目录
1. 默认构造
代码:
相关知识点:
2. 有参构造函数 以及 使用{}初始化对象
代码:
相关知识点:
3. vector容器在尾部添加和删除元素
代码: 使用push_back()和pop_back()进行尾部元素的添加和删除
相关知识点:
代码: 使用emplace_back在尾部添加元素
相关知识点:
4. 使用emplace_back() 和 push_back()的区别
代码:
所以使用emplace_back的好处是: 效率更加的高。
原因:
使用有参构造函数初始化存放类的容器时的情况
总结:
5. vector容器的元素个数和容量大小
元素个数和容器容量的区别
代码: 使用size()获取容器元素个数,使用capacity()获取元素容量
相关知识点:
问题: 上面的运行结果,我们只存放了5个数据,为什么容器容量为6呢?
6. vector动态开辟空间以及注意事项
1. 什么时候动态分配?
2. 怎样动态新增内存?
注意:
3. 为什么上面我们存放5个数据,打印容量却是6?
原因:
4. 既然在重新开辟内存那么耗时,我们有什么办法呢?
办法:
代码: 使用reserve()函数增加容器容量,使用shrink_to_fit()函数将容量缩减到与元素个数相同。
分析:
7. vector容器在指定位置插入元素
代码: 使用insert()函数在指定位置添加元素
相关知识点:
代码: 使用emplace()函数在指定位置插入数据
相关知识点:
vector插入元素的效率
8. vector容器元素的访问
代码: 使用[]运算符和at()函数随机访问元素
相关知识点:
代码: 使用front()函数访问容器第一个数据, 使用back()函数访问容器的最后一个数据
相关知识点:
9.vector容器的迭代器
代码: 使用begin()和end()
相关知识点:
代码: 使用rbegin()和rend()
相关知识点:
cbegin(),cend(),crbegin(),crend()
10.insert()的返回值
代码:
相关知识点:
11. vector容器删除元素
代码: 使用erase()和clear()
相关知识点:
erase()函数的返回值
erase()和循环结合删除指定元素
相关知识点:
注意事项(切记):
12. vector容器赋值
代码: 使用=运算符重载和assign()函数
相关知识点:
13. resize()重设容器大小(准确来说是元素个数)
代码:
相关知识点:
14. vector的其它函数
代码: swap()函数
相关知识点:
代码: data()函数
相关知识点:
代码: max_size()函数
相关知识点:
15. vector其它的注意事项
vector容器是一个动态数组,可以根据存入的数据动态的扩容内存。
要使用vector,我们需要导入头文件 #include <vector>
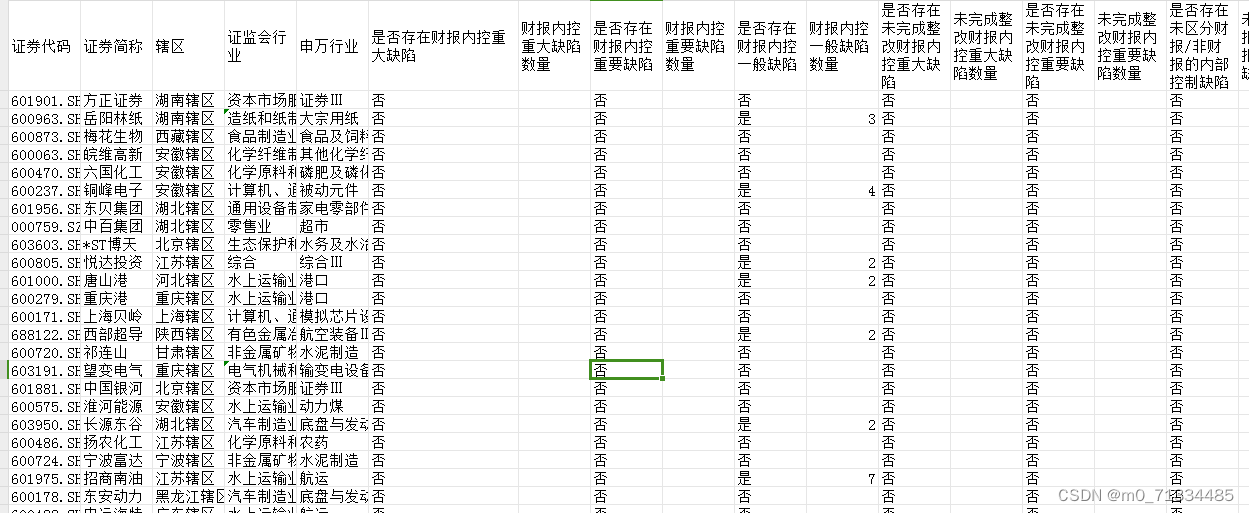
| 函数成员 | 函数功能 |
|---|---|
| begin() | 返回指向容器中第一个元素的迭代器。 |
| end() | 返回指向容器最后一个元素所在位置后一个位置的迭代器,通常和 begin() 结合使用。 |
| rbegin() | 返回指向最后一个元素的迭代器。 |
| rend() | 返回指向第一个元素所在位置前一个位置的迭代器。 |
| cbegin() | 和 begin() 功能相同,只不过在其基础上,增加了 const 属性,不能用于修改元素。 |
| cend() | 和 end() 功能相同,只不过在其基础上,增加了 const 属性,不能用于修改元素。 |
| crbegin() | 和 rbegin() 功能相同,只不过在其基础上,增加了 const 属性,不能用于修改元素。 |
| crend() | 和 rend() 功能相同,只不过在其基础上,增加了 const 属性,不能用于修改元素。 |
| size() | 返回实际元素个数。 |
| max_size() | 返回元素个数的最大值。这通常是一个很大的值,一般是 232-1,所以我们很少会用到这个函数。 |
| resize() | 改变实际元素的个数。 |
| capacity() | 返回当前容量。 |
| empty() | 判断容器中是否有元素,若无元素,则返回 true;反之,返回 false。 |
| reserve() | 增加容器的容量。 |
| shrink _to_fit() | 将内存减少到等于当前元素实际所使用的大小。 |
| operator[ ] | 重载了 [ ] 运算符,可以向访问数组中元素那样,通过下标即可访问甚至修改 vector 容器中的元素。 |
| at() | 使用经过边界检查的索引访问元素。 |
| front() | 返回第一个元素的引用。 |
| back() | 返回最后一个元素的引用。 |
| data() | 返回指向容器中第一个元素的指针。 |
| assign() | 用新元素替换原有内容。 |
| push_back() | 在序列的尾部添加一个元素。 |
| pop_back() | 移出序列尾部的元素。 |
| insert() | 在指定的位置插入一个或多个元素。 |
| erase() | 移出一个元素或一段元素。 |
| clear() | 移出所有的元素,容器大小变为 0。 |
| swap() | 交换两个容器的所有元素。 |
| emplace() | 在指定的位置直接生成一个元素。 |
| emplace_back() | 在序列尾部生成一个元素。 |
1. 默认构造
vector其实就是一个模板类,我们使用的时候需要定义它的对象,并且需要使用<>传入要在vector容器中存储数据的类型。(其实就是类模板的使用)
代码:
只需要注意定义vector对象的部分,其它的功能后面会介绍。
#include <iostream>
#include <stdlib.h>
#include <vector>
using namespace std;
class Student{
public:
private:
};
int main(void) {
vector<int> v1; // 定义存放int类型的容器
/*
<>可以传入基本类型,自定义类型,和指针类型
vector<float> v2; // 定义存放float类型的容器
vector<int*> v3; // 定义存放int*的指针类型的容器
vector<Student> v4; // 定义存放自定义类Student的容器
vector<Student*> v5;
*/
// 使用循环在尾部添加数据
for (int i = 0; i < 5; i++) {
v1.push_back(i);
}
// 打印v1中存放的元素个数
cout << v1.size() << endl;
system("pause");
return 0;
}
相关知识点:
1. 我们导入vector的头文件(#include <vector>)之后,就可以使用vector类来定义对象了。
2. 语法: vector<类型名> 对象名。 -- 这样定义的容器对象,内部空的,什么都没有(就是空对象)。
3. 我们可以在类型名的位置写普通类型,自定义类型和指针类型,来实现存放对应类型数据的vector类。 (就是类模板的使用)
4. 然后会调用默认构造函数创建对象。
5. push_back()是在容器的尾部添加元素, size()是返回容器的元素个数。
2. 有参构造函数 以及 使用{}初始化对象
调用有参构造函数进行创建对象
代码:
#include <iostream>
#include <stdlib.h>
#include <vector>
using namespace std;
int main(void) {
string s1(20, '-'); // 使用s存放分割线
/*
有参构造函数:
vector<int> v1(10); 指定容器开始时的元素个数为10,并将这些元素的值设置为0
vector<int> v1(10,5); 指定容器开始时的元素个数为10,并将这些元素的值设置为5
拷贝构造函数:
vector<int> v1{1,2,3,4,5};
vector<int> v2(v1);
使用v1的迭代器:
vector<int> v2(v1.begin(),v1.end()); 使用v1的[begin(),end())的元素初始化v2
使用指针:
int arr[] = {1,2,3,4,5};
vector<int> v1(arr, arr + 2); // 1,2 指针[arr,arr+2)范围内对应的数组元素初始化v1
*/
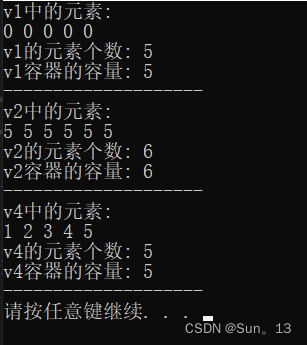
vector<int> v1(5);
cout << "v1中的元素:" << endl;
