原文地址:https://towardsdatascience.com/the-research-agent-4ef8e6f1b741
2023 年 8 月 29 日
问题简介
在2021年,开始应对基于大量文本回答问题的挑战。在预训练transformers之前的时代,这个问题很难破解。
人工智能和大型预训练transformers的快速进步正在从根本上深刻地改变技术世界。
应对基于大量文本回答问题的总体思路是制作个可以处理任何复杂知识库的自主研究代理。
研究代理
在这里,我将讨论一个自主人工智能研究代理的设计和实现,它可以解决具有深度推理能力的多跳KBQA问题。
需要研究代理的原因
向 ChatGPT 询问了几个有关《摩诃婆罗多》的问题。我对一些问题得到了很好的答案。然而,他们大多数人缺乏严谨性。这是预期的。GPT 在通用数据集上进行训练。它可以很好地理解和解释自然语言。它也可以很好地推理。然而,它并不是任何特定领域的专家。因此,虽然它可能对《摩诃婆罗多》有一些了解,但它可能不会给出经过深入研究的答案。有时 GPT 可能根本没有任何答案。在这些情况下,它要么谦虚地拒绝回答问题,要么自信地编造问题(幻觉)。
实现 KBQA 的第二个最明显的方法是使用检索 QA 提示。这就是 LangChain 开始变得非常有用的地方。
检索质量保证
对于那些不熟悉 LangChain 库的人来说,这是在代码中使用 GPT 等 LLM 的最佳方法之一。这是使用 LangChain 的 KBQA 实现。
使用检索器进行QA检查
总而言之,以下是在任何文档主体上实现 KBQA 的步骤:
- 将知识库拆分为文本块。
- 为每个块创建数字表示(嵌入)并将其保存到矢量数据库中。
如果您的数据是静态的,则步骤 1 和 2 是一次性的工作。 - 使用用户对此数据库的查询运行语义搜索并获取相关文本块。
- 将这些文本块与用户的问题一起发送给法学硕士,并要求他们回答。
这是此过程的图形表示。
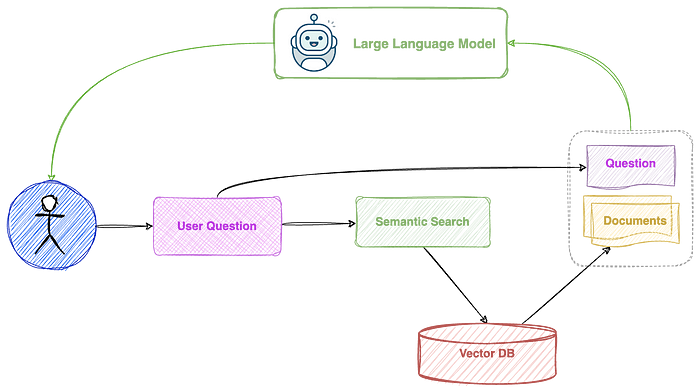
这种方法非常适合解决简单且是事实的知识库上的简单问题。然而,它不适用于更复杂的知识库和需要更深入、多跳推理的更复杂的问题。多跳推理是指采取多个步骤的逻辑或上下文推理来得出问题的结论或答案的过程。
此外,LLMs可以在一篇提示中咀嚼的文本长度受到限制。当然,您可以一次发送一份文件,然后在每次通话时“完善”或“减少”答案。然而,这种方法不允许复杂的“多跳”推理。在某些情况下,使用“优化”或“减少”方法的结果比简单地将所有文档填充到单个提示中要好,但差距并不大。
对于复杂的知识库,用户的问题本身可能不足以找到所有可以帮助LLM得出准确答案的相关文档。例如:
阿朱那是谁?
这是一个简单的问题,可以在有限的上下文中回答。然而,有以下问题:
为什么会发生摩诃婆罗多战争?
是一个上下文遍布整个文本语料库的问题。该问题本身对其上下文的信息有限。找到相关的文本块然后据此进行推理可能行不通。
那么接下来怎么办?
