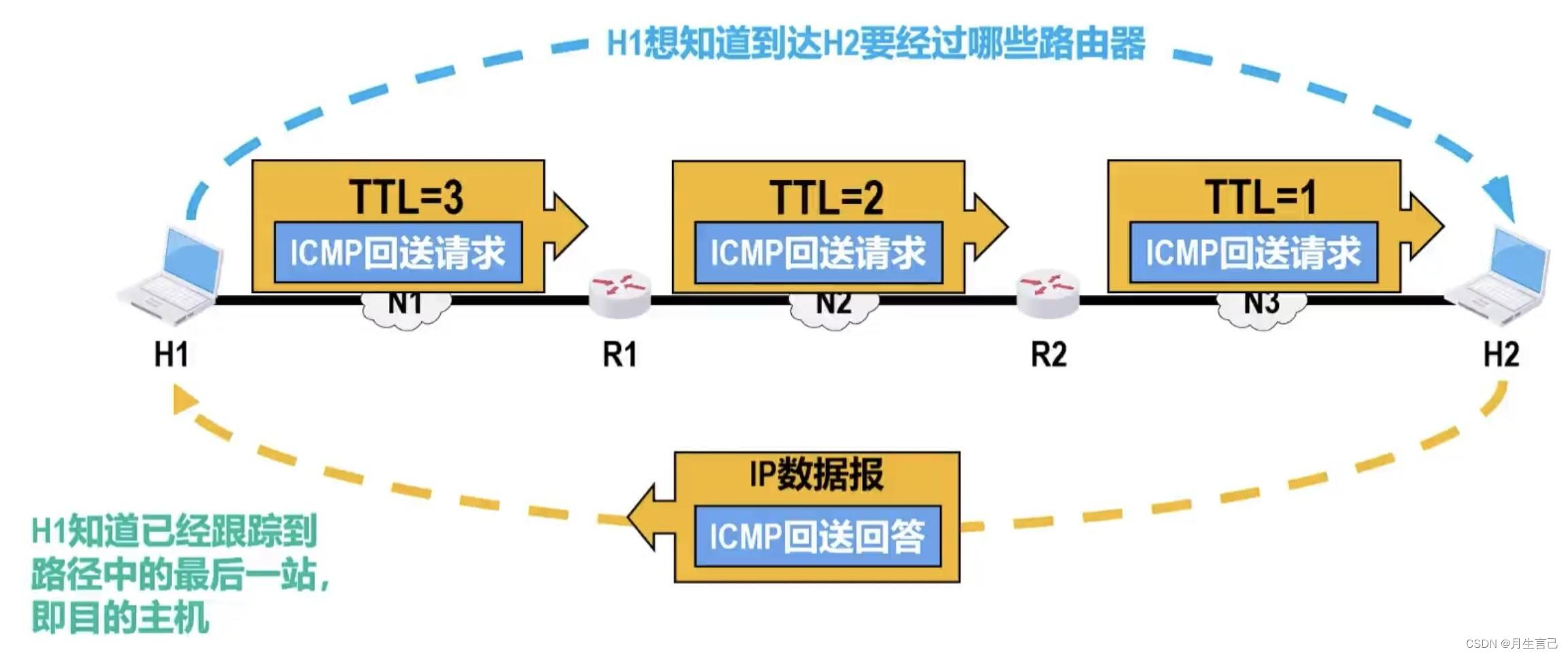
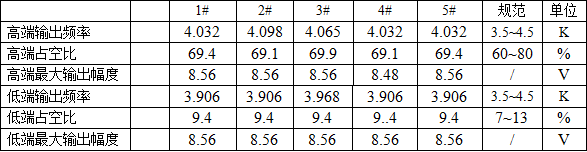
loss的作用如下:
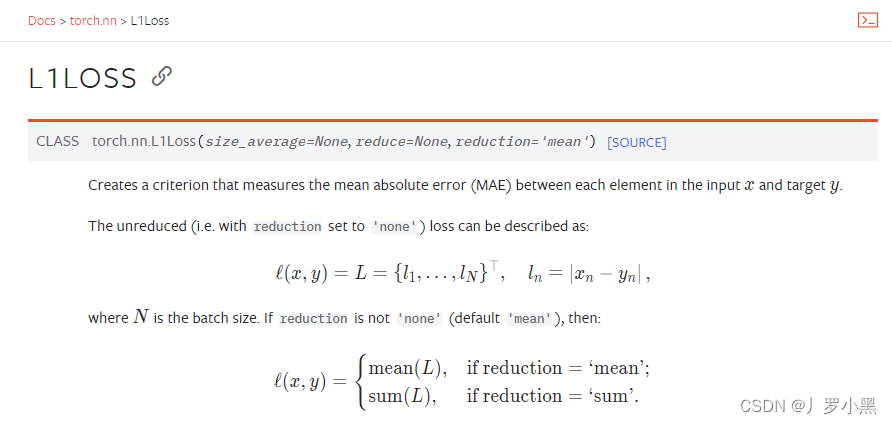
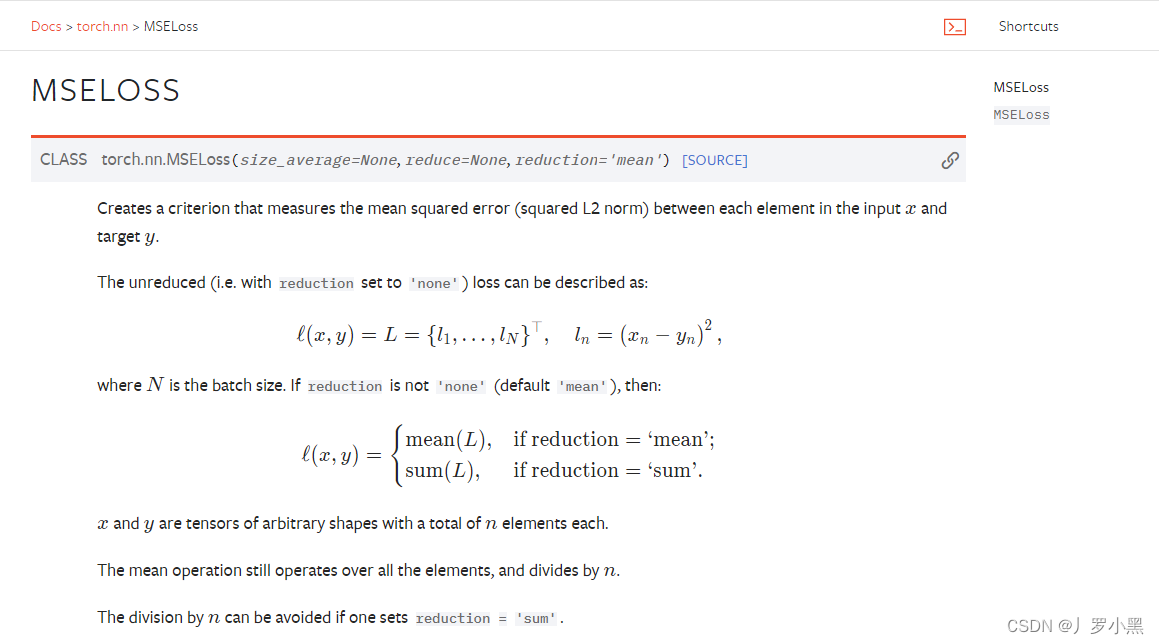
计算实际输出和真实值之间的差距 为我们更新模型提供一定的依据(反向传播) 绝对值损失函数:在每一个batch_size内,求每个输入x和标签y的差的绝对值,最后返回他们平均值 均方损失函数:在每一个batch_size内,求每个输入x和标签y的差的平方,最后返回他们的平均值 当我们在处理分类问题时,经常使用交叉熵损失函数。
