1.面向对象的常见知识点
类、
对象、
成员变量(属性)、成员函数(方法)、
封装、继承、多态
2.类
在C++中可以通过struct、class定义一个类
struct和class的区别:
struct的默认权限是public(在C语言中struct内部是不可以定义函数的) 而class的默认权限是private(该权限限制了用class定义的类中的成员只可以在当前类中进行访问 不可以在当前源文件中除了类以外的其他地方访问)
虽说C语言的struct中不可以直接定义函数 但是可以间接定义 通过函数指针的方式指向一个函数 从而达到间接定义函数的目的
以下是C语言中模拟的通过struct定义的类
void test() {
printf("hello world\n");
}
struct Person {
int age;
void(*run)();
};
int main() {
struct Person p;
p.age = 10;
p.run = test;
p.run();
getchar();
return 0;
}
但是在C++中 其实struct也可以用来定义结构体 那么struct到底是叫做结构体还是类 其实并不需要去纠结这个问题 因为这属于语法糖层面的问题
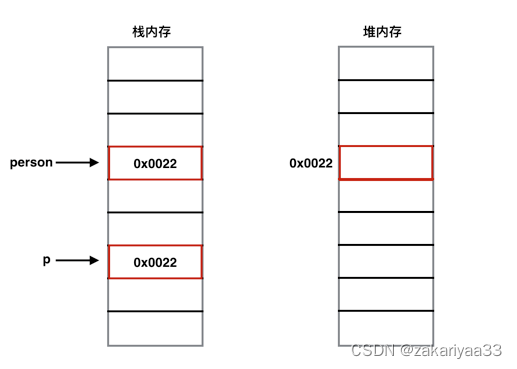
以下是C++中通过struct定义的类 而且在C++中 Person p就是在定义一个对象 只不过这个对象是存放在栈空间中 有别于Java中对象存放在堆空间的事实
struct Person {
int m_age;
void run() {
cout << "Person::run() - " << m_age << endl;
}
};
int main() {
Person p;
p.m_age = 10;
getchar();
return 0;
}
以下则是C++中通过class定义的类
class Person {
public:
int m_age;
void test() {
cout << "Person::test() - " << m_age << endl;
}
};
int main() {
Person p;
p.m_age = 30;
p.test();
getchar();
return 0;
}
以上案例都是通过类变量直接访问类对象中的成员 我们也可以通过指针来间接访问类对象中的成员 以下是详细案例
class Person {
public:
int m_age;
void test() {
cout << "Person::test() - " << m_age << endl;
}
};
int main() {
Person person;
Person* p = &person;
p->m_age = 11;
p->test();
getchar();
return 0;
}
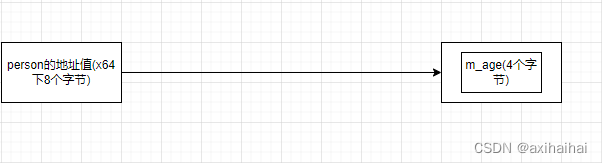
上述的person对象和p指针这些局部变量都是在函数的栈空间中自动分配和回收的 其中对于person对象来说 他的大小等价于m_age的大小
