文章目录
- 发现宝藏
- 一、 目标
- 二、简单分析网页
- 1. 寻找所有新闻
- 2. 分析模块、版面和文章
- 三、爬取新闻
- 1. 爬取模块
- 2. 爬取版面
- 3. 爬取文章
- 四、完整代码
- 五、效果展示
发现宝藏
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。【宝藏入口】。
一、 目标
爬取https://news.nd.edu/的字段,包含标题、内容,作者,发布时间,链接地址,文章快照 (可能需要翻墙才能访问)
二、简单分析网页
1. 寻找所有新闻
-
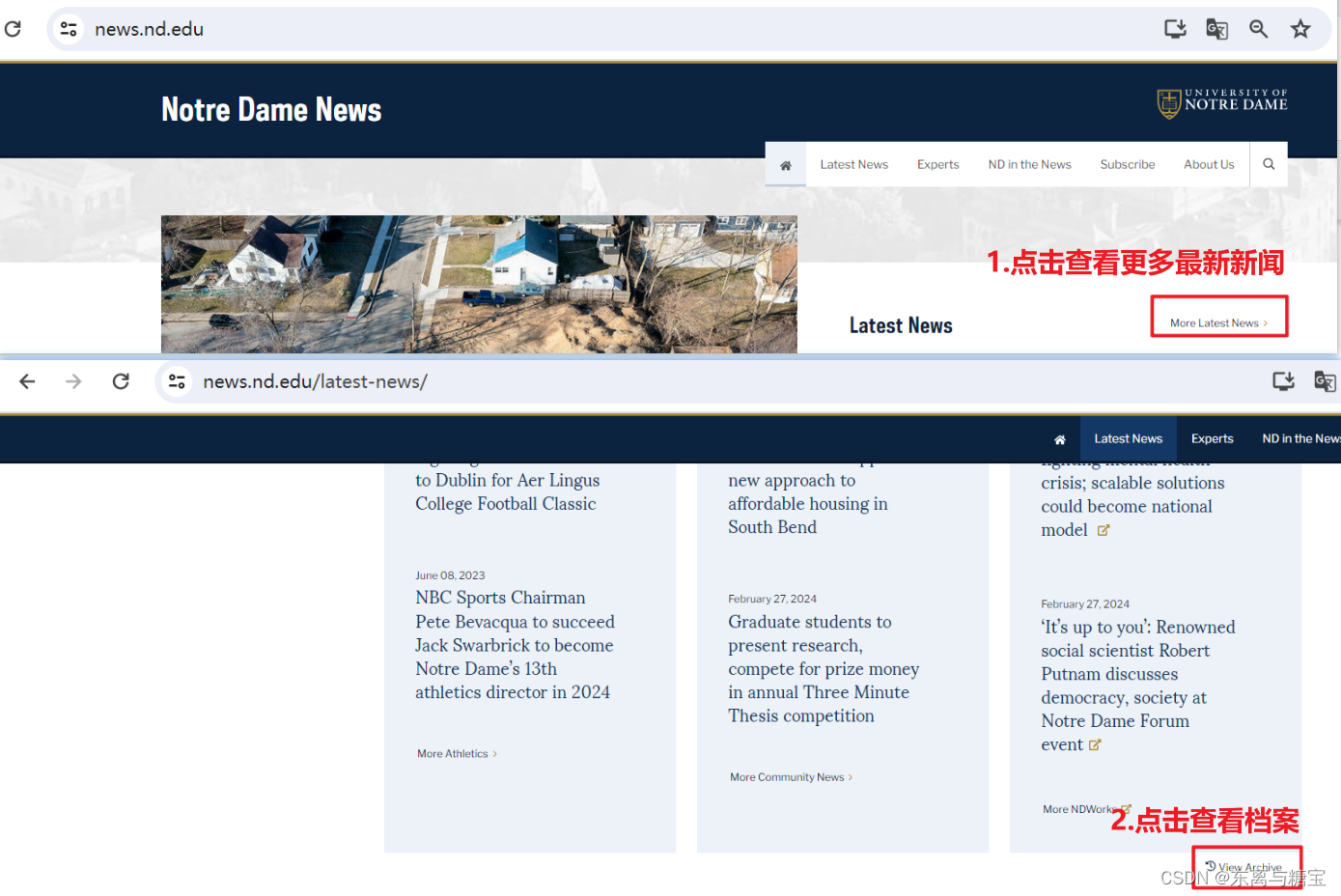
点击查看更多最新新闻>>点击查看档案
-
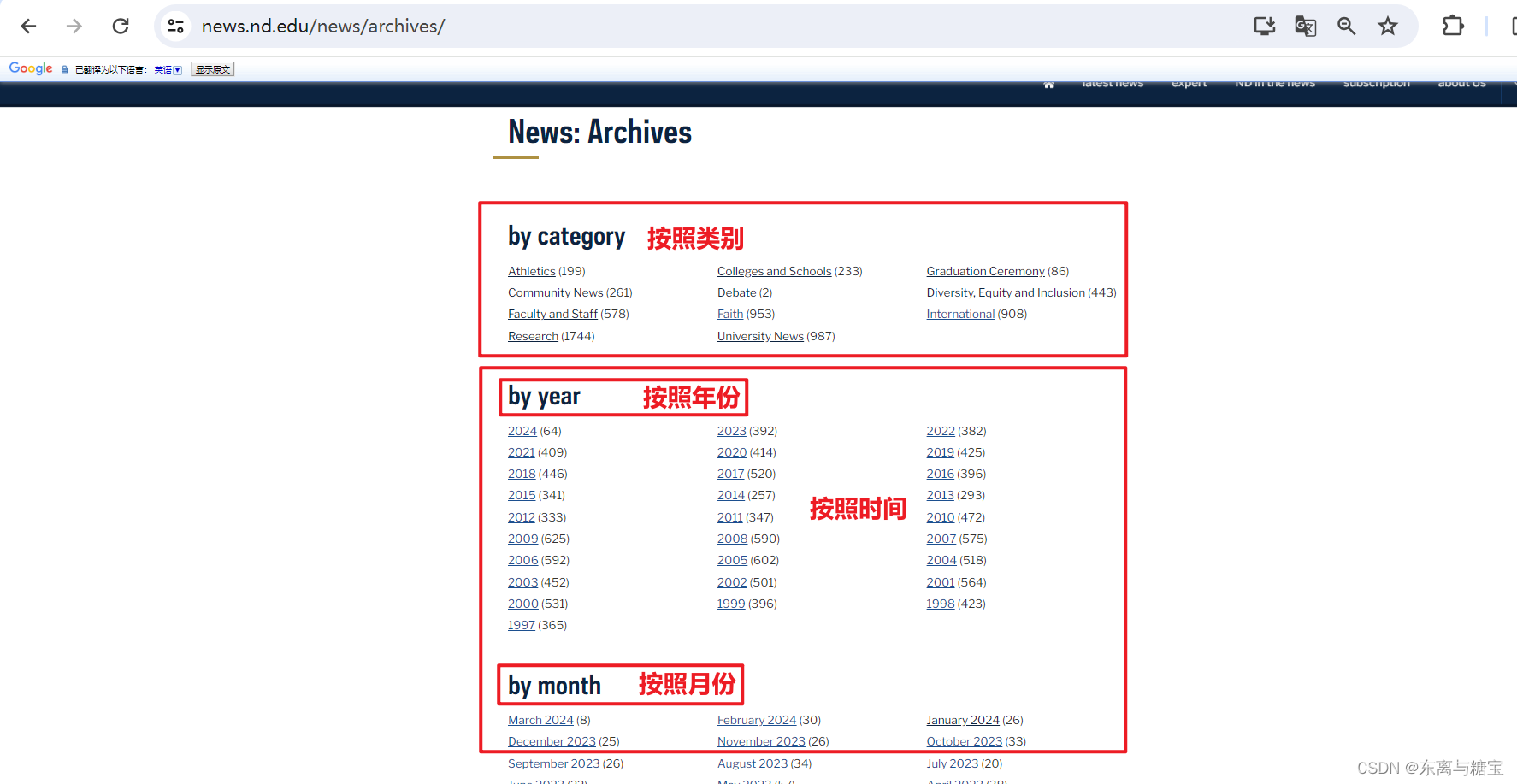
