目录
一、基本概念
二、描述进程-PCB
1、task_struct-PCB的一种
2、task_ struct内容分类
三、组织进程
四、查看进程
1、ps指令
2、top命令
3、/proc文件系统
4、在/proc文件中查看指定进程
5、进程的工作目录
五、通过系统调用获取进程标示符
1、getpid()/getppid()
getpid()
getppid()
2、kill命令
五、通过系统调用创建进程
1、bash
2、fork()
父子进程返回结果不同
fork之后有两个不同的执行流
fork创建进程后,为什么会有两个返回值?
3、总结:
一、基本概念
程序的本质是文件,以二进制形式存储在磁盘中。当程序文件加载到内存时,就形成了一个进程。因此,操作系统帮助我们将程序转换为进程,以执行特定任务。简单来说,每次打开一个程序或应用时,都会生成一个对应的进程。
- 教材概念:程序的一个执行实例,正在执行的程序等
- 内核观点:担当分配系统资源(CPU时间,内存)的实体。
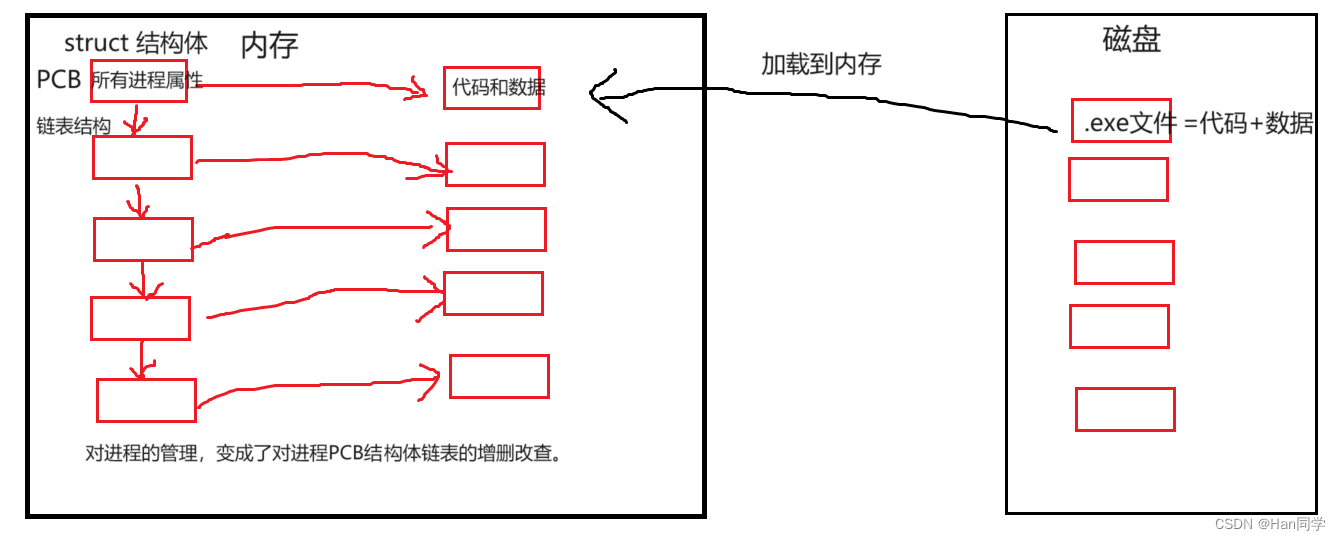
进程=程序的代码和数据(磁盘)+操作系统维护的进程控制块(PCB)结构体
进程是计算机中正在运行的程序的实例,它包括了程序的代码和数据(存储在磁盘上),以及操作系统维护的进程控制块(PCB)结构体。
- 代码指的是程序的指令集合,定义了程序的逻辑和执行流程。这些指令存储在磁盘上的可执行文件中。当进程被加载到内存中运行时,这些指令被复制到内存中的代码段中,并由处理器执行。代码段通常包括程序的可执行指令、函数、子程序等。
- 数据指的是程序在运行过程中使用的变量、常量、对象等存储数据。数据存储在进程的数据段中,也就是进程的内存空间中的一部分。数据段包括全局变量、静态变量、堆、栈等。
- 这些代码和数据构成了进程的执行环境,使得程序能够在计算机上正确运行。除了代码和数据外,进程还包括了操作系统维护的进程控制块(PCB)。PCB是用于存储和管理进程的各种信息的数据结构,如进程的状态、优先级、寄存器值、内存分配情况等。PCB存储了进程的标识、状态、优先级、程序计数器(PC)值、寄存器内容、内存分配情况等重要信息,是操作系统用于管理和控制进程的关键数据结构。
二、描述进程-PCB
在Windows任务管理器中,我们可以看到许多正在运行和后台运行的进程。操作系统需要对这些进程进行管理,这是通过一种称为进程控制块(PCB)的数据结构来实现的。PCB包含了进程的属性信息,类似于文件的内容和属性。
- 进程信息被放在一个叫做进程控制块的数据结构中,可以理解为进程属性的集合。
- 课本上称之为PCB(process control block),Linux操作系统下的PCB是: task_struct
1、task_struct-PCB的一种
- task_struct是Linux内核的一种数据结构,它会被装载到RAM(内存)里并且包含着进程的信息
