编译原理之词法分析-语法分析-中间代码生成
- 文章说明
- 源码
- 效果展示
- Gitee链接
文章说明
学习编译原理后,总是想制作自己的一款小语言编译器,虽然对技术不是很理解,学的不是很扎实,但还是想着尝试尝试;目前该效果只是初步设计实现下的效果,没有采用较为规范的EBNF(巴科斯范式)来进行文法的描述,因为我总觉得那样的效果对我来说有些抽象,有些困难。所以我自己简单的采用解释器模式来模拟编译的关键步骤:词法分析、语法分析、中间代码生成
源码
参见链接,部分核心代码如下:
主程序
package com.boot.compiler;
import com.boot.compiler.entity.AbstractSyntaxTree;
import com.boot.compiler.entity.Block;
import com.boot.compiler.entity.Function;
import com.boot.compiler.entity.Operation;
import com.boot.compiler.util.ir.IrAnalyzer;
import com.boot.compiler.util.lexical.LexicalAnalyzer;
import com.boot.compiler.util.semantic.SemanticAnalyzer;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.nio.charset.StandardCharsets;
import java.util.List;
/**
* @author bbyh
* @date 2024/3/9 22:30
*/
public class TestMain {
private static final String PROGRAM_PATH = "D:/compiler/program.txt";
private static final String SPLIT_WORD_PATH = "D:/compiler/split_word.txt";
private static final String ABSTRACT_SYNTAX_TREE_PATH = "D:/compiler/abstract_syntax_tree.txt";
private static final String IR_CODE_PATH = "D:/compiler/ir_code.txt";
public static void main(String[] args) throws Exception {
byte[] buf = new byte[1024 * 1024];
String text;
try (FileInputStream inputStream = new FileInputStream(PROGRAM_PATH)) {
int read = inputStream.read(buf);
text = new String(buf, 0, read);
}
List<Operation> operationList = LexicalAnalyzer.analyse(text);
try (FileOutputStream outputStream = new FileOutputStream(SPLIT_WORD_PATH)) {
for (Operation operation : operationList) {
outputStream.write(operation.type.toString().getBytes(StandardCharsets.UTF_8));