struct和class之间除了上述说的这个访问权限的区别之外 我们还可以利用反汇编去看一下是否存在其他的区别
以下是通过class定义类的代码以及汇编
class Car {
public:
int m_price;
};
int main() {
Car car;
car.m_price = 10;
getchar();
return 0;
}

以下是通过struct定义的代码和汇编
struct Car {
int m_price;
};
int main() {
Car car;
car.m_price = 10;
getchar();
return 0;
}

对比一下两者的汇编 可以发现 其实两者的底层是一模一样的 他们的唯一差别在于:class的默认权限是private 而struct的默认权限是public
对于以上的分析 可能会有这样的疑问 为什么对象的内存中只储存了成员变量的内存 而没有储存成员函数的内存呢
首先对于成员变量来说 肯定是每一个对象都有一块分配给成员变量的内存 因为每一个对象的属性都各不相同
但是对于成员函数来说 每一个对象共用一块成员函数的内存就够了(每一个对象调用函数所执行的代码相似甚至一样) 而且这块分配给成员函数的内存并不储存在对象中 而是储存在其他地方
至于更深层的原因 等到后面就会逐一解释的
以下是对于每个对象中都有一块分配给成员变量的内存 而每个对象都共用一块分配给成员函数的内存说法的检验
struct Car {
int m_price;
void run() {
cout << "Car::run() - " << m_price << endl;
}
};
int main() {
Car car1;
car1.m_price = 10;
car1.run();
Car car2;
car2.m_price = 20;
car2.run();
Car car3;
car3.m_price = 30;
car3.run();
getchar();
return 0;
}
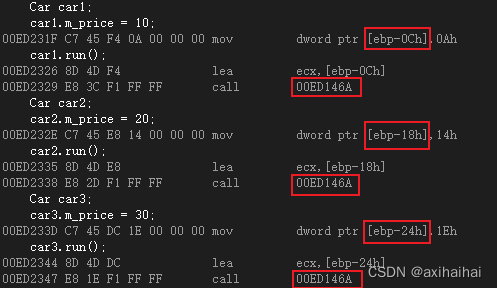
我们可以看到 三个对象中的三个成员变量的地址值是不一样的 说明每个对象中都有各自独立的成员变量 而三个对象所调用的成员函数的地址值确实一样的 也正说明了这三个对象共用同一个成员函数
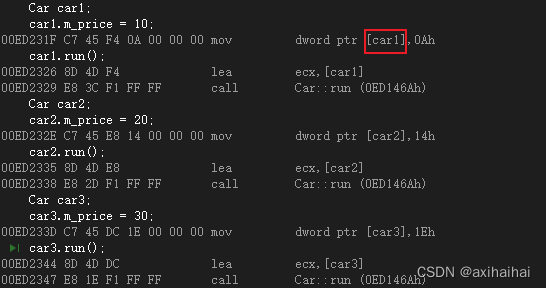
而且有个细节 就是他将10赋值给了car1所在内存块中 说明了car1的地址值等于car1当中的m_price的地址值
在实际开发中 用class定义类是比较常见的
3.对象中的内存布局
struct Person {
int m_id;
int m_age;
int m_height;
void display() {
cout << "m_id" << m_id << ", m_age = " << m_age << ", m_height = " << m_height << endl;
}
};
int main() {
Person p;
p.m_id = 1;
p.m_age = 10;
p.m_height = 170;