交叉熵能够衡量同一个随机变量中的两个不同概率分布的差异程度,在机器学习中就表示为真实概率分布与预测概率分布之间的差异。交叉熵的值越小,模型预测效果就越好。 交叉熵在分类问题中常常与softmax是标配,softmax将输出的结果进行处理,使其多个分类的预测值和为1,再通过交叉熵来计算损失。 由于以下内容需要理解Softmax函数和交叉熵损失函数,所以先回顾一遍: Softmax函数:
首先,分类任务的目标是通过比较每个类别的概率大小来判断预测的结果。但是,我们不能选择未规范化的线性输出作为我们的预测。原因有两点。 1. 线性输出的总和不一定为1
2. 线性输出可能有负值
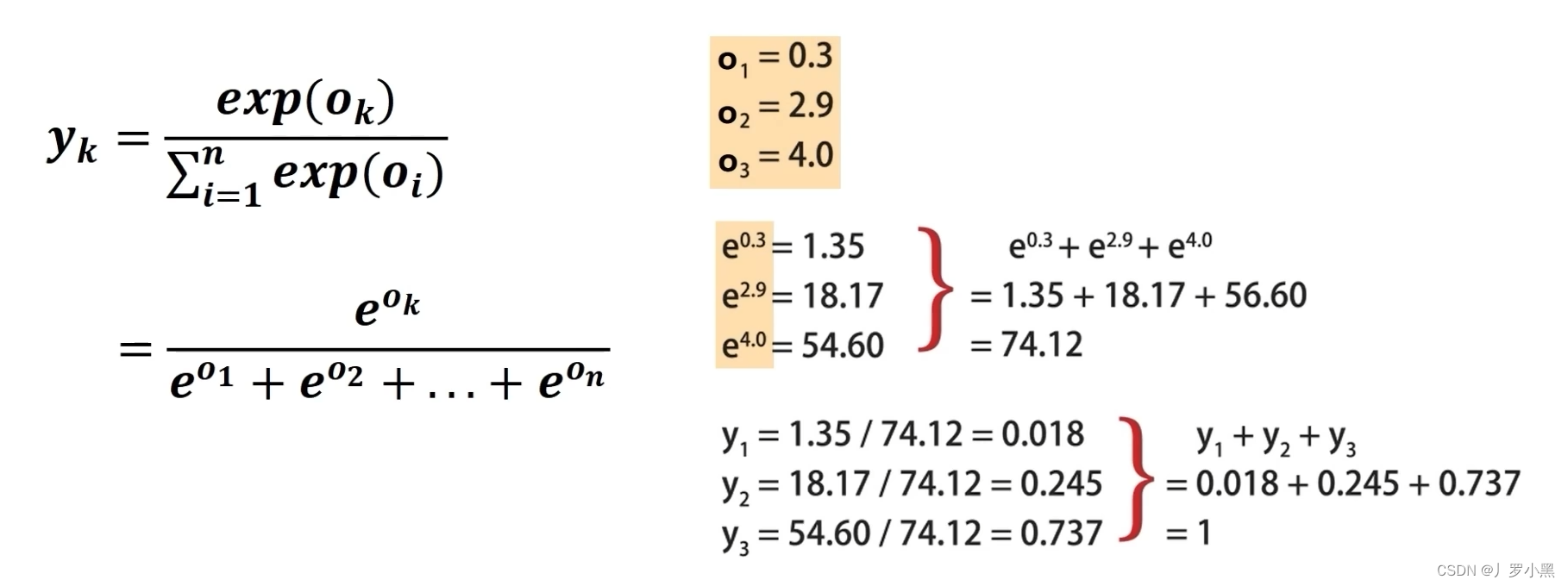
因此我们采用Softmax规范手段来保证输出的非负、和为1,公式和举例如下:
左侧为Softmax函数公式,右侧的o为线性输出,y为Softmax规范后的输出 交叉熵损失函数:
下图为交叉熵损失函数公式,P(x)为真实概率分布,q(x)为预测概率分布: 我们将Softmax规范后的输出代入交叉熵损失函数中,可得:
在训练中,我们已知该样本的类别,那么在该样本的真实概率分布中,只有该类别为1,其他都为0。 在计算机中的log,默认都是ln。 这就是Pytorch官网中的交叉熵损失函数公式: 注意:给此公式的交叉熵损失函数传入的input,不需要进行规范化,即不需要进行Softmax变换 