简介
针对网络安全领域的NSL-KDD数据集进行分类任务的预处理和模型训练、以及超参数调优。
数据预处理
- 读取并解析数据集;
- 检查并删除指定列(outcome)的缺失值;
- 对类别型特征(protocol_type, service, flag)进行LabelEncoder编码转换;
- 将攻击类型标签字段"attack"二值化,'normal’映射为0,其他攻击类型映射为1;
- 划分训练集和测试集,并对两者执行标准化预处理。
模型训练与验证:
- 使用线性SVM(LinearSVC)、RBF核SVM和多项式核SVM建立三个不同的分类模型;
- 分别在训练集上训练这三种模型,并在测试集上进行预测;
- 计算并打印每种模型在训练集和测试集上的准确率以评估模型性能。
此外,还使用GridSearchCV进行了超参数调优,针对RBF核SVM模型搜索最优的C和gamma参数,并用找到的最佳参数重新训练模型,最后计算优化后模型在测试集上的准确率。
代码步骤
主要实现了以下功能:
- 导入必要的库和模块,如numpy、pandas、matplotlib等,并从sklearn中导入支持向量机(SVM)及其相关工具,用于数据预处理、模型训练和性能评估。
- 读取KDDTrain+.txt数据集并重命名列名,检查并删除缺失值(这里没有发现缺失值),同时对其中的类别型特征进行编码转换,以适应机器学习模型的要求。将攻击类型标签字段"attack"中的’normal’标记为0,其余标记为1。
- 使用LabelEncoder对三个类别型特征(protocol_type, service, flag)进行编码,将其转化为数值形式。
- 将数据集划分为特征矩阵x和目标变量y,通过train_test_split函数分割为训练集和测试集,并对两者都应用StandardScaler进行标准化处理。
- 使用线性SVM模型以及RBF核函数和多项式核函数的SVM模型分别在训练集上进行训练,并在测试集上进行预测。计算并打印每种模型在训练集和测试集上的准确率。
- 对于RBF核函数的SVM模型,利用GridSearchCV进行参数调优,寻找最优超参数组合,然后使用最佳参数重新训练模型并在测试集上进行预测及准确率计算。
实现代码
导入必要的库和模块
import numpy as np # 提供高效的数值计算及数组操作
import pandas as pd # 提供数据处理和数据分析的功能
from pandas import Timestamp # 用于处理时间戳
import matplotlib.pyplot as plt # 提供数据可视化功能
from sklearn import svm # 支持向量机算法
from sklearn.svm import SVC # SVC为支持向量分类器
from sklearn.preprocessing import MinMaxScaler # 数据标准化处理
from sklearn.metrics import classification_report, confusion_matrix ,accuracy_score ,plot_roc_curve,roc_auc_score,roc_curve # 评估模型性能的指标
from sklearn.model_selection import train_test_split # 数据集划分
import seaborn as sns # 提供更美观的可视化效果
from sklearn.preprocessing import LabelEncoder # 对类别型数据进行编码
from sklearn.model_selection import GridSearchCV # 参数网格搜索
import matplotlib.gridspec as gridspec # 多图布局管理器
读取数据
data_Train =pd.read_csv('../input/nslkdd/KDDTrain+.txt')
数据格式如下:
| 0 | tcp | ftp_data | SF | 491 | 0.1 | 0.2 | 0.3 | 0.4 | 0.5 | ... | 0.17.1 | 0.03 | 0.17.2 | 0.00.6 | 0.00.7 | 0.00.8 | 0.05 | 0.00.9 | normal | 20 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | udp | other | SF | 146 | 0 | 0 | 0 | 0 | 0 | ... | 0.00 | 0.60 | 0.88 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | normal | 15 |