cout << "&p = " << &p << endl;// &p = 00F3F978
cout << "&p.m_id = " << &p.m_id << endl;// &p.m_id = 00F3F978
cout << "&p.m_age = " << &p.m_age << endl;// &p.m_age = 00F3F97C
cout << "&p.m_height = " << &p.m_height << endl;// &p.m_height = 00F3F980
getchar();
return 0;
}
从打印结果来看 可以发现在对象中定义的多个成员变量的内存是连续分布的 并且是按照成员变量的定义顺序依次排布的
从内存这一方面我们也可以验证
struct Person {
int m_id;
int m_age;
int m_height;
void display() {
cout << "m_id" << m_id << ", m_age = " << m_age << ", m_height = " << m_height << endl;
}
};
int main() {
Person p;
p.m_id = 1;
p.m_age = 10;
p.m_height = 170;
cout << "&p = " << &p << endl;// &p = 00F9FD24
cout << "&p.m_id = " << &p.m_id << endl;
cout << "&p.m_age = " << &p.m_age << endl;
cout << "&p.m_height = " << &p.m_height << endl;
getchar();
return 0;
}
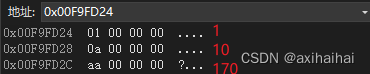
从内存中 我们可以发现 定义在对象中的多个成员变量是连续排布并且是按顺序排布的 也进一步证明了对象中只储存了成员变量的内存 并没有储存成员函数的内存
在上述例子中 person对象的内存是储存在函数的栈空间中 因此他可以自动的创建和销毁的 但是在Java中 我们知道对象的创建和销毁都是发生在堆空间中的
但是对于对象中存在不同类型的成员变量 可能会发生内存对齐现象 也就是类对齐 即一个类的大小也为其内部最大成员变量大小的倍数
对于下面这段代码来说 他就发生了内存对齐
class Person {
public:
int m_age;
long m_height;
short m_weight;
};
int main() {
Person p;
p.m_age = 10;
p.m_height = 20;
p.m_weight = 30;
cout << "&p = " << &p << endl;
cout << sizeof(p) << endl;// 12
getchar();
return 0;
}
本来sizeof§的结果应该为10 可实际打印的结果却是12 原因在于他触发了类对齐 10显然不是最大成员字节数4的倍数 所以必须得凑到12 方可为4的倍数 所以实际上往原本的10个字节内存中又填充了2个字节 形成了最终的12个字节
