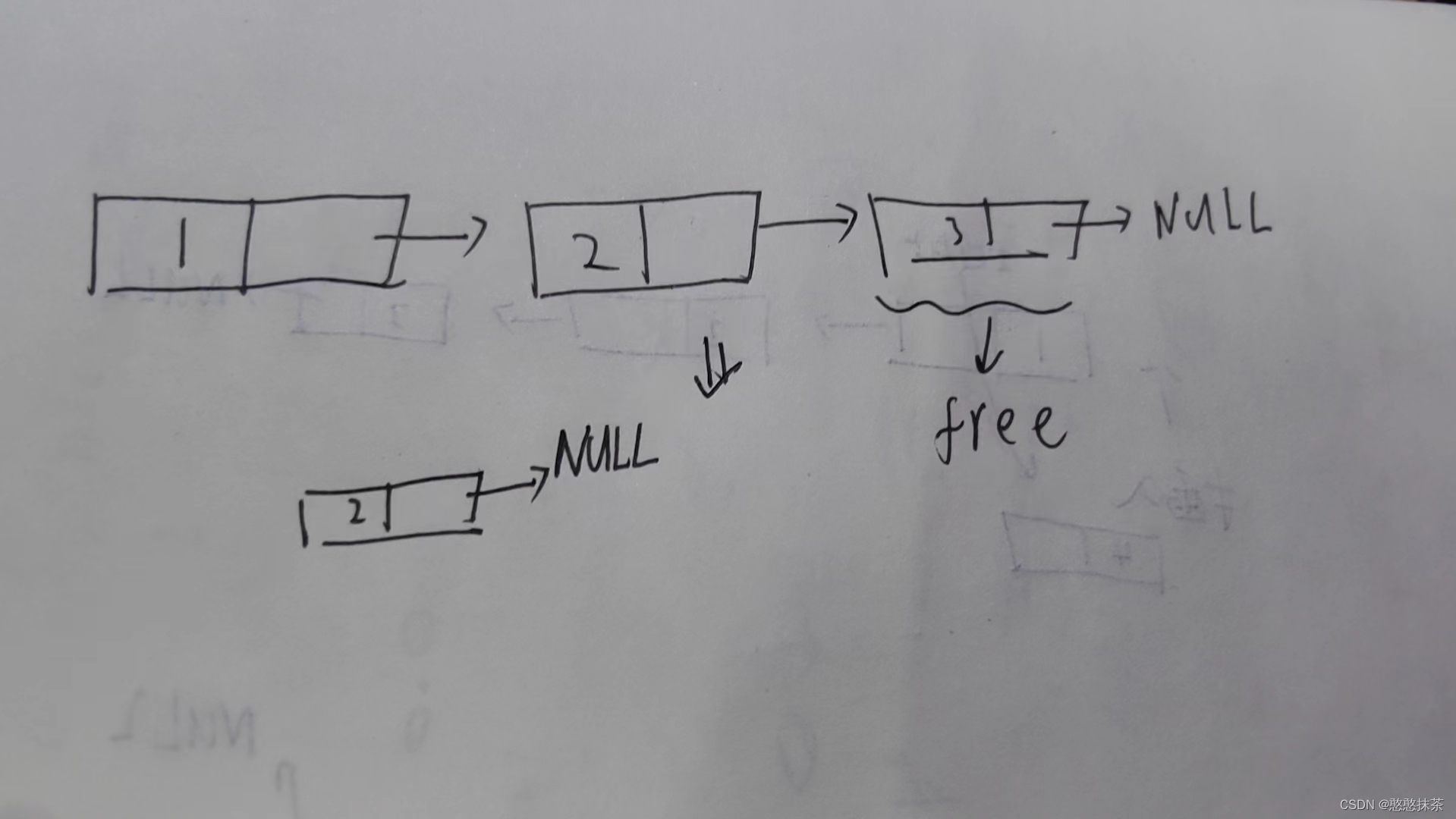
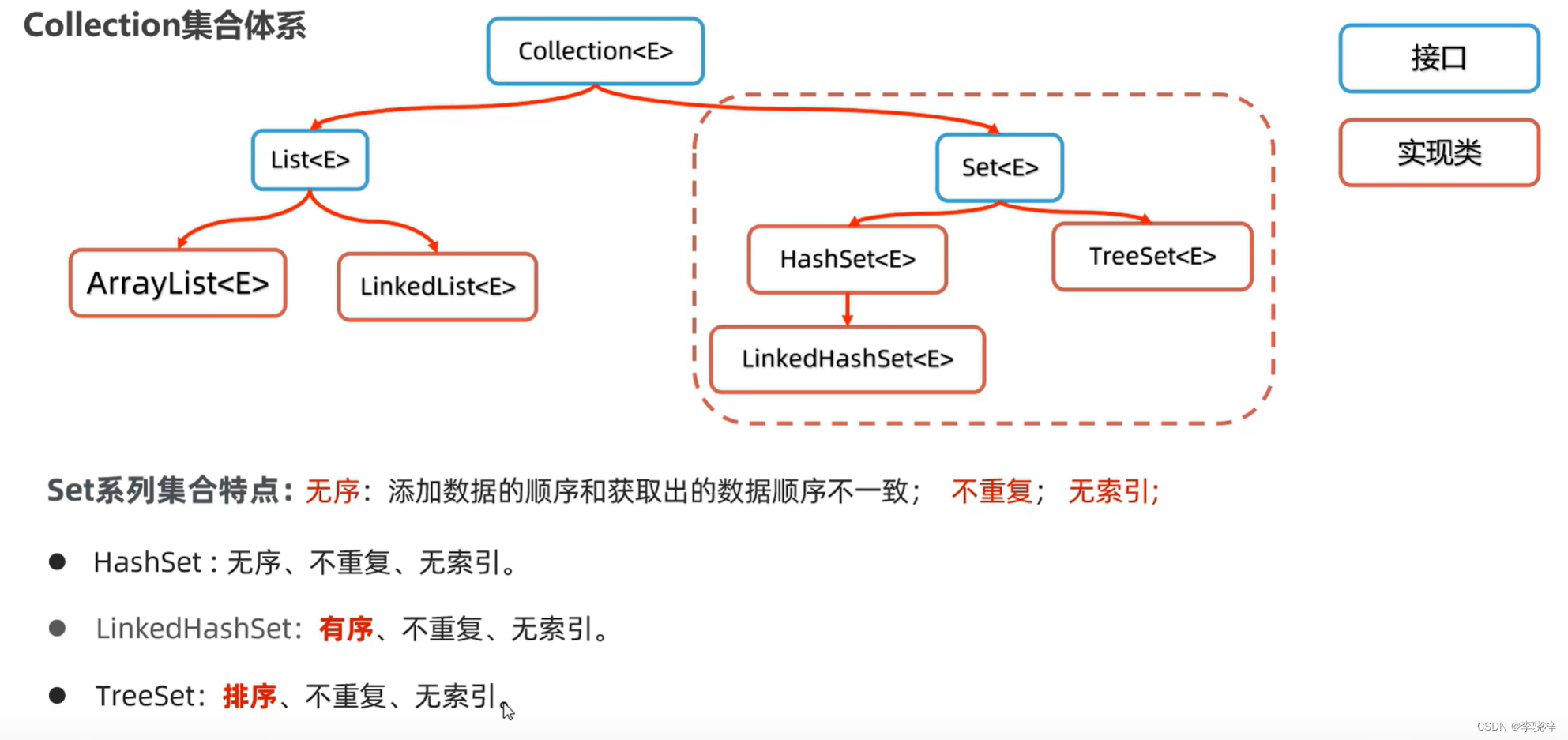