人工智能代理
这是人工智能出现后出现的最酷的概念之一。如果你不知道AI Agent的概念,我迫不及待地向你解释它,但我可能仍然无法传达它的厉害之处。我先用ChatGPT来解释一下。
人工智能代理,也简称为“代理”,是指能够自主感知环境、做出决策并采取行动以实现特定目标的软件程序或系统。人工智能代理旨在在解决问题和决策任务中模仿类人行为。它们在定义的环境中运行并与该环境交互以实现期望的结果。
简单来说,Agent就是一个程序,它接受一个问题,决定如何解决它,然后解决它。代理提供了一组工具,例如函数、方法、API 调用等。如果它选择按照它认为合适的任何顺序执行操作,则可以使用其中任何工具。与传统软件相比,解决问题所需的步骤顺序是预先编程的。当然,这是一个非常模糊的定义。但你现在可能已经掌握了窍门。
以下是我为 KBQA 用例尝试过的两种不同代理。
ReAct
该代理使用“ReAct”风格的推理来决定使用哪个工具来解决给定的问题。
ReAct Agent 的 LangChain 实现:ReAct
我为代理提供了以下工具供选择:
- 带有文档存储的检索 QA 链。
- 字符词汇表搜索(使用预训练模型通过命名实体识别创建了一个词汇表)
- 维基百科搜索。
ReAct代理没有给我很好的结果,并且大多数时候都无法收敛到任何答案。它不适用于 GPT 3.5。它可能与 GPT 4 配合使用效果更好,而 GPT 4 比 GPT 3.5 贵 20 -30 倍,因此可能还不是一个选择。
即使它收敛了,我也无法得到好的结果。如果有人在创建“ReAct”提示方面更有知识,可能会做得更好。
Self-Ask Agent
该代理根据原始问题提出后续问题,然后尝试找到中间答案。使用这些中间答案,最终得出最终答案。这是一篇解释 Self-Ask Agent 的文章。
Self-Ask Prompting
这种方法给我带来了一些好的结果。由于单跳原因,它运行良好。但对于需要多次跳跃的问题,即使这样也会失败。例如,以下问题:
谁杀了迦尔纳,为什么?
用这种方法相对容易回答
阿朱那为什么要杀他同父异母的弟弟迦尔纳?
回答起来要困难得多。它要求LLMs知道阿朱那不知道卡纳是他同父异母的兄弟这一事实。LLM 无法知道它需要了解这个事实,无论是通过理解问题还是根据原始问题提出进一步的问题。
人类研究过程
再次引用GPT
人工智能代理旨在模仿人类在解决问题和决策任务中的行为
所以,我的下一个想法是研究人类如何研究,如果你愿意的话,可以称之为元研究。我想象自己坐在图书馆(大学怀旧)中,可以轻松访问与我的研究主题相关的所有书籍。我拿了一个笔记本和一支笔,开始记下我研究一个主题时遵循的过程。
研究方法论:
记下页面上的原始查询。
- 我尝试通过阅读几本书来回答当前的问题。在此过程中,我做了一些笔记,并为我认为与当前问题最相关的一些摘录添加了书签。
- 我总是在这些摘录中发现许多未知之处。我记下这些未知数,并写下更多问题,以帮助我了解这些未知数。
- 从这些问题中,我选择一个与原始问题最相关的问题。
- 我回到步骤1
经过几次这样的迭代后,我问自己是否有足够的信息来回答最初的问题。
最后,我知道要编码什么。我希望,通过一些及时的工程设计,这个过程可以给我比我之前尝试过的任何其他方法更深刻的答案。
在坐下来编写代码之前,我在互联网上搜索了类似的想法。我发现了 BabyAGI。
这是一个描述BabyAGI 的仓库
我意识到BabyAGI和上述研究过程有很多相似之处。因此,怀着感激之情,我从 BabyAGI 实现中使用的提示中获得了一些灵感。
研究代理—实施
这是使用令人惊叹的draw.io转换为流程图的相同过程。
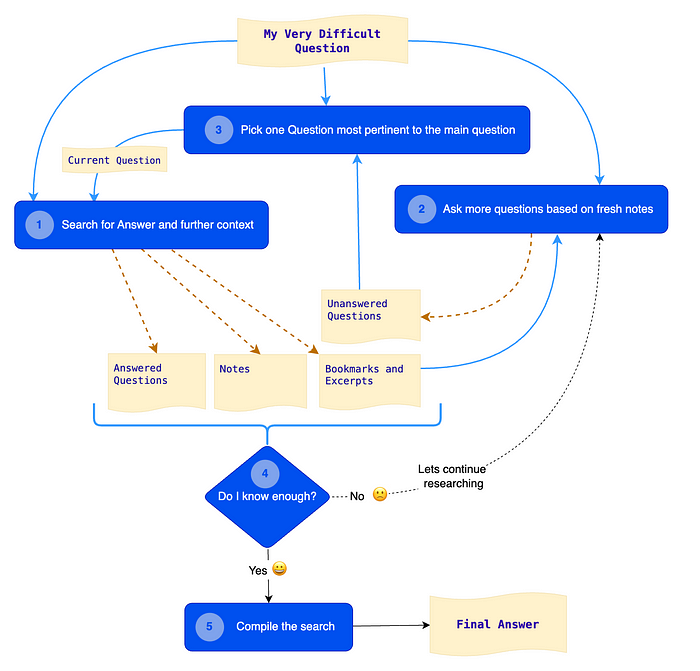
该图表中的每个蓝色框都是对LLMs的调用。
Components
- QA 代理 —搜索答案和进一步的上下文。这是个使用向量存储的简单“内容”检索 QA 链。未来,这可以是个人工智能代理,使用矢量存储、搜索 API 或维基百科 API、审核 API 和之前的研究数据等工具。此处的提示经过调整,可根据 1. 上下文(文档)和 2. 与原始问题的相关性生成简洁的答案。除了第一个循环之外,当前问题始终是步骤 2 中生成并在步骤 3 中选择的中间问题。 Agent 将中间答案附加到注释中,并将最新摘录(用于回答当前问题的文档)附加到书签中。步骤 2 中使用了最新的这些文档。
- 问题生成器 -根据新笔记提出更多问题在这里,代理使用与当前问题匹配的最新向量搜索结果,并使用它们生成与原始问题相关的更多问题。它将这些问题附加到未回答的问题列表中。此处的提示经过调整,以便新生成的问题不会与现有问题列表重叠。
- 最相关的问题选择器 —选择与原始问题最相关的一个问题此提示从未回答的问题列表中选择与原始问题最相关的一个问题。该问题用作下一个循环的当前问题。在下一个循环中,代理在生成一组新问题后从未回答问题列表中删除该问题。