2、task_ struct内容分类
- 标示符: 描述本进程的唯一标示符,用来区别其他进程。
- 状态: 任务状态,退出代码,退出信号等。
- 优先级: 相对于其他进程的优先级。(优先级:先后顺序,权限:能与不能)
- 程序计数器: 程序中即将被执行的下一条指令的地址。
- 内存指针: 包括程序代码和进程相关数据的指针,还有和其他进程共享的内存块的指针。
- 上下文数据: 进程执行时处理器的寄存器中的数据[休学例子,要加图CPU,寄存器]。
- I/O状态信息: 包括显示的I/O请求,分配给进程的I/O设备和被进程使用的文件列表。
- 记账信息: 可能包括处理器时间总和,使用的时钟数总和,时间限制,记账号等。
- 其他信息
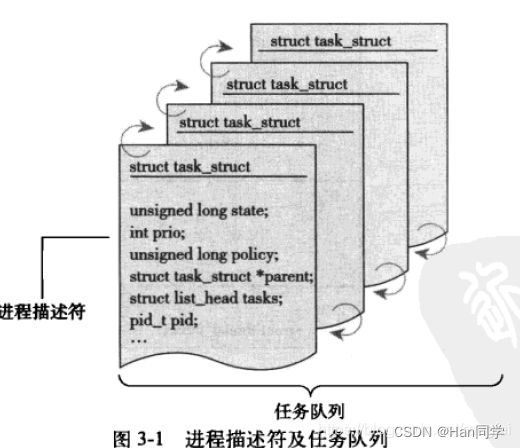
三、组织进程
- 有些操作系统会把任务队列称为任务数组。但是Linux实现时使用的是队列而不是静态数组,所以称为任务队列.
四、查看进程
新创建一个myproc.c文件,为其编写一个Makefile文件对其进行编译,然后运行myproc这个死循环的可执行程序方便持续查看进程。
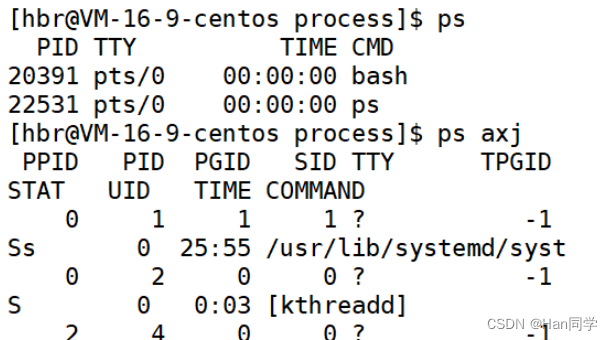
1、ps指令
ps指令是 Linux 中用于显示当前正在运行的进程的命令。它提供了有关进程的各种信息,例如进程的 PID(进程标识符)、CPU 和内存使用情况等。
- 默认情况下,如果你只输入
ps命令而不加任何选项,它会显示与当前终端会话相关的进程信息。这可能包括 Shell 以及你通过该 Shell 启动的其他进程。
ps axj | grep 'myproc'
- 这个命令是将两个命令结合起来使用,首先执行
ps axj命令,它会显示所有进程的详细信息。然后使用管道|将输出传递给grep 'myproc'命令,grep是用于搜索指定模式的文本的工具。- 因此,
ps axj | grep 'myproc'命令的作用是从所有进程的详细信息中过滤出包含字符串'myproc'的行。这样就能找到与'myproc'相关的进程信息。a选项表示显示所有用户的进程,而不仅仅是当前用户的进程。x选项表示显示没有控制终端的进程,即显示所有进程而不仅仅是与当前终端关联的进程。j选项表示以作业控制的格式显示进程信息,这种格式通常包括更多关于进程的详细信息。

ps axj | head -1 && ps axj | grep 'myproc'
- 首先执行
ps axj命令,它会显示所有进程的详细信息。然后使用管道|将输出传递给head -1命令,head -1只会显示输出的第一行,即列标题行,这样可以让我们看到列的含义。- 接着,
&&运算符表示如果前一个命令成功执行(即返回状态码为 0),则执行下一个命令。因此,如果第一个命令成功执行,就会继续执行第二个命令。- 第二个命令是
ps axj | grep 'myproc',它会从所有进程的详细信息中过滤出包含字符串'myproc'的行。这样就能找到与'myproc'相关的进程信息。