4.this
既然我们之前提到了每一个对象中都有一块各自独有的成员变量内存 每一个对象共用一块独立的成员函数内存 那么对于以下这段代码来说 是如何做到不同的对象通过同一份内存去访问不同的成员的呢
struct Person {
int m_age;
void run() {
cout << "Person::run() -- " << m_age << endl;
}
};
int main() {
Person p1;
p1.m_age = 10;
p1.run();// Person::run() -- 10
Person p2;
p2.m_age = 20;
p2.run();// Person::run() -- 20
getchar();
return 0;
}
我们从打印结果可以看到 这两个不同的对象调用同一份函数内存竟然可以做到打印不同的结果 其实这取决于this指针的存在
在代码区中的成员函数只有获取了位于栈空间中的成员变量的地址值才能够访问其内存 从而取出里面的值 而this指针正好提供了栈空间中成员变量的地址值
this指针本质上是一个指向当前函数调用者的指针 而他会作为对象中成员函数的隐式参数存在 所以在成员函数中 是可以通过this指针间接访问当前调用者对象中的成员的
1.反汇编窥探this
struct Person {
int m_age;
void run() {
m_age = 20;
}
};
int main() {
Person p1;
p1.m_age = 10;
p1.run();// Person::run() -- 10
getchar();
return 0;
}
我们可以借助excel辅助我们完整的走一趟这段代码背后的汇编语句


执行call命令
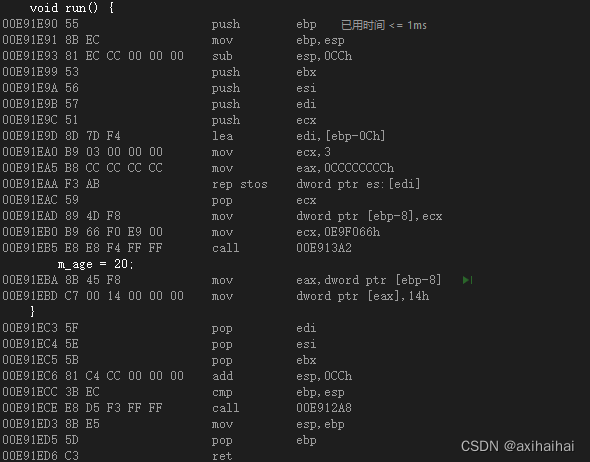
执行push ebp 将ebp的指向压栈

执行mov ebp, esp 将ebp的指向改成esp的指向

执行sub esp, xxx 将esp往低地址方向移动 移动的量为分配给run函数的栈空间

执行push ebx、push esi、push edi 将这三个寄存器依次压栈 这是为了防止等会的操作修改了这三个寄存器的值而无法还原
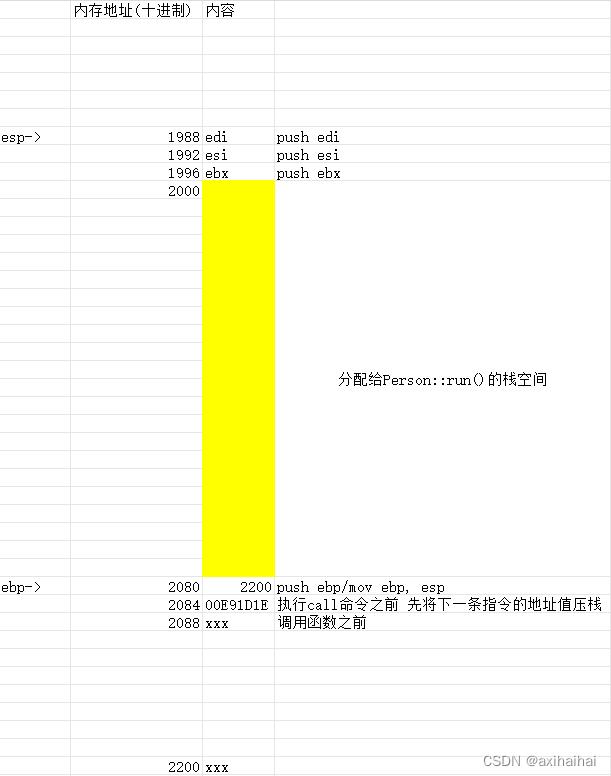
执行push ecx 将p1 即将函数调用者的地址值压栈
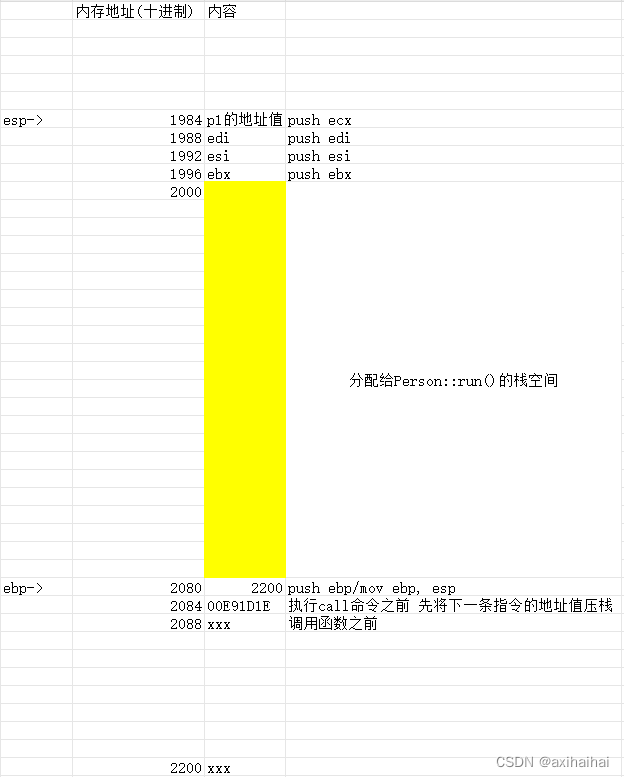
执行pop ecx 弹栈 并且将栈顶元素赋值给ecx
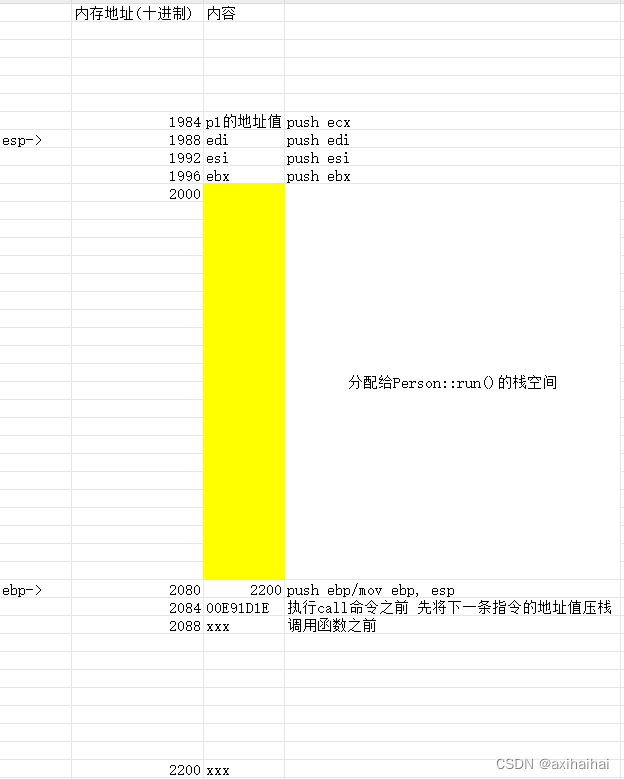
执行mov dword ptr [ebp - 8], ecx、mov eax, dword ptr [ebp - 8] 将p1的地址值传递给eax
执行mov dword ptr [eax], 20 将20传递给eax寄存器中的地址值所引导的内存
执行pop edi、pop esi、pop ebx 将栈顶的三个值弹出 并且依次赋值给三个寄存器
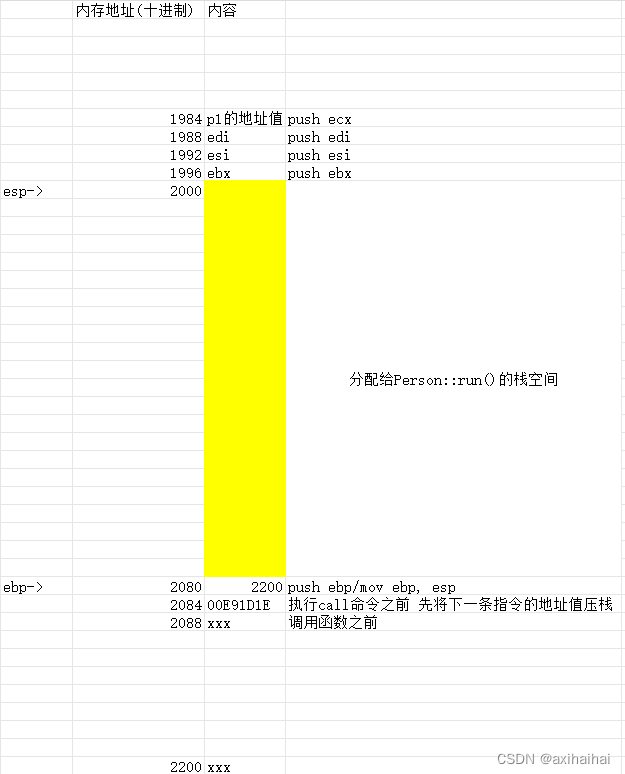