| 1 | 0 | tcp | private | S0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0.10 | 0.05 | 0.00 | 0.00 | 1.00 | 1.00 | 0.00 | 0.00 | neptune | 19 |
| 2 | 0 | tcp | http | SF | 232 | 8153 | 0 | 0 | 0 | 0 | ... | 1.00 | 0.00 | 0.03 | 0.04 | 0.03 | 0.01 | 0.00 | 0.01 | normal | 21 |
| 3 | 0 | tcp | http | SF | 199 | 420 | 0 | 0 | 0 | 0 | ... | 1.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | normal | 21 |
| 4 | 0 | tcp | private | REJ | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0.07 | 0.07 | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 | 1.00 | neptune | 21 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 125967 | 0 | tcp | private | S0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0.10 | 0.06 | 0.00 | 0.00 | 1.00 | 1.00 | 0.00 | 0.00 | neptune | 20 |
| 125968 | 8 | udp | private | SF | 105 | 145 | 0 | 0 | 0 | 0 | ... | 0.96 | 0.01 | 0.01 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | normal | 21 |
| 125969 | 0 | tcp | smtp | SF | 2231 | 384 | 0 | 0 | 0 | 0 | ... | 0.12 | 0.06 | 0.00 | 0.00 | 0.72 | 0.00 | 0.01 | 0.00 | normal | 18 |
| 125970 | 0 | tcp | klogin | S0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0.03 | 0.05 | 0.00 | 0.00 | 1.00 | 1.00 | 0.00 | 0.00 | neptune | 20 |
| 125971 | 0 | tcp | ftp_data | SF | 151 | 0 | 0 | 0 | 0 | 0 | ... | 0.30 | 0.03 | 0.30 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | normal | 21 |
125972 rows × 43 columns
data_Train.columns
Index([‘0’, ‘tcp’, ‘ftp_data’, ‘SF’, ‘491’, ‘0.1’, ‘0.2’, ‘0.3’, ‘0.4’, ‘0.5’,
‘0.6’, ‘0.7’, ‘0.8’, ‘0.9’, ‘0.10’, ‘0.11’, ‘0.12’, ‘0.13’, ‘0.14’,
‘0.15’, ‘0.16’, ‘0.17’, ‘2’, ‘2.1’, ‘0.00’, ‘0.00.1’, ‘0.00.2’,
‘0.00.3’, ‘1.00’, ‘0.00.4’, ‘0.00.5’, ‘150’, ‘25’, ‘0.17.1’, ‘0.03’,
‘0.17.2’, ‘0.00.6’, ‘0.00.7’, ‘0.00.8’, ‘0.05’, ‘0.00.9’, ‘normal’,
