前言
本章主要基于面试中的常见问题,进行 Binder 机制的讲解;
Binder 是什么?
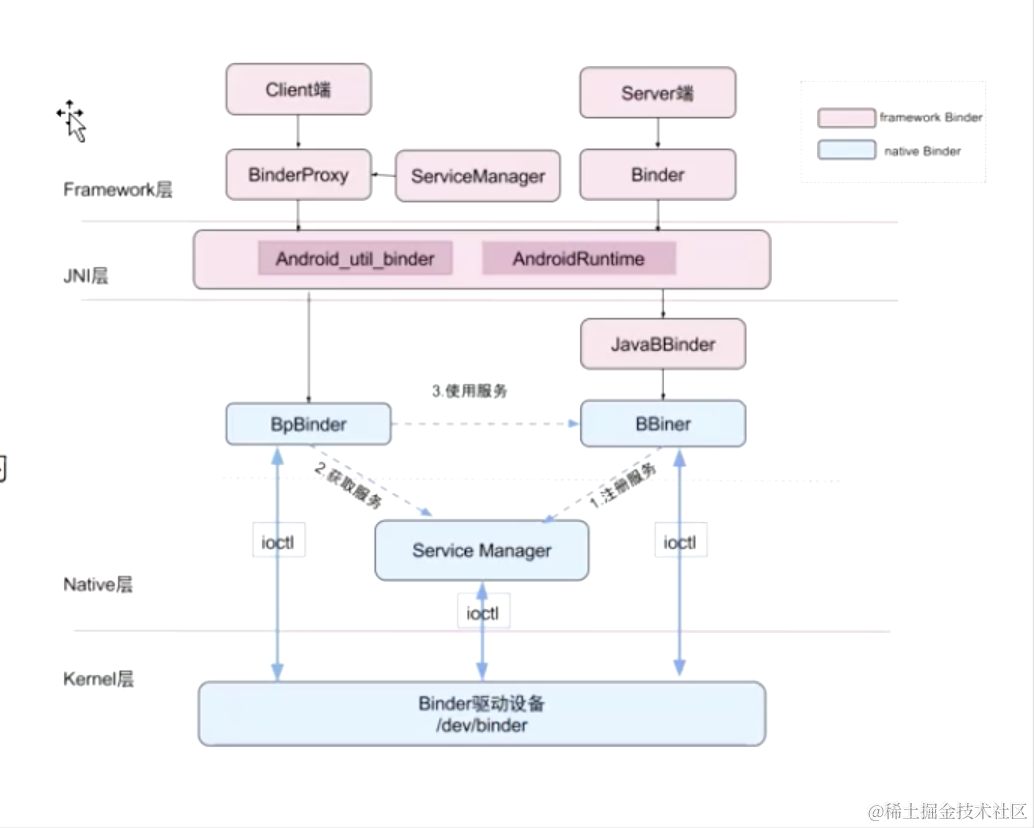
在 Android 中我们所使用的 Activity,Service 等组件都需要和 AMS 通信,这种跨进程的通信都是通过 Binder 完成的;
- 机制角度,Binder 是一种进程间通信机制;
- 驱动角度,站在内核层角度,Binder 是一个虚拟物理设备驱动;
- 应用层角度,Binder.java 是一个能发起通信的 Java 类。根据声明的 AIDL 文件,它会帮助我们生成一些 Binder 的子类,这些子类会帮助我们完成进程间通信;
- Framework、Native 角度,Binder 连接了 Client、Server、ServiceManager 和 Binder 驱动程序,形成一套 C/S 通信架构;
什么情况下使用多进程?多进程的优点有哪些
Binder 在跨进程通信中使用,那么什么情况下应该使用多进程呢?以及使用多进程有哪些优势呢?
- 突破进程内存限制,如图库占用内存太多(大图浏览);
- 功能稳定性,独立的通信进程保持长连接的稳定性(例如微信的通信,push);
- 规避系统内存泄漏,独立的 webview、播放器,进程阻隔内存泄露导致的问题;
- 隔离风险:对于不稳定的功能放入独立进程,避免导致主进程崩溃;
Binder 有什么优势?Android 为什么要用 Binder 来执行进程间通信
Linux 进程间都有哪些通信方式?
再说 Binder 优势的时候,我们先来看下 Linux 进程间都有哪些通信方式?
- 管道 Pipe;
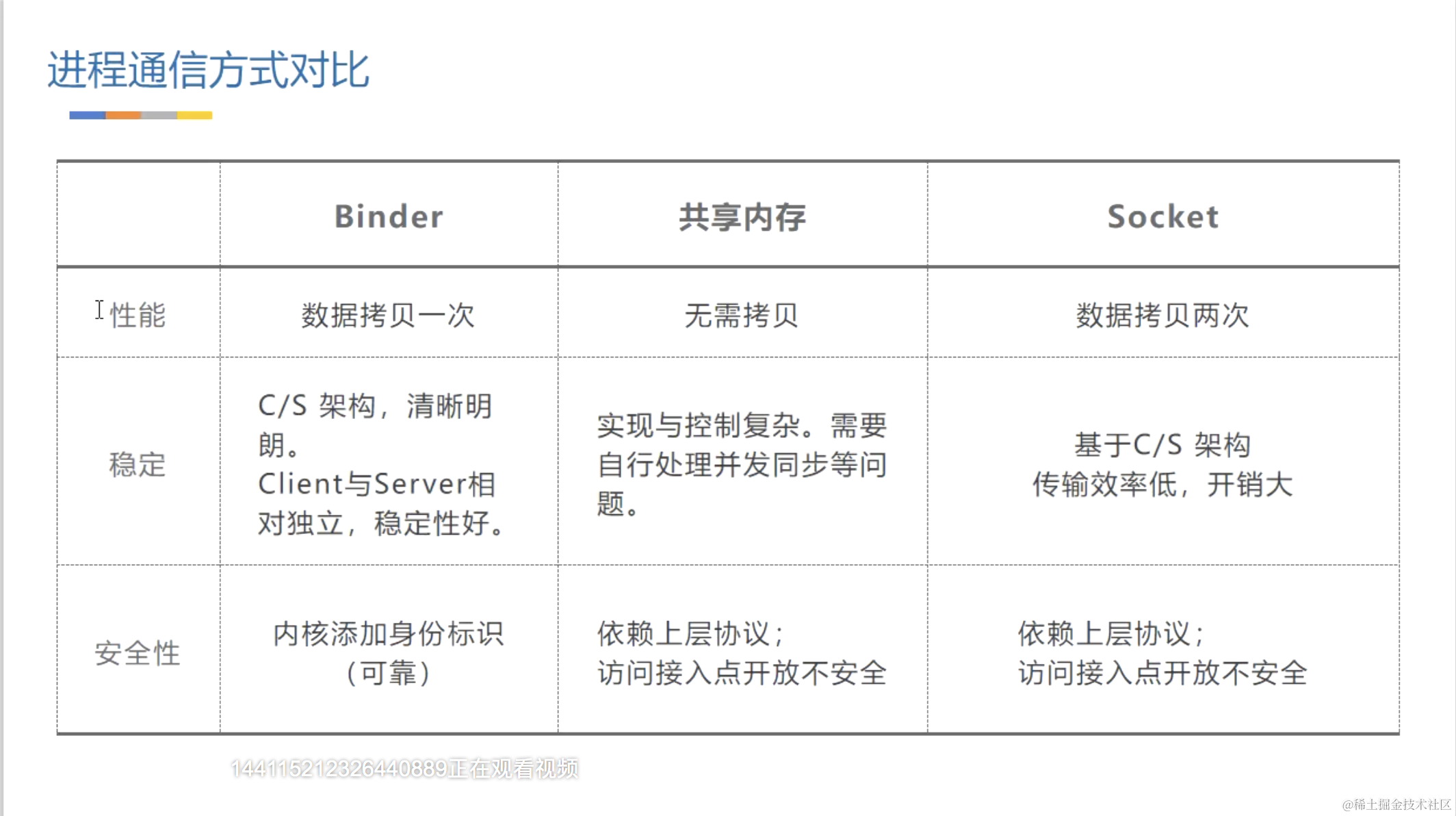
- Socket,它是基于C/S架构做为一款通用接口,传输效率低,开销大;Socket 进程通信的时候数据需要拷贝两次;Socket 通信依赖上层协议访问接入点是开放的,是不安全的;
- 信号量;
- 共享内存:数据无需拷贝;但是实现与控制较为复杂,需要自行处理并发同步等问题;依赖上层协议(不靠谱),访问接入点开放不安全(依赖上层协议 说的是身份识别的时候,当前 app 调用服务的时候,需要传递身份标识进行身份识别,当前 app 将自己的 pid 告诉服务,那么就可以随意的产出一个 pid 告诉服务,不靠谱)访问接入点开放,就类似公共汽车,谁都可以上车一样,不安全;
- Binder;
而 管道、Socket、信号量,它们的通信方式原理是一样的:都是内核空间通过系统调用将用户空间的数据复制一份到内核空间(copy from user)。再通过系统调用由内核空间复制给另一个进程的用户空间(copy to user),这种传统方式的通信进行了两次拷贝;
什么是系统调用?