执行add esp, xxx 增量和刚才sub的减量是一致的 相当于回收刚才分配给run函数的栈空间

执行mov esp, ebp 将esp的指向改成ebp的指向
执行pop ebp 弹栈 并且将栈顶元素赋值给ebp
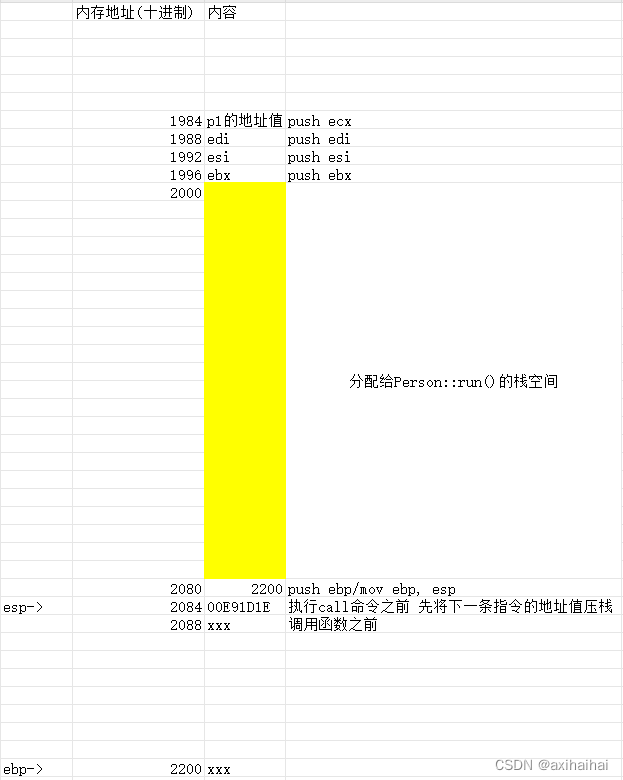
执行ret语句 首先会弹栈 其次会跳转到刚才弹出的栈顶元素
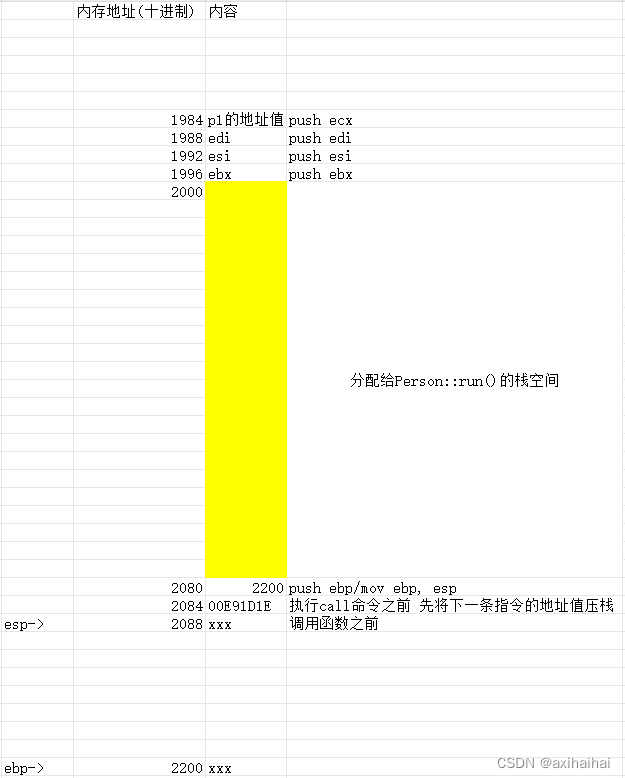
最后调用完毕 也维持了栈平衡
其中有关于this指针的几句核心代码为:
mov dword ptr [ebp-0Ch],0Ah
lea ecx,[ebp-0Ch]
mov dword ptr [ebp-8],ecx
mov eax,dword ptr [ebp-8]
mov dword ptr [eax],14h
分析一下上述几句汇编代码
首先将10赋值给了ebp - 0ch 很显然这个ebp - 0ch是p1/p1.m_age的地址值
接着将ebp - 0ch直接赋值给ecx 这样ecx中储存的便是p1的地址值
接着将p1的地址值赋值给ebp - 8 显然ebp - 8是this指针的地址值
接着将ebp - 8中的内容赋值给了eax eax中储存的便是p1的地址值
最后将20赋值给了eax中地址值所引导的内存 也就是p1.m_age = 20
总之 this是一个指向当前函数调用者的指针
5.指针访问成员的本质
我们先来看一看通过对象直接访问成员的本质
struct Person {
int m_id;
int m_age;
int m_height;
void display() {
cout << "m_id = " << m_id << ", m_age = " << m_age << ", m_height = " << m_height << endl;
}
};
int main() {
Person p;
p.m_id = 10;
p.m_age = 20;
p.m_height = 30;
p.display();
getchar();
return 0;
}
其本质就是
mov dword ptr [ebp-14h],0Ah
mov dword ptr [ebp-10h],14h
mov dword ptr [ebp-0Ch],1Eh
我们大致也可以知道ebp - 14h是p的地址值 也是p.m_id的地址值
第一句话中ebp - 14h是p.m_id的地址值 相当于往p.m_id的空间中存放10
第二句话中的ebp - 10h和ebp - 14h相差4个字节 是p.m_age的地址值 他和p.m_id是相邻的 相当于往里面存放20
第三句话的ebp - 0ch和ebp - 10h也是相差4个字节 是p.m_height的地址值 相当于往其中存放了30
再来看一下通过指针间接访问成员的本质究竟是怎样的
struct Person {
int m_id;
int m_age;
int m_height;
void display() {
cout << "m_id = " << m_id << ", m_age = " << m_age << ", m_height = " << m_height << endl;