- 分析器——我了解得够多吗?我使用max_iterations参数来退出循环。目前这效果很好。然而,最好根据不断变化的上下文动态决定迭代次数或退出策略。将来我将开发一个可以自动完成此操作的“分析器”。
- 研究编译器 -编译研究这是最后的提示。它使用研究过程中所做的笔记来对“原始问题”得出详尽的“最终答案”。
结果
该代理比以前的任何方法都更大程度地避免了幻觉问题。它会自动纠正在前几次迭代中以及随后的迭代中产生的幻觉和事实错误。问题越深入,得出的结果就越准确。
问题:为什么潘达瓦一家必须在森林里生活 12 年?
输出 -

以防万一您好奇,这是最终答案
Final Answer:
The Pandavas' decision to live in the forest for 12 years
was primarily due to the circumstances and events that
unfolded in their lives. After losing a game of dice to
The Kauravas and the Pandavas were forced into exile for
13 years, with the last year to be spent incognito.
During their exile, they faced numerous challenges
and hardships, including living in the forest.
Bhima contemplated killing all of
the Kurus, but his brother Yudhisthira always
pacified him, stating that it was not the opportune
time to fulfil their desires.
Thus, living in the forest allowed them to avoid
confrontations and maintain peace.
During their time in the forest, the Pandavas faced several difficulties.
One of the main challenges was Bhima's struggle to tolerate the ascetic
life. He contemplated killing all of the Kurus, but his brother
Yudhisthira always pacified him and advised against it.
Additionally, the Pandavas had to live in the forest and depend
on begging for their sustenance since their kingdom had been
plundered in gambling. They were distressed by the loss of their
kingdom and the insults to their queen Draupadi. The forest itself
was also full of dangers, adding to their hardships. Furthermore,
the Pandavas felt unable to fulfil the needs of certain pious Brahmanas
who stayed with them in the forest, as they did not possess anything
and were dependent on begging for their own survival.
Despite these challenges, the Pandavas made the most of their time
in the forest. They received knowledge from sages and saintly persons,
which helped them gain wisdom and spiritual insights. The great sage
Vyasa informed them that many generals had agreed to support their
cousin Duryodhana, including Karna, Shakuni, Bhurishravas, Sala,
Drona, and Bhishma. Vyasa also told Arjuna that if he were to fight
in a future war, he would need to obtain the divine astras of Lord
Indra and Lord Shiva.
