目录
一、知识点
1、虚拟存储
1.1、虚拟存储需求
1.2、虚拟存储的局部现象
1.3、虚拟页式存储管理
1.4、虚拟页式存储管理总流程
2、页面置换算法
2.1、页面置换算法的概念
2.2、常见的局部页面置换算法
3、虚拟存储管理实现分析
3.1、总体流程介绍
3.2、关键数据结构和相关函数分析
3.3、缺页异常处理
3.4、页面置换算法实现
二、练习解答
1、给未被映射的地址映射上物理页(需要编程)
2、补充完成基于FIFO的页面替换算法(需要编程)
一、知识点
1、虚拟存储
在电脑游戏行业中,程序规模增长速度远大于存储器容量的增长速度。其中第一代游戏437KB,而到了第八代游戏已经迅速增加到138M。正是行业的需求驱动,带来了应用程序对内存的需求。
1.1、虚拟存储需求
理想中的存储器是容量更大、速度更快、价格更便宜的非易失性存储器,然而现实的情况如下图。性能越好的存储器,价格越贵,容量越小。为了满足市场的需求,需要对存储器的性能与容量进行折中的处理。
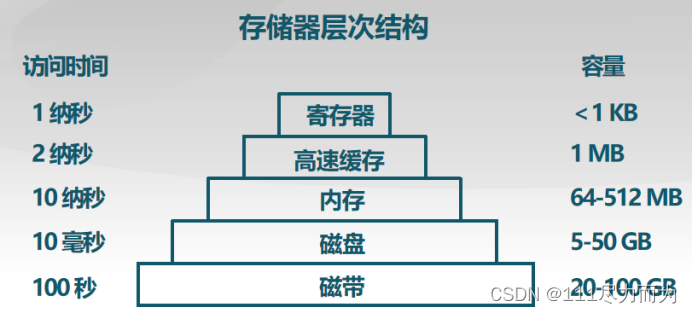
图1-1 存储器具有层次结构
此外,各个厂家的存储器略有不同,一套程序要更好的兼容硬件的差异,操作系统需要对存储器硬件进行抽象。对存储器的地址进行地址转换是一个好用的办法,下图中是不同的进程地址空间转换到物理地址空间的过程。物理地址空间中有内存的地址、磁盘的地址、寄存器、缓存的地址。物理地址空间从内存扩展到磁盘的方式,使得计算机能够在有限的内存中,装入更多更大的程序。

图1-2 进程地址转换物理地址空间
1.2、虚拟存储的局部现象
虚拟存储只把部分程序放到内存中,从而运行比物理内存更大的程序。在虚拟存储技术中,程序的换入换出是由操作系统自动完成。虚拟存储实现进程的内存与外存交换,并且只交换进程的部分内容。
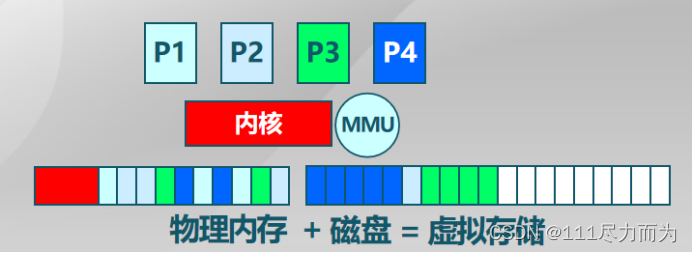
图1-3 虚拟存储的概念
为什么进行进程的部分内容交换,进程的访问速度也不会受到外存的多大影响呢?这是由于程序的局部性原理。
程序局部性原理。指的是程序在执行过程中的一个较短时期,所执行的指令地址和指令的操作数地址,分别局限于一定区域。具体来说,这是应用程序本身的特点,局限于一个区域体现在三个部分。1)时间局部性。一条指令的一次执行和下次执行,一个数据的一次访问和下次访问都集中在一个较短时期内。2)空间局部性。当前指令和邻近的几条指令,当前访问的数据和邻近的几个数据都集中在一个较小区域内。3)分支局部性。一条跳转指令的两次执行,很可能跳到相同的内存位置。
程序本身在统计意义上具有局部性,而虚拟存储基于局部内存交换,这样虚拟存储技术是能够实现的,而且可取得满意的效果。
1.3、虚拟页式存储管理
在虚拟存储中,基于程序局部原理,进行进程的部分内存的置换。具体而言,分为3个步骤:1)当用户程序要装载到内存运行时,只装入部分页面,就启动程序运行。2)进程在运行中发现有需要的代码或数据不在内存时,则向系统发出缺页异常请求。3)操作系统在处理缺页异常时,将外存中相应的页面调入内存,使得进程能继续运行。
以上的虚拟内存处理中,需要在虚拟页式存储的基础上进行。当逻辑地址(p.o)在转换的过程中,在页表中查找该地址无效,就会发生缺页异常。此时将外存中的页换入内存,然后继续执行(p,o)地址转换,能够访问到该地址物理页了。
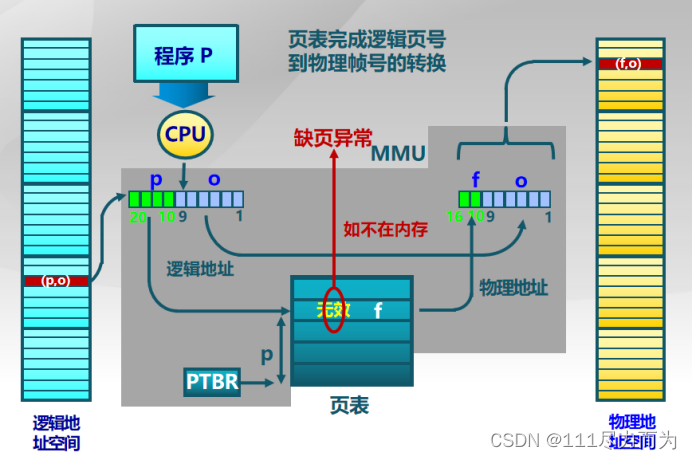
图1-4 虚拟页式存储地址转换
为了支持缺页异常,需要对页表项新增相关的信息,如下图。除了从逻辑页号i映射到物理页帧号信息外,添加了4个标志位信息。这些标志位:1)驻留位。表示该页是否在内存。1表示该页位于内存中,该页表项有效,可以使用;0表示该页当前在外存,访问该页表项将导致缺页异常。2)修改位。表示在内存中的该页是否被修改过。1表示回收该页面的时候,需要将该页写回到外存中。3)访问位。表示该页面是否被访问过(读或写),可用于页面置换算法。1表示过去一段时间被访问过。0表示过去一段时间没有被访问过。4)保护位。表示该页允许访问的方式。比如可读、可写、可执行等这些信息。
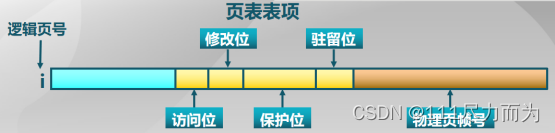
图1-5 页表项标志位
根据上面的分析,在X86中,针对虚拟存储对页表项进行了扩展,扩展信息如下:
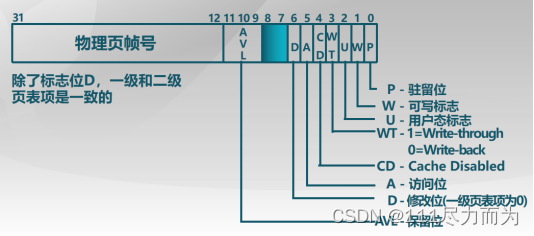
图1-6 X86页表项标志位
1.4、虚拟页式存储管理总流程
虚拟存储的关键技术是通过缺页处理完成的,对于缺页异常距离描述如下:
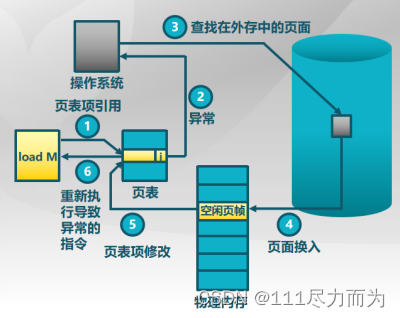
图1-7 虚拟存储缺页异常处理流程
第0步,CPU访问指令load M。
第1步,CPU查找这条指令m对应的页表项。
第2步,如果这个页表项驻留位是1(有效),则直接访问内存;否则无效,产生缺页异常。
第3步,操作系统程序查找外存中的页面x。
第4步,页面换入换出。如果外存页x找到了,就需要把这一页读到内存中。这个处理的流程如下,如果内存有空闲页,执行A+E+F;如果没有空闲页,执行B+C+D+E+F。

第5步,页表项修改。该步骤与第4步存在流程重叠的地方,因此可以与第4步合并在一起执行。
第6步,重新执行导致异常的指令。在第4、5步中,页面已经换入换出,并且修改完成了相应的标志位了。
虚拟页式存储中外存管理。在以上的流程中,在哪里保存没有被映射的页呢?所设计的外存页管理中,应该能够方便的找到外存中的页面内容,在Linux中保存在交换空间中。对于代码段,外存在可执行二进制文件中。对于动态加载的共享库程序段,外存在动态调用的库文件。对于不是以上的其他段,外存采用交换空间存储。
2、页面置换算法
2.1、页面置换算法的概念