‘20’],
dtype=‘object’)
columns = (['duration','protocol_type','service','flag','src_bytes','dst_bytes','land','wrong_fragment','urgent'
,'hot','num_failed_logins','logged_in','num_compromised','root_shell','su_attempted','num_root'
,'num_file_creations','num_shells','num_access_files','num_outbound_cmds','is_host_login'
,'is_guest_login','count','srv_count','serror_rate','srv_serror_rate','rerror_rate','srv_rerror_rate'
,'same_srv_rate','diff_srv_rate','srv_diff_host_rate','dst_host_count','dst_host_srv_count'
,'dst_host_same_srv_rate','dst_host_diff_srv_rate','dst_host_same_src_port_rate'
,'dst_host_srv_diff_host_rate','dst_host_serror_rate','dst_host_srv_serror_rate','dst_host_rerror_rate'
,'dst_host_srv_rerror_rate','attack','outcome'])
data_Train.columns=columns
定义一个元组columns,包含了一系列的字段名称,这些字段主要用于描述网络活动的数据特征。
这些字段包括:
duration: 持续时间
protocol_type: 协议类型
service: 服务
flag: 标记
src_bytes: 来源字节
dst_bytes: 目标字节
land: 是否是本地连接
wrong_fragment: 错误的分片
urgent: 是否紧急
hot: 是否热门
num_failed_logins: 登录失败次数
logged_in: 是否已登录
num_compromised: 受损次数
root_shell: 是否获得根shell
su_attempted: 是否尝试过su
num_root: 根用户数量
num_file_creations: 文件创建数量
num_shells: shell数量
num_access_files: 访问文件数量
num_outbound_cmds: 出站命令数量
is_host_login: 是否为主机登录
is_guest_login: 是否为guest登录
count: 计数
srv_count: 服务计数
serror_rate: 客户端错误率
srv_serror_rate: 服务器错误率
rerror_rate: 客户端重传率
srv_rerror_rate: 服务器重传率
same_srv_rate: 同一服务率
diff_srv_rate: 不同服务率
srv_diff_host_rate: 服务不同主机率
dst_host_count: 目标主机计数
dst_host_srv_count: 目标主机服务计数
dst_host_same_srv_rate: 目标主机同一服务率
dst_host_diff_srv_rate: 目标主机不同服务率
dst_host_same_src_port_rate: 目标主机相同源端口率
dst_host_srv_diff_host_rate: 目标主机服务不同主机率
dst_host_serror_rate: 目标主机客户端错误率
dst_host_srv_serror_rate: 目标主机服务器错误率
dst_host_rerror_rate: 目标主机客户端重传率
dst_host_srv_rerror_rate: 目标主机服务器重传率
attack: 攻击类型
outcome: 结果
数据清洗
data_Train.isnull().sum()
# 从data_Train数据集中删除'outcome'列
data_Train.drop(columns='outcome',axis=1, inplace=True )