}
};
int main() {
Person person;
Person* p = &person;
p->m_id = 10;
p->m_age = 20;
p->m_height = 30;
p->display();
getchar();
return 0;
}
他的核心汇编如下所示
// Person* p = &person;
// 首先将person对象的地址值赋值给了eax
lea eax,[ebp-14h]
// 其次将person对象的地址值通过eax赋值给了ebp - 20h这块内存 ebp - 20h就是p的地址值
mov dword ptr [ebp-20h],eax
// p->m_id = 10;
// 然后将person对象的地址值通过ebp - 20h赋值给了eax
mov eax,dword ptr [ebp-20h]
// 然后将10赋值给了eax中的person对象所引导的4个字节的内存 即m_id这块内存
mov dword ptr [eax],0Ah
// p->m_age = 20;
// 然后将person对象的地址值通过ebp - 20h赋值给了eax
mov eax,dword ptr [ebp-20h]
// 首先通过m_age和m_id之间的偏移量获取m_age的地址值 接着将20赋值给了结果地址值所引导的4个字节的内存 即m_age这块内存
mov dword ptr [eax+4],14h
// p->m_height = 30;
// 然后将person对象的地址值通过ebp - 20h赋值给了eax
mov eax,dword ptr [ebp-20h]
// 首先通过m_height和m_id之间的偏移量获取m_height的地址值 接着将30赋值给了结果地址值所引导的4个字节的内存 即m_height这块内存
mov dword ptr [eax+8],1Eh
mov ecx,dword ptr [ebp-20h]
call 00A914C4
总结一下指针间接访问对象的成员的汇编代码:
1.通过指针获取对象的地址值
2.通过偏移量(当前成员和对象地址之间的差)获取当前成员变量的地址值
3.根据成员变量的地址值访问成员变量所在的内存空间
但是对比了一下通过对象访问成员和通过指针访问成员的效率 从汇编指令的条数上来看 的确是通过对象访问成员的效率高
但是要知道一点 指针的出现并不是为了比对象访问效率高而诞生的 而是为了针对某些必须用到指针的情景而应运而生的
1.指针间接访问对象成员的有关思考题
以下代码中 实际结果会不会符合预期呢
struct Person {
int m_id;
int m_age;
int m_height;
void display() {
cout << "m_id = " << m_id << ", m_age = " << m_age << ", m_height = " << m_height << endl;
}
};
int main() {
Person person;
person.m_id = 10;
person.m_age = 20;
