equals和==的区别
使用基本数据类型(char,int,long等)的时候,==比较的是它们的值
使用引用数据类型的时候,比较的是地址
equals如果不重写,那么和 == 是没差别的
下面来看String的比较,这里有个浅拷贝的知识点
public class StringDemo {
public static void main(String args[]) {
String str1 = "Hello";
String str2 = new String("Hello");
String str3 = str2; // 引用传递
System.out.println(str1 == str2); // false
System.out.println(str1 == str3); // false
System.out.println(str2 == str3); // true
System.out.println(str1.equals(str2)); // true
System.out.println(str1.equals(str3)); // true
System.out.println(str2.equals(str3)); // true
}
}
这里str3 = str2的时候,只是进行了一个浅拷贝,也就是把str2的地址赋给了str3,它们两个指向的堆的地方是相同的
值传递和引用传递
一句话总结:Java的参数传递,只有值传递(实际上java函数中的参数可以粗暴理解为像是c++中的指针一样)
public class TransferTest2 {
public static void main(String[] args) {
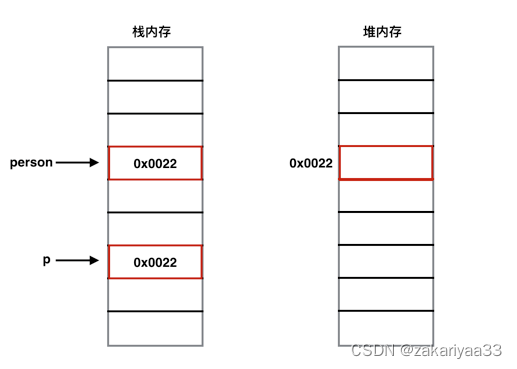
Person person = new Person();
System.out.println(person);
change(person);
System.out.println(person);
}
public static void change(Person p) {
p = new Person();
}
}
class Person {
}
上面代码两次输出都是一致的,这是因为change函数中,Person p参数接收的其实是传进来的实例的内存地址(所以说类似指针),p = new Person()也只是把这个指针指向了另一个新的地址,原来地址的数据并没有变化
String s = new String(“xxx”)的时候创建了几个对象
因为“xxx”是个字符串常量,所以如果这个常量不存在,会先创建“xxx”这个常量,然后把这个常量的地址给String类,创建一个新String,就创建了两个对象
如果“xxx”常量存在,就只会创建一个String对象
序列Parcelable,Serializable的区别
Serializable是Java提供的序列化机制,而 Parcelable则是Android提供的适合于内存中进行传输的序列化方式。据说Parcelable的效率是Serializable的10倍以上,不知真假
使用Serializable修饰一个类的时候,类内的成员都要实现Serializable接口,否则会报错
如果只需要在内存中进行数据传输是,序列化应该选择Parcelable,而如果需要存储到设备或者网络传输上应该选择Serializable。这是因为Android不同版本Parcelable数据规则可能不同,所以不推荐使用Parcelable进行数据持久化。
泛型和泛型擦除
无论是java还是c++,泛型都有广泛的应用,但是在jdk中,泛型的实现其实是伪泛型,也就是说在编译的时候,泛型类会被替换成Object
extends和super
? extends T为上界通配符,也就是说限制类型只能是T 或者 T 的派生类
List<? extends Fruit> plates = new ArrayList<>();
plates.add(new Apple()); //Error
plates.add(new Banana()); //Error
Fruit fruit1 = paltes.get();
Object fruit1 = paltes.get();
Apple fruit1 = paltes.get(); //Error
? super T 为通配符下界,也就是说限制类型只能是T 或者T的超类
List<? super Fruit> plates = new ArrayList<>();
Fruit fruit = plates.get(0);//Error
Apple apple = plates.get(0);//Error
Object object = plates.get(0);
plates.add(new Apple());
plates.add(new Banana());
CAS(Compare and Swap)
Jdk中java.util.concurrent.atomic包下的类都是采用CAS来实现的。
CAS机制当中使用了3个基本操作数:内存地址V,旧的预期值A,要修改的新值B。更新一个变量的时候,只有当变量的预期值A和内存地址V当中的实际值相同时,才会将内存地址V对应的值修改为B。
例如线程1和2都要对内存地址v存的值+1,旧值为10,线程1提交更新之前,线程2已经完成了值的更新,于是v的值变成了11
这时候线程1提交更新,将v的值与旧的预期值A比较,发现11!=10,提交失败了,于是线程1重新获取内存地址v中的当前值,然后重新计算想修改的新值,再次重复一遍之前的提交-比较流程,如果这一次比较后发现没有冲突,就执行Swap,把B的值换进地址v里
volatile
能否保证线程安全
不能,假如两个线程都想对i进行i++操作,它们同时调用++方法,线程A读取i为0并计算i+1结果为1,这时线程B也调用++方法,计算i+1结果为1,然后线程A把1写回i,线程B也把1写回i,最终i只增加了1而不是期望的2
防止指令重排
jvm会对一些非原子指令进行重排,例如创建一个新对象的时候,会经历以下三个步骤
1、分配内存
2、初始化对象
3、将内存地址赋值给引用
如果2和3的顺序重排了,就会发生异常
public class SingletonClass {
private volatile static SingletonClass instance = null;
public static SingletonClass getInstance() {
if (instance == null) {
synchronized (SingletonClass.class) {
if(instance == null) {
instance = new SingletonClass();
}
}
}
return instance;
}
private SingletonClass() {
}
}
这里的instance如果不加volatile关键字的话,多线程一起来getInstance就有可能会发生上面说的重排错误
volatile和synchronize的区别
volatile 只能作用于变量,synchronized 可以作用于变量、方法、对象。
volatile 只保证了可见性和有序性,无法保证原子性,synchronized 可以保证线程间的有序性、原子性和可见性。
volatile 线程不阻塞,synchronized 线程阻塞。
volatile 本质是告诉 jvm 当前变量在寄存器中的值是不安全的需要从内存中读取;sychronized 则是锁定当前变量,只有当前线程可以访问到该变量其他线程被阻塞。
volatile标记的变量不会被编译器优化, synchronized标记的变量可以被编译器优化。