文章目录
- 前言
- EMA的定义
- 在深度学习中的应用
- PyTorch代码实现
- yolov5中模型的EMA实现
- 参考
前言
在深度学习中,经常会使用EMA(指数移动平均)这个方法对模型的参数做平均,以求提高测试指标并增加模型鲁棒。
实际上,_EMA可以看作是Temporal Ensembling,在模型学习过程中融合更多的历史状态,从而达到更好的优化效果。
EMA的定义
指数移动平均(Exponential Moving Average)也叫权重移动平均(Weighted Moving Average),是一种给予近期数据更高权重的平均方法。
假设有n个权重数据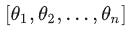 :
:
- 普通的平均数:
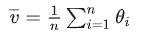
- EMA:
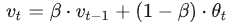
其中, vt表示前 t条的平均值 ( v0=0 ),β是加权权重值 (一般设为0.9-0.999)。
Andrew Ng在Course 2 Improving Deep Neural Networks中讲到,EMA可以近似看成过去 1/(1−β) 个时刻 v 值的平均。
普通的过去n时刻的平均是这样的: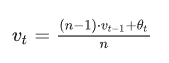
类比EMA,可以发现当 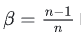 时,两式形式上相等。需要注意的是,两个平均并不是严格相等的,这里只是为了帮助理解。
时,两式形式上相等。需要注意的是,两个平均并不是严格相等的,这里只是为了帮助理解。
实际上,EMA计算时,过去 1/(1−β) 个时刻之前的数值平均会decay到 1/e 的加权比例,证明如下。
如果将这里的 vt展开,可以得到: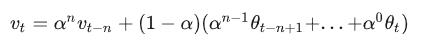
其中, 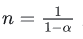 ,代入可以得到
,代入可以得到 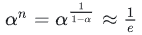 。
。
在深度学习中的应用
上面讲的是广义的ema定义和计算方法,特别的,在深度学习的优化过程中, 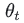 是t时刻的模型权重weights, vt是t时刻的影子权重(shadow weights)。在梯度下降的过程中,会一直维护着这个影子权重,但是这个影子权重并不会参与训练。
是t时刻的模型权重weights, vt是t时刻的影子权重(shadow weights)。在梯度下降的过程中,会一直维护着这个影子权重,但是这个影子权重并不会参与训练。
基本的假设是,模型权重在最后的n步内,会在实际的最优点处抖动,所以我们取最后n步的平均,能使得模型更加的鲁棒。
PyTorch代码实现
下面是一个简单的指数移动平均(EMA)的PyTorch实现:
import torch
class EMA():
def __init__(self, alpha):
self.alpha = alpha # 初始化平滑因子alpha
self.average = None # 初始化平均值为空
self.count = 0 # 初始化计数器为0
def update(self, x):
if self.average is None: # 如果平均值为空,则将其初始化为与x相同大小的全零张量
self.average = torch.zeros_like(x)
self.average = self.alpha * x + (1 - self.alpha) * self.average # 更新平均值
self.count += 1 # 更新计数器
def get(self):
return self.average / (1 - self.alpha ** self.count) # 根据计数器和平滑因子计算EMA值,并返回平均值除以衰减系数的结果
在这个类中,我们定义了三个方法,分别是__init__、update和get。
- __init__方法用于初始化平滑因子alpha、平均值average和计数器count
- update方法用于更新EMA值
- get方法用于获取最终的EMA值。
使用这个类时,我们可以先实例化一个EMA对象,然后在每个时间步中调用update方法来更新EMA值,最后调用get方法来获取最终的EMA值。
例如:
ema = EMA(alpha=0.5)
for value in data:
ema.update(torch.tensor(value))
smoothed_data = ema.get()
在这个例子中,我们使用alpha=0.5来初始化EMA对象,然后遍历数据集data中的每个数据点,调用update方法更新EMA值。最后我们调用get方法来获取平滑后的数据。
yolov5中模型的EMA实现
如下:
class ModelEMA:
"""
Updated Exponential Moving Average (EMA) from https://github.com/rwightman/pytorch-image-models
Keeps a moving average of everything in the model state_dict (parameters and buffers)
For EMA details see https://www.tensorflow.org/api_docs/python/tf/train/ExponentialMovingAverage
"""
def __init__(self, model, decay=0.9999, tau=2000, updates=0):
# Create EMA
self.ema = deepcopy(de_parallel(model)).eval() # FP32 EMA
self.updates = updates # number of EMA updates
self.decay = lambda x: decay * (1 - math.exp(-x / tau)) # decay exponential ramp (to help early epochs)
for p in self.ema.parameters():
p.requires_grad_(False)
def update(self, model):
# Update EMA parameters
self.updates += 1
d = self.decay(self.updates)
msd = de_parallel(model).state_dict() # model state_dict
for k, v in self.ema.state_dict().items():
if v.dtype.is_floating_point: # true for FP16 and FP32
v *= d
v += (1 - d) * msd[k].detach()
# assert v.dtype == msd[k].dtype == torch.float32, f'{k}: EMA {v.dtype} and model {msd[k].dtype} must be FP32'
def update_attr(self, model, include=(), exclude=('process_group', 'reducer')):
# Update EMA attributes
copy_attr(self.ema, model, include, exclude)
参考
https://zhuanlan.zhihu.com/p/68748778
如果有用,请点个三连呗 点赞、关注、收藏。
你的鼓励是我最大的动力