outputStream.write("\t".getBytes(StandardCharsets.UTF_8));
outputStream.write(operation.value.getBytes(StandardCharsets.UTF_8));
outputStream.write("\n".getBytes(StandardCharsets.UTF_8));
}
}
AbstractSyntaxTree abstractSyntaxTree = SemanticAnalyzer.analyse(operationList);
try (FileOutputStream outputStream = new FileOutputStream(ABSTRACT_SYNTAX_TREE_PATH)) {
List<Function> functionList = abstractSyntaxTree.functionList;
for (Function function : functionList) {
outputStream.write((function.name + "\n").getBytes(StandardCharsets.UTF_8));
List<Block> blockList = function.blockList;
for (Block block : blockList) {
outputStream.write(("\t" + block.blockType + "\n").getBytes(StandardCharsets.UTF_8));
List<Operation> blockOperationList = block.operationList;
for (Operation blockOperation : blockOperationList) {
outputStream.write(("\t\t" + blockOperation.type + "\t" + blockOperation.value + "\n").getBytes(StandardCharsets.UTF_8));
}
}
}
}
IrAnalyzer.analyse(abstractSyntaxTree);
try (FileOutputStream outputStream = new FileOutputStream(IR_CODE_PATH)) {
List<Function> functionList = abstractSyntaxTree.functionList;
for (Function function : functionList) {
outputStream.write((function.name + "\n").getBytes(StandardCharsets.UTF_8));
List<String> irList = function.irList;
for (String irCode : irList) {
outputStream.write(("\t" + irCode + "\n").getBytes(StandardCharsets.UTF_8));
}
}
}
}
}
定义的关键字
package com.boot.compiler.entity;
import java.util.HashMap;
import java.util.HashSet;
import java.util.Map;
import java.util.Set;
public class KeyWord {