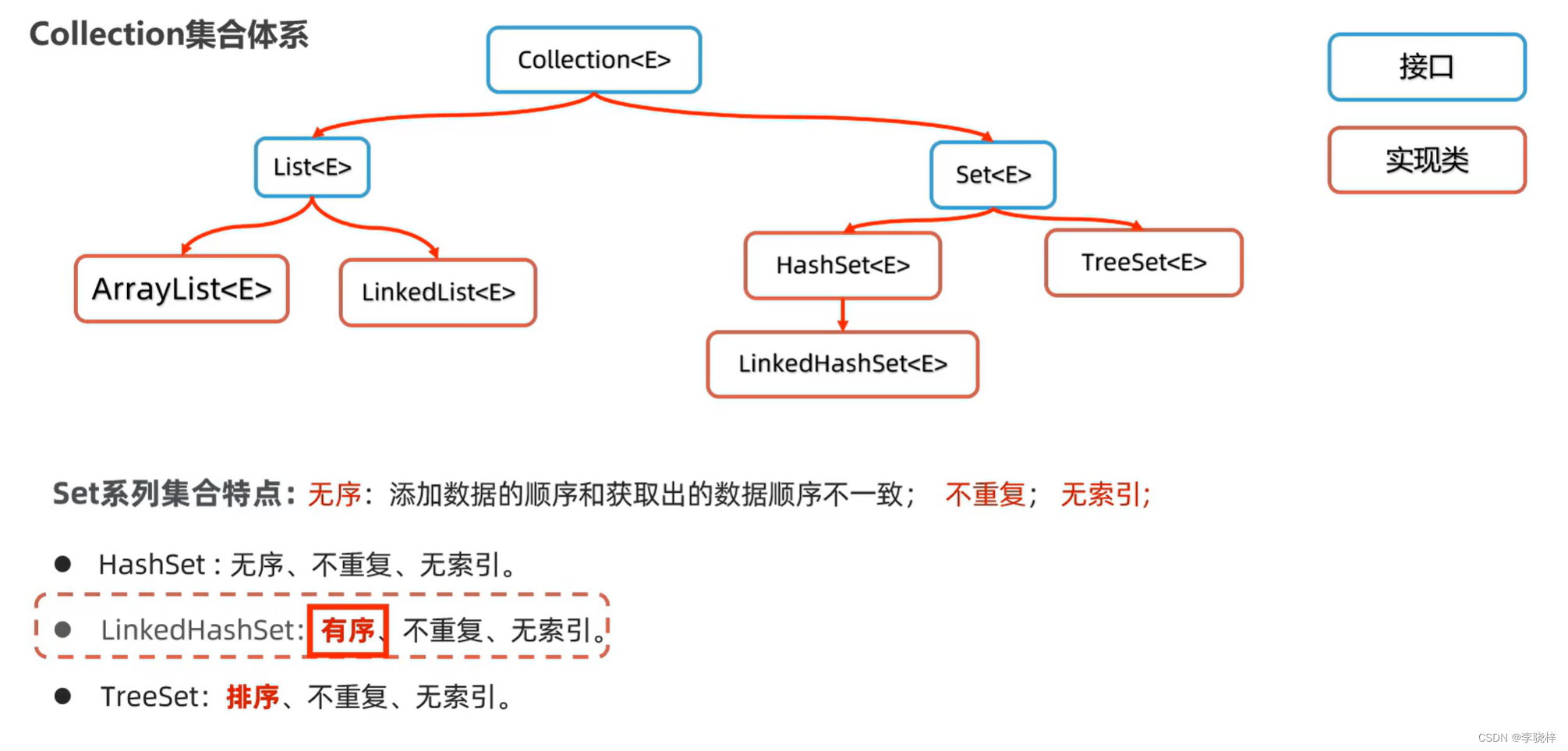
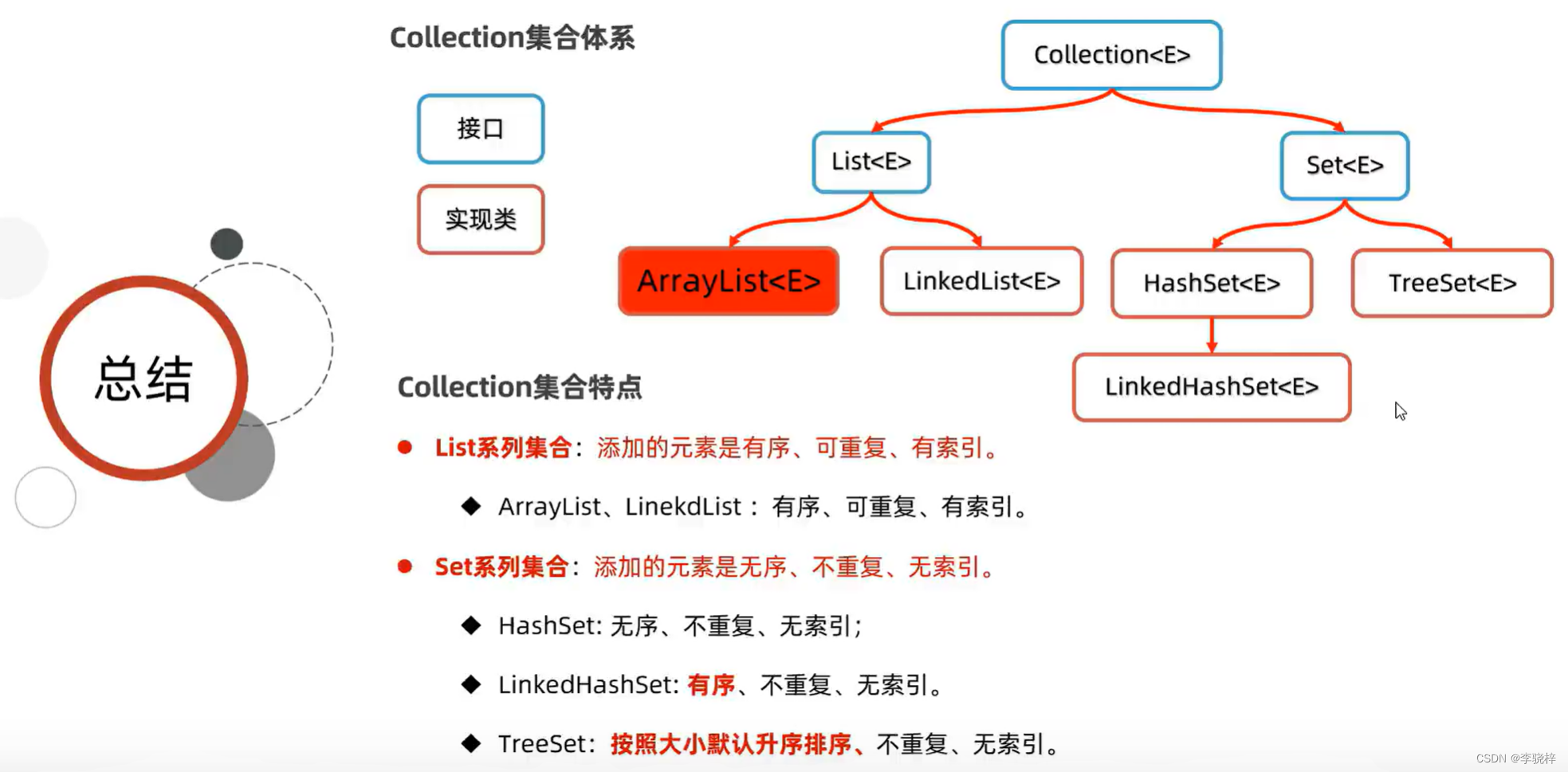