copy_from_user 和 copy_to_user 就是系统调用;
Binder 有哪些优势?
Android 没有采用传统的进程间通信方式,而是采用了 Binder,那么 Binder 通信有哪些优势呢?
- 数据拷贝一次;
- C/S 架构,清晰明朗。Client 与 Server 相对独立,稳定性好;
- 除了性能上(拷贝一次)比共享内存(无需拷贝)差一些,其他都优于共享内存;
- 安全性有保证,内核添加身份(UID/PID)标识(可靠),支持实名和匿名;实名:系统服务就是实名制进行binder通信,例如我们可以直接通过 getSystemService() 来获取系统服务;匿名:自己启动的服务;UID 是由系统进行分配的一个字符串;
传统方式的进程间是如何通信的?
说完 Binder 的优势之后,我们来看 Binder 是如何通信的,再说 Binder 是如何通信之前,我们需要看下进程间是如何通信的;
由于进程间的内存是隔离的,不像线程之间是内存共享的,那么我们来看下进程间的内存是如何划分的:整体分为用户空间和内核空间,用户空间内存隔离,内核空间内存共享;
什么是内存空间
用户程序代码运行的地方;
什么是内核空间
内核代码运行的地方;
用户空间和内核空间 都是虚拟内存,但是 所有 app 的内核空间映射的物理内存都是同一个;
每个进程的用户空间都是独立的,也是隔离的,每个进程的用户空间和内核空间也是隔离的,但是所有的内核空间是共享的;
为了安全,它们是隔离的(也就是说用户空间拿不到内核空间的虚拟内存数据,内核空间也拿不到用户空间的虚拟内存数据),即使用户空间崩溃了,内核空间也不受影响;
所以,进程间通信的核心原理就是:A 进程将自己用户空间的数据交给内核空间,让内核空间交给接收方进程的用户空间,从而完成进程间通信,期间发生了两次拷贝,一次是从用户空间拷贝到内核空间(copy_from_user),一次是从内核空间拷贝到用户空间(copy_to_user);

PS: 不同架构系统,内存空间和内核空间划分也不同;
32位系统:即2的32次幂,总共可访问地址为4G,内核空间为1G,用户空间为3G。
64位系统:低位0-47位才是可变的有效地址(寻址空间256T),高位48-63位全部补0或者补1。一般高位全部补0对应的是用户空间,高位全部补1对应的是内核空间;

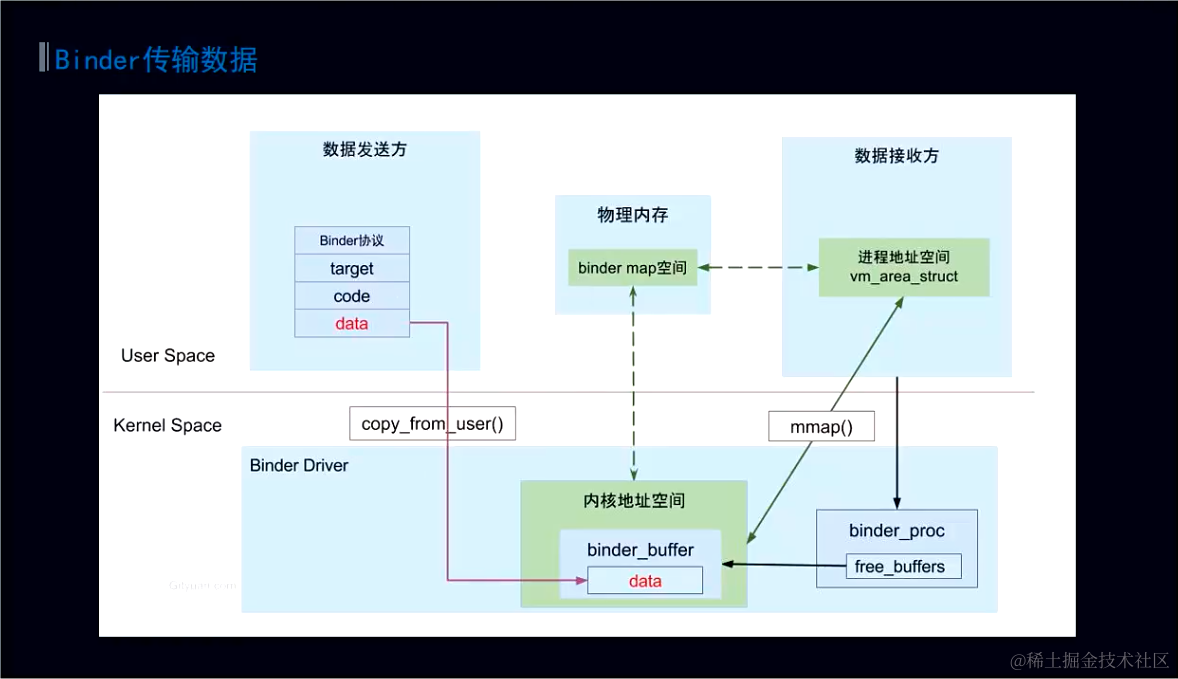
Binder 是如何做到一次拷贝的(如何通信)?