duration 0
protocol_type 0
service 0
flag 0
src_bytes 0
dst_bytes 0
land 0
wrong_fragment 0
urgent 0
hot 0
num_failed_logins 0
logged_in 0
num_compromised 0
root_shell 0
su_attempted 0
num_root 0
num_file_creations 0
num_shells 0
num_access_files 0
num_outbound_cmds 0
is_host_login 0
is_guest_login 0
count 0
srv_count 0
serror_rate 0
srv_serror_rate 0
rerror_rate 0
srv_rerror_rate 0
same_srv_rate 0
diff_srv_rate 0
srv_diff_host_rate 0
dst_host_count 0
dst_host_srv_count 0
dst_host_same_srv_rate 0
dst_host_diff_srv_rate 0
dst_host_same_src_port_rate 0
dst_host_srv_diff_host_rate 0
dst_host_serror_rate 0
dst_host_srv_serror_rate 0
dst_host_rerror_rate 0
dst_host_srv_rerror_rate 0
attack 0
outcome 0
dtype: int64
EDA
将数据集中的攻击类型标准化
attack_n = []
for i in data_Train.attack :
# 将攻击类型转换为标准化的字符串
if i == 'normal':
attack_n.append("normal")
else:
attack_n.append("attack")
# 将转换后的攻击类型列表赋值回原数据集的对应列
data_Train['attack'] = attack_n
计算并返回训练数据集中‘attack’列中各标签的出现次数
data_Train['attack'].value_counts()
normal 67342
attack 58630
Name: attack, dtype: int64
数据集可视化展示
根据数据集中的攻击类型绘制计数直方图。
sns.countplot: Seaborn库中的函数,用于绘制计数直方图。
data_Train.attack: 使用的数据集中的攻击类型列。
palette = ‘CMRmap’: 设置颜色映射为’CMRmap’。
sns.countplot(data_Train.attack , palette = 'CMRmap')
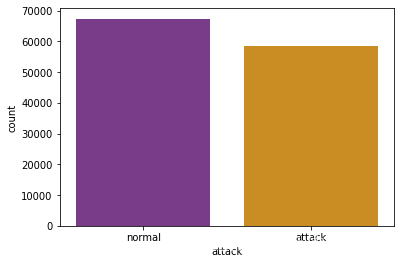
根据数据集中的’protocol_type’列绘制计数直方图。
sns.countplot函数用于绘制类别数据的计数图,可以直观地看出不同协议类型的数量分布。
参数:
- data_Train: 训练数据集,需要是一个包含’protocol_type’列的数据框(如pandas的DataFrame类型)。
sns.countplot(data_Train[ 'protocol_type'], palette ='CMRmap')
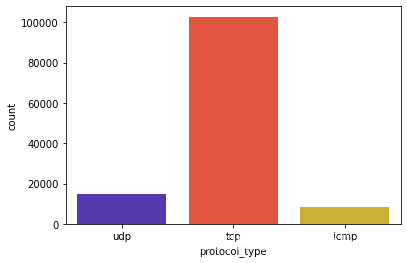
生成一个基于数据集data_Train的计数柱状图,展示不同协议类型在正常与攻击情况下的分布
参数说明:
x=‘protocol_type’: 指定x轴的分类变量为’protocol_type’,即协议类型
hue=‘attack’: 指定通过颜色来区分的分类变量为’attack’,即攻击类型
data=data_Train: 使用的数据集为data_Train
palette=‘CMRmap’: 指定使用的颜色映射为’CMRmap’
sns.countplot(x='protocol_type', hue='attack', data=data_Train, palette='CMRmap')
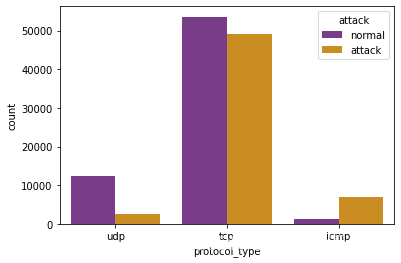
生成服务类型计数的柱状图。
参数:
- figsize: 指定图表的大小,格式为(width, height)。