Set<E>是一个接口
特点
无序:添加数据的顺序和获取出的数据顺序不一致;不重复,无索引
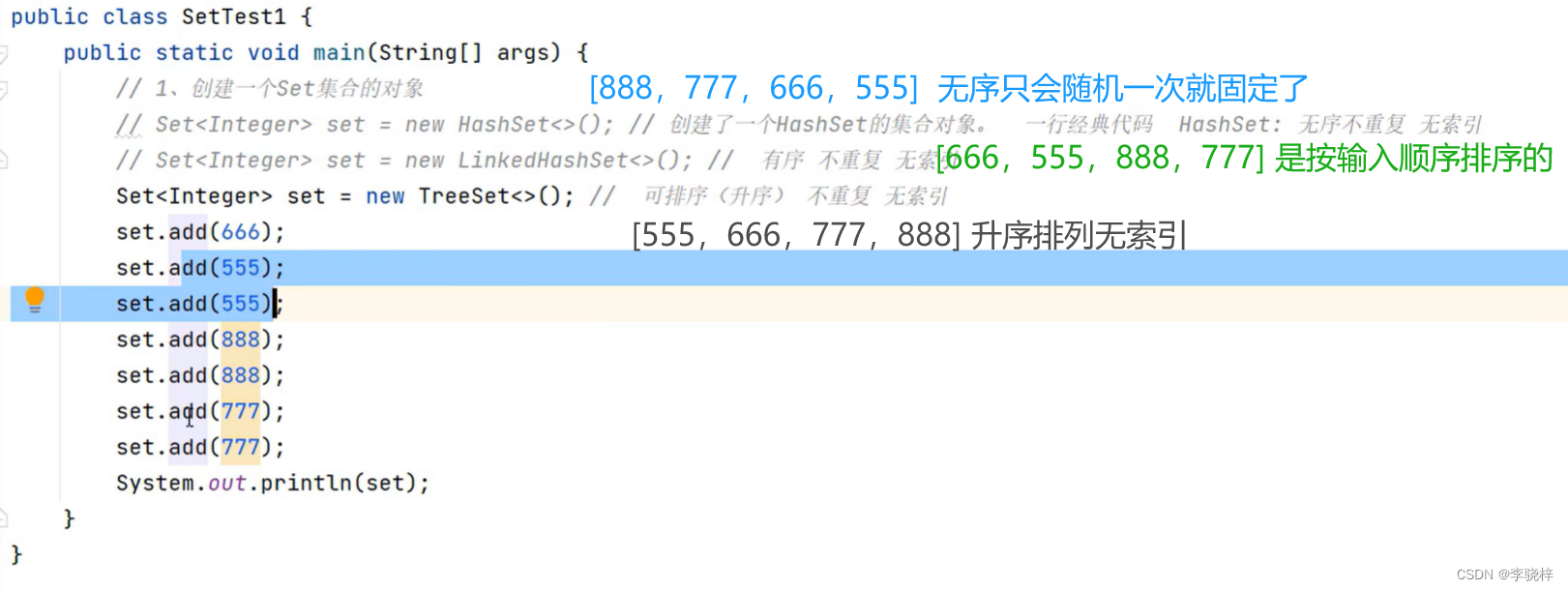
注意:Set要用到的常用方法,基本上就是collection提供的!自己几乎没有额外新增一些常用功能!