for (int i = 0; i < v1.size(); i++) {
cout << v1[i] << " ";
}
cout << endl;
cout << "v1的元素个数: " << v1.size() << endl;
cout << "v1容器的容量: " << v1.capacity() << endl;
cout << s1 << endl;
vector<int> v2(6, 5);
cout << "v2中的元素:" << endl;
for (int i = 0; i < v2.size(); i++) {
cout << v2[i] << " ";
}
cout << endl;
cout << "v2的元素个数: " << v2.size() << endl;
cout << "v2容器的容量: " << v2.capacity() << endl;
cout << s1 << endl;
vector<int> v3{ 1,2,3,4,5 };
vector<int> v4(v3);
cout << "v4中的元素:" << endl;
for (int i = 0; i < v4.size(); i++) {
cout << v4[i] << " ";
}
cout << endl;
cout << "v4的元素个数: " << v4.size() << endl;
cout << "v4容器的容量: " << v4.capacity() << endl;
cout << s1 << endl;
system("pause");
return 0;
}
结果:
相关知识点:
1. 上面我们使用了多个有参数构造函数的重载:
- vector<类型> v1(num); // 指定开始时v1中有num个元素,并且这些元素的值为对应类型的默认值。 --> vector<int> v1(10); // 指定10个元素,并且元素默认值为0
- vector<类型> v1(num,elem); // 指定可是时v1中有num个元素,并且这些元素的值为elem指定的值。 --> vector<int> v1(10,5); // 指定10个元素,并且元素值为5
- vector<类型> v1{data1...}; // 定义一个vector容器v1,并且将{}中的数据放到v1当中。--> vector<类型> v1{1,2,3,4,5}; // 初始化容器v1,v1开始就存有1-5的5个元素
- vector<类型> v2(v1); // 调用拷贝构造函数,构造v2,v2存放的内容和v1一样。
- vector<类型> v3(v1.begin(),v1.end()); // 使用另一个容器的迭代器指定一个范围。将v1中迭代器[begin(),end())范围内的数据初始化v3。 -- 注意这里的范围是左闭右开的。迭代器是什么,看后面。
- vector<类型> v4(ptr1,ptr2); // 使用指针[ptr1,ptr2)范围内的数据初始化v4 -- 注意这个区间也是左闭右开的,--> int arr[] = {1,2,3,4,5},vector<类型> v4(arr,arr+2); // 使用数组指针[arr,arr+2)区间内的数据初始化v4。
对于指针指定数据范围,一般是使用数组中的数据初始化容器的时候使用。
[arr,arr+2) , arr指向数组中数据1,arr+2指向数组中数据3。 因为区间是左闭右开的,所 以最后v4中的数据为1和2.
2. string s1(20,'-'); 表示s1中是由20个-字符组成的字符串,用于对输出的数据进行分割,方便查看。
3. capacity()函数用于返回容器的容量。
3. vector容器在尾部添加和删除元素
对vector容器在尾部添加或者删除元素是非常快的,但是对于其它位置的元素删除和添加,就很慢了,因为需要涉及到元素移动的问题。(后面说)
代码: 使用push_back()和pop_back()进行尾部元素的添加和删除
#include <iostream>
#include <stdlib.h>
#include <vector>
using namespace std;
int main(void) {
vector<int> v1;
int nub = 20;
v1.push_back(10); // 直接存入类型常量 10
v1.push_back(11); // 10,11
v1.push_back(12); // 10,11,12
v1.push_back(13); // 10,11,12,13
v1.push_back(nub); // 直接存入类型变量 10,11,12,13,20
v1.pop_back(); // 10,11,12,13
v1.pop_back(); // 10,11,12
cout << "v1 中的元素:" << endl;
for (int i = 0; i < v1.size(); i++) {
cout << v1[i] << " "; // 10,11,12
}
cout << endl;
system("pause");
return 0;
}
相关知识点:
- 1. push_back() 就是在容器的尾部(准确的说是容器中存放元素的尾部)添加一个元素,如果增加元素的时候,容器的容量不够(容器元素个数 = 容器容量),那么就会根据内部算法动态开辟内存,以存放新增数据。-- 后面会说明
- 使用push_back()添加元素,其()既可以传入类型常量,也可以传入类型变量。 (代码中已经展示)
- push_back()是值传递的,我们可以将上面代码中nub的值进行修改(在push_back()之 后),观察容器中对应位置的值是否也同样发生改变,如果有:说明是地址传递; 如果没有: 说明是值传递。很明显答案是后者。
- 2. pop_back() 就是在容器的尾部删除一个元素,容器中元素的个数-1,但是容器的容量不变。并且,此函数不需要参数。
注意: 如果容器中没有元素,那么就不能删除元素。
代码: 使用emplace_back在尾部添加元素
#include <iostream>
#include <stdlib.h>
#include <vector>
using namespace std;
int main(void) {
vector<int> v1;
int nub = 20;
v1.emplace_back(nub); // 20 不建议使用
v1.emplace_back(10); // 20,10
v1.emplace_back(100); // 20,10,100
v1.pop_back(); // 20,10
cout << "v1 中的元素:" << endl;
for (int i = 0; i < v1.size(); i++) {
cout << v1[i] << " "; // 10,11,12
}
cout << endl;
system("pause");
return 0;
}相关知识点:
- 1. emplace_back() 和 push_back() 的用法是一致的。 都是在容器尾部添加数据,而且在容量不够时开辟空间。
- 使用emplace_back()添加元素,依然可以使用pop_back()进行尾部元素的删除。
那为什么还要实现emplace_back()函数呢?
4. 使用emplace_back() 和 push_back()的区别
从上面的实现过程来看,两者的用法没有什么区别,那为什么还要定义两种不同的函数呢?
想要看出两者的区别,我们可以使用一个存放自定义类的容器,然后分别用两函数添加数据,就可以看出问题所在了。
代码:
1. 使用push_back()存放Student对象
#include <iostream>
#include <stdlib.h>
#include <vector>
using namespace std;
class Student {
public:
Student() {
cout << "调用默认构造函数!" << endl;
}
Student(int age) {
cout << "调用有参构造函数!" << endl;
}
Student(const Student& s1) {
cout << "调用拷贝构造函数!" << endl;
}
~Student() {
cout << "调用析构函数!" << endl;
}
};
int main(void) {
vector<Student> v1;
v1.reserve(10); // 将v1容器的容量设置为10
v1.push_back(Student());
// v1.push_back(Student(10));
system("pause");
return 0;
}
结果:
v1.push_back(Student()); 的结果