public OperationType type;
public String name;
public KeyWord(OperationType type, String name) {
this.type = type;
this.name = name;
}
public static final Map<String, OperationType> KEY_WORD_MAP = new HashMap<>(10);
public static final Set<String> KEY_WORD_SET = new HashSet<>(10);
static {
KEY_WORD_SET.add("function");
KEY_WORD_SET.add("int");
KEY_WORD_MAP.put("function", OperationType.FUNCTION);
KEY_WORD_MAP.put("int", OperationType.INT);
}
}
定义的运算符
package com.boot.compiler.entity;
import java.util.*;
/**
* @author bbyh
* @date 2024/3/10 11:44
*/
public class Calculator {
public OperationType type;
public String name;
public Calculator(OperationType type, String name) {
this.type = type;
this.name = name;
}
@Override
public String toString() {
return "Calculator{" +
"type=" + type +
", name='" + name + '\'' +
'}';
}
public static final Map<String, OperationType> CALCULATOR_MAP = new HashMap<>(10);
public static final Set<String> CALCULATOR_SET = new HashSet<>(10);
static {
CALCULATOR_SET.add("(");
CALCULATOR_SET.add(")");
CALCULATOR_SET.add("{");
CALCULATOR_SET.add("}");
CALCULATOR_SET.add(";");
CALCULATOR_SET.add("=");
CALCULATOR_SET.add("+");
CALCULATOR_MAP.put("(", OperationType.LEFT_LITTLE);
CALCULATOR_MAP.put(")", OperationType.RIGHT_LITTLE);
CALCULATOR_MAP.put("{", OperationType.LEFT_LARGE);
CALCULATOR_MAP.put("}", OperationType.RIGHT_LARGE);
CALCULATOR_MAP.put(";", OperationType.SEMICOLON);
CALCULATOR_MAP.put("=", OperationType.ASSIGN);
CALCULATOR_MAP.put("+", OperationType.ADD);
}
}
词法分析实现
package com.boot.compiler.util.lexical;