HashSet集合的底层原理
前置知识:哈希值:就是一个int类型的数值,Java中每个对象都有一个哈希值。

HashSet集合的底层原理:基于哈希表(是一种增删改查数据,性能都较好的数据结构)实现。
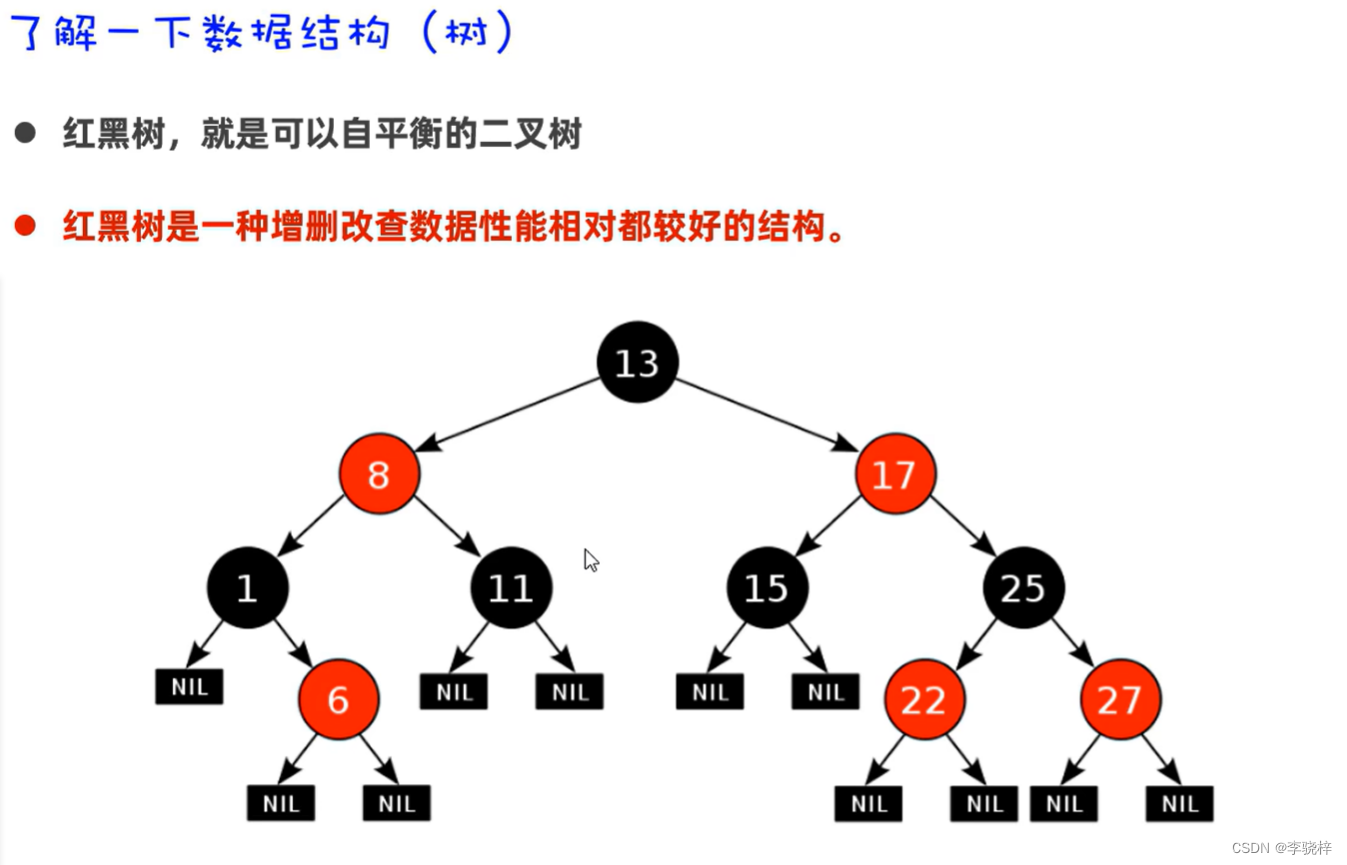
哈希表
- JDK8之前,哈希表=数组+链表
- JDK8开始,哈希表=数组+链表+红黑树

问题:
1. 如果数组快占满了,会出什么问题?该咋办? 链表会过长,导致查询性能降低。
(哈希表有一种机制:扩容。就是把底层的数组长度扩大,再把元素放到新数组里面去,把他分散开来,这样就会使链表上的数据要少一些,性能就得到一定的优化。)一旦数组占满了16*0.75=12个位置了,他就会扩容,并不会等到把数组中所有的位置都占完。