- palette: 指定图表中颜色方案。
- y: 指定数据集中要绘制在y轴上的列。
- data: 数据集,需要是一个DataFrame。
- order: 指定y轴上服务类型的顺序,按照数据集中服务类型出现的频率排序。
# 创建一个新的图形窗口,并设置其大小
plt.figure(figsize=(10,40))
# 使用seaborn库绘制计数柱状图,按照服务类型的频率绘制
sns.countplot(palette='mako', y='service' , data=data_Train, order = data_Train['service'].value_counts().index)

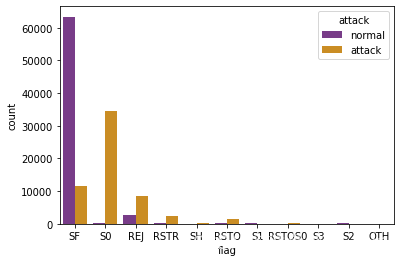
生成一个基于数据集data_Train的计数柱状图,展示’flag’不同取值下的攻击事件分布
参数说明:
x=‘flag’: 指定x轴的分类变量为’flag’
hue=‘attack’: 指定通过不同颜色区分的分类变量为’attack’
data=data_Train: 使用的数据集
palette=‘CMRmap’: 指定使用的颜色映射为’CMRmap’
sns.countplot(x='flag',hue='attack' , data = data_Train , palette ='CMRmap')
数据编码
# 选择数据集中所有类型为'object'的列,并返回它们的列名
data_obj = data_Train.select_dtypes(['object']).columns
# 计算并返回训练数据集中“attack”列中各标签的出现次数
data_Train["attack"].value_counts()
normal 67342
attack 58630
Name: attack, dtype: int64
从sklearn.preprocessing导入LabelEncoder
# LabelEncoder用于将类别型标签数据转换为数值型,便于机器学习模型处理
from sklearn.preprocessing import LabelEncoder
# 初始化用于处理protocol_type字段的LabelEncoder实例
protocol_type_le = LabelEncoder()
# 初始化用于处理service字段的LabelEncoder实例
service_le = LabelEncoder()
# 初始化用于处理flag字段的LabelEncoder实例
flag_le = LabelEncoder()
对训练数据集中的特征进行编码
# 1. 使用LabelEncoder对'protocol_type'特征进行编码
data_Train['protocol_type'] = protocol_type_le.fit_transform(data_Train['protocol_type'])
# 2. 使用LabelEncoder对'service'特征进行编码
data_Train['service'] = service_le.fit_transform(data_Train['service'])
# 3. 使用LabelEncoder对'flag'特征进行编码
data_Train['flag'] = flag_le.fit_transform(data_Train['flag'])
将数据集中的攻击类型转化为二进制形式
attack_n = []
for i in data_Train.attack :
# 遍历攻击类型,将'normal'标记为0,其他类型标记为1
if i == 'normal':
attack_n.append(0)
else:
attack_n.append(1)
# 将处理后的攻击类型数据添加到data_Train数据集中
data_Train['attack'] = attack_n
data_Train['attack'].value_counts()
0 67342
1 58630
Name: attack, dtype: int64
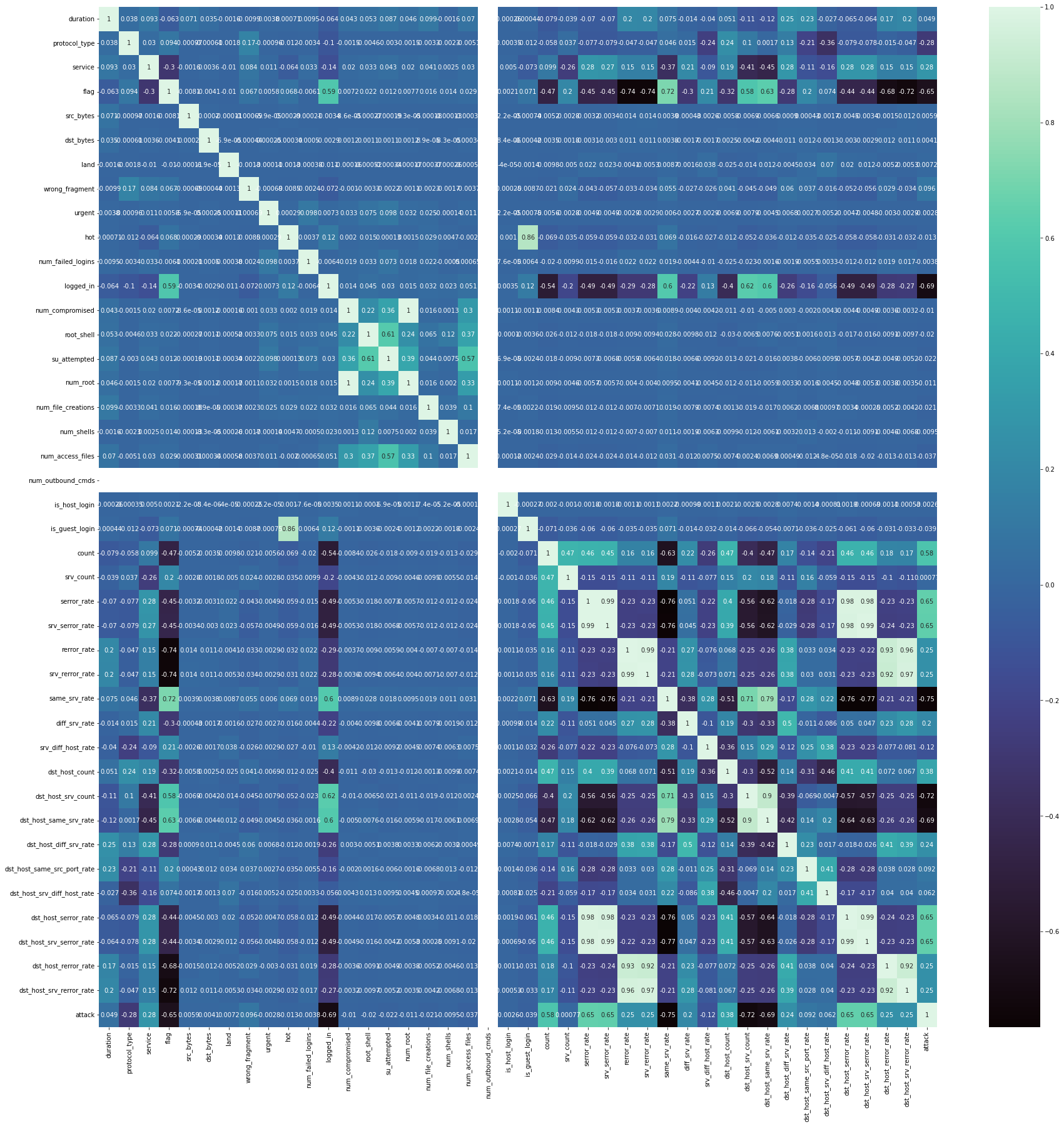
生成并显示数据集的热力图
# 创建一个大小为30x30的画布
plt.figure(figsize=(30,30))
