为了解决单点问题,实现多服务器部署redis,有几种解决方案可以实现:主从复制,主从+哨兵还有集群。
何为主从复制
简单来说有三个服务器分别部署了redis-server程序,选中一个服务器当作主节点,其他的就是从节点了。主节点上有一堆的数据,复制出来拷贝到从节点上,后续主节点有任何修改的数据,都要在从节点上体现出来,要注意的时候为了避免从节点影响到主节点,从节点只能读,不能写。
主从解决的问题
在可用性方面,如果是单机结构,机器挂了整个程序就挂了,如果是主从结构的话,大大提高了程序的可用性。
在性能方面来看,由于从节点的数据时刻保持和主节点一致,那么客户端从 从节点访问数据和从 主节点访问数据是一致的,后续如果有大量的客户端访问数据的话,平均下来,各个节点的压力减少了不小。这其实也相当于引入了计算机资源,并发量自然提升了。
更准确来说主从只针对读操作进行并发量可用性的提高 ,而写操作依赖于主节点,但是主节点又不能搞多个。
单机部署多个redis
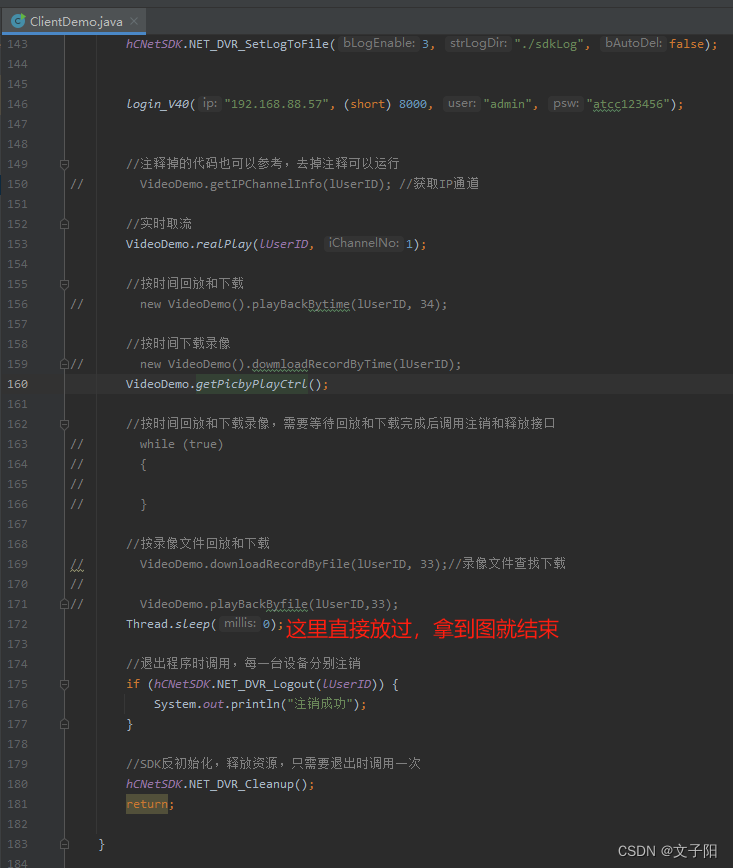
单机情况下部署redis的前提那就是,不同的redis需要有着不同的端口,修改端口常用的有俩种方式,一个是修改配置文件,另一个就是--port命令行来实现。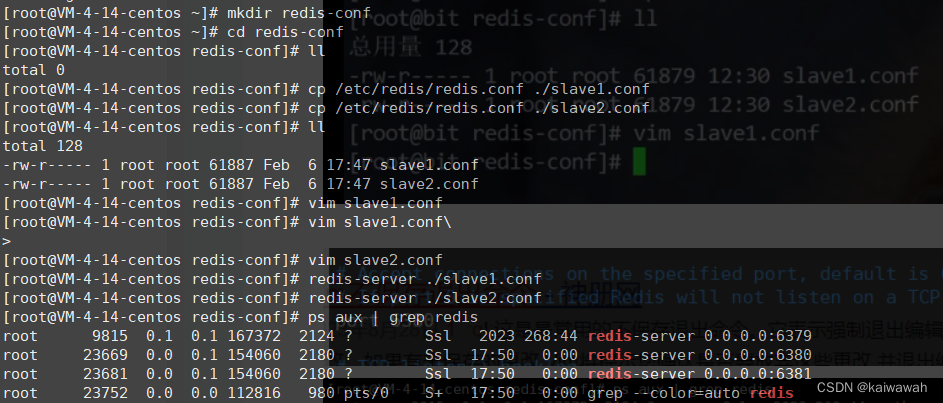