内核空间通过系统调用将A进程用户空间的数据复制一份到内核空间(copy from user);
内核空间的虚拟内存 最终都必须要关联到同一个物理内存「所有app的内核空间都映射同一个物理空间」(利用 MMU,将虚拟内存转换成物理内存);
内核空间将数据放到内核空间的虚拟内存,内核空间的这个虚拟内存映射的物理内存地址和接收方 B 进程的用户空间中虚拟内存映射的物理内存地址是同一个(如何映射:通过 mmap(零拷贝技术) 来完成映射);
内核往里面放,就相当于放到了 B 进程用户空间的虚拟内存中,B 进程可直接访问;
传统 IO 操作
这里要额外的说一下传统的 IO 操作
传统 IO 上,用户空间是不能直接操作文件的;
所以,传统 IO 执行了两次数据拷贝,虚拟内存拷贝到内核空间虚拟内存,再由内核空间虚拟内存拷贝到物理地址的文件;
用户态到内核态,以及内核态到物理文件的两次 copy 都是耗时的,所以 IO 操作是耗时的;
mmap 原理(Binder 通信原理)
Linux 通过将一个虚拟内存区域与文件描述符关联起来,以初始化这个虚拟内存区域的内容,这个过程称为内存映射(memory mapping);
通过 mmap(系统提供的 Api) 将文件和用户空间的虚拟内存映射区域建立了一个联系,用户空间可直接操作这个文件(无需通过 copy 数据到内核空间,再由内核空间到文件的过程);
对文件进行 mmap 会在进程的虚拟内存分配地址空间创建映射关系,实现这样的映射关系之后,就可以采用指针的方式读写操作这一段内存,而系统会自动回写到对应的文件磁盘上。
mmap 本质就是:能够让虚拟内存和指定的物理内存直接联系起来;
所以 mmap 相对于传统的 IO 的优势有如下几点:
- mmap 对文件的读写操作只需要从磁盘到用户主存的一次数据拷贝过程,减少了数据的拷贝次数,提高了文件操作效率;
- mmap 使用逻辑内存对磁盘进行映射,操作内存就相当于操作文件,不需要开启线程,操作 mmap 的速度和操作内存的速度一样快;
- mmap 提供一段可供随时写入的内存块,App 只管往里面写数据,由操作系统(如内存不足、进程退出等时候)负责将内存回写到文件;
共享内存是如何实现零拷贝的?
讲到这里,共享内存的零拷贝技术也就知道了,发送方 接收方 内核共同映射同一块物理内存就可以实现零拷贝了;
Binder 驱动是如何启动的?
linux 中一切皆文件,所以 Binder 驱动其实也是一个文件,既然是一个文件,那么就可以像 mmap 似的,指定一块内存和这个文件进行一个联系;
Binder 驱动的启动,可以从下面这张图中更详细的理解
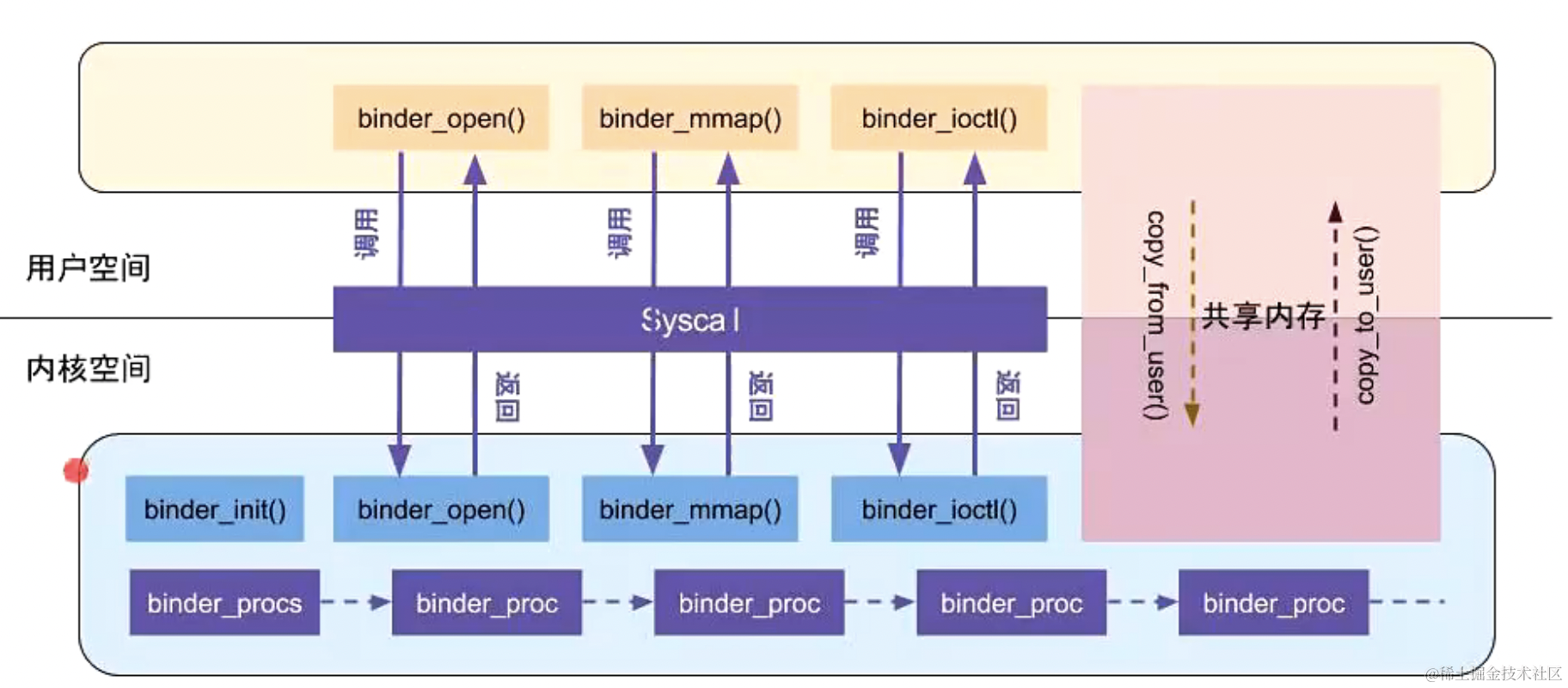
Binder 驱动的启动,主要是通过binder_init()、binder_open()、binder_mmap()、binder_ioctll() 四个方法来启动的;
binder_init()
Binder 启动的是 misc 设备,它是没有具体硬件的,它实际上就是一块内存,Android 为什么要使用 misc 设备,是因为注册简单;
binder_init() 这个方法具体做了什么?我们进入源码看下:
device_initcall(binder_init);
通过 device_initcall 来调用 binder_init 进行初始化启动,我们进入这个 binder_init 方法看下:
static int __init binder_init(void)
{
int ret;
char *device_name, *device_names;
struct binder_device *device;
struct hlist_node *tmp;
// 创建一个单线程的工作队列
binder_deferred_workqueue = create_singlethread_workqueue("binder");
if (!binder_deferred_workqueue)
return -ENOMEM;
binder_debugfs_dir_entry_root = debugfs_create_dir("binder", NULL);
if (binder_debugfs_dir_entry_root)
binder_debugfs_dir_entry_proc = debugfs_create_dir("proc",
binder_debugfs_dir_entry_root);
if (binder_debugfs_dir_entry_root) {
debugfs_create_file("state",
S_IRUGO,
binder_debugfs_dir_entry_root,
NULL,
&binder_state_fops);
debugfs_create_file("stats",
S_IRUGO,
binder_debugfs_dir_entry_root,
NULL,
&binder_stats_fops);
debugfs_create_file("transactions",
S_IRUGO,
binder_debugfs_dir_entry_root,
NULL,
&binder_transactions_fops);
debugfs_create_file("transaction_log",
S_IRUGO,
binder_debugfs_dir_entry_root,
&binder_transaction_log,
&binder_transaction_log_fops);
debugfs_create_file("failed_transaction_log",
S_IRUGO,
binder_debugfs_dir_entry_root,
&binder_transaction_log_failed,
&binder_transaction_log_fops);
}
/*
* Copy the module_parameter string, because we don't want to
* tokenize it in-place.