v1.push_back(Student(10)); 的结果
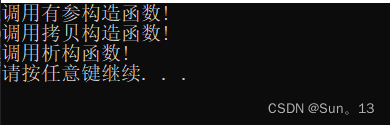
2. 使用emplace_back()函数存放Student对象
前面部分和上面一样
int main(void) {
vector<Student> v1;
v1.reserve(10); // 将v1容器的容量设置为10
v1.emplace_back();
// v1.emplace_back(10);
system("pause");
return 0;
}
结果:
v1.emplace_back(); 的结果
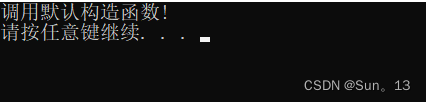
v1.emplace_back(10); 的结果

对比:
观察我们使用push_back()和emplace_back()存放类类型的结果,你会发现,使用push_back()需要调用三次函数,而使用emplace_back()只需要调用一次就行。
所以使用emplace_back的好处是: 效率更加的高。
原因:
细心的应该已经发现了,在我们使用两个函数分别往容器中存储对象的时候,会发现它们的参数不一样。
先来看push_back()的情况:
- 我们传入一个匿名对象,在构建匿名对象的时候,会调用默认构造函数。
- 然后构造的匿名对象传入push_back(), 编译器会调用拷贝构造函数,再创建一个对象,然后将这个对象放到容器中。
- 最后匿名对象被销毁调用析构函数。(如果不是匿名对象,在对象作用域结束的时候调用析构函数)
- push_back()将对象存入容器的过程中,多次调用构造函数。
- 此处使用的是匿名对象,换成局部对象也一样,只是析构调用的时机不同。使用局部对象:Student s1; push_back(s1);
再来看emplace_back的情况:
- 我们并没有像push_back()一样传入一个对象,而是直接传入数据(或者不传)。
- 在emplace_back()会根据我们传入的参数,自己去调用对应的拷贝构造函数,在容器的对应位置创建一个对象(无参的情况下调用默认构造函数)。
- emplace_back()根据我们传入的参数,调用构造函数,构造对象,存放在容器中,整个过程只调用了一次构造函数。
结论:
所以emplace_back的效率要高于push_back(),所以在两函数都被允许使用的情况下,建议使用emplace_back。
注意事项:
- emplace_back()是c++11新增的,如果所使用的编译器不支持c++11,那么还是使用push_back()。
- 注意使用emplace_back()函数一定不能像push_back()那样传参数(直接将对象作为参数),虽然语法允许,但是如果那样,效率就不会提高(无论传入局部对象还是匿名对象)。-- 所以我们前面不建议将整数放在变量中,然后将变量作为emplace_back()的参数,而是将数据直接作为参数。
- 所以在使用emplace_back(),我们应该直接传入相应的数据(如果是类,就传入与对应构造函数匹配的数据)
emplace_back()中的参数如果直接传入对象。
// 上面代码和前面的一样
int main(void) {
vector<Student> v1;
v1.reserve(10); // 将v1容器的容量设置为10
v1.emplace_back(Student(10));
system("pause");
return 0;
}结果:

会发现,效率并没有提高。
至于对象存放的过程和push_back()是一样的。
使用有参构造函数初始化存放类的容器时的情况
我们前面在使用有参构造函数的时候,可以指定容器初始化的元素个数,这其实也是一种元素的增加,那么这个增加的过程和上面是一样的吗?
分两种情况,一种不指定值,使用默认值,另一种指定值。
情况一:
int main(void) {
vector<Student> v1(10); // v1此时为空
system("pause");
return 0;
}结果:
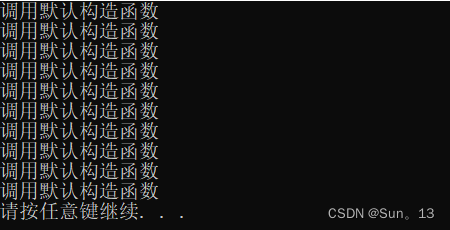
代码中,我们使用有参构造函数,在容器对象初始化的时候存放了10个元素。 会发现结果中只有调用默认构造函数构造了类对象。因为我们在初始化的时候,并没有传入默认值,所以内部就会调用默认构造函数,生成一个默认对象(空对象)。存放到容器中。
情况二:
int main(void) {
Student s1(10);
vector<Student> v1(10,s1); // v1此时为空
system("pause");
return 0;
}结果:

代码中,我们使用了s1作为初始化v1的10个空间的指定值,会发现调用了拷贝构造函数。说明我们传入s1之后,编译器会创建一个对象将s1的数据拷贝过去,然后将这个对象放到v1容器当中。
总结:
emplace_back()之所以插入的时候高效,就是因为它特殊的实现(或者说它特殊的参数),我们只要直接传入构造函数所需要的参数(默认构造就不需要传参数),内部就会根据这些参数调用对应构造函数构造对象,并且存储进去。
不会像,push_back()或者有参构造函数,要想指定存储的数据,只能在外部定义好,或者使用匿名对象的形式作为参数传递。这样会导致,编译器会多执行一次拷贝构造将传入对象的数据拷贝到内部创建的对象中,就会损失性能。
5. vector容器的元素个数和容量大小
vector容器是用来存储一类元素的动态数组,那么在存储的过程中,就会遇到容器中有多少的元素,添加元素时是否还有空间去存放元素等等。
元素个数和容器容量的区别
元素个数: 容器中实际存储了多少的元素个数。
容器容量: 就是目前容器有多少个空间。
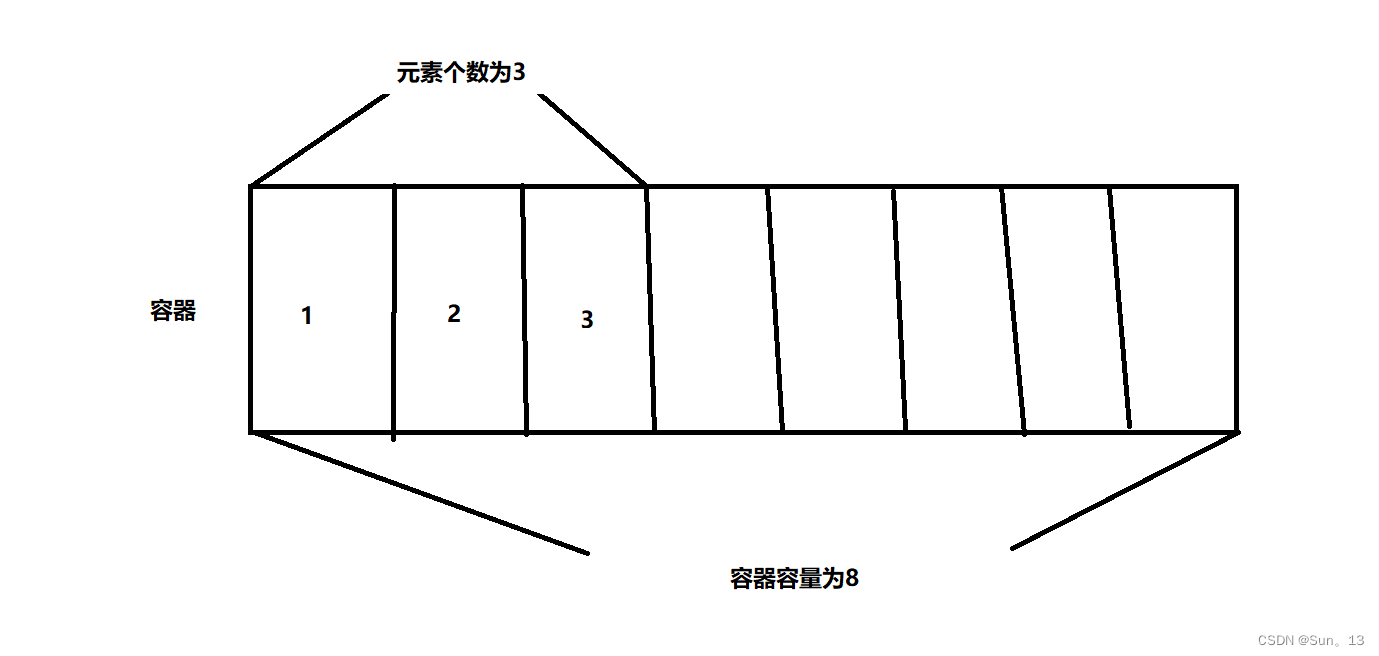
如图: 容器的容量 >= 容器的元素个数。
代码: 使用size()获取容器元素个数,使用capacity()获取元素容量
#include <iostream>
#include <stdlib.h>
#include <vector>
#include <string>
using namespace std;
int main(void) {
string s1(20, '-');
vector<int> v1;
cout << "添加元素之前: " << endl;
cout << "v1的元素个数:" << v1.size() << endl;
cout << "v1容器的容量:" << v1.capacity() << endl;
cout << s1 << endl;
cout << "添加元素之后: " << endl;
v1.emplace_back(1);
v1.emplace_back(2);
v1.emplace_back(3);
v1.emplace_back(4);
v1.emplace_back(5);
vector<int>::size_type st1 = v1.size();
vector<int>::size_type st2 = v1.capacity();
cout << "v1的元素个数:" << st1 << endl;
cout << "v1容器的容量:" << st2 << endl;
cout << s1 << endl;
system("pause");
return 0;
}结果:
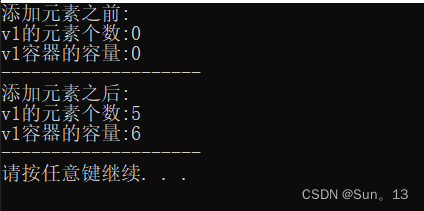
相关知识点:
- size()函数可以返回容器中当前存储的元素个数有多少个。 如果没返回0。(空对象:默认构造的对象,其的size()就返回0)。
- capacity()函数可以返回容器当前的容量是多少。如果没有返回0。(空对象:其的capacity()就返回0)
- 至于二者的区别: 请看此节第一个图。
- size_type是vector容器中内嵌的一个类型,用于表示容器大小的类型(元素个数或者容器容量)。如果要使用size_type类型,需要表明是属于哪个作用域下的。(此处为vector类作用域下)。又因为vector类是类模板,所以在使用类作用域的时候应该显示传入实例化类型。
- 所以使用vector中的size_type类型 --> vector<int>:: size_type(这样就可以使用这个类型来定义变量了,定义的变量用来存放容器的大小) -- 代码中已经使用。
- 我们在写size()或者capacity()函数的时候,会发现函数提示其返回值为size_t类型(vs2022)。其实size_t你可以简单看做是一个无符号整形。那我们可以直接使用size_t或者是int(代码中有使用)类型的变量,为什么还要在类内部定义一个这样的类型呢?
- 我想是为了代码更加的兼容吧,1. 虽然vs2020返回的是size_t,但是你使用别的编译器之后,返回值可能会不一样。(有可能返回的就是size_type类型或者其它) 2. 而且如果我们使用int类型去接收这个返回值会触发一个警告(size_t转换为int可能会导致数据丢失)。我们使用了size_type之后那么其内部就会自动转换,就不会有上面的两种问题,使得代码的兼容性更高。
问题: 上面的运行结果,我们只存放了5个数据,为什么容器容量为6呢?
这主要是因为vector是一个动态数组,如果容量不够会动态的开辟空间。
6. vector动态开辟空间以及注意事项
前面说到vector是一个动态的数组,就是如果空间不够会动态的去分配空间。那么具体是怎么分配的呢? 或者说再什么是否分配?等。
1. 什么时候动态分配?
当元素个数 == 容器容量(v1.size() == v1.capacity())的时候,如果此时我们向容器中存放数据,那么就会动态开辟内存了。(不然数据都放不下了)。
构造函数,insert(),emplace(),push_back(),emplace_back(),resize(),assign()这些函数(后面都会介绍)都会在空间不够(容器容量==元素个数)时,动态开辟空间。
比如: 使用默认构造函数创建的vector对象,其是一个空对象,也就是v.size() == v.capacity() == 0; 这时候,元素个数等于容器容量,我们要添加新的元素(调用push_back()等接口),显然空间是不够的。 所以这时候就需要动态开辟内存了。(是内部实现,不需要我们手动开辟)
注意: 如果空间足够(v.capacity() > v.size()),那么就不会开辟空间,直接将数据存放到容器中。
2. 怎样动态新增内存?
vector是一个动态数组,既然是数组,那么其物理内存就是一片连续的空间。 所以我们要新增空间,就必须在原来空间后续位置进行增加。 如图:

但是,在实际开辟内存的过程中并不是这么的理想,因为vector的内存是连续的,所以我们开辟内存会考虑在原有的内存后面增加内存,但是如果后面的内存中已经存有了数据怎么办呢? 你不能将人家的数据给覆盖掉吧。
所以,鉴于上面的情况,编译器在vector容器新增空间的时候(不同的编译器可能有不同的处理,但是原理都一样),会执行三步:
- 会在另外一个位置,开辟一片空间,新空间的大小 > 原来内存的大小(具体多大根据内部的算法决定)。
- 将原来位置的原有数据,原样拷贝到新开辟空间的对应位置(元素在容器中的相对位置不变),然后在将新增数据增加进去(根据我们的要求进行添加)。 --> 当然,如果你最开始就没有空间(使用默认构造定义对象),那自然也没有拷贝数据这一环节。
- 拷贝结束后,会删除原来位置的数据,释放内存。
我们用代码来验证这个过程:
#include <iostream>
#include <stdlib.h>
#include <vector>
#include <string>
using namespace std;
class Student {
public:
Student() {
cout << "调用默认构造函数" << endl;
}
Student(int age) {
cout << "调用有参构造函数" << endl;
}
Student(const Student& stu) {
cout << "调用拷贝构造函数" << endl;
}
~Student() {
cout << "调用析构函数" << endl;
}
};
int main(void) {
string s1(20, '-');
vector<Student> v1(1); // v1此时为空
cout << "此时的v1容器的大小:" << endl;
cout << "v1容器的元素个数:" << v1.size() << endl;
cout << "v1容器的容量:" << v1.capacity() << endl;
cout << s1 << endl; // 分割线
cout << "使用push_back()添加数据后:" << endl;
v1.push_back(Student());
cout << s1 << endl;
cout << "使用emplace_back()添加数据后:" << endl;
v1.emplace_back(10); // 注意emplace_back()的用法
cout << s1 << endl;
system("pause");
return 0;
}结果:

我们使用有参构造函数初始化v1,使其最开始就拥有一块空间(这样v1就不是空对象了,因为往空对象中添加数据是不会移动数据的(上面说到原因)),此时容器的元素个数 == 容器容量。当我们再添加数据的时候,就会动态开辟内存了。
我们分别使用了push_back()和emplace_back()进行添加数据,观察构造函数调用情况。
使用push_back():
从结果中会发现:
- 一次无参构造: 用于构造我们传入的匿名变量。
- 第一个拷贝构造函数:就是编译器创建一个对象将传入对象的数据拷贝过去。
- 第二个拷贝构造函数: 就是我们在开辟内存的时候,会在新的位置去开辟空间,会将原有的数据(因为最开始我们存入了一个对象),拷贝到新的空间上去,这就需要调用拷贝构造函数。
- 第一个析构函数:我们将数据拷贝到新空间之后,原有空间的数据就会被删除,调用析构函数。
- 第二个析构函数: 这行代码结束,我们传入的匿名函数销毁,调用析构函数。
使用emplace_back():
从结果发现:
- 我们之所以要将emplace_back()进行测试,是因为使用其添加数据的效率要高于push_back(),那么我们看看在开辟空间的过程中是否也会高效率。
- 一个有参构造函数:是emplace_back()根据我们传入的参数调用对应的构造函数创建对象
- 第一个拷贝构造函数:因为我们在emplace_back()添加数据之前,容器中已经存在两个数据了,所以第一个构造函数就是将第一份数据从旧空间拷贝到新空间。
- 第二个拷贝构造函数: 将第二份数据拷贝从旧空间到新空间
- 两个析构函数:就是析构原来空间的两份数据。
结论:
从上面的分析可以看出,使用emplace_back()在开辟空间的时候其实是一样的,都是开辟新空间,将老空间的数据拷贝过去。
注意:
由于开辟新空间,会切换位置,所以如果我们在开辟新空间之前定义的指针,引用,迭代器旧不能再使用了,因为内存的位置发生变化,不是原来的位置了。如果我们在开辟新内存后还需要使用这些量,那就建议重新定义。
3. 为什么上面我们存放5个数据,打印容量却是6?
这个主要的原因就是因为2.怎样动态新增内存中提到的情况,
2.中说到开辟新内存,会将原来空间的数据拷贝到新的内存中,这无疑是很耗费性能的,添加一个数据,可能就得进行好几份数据的拷贝,这显然效率是不高的。
原因:
鉴于上面的情况,如果我们频繁的去开辟内存,那无疑时间都浪费在了数据拷贝上,所以编译器在每次开辟空间时,会多开辟几个空间,这样如果后面再添加数据,就不需要新增空间,也就不用新旧空间数据拷贝了。
所以,多开空间是为了减少开辟新空间的次数(减少新旧内存的数据拷贝次数),至于多开辟多少的空间,是根据内部算法来决定的。
4. 既然在重新开辟内存那么耗时,我们有什么办法呢?
首先emplace_back()和emplace()并不能提高新开内存造成的效率降低。-- 我们前面已经验证了。
那么我们应该用什么办法呢?
办法:
- 使用函数reserve()开辟足够的空间,这样存数据的时候就可以保证我们又足够的容量去存放数据了,就不用开辟内存了。
- 那如果我们开辟的多了,不是浪费空间吗? 如果我们将数据都存储完了,但是我们提前开辟的内存还没有用完,我们可以使用shrink_to_fit()函数,它可以将当前容器的容量缩小到和元素个数相同。
- 如果需要多次开辟空间,可以使用list容器。
办法中,我们提到了两个函数,我们在代码中使用一下。
代码: 使用reserve()函数增加容器容量,使用shrink_to_fit()函数将容量缩减到与元素个数相同。
#include <iostream>
#include <stdlib.h>
#include <vector>
#include <string>
using namespace std;
class Student {
public:
Student() {
cout << "调用默认构造函数" << endl;
}
Student(int age) {
cout << "调用有参构造函数" << endl;
}
Student(const Student& stu) {
cout << "调用拷贝构造函数" << endl;
}
~Student() {
cout << "调用析构函数" << endl;
}
};
int main(void) {
string s(20, '-');
vector<Student> v1; // v1此时为空
v1.reserve(10); // 提前开辟容器容量
cout << s << endl;
cout << "使用reserve():" << endl;
cout << "v1的元素个数:" << v1.size() << endl;
cout << "v1的容量大小::" << v1.capacity() << endl;
cout << s << endl;
v1.emplace_back(10);
v1.emplace_back(20);
v1.emplace_back(30);
v1.shrink_to_fit();
cout << s << endl;
cout << "使用shrink_to_fit():" << endl;
cout << "v1的元素个数:" << v1.size() << endl;
cout << "v1的容量大小::" << v1.capacity() << endl;
cout << s << endl;
system("pause");
return 0;
}结果:

分析:
1. 我们先来说一下,为什么结果中会有那么多构造函数?
这是因为,我们使用shrink_to_fit()函数进行空间缩减时,它并不是将原来空间进行缩减,也是在一个新的位置开辟一片等于数据元素个数的空间,然后再将旧位置的元素都拷贝过去,然后删除原位置的数据。
因为代码中,原数据有三份,所以相应的构造函数和析构函数调用了三次。
既然使用shrink_to_fit()函数之后,还需要新旧数据的拷贝,但是你这样只会拷贝一次,如果你不提前开辟够足够的内存,同一份数据你可能得拷贝好几次。所以还是会提高性能的。
2. 其它的部分
- 使用reserve()函数之后,会提前扩充容器的容量(原理一样),并且不会在空间中放入数据。
- 使用shrink_to_fit()函数之后,容量的大小和元素的个数相同了。
7. vector容器在指定位置插入元素
首先插入操作有两个函数可以实现,一个是insert(),一个是emplace()。
代码: 使用insert()函数在指定位置添加元素
#include <iostream>
#include <stdlib.h>
#include <vector>
#include <string>
using namespace std;
int main(void) {
vector<int> v1{1,2,3,4,5};
vector<int> v2;
v2.insert(v2.begin(), 5); // 在v2的开始位置插入5 5
v2.insert(v2.begin(), 2, 3); // 在v2的开始位置插入2个3 3 3 5
v2.insert(v2.begin(), { 1,2 }); // 在v2的开始位置插入1,2 1,2,3,3,5
v2.insert(v2.begin(), v1.begin(), v1.begin() + 2); // 将v1中的前两个数据添加到v2中 1,2,1,2,3,3,5
cout << "v2的元素个数:" << v2.size() << endl;
cout << "v2的容量:" << v2.capacity() << endl;
for (int i = 0; i < v2.size(); i++) {
cout << v2[i] << " "; // 1,2,1,2,3,3,5
}
cout << endl;
system("pause");
return 0;
}结果:

相关知识点:
- v1.insert(pos,num); // 将num插入到pos迭代器指定的位置 --> v1.insert(v1.begin(),5) ; // 将5插入到v1开始的位置
- v1.insert(pos,n,num); // 将n个num插入到pos迭代器指定的位置 --> v1.insert(v1.begin(),5,3); // 在v1的开始位置插入5个3
- v1.insert(pos,{data...}); // 将{}中的数据插入到pos迭代器指定的位置 --> v1.insert(v1.begin(),{1,2,3}); // 在v1开始的位置插入1,2,3
- v1.insert(pos,其它容器.迭代器1,其它容器.迭代器2); // 将别的容器中迭代器1和迭代器2范围内的数据插入到v1的开始位置。 --> v1.insert(v1.begin(),v2.begin(),v2.begin()+2); // 将v2中的前三个数据插入到v1的开始位置
代码: 使用emplace()函数在指定位置插入数据
#include <iostream>
#include <stdlib.h>
#include <vector>
#include <string>
using namespace std;
int main(void) {
vector<int> v2;
v2.emplace(v2.begin(),5); // 5
v2.emplace(v2.begin(),4); // 4,5
v2.emplace(v2.begin(),3); // 3,4,5
v2.emplace(v2.begin(),2); // 2,3,4,5
v2.emplace(v2.begin(),1); // 1,2,3,4,5
cout << "v2的元素个数:" << v2.size() << endl;
cout << "v2的容量:" << v2.capacity() << endl;
for (int i = 0; i < v2.size(); i++) {
cout << v2[i] << " ";
}
cout << endl;
system("pause");
return 0;
}结果:

相关知识点:
emplace()函数添加元素时,其只有一种重载的形式。
在如果是添加类对象,那么就直接在第二个参数后面,传入和对象构造函数相对应的数据。
vector插入元素的效率
vector只有在尾部添加数据是相当快的。
如果在其它的位置添加数据, 效率会很慢。 --> 因为需要移动原来的元素。
比如: 1,2,3,4,5 我们要在2的后面添加一个6, 那么需要先就那个2后面的元素向后移动一个空间,再将6放到2的后面。 1,2,6,3,4,5
在任意位置添加数据,并不是vector(或者数组)的长处,它的长处是可以快速的访问元素。
8. vector容器元素的访问
代码: 使用[]运算符和at()函数随机访问元素
#include <iostream>
#include <stdlib.h>
#include <vector>
#include <string>
using namespace std;
int main(void) {
string s1(20, '-');
vector<int> v2;
v2.emplace_back(1);
v2.emplace_back(2);
v2.emplace_back(3);
v2.emplace_back(4);
v2.emplace_back(5);
cout << "使用[]运算符访问数据:" << endl;
cout << "v2[2] = " << v2[2] << endl;
cout << s1 << endl;
cout << "使用at()函数访问数据:" << endl;
cout << "v2.at(0) =" << v2.at(0) << endl;
cout << s1 << endl;
// 通过[]和at()对数据进行修改
v2[2] = 100;
v2.at(0) = 10;
cout << "修改数据之后的情况:" << endl;
cout << "使用[]运算符访问数据:" << endl;
cout << "v2[2] = " << v2[2] << endl;
cout << s1 << endl;
cout << "使用at()函数访问数据:" << endl;
cout << "v2.at(0) =" << v2.at(0) << endl;
cout << s1 << endl;
system("pause");
return 0;
}结果:
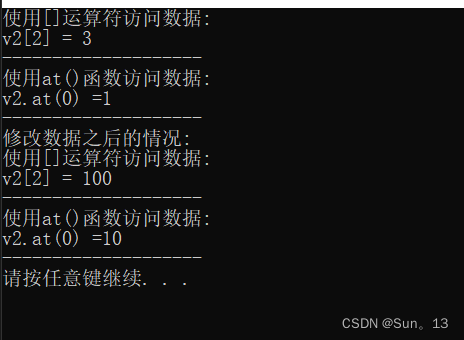
相关知识点:
- v1[nub]; // 这样可以访问到动态数组中下标为nub的数据。
- 注意: 数组的下标是从0开始的,而且使用[]访问数据应该注意下标不能越界。(不能超出存储的元素个数-1)
- v1.at(nub); // 这样可以访问到动态数组中下标为nub的数组。
- 注意: 数组的下标是从0开始的,而且使用at()访问数据应该注意下标不能越界。(不能超出存储的元素个数-1)
从上面两种访问方式可以看出,没有什么区别,那为什么弄两个呢?
因为: 在at()函数中使用了异常机制。 当[]访问的时候,如果下标越界就会终止程序,而使用at()下标越界会抛出一个越界的异常(out_of_range),我们可以使用exception异常类进行捕获并且处理。(如果不处理也会出错)
- 使用[]和at()访问数据是它们返回的是对应数据的引用。 --> 所以,我们可以通过[]和at()的返回值直接修改访问位置的数据。(代码中已经使用)
代码: 使用front()函数访问容器第一个数据, 使用back()函数访问容器的最后一个数据
#include <iostream>
#include <stdlib.h>
#include <vector>
#include <string>
using namespace std;
int main(void) {
string s1(20, '-');
vector<int> v2;
v2.emplace_back(1);
v2.emplace_back(2);
v2.emplace_back(3);
v2.emplace_back(4);
v2.emplace_back(5);
cout << "使用front()函数访问数据:" << endl;
cout << "v2.front() = " << v2.front() << endl;
cout << s1 << endl;
cout << "使用back()函数访问数据:" << endl;
cout << "v2.back() =" << v2.back() << endl;
cout << s1 << endl;
// 通过front()和back()对数据进行修改
v2.front() = 100;
v2.back() = 10;
cout << "修改数据之后的情况:" << endl;
cout << "使用front()函数访问数据:" << endl;
cout << "v2.front() = " << v2.front() << endl;
cout << s1 << endl;
cout << "使用back()函数访问数据:" << endl;
cout << "v2.back() =" << v2.back() << endl;
cout << s1 << endl;
system("pause");
return 0;
}结果:
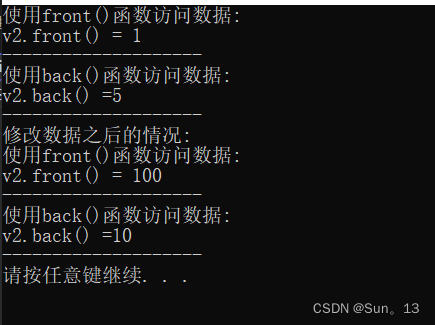
相关知识点:
- v1.front(); // 可以访问到v1容器的第一个元素
- v1.back(); // 可以访问到v1容器的最后一个元素
- 因为front()和back()函数返回的是对应数据的引用,所以可以通过这两个函数的返回值对访问的数据进行修改。 (代码中已经使用了)
还有一种方式是使用迭代器来访问数据,这个我们在迭代器的一节中说。
9.vector容器的迭代器
| 成员函数 | 功能 |
|---|---|
| begin() | 返回指向容器中第一个元素的正向迭代器;如果是 const 类型容器,在该函数返回的是常量正向迭代器。 |
| end() | 返回指向容器最后一个元素之后一个位置的正向迭代器;如果是 const 类型容器,在该函数返回的是常量正向迭代器。此函数通常和 begin() 搭配使用。 |
| rbegin() | 返回指向最后一个元素的反向迭代器;如果是 const 类型容器,在该函数返回的是常量反向迭代器。 |
| rend() | 返回指向第一个元素之前一个位置的反向迭代器。如果是 const 类型容器,在该函数返回的是常量反向迭代器。此函数通常和 rbegin() 搭配使用。 |
| cbegin() | 和 begin() 功能类似,只不过其返回的迭代器类型为常量正向迭代器,不能用于修改元素。 |
| cend() | 和 end() 功能相同,只不过其返回的迭代器类型为常量正向迭代器,不能用于修改元素。 |
| crbegin() | 和 rbegin() 功能相同,只不过其返回的迭代器类型为常量反向迭代器,不能用于修改元素。 |
| crend() | 和 rend() 功能相同,只不过其返回的迭代器类型为常量反向迭代器,不能用于修改元素。 |

代码: 使用begin()和end()
#include <iostream>
#include <stdlib.h>
#include <vector>
#include <string>
using namespace std;
int main(void) {
string s1(20, '-');
vector<int> v2;
v2.emplace_back(1);
v2.emplace_back(2);
v2.emplace_back(3);
v2.emplace_back(4);
v2.emplace_back(5);
vector<int>::iterator b_it1 = v2.begin();
vector<int>::iterator e_it1 = v2.end();
/*对迭代器进行递增和递减操作*/
b_it1++;
e_it1--;
/* 使用迭代器访问数据 */
for (; b_it1 < e_it1; b_it1++) {
cout << *b_it1 << " ";
}
cout << endl;
system("pause");
return 0;
}结果:
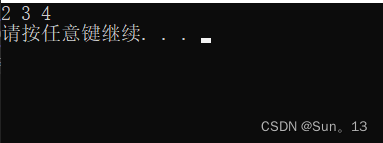
相关知识点:
在上面的表格中,已经说明了几种返回迭代器的函数的具体情况。
- 迭代器是STL的重要组成部分,它的主要作用就是用于遍历容器的。
- 迭代器是容器内嵌的类型:iterator(和size_type类似),所以我们要定义迭代器的变量和size_type是类似的,vector<int>::iterator it; 就定义了一个指向vector<int>的迭代器。
- 迭代器你可以把它看做是一个指针,指向容器中对应数据的所在的位置。而且也可以对它进行与指针类似的操作。
- 可以对迭代器进行++,--,或者 +一个数(+5等),来使迭代器指向下一个位置的数据。
- 可以使用解引运算符(*),来访问迭代器指向位置的具体数据。
- 可以使用下标运算符([]), 来访问对应位置的数据。(和指针是一个原理)
- begin()和end()既可以返回普通迭代器类型: iterator ,也可以返回常迭代器类型: const_iterator, 要看具体的使用场景。
- 因为迭代器可以看做指针,所以我们可以使用迭代器修改其指向的数据。 *it = 5; 就将it指向的数据修改为5。
- begin()和end()是值返回,也就是如果将其返回值赋值给别的迭代器,对这个迭代器++等操作,不会影响其返回值。
代码: 使用rbegin()和rend()
int main(void) {
vector<int> v1{ 1,2,3,4,5 };
vector<int>::reverse_iterator it1 = v1.rbegin();
vector<int>::reverse_iterator it2 = v1.rend();
for (; it1 < it2; it1++) {
cout << *it1 << endl;
}
system("pause");
return 0;
}结果:

相关知识点:
- rbegin()和rend()返回的是一个反向迭代器类型: reverse_iterator。
- 在前面的表格中,反向迭代器和正向迭代器是相反的。但是,它们的代码除类型不同外,其余都没有什么区别。
- 就比如: 上面的for循环和正向的for循环是一样的,那是因为在内部进行了设置。实际我们对逆向迭代器++或者其他+操作,其实是让它指向上一个位置的数据,--或-操作正好相反。(这正好是和正向迭代器是相反的)
- 因为迭代器可以看做指针,所以我们可以使用迭代器修改其指向的数据。 *it = 5; 就将it指向的数据修改为5。
- rbegin()和rend()是值返回,也就是如果将其返回值赋值给别的迭代器,对这个迭代器++等操作,不会影响其返回值。
cbegin(),cend(),crbegin(),crend()
- cbegin()和cend()返回的迭代器类型为: const_iterator;
- crbegin()和crend()返回的迭代器类型为: 常逆向迭代器;
- 它们返回的迭代器的操作和前面的是一样的,唯一不同的是不能通过常迭代器来修改器 指向的数据。
- 这几个函数是值返回,也就是如果将其返回值赋值给别的迭代器,对这个迭代器++等操作,不会影响其返回值。
10.insert()的返回值
代码:
int main(void) {
vector<int> v1{ 1,2,3,4,5 };
vector<int>::iterator it = v1.insert(v1.begin(), 5);
cout << *it << endl;
system("pause");
return 0;
}结果:

相关知识点:
- insert()函数插入单个元素的时候,会返回一个指向插入位置的迭代器。
- insert()函数插入多个数据的时候, 会返回void。
11. vector容器删除元素
代码: 使用erase()和clear()
#include <iostream>
#include <stdlib.h>
#include <vector>
#include <string>
using namespace std;
int main(void) {
string s(20, '-');
vector<int> v1{ 1,2,3,4,5 };
v1.erase(v1.begin()); // 删除容器首位置的数据 2,3,4,5
v1.erase(v1.begin(), v1.begin() + 1); // 删除迭代器范围[beg,end)的数据,此处删除第一个数据 3,4,5
cout << "erase()函数调用:" << endl;
cout << "v1的元素个数:" << v1.size() << endl;
cout << "v1的容量:" << v1.capacity() << endl;
for (vector<int>::iterator it = v1.begin(); it != v1.end(); it++) {
cout << *it << " ";
}
cout << endl;
cout << s << endl;
v1.clear(); // 清空容器
cout << "clear()函数调用:" << endl;
cout << "v1的元素个数:" << v1.size() << endl;
cout << "v1的容量:" << v1.capacity() << endl;
for (vector<int>::iterator it = v1.begin(); it != v1.end(); it++) {
cout << *it << " ";
}
cout << endl;
cout << s << endl;
system("pause");
return 0;
}结果:

相关知识点:
- erase(pos); // 删除pos迭代器指向位置的元素。
- erase(beg,end); // 删除容器[beg,end)迭代器范围内的数据。(范围是左闭右开)
- clear(); // 函数直接将容器内部的元素清0。
注意: 上面的两种删除函数,只会删除容器中的元素,并不会改变容器的容量。
erase()函数的返回值
代码:
int main(void) {
string s(20, '-');
vector<int> v1{ 1,2,3,4,5 };
vector<int>::iterator it = v1.erase(v1.begin());
cout << *it << endl; // 输出2
system("pause");
return 0;
}
- erase()无论删除指定位置的数据,还是删除指定范围内的数据,都会返回指向被删除元素的下一个元素的迭代器。
- 代码中,我们删除1,之后接收返回的迭代器,并且访问其指向元素,为2。(第二个数据)
erase()和循环结合删除指定元素
我们以for循环为例子:
#include <iostream>
#include <stdlib.h>
#include <vector>
#include <string>
using namespace std;
int main(void) {
string s(20, '-');
vector<int> v1{ 1,2,3,4,5 };
for (vector<int>::iterator it = v1.begin(); it != v1.end(); ) {
if (*it == 1) {
it = v1.erase(it);
}
else {
cout << *it << " "; // 输出2,3,4,5
it++;
}
}
cout << endl;
system("pause");
return 0;
}相关知识点:
- 我们要删除容器中值为1的数据,使用迭代器it指向容器开始的位置,然后*访问其指向的数据,判断是否为1。如果不是,那么就++指向下一个位置的数据。知道找到1,或者找不到。
- 找到1之后,此时it指向了它,那么我们可以使用erase(it)删除此元素。
注意事项(切记):
我们此处的it++放到了循环体中,并没有放到循环条件中。那是因为放到循环条件中就会出错。
看图:
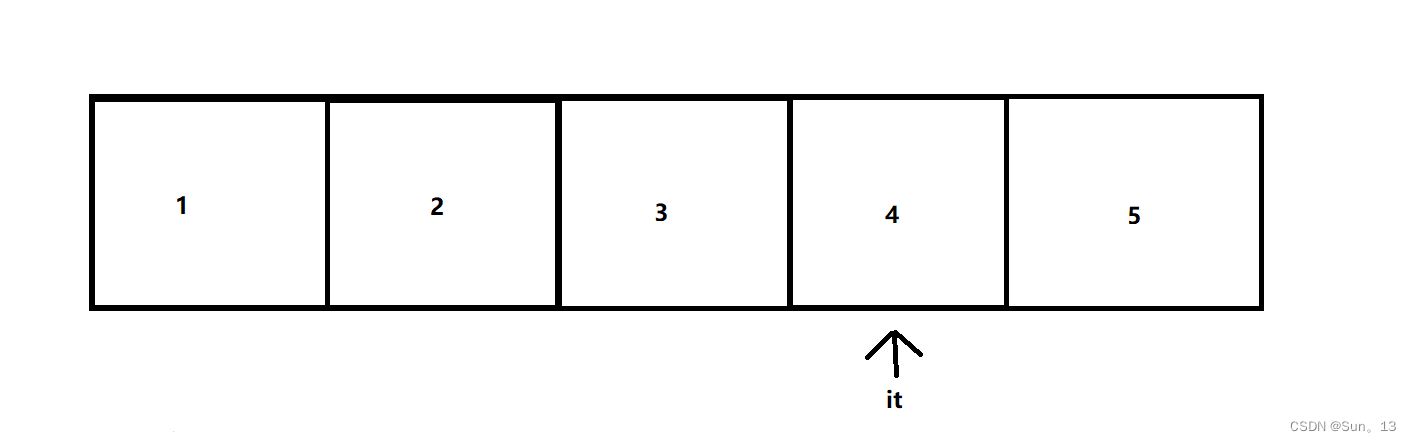
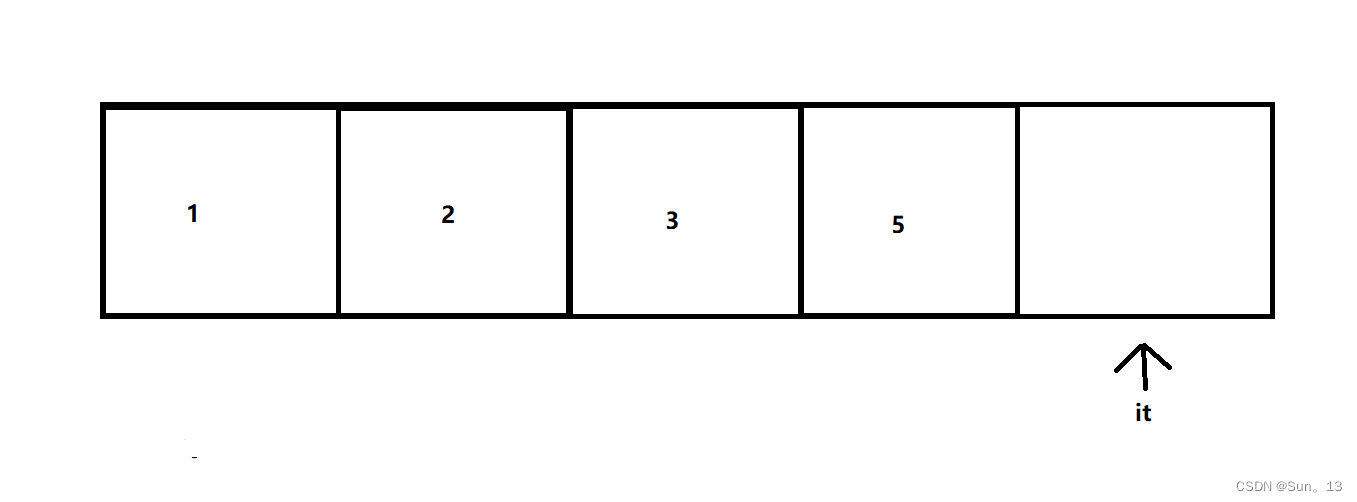
我们在遍历的过程中找到了要删除的数据4,然后调用erase()函数删除了它,这时候后面的元素就会向前移动,然后此时如果我们再对it++,it就会指向下一个位置,但是由于原来在此处的数据已经移动到前面了,此处已经没有数据了,所以我们输出it指向的数据时,就会出现越界问题。
那我们怎么办?
因为erase()返回的是下一个位置的迭代器,所以在我们删除的时候,将其返回值赋值给it,此时it就指向删除元素的下一个元素了,这样就不会越界了。
在没有删除的时候就对it++继续寻找要删除的值。(如果it++放在循环条件,在删除数据的时候一定会对it++,这样又会越界了)
12. vector容器赋值
代码: 使用=运算符重载和assign()函数
#include <iostream>
#include <stdlib.h>
#include <vector>
#include <string>
using namespace std;
int main(void) {
string s(20, '-');
vector<int> v1{ 1,2,3,4,5 };
vector<int> v2;
v2 = v1; // 将v1中的数据赋值给v2
cout << "v2的元素:" << endl;
for (vector<int>::iterator it = v1.begin(); it != v1.end(); it++) {
cout << *it << " ";
}
cout << endl << s << endl;
// 第一种用法
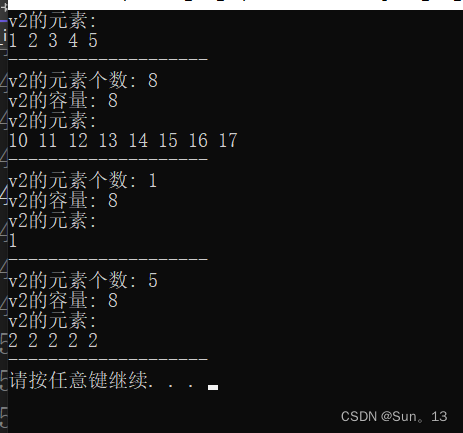
v2.assign({ 10,11,12,13,14,15,16,17 });
cout << "v2的元素个数: " << v2.size() << endl;
cout << "v2的容量: " << v2.capacity() << endl;
cout << "v2的元素:" << endl;
for (vector<int>::iterator it = v2.begin(); it != v2.end(); it++) {
cout << *it << " ";
}
cout << endl << s << endl;
// 第二种用法
v2.assign(v1.begin(),v1.begin()+1);
cout << "v2的元素个数: " << v2.size() << endl;
cout << "v2的容量: " << v2.capacity() << endl;
cout << "v2的元素:" << endl;
for (vector<int>::iterator it = v2.begin(); it != v2.end(); it++) {
cout << *it << " ";
}
cout << endl << s << endl;
// 第三种用法
v2.assign(5,2);
cout << "v2的元素个数: " << v2.size() << endl;
cout << "v2的容量: " << v2.capacity() << endl;
cout << "v2的元素:" << endl;
for (vector<int>::iterator it = v2.begin(); it != v2.end(); it++) {
cout << *it << " ";
}
cout << endl << s << endl;
system("pause");
return 0;
}结果:
相关知识点:
- v2 = v1; // 调用赋值运算符的重载,将v1中的元素赋值到v1中去
- v1.assign(n,elem); // 将n个elem元素放到容器中
- v1.assign({data...}); // 将{}中的数据放到容器中
- v1.assign(beg,end); // 将[beg,end)迭代器范围内的数据放到容器中(左闭右开)
注意:
- 使用assign()将对应数据放到容器中的时候,会先将容器中的原来数据都删除掉,然后放入添加的数据。(会改变容器的元素个数)
- 如果使用assign()函数放入的数据超过容器的容量,那么就会扩充容器的容量,然后放入数据。
- 如果放入的数据小于等于容器的容量,那么就不会改变容器的容量。
其它的赋值方法:
- 我们还可以使用[],at(),front(),back()和不是常迭代器来对相应的数据进行赋值(修改),前面已经说过了。
13. resize()重设容器大小(准确来说是元素个数)
代码:
#include <iostream>
#include <stdlib.h>
#include <vector>
#include <string>
using namespace std;
int main(void) {
string s(20, '-');
vector<int> v1{ 1,2,3,4,5 };
vector<int> v2{ 10,20,30,40,50 };
cout << "在调用resize()之前:" << endl;
cout << "v1的元素个数: " << v1.size() << endl;
cout << "v1的容量: " << v1.capacity() << endl;
cout << "v1的元素:" << endl;
for (vector<int>::iterator it = v1.begin(); it != v1.end(); it++) {
cout << *it << " ";
}
cout << endl << s << endl;
cout << "在调用resize()之前:" << endl;
cout << "v2的元素个数: " << v2.size() << endl;
cout << "v2的容量: " << v2.capacity() << endl;
cout << "v2的元素:" << endl;
for (vector<int>::iterator it = v2.begin(); it != v2.end(); it++) {
cout << *it << " ";
}
cout << endl << s << endl;
// 第一种用法
v1.resize(3);
v2.resize(3, 5);
cout << "在调用resize(3)之后:" << endl;
cout << "v1的元素个数: " << v1.size() << endl;
cout << "v1的容量: " << v1.capacity() << endl;
cout << "v1的元素:" << endl;
for (vector<int>::iterator it = v1.begin(); it != v1.end(); it++) {
cout << *it << " ";
}
cout << endl << s << endl;
cout << "在调用resize(3,5)之后:" << endl;
cout << "v2的元素个数: " << v2.size() << endl;
cout << "v2的容量: " << v2.capacity() << endl;
cout << "v2的元素:" << endl;
for (vector<int>::iterator it = v2.begin(); it != v2.end(); it++) {
cout << *it << " ";
}
cout << endl << s << endl;
// 第二种用法:
v1.resize(10);
v2.resize(10, 5);
cout << "在调用resize(10)之后:" << endl;
cout << "v1的元素个数: " << v1.size() << endl;
cout << "v1的容量: " << v1.capacity() << endl;
cout << "v1的元素:" << endl;
for (vector<int>::iterator it = v1.begin(); it != v1.end(); it++) {
cout << *it << " ";
}
cout << endl << s << endl;
cout << "在调用resize(10,5)之后:" << endl;
cout << "v2的元素个数: " << v2.size() << endl;
cout << "v2的容量: " << v2.capacity() << endl;
cout << "v2的元素:" << endl;
for (vector<int>::iterator it = v2.begin(); it != v2.end(); it++) {
cout << *it << " ";
}
cout << endl << s << endl;
system("pause");
return 0;
}结果:

相关知识点:
- resize(nub); // 将容器的容量调整为nub大小
- resize(nub,elem); // 将容器的容量调整为nub大小,并且填充值elem。
其实resize()可以将容器容量增大,也可以将容器容量缩小。
增大容量:
- resize(nub); // nub的值大于当前容器的容量,那么就会将当前容器的容量扩充为nub,并且将增加的空间中,放入默认值。(int的话为0,其它类型放入对应默认值) 并且不会影响原来数据。
- resize(nub,elem); // 和上麦那的过程类似,只不过是将值elem放到新增的空间中。
- 上面两个函数,如果只是大于容器的元素个数,并不大于容器的容量,那么不会影响容器容量,只会在相应位置放入默认值或者指定的值。
缩小容量:
- resize(nub); // nub值小于容器元素个数的时候,就会保存容器中前nub个元素,将后面的元素都删除掉。但是不影响容器容量。
- resize(nub,elem); // 和上面是一样的,当nub<容器的元素个数的时候,加不加elem都一样
14. vector的其它函数
代码: swap()函数
#include <iostream>
#include <stdlib.h>
#include <vector>
#include <string>
using namespace std;
int main(void) {
string s(20, '-');
vector<int> v1{ 1,2,3 };
vector<int> v2{ 10,20,30,40,50 };
v2.swap(v1);
cout << "v1:" << endl;
cout << v1.size() << endl;
cout << v1.capacity() << endl;
for (int i = 0; i < v1.size(); i++) {
cout << v1[i] << " ";
}
cout << endl << s << endl;
cout << "v2:" << endl;
cout << v2.size() << endl;
cout << v2.capacity() << endl;
for (int i = 0; i < v2.size(); i++) {
cout << v1[i] << " ";
}
cout << endl << s << endl;
system("pause");
return 0;
}结果:

相关知识点:
- swap()函数可以将两个容器的数据进行互换,并且会互换它们的元素个数和容器大小。
代码: data()函数
int main(void) {
string s(20, '-');
vector<int> v1{ 1,2,3 };
int* ptr = v1.data();
cout << *ptr << endl; // 输出1
system("pause");
return 0;
}相关知识点:
- data()函数会返回指向容器首元素的指针,类型和容器中存放类型一致。
代码: max_size()函数
int main(void) {
string s(20, '-');
vector<int> v1{ 1,2,3 };
cout << v1.max_size() << endl; // 4611686018427387903
system("pause");
return 0;
}相关知识点:
- max_size()会返回这个容器最多可以存储多少个这种类型的数据。
- 但是并不一定就能存储返回的那么多,这样根据你电脑的内存,编译器等共同决定的。
15. vector其它的注意事项
- 拷贝构造函数,vector<int> v1(v2); 如果v2的元素个数为5,容量为10。经过拷贝构造函数,v2的元素个数和容量都为5。(也就是不会拷贝容量)
- 赋值运算符也是类似的
- 使用构造函数在初始化时就在容器中存放相应的数据(不指定就存放对应默认数据),而且此时容器的容量等于元素的个数。
- 注意初始化列表是c++11新增的特性,也就是说vector<int> v1{1,2,3,4,5}; 在不支持c++11特性的编译器上不能通过编译。