修改新复制的配置文件端口分别改成6380 和 81 
当前这几个redis并没有构成主从结构

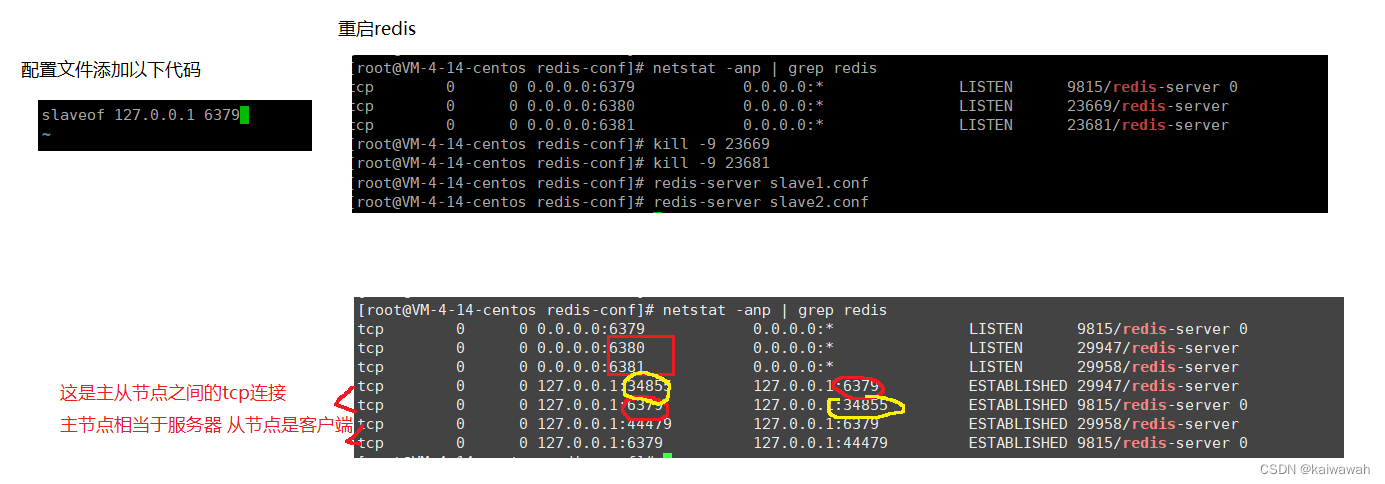
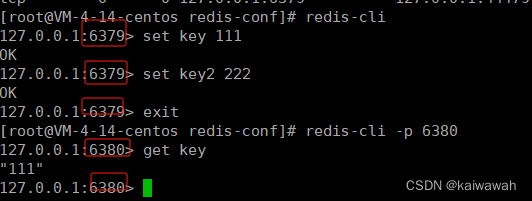 由于主从建立了连接,主节点数据一发生改变,从节点立马感知到。而且从节点没办法写数据(set)
由于主从建立了连接,主节点数据一发生改变,从节点立马感知到。而且从节点没办法写数据(set)
了解主从结构(info命令)
 断开主从关系/修改主从关系
断开主从关系/修改主从关系
slaveof no one
直接在客户端使用这个命令断开现有的主从复制关系 ,此时从节点就不属于任何主节点了,自己变成主节点了
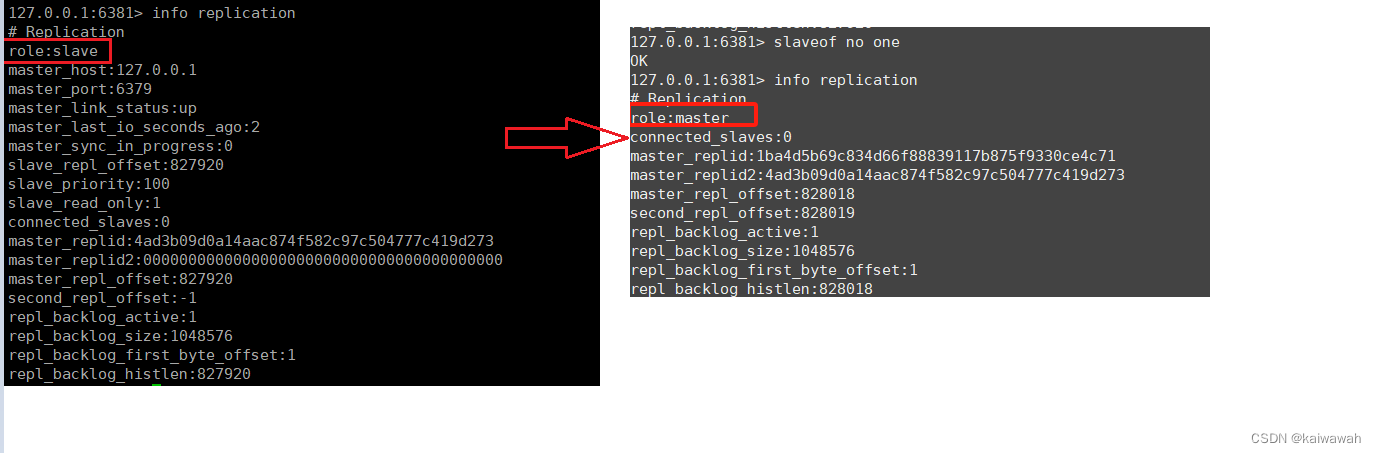
要注意的是删除的只是关系,从节点的数据不会发生改变的

使用slaveof修改只是暂时的,重新启动redis优惠恢复如初。
安全性、只读、传输延迟
对于数据比较重要的节点,主机点通过设置requirepass参数进行密码验证,这时所有的客户端访问必须使用auth命令进行验证,从主节点之间的数据复制是一个特殊的客户端来完成的,因此需要配置从节点的masterauth参数与主节点密码保持一致,这样才能连接并且复制。
从节点不允许修改文件,只能进行读操作。最好不要修改,因为主节点无法感知从节点数据修改的。