页面置换算法的功能和目标。页面置换算法的功能是当出现缺页异常,需调入新页面而内存已满时,置换算法选择被置换的物理页面。页面置换算法的目标是尽可能减少页面的调入调出次数,未来不再访问或短期内不访问的页面调出。在这个目标中,对未来的估计和对短期不访问的估计是需要更多的考虑的。
页面锁定是虚拟存储当中一个概念,指的是有些页面是不可以置换到外存中。比如必须常驻内存的逻辑页面、操作系统的关键部分、要求响应速度的代码和数据。对于这样的一些页面,需要在页表中增加一个锁定标志位。
页面置换算法的评估。首先需要记录进程访问内存的页面轨迹,针对某个页面置换算法,模拟页面置换行为,记录产生缺页的次数。那么更好的缺页次数,页面置换算法的能力就更强。
页面置换算法的分类。页面置换算法分成局部页面置换算法和全局页面置换算法。局部页面置换算法指的是换页面的选择范围仅限于当前进程占用的物理页面内,而全局页面置换算法指的是置换页面的选择范围是所有可换出的物理页面。
常见的局部页面置换算法有最优算法、先进先出算法、最近最久未使用算法、时钟算法、最不常用算法。
常见的全局页面置换算法有工作集算法、缺页率算法。
2.2、常见的局部页面置换算法
对于局部页面置换算法,是指每个进程的物理页已经分配固定了,不能动态的变动。其中最优页面置换算法是理想解,先进先出算法复杂度以及内存开销最低。而最近最久不使用算法是对最优页面置换算法的一种近似求解,而时钟置换算法是最优置换算法和先进先出算法的折中。
最优页面置换算法。它的基本思路是置换未来最长时间不访问的页面。算法的实现是1)缺页的时候计算内存中每个逻辑页面下次的访问时间。2)选择未来最长时间不访问的页面。
由于无法预知每个页面在下次访问前的等待时间,最优页面置换算法在实际系统中无法实现,然而它可以作为其他算法的评价依据。评价方法是这样子的,1)在模拟器上运行某个程序,并记录每一次的页面访问情况。2)第二遍运行时使用最优算法。这样得到的页面置换序列就是最优的置换序列。
以下是最优页面置换算法的举例,该算法在分配4个物理页面的时候,最理想的情况下出现两次缺页。
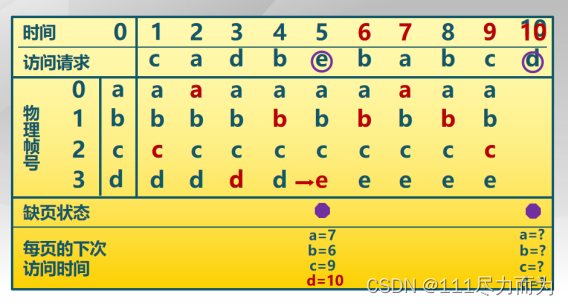
图2-1 最优页面置换算法举例
先进先出算法。它的基本思路是选择在内存驻留时间最长的页面进行置换。算法的实现是1)维护一个记录所有位于内存中的逻辑页面链表。2)链表元素按驻留内存的时间排序,链首最长,链尾最短。3)出现缺页时,选择链首页面进行置换,新页面加到链尾。
这种算法实现简单,缺点是性能较差,调出的页面可能是经常访问的。还有一个缺点是进程分配物理页面数增加时,缺页并不一定减少。
最近最久不使用算法。正是由于对进程未来的页面使用情况无法估计,那么选择近似估计的方式,近似的方式是置换过去最长时间不访问的页面。算法的实现是1)缺页时,计算内存中每个逻辑页面的上一次访问时间。2)选择上一次使用到当前时间最长的页面。
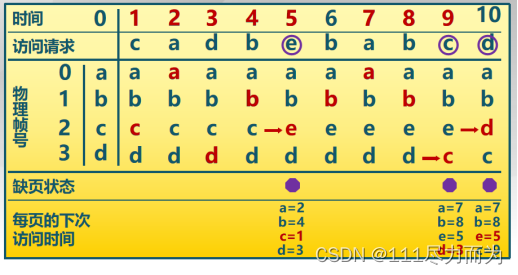
图2-2 最近最久不使用算法举例
在具体实现中,使用了活动页面栈。访问页面时,将此页号压入栈顶,并栈内相同的页号抽出。缺页时,置换栈底的页面。
最近最近不使用算法仍然开销大,主要是需要计算每个逻辑页面上次访问的时间,此外还要维护栈的数据结构。
时钟置换算法。它的基本思路是仅仅对页面的使用情况进行大致的统计,即设置访问位,若是1表示访问过,否则0表示没有访问过。没有访问过的页面可以被置换掉。算法的实现是1)页面装入内存时,访问位初始化为0。2)访问页面(读/写)时,访问位置1。3)缺页时,从指针当前位置顺序检查环形链表。访问位为0,则置换该页。访问位为1,则访问位置0,并指针移动到下一个页面,直到找到可置换的页面。
时钟置换算法使用了环形链表这种数据结构,指针指向的是最先调入的界面,页表项中加了一位,表示过去一段时间的访存情况。
时钟置换算法是LRU和FIFO算法的折中,它对过去的访问情况做了统计,但是不像LRU统计的那么详细,也不像FIFO那样对过去的访问情况完全不考虑。
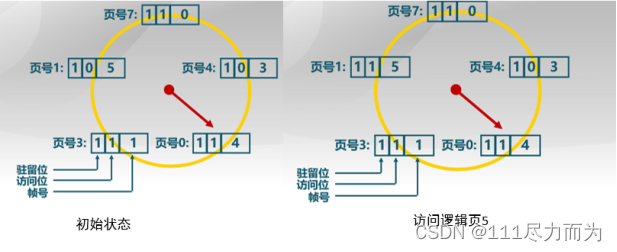
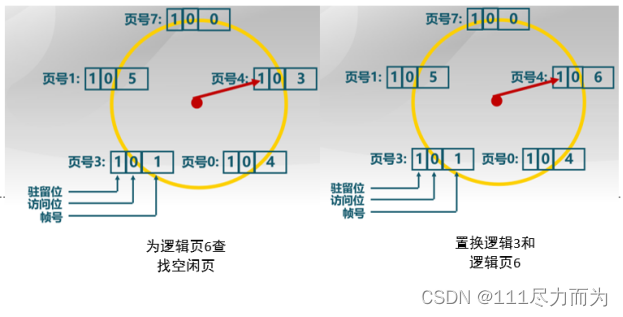
图2-3 时钟置换算法举例
在时钟置换算法举例中,初始化状态指针指向页号0,且给定其他的页号状态,即0/1/3/4/5逻辑页面驻留内存。当访问逻辑页5时,逻辑页5在内存中,此时将访问位设置成1。当要访问逻辑页6时,逻辑页6不在内存中,发生缺页中断。指针从页号0循环查找,访问位是1,则访问位置0,直到找到可以置换的页面。当找到可置换的页面时,页号4中的逻辑页3变更成逻辑页6(置换),此时不会设置访问位。
3、虚拟存储管理实现分析
在本章中主要介绍虚拟存储管理的实验,关注的是实验细节和原理之间是如何对应上的。
3.1、总体流程介绍
虚存管理总体框架流程如下:
1)完成初始化虚拟内存管理机制:IDE 硬盘读写,缺页异常处理
2)设置虚拟页空间和物理页帧空间,表述不在物理内存中的“合法”虚拟页
3)完善建立页表映射、页访问异常处理操作等函数实现
4)执行访存测试,查看建立的页表项是否能够正确完成虚实地址映射
5)执行访存测试,查看是否正确描述了虚拟内存页在物理内存中还是在硬盘上
6)执行访存测试,查看是否能够正确把虚拟内存页在物理内存和硬盘之间进行传递
7)执行访存测试,查看是否正确实现了页面替换算法等
首先是初始化的工作,在kern_init()函数中,依次调用pmm_init()、pic_init()、idt_init()函数。其中pmm_init()是初始化物理内存,用一个数组存储物理页的开始位置和大小,这样方便索引查询物理页并使用。
【pmm_init()函数解读】