扩容的话会扩容成原数组的两倍的样子,再把原数组中的数据重新转移到新数组中,这样就可以把链上的数据变得少一些都分散开来,这样他的查询性能也就得到优化了。
JDK8开始,当链表长度超过8,且数组长度>=64时,自动将链表转为红黑树。



如果要认为两个不同对象是重复的,就必须要重写这个对象的hashCode()方法和equal()方法。这样HashSet<>集合就会认为内容一样的两个对象是重复的,就会帮我们去掉一个重复的。
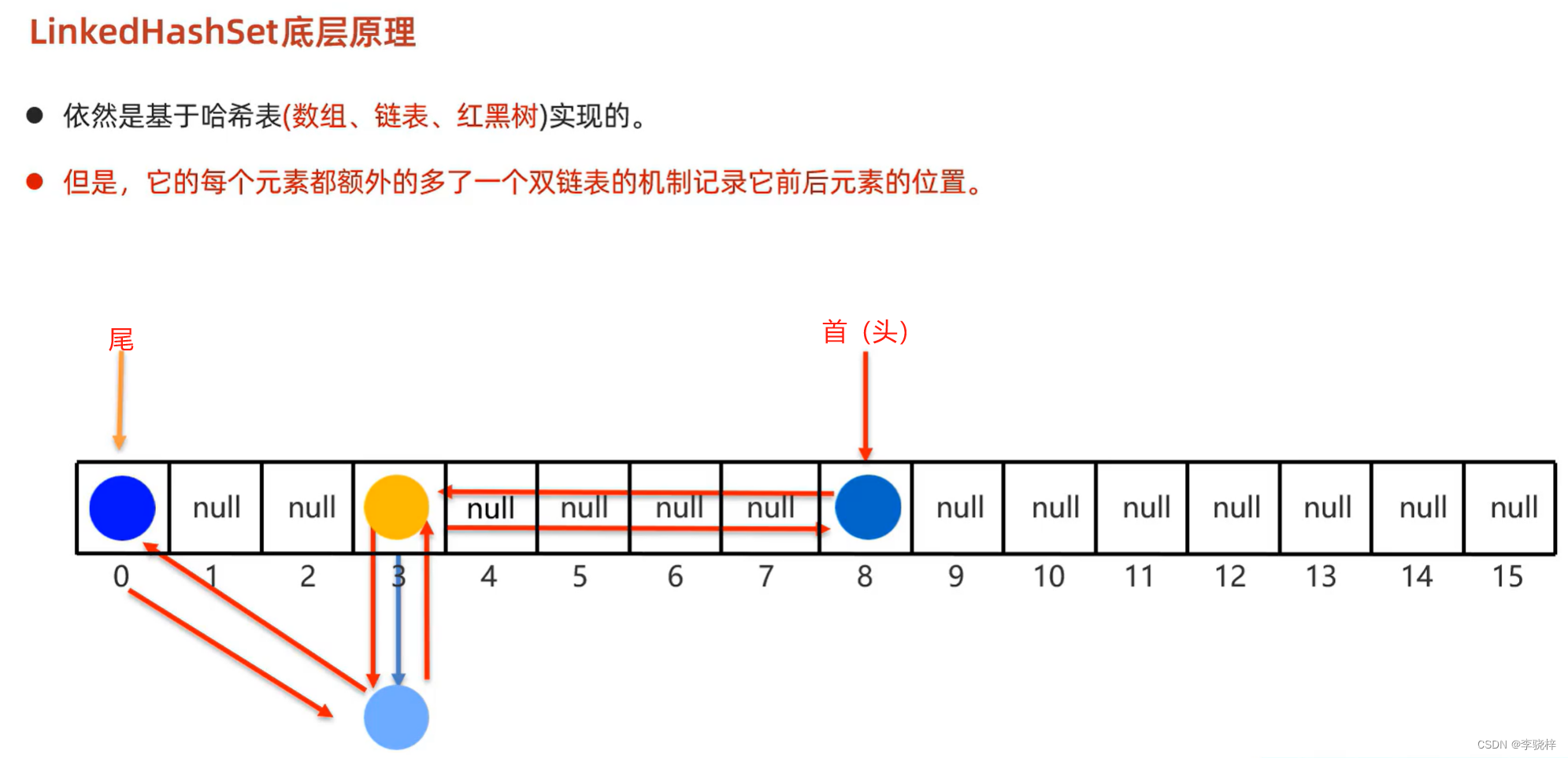
LinkedHashSet集合的底层原理
依旧是基于哈希表(数组、链表、红黑树)实现的。
但是,他的每个元素都额外多了一个双链表的机制记录他前后元素的位置。
TreeSet集合
特点:不重复、无索引、可排序(默认升序排序,按照元素的大小,由小到大排序)