person.m_height = 30;
// 这边之所以需要进行强制转换的操作 原因在于&person.m_age取出来的是int类型数据的地址值 所以返回值应该是int* 和Person*不匹配
Person* p = (Person*) & person.m_age;
p->m_id = 40;
p->m_age = 50;
p->display();
getchar();
return 0;
}
对于这道思考题的结果 我们的预期可能是40 50 30 可实际上的结果是10 40 50
这就和我们刚才所讲到的通过指针间接访问成员中的偏移量有着莫大的关系了
我们刚才说过 通过指针间接访问对象成员的本质就是:通过指针获取对象地址 然后通过偏移量获取当前成员的地址值 最后通过这个地址值访问当前成员所在的储存空间
套在这道题上就是
我们通过指针获取到的地址值是person.m_age的地址值 是&person + 4
然后通过偏移量获取当前成员的地址值 也就是要获取person.m_id的地址值 也就是&person + 4 + 0 其实就是person.m_age的地址值 这和我们所想获取的person.m_id的地址值大相径庭 当然赋值的时候也就出现了差错
之后的p->m_age也是同理
以下代码中 通过对象访问的成员函数和通过指针访问的成员函数所打印的结果是否一致
struct Person {
int m_id;
int m_age;
int m_height;
void display() {
cout << "m_id = " << m_id << ", m_age = " << m_age << ", m_height = " << m_height << endl;
}
};
int main() {
Person person;
person.m_id = 10;
person.m_age = 20;
person.m_height = 30;
Person* p = (Person*) & person.m_age;
p->m_id = 40;
p->m_age = 50;
// 以下两种写法访问成员函数时打印的结果是否一致
person.display();
p->display();
getchar();
return 0;
}
答案是不一致
我们其实得知道成员函数中访问成员变量的本质 就是通过this指针间接访问对象中的成员变量 因此他在访问某一成员的时候 也遵循"先通过指针获取对象地址 在通过偏移量获取成员地址 最后通过成员地址访问成员所在的储存空间"的原则
按照上述这个原则 对于对象直接访问的结果是肯定符合预期的 其中this指针是指向person对象的
但是对于指针间接访问的话 那么this指针储存的就是p指针中储存的地址值 即person.m_age的地址值 那么到时候在访问的过程中 比如访问person.m_id的时候 偏移量就是0 那么获取到的值是person.m_age的值 而不是person.m_id的值 同理打印person.m_age的时候 结果为person.m_height的值(&person + 4 + 4) 再者 打印person.m_height的时候访问到的内存是一块未知的内存(&person + 4 + 4 + 4) 从而打印出乱码来