import com.boot.compiler.entity.Operation;
import com.boot.compiler.entity.OperationType;
import com.boot.compiler.util.Character;
import java.util.ArrayList;
import java.util.List;
import static com.boot.compiler.entity.Calculator.CALCULATOR_MAP;
import static com.boot.compiler.entity.Calculator.CALCULATOR_SET;
import static com.boot.compiler.entity.KeyWord.KEY_WORD_MAP;
import static com.boot.compiler.entity.KeyWord.KEY_WORD_SET;
/**
* @author bbyh
* @date 2024/3/9 22:38
*/
public class LexicalAnalyzer {
private static final String LINE_SPLIT = "\n";
private static final String WORD_SPLIT = " ";
private static final String TAB_SPLIT = "\t";
private static String[] split(String text) {
text = text.replaceAll(TAB_SPLIT, " ");
StringBuilder buffer = new StringBuilder();
String[] lines = text.split(LINE_SPLIT);
for (String line : lines) {
buffer.append(line.trim());
}
return buffer.toString().split(WORD_SPLIT);
}
public static List<Operation> analyse(String text) {
String[] split = split(text);
List<Operation> wordList = new ArrayList<>(split.length);
for (String word : split) {
if (KEY_WORD_SET.contains(word)) {
wordList.add(new Operation(KEY_WORD_MAP.get(word), word));
continue;
}
if (CALCULATOR_SET.contains(word)) {
wordList.add(new Operation(CALCULATOR_MAP.get(word), word));
continue;
}
int current = 0;
int start = 0;
String subString;
while (current < word.length()) {
char ch = word.charAt(start);
// 处理为运算符的情况
if (CALCULATOR_SET.contains(ch + "")) {
wordList.add(new Operation(CALCULATOR_MAP.get(ch + ""), ch + ""));
current++;
start++;
continue;
}
ch = word.charAt(start);