*/
device_names = kzalloc(strlen(binder_devices_param) + 1, GFP_KERNEL);
if (!device_names) {
ret = -ENOMEM;
goto err_alloc_device_names_failed;
}
// 执行了一次复制,将 devices 拷贝到 device_names 中,也就是从配置信息中读取 binderDevice
strcpy(device_names, binder_devices_param);
while ((device_name = strsep(&device_names, ","))) {
// 初始化 binder 设备
ret = init_binder_device(device_name);
if (ret)
goto err_init_binder_device_failed;
}
return ret;
err_init_binder_device_failed:
hlist_for_each_entry_safe(device, tmp, &binder_devices, hlist) {
misc_deregister(&device->miscdev);
hlist_del(&device->hlist);
kfree(device);
}
err_alloc_device_names_failed:
debugfs_remove_recursive(binder_debugfs_dir_entry_root);
destroy_workqueue(binder_deferred_workqueue);
return ret;
}
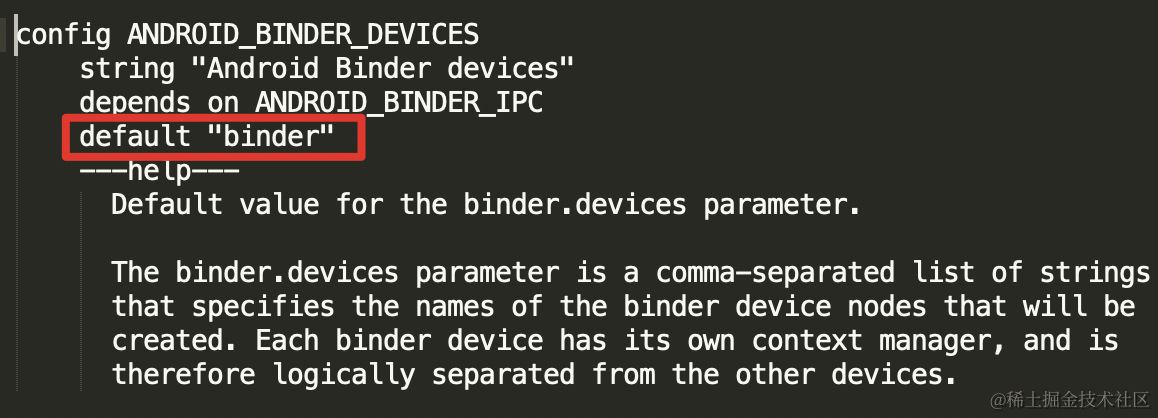
配置信息中的 binder_devices 就是 binder;
通过 init_binder_device 方法来初始化 Binder 设备,我们进入这个方法看下:
static int __init init_binder_device(const char *name)
{
int ret;
struct binder_device *binder_device;
// 为 binder 设备分配虚拟内存
binder_device = kzalloc(sizeof(*binder_device), GFP_KERNEL);
if (!binder_device)
return -ENOMEM;
// 对 binder 设备进行初始化
//
binder_device->miscdev.fops = &binder_fops;
binder_device->miscdev.minor = MISC_DYNAMIC_MINOR;
binder_device->miscdev.name = name;
// 获取 uid 放到 binder_service 中
binder_device->context.binder_context_mgr_uid = INVALID_UID;
binder_device->context.name = name;
ret = misc_register(&binder_device->miscdev);
if (ret < 0) {
kfree(binder_device);
return ret;
}
// 将 binder 设备添加到设备链表中
hlist_add_head(&binder_device->hlist, &binder_devices);
return ret;
}
这里用到了一个 &binder_fops 我们来看下这个数据结构
static const struct file_operations binder_fops = {
.owner = THIS_MODULE,
.poll = binder_poll,
.unlocked_ioctl = binder_ioctl,
.compat_ioctl = binder_ioctl,
// .mmap 是native 层, binder_mmap 就是驱动层
.mmap = binder_mmap,
.open = binder_open,
.flush = binder_flush,
.release = binder_release,
};
这里将 native 层和驱动层进行了一个映射;
所以 binder_init 做了三件事情:分配内存、初始化设备、添加到设备链表binder_devices;
binder_open()
我们接下来看下 binder_open 都做了什么,我们进入源码看下
static int binder_open(struct inode *nodp, struct file *filp)
{
struct binder_proc *proc;
struct binder_device *binder_dev;
binder_debug(BINDER_DEBUG_OPEN_CLOSE, "binder_open: %d:%d\n",
current->group_leader->pid, current->pid);
// 初始化一个结构体,分配内存,用来保存一个进程信息
proc = kzalloc(sizeof(*proc), GFP_KERNEL);
if (proc == NULL)
return -ENOMEM;
// 将当前线程任务栈保存到 proc,相当于是给这个 proc 结构体进行初始化
get_task_struct(current);
proc->tsk = current;
INIT_LIST_HEAD(&proc->todo);
init_waitqueue_head(&proc->wait);
// 将 nice 转换成优先级
proc->default_priority = task_nice(current);
binder_dev = container_of(filp->private_data, struct binder_device,
miscdev);
proc->context = &binder_dev->context;
// 创建一个同步锁,因为binder支持多线程,这里用来进行同步
binder_lock(__func__);
// proc 进行基数 +1
binder_stats_created(BINDER_STAT_PROC);
// 将 proc 添加到 binder_procs 数据链表中
hlist_add_head(&proc->proc_node, &binder_procs);
proc->pid = current->group_leader->pid;
INIT_LIST_HEAD(&proc->delivered_death);
// 将 proc 添加到 flip 中,后续 binder 都是从这里获取 proc
filp->private_data = proc;
binder_unlock(__func__);
if (binder_debugfs_dir_entry_proc) {
char strbuf[11];
snprintf(strbuf, sizeof(strbuf), "%u", proc->pid);
/*
* proc debug entries are shared between contexts, so
* this will fail if the process tries to open the driver
* again with a different context. The priting code will
* anyway print all contexts that a given PID has, so this
* is not a problem.