底层是基于红黑树实现的排序。
注意:
对于数值类型:Integer,Double,默认按照数值本身的大小进行升序排序对于字符串类型:默认按照首字符的编号升序排序。
对于自定义类型如Student对象,Treeset默认是无法直接排序的

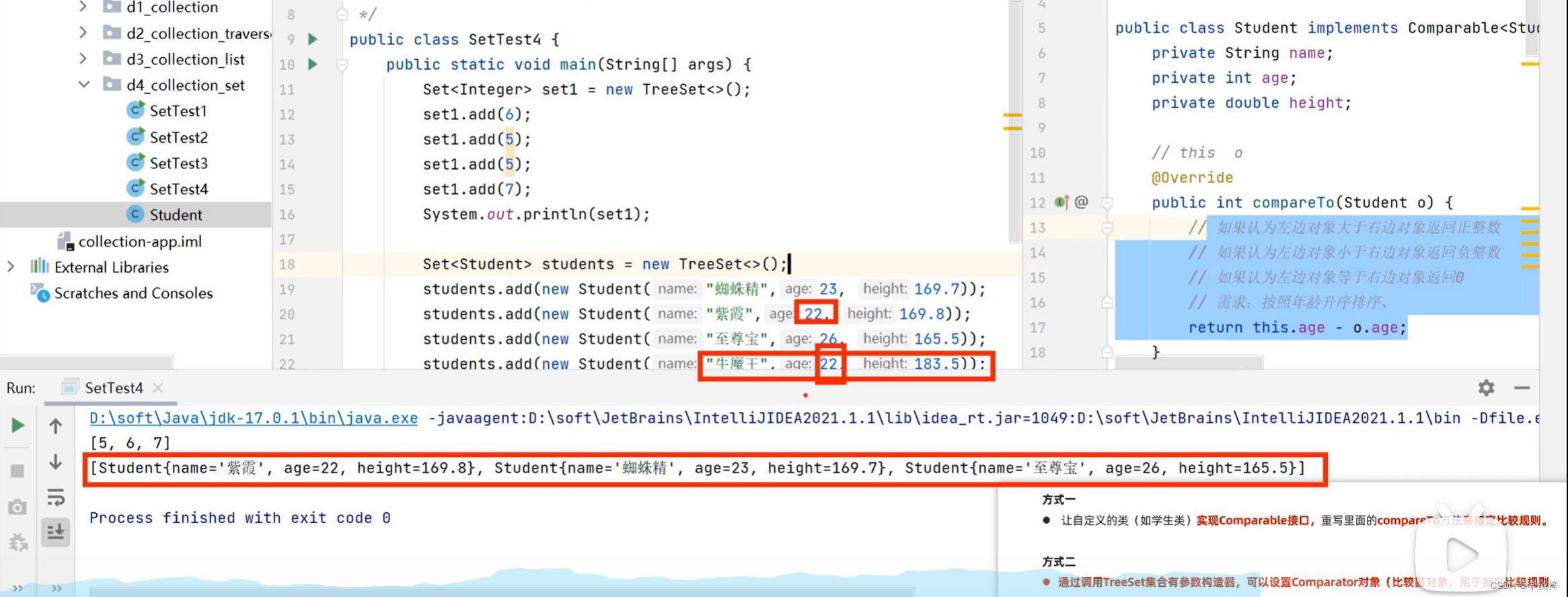
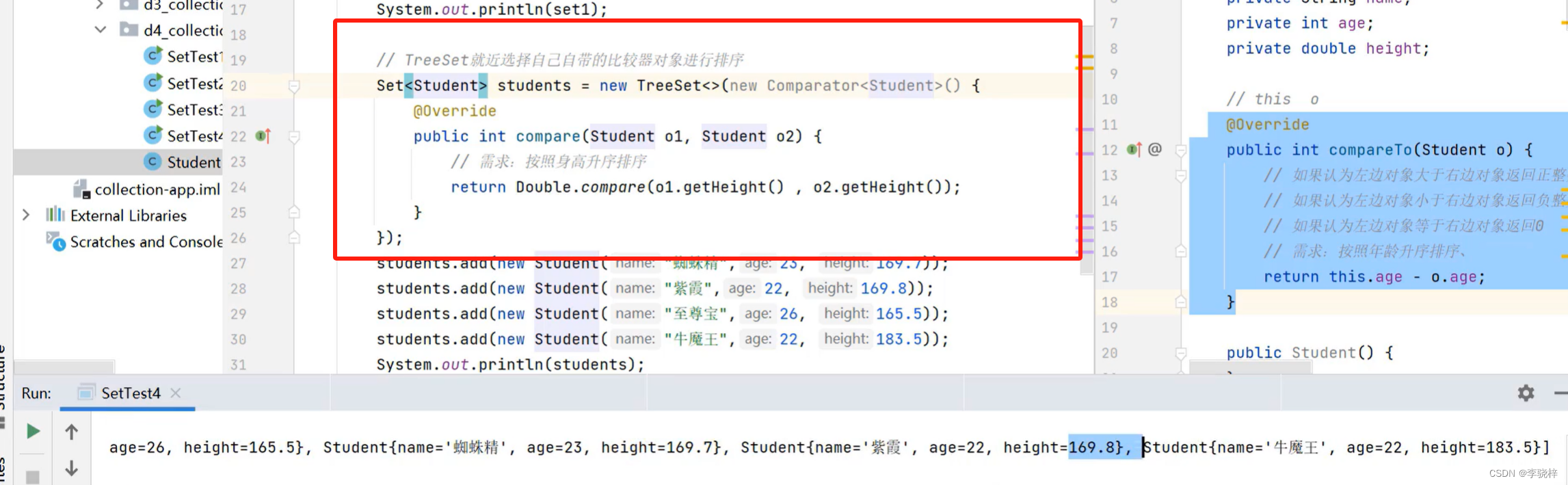 这个代码可以简化,函数式接口的匿名内部类形式可以简化。
这个代码可以简化,函数式接口的匿名内部类形式可以简化。

两种方式中,关于返回值的规则:
如果认为第一个元素 >第二个元素 返回正整数即可。
如果认为第一个元素<第二个元素 返回负整数即可。
如果认为第一个元素=第二个元素 返回0即可,此时Treeset集合只会保留一个元素,认为两者重复。