# 绘制热力图,显示数据集中的相关性
sns.heatmap(data_Train.corr(), annot= True,cmap='mako')
数据集划分
将数据集划分为训练集和测试集
y = data_Train['attack'].copy() # 复制目标变量(攻击类型)到y
x = data_Train.drop(['attack'], axis=1) # 从数据集中移除目标变量,得到特征矩阵x
# 使用train_test_split函数划分训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(x,y , test_size=0.3, random_state=40)
数据标准化
# 导入StandardScaler类以实现数据的标准化处理
from sklearn.preprocessing import StandardScaler
# 初始化StandardScaler对象
scalar=StandardScaler()
# 对训练数据集x_train进行标准化处理
x_train=scalar.fit_transform(x_train)
# 对测试数据集x_test应用相同的标准化处理
x_test = scalar.fit_transform(x_test)
训练模型
使用线性支持向量机(LinearSVC)进行训练和预测
lin_svc = svm.LinearSVC().fit(x_train, y_train) # 训练线性支持向量机模型
Y_pred = lin_svc.predict(x_test) # 使用训练好的模型对测试集进行预测
print('The Training accuracy = ', lin_svc.score(x_train, y_train)) # 打印训练集的准确率
print('The Testing accuracy = ', lin_svc.score(x_test, y_test)) # 打印测试集的准确率
print("------------------------------------------------")
# 计算并打印线性SVC模型的预测准确率
print( "linearSVC accuracy : " + str(np.round(accuracy_score(y_test,Y_pred),3)))
The Training accuracy = 0.9551145384440917
The Testing accuracy = 0.9547787891617273
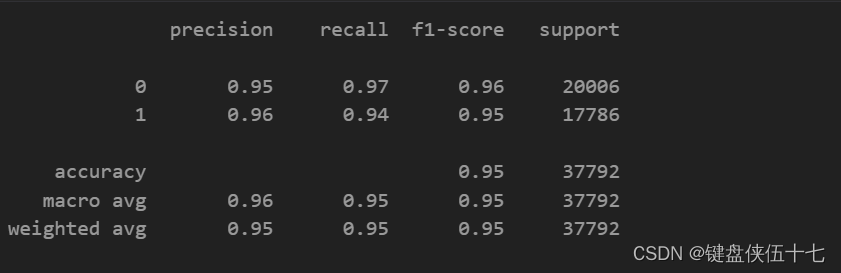
linearSVC accuracy : 0.955
print(classification_report(y_test,Y_pred))
使用RBF核函数训练SVC模型,进行训练和预测
# 使用rbf核函数训练SVC模型,并在训练集和测试集上测试模型的准确性
rbf_svc = svm.SVC(kernel='rbf').fit(x_train, y_train) # 训练SVM模型,使用径向基函数(RBF)作为核函数
Y_pred_rbf = rbf_svc.predict(x_test) # 使用训练好的模型预测测试集的标签
# 打印训练集和测试集的准确性
print('The Training accuracy = ', rbf_svc.score(x_train, y_train)) # 打印训练准确性
print('The Testing accuracy = ', rbf_svc.score(x_test, y_test)) # 打印测试准确性
print("------------------------------------------------")
# 使用accuracy_score函数计算并打印SVM模型(使用rbf核)在测试集上的准确率
print( "SVM (kernel: 'rbf') accuracy : " + str(np.round(accuracy_score(y_test, Y_pred_rbf), 3)))
The Training accuracy = 0.9920843728736675
The Testing accuracy = 0.9914796782387807
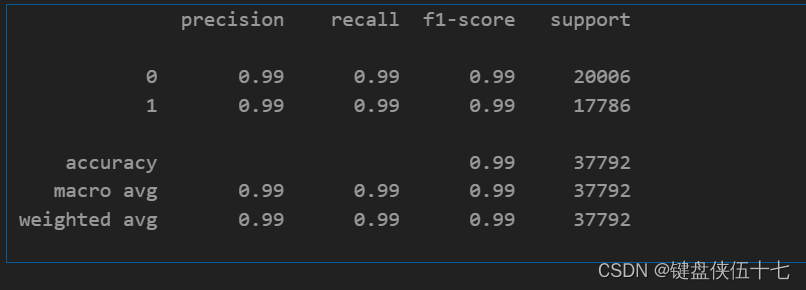
SVM (kernel: ‘rbf’) accuracy : 0.991