关于page_init()做进一步的解释,程序中会探测到memmap->nr_map个不连续的物理内存块,这些内存块的开始地址是memmap->map[i].addr,大小是memmap->map[i].size。这些物理内存存放在内核的数组中,以供索引查询并使用(申请、释放),这是怎么做到的?
首先,内核的物理页存放开始位置是end,在kernel.ld代码中定义。
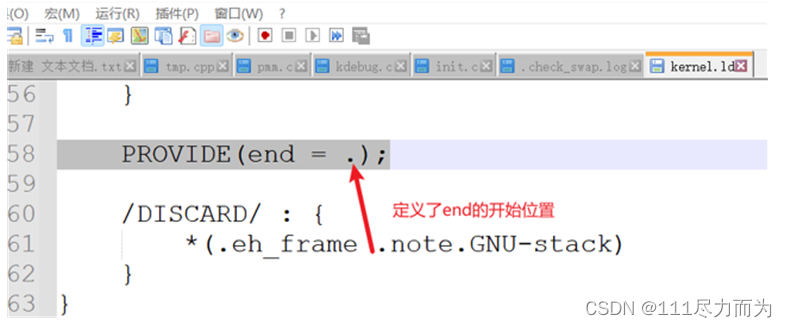
图3-1 定义内核物理页存放位置
然后,page_init()通过如下的指令将end为开始地址的内存转换成数组pages,有关pages的存储结构如下,每个pages的结构采用24字节记录。
pages = (struct Page *)ROUNDUP((void *)end, PGSIZE);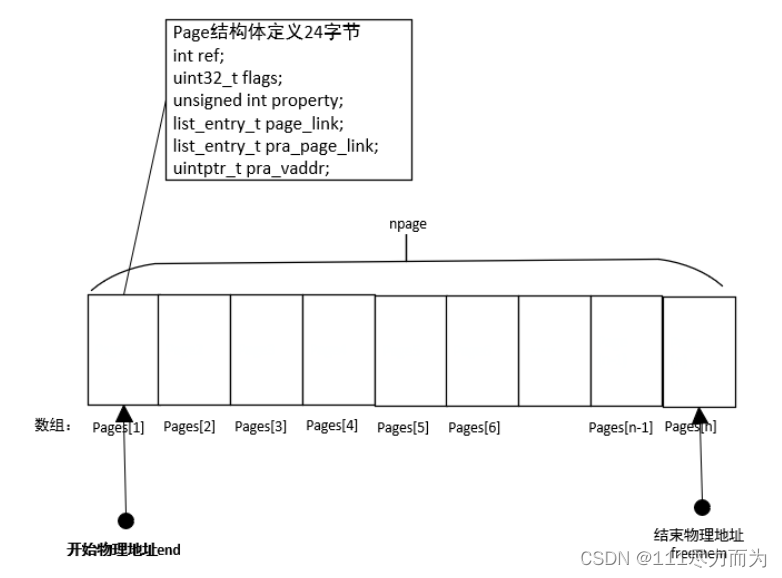
图3-2 pages数据解释
在ucore的pages数组中,一共有多少页呢?页的个数计算代码如下:
int i;
for (i = 0; i < memmap->nr_map; i ++) {
uint64_t begin = memmap->map[i].addr, end = begin + memmap->map[i].size;
cprintf(" memory: %08llx, [%08llx, %08llx], type = %d.\n",
memmap->map[i].size, begin, end - 1, memmap->map[i].type);
if (memmap->map[i].type == E820_ARM) {
if (maxpa < end && begin < KMEMSIZE) {
maxpa = end;
}
}
}
if (maxpa > KMEMSIZE) {
maxpa = KMEMSIZE;
}
npage = maxpa / PGSIZE;实际上,e820map的内存分布如下,ucore的虚拟存储中,采用的type=1。通过上面的代码可以计算maxpa=07ffd000,那么上图的npage=0x7FFD。当然0x9F+0x7EFD=0x7F9C<npage,这表明pages数组中间有空闲的页不能被用到。
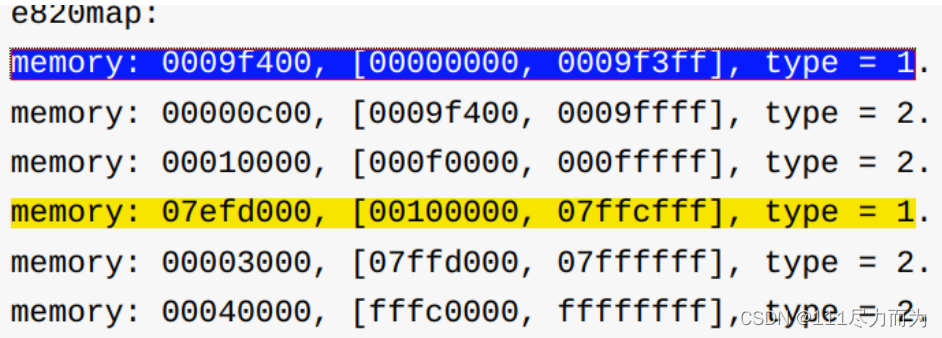
图3-3 ucore的e820map
接下来是物理内存[00000000,0009f3ff]、[00100000,7ffcfff]是如何放在内核的数组中,以供索引查询并使用(申请、释放)?这是因为pages是一个数组,严格的与物理内存的地址具有线性关系。正是这种线性关系,使得申请或释放某个物理内存能够映射到pages中。举个例子,在pages_inits()函数中,有如下含义。从e820map中拿到的物理地址pa,经过pages[PPN(pa)]的地址转换,寻址到了pages中某项。当la是0x00100000的时候,它找到了pages[0x100]项,pages[0x100].property=0x7efd,即该项后的0x7efd项是空闲的。
//pmm.h文件中 virtual address of physicall page array
struct Page *pages;//放在内存中的
static inline struct Page *
pa2page(uintptr_t pa) {
if (PPN(pa) >= npage) {
panic("pa2page called with invalid pa");
}
return &pages[PPN(pa)];
}
//pmm.c文件中
uint64_t begin = memmap->map[i].addr
begin = ROUNDUP(begin, PGSIZE);//物理地址
struct Page *p = pa2page(begin);
init_memmap(pa2page(begin), (end - begin) / PGSIZE);【pic_init()函数解读】
pic_init()函数初始化8259A中断控制器,8259A芯片是一个中断管理芯片,中断的来源除了来自于硬件自身的NMI中断和来自于软件的INT n指令造成的软件中断之外,还有来自于外部硬件设备的中断,这些中断是可屏蔽的。这些中断也都通过可编程中断控制器PIC(Programmable Interrupt Controller)进行控制,并传递给CPU。
【idt_init()函数解读】
初始化中断描述符表,即初始化kern/trap/vectors.S中的每一个entry points。更详细的解释在实验1中可以找到解读。
对于初始化工作,在kern_init()函数中,依次调用vmm_init()、ide_init()、swap_init()函数。
【vmm_init()函数解读】
虚拟页式存储管理概念见1.3.虚拟页式存储管理,在这节的介绍中,有两个关键点是需要工程实现的:1)缺页机制。2)合法的虚拟页表示。为了表示不在物理内存中的“合法”虚拟页,需要有数据结构来描述这样的页,为此ucore建立了mm_struct和vma_struct数据结构。假定我们已经描述好了这样的“合法”虚拟页,当ucore访问这些”“合法”虚拟页时,会由于没有虚实地址映射而产生页访问异常。,则do_pgfault函数会申请一个空闲物理页,建立好虚实映射关系,从而使得这样的“合法”虚拟页有实际的物理页帧对应。
vmm_init()函数主要的功能是检查虚拟内存管理的正确性,即函数check_vmm()。在check_vmm函数中,调用了check_vma_struct()函数和check_pgfault()函数。其中check_vma_struct()检查的是为了虚拟内存地址管理,构建的数据结构是不是能够产生“合法”的虚拟页,用如下的图解释。在CPU访问虚拟内存空间的时候,如果存在虚实映射,那么访存成功;如果不存在虚实映射关系,就产生缺页中断,从而调用do_pgfault()函数,申请一个空闲的物理页,建立好虚实映射关系。
