文章目录
- 浮点数问题
- 浮点数赋值和打印不同
- 0.1累加100次,得到的不是10
- 计算机如何存储整数
- 计算机如何存储浮点数
- 二进制小数表示法
- 浮点数表示
- 小数和浮点数的转换
- 十进制小数转换成浮点数二进制
- float二进制转换成十进制小数
- 问题
- 解决方法
- 参考资料
浮点数问题
浮点数赋值和打印不同
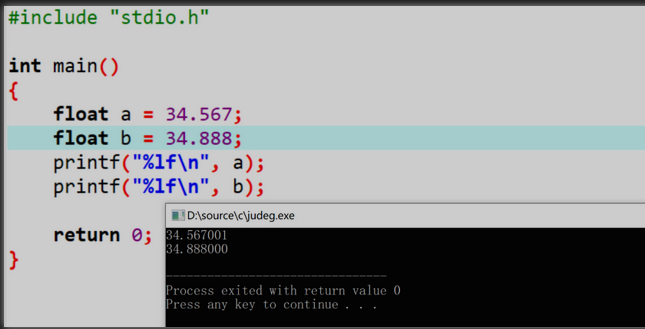
0.1累加100次,得到的不是10

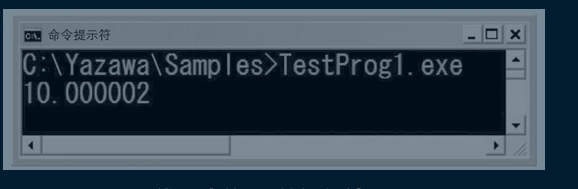
得到结果是10.000002
计算机如何存储整数
在讲为什么会有浮点误差之前,先来谈谈电脑是怎么用0 跟1 来表示一个 整数,大家应该都知道二进制这个东西:像 101 代表2² + 2⁰ 也就是5、1010代表2³ + 2¹ 也就是10
十进制整数的每个1,二进制都能对应1增加,因为每一个bit 都可以是0 或1,整个变数值有2³² 种可能性,所以可以 精确的 表达出0 到2³²-1 中任一个值,不会有任何误差
计算机如何存储浮点数
虽然从0 到2³²-1 之间有很多很多个整数,但数量终究是 有限 的,就是2³² 个那么多而已;
但浮点数就大大的不同了,大家可以这样想:在1 到10 这个区间中只有十个整数,但却有无限多个 浮点数,譬如说5.1、5.11、5.111 等等,再怎么数都数不完。
但因为在32 bit 的空间中就只有2³² 种可能性,为了把所有浮点数都塞在这个32 bit 的空间里面,许多CPU 厂商发明了各种浮点数的表示方式,但若各家CPU 的格式都不一样也很麻烦,所以最后是以IEEE发布的IEEE 754作为通用的浮点数运算标准,后来的CPU 也都遵循这个标准进行设计
二进制小数表示法
二进制小数转换成十进制
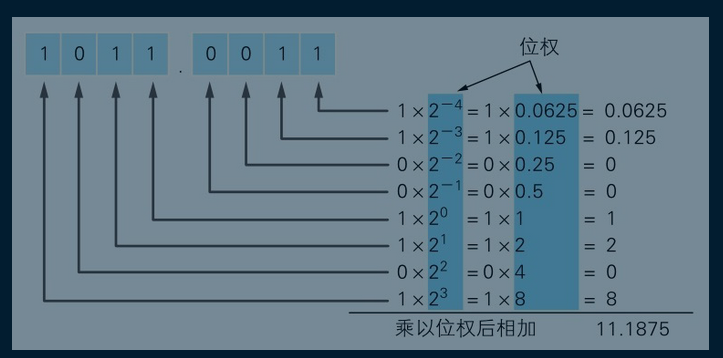
通过上面图可以看到小数部分表示和整数计算方式是一样的。
但是有个问题就是小数可以无限往后N多位,而我们计算机的位数是有限的,所以只能表示特定的一些数。
比如上面如果只有4位小数的话,那么我们是无法表示0.0625和0.125之间的数。