print(classification_report(y_test,Y_pred_rbf))
使用多项式核函数的SVM分类器训练和测试
# 使用多项式核函数的SVM分类器训练和测试
svclassifier_poly = SVC(kernel='poly') # 定义SVM分类器,使用多项式核函数
poly = svclassifier_poly.fit(x_train,y_train) # 使用训练数据拟合模型
Y_pred_poly = svclassifier_poly.predict(x_test) # 使用测试数据进行预测
# 打印训练集和测试集的准确率
print('The Training accuracy = ',poly.score(x_train, y_train))
print('The Testing accuracy = ',poly.score(x_test, y_test))
print("------------------------------------------------")
# 打印整体的SVM(多项式核)分类器准确率和分类报告
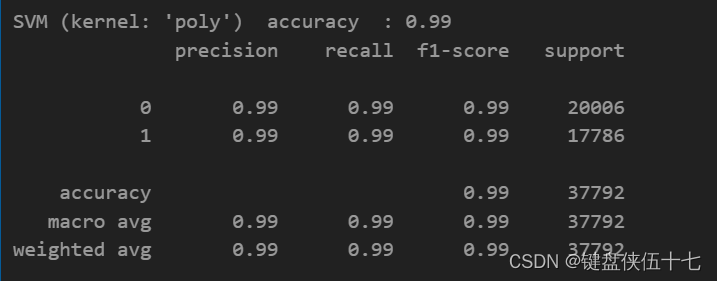
print( "SVM (kernel: 'poly') accuracy : " + str(np.round(accuracy_score(y_test,Y_pred_poly),3)))
print(classification_report(y_test,Y_pred_poly))
The Training accuracy = 0.9911317759129055
The Testing accuracy = 0.989997883149873
SVM (kernel: ‘poly’) accuracy : 0.99
使用网格搜索进行参数调优
# 使用网格搜索进行参数调优
param_grid = {'C': [0.2,0.5,1], 'gamma': [0.5],'kernel': ['rbf']} # 定义超参数搜索范围
grid = GridSearchCV(SVC(),param_grid ,verbose=2, cv= 3,refit=False) # 实例化网格搜索对象
grid.fit(x_train,y_train) # 对训练数据进行拟合,寻找最优参数组合
Fitting 3 folds for each of 3 candidates, totalling 9 fits
[CV] END …C=0.2, gamma=0.5, kernel=rbf; total time= 1.2min
[CV] END …C=0.2, gamma=0.5, kernel=rbf; total time= 1.2min
[CV] END …C=0.2, gamma=0.5, kernel=rbf; total time= 1.2min
[CV] END …C=0.5, gamma=0.5, kernel=rbf; total time= 1.4min
[CV] END …C=0.5, gamma=0.5, kernel=rbf; total time= 1.3min
[CV] END …C=0.5, gamma=0.5, kernel=rbf; total time= 1.7min
[CV] END …C=1, gamma=0.5, kernel=rbf; total time= 1.4min
[CV] END …C=1, gamma=0.5, kernel=rbf; total time= 1.4min
[CV] END …C=1, gamma=0.5, kernel=rbf; total time= 1.4min
GridSearchCV(cv=3, estimator=SVC(),
param_grid={‘C’: [0.2, 0.5, 1], ‘gamma’: [0.5], ‘kernel’: [‘rbf’]},
refit=False, verbose=2)
print(grid.best_params_)
{‘C’: 1, ‘gamma’: 0.5, ‘kernel’: ‘rbf’}
重新使用最优参数训练RBF核的SVC模型
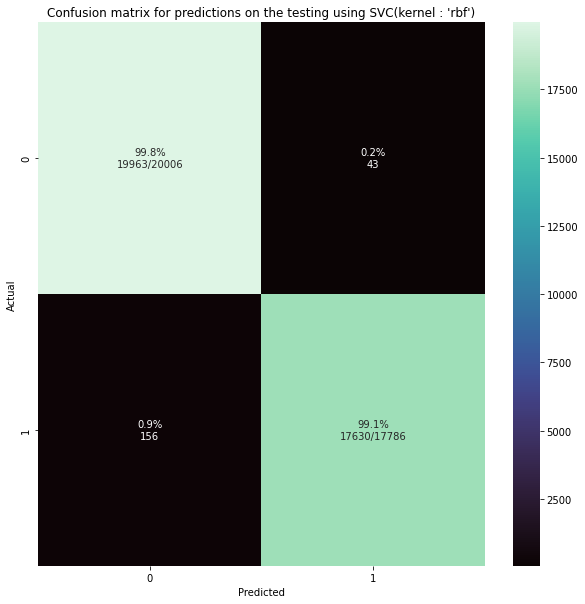