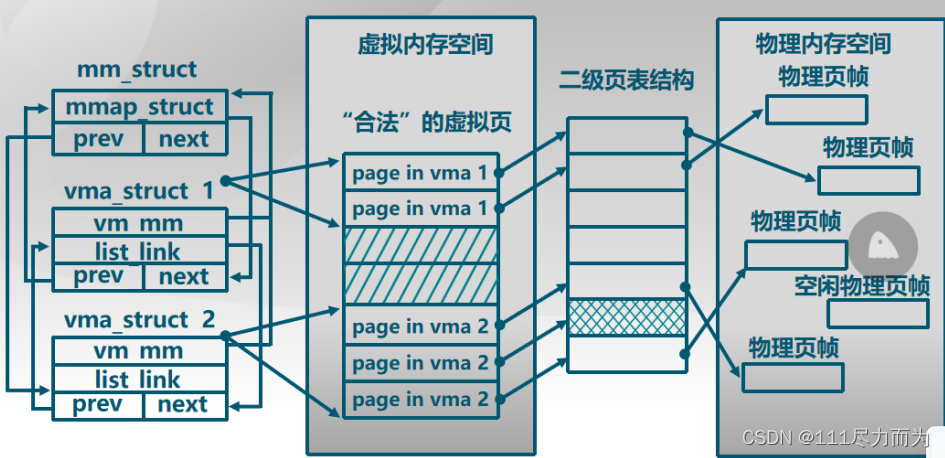
图3-4 虚拟内存管理的合法虚拟页
check_vma_struct()函数。在这个函数中,存在两种数据结构,mm_struct数据结构和vma_struct数据结构。mm_struct定义了mm,代表了所有虚拟内存管理的总入口。mm中含有多个vma,表示具有若干个连续地址空间的虚拟存储块。check_vma_struct的处理逻辑如下,从这个逻辑中可以看出,主要是为了验证mm_struct/vma_struct数据结构能不能表示虚拟内存的创建、查找、删除。

图3-5 check_vma_struct处理逻辑
check_pgfault()函数。在这个函数中,会创建一个应用程序的虚拟内存管理器check_mm_struct。该应用程序的虚拟管理器是一个共享的结构,会被当前的内核线程和缺页处理函数do_pgfault共享。然后设置该虚拟内存管理器的一级页表boot_pgdir,这样程序可以执行页机制了。之后创建一个0~4M的可写的vma,并添加到该程序的虚拟内存管理器check_mm_struct中。当程序对虚拟地址(0x100+i)进行写操作,对虚拟地址(0x100+i)进行读操作,此时页机制已经生效了。当缺页发生时,进入do_pgfault()函数处理。当do_do_pgfault()函数处理完成后,就会退出中断处理程序,恢复进入check_pgfault()函数。有关check_pgfault()函数处理逻辑如下。
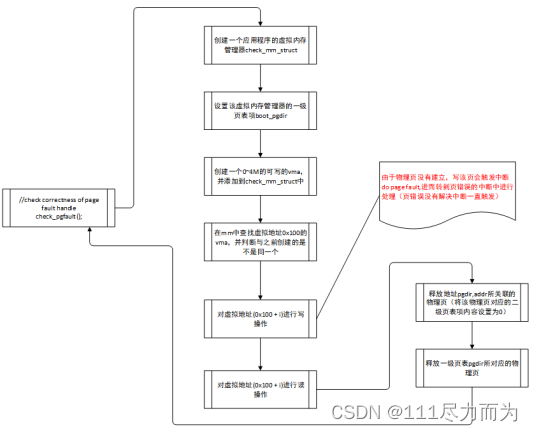
图3-6 check_pgfault处理逻辑
do_pgfault()函数。在这个函数中有三个功能,第一个功能是在check_mm_struct中查找是否存在逻辑地址addr的vma,如果不存在表示非法的,那么缺页失败。第二个功能是通过错误码error_code检查程序的可读、可写、可执行的状态,若状态非法,那么缺页失败。第三个功能是正常的缺页异常处理逻辑,将物理页置换到内存中。
3.2、关键数据结构和相关函数分析
在实验二中有关内存的数据结构和相关的操作都是直接针对物理内存空间的管理,没有从一般的应用程序对内存的“需求”考虑,即需要相关的数据结构和操作来体现一般应用程序对虚拟内存的“需求”。一般的应用程序对虚拟内存的“需求”与物理内存空间的“供给”没有直接的对应关系,ucore是通过page_fault异常处理来间接完成二者之间的衔接。为此ucore通过建立mm_struct和vma_struct数据结构,描述了ucore模拟应用程序运行所需的合法内存空间。当访问内存产生pagefault异常时,可获得访问的内存的方式(读或写)以及具体的虚拟内存地址,这样ucore就可以查询此地址,看是否属于vma_struct数据结构中描述的合法地址范围中,如果在,则可根据具体情况进行请求调页/页换入换出处(这就是练习2涉及的部分);如果不在,则报错。
在ucore中描述应用程序对虚拟内存“需求”的数据结构是vma_struct(定义在vmm.h中),以及针对vma_struct的函数操作。这里把一个vma_struct结构的变量简称为vma变量。
vma_struct的定义如下:
// the virtual continuous memory area(vma), [vm_start, vm_end),
// addr belong to a vma means vma.vm_start<= addr <vma.vm_end
struct vma_struct {
struct mm_struct *vm_mm; // the set of vma using the same PDT
uintptr_t vm_start; // start addr of vma
uintptr_t vm_end; // end addr of vma, not include the vm_end itself
uint32_t vm_flags; // flags of vma
list_entry_t list_link; // linear list link which sorted by start addr of vma
};vm_start和vm_end描述了一个连续地址的虚拟内存空间的起始位置和结束位置,这两个值都应该是PGSIZE对齐的,而且描述的是一个合理的地址空间范围(即严格确保vm_start<vm_end的关系);list_link是一个双向链表,按照从小到大的顺序把一系列用vma_struct表示的虚拟内存空间链接起来,并且还要求这些链起来的vma_struct是不相交的,即vma之间的地址空间无交集;vm_flags表示了这个虚拟内存空间的属性,目前的属性包括:
#define VM_READ 0x00000001 //只读
#define VM_WRITE 0x00000002 //可读写
#define VM_EXEC 0x00000004 //可执行vm_mm是一个指针,指向一个比vma_struct更高的抽象层次的数据结构mm_struct,这里把一个mm_struct结构的变量简称为mm变量。这个数据结构表示了包含所有虚拟内存空间的共同属性,具体定义如下:
// the control struct for a set of vma using the same PDT
struct mm_struct {