主从节点一般是不同的机器上的,要考虑到传输延迟,而主从节点的交互是靠网络传输的,也就是tcp。TCP内部支持了nagle算法,开启了会增加传输延迟,但是节省了网络带宽,关闭了减少网络延迟,增加网络带宽,究其原因是nagle算法相当于把tcp数据包打包起来,针对小的数据包进行合并,减少了包的个数。![]()
拓扑
首先,拓扑的含义是若干个节点之间,按照啥样的方式进行组织连接?
一主一从
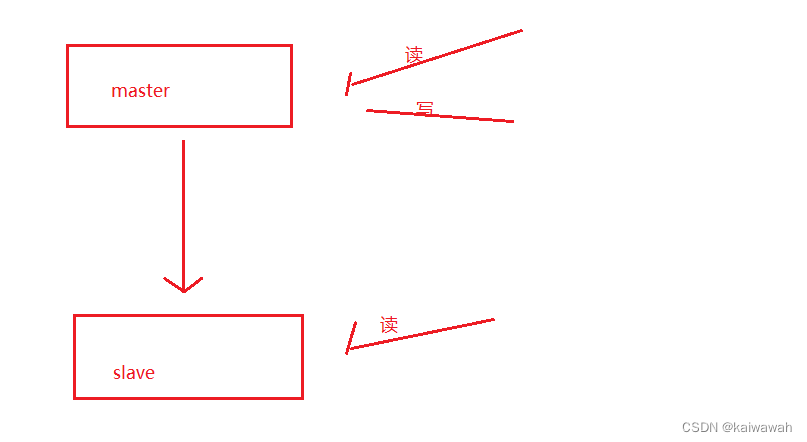
客户端发生读请求既可以向主节点发送也可以发送给从节点,但是写请求只能发给主节点 ,会对主节点造成不小的压力,因此我们可以通过关闭主节点的AOF,打开从节点的AOF,但是这种是有缺陷的,主节点一旦挂掉,会自动启动,此时主节点又没有AOF文件,那么从节点还没来得及保存的数据又会丢失了,优化办法是,当主节点挂了 ,需要让主节点向从节点要AOF文件,再启动。
一主多从
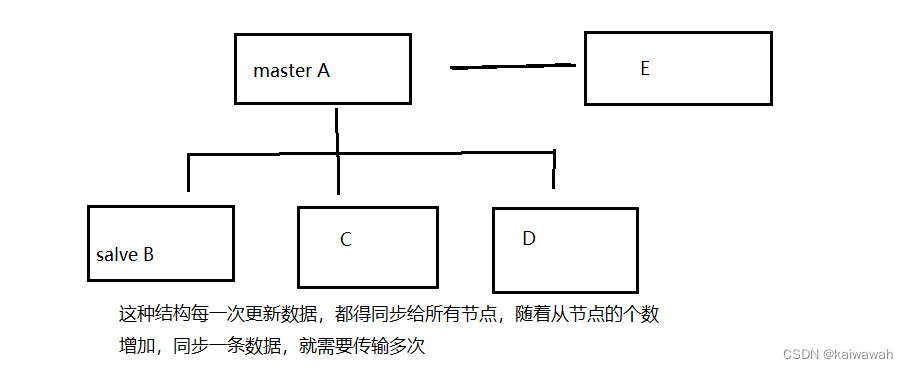
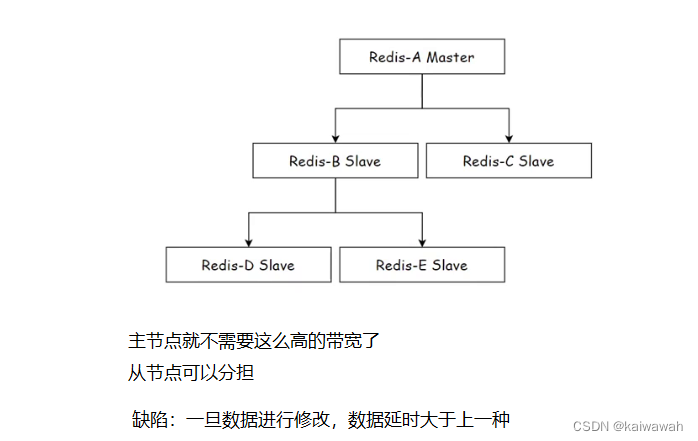
主从复制流程