*/
proc->debugfs_entry = debugfs_create_file(strbuf, S_IRUGO,
binder_debugfs_dir_entry_proc,
(void *)(unsigned long)proc->pid,
&binder_proc_fops);
}
return 0;
}
驱动的打开,肯定是客户端或者服务端来调用,binder_open 在这里做了四件事:初始化 binder_proc 对象,将当前进程信息保存到 proc 中,将 proc 信息保存到 flip 中,将 binder_proc 添加到 binder_procs 链表中;
binder_mmap()
我们接下来看下 binder_mmap 都做了什么,我们进入源码看下:
// vma 进程的虚拟内存
static int binder_mmap(struct file *filp, struct vm_area_struct *vma)
{
int ret;
// area 内核的虚拟内存
struct vm_struct *area;
struct binder_proc *proc = filp->private_data;
const char *failure_string;
struct binder_buffer *buffer;
if (proc->tsk != current)
return -EINVAL;
// 先进行进程的虚拟内存判断,不能超过 4M(这个是驱动设定的)
if ((vma->vm_end - vma->vm_start) > SZ_4M)
vma->vm_end = vma->vm_start + SZ_4M;
binder_debug(BINDER_DEBUG_OPEN_CLOSE,
"binder_mmap: %d %lx-%lx (%ld K) vma %lx pagep %lx\n",
proc->pid, vma->vm_start, vma->vm_end,
(vma->vm_end - vma->vm_start) / SZ_1K, vma->vm_flags,
(unsigned long)pgprot_val(vma->vm_page_prot));
if (vma->vm_flags & FORBIDDEN_MMAP_FLAGS) {
ret = -EPERM;
failure_string = "bad vm_flags";
goto err_bad_arg;
}
vma->vm_flags = (vma->vm_flags | VM_DONTCOPY) & ~VM_MAYWRITE;
mutex_lock(&binder_mmap_lock);
// 是否已经做过映射
if (proc->buffer) {
ret = -EBUSY;
failure_string = "already mapped";
goto err_already_mapped;
}
// 给内核空间分配一块和用户空间、物理内存一样大的区域,并进行映射
area = get_vm_area(vma->vm_end - vma->vm_start, VM_IOREMAP);
if (area == NULL) {
ret = -ENOMEM;
failure_string = "get_vm_area";
goto err_get_vm_area_failed;
}
// 将 proc 中的 buffer 指针指向这一块内核空间虚拟内存
proc->buffer = area->addr;
// 计算偏移,这个偏移值是让用户空间来获取内核空间的数据的(用户空间 = 虚拟内存地址 + 偏移值)然后就指向了内核空间存放的数据地址;
proc->user_buffer_offset = vma->vm_start - (uintptr_t)proc->buffer;
mutex_unlock(&binder_mmap_lock);
#ifdef CONFIG_CPU_CACHE_VIPT
if (cache_is_vipt_aliasing()) {
while (CACHE_COLOUR((vma->vm_start ^ (uint32_t)proc->buffer))) {
pr_info("binder_mmap: %d %lx-%lx maps %p bad alignment\n", proc->pid, vma->vm_start, vma->vm_end, proc->buffer);
vma->vm_start += PAGE_SIZE;
}
}
#endif
// 分配内存
proc->pages = kzalloc(sizeof(proc->pages[0]) * ((vma->vm_end - vma->vm_start) / PAGE_SIZE), GFP_KERNEL);
if (proc->pages == NULL) {
ret = -ENOMEM;
failure_string = "alloc page array";
goto err_alloc_pages_failed;
}
proc->buffer_size = vma->vm_end - vma->vm_start;
vma->vm_ops = &binder_vm_ops;
vma->vm_private_data = proc;
// 分配物理内存
if (binder_update_page_range(proc, 1, proc->buffer, proc->buffer + PAGE_SIZE, vma)) {
ret = -ENOMEM;
failure_string = "alloc small buf";
goto err_alloc_small_buf_failed;
}
buffer = proc->buffer;
INIT_LIST_HEAD(&proc->buffers);
// buffer 添加到链表中
list_add(&buffer->entry, &proc->buffers);
// 标记内存可以使用了
buffer->free = 1;
binder_insert_free_buffer(proc, buffer);
// 异步传输的时候,可以使用的内存就变成了二分之一
proc->free_async_space = proc->buffer_size / 2;
barrier();
proc->files = get_files_struct(current);
proc->vma = vma;
proc->vma_vm_mm = vma->vm_mm;
/*pr_info("binder_mmap: %d %lx-%lx maps %p\n",
proc->pid, vma->vm_start, vma->vm_end, proc->buffer);*/
return 0;
err_alloc_small_buf_failed:
kfree(proc->pages);
proc->pages = NULL;
err_alloc_pages_failed:
mutex_lock(&binder_mmap_lock);
vfree(proc->buffer);
proc->buffer = NULL;
err_get_vm_area_failed:
err_already_mapped:
mutex_unlock(&binder_mmap_lock);
err_bad_arg:
pr_err("binder_mmap: %d %lx-%lx %s failed %d\n",
proc->pid, vma->vm_start, vma->vm_end, failure_string, ret);
return ret;
}
通过 binder_update_page_range 分配物理内存,我们进入这个方法看下:
static int binder_update_page_range(struct binder_proc *proc, int allocate,
void *start, void *end,
struct vm_area_struct *vma)
{
void *page_addr;
unsigned long user_page_addr;
struct page **page;
struct mm_struct *mm;
binder_debug(BINDER_DEBUG_BUFFER_ALLOC,
"%d: %s pages %p-%p\n", proc->pid,
allocate ? "allocate" : "free", start, end);
if (end <= start)
return 0;
trace_binder_update_page_range(proc, allocate, start, end);
if (vma)
mm = NULL;
else
mm = get_task_mm(proc->tsk);
if (mm) {
down_write(&mm->mmap_sem);
vma = proc->vma;
if (vma && mm != proc->vma_vm_mm) {
pr_err("%d: vma mm and task mm mismatch\n",
proc->pid);
vma = NULL;
}
}
if (allocate == 0)
goto free_range;
if (vma == NULL) {
pr_err("%d: binder_alloc_buf failed to map pages in userspace, no vma\n",
proc->pid);
goto err_no_vma;
}
for (page_addr = start; page_addr < end; page_addr += PAGE_SIZE) {
int ret;
page = &proc->pages[(page_addr - proc->buffer) / PAGE_SIZE];
BUG_ON(*page);
// 分配一个 page 页(4kb的物理内存)
*page = alloc_page(GFP_KERNEL | __GFP_HIGHMEM | __GFP_ZERO);
if (*page == NULL) {
pr_err("%d: binder_alloc_buf failed for page at %p\n",
proc->pid, page_addr);
goto err_alloc_page_failed;
}
// 把物理空间映射的虚拟内核空间(mmap映射的地方)
ret = map_kernel_range_noflush((unsigned long)page_addr,
PAGE_SIZE, PAGE_KERNEL, page);
flush_cache_vmap((unsigned long)page_addr,
(unsigned long)page_addr + PAGE_SIZE);
if (ret != 1) {
pr_err("%d: binder_alloc_buf failed to map page at %p in kernel\n",
proc->pid, page_addr);
goto err_map_kernel_failed;
}
user_page_addr =
(uintptr_t)page_addr + proc->user_buffer_offset;
// 把用户空间的虚拟内存映射到物理内存
ret = vm_insert_page(vma, user_page_addr, page[0]);
if (ret) {
pr_err("%d: binder_alloc_buf failed to map page at %lx in userspace\n",
proc->pid, user_page_addr);
goto err_vm_insert_page_failed;
}
/* vm_insert_page does not seem to increment the refcount */
}
if (mm) {
up_write(&mm->mmap_sem);
mmput(mm);
}
return 0;
free_range:
for (page_addr = end - PAGE_SIZE; page_addr >= start;
page_addr -= PAGE_SIZE) {
page = &proc->pages[(page_addr - proc->buffer) / PAGE_SIZE];
if (vma)
zap_page_range(vma, (uintptr_t)page_addr +
proc->user_buffer_offset, PAGE_SIZE, NULL);
err_vm_insert_page_failed:
unmap_kernel_range((unsigned long)page_addr, PAGE_SIZE);
