模型
| 模型名 | 模型大小 | 默认模块 | Template |
|---|---|---|---|
| Baichuan2 | 7B/13B | W_pack | baichuan2 |
| BLOOM | 560M/1.1B/1.7B/3B/7.1B/176B | query_key_value | - |
| BLOOMZ | 560M/1.1B/1.7B/3B/7.1B/176B | query_key_value | - |
| ChatGLM3 | 6B | query_key_value | chatglm3 |
| DeepSeek (MoE) | 7B/16B/67B | q_proj,v_proj | deepseek |
| Falcon | 7B/40B/180B | query_key_value | falcon |
| Gemma | 2B/7B | q_proj,v_proj | gemma |
| InternLM2 | 7B/20B | wqkv | intern2 |
| LLaMA | 7B/13B/33B/65B | q_proj,v_proj | - |
| LLaMA-2 | 7B/13B/70B | q_proj,v_proj | llama2 |
| Mistral | 7B | q_proj,v_proj | mistral |
| Mixtral | 8x7B | q_proj,v_proj | mistral |
| Phi-1.5/2 | 1.3B/2.7B | q_proj,v_proj | - |
| Qwen | 1.8B/7B/14B/72B | c_attn | qwen |
| Qwen1.5 | 0.5B/1.8B/4B/7B/14B/72B | q_proj,v_proj | qwen |
| XVERSE | 7B/13B/65B | q_proj,v_proj | xverse |
| Yi | 6B/34B | q_proj,v_proj | yi |
| Yuan | 2B/51B/102B | q_proj,v_proj | yuan |
单 GPU 训练
[!IMPORTANT]
如果您使用多张 GPU 训练模型,请移步多 GPU 分布式训练部分。
预训练
CUDA_VISIBLE_DEVICES=0 python src/train_bash.py \
--stage pt \
--do_train \
--model_name_or_path path_to_llama_model \
--dataset wiki_demo \
--finetuning_type lora \
--lora_target q_proj,v_proj \
--output_dir path_to_pt_checkpoint \
--overwrite_cache \
--per_device_train_batch_size 4 \
--gradient_accumulation_steps 4 \
--lr_scheduler_type cosine \
--logging_steps 10 \
--save_steps 1000 \
--learning_rate 5e-5 \
--num_train_epochs 3.0 \
--plot_loss \
--fp16
指令监督微调
CUDA_VISIBLE_DEVICES=0 python src/train_bash.py \
--stage sft \
--do_train \
--model_name_or_path path_to_llama_model \
--dataset alpaca_gpt4_zh \
--template default \
--finetuning_type lora \
--lora_target q_proj,v_proj \
--output_dir path_to_sft_checkpoint \
--overwrite_cache \
--per_device_train_batch_size 4 \
--gradient_accumulation_steps 4 \
--lr_scheduler_type cosine \
--logging_steps 10 \
--save_steps 1000 \
--learning_rate 5e-5 \
--num_train_epochs 3.0 \
--plot_loss \
--fp16
奖励模型训练
CUDA_VISIBLE_DEVICES=0 python src/train_bash.py \
--stage rm \
--do_train \
--model_name_or_path path_to_llama_model \
--adapter_name_or_path path_to_sft_checkpoint \
--create_new_adapter \
--dataset comparison_gpt4_zh \
--template default \
--finetuning_type lora \
--lora_target q_proj,v_proj \
--output_dir path_to_rm_checkpoint \
--per_device_train_batch_size 2 \
--gradient_accumulation_steps 4 \
--lr_scheduler_type cosine \
--logging_steps 10 \
--save_steps 1000 \
--learning_rate 1e-6 \
--num_train_epochs 1.0 \
--plot_loss \
--fp16
PPO 训练
CUDA_VISIBLE_DEVICES=0 python src/train_bash.py \
--stage ppo \
--do_train \
--model_name_or_path path_to_llama_model \
--adapter_name_or_path path_to_sft_checkpoint \
--create_new_adapter \
--dataset alpaca_gpt4_zh \
--template default \
--finetuning_type lora \
--lora_target q_proj,v_proj \
--reward_model path_to_rm_checkpoint \
--output_dir path_to_ppo_checkpoint \
--per_device_train_batch_size 2 \
--gradient_accumulation_steps 4 \
--lr_scheduler_type cosine \
--top_k 0 \
--top_p 0.9 \
--logging_steps 10 \
--save_steps 1000 \
--learning_rate 1e-5 \
--num_train_epochs 1.0 \
--plot_loss \
--fp16
这些命令行参数用于在单GPU上进行不同类型的模型训练,包括预训练、指令监督微调、奖励模型训练和PPO训练。下面是对每个参数的详细解释:
- CUDA_VISIBLE_DEVICES:指定使用哪张GPU进行训练。在这里,它被设置为0,意味着将使用第一张GPU。
- python src/train_bash.py:这是训练脚本的路径,它包含执行训练的代码。
- –stage pt/sft/rm/ppo:指定训练的阶段。
pt代表预训练,sft代表指令监督微调,rm代表奖励模型训练,ppo代表PPO训练。 - –do_train:指示脚本执行训练步骤。
- –model_name_or_path:指定要训练的模型的名称或路径。
- –dataset:指定用于训练的数据集。
- –finetuning_type lora:指定微调类型为LoRA,这是一种用于放大模型容量的技术。
- –lora_target:指定LoRA适配器的目标模块,这里是指定模型的特定层。
- –output_dir:指定训练输出的目录,用于保存检查点和其他相关文件。