从节点接收到slaveof指令之后,从节点第一步就首先记录主节点的信息(ip、端口号之类的),当然是通过变量的形式记录,在那之后主从之间要建立连接,使用的是tcp建立连接(三次握手),然后是通过发送ping看功能命令能否正常使用,再者就是有的时候主节点会设置密码, 因此会出现权限验证的环节,后面就是同步数据集和命令持续复制了。
redis提供了psync命令来完成数据同步的过程,不需要手动执行的,主从关系建立成功之后,会自动执行psync,从节点负责从主节点拉取数据。
PSYNC replicaitonid offset
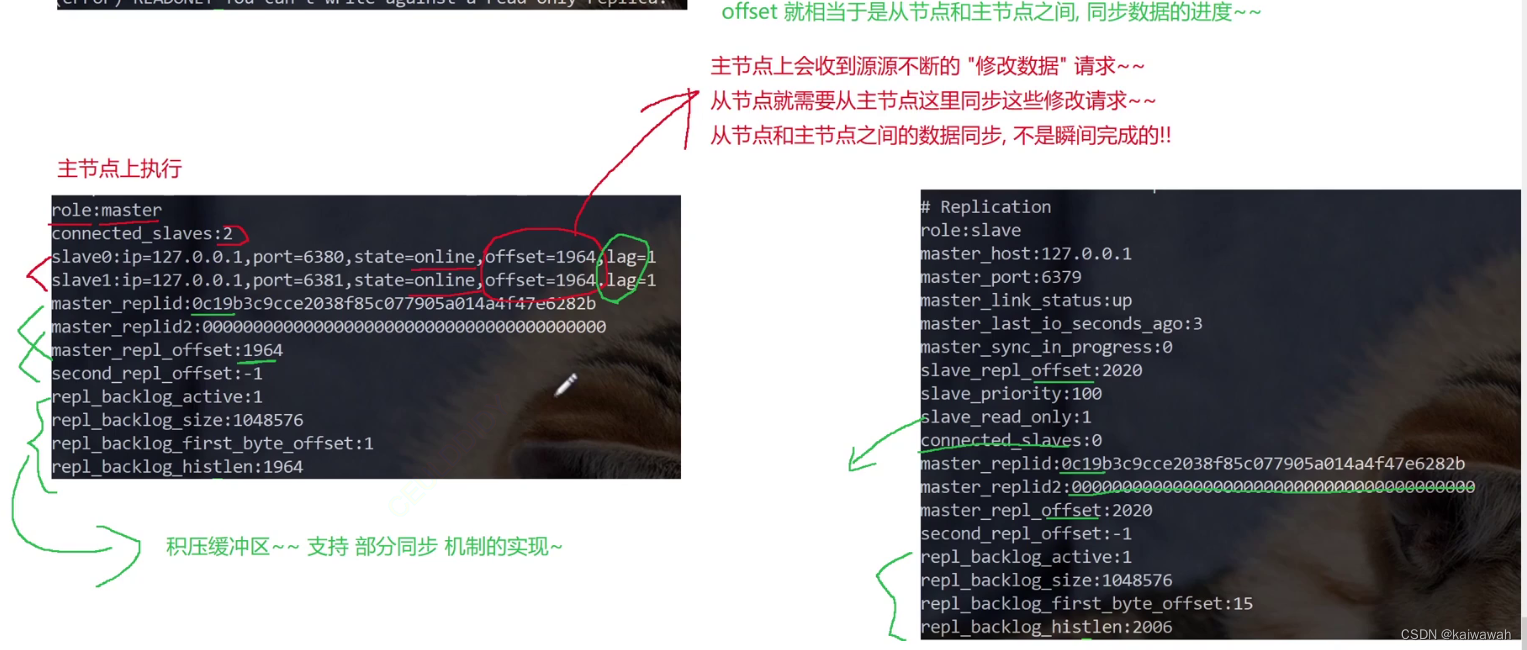
replicationid是主节点生成的,每次启动会随机生成一个主节点的id,用于区分不同的主节点,从节点与主节点建立关系之后,就会从主节点获取到了replication id
info reolication 可以获取到repl_id
offset就是偏移量,主节点进行修改命令的时候,需要记录下所有修改命令的字节个数,从节点的offset就描述了,现在从节点这里数据同步到哪里了。
replication id 和 offset 共同描述了一个"数据集合
如果发现两个机器, replication id 一样, offset 也一样就可以认为这两个 redis 机器上存储的数据就是完全一样的!!
psync流程
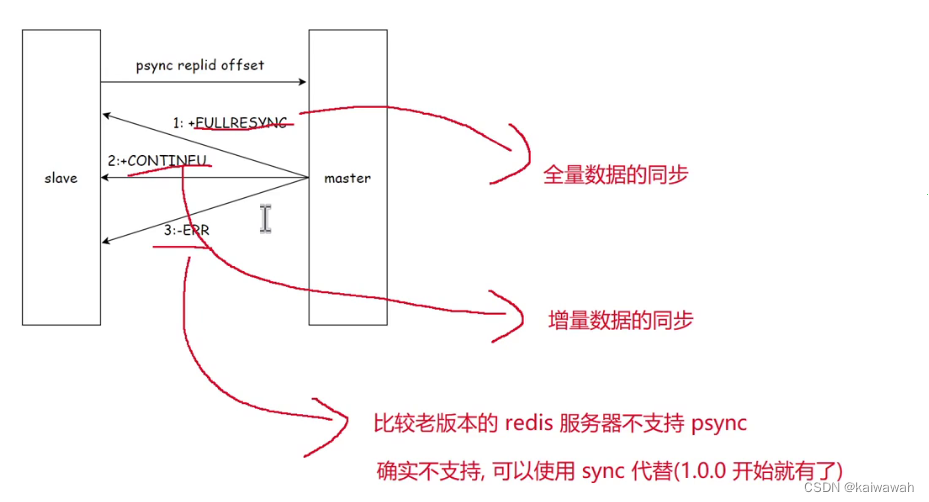
全量复制的流程