err_map_kernel_failed:
__free_page(*page);
*page = NULL;
err_alloc_page_failed:
;
}
err_no_vma:
if (mm) {
up_write(&mm->mmap_sem);
mmput(mm);
}
return -ENOMEM;
}
通过 binder_insert_free_buffer 计算出我们可以使用的 buffer 大小,我们进入这个方法看下:
static void binder_insert_free_buffer(struct binder_proc *proc,
struct binder_buffer *new_buffer)
{
struct rb_node **p = &proc->free_buffers.rb_node;
struct rb_node *parent = NULL;
struct binder_buffer *buffer;
size_t buffer_size;
size_t new_buffer_size;
BUG_ON(!new_buffer->free);
new_buffer_size = binder_buffer_size(proc, new_buffer);
binder_debug(BINDER_DEBUG_BUFFER_ALLOC,
"%d: add free buffer, size %zd, at %p\n",
proc->pid, new_buffer_size, new_buffer);
while (*p) {
parent = *p;
buffer = rb_entry(parent, struct binder_buffer, rb_node);
BUG_ON(!buffer->free);
// 主要是通过这里获取可用 buffer 大小
buffer_size = binder_buffer_size(proc, buffer);
if (new_buffer_size < buffer_size)
p = &parent->rb_left;
else
p = &parent->rb_right;
}
rb_link_node(&new_buffer->rb_node, parent, p);
// 将可用的 buffer 插入到 free_buffers 中
rb_insert_color(&new_buffer->rb_node, &proc->free_buffers);
}
binder_mmap 主要做了三件事,通过用户空间虚拟内存大小分配了一块内核空间同等大小的虚拟内存,分配了一块4kb的物理内存,把这块物理内存分别映射到用户空间的虚拟内存和内核空间的虚拟内存;
这里的 4kb 只是先分配,等到真正要使用的时候,要用多少分配多少;
binder_ioctl()
这个方法主要是用来进行文件的读写操作的,我们进入这个方法看一下:
static long binder_ioctl(struct file *filp, unsigned int cmd, unsigned long arg)
{
int ret;
struct binder_proc *proc = filp->private_data;
struct binder_thread *thread;
unsigned int size = _IOC_SIZE(cmd);
void __user *ubuf = (void __user *)arg;
/*pr_info("binder_ioctl: %d:%d %x %lx\n",
proc->pid, current->pid, cmd, arg);*/
trace_binder_ioctl(cmd, arg);
ret = wait_event_interruptible(binder_user_error_wait, binder_stop_on_user_error < 2);
if (ret)
goto err_unlocked;
binder_lock(__func__);
thread = binder_get_thread(proc);
if (thread == NULL) {
ret = -ENOMEM;
goto err;
}
switch (cmd) {
// 用的最多的主要是这个 case 下的 binder_ioctl_write_read 这个方法
case BINDER_WRITE_READ:
ret = binder_ioctl_write_read(filp, cmd, arg, thread);
if (ret)
goto err;
break;
case BINDER_SET_MAX_THREADS:
if (copy_from_user(&proc->max_threads, ubuf, sizeof(proc->max_threads))) {
ret = -EINVAL;
goto err;
}
break;
case BINDER_SET_CONTEXT_MGR:
ret = binder_ioctl_set_ctx_mgr(filp);
if (ret)
goto err;
break;
case BINDER_THREAD_EXIT:
binder_debug(BINDER_DEBUG_THREADS, "%d:%d exit\n",
proc->pid, thread->pid);
binder_free_thread(proc, thread);
thread = NULL;
break;
case BINDER_VERSION: {
struct binder_version __user *ver = ubuf;
if (size != sizeof(struct binder_version)) {
ret = -EINVAL;
goto err;
}
if (put_user(BINDER_CURRENT_PROTOCOL_VERSION,
&ver->protocol_version)) {
ret = -EINVAL;
goto err;
}
break;
}
default:
ret = -EINVAL;
goto err;
}
ret = 0;
err:
if (thread)
thread->looper &= ~BINDER_LOOPER_STATE_NEED_RETURN;
binder_unlock(__func__);
wait_event_interruptible(binder_user_error_wait, binder_stop_on_user_error < 2);
if (ret && ret != -ERESTARTSYS)
pr_info("%d:%d ioctl %x %lx returned %d\n", proc->pid, current->pid, cmd, arg, ret);
err_unlocked:
trace_binder_ioctl_done(ret);
return ret;
}
用的最多的主要是这个 case 下的 binder_ioctl_write_read 这个方法,我们进入这个方法看下:
static int binder_ioctl_write_read(struct file *filp,
unsigned int cmd, unsigned long arg,
struct binder_thread *thread)
{
int ret = 0;
struct binder_proc *proc = filp->private_data;
unsigned int size = _IOC_SIZE(cmd);
void __user *ubuf = (void __user *)arg;
struct binder_write_read bwr;
if (size != sizeof(struct binder_write_read)) {
ret = -EINVAL;
goto out;
}
if (copy_from_user(&bwr, ubuf, sizeof(bwr))) {
ret = -EFAULT;
goto out;
}
binder_debug(BINDER_DEBUG_READ_WRITE,
"%d:%d write %lld at %016llx, read %lld at %016llx\n",
proc->pid, thread->pid,
(u64)bwr.write_size, (u64)bwr.write_buffer,
(u64)bwr.read_size, (u64)bwr.read_buffer);
// 写数据
if (bwr.write_size > 0) {
ret = binder_thread_write(proc, thread,
bwr.write_buffer,
bwr.write_size,
&bwr.write_consumed);
trace_binder_write_done(ret);
if (ret < 0) {
bwr.read_consumed = 0;
if (copy_to_user(ubuf, &bwr, sizeof(bwr)))
ret = -EFAULT;
goto out;
}
}
// 读数据
if (bwr.read_size > 0) {
ret = binder_thread_read(proc, thread, bwr.read_buffer,
bwr.read_size,
&bwr.read_consumed,
filp->f_flags & O_NONBLOCK);
trace_binder_read_done(ret);
if (!list_empty(&proc->todo))
wake_up_interruptible(&proc->wait);
if (ret < 0) {
if (copy_to_user(ubuf, &bwr, sizeof(bwr)))
ret = -EFAULT;
goto out;
}
}
binder_debug(BINDER_DEBUG_READ_WRITE,
"%d:%d wrote %lld of %lld, read return %lld of %lld\n",
proc->pid, thread->pid,
(u64)bwr.write_consumed, (u64)bwr.write_size,
(u64)bwr.read_consumed, (u64)bwr.read_size);
if (copy_to_user(ubuf, &bwr, sizeof(bwr))) {
ret = -EFAULT;
goto out;
}
out:
return ret;
}
我们接下来看下 jni 层调用流程;
我们 zygote 的启动,会通过 /system/core/rootdir/init.zygote32.rc文件中的命令进行启动,通过这个命令就会启动我们的 app_main.cpp 下的 main 方法;
service zygote /system/bin/app_process -Xzygote /system/bin --zygote --start-system-server
class main
socket zygote stream 660 root system
onrestart write /sys/android_power/request_state wake
onrestart write /sys/power/state on
onrestart restart media
onrestart restart netd
writepid /dev/cpuset/foreground/tasks
我们进入这个 main 方法看下:
int main(int argc, char* const argv[])
{
if (prctl(PR_SET_NO_NEW_PRIVS, 1, 0, 0, 0) < 0) {
// Older kernels don't understand PR_SET_NO_NEW_PRIVS and return
// EINVAL. Don't die on such kernels.
if (errno != EINVAL) {
LOG_ALWAYS_FATAL("PR_SET_NO_NEW_PRIVS failed: %s", strerror(errno));
return 12;
}
}
AppRuntime runtime(argv[0], computeArgBlockSize(argc, argv));
// Process command line arguments
// ignore argv[0]
argc--;
argv++;
// Everything up to '--' or first non '-' arg goes to the vm.