我们仍然使用该类的对象函数来调用forward方法,而forward方法需要满足以下条件:
input:第一位为batch_size,第二位为输入的class数量 target:只有一位,为batch_size 代码如下: import torch
x = torch.tensor( [ 0.1 , 0.2 , 0.3 ] )
print( x.shape)
print( x)
y = torch.tensor( [ 1 ] )
x = torch.reshape( x, ( 1,3 ))
print( x.shape)
print( x)
loss_cross = torch.nn.CrossEntropyLoss( )
result_loss = loss_cross( x, y)
print( result_loss)
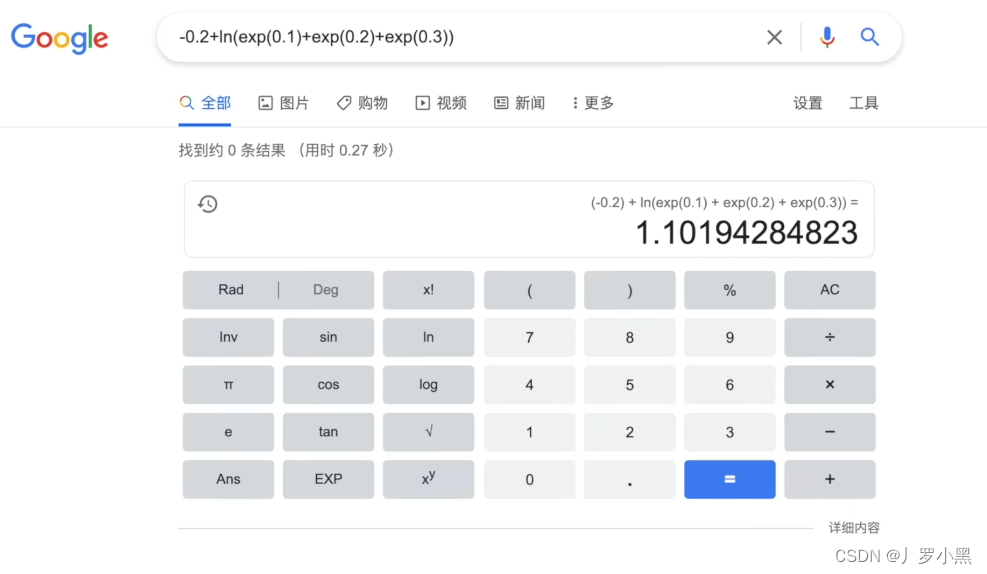
计算器的输出结果如下:
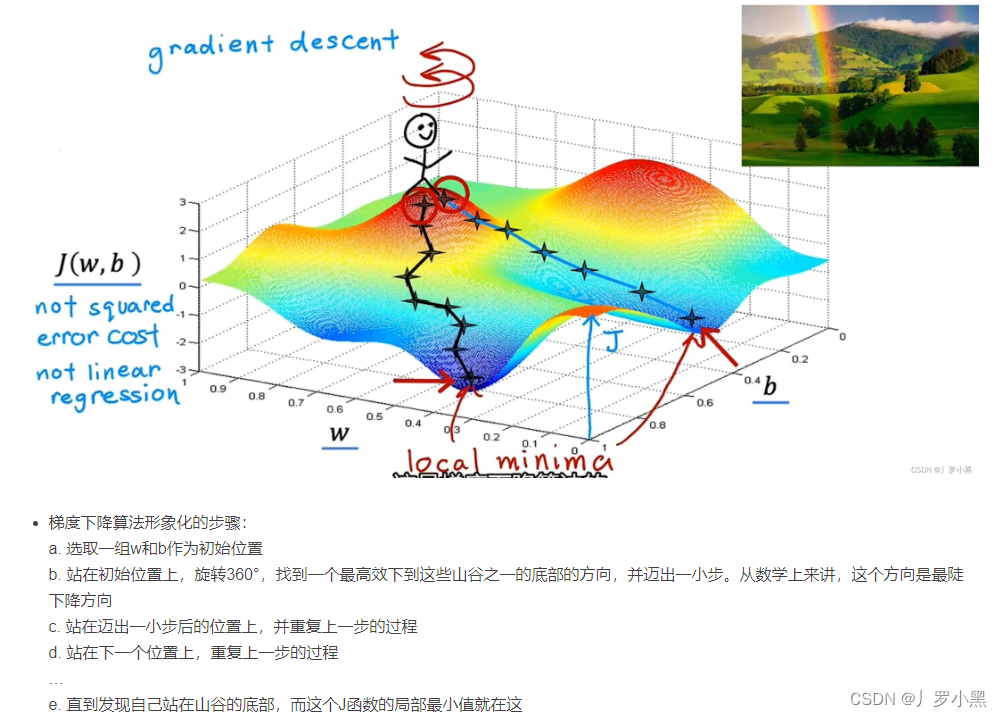
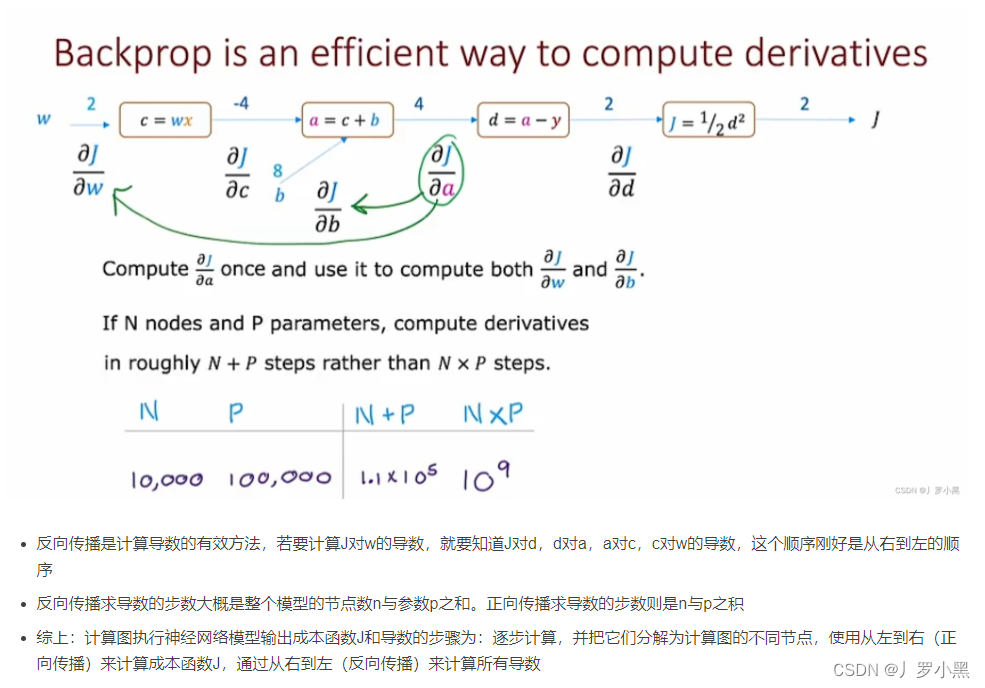
代码中的log默认为ln 当输入不变时,我们要想让总loss最小,就是要找到一组最小的w、b序列,这时我们可以采用一种系统的方法:梯度下降方法
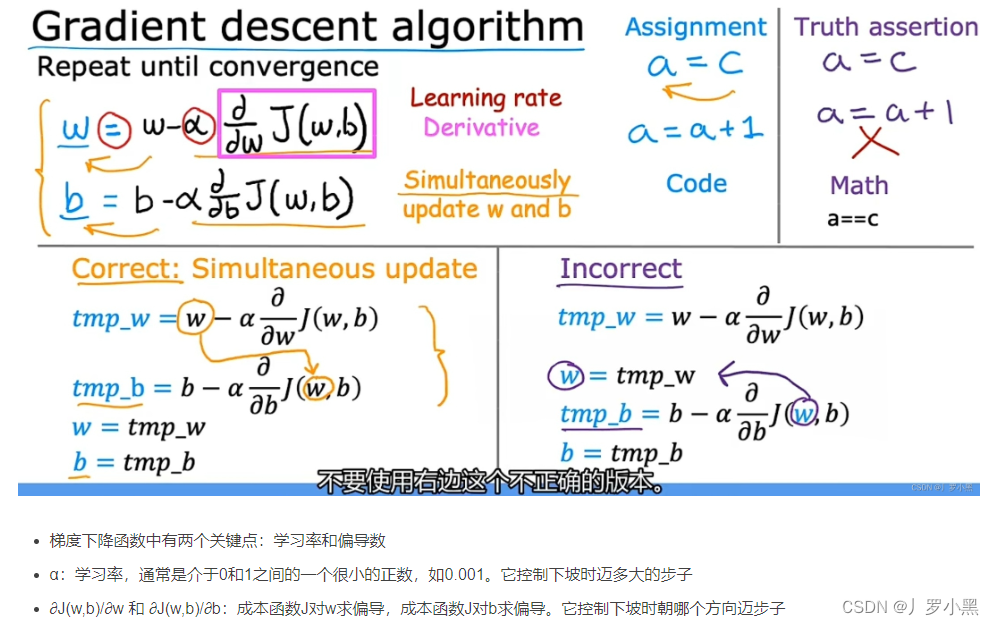