 要注意的是在 4 和 5 步骤的时候,一个是生成rdb文件和网络传输的时候需要耗费大量的时间,这段时间主节点可能会收到新的修改请求,因此还是需要把这个新的修改请求发送给从节点,也就是第六步。
要注意的是在 4 和 5 步骤的时候,一个是生成rdb文件和网络传输的时候需要耗费大量的时间,这段时间主节点可能会收到新的修改请求,因此还是需要把这个新的修改请求发送给从节点,也就是第六步。
当然全量复制也有优化手段:主节点生成的rdb文件不再保存到硬盘中,而是直接发给从节点,还有从节点收到rdb文件之后,直接读取数据,不在保存,这种实现方式叫 无硬盘模式(diskless)。
部分复制的流程
全量复制比较大,如果从节点已经有了主节点大量的数据,只需要拷贝少量数据,就可以使用部分复制(网络抖动)。

实时复制的流程
主从节点同步好数据了,但是之后主节点会源源不断的收到新的修改数据的请求,也是需要同步给从节点的,因此可以让主从节点建立TCP长连接,然后主节点根据上述连接将新的修改请求数据发送给从节点。从节点再根据这些数据进行对内存的修改;
在进行实时复制的时候,需要保证连接处于可用状态
心跳包 机制
主节点: 默认, 每隔 10s 给从节点发送一个 ping 命令.从节点收到就返回 pong
从节点: 默认, 每隔 1s 就给主节点发起一个特定的请求,就会上报当前从节点复制数据的进度(offset)