list_entry_t mmap_list; // linear list link which sorted by start addr of vma
struct vma_struct *mmap_cache; // current accessed vma, used for speed purpose
pde_t *pgdir; // the PDT of these vma
int map_count; // the count of these vma
void *sm_priv; // the private data for swap manager
};mmap_list是双向链表头,链接了所有属于同一页目录表的虚拟内存空间,mmap_cache是指向当前正在使用的虚拟内存空间,由于操作系统执行的“局部性”原理,当前正在用到的虚拟内存空间在接下来的操作中可能还会用到,这时就不需要查链表,而是直接使用此指针就可找到下一次要用到的虚拟内存空间。由于mmap_cache的引入,可使得mm_struct数据结构的查询加速30%以上。pgdir所指向的就是mm_struct数据结构所维护的页表。通过访问pgdir关键数据结构和相关函数分析,可以查找某虚拟地址对应的页表项是否存在以及页表项的属性等。map_count记录mmap_list里面链接的vma_struct的个数。sm_priv指向用来链接记录页访问情况的链表头,这建立了mm_struct和后续要讲到的swap_manager之间的联系。
涉及vma_struct的操作函数也比较简单, 主要包括三个:
- vma_create--创建vma
- insert_vma_struct--插入一个vma
- find_vma--查询vma。
vma_create函数根据输入参数vm_start、vm_end、vm_flags来创建并初始化描述一个虚拟内存空间的vma_struct结构变量。insert_vma_struct函数完成把一个vma变量按照其空间位置[vma->vm_start,vma->vm_end]从小到大的顺序插入到所属的mm变量中的mmap_list双向链表中。find_vma根据输入参数addr和mm变量,查找在mm变量中的mmap_list双向链表中某个vma包含此addr,即vma->vm_start<=addrend。
涉及mm_struct的操作函数比较简单,只有mm_create和mm_destroy两个函数,从字面意思就可以看出是是完成mm_struct结构的变量创建和删除。在mm_create中用kmalloc分配了一块空间,所以在mm_destroy中也要对应进行释放。在ucore运行过程中,会产生描述虚拟内存空间的vma_struct结构,所以在mm_destroy中也要进对这些mmap_list中的vma进行释放。
3.3、缺页异常处理
当启动分页机制以后,如果一条指令或数据的虚拟地址所对应的物理页框不在内存中或者访问的类型有错误(比如写一个只读页或用户态程序访问内核态的数据等),就会发生页访问异常。产生页访问异常的原因主要有:
- 目标页帧不存在(页表项全为0,即该线性地址与物理地址尚未建立映射或者已经撤销);
- 相应的物理页帧不在内存中(页表项非空,但Present标志位=0,比如在swap分区或磁盘文件上),这在本次实验中会出现,我们将在下面介绍换页机制实现时进一步讲解如何处理;
- 不满足访问权限(此时页表项P标志=1,但低权限的程序试图访问高权限的地址空间,或者有程序试图写只读页面)
当出现上面情况之一,那么就会产生页面pagefault(#PF)异常。CPU会把产生异常的线性地址存储在CR2中,并且把表示页访问异常类型的值(简称页访问异常错误码,errorCode)保存在中断栈中。
当出现上面情况之一,那么就会产生页面pagefault(#PF)异常。CPU会把产生异常的线性地址存储在CR2中,并且把表示页访问异常类型的值(简称页访问异常错误码,errorCode)保存在中断栈中。
CR2是页故障线性地址寄存器,保存最后一次出现页故障的全32位线性地址。CR2用于发生页异常时报告出错信息。当发生页异常时,处理器把引起页异常的线性地址保存在CR2中。操作系统中对应的中断服务例程可以检查CR2的内容,从而查出线性地址空间中的哪个页引起本次异常。
页访问异常错误码有32位。位0为1表示对应物理页不存在;位1为1表示写异常(比如写了只读页;位2为1表示访问权限异常(比如用户态程序访问内核空间的数据)。错误码的格式如下:
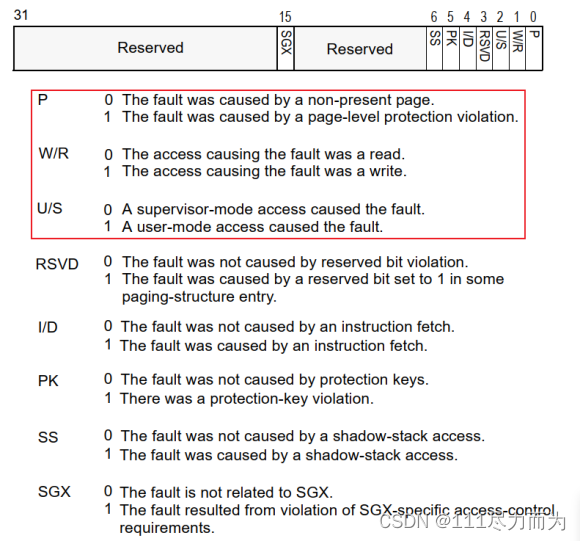
图3-7 Page-Fault Error Code
产生页访问异常后,CPU硬件和软件都会做一些事情来应对此事。首先页访问异常也是一种异常,所以针对一般异常的硬件处理操作是必须要做的,即CPU在当前内核栈保存当前被打断的程序现场,即依次压入当前被打断程序使用的EFLAGS,CS,EIP,errorCode;由于页访问异常的中断号是0xE,CPU把异常中断号0xE对应的中断服务例程的地址(vectors.S中的标号vector14处)加载到CS和EIP寄存器中,开始执行中断服务例程。这时ucore开始处理异常中断,首先需要保存硬件没有保存的寄存器。在vectors.S中的标号vector14处先把中断号压入内核栈,然后再在trapentry.S中的标号__alltraps处把DS、ES和其他通用寄存器都压栈。自此,被打断的程序执行现场(context)被保存在内核栈中。接下来,在trap.c的trap函数开始了中断服务例程的处理流程,大致调用关系为:
trap--> trap_dispatch-->pgfault_handler-->do_pgfault

图3-8 页访问异常的流程