那么找w、b序列,就转换为求学习率和loss对w、b的偏导数,形象化的表示如下: 梯度下降的公式如下: 这其中:学习率是我们手动设定的,偏导数则是模型自动计算的。 由于每一个节点都需要计算偏导数,如果我们采用正向传播计算,那么针对每一个节点,我们都需要正向计算到结尾一次,而反向传播,只需要我们从头正向计算到结尾一次,之后根据节点位置,进行反向偏导数相乘即可,流程图如下:

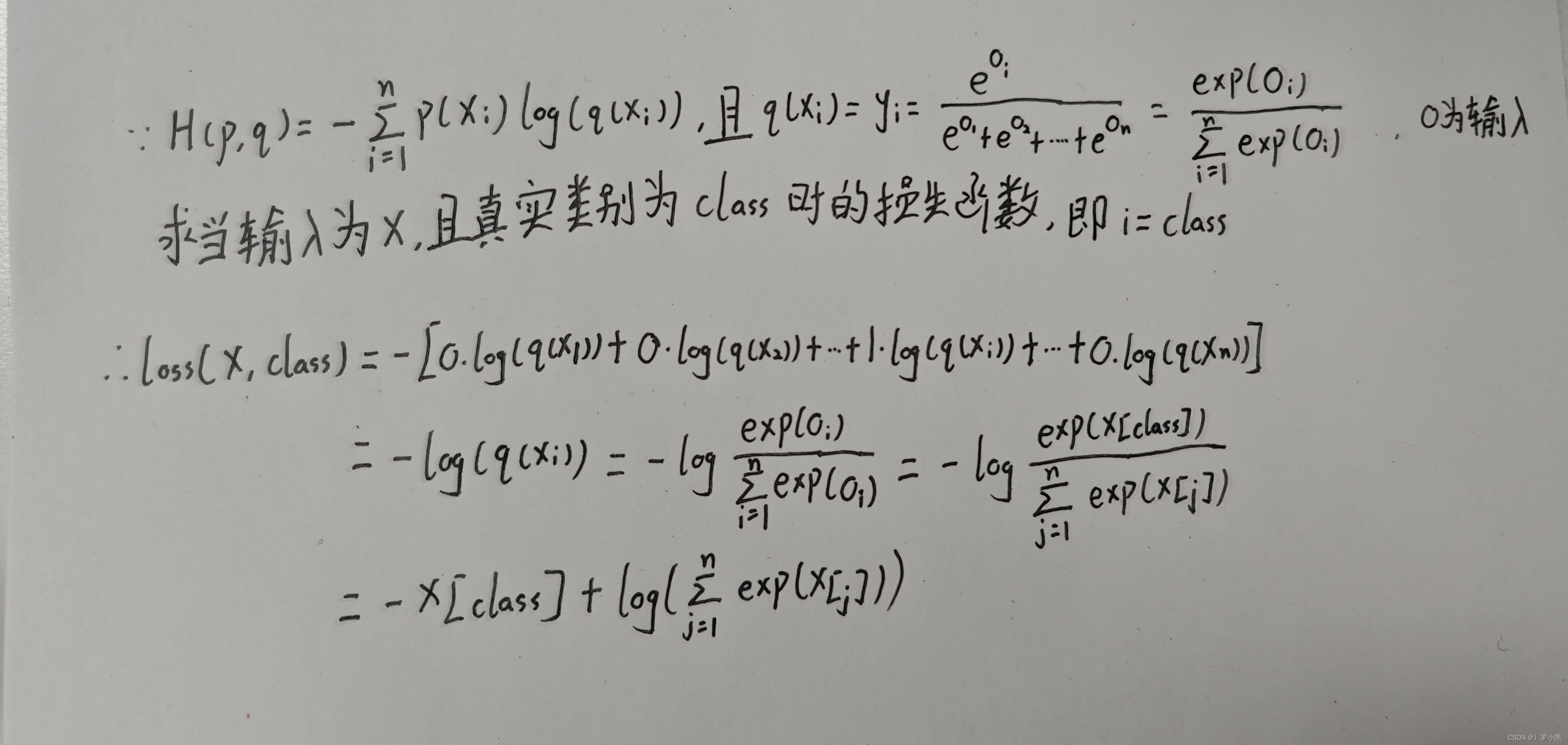







![[VulnHub靶机渗透] Nullbyte](https://img-blog.csdnimg.cn/direct/4d68d19fc4854301aa5698e74d2e1729.png)