如果增加二进制数小数点后面的位数,与其相对应的十进制数的个数也会增加,但不管增加多少位,2的-nn次幂怎么相加都无法得到0.1这个结果。实际上,十进制数0.1转换成二进制后,会变成0.00011001100…(1100循环)这样的循环小数[插图]。这和无法用十进制数来表示1/3是一样的道理。1/3就是0.3333…,同样是循环小数。
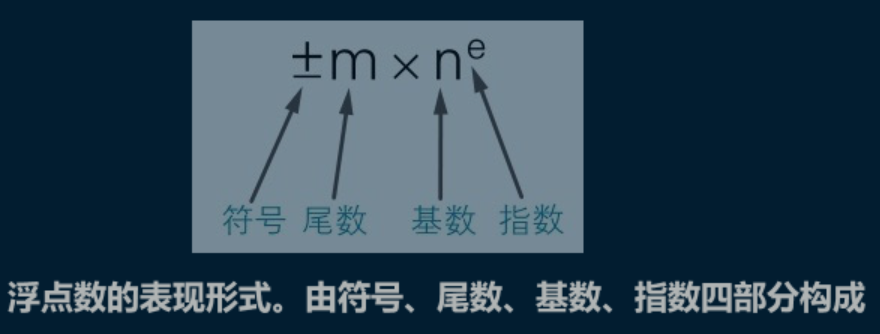
浮点数表示
1000.101 这种表达是「定点数」形式,代表着小数点是固定的,不能移动,如果你移动了它的小数点,这个数就被改变了。
然而,计算机并不是这样存储的小数的,计算机存储小数的采用的是浮点数,表示小数点是可以浮动的。
比如 1000.101 这个二进制数,可以表示成 1.000101 x 2^3,类似于数学上的科学记数法。
浮点数表达规定,要保证基数为 2,并且小数点左侧只有 1 位,且必须为 1。(即一定要表示为 1.xxx * 2^x,0.11 要表示成 1.1 * 2^-1)
现在绝大多数计算机使用的浮点数,一般采用的是 IEEE 制定的国际标准,这种标准形式如下图:

- 符号位:表示数字是正数还是负数,为 0 表示正数,为 1 表示负数;
- 指数位:指定了小数点在数据中的位置,指数可以是负数,也可以是正数,指数位的长度越长则数值的表达范围就越大;
- 尾数位:小数点右侧的数字,也就是小数部分,尾数的长度决定了这个数的精度,因此如果要表示精度更高的小数,则就要提高尾数位的长度;
用 32 位来表示的浮点数,则称为单精度浮点数,也就是编程语言中的 float 变量
用 64 位来表示的浮点数,称为双精度浮点数,也就是 double 变量
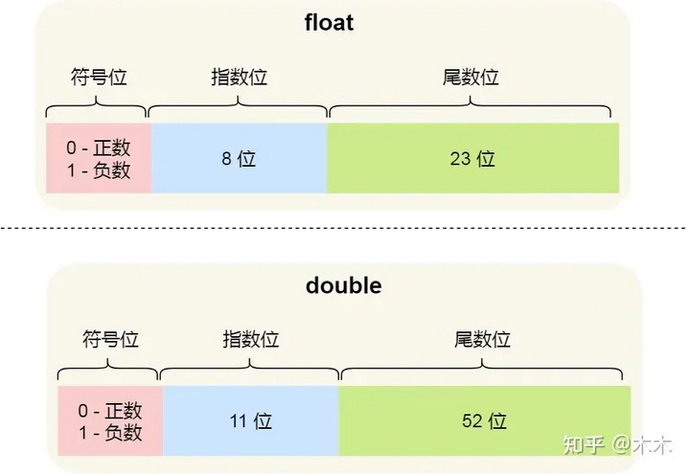
IEEE 754 里面定义了很多东西,其中包括单精度(32 bit)、双精度(64 bit)跟特殊值(无穷大、NaN)的表示方式等等
小数和浮点数的转换
十进制小数转换成浮点数二进制
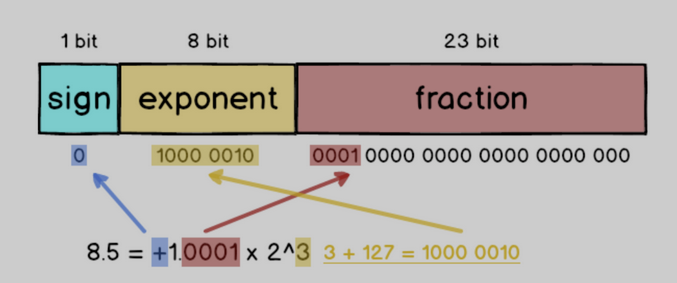
以8.5 这个符点数来说,如果要变成IEEE 754 格式的话必须先做正规化:把8.5 拆成8 + 0.5 也就是2³ + 1/2¹,接着写成二进位变成1000.1,最后再写成1.0001 x 2³,跟十进位的科学记号满像的

为什么要加偏移量?