In light of this information, Yudhisthira ordered Arjuna to go to the
Himalayan mountains to perform austerities to please Lord Shiva.
This was necessary for Arjuna to obtain the divine weapons that would
be crucial in the upcoming war. The Pandavas understood the importance
of being prepared and gathering the necessary resources to counter
the strength of their opponents. Therefore, Yudhisthira made the
decision to send Arjuna on this mission to seek Lord Shiva's blessings
and acquire the divine astras.
Overall, the Pandavas' exile in the forest for twelve years was a
result of the conditions imposed on them after losing the game
of dice. They faced various difficulties during their time in the
forest, but also gained valuable knowledge and prepared themselves
for the challenges that lay ahead.智能体的美妙之处不仅在于它准确地回答了最初的问题,还在于它更进一步,发现了围绕该问题的故事。
代理还会生成一组已回答的问题和未回答的问题,并在研究过程中记录下来。
** Unanswered Questions **
'4. How did the Pandavas receive knowledge from sages and saintly persons during their time in the forest?'
'5. What were the specific austerities that Arjuna had to perform in the Himalayan mountains to please Lord Shiva?'
'6. How did the Pandavas manage to hide from Duryodhana's spies for almost the entire thirteenth year of their exile?'
'8. How did Bhima cope with the challenges of living as an ascetic in the forest? Did he face any particular difficulties or struggles during their time in exile?'
'9. Can you provide more information about the generals who supported Duryodhana's cause? What were their roles and contributions in the Kurukshetra war?'
'10. How did the Pandavas manage to maintain a peaceful life in the forest despite the challenges they faced?'
'11. What were the specific teachings and knowledge that the Pandavas received from the sages and saintly persons during their time in the forest?'
'12. Can you provide more information about the palace where the Pandavas lived for one full year before going to the forest?'
'13. How did Lord Krishna's presence in the forest affect the Pandavas' experience during their exile?'
'14. Can you provide more information about the dangers the Pandavas faced while living in the forest?'
'15. What were the specific challenges and difficulties that Yudhisthira and his brothers faced in their daily lives as inhabitants of the forest?'代码
这里是带有研究代理实现的 Python 笔记本:research_agent
Mahabharata 数据集的 Git 存储库:Mahabharata,从多个来源编译的摩诃婆罗多文本
接下来是什么?
- 在公共链接上部署此代理并观察更多使用模式。
- 将代理与《摩诃婆罗多》以外的不同源文档一起使用。
- 该过程的第一步目前是个简单的“stuff”QA 链,它使用带有源文本语料库的向量存储。我正在努力将其替换为“ReAct”代理,以便在研究过程中可以使用搜索 API、维基百科、审核 API 等其他工具。
- 我将每次运行期间生成的数据和元数据保存到“runs”向量存储中。我还将原始问题的嵌入保存到同一商店。这帮助我跟踪智能体的推理轨迹,并观察从中出现的几种逻辑模式。这可以帮助调整 QA 代理以遵循更严格的推理路径。
- 目前,研究代理在一组固定的迭代之后存在。这对于大多数问题都很有效。然而,最好根据不断变化的上下文动态决定迭代次数或退出策略。我将开发一个可以自主完成此操作的“分析器”。
- 该代理适用于大多数类型的问题(元问题除外)。例如,如果我问“描述一下第 5 本书第 3 章中发生的事情”,代理就很难回答。在未来的版本中,我将在“ReAct”代理中包含一个自查询检索器来处理此类情况。
- 到目前为止,我仅在 OpenAI GPT3.5 模型上尝试过 Agent。每次运行花费我大约 0.02 美元。我很快就会尝试使用像 Llama 这样可以在本地托管的较小模型的研究代理。
Credits for the data sets I used in the above article, along with the licensing information.
- Complete Translation by K. M. Ganguli: Available in the public domain.
- Laura Gibbs Tiny Tales: This is a retelling of the Mahabharata using two hundred episodes that are each 100 words long. I am using her work here with her permission.
- Kaggle data repo by Tilak: All 18 Parvas of Mahabharata in text format for NLP. Shared with public domain license by Tilak