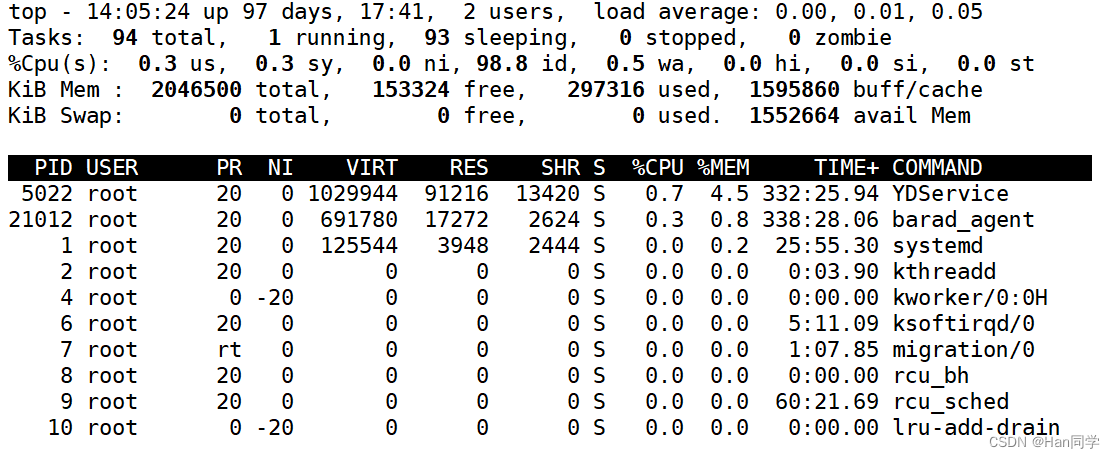
2、top命令
top命令是一个交互式的实用程序,用于动态监视系统的进程活动和资源利用情况。它可以显示各个进程的 CPU 占用、内存占用、以及其他系统资源的使用情况。top命令提供了一个实时更新的进程列表,用户可以通过键盘命令与其交互,例如排序进程、终止进程等。下面是一些常用的
top命令的键盘快捷键:
q:退出top命令。k:终止进程。输入该命令后,会提示输入需要终止的进程的 PID。Space:更新显示。1:切换到显示每个 CPU 核心的独立信息。M:按内存使用量排序。P:按 CPU 使用量排序。T:按时间排序。
top命令的输出通常包括:
- 系统概述:系统的运行时间、平均负载等。
- 进程信息:各个进程的 PID、CPU 使用率、内存使用量等。
- 系统资源:CPU 使用率、内存使用情况、交换分区使用情况等。
3、/proc文件系统
进程的信息可以通过 /proc 系统文件夹查看,/proc是一个特殊的虚拟文件系统,用于在Linux系统中提供进程和系统信息。虽然它在文件系统中显示为一个目录,但实际上它是一个由内核动态生成的虚拟文件系统,用于向用户空间提供系统和进程的信息。通过访问/proc目录,可以查看和管理运行中的进程,以及获取有关系统状态和配置的信息。
ls /proc
- 这个目录是动态的,多一个进程就多一个目录,少一个进程就少一个目录。
ls /proc -l
4、在/proc文件中查看指定进程
查找 myproc 进程:
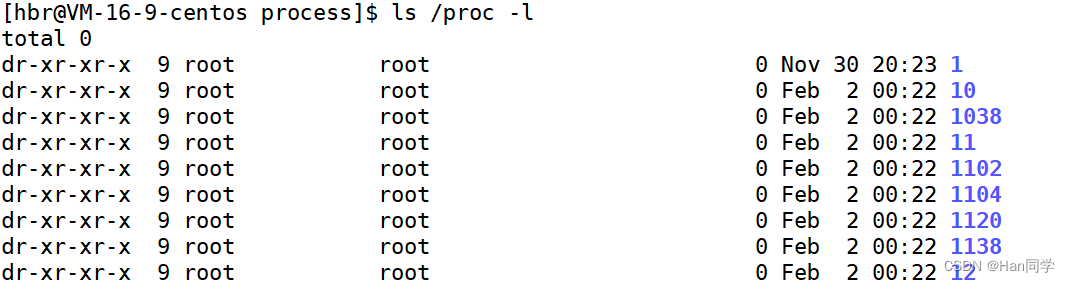
ps axj | grep myproc![]() 使用
使用 ps axj 命令列出所有进程的详细信息,然后用 grep 过滤出包含 myproc 的行。输出显示 myproc 进程的 PID 是 24857,同时也显示了运行 grep 命令本身的进程信息。
在 /proc 目录中查找进程:
ls /proc -l | grep '24857'![]() 这个命令列出了
这个命令列出了 /proc 目录的内容,并使用 grep 查找与 myproc 进程 PID(24857)相关的目录。/proc 文件系统包含了系统信息和正在运行的每个进程的详细信息。每个进程都有一个以其 PID 命名的目录。输出显示了 PID 为 24857 的进程的目录。
列出 /proc/24857 目录的内容:
ls /proc/24857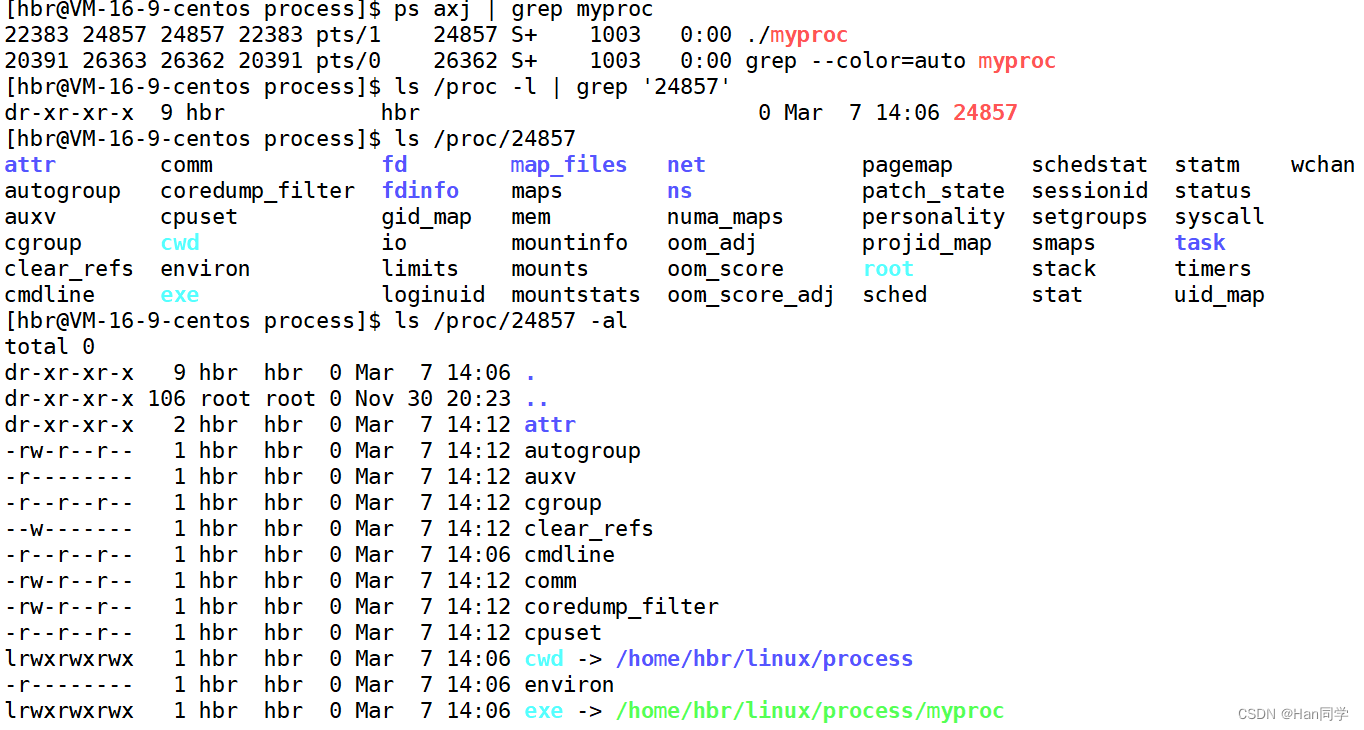 通过列出
通过列出 /proc/24857 目录的内容,可以看到与进程相关的许多文件和目录。这些文件和目录提供了关于进程的各种信息,包括:
cmdline:进程启动命令。cwd:进程的当前工作目录。environ:进程的环境变量。exe:到启动进程的可执行文件的符号链接。fd:包含指向进程打开的文件描述符的符号链接。status:进程的状态信息。mem:进程的内存映射。- 等等其他许多提供关于进程运行状态、资源使用情况等信息的文件和目录。
5、进程的工作目录
其中cwd表示当前进程的工作目录
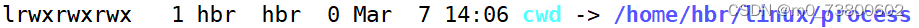
以前学习的FILE *fp = fopen("log.txt","w"),第一个参数没有带路径,默认打开当前路径。为什么呢?
这是因为我们的程序经过编译形成可执行程序,打开文件运行后,形成一个进程,每个进程都会有一个属性,来保存自己的工作路径。
五、通过系统调用获取进程标示符
1、getpid()/getppid()
使用man手册查看使用方法
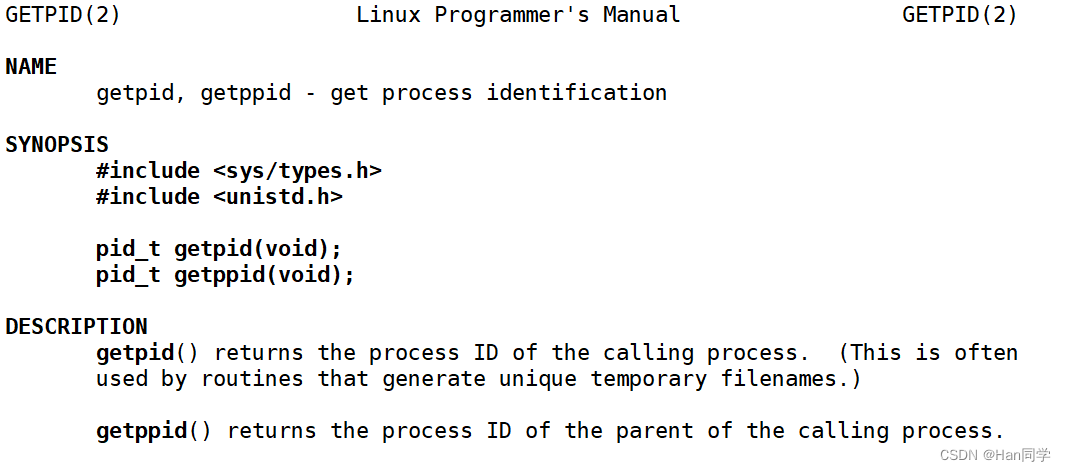
getpid()
- 功能:
getpid()函数用于获取当前进程的进程 ID(PID)。 - 返回值:它返回一个
pid_t类型的值,即当前进程的 PID。在 Linux 中,每个运行的进程都有一个唯一的进程标识符,用于区分不同的进程。 - 使用场景:该函数在需要根据进程 ID 进行进程管理或信息记录时非常有用。例如,日志记录时可能需要记录发起日志条目的进程 ID。
getppid()
- 功能:
getppid()函数用于获取当前进程的父进程的进程 ID(PPID)。 - 返回值:同样返回一个
pid_t类型的值,即当前进程的父进程的 PID。当一个进程被创建(通常是通过fork()调用)时,创建它的进程成为其父进程。 - 使用场景:这在需要了解或控制进程的层级结构时非常有用,比如,在创建守护进程时,可能会根据父进程的 ID 进行特定的逻辑判断。
下面我们创建一个myproc.c文件,输出的pid与我们查询的进程id进行比较:
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
int main()
{
while(1)
{
pid_t id=getpid(); //获取的是自己的进程
printf("hello world,pid: &d\n",,id);
sleep(1);
}
return 0;
}
右边复制一个SSH渠道,边运行边查看,如下图:

我们可以发现右边通过getpid成功输出进程myproc的pid。
我们再输出一下父进程id(ppid)
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
int main()
{
while(1)
{
pid_t id=getpid();
printf("hello world, pid: %d, ppid: %d\n",id,getppid());
sleep(1);
}
return 0;
}
输出结果 :

2、kill命令