当页访问异常是一次合法的访问,只是没有建立虚实映射关系。所以需要分配一个空闲的内存页,并修改页表完成虚拟地址到物理地址的映射,刷新TLB,然后调用iret中断,返回到产生页访问异常的指令处重新执行此指令。
3.4、页面置换算法实现
如果想要实现页面置换机制,仅凭页面置换算法在操作系统实践中是远远不够的。还需要考虑其他的问题:
- 哪些页可以被置换
- 虚拟页如何与硬盘扇区建立联系
- 何时换入换出
- 如何设计数据结构以支持页替换算法
- 如何完成页的换入换出
1)可以被换出的页
在操作系统设计中,一个基本的原则是:不是所有的物理页都可以交换出去,只有映射到用户空间且被用户程序直接访问的页才能被交换。但是在实验三中,我们只是实现了换入换出机制,还没有设计用户态执行的程序。因此我们用check_swap()函数在内核中分配一些页,模拟对这些页的访问。
虚存中页与硬盘上的扇区之间的映射关系
如果一个页被置换到了硬盘上,那么操作系如何能简单的表示这种情况呢?在ucore的设计上,充分的利用页表中的PTE来表示这种情况:当一个PTE用于表示一般意义上的物理页时,显然它应该维护各种权限和映射关系,以及应该有的PTE_P标记;但是当它用来描述一个被置换出去的物理页时,它被用来维护该物理页与swap磁盘上扇区的映射关系,并且该PTE不该由MMU解释成物理页映射(即没有PTE_P标记),与此同时对应的权限交给mm_struct来维护。当对该页的内存地址访问的时候,必然导致page_fault,然后ucore能够根据PTE描述的swap项目将相应的物理页重新建立起来,并根据虚拟存储所描述的权限重新设置号PTE使得内存访问能够正常进行。
如果一个页(4KB/页)被置换到了硬盘某8个扇区(0.5KB/扇区),该PTE的最低位--present位应该为0(即PTE_P标记为空,表示虚实地址映射关系不存在),接下来的7位暂时保留,可以用作各种扩展;而原来用来表示页帧号的高24位地址,恰好可以用来表示此页在硬盘上的起始扇区的位置(其从第几个扇区开始)。为了在页表项中区别0和swap分区的映射,将swap分区的一个page空出来不用,也就是说一个高24位不为0,而最低位为0的PTE表示了一个放在硬盘上的页的起始扇区号(见swap.h中对swap_entry_t的描述):
/* *
* swap_entry_t
* --------------------------------------------
* | offset | reserved | 0 |
* --------------------------------------------
* 24 bits 7 bits 1 bit
* */考虑到硬盘的最小访问单位是一个扇区,而一个扇区的大小是512字节,所以需要8个连续扇区才能放置一个4KB的页。在ucore中,用了第一个IDE硬盘来保存被换出的扇区,根据实验的输出信息
“ide 1: 262144(sectors), 'QEMU HARDDISK'.”
我们可以知道实验三可以保存262144/8=32768个页,即128M的内存空间。swap分区的大小是swapfs_init里面根据磁盘驱动的接口计算出来的,目前ucore里面要求swap磁盘至少包含1000个page,并且至多能使用1<<24个page。
在虚拟页与扇区建立映射关系中,ide_init完成对扇区的初始化,通过ide_init函数获取磁盘的扇区序号、大小,有关ide_init的流程如下:
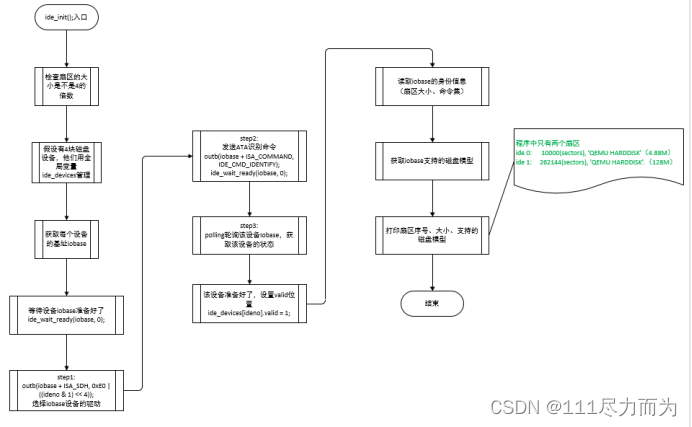
图3-9 ide_init流程
在ide_init函数中,使用了inb/outb指令,这两条指令是对计算机的I/O进行输出输出操作的指令。
//从端口port中输入一个字节的数据data
static inline uint8_t
inb(uint16_t port) {
uint8_t data;
asm volatile ("inb %1, %0" : "=a" (data) : "d" (port) : "memory");
return data;
}
//向端口port输出一个字节的数据data
static inline void
outb(uint16_t port, uint8_t data) {
asm volatile ("outb %0, %1" :: "a" (data), "d" (port) : "memory");
}在虚拟页与扇区建立映射关系中,swap_init函数主要的功能是初始化128M的交换分区1。一页换算成扇区作为单位,交换分区一共能表示多少页max_swap_offset = ide_device_size(SWAP_DEV_NO) / (PGSIZE / SECTSIZE);这个磁盘空间一共有32768页可用;初始化页换入换出算法,sm = &swap_manager_fifo;;换入换出的算法初始化完成后, 就检查换入换出是否达到了效果check_swap();。
当ucore或者应用程序访问的页不存在时,就会产生page fault异常,引起调用do_pgfault函数,此函数会判断产生访问异常的地址属于check_mm_struct某个vma表示的合法地址空间,且保存在硬盘swap文件中(即对于的PTE高24位不是0,而最低位是0),执行页换入的时机,调用swap_in函数完成页面换入。
ucore采用消极的换出策略,只是当试图得到空闲页时, 发现当前没有空闲的物理页可供分配, 这时才开始查找“不常用”页面, 并把一个或多个这样的页换出到硬盘上。
4)fifo置换算法
到实验二为止,物理页的使用情况是基于数据结构Page的全局变量pages,pages的每一项表示了计算机中一个物理页的使用情况。为了表示物理页的换入换出情况,可以对Page进行扩展:
struct Page {
......