// 处理为"小大写字母"的情况
if (Character.isLetter(ch)) {
while (Character.isLetterOrNumber(ch)) {
current++;
if (current == word.length()) {
break;
}
ch = word.charAt(current);
}
subString = word.substring(start, current);
if (KEY_WORD_SET.contains(subString)) {
wordList.add(new Operation(KEY_WORD_MAP.get(subString), subString));
} else {
wordList.add(new Operation(OperationType.VAR, subString));
}
start = current;
continue;
}
ch = word.charAt(start);
// 处理为"整数"的情况
if (Character.isNumber(ch)) {
while (Character.isNumber(ch)) {
current++;
if (current == word.length()) {
break;
}
ch = word.charAt(current);
}
subString = word.substring(start, current);
wordList.add(new Operation(OperationType.INT_NUMBER, subString));
start = current;
}
}
}
return wordList;
}
}
语法分析实现
package com.boot.compiler.util.semantic;
import com.boot.compiler.entity.AbstractSyntaxTree;
import com.boot.compiler.entity.Operation;
import com.boot.compiler.util.semantic.executor.AbstractSemanticAnalyzerExecutor;
import java.util.List;
/**
* @author bbyh
* @date 2024/3/10 13:32
*/
public class SemanticAnalyzer {
public static AbstractSyntaxTree analyse(List<Operation> operationList) {
AbstractSemanticAnalyzerExecutor executor = new AbstractSemanticAnalyzerExecutor(operationList);
executor.execute();
return AbstractSemanticAnalyzerExecutor.abstractSyntaxTree;
}
}
package com.boot.compiler.util.semantic.executor;
import com.boot.compiler.entity.AbstractSyntaxTree;
import com.boot.compiler.entity.Block;
import com.boot.compiler.entity.Function;
import com.boot.compiler.entity.Operation;
import java.util.List;
