判断选择什么模型,什么量化方案,什么推理框架,最基础的知识就是如何评估自己的模型以及推理平台。
模型衡量标准
衡量一个模型的最直接标准就是运算速度,但是运算速度是无法计算的,所以定义了一些间接标准来推测模型的运算速度。这些标准不仅仅可以用来选择模型的量化方案,在设计模型时也应该有所参考。
模型计算量FLOPs
Floating point operations,浮点运算数量,代表一次推理需要的浮点运算次数
注意不要与FLOPS混淆,FLOPS是floating point operations per second指芯片每秒浮点运算数量用于衡量芯片的运算能力。
例如对于一个普通CNN卷积层,输入尺寸为
C
o
u
t
×
H
×
W
C_{out}\times H\times W
Cout×H×W输出尺寸相同,卷积核尺寸
K
=
3
K=3
K=3,添加偏置
b
i
a
s
bias
bias
一次卷积的运算量:
- 乘法: C i n K 2 C_{in} K^2 CinK2
- 加法: C i n ( K 2 − 1 ) + ( C i n − 1 ) + 1 = C i n K 2 C_{in}(K^2-1)+(C_{in}-1)+1=C_{in}K^2 Cin(K2−1)+(Cin−1)+1=CinK2
输出尺寸
C
o
u
t
×
H
×
W
C_{out}\times H\times W
Cout×H×W中的每个像素点都是一次卷积,运算量共计:
2
C
i
n
C
o
u
t
H
W
×
K
2
2C_{in}C_{out}HW\times K^2
2CinCoutHW×K2
计算方法的不同以及是否添加bias导致算出来的结果可能不完全一样,无所谓,FLOPs这种就跟算法中的复杂度O(n)差不多,常数不会对结果产生数量级的影响。
FLOPs只是一个衡量标准,还有其他的衡量标准例如MACCs,multiply-accumulate operations,乘-加操作次数,一次乘法+一次加法为一个MACCs,MACCs 大约是 FLOPs 的一半。
模型参数量parameters
顾名思义,模型的参数总量
例如对于普通CNN卷积层,一共有
C
i
n
C
o
u
t
C_{in}C_{out}
CinCout个卷积核,参数量:
C
i
n
C
o
u
t
×
K
2
C_{in}C_{out}\times K^2
CinCout×K2
模型内存访问代价MAC
一次前向推理的过程中,模型内存交换的总量,体现了模型的空间复杂度。
模型计算强度
I = F L O P s M A C I=\frac{FLOPs}{MAC} I=MACFLOPs,表示每次内存交换对应多少次浮点运算,计算强度越大,模型内存利用率越高,
模型量化就约等于是运算量不变,但是每次运算本来要读取fp32,4个字节,现在换成了读取int8,1个字节,MAC降低了,模型计算强度提高了。
推理平台衡量标准
算力FLOPS
每秒浮点数运算次数,(用 π \pi π来表示)
带宽
每秒的内存交换量,(用 β \beta β表示)
计算强度上限
I m a x = π β I_{max}=\frac{\pi}{\beta} Imax=βπ
理论上模型的计算强度刚好达到推理平台的计算强度上限时性能最佳,这个理论最佳性能称为roof-line。计算强度低于
I
m
a
x
I_{max}
Imax时被称为带宽瓶颈区,这时推理平台的性能没有完全发挥出来,性能的上限取决于模型的计算强度;计算强度高于
I
m
a
x
I_{max}
Imax时称为计算瓶颈区,平台的算力得到了充分利用。
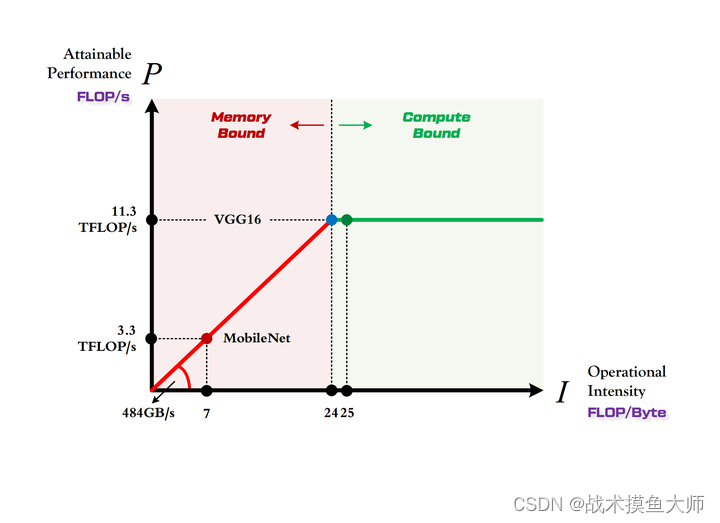
不过想要达到roof-line不是光考虑模型的计算量和内存访问代价就够的。因为实际计算过程中还有除算力和带宽之外的其他重要因素,它们也会影响模型的实际性能,这是 Roofline Model 未考虑到的。例如矩阵乘法,会因为 cache 大小的限制、GEMM 实现的优劣等其他限制,导致你几乎无法达到 Roofline 模型所定义的边界(屋顶)。
GEMM指通用矩阵乘法,这个在后面的blog中我们也要讲到,多年来数学家和计算机科学家都在努力优化矩阵乘法,但是进展不大,最近清华姚班大佬发了一篇paper被称为十年来矩阵乘法的最大优化,有空可以读一下
论文地址:https://epubs.siam.org/doi/10.1137/1.9781611977912.134
多年来矩阵乘法优化算法的发展历程
pytorch社区中的一篇讲解矩阵乘法的blog:https://pytorch.org/blog/inside-the-matrix/

解放双手
这么复杂的运算,自然不会是考我们人手工计算然后评估模型,实际上有很多用于评估模型的库,实践如下:
pytorch自行计算
如果只是评估模型参数量,不需要进行借助工具,直接两行代码就搞定
from torchvision.models import resnet50
model = resnet50()
total = sum([param.nelement() for param in model.parameters()])
print("parameter:%fM" % (total/1e6))
Torchstat
- 统计模型的参数量、计算量、访存量等指标,且会针对模型的每层指标进行打印;
- 部分指标与常见含义不同,具体会结合yolov5的指标进行介绍
- 只对常见网络层进行统计;
- 安装方法如下:
pip install torchstat
- 使用方法如下:
import torch
import torchvision.models as models
from torchstat import stat
model = models.resnet50(pretrained=True)
# 使用torchstat的stat函数来分析模型
stat(model, (3, 224, 224))
Thop
top这个词在计算机领域很常见,很多关系到性能的都会有top这个词,例如Linux平台下的性能管理工具:top,Jetson中的性能检测工具:jtop。这是为啥呢,不懂。
- 统计模型的参数量和计算量;
- 部分指标与常见含义不同,具体会结合yolov5的指标进行介绍;
- 只对常见网络层进行统计;
- 安装方法如下:
pip install thop
- 使用方法如下:
from torchvision.models import resnet50
from thop import profile
model = resnet50()
input = torch.randn(1, 3, 224, 224)
flops, params = profile(model, inputs=(input, ))
print("FLOPs=", str(flops/1e9) + '{}'.format("G"))
print("params=", str(params/1e6) + '{}'.format("M"))
更复杂的使用建议用到了再去翻文档学习,工具类的提前学习没有意义。
如果感觉有帮助,点赞收藏+关注,thanks