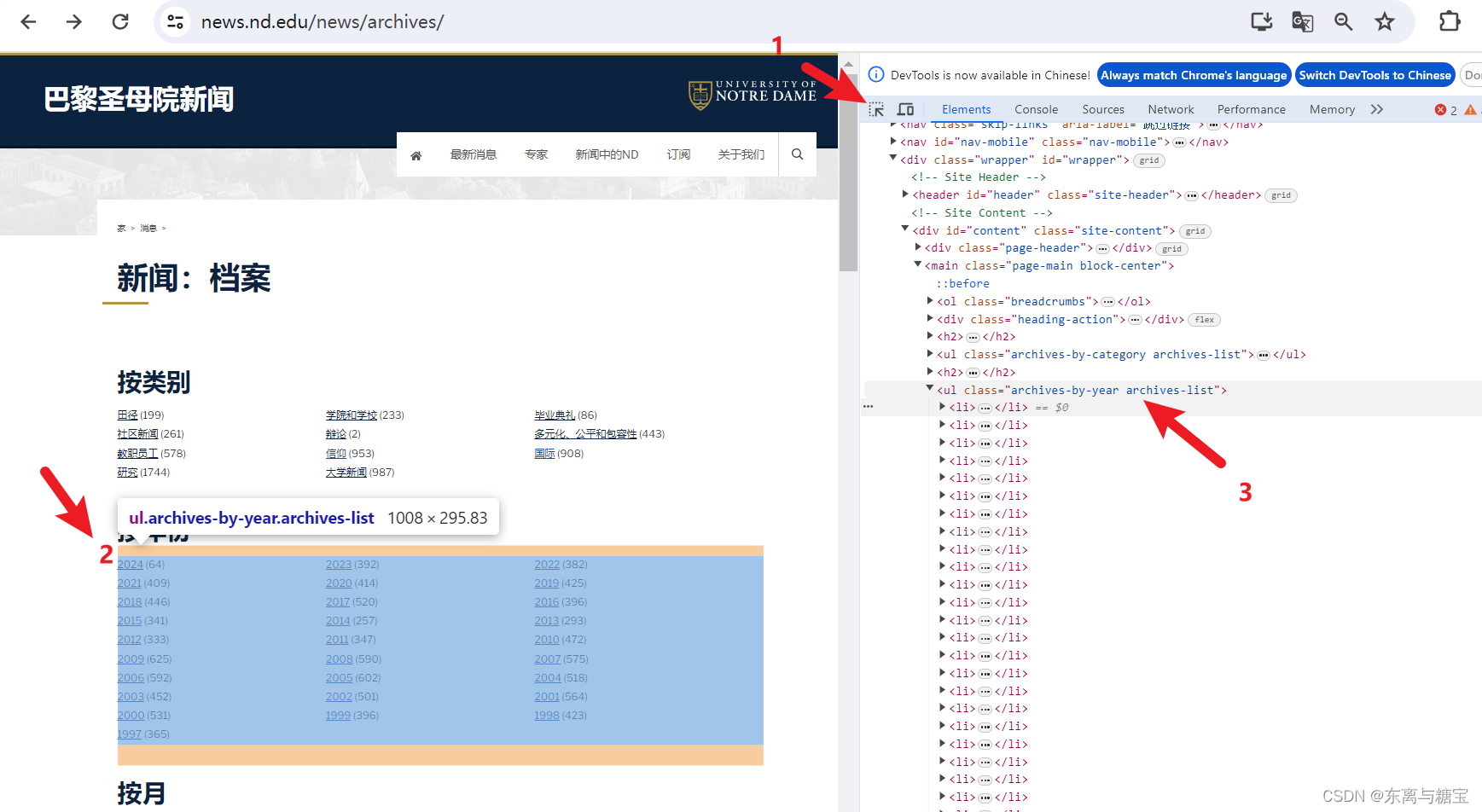
我们发现有两种方式查看所有新闻,一种是按照类别,一种是按照时间,经过进一步的观察我们发现按照时间查看新闻会更全,所以我们选择按照年份(按照月份和按照年份一样的效果)爬取
2. 分析模块、版面和文章
-
为了规范爬取的命名与逻辑,我们分别用模块、版面、文章三部分来进行爬取,具体如下
-