/**
* @author bbyh
*/
public class AbstractSemanticAnalyzerExecutor {
protected static List<Operation> operationList;
protected static int index;
public static AbstractSyntaxTree abstractSyntaxTree;
public AbstractSemanticAnalyzerExecutor() {
}
public AbstractSemanticAnalyzerExecutor(List<Operation> operationList) {
AbstractSemanticAnalyzerExecutor.abstractSyntaxTree = new AbstractSyntaxTree();
AbstractSemanticAnalyzerExecutor.operationList = operationList;
AbstractSemanticAnalyzerExecutor.index = 0;
}
public void execute() {
nextExecutor().execute();
}
protected final AbstractSemanticAnalyzerExecutor nextExecutor() {
Operation operation = operationList.get(index);
switch (operation.type) {
case FUNCTION:
return new FunctionExecutor();
case INT:
return new IntExecutor();
case LEFT_LITTLE:
return new LeftLittleExecutor();
case RIGHT_LITTLE:
return new RightLittleExecutor();
case LEFT_LARGE:
return new LeftLargeExecutor();
case RIGHT_LARGE:
return new RightLargeExecutor();
case SEMICOLON:
return new SemicolonExecutor();
case ASSIGN:
return new AssignExecutor();
case ADD:
return new AddExecutor();
case INT_NUMBER:
return new IntNumberExecutor();
case VAR:
return new VarExecutor();
default:
throw new UnsupportedOperationException("语义解析出错,执行器获取失败");
}
}
protected final void addOperation(Operation operation) {
Function function = abstractSyntaxTree.functionList.get(abstractSyntaxTree.functionList.size() - 1);
if (function.blockList == null) {
throw new UnsupportedOperationException("语义解析出错,语句块声明缺失");
}
Block block = function.blockList.get(function.blockList.size() - 1);