- –overwrite_cache:如果缓存已存在,此选项将覆盖它。
- –per_device_train_batch_size:指定每个设备的训练批次大小。
- –gradient_accumulation_steps:指定梯度累积的步数,这可以增加批次大小而不增加内存消耗。
- –lr_scheduler_type cosine:指定学习率调度器的类型,这里使用余弦调度器。
- –logging_steps:指定记录日志的步数。
- –save_steps:指定保存检查点的步数。
- –learning_rate:指定学习率。
- –num_train_epochs:指定训练的epoch数量。
- –plot_loss:在训练过程中绘制损失图。
- –fp16:指示使用16位浮点数进行训练,这可以提高训练效率。
- –adapter_name_or_path:如果需要,指定适配器的名称或路径,用于迁移学习。
- –create_new_adapter:如果需要,创建一个新的适配器。
- –reward_model:如果正在进行PPO训练,指定奖励模型的路径。
- –top_k和**–top_p**:这些参数用于控制随机抽样的方式,用于生成文本。
这些参数可以根据不同的模型和任务进行调整。在实际使用中,可能还需要根据具体情况添加或修改其他参数。
以qwen 14B 举例子
CUDA_VISIBLE_DEVICES=0 python src/train_bash.py
--stage pt
--do_train
--model_name_or_path qwen/Qwen-14B
--dataset wiki_demo
--finetuning_type lora
--lora_target c_attn
--output_dir path_to_pt_checkpoint
--overwrite_cache --per_device_train_batch_size 4
--gradient_accumulation_steps 4 --lr_scheduler_type cosine
--logging_steps 10 --save_steps 1000 --learning_rate 5e-5
--num_train_epochs 3.0 --plot_loss --fp16
这里我们看到llama factory的预训练也是基于lora进行预训练的。
显存占用38GB
那么 接下来我们尝试多卡进行 qwen/Qwen-14B lora 预训练
首先配置accelerate,输入只有accelerate config,剩下的内容都是选项。
accelerate config
In which compute environment are you running?
This machine
Which type of machine are you using?
multi-GPU
How many different machines will you use (use more than 1 for multi-node training)? [1]: 1
Should distributed operations be checked while running for errors? This can avoid timeout issues but will be slower. [yes/NO]: yes
Do you wish to optimize your script with torch dynamo?[yes/NO]:yes
Which dynamo backend would you like to use?
tensorrt
Do you want to customize the defaults sent to torch.compile? [yes/NO]:
Do you want to use DeepSpeed? [yes/NO]: NO
Do you want to use FullyShardedDataParallel? [yes/NO]: M^HNPO^H^H
Please enter yes or no.
Do you want to use FullyShardedDataParallel? [yes/NO]: NO
Do you want to use Megatron-LM ? [yes/NO]: yes
What is the Tensor Parallelism degree/size? [1]:1
What is the Pipeline Parallelism degree/size? [1]:1
Do you want to enable selective activation recomputation? [YES/no]: 1
Please enter yes or no.
Do you want to enable selective activation recomputation? [YES/no]: YES
Do you want to use distributed optimizer which shards optimizer state and gradients across data parallel ranks? [YES/no]: YES
What is the gradient clipping value based on global L2 Norm (0 to disable)? [1.0]: 1
How many GPU(s) should be used for distributed training? [1]:3
Do you wish to use FP16 or BF16 (mixed precision)?
bf16
accelerate configuration saved at /home/ca2/.cache/huggingface/accelerate/default_config.yaml
您已经成功地为多GPU训练环境配置了accelerate。以下是您提供的配置的简要概述以及每个选项的含义:
- 计算环境:您正在使用本地机器,这可能意味着您将在单台物理服务器或工作站上使用多个GPU。
- 机器类型:您正在使用多GPU机器。
- 多机器训练:您只计划使用一台机器进行训练,这意味着您将在单节点上进行训练。
- 分布式操作检查:您希望在运行时检查分布式操作是否有错误,这样可以避免超时问题,但可能会使训练变慢。
- 使用torch dynamo优化:您希望使用
torch dynamo来优化您的PyTorch代码,这可以提高性能。 - dynamo后端:您选择使用
tensorrt作为后端,这通常用于生产环境,可以提供优化的代码。 - DeepSpeed:您不打算使用DeepSpeed,这是一个用于深度学习训练的优化库。
- FullyShardedDataParallel:您不打算使用
FullyShardedDataParallel,这是一个用于数据并行的PyTorch分布式训练的库。 - Megatron-LM:您打算使用
Megatron-LM,这是一个用于大规模语言模型训练的PyTorch扩展。 - Tensor并行度:您设置为1,这意味着您不会使用Tensor并行。
- 流水线并行度:您设置为1,这意味着您不会使用流水线并行。
- 选择性激活重计算:您启用了选择性激活重计算,这可以提高效率。
- 分布式优化器:您启用了分布式优化器,这意味着优化器状态和梯度将在数据并行等级上分片。
- 梯度裁剪:您设置了一个基于全局L2范数的梯度裁剪值。
- 用于分布式训练的GPU数量:您指定了使用3个GPU进行分布式训练。
- FP16或BF16(混合精度):您选择了BF16,这是英伟达的混合精度之一,可以提高训练性能。
这些配置为您的训练环境提供了一个良好的起点,但您可能需要根据您的具体需求和硬件配置进行调整。在开始训练之前,请确保您的环境变量(如CUDA_VISIBLE_DEVICES)设置正确,以便accelerate可以识别和使用您指定的GPU。
如果您遇到任何问题或需要进一步的帮助,请随时提问。祝您训练顺利!