//
// The first argument after the VM args is the "parent dir", which
// is currently unused.
//
// After the parent dir, we expect one or more the following internal
// arguments :
//
// --zygote : Start in zygote mode
// --start-system-server : Start the system server.
// --application : Start in application (stand alone, non zygote) mode.
// --nice-name : The nice name for this process.
//
// For non zygote starts, these arguments will be followed by
// the main class name. All remaining arguments are passed to
// the main method of this class.
//
// For zygote starts, all remaining arguments are passed to the zygote.
// main function.
//
// Note that we must copy argument string values since we will rewrite the
// entire argument block when we apply the nice name to argv0.
int i;
for (i = 0; i < argc; i++) {
if (argv[i][0] != '-') {
break;
}
if (argv[i][1] == '-' && argv[i][2] == 0) {
++i; // Skip --.
break;
}
runtime.addOption(strdup(argv[i]));
}
// Parse runtime arguments. Stop at first unrecognized option.
bool zygote = false;
bool startSystemServer = false;
bool application = false;
String8 niceName;
String8 className;
++i; // Skip unused "parent dir" argument.
while (i < argc) {
const char* arg = argv[i++];
// 判断是不是 zygote 启动
if (strcmp(arg, "--zygote") == 0) {
zygote = true;
niceName = ZYGOTE_NICE_NAME;
} else if (strcmp(arg, "--start-system-server") == 0) {
startSystemServer = true;
} else if (strcmp(arg, "--application") == 0) {
application = true;
} else if (strncmp(arg, "--nice-name=", 12) == 0) {
niceName.setTo(arg + 12);
} else if (strncmp(arg, "--", 2) != 0) {
className.setTo(arg);
break;
} else {
--i;
break;
}
}
Vector<String8> args;
if (!className.isEmpty()) {
// We're not in zygote mode, the only argument we need to pass
// to RuntimeInit is the application argument.
//
// The Remainder of args get passed to startup class main(). Make
// copies of them before we overwrite them with the process name.
args.add(application ? String8("application") : String8("tool"));
runtime.setClassNameAndArgs(className, argc - i, argv + i);
} else {
// We're in zygote mode.
maybeCreateDalvikCache();
if (startSystemServer) {
args.add(String8("start-system-server"));
}
char prop[PROP_VALUE_MAX];
if (property_get(ABI_LIST_PROPERTY, prop, NULL) == 0) {
LOG_ALWAYS_FATAL("app_process: Unable to determine ABI list from property %s.",
ABI_LIST_PROPERTY);
return 11;
}
String8 abiFlag("--abi-list=");
abiFlag.append(prop);
args.add(abiFlag);
// In zygote mode, pass all remaining arguments to the zygote
// main() method.
for (; i < argc; ++i) {
args.add(String8(argv[i]));
}
}
if (!niceName.isEmpty()) {
runtime.setArgv0(niceName.string());
set_process_name(niceName.string());
}
if (zygote) {
// 如果是 zygote 启动,就会执行 AppRuntime(继承 AndroidRuntime) 的 start 方法
runtime.start("com.android.internal.os.ZygoteInit", args, zygote);
} else if (className) {
runtime.start("com.android.internal.os.RuntimeInit", args, zygote);
} else {
fprintf(stderr, "Error: no class name or --zygote supplied.\n");
app_usage();
LOG_ALWAYS_FATAL("app_process: no class name or --zygote supplied.");
return 10;
}
}
如果是 zygote 启动,就会执行 AppRuntime(继承 AndroidRuntime) 的 start 方法,我们进入 AndroidRuntime 的 start 方法看下:
void AndroidRuntime::start(const char* className, const Vector<String8>& options, bool zygote)
{
ALOGD(">>>>>> START %s uid %d <<<<<<\n",
className != NULL ? className : "(unknown)", getuid());
static const String8 startSystemServer("start-system-server");
/*
* 'startSystemServer == true' means runtime is obsolete and not run from
* init.rc anymore, so we print out the boot start event here.
*/
for (size_t i = 0; i < options.size(); ++i) {
if (options[i] == startSystemServer) {
/* track our progress through the boot sequence */
const int LOG_BOOT_PROGRESS_START = 3000;
LOG_EVENT_LONG(LOG_BOOT_PROGRESS_START, ns2ms(systemTime(SYSTEM_TIME_MONOTONIC)));
}
}
const char* rootDir = getenv("ANDROID_ROOT");
if (rootDir == NULL) {
rootDir = "/system";
if (!hasDir("/system")) {
LOG_FATAL("No root directory specified, and /android does not exist.");
return;
}
setenv("ANDROID_ROOT", rootDir, 1);
}
//const char* kernelHack = getenv("LD_ASSUME_KERNEL");
//ALOGD("Found LD_ASSUME_KERNEL='%s'\n", kernelHack);
/* start the virtual machine */
JniInvocation jni_invocation;
jni_invocation.Init(NULL);
JNIEnv* env;
if (startVm(&mJavaVM, &env, zygote) != 0) {
return;
}
onVmCreated(env);
// 我们只需要关心这里就可以了,这里就是进行注册的逻辑
/*
* Register android functions.
*/
if (startReg(env) < 0) {
ALOGE("Unable to register all android natives\n");
return;
}
/*
* We want to call main() with a String array with arguments in it.
* At present we have two arguments, the class name and an option string.
* Create an array to hold them.
*/
jclass stringClass;
jobjectArray strArray;
jstring classNameStr;
stringClass = env->FindClass("java/lang/String");
assert(stringClass != NULL);
strArray = env->NewObjectArray(options.size() + 1, stringClass, NULL);
assert(strArray != NULL);
classNameStr = env->NewStringUTF(className);
assert(classNameStr != NULL);
env->SetObjectArrayElement(strArray, 0, classNameStr);
for (size_t i = 0; i < options.size(); ++i) {
jstring optionsStr = env->NewStringUTF(options.itemAt(i).string());
assert(optionsStr != NULL);
env->SetObjectArrayElement(strArray, i + 1, optionsStr);
}
/*
* Start VM. This thread becomes the main thread of the VM, and will
* not return until the VM exits.
*/
char* slashClassName = toSlashClassName(className);
jclass startClass = env->FindClass(slashClassName);
if (startClass == NULL) {
ALOGE("JavaVM unable to locate class '%s'\n", slashClassName);
/* keep going */
} else {
jmethodID startMeth = env->GetStaticMethodID(startClass, "main",
"([Ljava/lang/String;)V");
if (startMeth == NULL) {
ALOGE("JavaVM unable to find main() in '%s'\n", className);
/* keep going */
} else {
env->CallStaticVoidMethod(startClass, startMeth, strArray);
#if 0
if (env->ExceptionCheck())
threadExitUncaughtException(env);
#endif
}
}
free(slashClassName);
ALOGD("Shutting down VM\n");
if (mJavaVM->DetachCurrentThread() != JNI_OK)
ALOGW("Warning: unable to detach main thread\n");
if (mJavaVM->DestroyJavaVM() != 0)
ALOGW("Warning: VM did not shut down cleanly\n");
}
我们只需要关心 startReg 这里就可以了,这里就是进行 jni 的注册的逻辑;
int AndroidRuntime::startReg(JNIEnv* env)
{
/*
* This hook causes all future threads created in this process to be
* attached to the JavaVM. (This needs to go away in favor of JNI
* Attach calls.)