if (block.operationList == null) {
throw new UnsupportedOperationException("语义解析出错,语句块声明缺失");
}
block.operationList.add(new Operation(operation.type, operation.value));
}
}
IR生成
package com.boot.compiler.util.ir.executor;
import com.boot.compiler.entity.AbstractSyntaxTree;
import com.boot.compiler.entity.Block;
/**
* @author bbyh
* @date 2024/3/10 16:30
*/
public class AbstractIrAnalyzerExecutor {
public static AbstractSyntaxTree abstractSyntaxTree;
public static int indexOfFunction;
public static int indexOfBlock;
public AbstractIrAnalyzerExecutor() {
}
public AbstractIrAnalyzerExecutor(AbstractSyntaxTree abstractSyntaxTree) {
AbstractIrAnalyzerExecutor.abstractSyntaxTree = abstractSyntaxTree;
AbstractIrAnalyzerExecutor.indexOfFunction = 0;
AbstractIrAnalyzerExecutor.indexOfBlock = 0;
}
public void execute() {
new FunctionExecutor().execute();
}
public final AbstractIrAnalyzerExecutor nextBlockExecutor() {
Block block = abstractSyntaxTree.functionList.get(indexOfFunction).blockList.get(indexOfBlock);
switch (block.blockType){
case SEQUENCE:
return new SequenceBlockExecutor();
case CONDITION:
return new ConditionBlockExecutor();
case LOOP:
return new LoopBlockExecutor();
default:
throw new UnsupportedOperationException("语法树解析出错,执行器获取失败");
}
}
}
效果展示
源程序
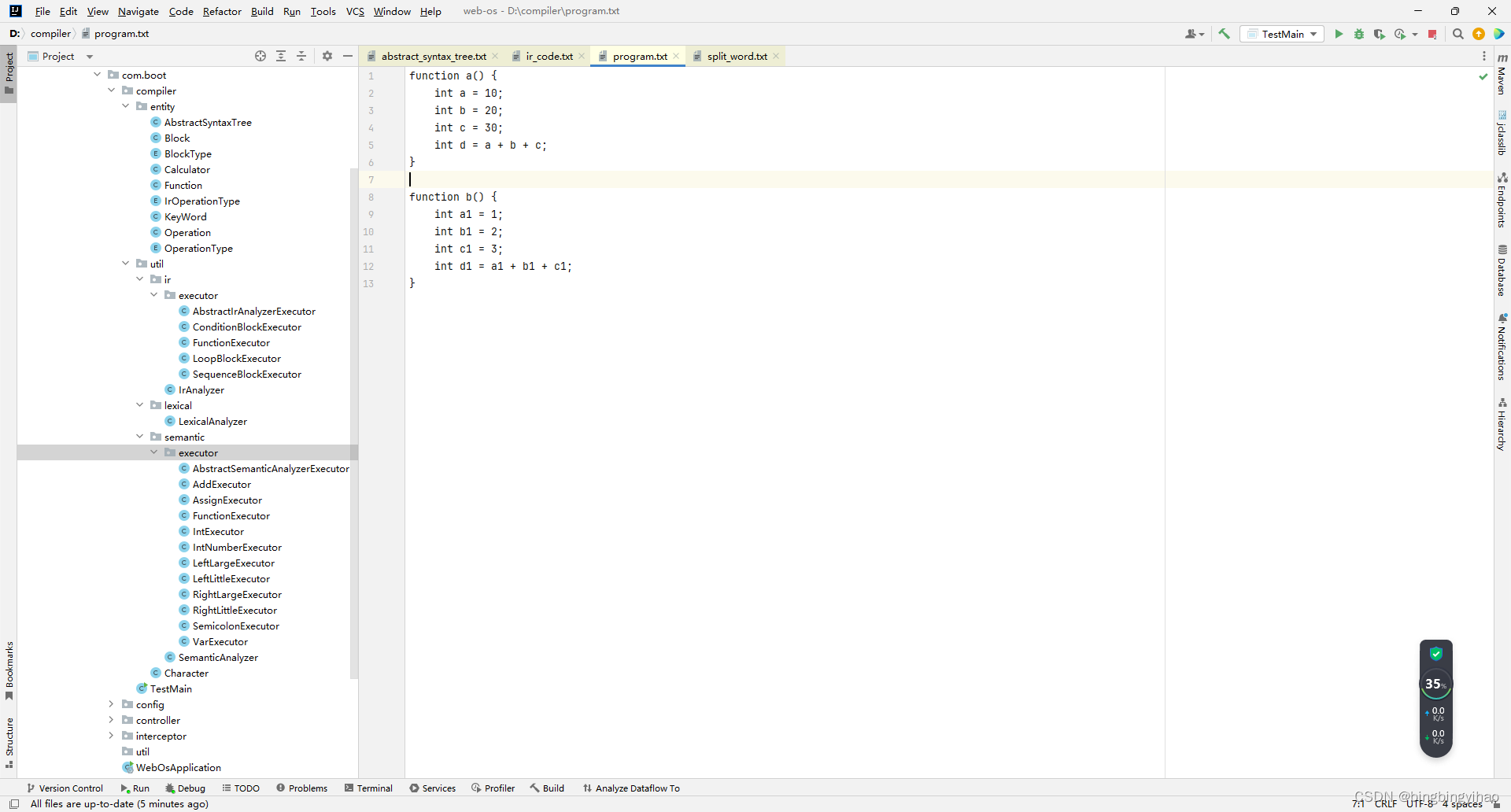
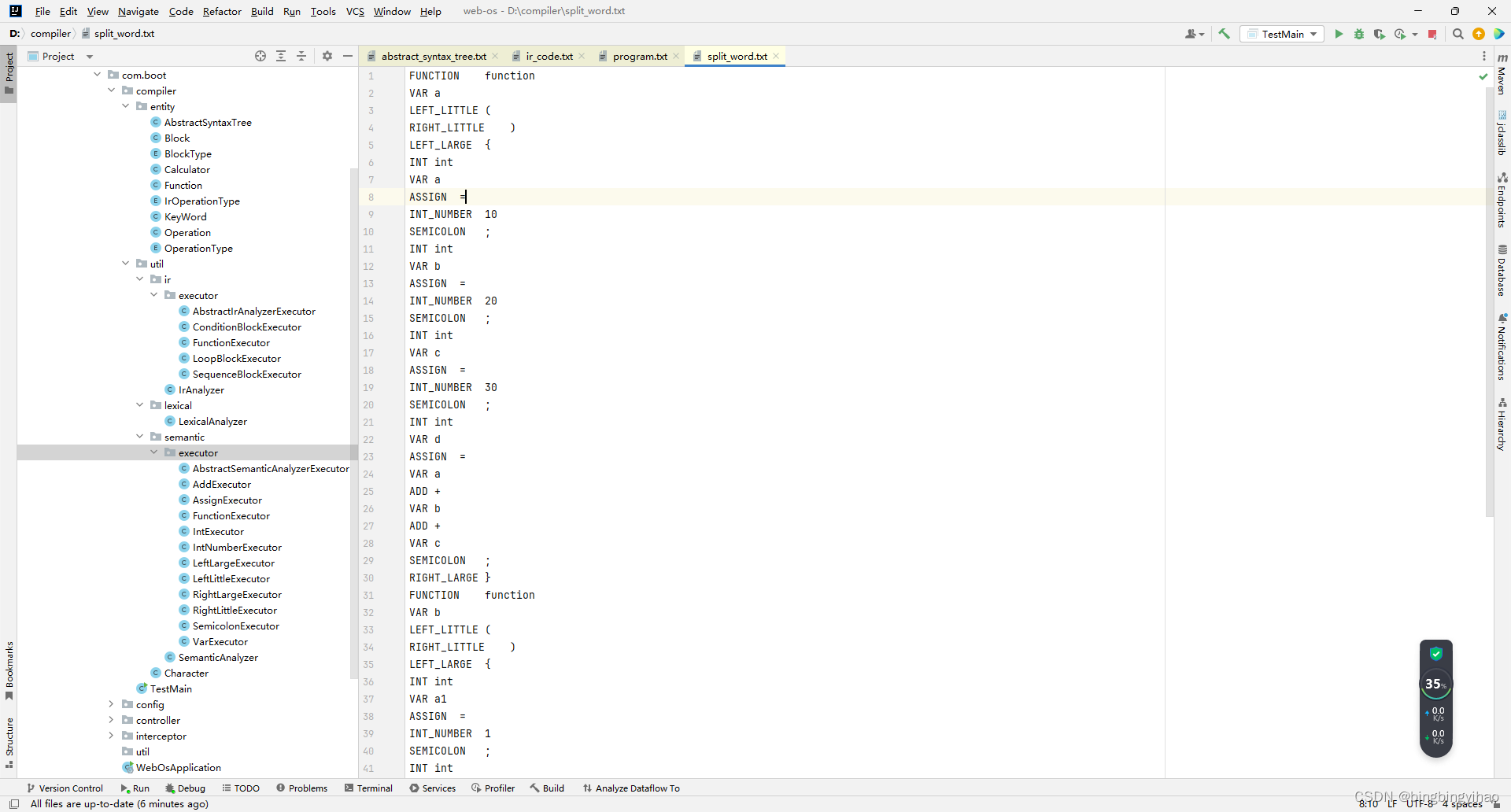
词法分析结果
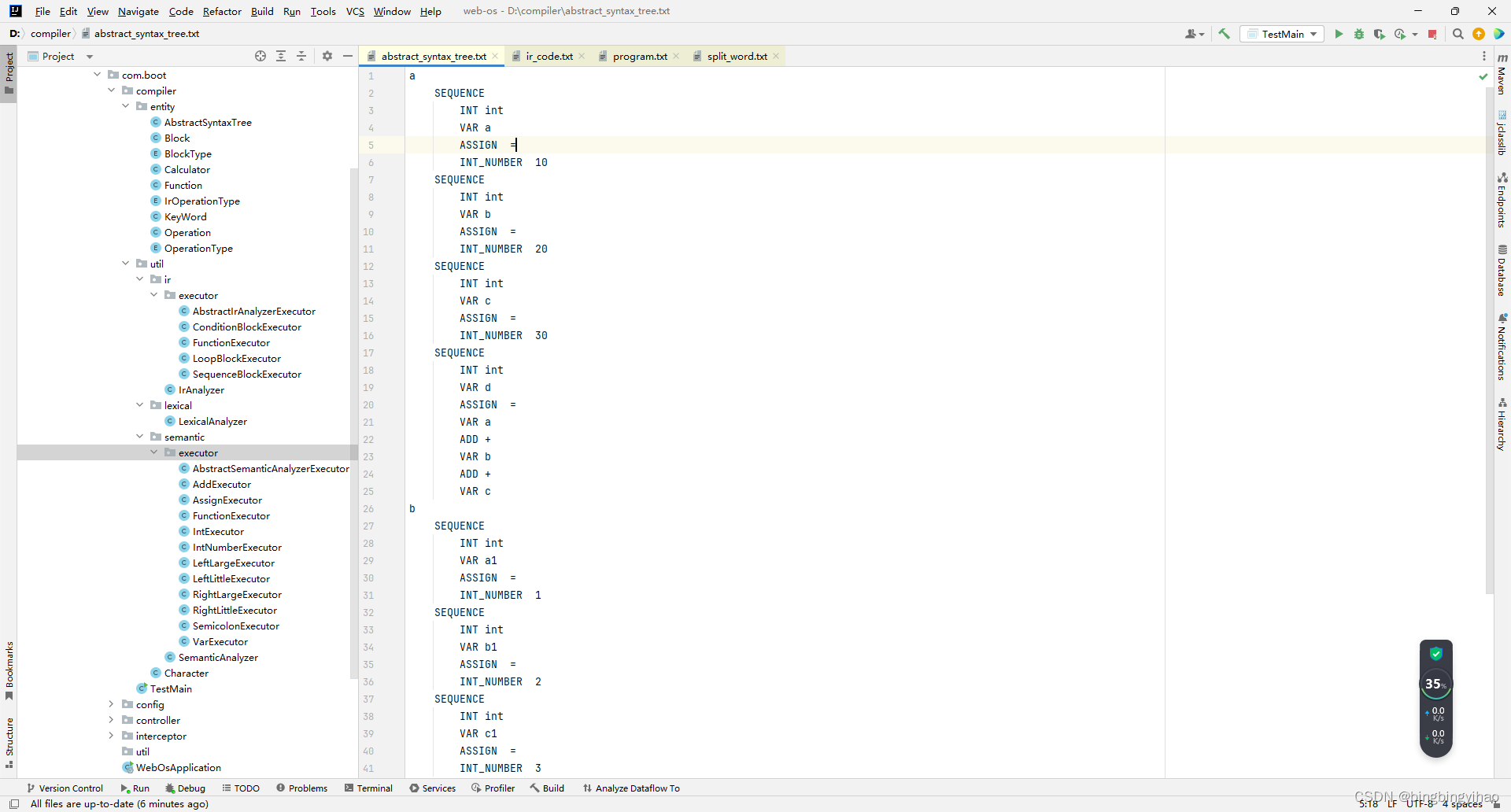
抽象语法树结果
生成的IR(中间代码),以常见的汇编格式展示,并不是规范的ARM或x86格式
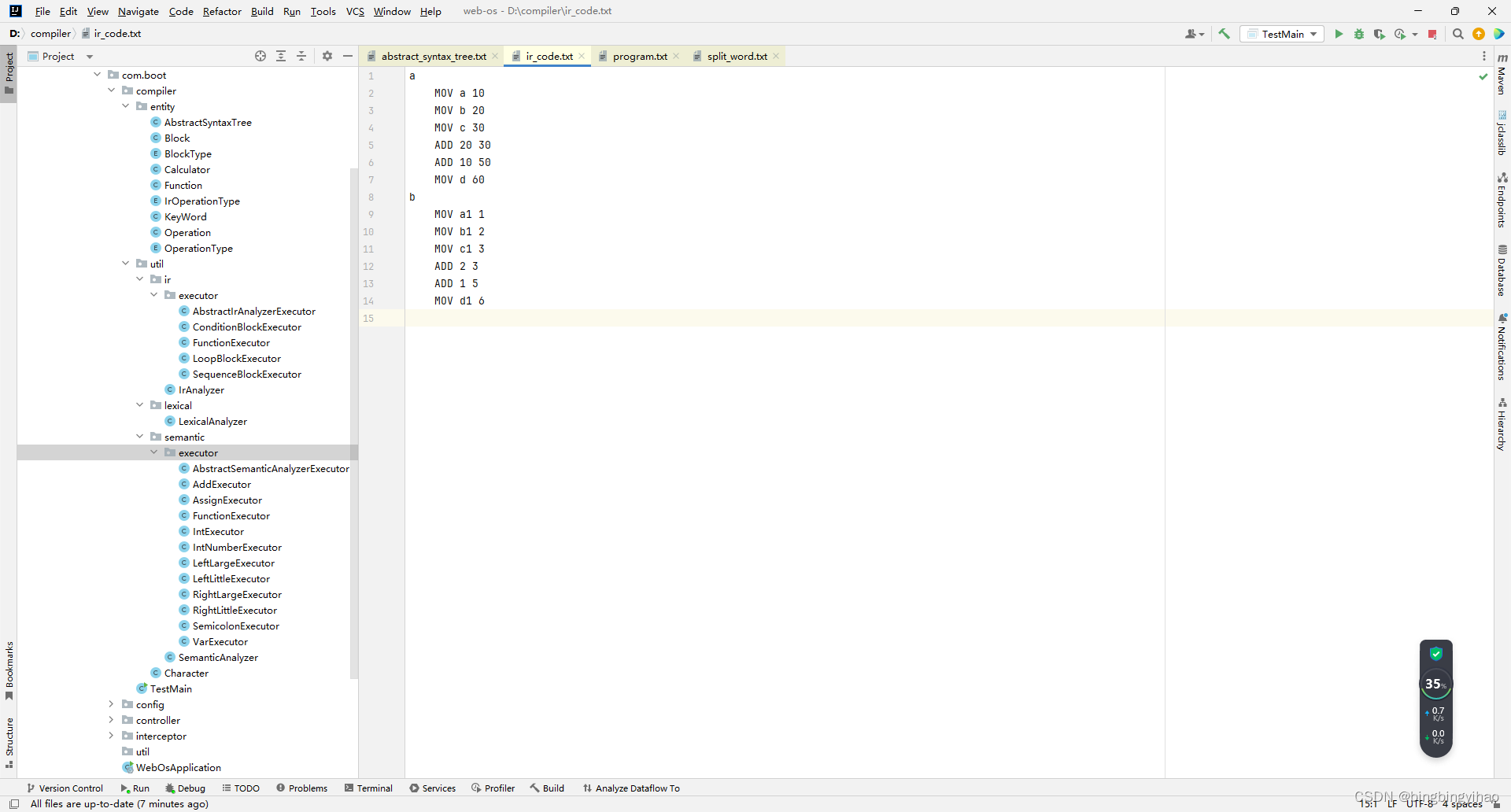
采用立即数表示的ADD操作,是因为我对其中的生成IR的实现还存有一些困难点没解决,后续会考虑修正该效果
Gitee链接
参见Gitee链接(WEB-OS-SYSTEM)