list_entry_t pra_page_link; // used for pra (page replace algorithm)
uintptr_t pra_vaddr; // used for pra (page replace algorithm)
};pra_page_link可用来构造按页的第一次访问时间进行排序的一个链表,这个链表的开始表示第一次访问时间最近的页,链表结尾表示第一次访问时间最远的页。当然链表头可以设置位pra_list_head(定义在swap_fifo.c中),构造的时机是在page_fault发生后,进行do_pgfault函数时。pra_vaddr可以用来记录此物理页对应的虚拟页开始地址。
当一个物理页需要被swap出去,首先确保它已经分配了一个位于磁盘的swap page(由连续的8扇区组成)。这里为了简化设计,在swap_check函数中建立每个虚拟页唯一对应的swap page,其对应关系设定:虚拟页对应PTE的索引值=swap page的扇区开始位置*8。
为了实现各种页替换算法,我们设计了一个页替换算法的框架类swap_manager:
struct swap_manager
{
const char *name;
/* Global initialization for the swap manager */
int (*init) (void);
/* Initialize the priv data inside mm_struct */
int (*init_mm) (struct mm_struct *mm);
/* Called when tick interrupt occured */
int (*tick_event) (struct mm_struct *mm);
/* Called when map a swappable page into the mm_struct */
int (*map_swappable) (struct mm_struct *mm, uintptr_t addr, struct Page *page, int swap_in);
/* When a page is marked as shared, this routine is called to
* delete the addr entry from the swap manager */
int (*set_unswappable) (struct mm_struct *mm, uintptr_t addr);
/* Try to swap out a page, return then victim */
int (*swap_out_victim) (struct mm_struct *mm, struct Page **ptr_page, int in_tick);
/* check the page relpacement algorithm */
int (*check_swap)(void);
};在这里有两个关键的函数指针map_swappable和swap_out_vistim,前一个记录页访问情况,后一个函数用于挑选需要换出的页。显然第二个函数依赖第一个函数的记录页访问情况。tick_event函数页非常重要,结合定时产生的中断,可以实现一个积极的换页策略。
5)check_swap()检查
- 调用mm_create建立mm变量,并调用vma_create创建vma变量,设置合法的访问范围为4KB~24KB;
- 调用free_page等操作,模拟形成一个只有4个空闲physicalpage;并设置了从4KB~24KB的连续5个虚拟页的访问操作;
- 设置记录缺页次数的变量pgfault_num=0,执行check_content_set函数,使得起始地址分别对起始地址为0x1000,0x2000,0x3000,0x4000的虚拟页按时间顺序先后写操作访问,由于之前没有建立页表,所以会产生pagefault异常,如果完成练习1,则这些从4KB~20KB的4虚拟页会与ucore保存的4个物理页帧建立映射关系;
- 然后对虚页对应的新产生的页表项进行合法性检查;
- 然后进入测试页替换算法的主体,执行函数check_content_access,并进一步调用到_fifo_check_swap函数,如果通过了所有的assert。这进一步表示FIFO页替换算法基本正确实现;
- 最后恢复ucore环境
check_swap()模拟了CHECK_VALID_PHY_PAGE_NUM=4页的访问,先是通过alloc_page()/free_pages()/check_rp[]模拟了物理内存的分配和释放的过程。然后check_content_set()函数中写0x1000~0x4010的虚拟地址,从而触发缺页中断,来检测缺页处理数目pgfault_num是否正确。在缺页处理完成后,4个物理页建立了与虚拟地址0x1000~0x4010之间的映射关系。因此可以通过获取当前的虚拟地址页表项,并放在页表项的检查目录check_ptep[]中。由于之前已经记录了4页的物理页分配过程,理论上应该与缺页处理的页是一样的顺序。所以就可以执行指令assert(pte2page(*check_ptep[i]) == check_rp[i])。
解析来检查页替换算法,同样的是对不同的虚拟地址进行写操作,检查缺页出现的次数是否符合算法预期。实验三的页替换算法检查函数在_fifo_check_swap()中实现。
在check_swap()函数结束了对页表项访问顺序的检查(即检查check_ptep[i])、也替换算法的检查(即检查pgfault_num出现的次数是否符合预期)。就对当前的内存进行释放,释放check_rp[i]、mm。
二、练习解答
1、给未被映射的地址映射上物理页(需要编程)
完成do_pgfault(mm/vmm.c)函数,给未被映射的地址映射上物理页。设置访问权限的时候需要参考页面所在VMA的权限,同时需要注意映射物理页时需要操作内存控制结构所指定的页表,而不是内核的页表。
int
do_pgfault(struct mm_struct *mm, uint32_t error_code, uintptr_t addr) {
int ret = -E_INVAL;
//try to find a vma which include addr
struct vma_struct *vma = find_vma(mm, addr);
pgfault_num++;
//If the addr is in the range of a mm's vma?
if (vma == NULL || vma->vm_start > addr) {
cprintf("not valid addr %x, and can not find it in vma\n", addr);
goto failed;
}
//check the error_code
switch (error_code & 3) {
default:
/* error code flag : default is 3 ( W/R=1, P=1): write, present */
case 2: /* error code flag : (W/R=1, P=0): write, not present */
if (!(vma->vm_flags & VM_WRITE)) {
cprintf("do_pgfault failed: error code flag = write AND not present, but the addr's vma cannot write\n");
goto failed;
}
break;
case 1: /* error code flag : (W/R=0, P=1): read, present */
cprintf("do_pgfault failed: error code flag = read AND present\n");
goto failed;
case 0: /* error code flag : (W/R=0, P=0): read, not present */
if (!(vma->vm_flags & (VM_READ | VM_EXEC))) {
cprintf("do_pgfault failed: error code flag = read AND not present, but the addr's vma cannot read or exec\n");
goto failed;
}
}
/* IF (write an existed addr ) OR
* (write an non_existed addr && addr is writable) OR
* (read an non_existed addr && addr is readable)
* THEN
* continue process
*/
uint32_t perm = PTE_U;
if (vma->vm_flags & VM_WRITE) {
perm |= PTE_W;
}
addr = ROUNDDOWN(addr, PGSIZE);
ret = -E_NO_MEM;
pte_t *ptep=NULL;
#if 1
/*LAB3 EXERCISE 1: YOUR CODE
* Maybe you want help comment, BELOW comments can help you finish the code
*
* Some Useful MACROs and DEFINEs, you can use them in below implementation.