指数可能是正数,也可能是负数,即指数是有符号的整数,而有符号整数的计算是比无符号整数麻烦的,所以为了减少不必要的麻烦,在实际存储指数的时候,需要把指数转换成无符号整数。float 的指数部分是 8 位,IEEE 标准规定单精度浮点的指数取值范围是 -126 ~ +127,于是为了把指数转换成无符号整数,就要加个偏移量,比如 float 的指数偏移量是 127,这样指数就不会出现负数了。
比如,指数如果是 8,则实际存储的指数是 8 + 127(偏移量)= 135,即把 135 转换为二进制之后再存储,而当我们需要计算实际的十进制数的时候,再把指数减去「偏移量」即可。
所以8.5转化成浮点数就如下形式
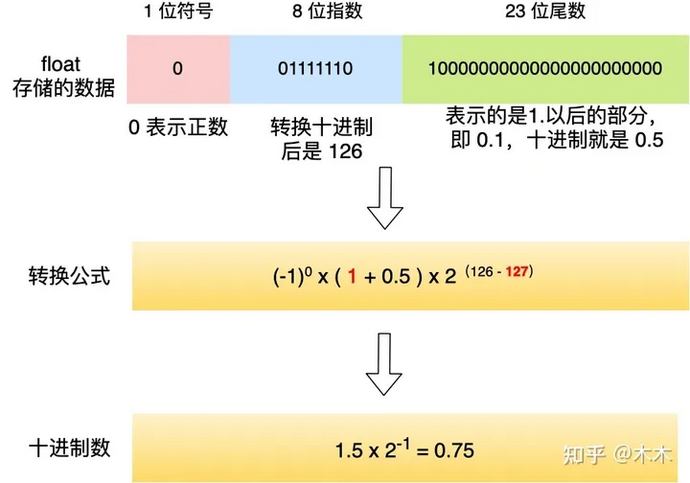
float二进制转换成十进制小数
转换公式为

比如将下面float转换成十进制小数
问题
-
什么情况下会不准呢?
刚刚8.5 的例子可以完全表示为2³+ 1/2¹,是因为8 跟0.5 刚好都是2 的次方数,所以完全不需要牺牲任何精准度
但如果是8.9 的话因为没办法换成2 的次方数相加,所以最后会被迫表示成1.0001110011… x 2³,而且还会产生大概0.0000003 的误差,好奇结果的话可以到IEEE-754 Floating Point Converter网站上玩玩看 -
为什么浮点数会有精度问题?
因为计算机使用的是二进制,而二进制并不能完整表示所有小数,对于无法完整表示的小数,只能尽量用接近值表示,所以浮点数会存在精确度问题,而且 double 类型比 float 类型更精确。 -
half
半精度,使用优势:float16和float相比恰里,总结下来就是两个原因:内存占用更少,计算更快。
内存占用更少:这个是显然可见的,通用的模型 fp16 占用的内存只需原来的一半。memory-bandwidth 减半所带来的好处:
模型占用的内存更小,训练的时候可以用更大的batchsize。
模型训练时,通信量(特别是多卡,或者多机多卡)大幅减少,大幅减少等待时间,加快数据的流通。计算更快:目前的不少GPU都有针对 fp16 的计算进行优化。论文指出:在近期的GPU中,半精度的计算吞吐量可以是单精度的 2-8 倍
半精度,缺点:
数据溢出问题
舍入误差
解决方法
既然无法避免浮点误差,那就只好跟他共处了(打不过就加入?),这边提供两个比较常见的处理方法
-
设定最大误差
在某些语言里面会提供所谓的epsilon,用来让你判断是不是在浮点误差的允许范围内,以Python 来说epsilon 的值大概是2.2e-16
所以你可以把 0.1 + 0.2 == 0.3 改写成0.1 + 0.2 — 0.3 <= epsilon,这样就能避免浮点误差在运算过程中作怪,也就可以正确比较出0.1 加0.2 是不是等于0.3 -
小数转成整数计算
本章一开头讲过的将0.1相加100次这一计算,就可以转换为将0.1扩大10倍后再将1相加100次的计算,最后把结果除以10就可以了
参考资料
https://mp.weixin.qq.com/s/NJeG76O_gbofSkA5qEnxcQ
https://zhuanlan.zhihu.com/p/544022612?utm_id=0