注意:如果类本身有实现Comparable接口,Treest集合同时也自带比较器,默认使用集合自带的比较器排序。
Collection集合的使用总结
 集合的并发修改异常问题
集合的并发修改异常问题
集合的并发修改异常
使用迭代器遍历集合时,又同时在删除集合中的数据,程序就会出现并发修改异常的错误。
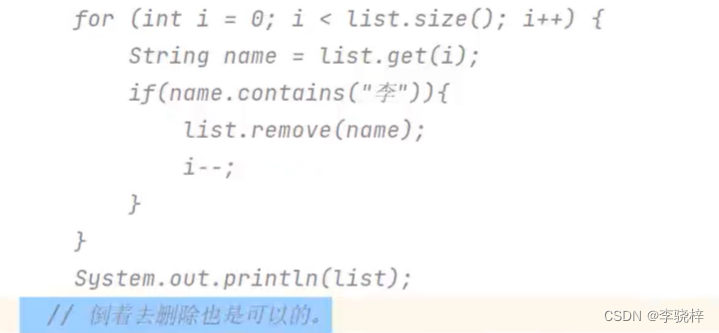 for循环
for循环
 迭代器
迭代器
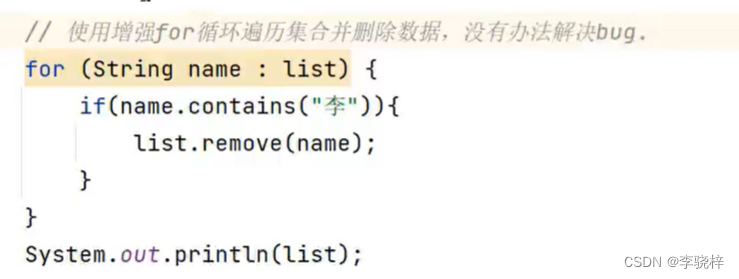 增强for循环
增强for循环
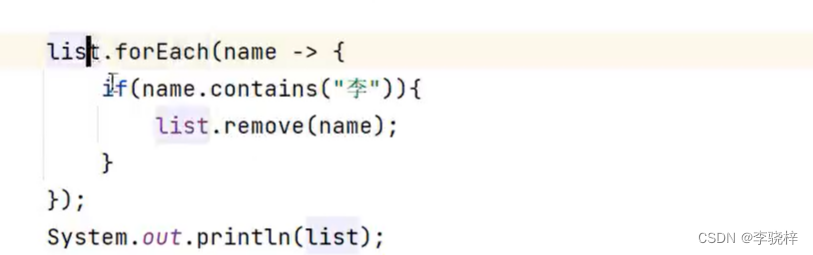 Lambda表达式
Lambda表达式
(Lamdba表达式底层原理就是增强for循环)