kill 命令用于向进程发送信号,以控制进程的行为或终止进程。它的基本语法是:
kill [options] <PID>其中 <PID> 是要终止的进程的进程标识符。

常用的 kill 命令选项包括:
-l:列出可用的信号名称。-9:发送强制终止信号,也称为 SIGKILL,立即终止目标进程。-15:发送终止信号,也称为 SIGTERM,默认行为是终止目标进程,但它可以被进程捕获、忽略或处理。-SIG<signal>:使用信号名称来指定要发送的信号,例如-SIGTERM。
例如,要终止PID为22053的进程,操作如下:

五、通过系统调用创建进程
1、bash
每次查询当前运行的命令时,我们知道子进程是我们创建并运行的,那父进程是谁?
- 父进程是bash。
系统中,每个命令行上运行的命令都是由 Bash shell 的一个子进程执行。此外,Bash shell 本身也是系统中许多进程的父进程。 Bash shell 是命令行界面的核心,负责解释和执行用户输入的命令。
复习Shell概念
- Shell(外壳)是计算机操作系统中的一个用户界面,用于与操作系统内核进行交互。Shell允许用户通过命令行或图形用户界面(GUI)来执行操作系统提供的功能和应用程序。Shell接受用户输入的命令,并将其解释并传递给操作系统内核执行。
- 在类Unix操作系统(如Linux、macOS等)中,常见的Shell包括Bash(Bourne Again Shell)、Zsh(Z Shell)、Fish等。这些Shell提供了丰富的命令和功能,使用户能够管理文件、运行程序、配置系统等操作。
在大多数Linux系统中,常用的命令行解释器(shell)是Bash(Bourne Again Shell)。Bash是一个流行的Unix shell,也是许多Linux发行版的默认shell。它提供了丰富的功能和命令,使用户能够与操作系统进行交互、执行命令、编写脚本等。
如果我们kill -9 bash呢?
kill -9 加上bash的id ,命令行会会失效。
-
立即终止会话: 当前终端或会话中的Bash进程会被立即终止,导致您失去对该终端会话的访问。
-
子进程可能被终止: 如果该Bash进程启动了任何子进程,那么这些进程可能也会因为父进程的终止而受到影响,除非它们已经被设置为守护进程或与终端会话分离。
-
未保存的数据丢失: 如果您在该Bash会话中运行的程序或编辑器中有未保存的工作,强制终止Bash进程将导致这些数据丢失。
-
不影响其他Bash会话: 如果您在同一系统上打开了多个终端会话,这个操作只会影响您向其发送
kill -9命令的那个Bash进程。其他Bash会话及其子进程将不受影响。 -
可能需要重新登录: 终止当前会话的Bash进程后,您可能需要重新打开一个新的终端会话或重新登录您的用户账户来恢复正常操作。
- 注意:每次登入的bash都不同,复制一个SSH通道,杀掉bash进程,不会影响另一个窗口运行命令。
2、fork()
