微信公众号|人工智能技术派
作 者|hws
- 一种解码策略优化技术:目标是不需要任何显示的CoT prompting,能够有效提升大型语言模型在各种推理任务中的表现,并通过自发地揭示CoT推理路径,改善模型的推理能力和准确性。
背景介绍
大模型推理,prompt会在很大程度上影响结果准确性,因此很多公司专门设置"prompt工程师"这个职位,显然就像先前NLU写规则一样,获取适合任务的prompt也渐渐成为一个非常耗费人力的方向,那么是否可以在保证精度的情况下,跳过编写prompt这个流程?

方案阐述
既然通过合适的prompt可以获理正确的结果,那么理论上即使不需要任何explicit的CoT prompting,包含CoT过程的解码路径(decoding path)也是自然存在于LLM之中的,作者实验发现,只要多输出接个结果就模型就会给出正确的结果。
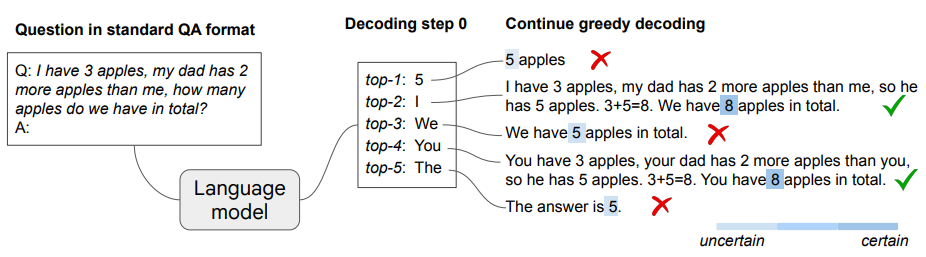

归纳总结
从实现方案及效果来看,该技术方案离“不需要任何显式的CoT prompting”还有一定距离。
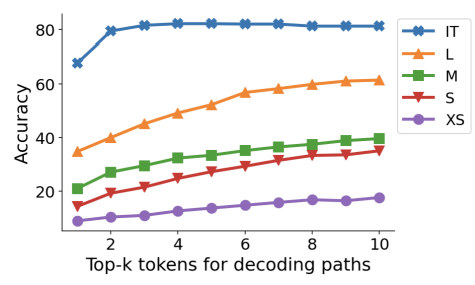
1. 计算量增加:从Figure-3可以看出,通常topk越大效果越好,但与之相应的是计算量也会增加
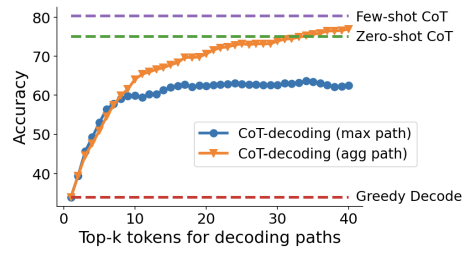
2. 效果比few shot 要差:从Figure4可以看出:效果比Few-shot CoT差,在token数小于40时,甚至小于zero-shot
3. 应用领域受限:确定答案区间比较重要,针对不同的任务答案区间的确定方法不统一
参考文献
- https://arxiv.org/pdf/2402.10200v1.pdf
- Google | 提出CoT解码新方法,无需Prompt,就能让大模型(LLM)进行CoT推理
- 为什么 chain of thoughts 能提升 prompt 效果? - 知乎
如遇排版问题,请参阅创作链接