操作,而无需编写复杂的低级别代码。
下面是一个简单的示例,演示如何在 Flink 中使用 Table API 来实现对输入数据流的简单转换和聚合:
Java 示例:
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
public class TableAPIExample {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// 创建输入数据流
Table inputTable = tableEnv.fromDataStream(inputDataStream, "name, age");
// 查询和转换操作
Table resultTable = inputTable .filter("age > 18") .groupBy("name") .select("name, count(1) as count");
// 将结果表转换为数据流并打印输出 tableEnv.toRetractStream(resultTable, Row.class).print(); env.execute("Table API Example");
}
}Python 示例:
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.table import
StreamTableEnvironment env = StreamExecutionEnvironment.get_execution_environment()
table_env = StreamTableEnvironment.create(env)
# 创建输入数据流 input_table = table_env.from_data_stream(input_data_stream, ['name', 'age'])
# 查询和转换操作
result_table = input_table \ .filter("age > 18") \ .group_by("name") \ .select("name, count(1) as count")
# 将结果表转换为数据流并打印输出
table_env.to_retract_stream(result_table, Row).print() env.execute("Table API Example")创建了一个输入数据流,然后使用 Table API 对数据流进行过滤、分组和聚合操作,最后将结果表转换为数据流并打印输出。这展示了 Table API 的简单用法,更复杂的操作和功能可以根据具体需求进行扩展。
发展历史和市场优势
- 发展历史:Flink 于 2015 年正式发布,是一个快速发展的流处理引擎,Aflink 是 Flink 在国内的一个分支,也得到了广泛应用。
- 市场优势:Flink 和 Aflink 具有低延迟、高吞吐量等优势,适用于实时数据处理场景。在大数据领域,它们已成为重要的流式计算框架,广泛应用于金融、电商、物联网等行业。