* MACROs or Functions:
* get_pte : get an pte and return the kernel virtual address of this pte for la
* if the PT contians this pte didn't exist, alloc a page for PT (notice the 3th parameter '1')
* pgdir_alloc_page : call alloc_page & page_insert functions to allocate a page size memory & setup
* an addr map pa<--->la with linear address la and the PDT pgdir
* DEFINES:
* VM_WRITE : If vma->vm_flags & VM_WRITE == 1/0, then the vma is writable/non writable
* PTE_W 0x002 // page table/directory entry flags bit : Writeable
* PTE_U 0x004 // page table/directory entry flags bit : User can access
* VARIABLES:
* mm->pgdir : the PDT of these vma
*
*/
/*LAB3 EXERCISE 1: YOUR CODE*/
//(1) try to find a pte, if pte's PT(Page Table) isn't existed, then create a PT.
//create a page table which can contains 1024 page table entrys.
//one entry can maps 4K physical page.
ptep = get_pte(mm->pgdir,addr,1);
if (*ptep == 0) {
//(2) if the phy addr isn't exist, then alloc a page & map the phy addr with logical addr
//get page table entry according to logical addr,then connects physical page to the entry.
//the entry property is perm
pgdir_alloc_page(mm->pgdir,addr,perm);
}
else {
/*LAB3 EXERCISE 2: YOUR CODE
* Now we think this pte is a swap entry, we should load data from disk to a page with phy addr,
* and map the phy addr with logical addr, trigger swap manager to record the access situation of this page.
*
* Some Useful MACROs and DEFINEs, you can use them in below implementation.
* MACROs or Functions:
* swap_in(mm, addr, &page) : alloc a memory page, then according to the swap entry in PTE for addr,
* find the addr of disk page, read the content of disk page into this memroy page
* page_insert : build the map of phy addr of an Page with the linear addr la
* swap_map_swappable : set the page swappable
*/
if(swap_init_ok) {
struct Page *page=NULL;
//(1)According to the mm AND addr, try to load the content of right disk page
// into the memory which page managed.
ret = swap_in(mm,addr,&page);
if (ret != 0 ) {
cprintf("swap_in failed in do_pgfault\n");
goto failed;
}
//(2) According to the mm, addr AND page, setup the map of phy addr <---> logical addr
page_insert(mm->pgdir,page,addr,perm);
//(3) make the page swappable.swap area index according to this page virtual address.
//disk-->memory;memory-->disk;disk-->memory;memory-->disk;...,we must keep this sequences corretion
page->pra_vaddr = addr;
swap_map_swappable(mm,addr,page,1);
}
else {
cprintf("no swap_init_ok but ptep is %x, failed\n",*ptep);
goto failed;
}
}
#endif
ret = 0;
failed:
return ret;
}当页表项完全不存在的时候*ptep == 0,pgdir_alloc_page(mm->pgdir,addr,perm);函数的作用是分配一个物理页,并进行磁盘换入操作。
否则,*ptep非零,表示这是一个swap entry,那么接下来进行换入换出的操作了。swap_in(mm,addr,&page);函数将从磁盘中换入addr所代表的页到内存中,在swap_in函数中调用了alloc_page函数,alloc_page函数调用了swap_out函数。这样能够确保每次换入的时候,都是申请既有的内存换出(所有的物理内存在free_area链表中),然后换入。有关alloc_page详细解释如下:
//alloc_pages - call pmm->alloc_pages to allocate a continuous n*PAGESIZE memory
struct Page *
alloc_pages(size_t n) {
struct Page *page=NULL;
bool intr_flag;
while (1)
{
local_intr_save(intr_flag);
{
page = pmm_manager->alloc_pages(n);
}
local_intr_restore(intr_flag);
if (page != NULL || n > 1 || swap_init_ok == 0) break;//能从物理内存申请内存,就推出
extern struct mm_struct *check_mm_struct;
//cprintf("page %x, call swap_out in alloc_pages %d\n",page, n);
swap_out(check_mm_struct, n, 0);//否则已经满了,不能从内存中申请内存,就从check_mm_struct中换出n页
}
//cprintf("n %d,get page %x, No %d in alloc_pages\n",n,page,(page-pages));
return page;
}假设当前是物理页均分配完了,那么page是NULL,就会执行swap_out,换出n页出去,并释放物理内存页。由于是while循环,下次通过alloc_pages分配就能成功。
换出的页要被应用程序使用,还需要建立虚拟地址和实际地址之间的联系,靠page_insert(mm->pgdir,page,addr,perm);函数执行。
当页换出换出执行完成后,为了记录访问情况,调用fifo算法进行记录,记录函数是swap_map_swappable(mm,addr,page,1);
2、补充完成基于FIFO的页面替换算法(需要编程)
完成vmm.c中的do_pgfault函数,并且在实现FIFO算法的swap_fifo.c中完成map_swappable和swap_out_vistim函数。通过对swap的测试。
/*
* (3)_fifo_map_swappable: According FIFO PRA, we should link the most recent arrival page at the back of pra_list_head qeueue
*/
static int
_fifo_map_swappable(struct mm_struct *mm, uintptr_t addr, struct Page *page, int swap_in)
{
list_entry_t *head=(list_entry_t*) mm->sm_priv;
list_entry_t *entry=&(page->pra_page_link);
assert(entry != NULL && head != NULL);
//record the page access situlation
/*LAB3 EXERCISE 2: YOUR CODE*/
//(1)link the most recent arrival page at the back of the pra_list_head qeueue.
//first insert,fifo is null head->next == head
list_add_after(head, entry);
return 0;
}
/*
* (4)_fifo_swap_out_victim: According FIFO PRA, we should unlink the earliest arrival page in front of pra_list_head qeueue,
* then assign the value of *ptr_page to the addr of this page.
*/
static int
_fifo_swap_out_victim(struct mm_struct *mm, struct Page ** ptr_page, int in_tick)
{
list_entry_t *head=(list_entry_t*) mm->sm_priv;
assert(head != NULL);
assert(in_tick==0);
/* Select the victim */
/*LAB3 EXERCISE 2: YOUR CODE*/
//(1) unlink the earliest arrival page in front of pra_list_head qeueue
list_entry_t *front = head->prev;
assert(front!=NULL);
assert(front!=head);
list_del(front);
//(2) assign the value of *ptr_page to the addr of this page
//assign earliest longest unused page
struct Page *page = le2page(front, pra_page_link);
assert(ptr_page!=NULL);
*ptr_page = page;
return 0;
}