*/
androidSetCreateThreadFunc((android_create_thread_fn) javaCreateThreadEtc);
ALOGV("--- registering native functions ---\n");
/*
* Every "register" function calls one or more things that return
* a local reference (e.g. FindClass). Because we haven't really
* started the VM yet, they're all getting stored in the base frame
* and never released. Use Push/Pop to manage the storage.
*/
env->PushLocalFrame(200);
// 进行 jni 的注册逻辑,系统启动的时候就会注册系统的 jni 方法,这样 java 方法才能调用到 native 方法;
if (register_jni_procs(gRegJNI, NELEM(gRegJNI), env) < 0) {
env->PopLocalFrame(NULL);
return -1;
}
env->PopLocalFrame(NULL);
//createJavaThread("fubar", quickTest, (void*) "hello");
return 0;
}
进行 jni 的注册逻辑,系统启动的时候就会注册系统的 jni 方法,这样 java 方法才能调用到 native 方法;我们进入这个 register_jni_procs 方法看下:
static int register_jni_procs(const RegJNIRec array[], size_t count, JNIEnv* env)
{
for (size_t i = 0; i < count; i++) {
// array[i] 就是 RegJNIRec
if (array[i].mProc(env) < 0) {
#ifndef NDEBUG
ALOGD("----------!!! %s failed to load\n", array[i].mName);
#endif
return -1;
}
}
return 0;
}
就会调用这些方法:
这里就有一个 REG_JNI(register_android_os_Binder) binder 的注册就在这里,我们进入这个方法看下:
int register_android_os_Binder(JNIEnv* env)
{
// 主要是这三个方法,注册binder、binderInternal、binderProxy,我们看其中一个方法就可以
if (int_register_android_os_Binder(env) < 0)
return -1;
if (int_register_android_os_BinderInternal(env) < 0)
return -1;
if (int_register_android_os_BinderProxy(env) < 0)
return -1;
jclass clazz = FindClassOrDie(env, "android/util/Log");
gLogOffsets.mClass = MakeGlobalRefOrDie(env, clazz);
gLogOffsets.mLogE = GetStaticMethodIDOrDie(env, clazz, "e",
"(Ljava/lang/String;Ljava/lang/String;Ljava/lang/Throwable;)I");
clazz = FindClassOrDie(env, "android/os/ParcelFileDescriptor");
gParcelFileDescriptorOffsets.mClass = MakeGlobalRefOrDie(env, clazz);
gParcelFileDescriptorOffsets.mConstructor = GetMethodIDOrDie(env, clazz, "<init>",
"(Ljava/io/FileDescriptor;)V");
clazz = FindClassOrDie(env, "android/os/StrictMode");
gStrictModeCallbackOffsets.mClass = MakeGlobalRefOrDie(env, clazz);
gStrictModeCallbackOffsets.mCallback = GetStaticMethodIDOrDie(env, clazz,
"onBinderStrictModePolicyChange", "(I)V");
return 0;
}
主要是这三个方法,注册binder、binderInternal、binderProxy,我们看其中一个方法就可以,int_register_android_os_Binder 进入这个方法看下:
const char* const kBinderPathName = "android/os/Binder";
static int int_register_android_os_Binder(JNIEnv* env)
{
// 拿到 Binder 的 class 对象
jclass clazz = FindClassOrDie(env, kBinderPathName);
// 通过 gBinderOffsets 这个结构体,保存 java 的一些信息,可以想象成反射
gBinderOffsets.mClass = MakeGlobalRefOrDie(env, clazz);
gBinderOffsets.mExecTransact = GetMethodIDOrDie(env, clazz, "execTransact", "(IJJI)Z");
gBinderOffsets.mObject = GetFieldIDOrDie(env, clazz, "mObject", "J");
// 获取 gBinderMethods 注册 java 与 native 方法的映射关系;
return RegisterMethodsOrDie(
env, kBinderPathName,
gBinderMethods, NELEM(gBinderMethods));
}
tatic const JNINativeMethod gBinderMethods[] = {
/* name, signature, funcPtr */
{ "getCallingPid", "()I", (void*)android_os_Binder_getCallingPid },
{ "getCallingUid", "()I", (void*)android_os_Binder_getCallingUid },
{ "clearCallingIdentity", "()J", (void*)android_os_Binder_clearCallingIdentity },
{ "restoreCallingIdentity", "(J)V", (void*)android_os_Binder_restoreCallingIdentity },
{ "setThreadStrictModePolicy", "(I)V", (void*)android_os_Binder_setThreadStrictModePolicy },
{ "getThreadStrictModePolicy", "()I", (void*)android_os_Binder_getThreadStrictModePolicy },
{ "flushPendingCommands", "()V", (void*)android_os_Binder_flushPendingCommands },
{ "init", "()V", (void*)android_os_Binder_init },
{ "destroy", "()V", (void*)android_os_Binder_destroy },
{ "blockUntilThreadAvailable", "()V", (void*)android_os_Binder_blockUntilThreadAvailable }
};
可以看到 这里存放的就是 java 层可以用调用的方法;通过 int_register_android_os_Binder 这个方法 就是实现了 Java 与 native 的互相通信;
好了,binder 的启动就讲解到这里吧,我们接下来进行 MMKV 的核心实现:
MMKV 核心实现
这里直接上代码吧,核心实现其实还是比较简单的:
#include <jni.h>
#include <string>
#include <fcntl.h>
#include <unistd.h>
#include <sys/stat.h>
#include <sys/mman.h>
#include <android/log.h>
int8_t *m_ptr;
int32_t m_size;
int m_fd;
extern "C"
JNIEXPORT void JNICALL
Java_com_test_llc_1binder_MainActivity_writeTest(JNIEnv *env, jobject thiz) {
std::string file = "/sdcard/a.txt";
//打开文件
m_fd = open(file.c_str(), O_RDWR | O_CREAT, S_IRWXU);
//获得一页内存大小
//Linux采用了分页来管理内存,即内存的管理中,内存是以页为单位,一般的32位系统一页为 4096个字节
m_size = getpagesize();
//将文件设置为 m_size这么大
ftruncate(m_fd, m_size); // 100 1000 10000
// m_size:映射区的长度。 需要是整数页个字节 byte[]
m_ptr = (int8_t *) mmap(0, m_size, PROT_READ | PROT_WRITE, MAP_SHARED, m_fd,
0);
std::string data("mars刚刚写入的数据");
//将 data 的 data.size() 个数据 拷贝到 m_ptr
//Java 类似的:
// byte[] src = new byte[10];
// byte[] dst = new byte[10];
// System.arraycopy(src, 0, dst, 0, src.length);
memcpy(m_ptr, data.data(), data.size());
__android_log_print(ANDROID_LOG_ERROR, "mars", "写入数据:%s", data.c_str());
}
extern "C"
JNIEXPORT void JNICALL
Java_com_test_llc_1binder_MainActivity_readTest(JNIEnv *env, jobject thiz) {
//申请内存
char *buf = static_cast<char *>(malloc(100));
memcpy(buf, m_ptr, 100);
std::string result(buf);
__android_log_print(ANDROID_LOG_ERROR, "mars", "读取数据:%s", result.c_str());
//取消映射
munmap(m_ptr, m_size);
//关闭文件
close(m_fd);
}
简历润色
深度理解 Binder 原理、mmap原理,可手写 MMKV 核心实现
下一章预告
进程通信,启动与获取SM服务
欢迎三连
来都来了,点个关注点个赞吧,你的支持是我最大的动力~~~