accelerate launch src/train_bash.py --stage pt --do_train --model_name_or_path qwen/Qwen-14B --dataset wiki_demo --finetuning_type lora --lora_target c_attn --output_dir path_to_pt_checkpoint --overwrite_cache --per_device_train_batch_size 4 --gradient_accumulation_steps 4 --lr_scheduler_type cosine --logging_steps 10 --save_steps 1000 --learning_rate 5e-5 --num_train_epochs 3.0 --plot_loss --fp16
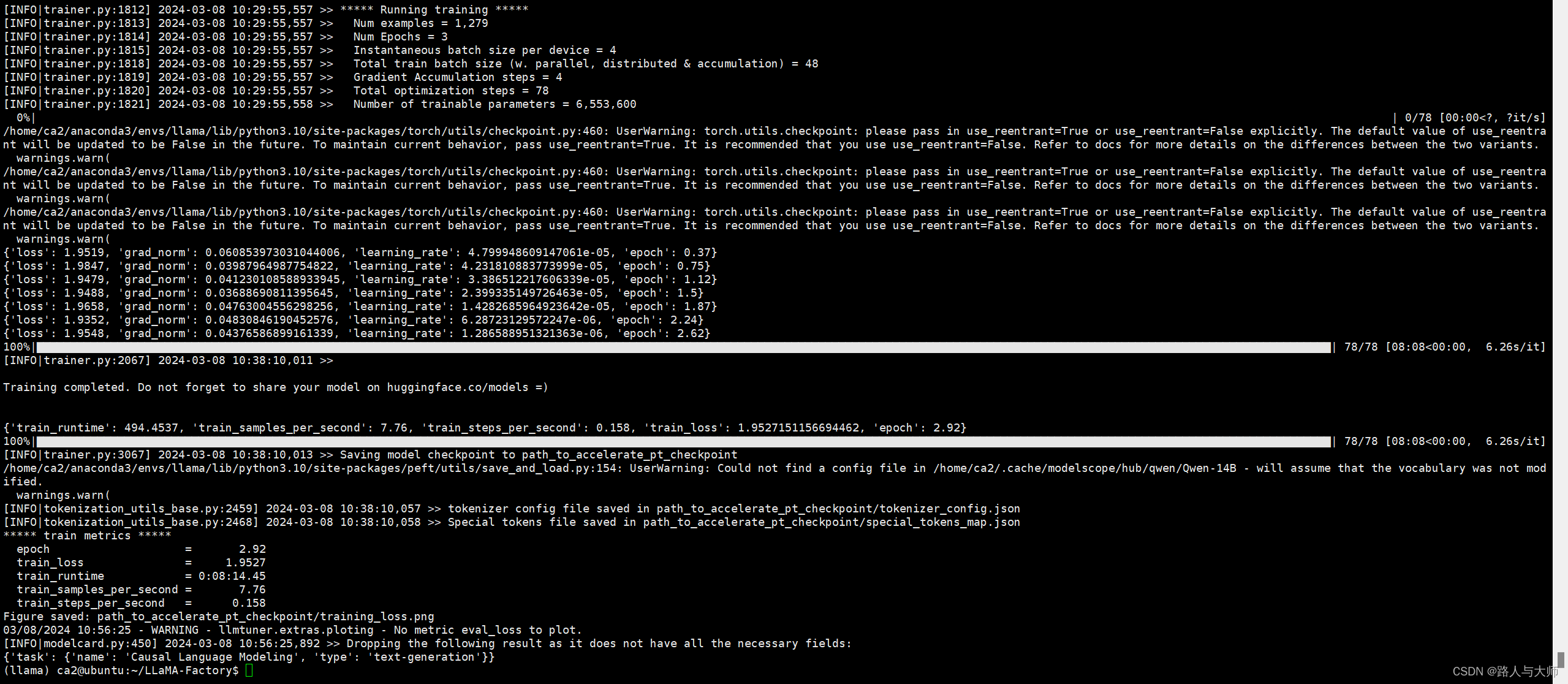
成功训练