在Linux系统中,
fork()是一个系统调用,用于创建一个新的进程。调用fork()后,操作系统会复制当前进程的副本,包括代码段、数据段、堆栈等,然后在新的进程中运行。原始进程被称为父进程,新创建的进程被称为子进程。
- 在
fork()调用后,父进程和子进程会继续执行后续的代码,但是它们会有不同的进程ID(PID)和返回值。在父进程中,fork()返回子进程的PID,而在子进程中,fork()返回0。 - 通过
fork()创建子进程后,父子进程之间会共享一些资源,如文件描述符、内存映射等,但各自有独立的地址空间。这样可以实现并发执行,父子进程可以在独立的执行环境中运行不同的任务。
按照顺序先运行没有fork的代码,再运行有fork的版本。
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
int main()
{
printf("I am parent process.\n");
printf("you can see me.\n");
return 0;
}#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
int main()
{
printf("I am parent process.\n");
fork();
printf("you can see me.\n");
sleep(1);
return 0;
}输出结果如下:我们可以发现创建子进程后有一句被输出了两次。
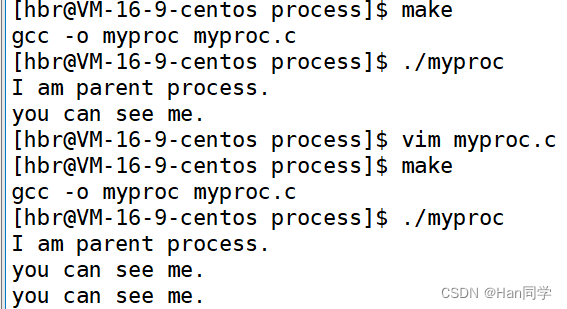
这是因为创建进程后,变为两个程序,一个是父进程,另一个是子进程,他们分别运行fork()后面的程序。
父子进程返回结果不同
我们再观察下面代码的输出结果
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
int main()
{
printf("I am parent process.\n");
pid_t ret=fork();
printf("ret: %d, pid: %d, ppid: %d\n",ret,getpid(),getppid());
sleep(1);
return 0;
}
fork为什么给父进程返回子进程pid,给子进程返回0?
- 当
fork()在父进程中被调用时,它会返回子进程的PID(进程ID),这样父进程就可以知道新创建的子进程的PID,从而可以对子进程进行管理或跟踪。 - 当
fork()在子进程中被调用时,它会返回0,这样子进程可以通过返回值来确定自己是子进程,而不是父进程。子进程可以根据返回值执行自己的逻辑,而不是继续执行父进程的代码。
fork之后有两个不同的执行流
为什么下面else if和else可以同时输出呢?因为fork之后有两个不同的执行流 。
#include <stdio.h>
#include <unistd.h>