# 使用网格搜索找到的最佳参数配置来初始化RBF核的SVC模型,并在训练数据上拟合
rbf_svc = svm.SVC(kernel=grid.best_params_['kernel'], gamma=grid.best_params_['gamma'], C=grid.best_params_['C']).fit(x_train, y_train)
# 使用拟合好的模型对测试集进行预测
Y_pred_rbf =rbf_svc.predict(x_test)
# 打印在训练集和测试集上的得分
print(rbf_svc.score(x_train, y_train))
print(rbf_svc.score(x_test, y_test))
print("------------------------------------------------")
# 打印经过四舍五入到小数点后3位的SVM(核函数为'rbf')的准确率
print( "SVM (kernel: 'rbf') accuracy : " + str(np.round(accuracy_score(y_test,Y_pred_rbf),3)))
0.9976525289181221
0.9947343353090601
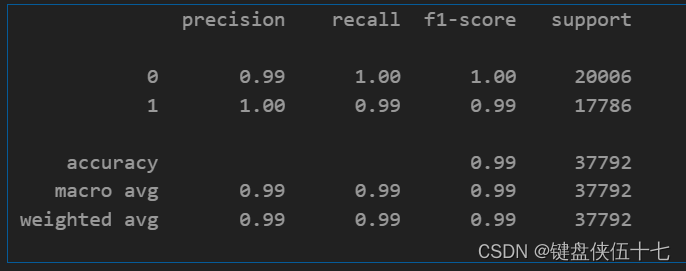
SVM (kernel: ‘rbf’) accuracy : 0.995
print(classification_report(y_test,Y_pred_rbf))
绘制混淆矩阵图
def plot_cm(y_true, y_pred, title):
# 设置图像大小
figsize=(10,10)
# 计算混淆矩阵
cm = confusion_matrix(y_true, y_pred, labels=np.unique(y_true))
# 计算每个类的总预测数,并转换为百分比
cm_sum = np.sum(cm, axis=1, keepdims=True)
cm_perc = cm / cm_sum.astype(float) * 100
# 准备在矩阵上标注百分比和总数
annot = np.empty_like(cm).astype(str)
nrows, ncols = cm.shape
for i in range(nrows):
for j in range(ncols):
c = cm[i, j]
p = cm_perc[i, j]
if i == j:
s = cm_sum[i]
annot[i, j] = '%.1f%%\n%d/%d' % (p, c, s)
elif c == 0:
annot[i, j] = ''
else:
annot[i, j] = '%.1f%%\n%d' % (p, c)
# 将混淆矩阵数据转换为DataFrame,便于绘制
cm = pd.DataFrame(cm, index=np.unique(y_true), columns=np.unique(y_true))
cm.index.name = 'Actual'
cm.columns.name = 'Predicted'
# 创建图像和子图
fig, ax = plt.subplots(figsize=figsize)
plt.title(title)
# 绘制混淆矩阵热力图
sns.heatmap(cm, cmap= "mako", annot=annot, fmt='', ax=ax)
plot_cm(y_test,Y_pred_rbf, 'Confusion matrix for predictions on the testing using SVC(kernel : \'rbf\')')
优化建议
1. 数据预处理:
- 在对类别型特征进行编码之前,可以考虑先查看各个类别数量的分布,对于不平衡类别数据,可能需要采取如过采样、欠采样或SMOTE等方法进行均衡处理。
- 对于连续数值型特征,可以进一步探索其分布特性,例如是否存在异常值,是否需要进行归一化而非标准化。
2. 特征选择与降维:
- 在训练模型前,可以尝试使用相关性分析(如皮尔逊相关系数)、卡方检验或基于模型的特征重要性评估(如随机森林)来筛选出对目标变量影响较大的特征,减少噪声和冗余信息。
3. 模型调优:
- 在GridSearchCV中,可以扩大超参数搜索范围,或者针对SVM模型尝试更多类型的核函数,并寻找各自的最优参数组合。
可以考虑集成学习策略,比如Bagging、Boosting或Stacking,结合多种基础模型提高整体性能。