我们可以看到 这段乱码是0xcccccccc

那么为什么要用一段cc来填充栈空间呢?原因在于当我们为一个函数分配一个新的栈空间时 这段空间中可能会有之前残留下来的垃圾数据 所以用cccc这种数据去填充整段分配的内存
那么为什么一定要选择cc作为填充的数据呢?原因在于之前残留的数据中可能存在某些危险的指令 万一我通过指针指向跳转指令 跳转到函数的栈空间中的某个危险代码 那么后果将不堪设想
而cc是int3的意思 int是interrupt的简称 即中断的意思 3是中断码 表示为断点的意思 我们都清楚 代码只要执行到断点位置处的话 那么就会停止执行
我们可以在汇编和内存中分析一下0xcccccccc
struct Person {
int m_id;
int m_age;
int m_height;
void display() {
cout << "m_id = " << m_id << ", m_age = " << m_age << ", m_height = " << m_height << endl;
}
};
int main() {
Person person;
person.m_id = 10;
person.m_age = 20;
person.m_height = 30;
Person* p = (Person*) & person.m_age;
p->m_id = 40;
p->m_age = 50;
// 以下两种写法访问成员函数时打印的结果是否一致
person.display();
p->display();
getchar();
return 0;
}
还是刚才这段代码 但是我们进去display函数中分析分析
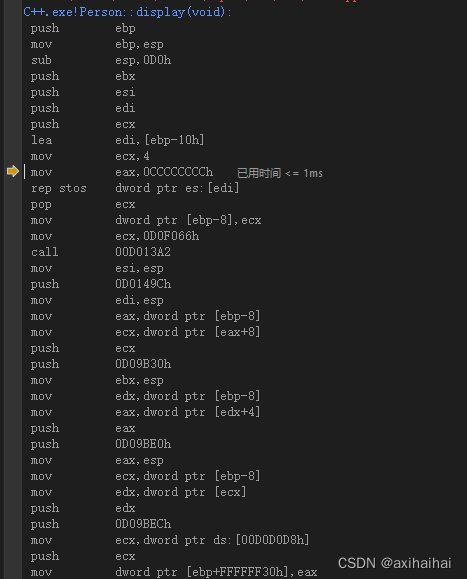
可以看到 在使用cc填充栈空间之前 栈空间还是一堆垃圾数据
当我们执行了mov eax, 0xcccc 以及 rep stos指令以后 再看一下内存中的效果
可以看到整个栈空间都被0xcccc所填满
6.函数执行时涉及的内存
我们在调用函数、执行函数代码的过程中 肯定会涉及到内存 一方面是用于储存函数代码的代码区 一方面是用于储存函数内部局部变量的栈空间 这两个究竟怎么区分呢?
其实不难 在调用函数的过程中 cpu会执行代码区中的函数代码 在执行过程中 遇到局部变量 就会在栈空间中为其开辟空间
有人说 为什么不直接在代码区中为局部变量开辟内存空间呢?因为代码区是只读的 而局部变量是可修改的 显然将局部变量放在代码区不合适 所以将其放置在栈空间中
7.C++的编程规范
我们之前学习Java的过程中 是有学习过Java的一套编程规范 也就是对于一些标识符来说 是需要有一些规范的 比如对于类、接口等这些类型的标识符采用大驼峰 对于方法、变量这些非类型的标识符采用小驼峰
而在C++中 也有着自己的一套规范:
变量名命名规范:
全局变量:g_
成员变量:m_
静态变量:s_
常量:c_
也可以使用和Java一样的驼峰标识去表示一个标识符 比如对于全局变量age来说 我们可以命名为gAge