int main()
{
pid_t id=fork();
if(id<0)
{
//创建失败
perror("fork");
return 1;
}
else if(id==0)
{
//child process
while(1)
{
printf("I am child, pid:%d, ppid:%d\n",getpid(),getppid());
sleep(1);
}
}
else
{
//parent process
while(1)
{
printf("I am father, pid:%d, ppid:%d\n",getpid(),getppid());
sleep(1);
}
}
printf("you can see me\n");
sleep(1);//进程退出顺序不一样
return 0;
}
我们通过下面命令是用来监视名为"myproc"的进程。
while :; do ps axj | head -1 && ps axj | grep myproc | grep -v grep; sleep 1; done这是一个无限循环(
while :; do ... done),在循环内部,它首先使用ps axj | head -1命令来显示进程列表的标题行(列名),然后通过ps axj | grep myproc | grep -v grep命令来显示包含 "myproc" 的进程,同时使用grep -v grep来排除 grep 进程本身。最后,sleep 1用于每秒暂停一次

我们可以为每次输出结果之间加上一条分割线。(###分隔符过长仅保留部分)
while :; do ps axj | head -1 && ps axj | grep myproc | grep -v grep; sleep 1; echo "###"; done

fork创建进程后,为什么会有两个返回值?
- Linux中的
fork()系统调用返回两次值,这是因为在Unix系统中,fork()的设计是基于父子进程的概念。调用fork()时,操作系统会复制当前进程,创建一个新的子进程。这个子进程是父进程的副本,但它们是两个独立的进程,各自有自己的地址空间。 fork()创建进程后返回两次值的原因是,在fork()内部,父进程和子进程各自会执行自己的return语句,这导致了两次返回。这并不意味着操作系统保存了两次状态,而是因为父进程和子进程在不同的执行上下文中各自返回。
3、总结:
- 在操作系统中,当需要运行一个进程时,实际上是从任务结构(
task_struct)形成的队列中选择一个任务结构来执行该进程的代码。进程调度实质上就是在任务结构队列中选择一个进程的过程。 - 在创建父子进程后,哪个进程先运行并不确定。这是由操作系统的调度器决定的。调度器会根据一定的策略(如优先级、时间片轮转等)来决定下一个要运行的进程。
- 因此,父子进程的执行顺序不确定,取决于操作系统的调度算法。