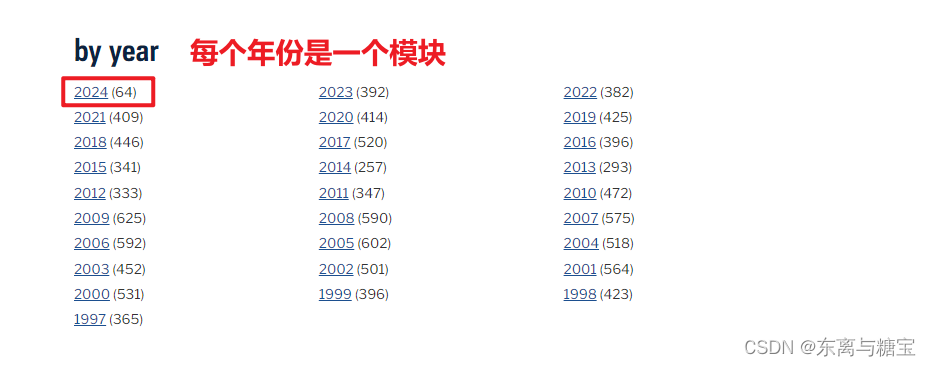
一个网站的全部新闻由数个模块组成,只要我们遍历爬取了所有模块就获得的该网站的所有新闻
- 一个模块由数页版面组成,只要遍历了所有版面,我们就爬取了一个模块
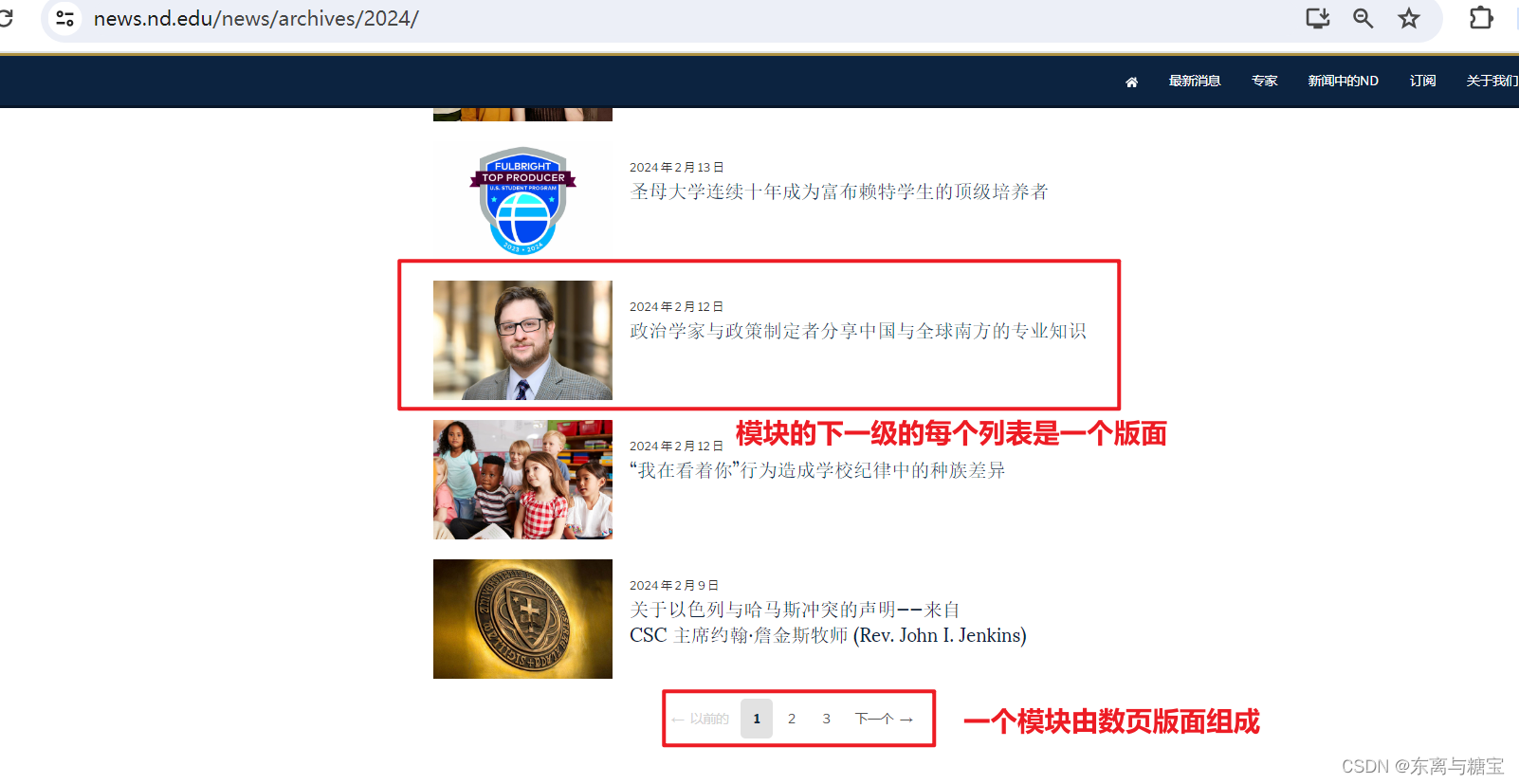
- 一个版面里有数页文章,由于该网站模块下的列表同时也是一篇文章,所以一个版面里只有一篇文章
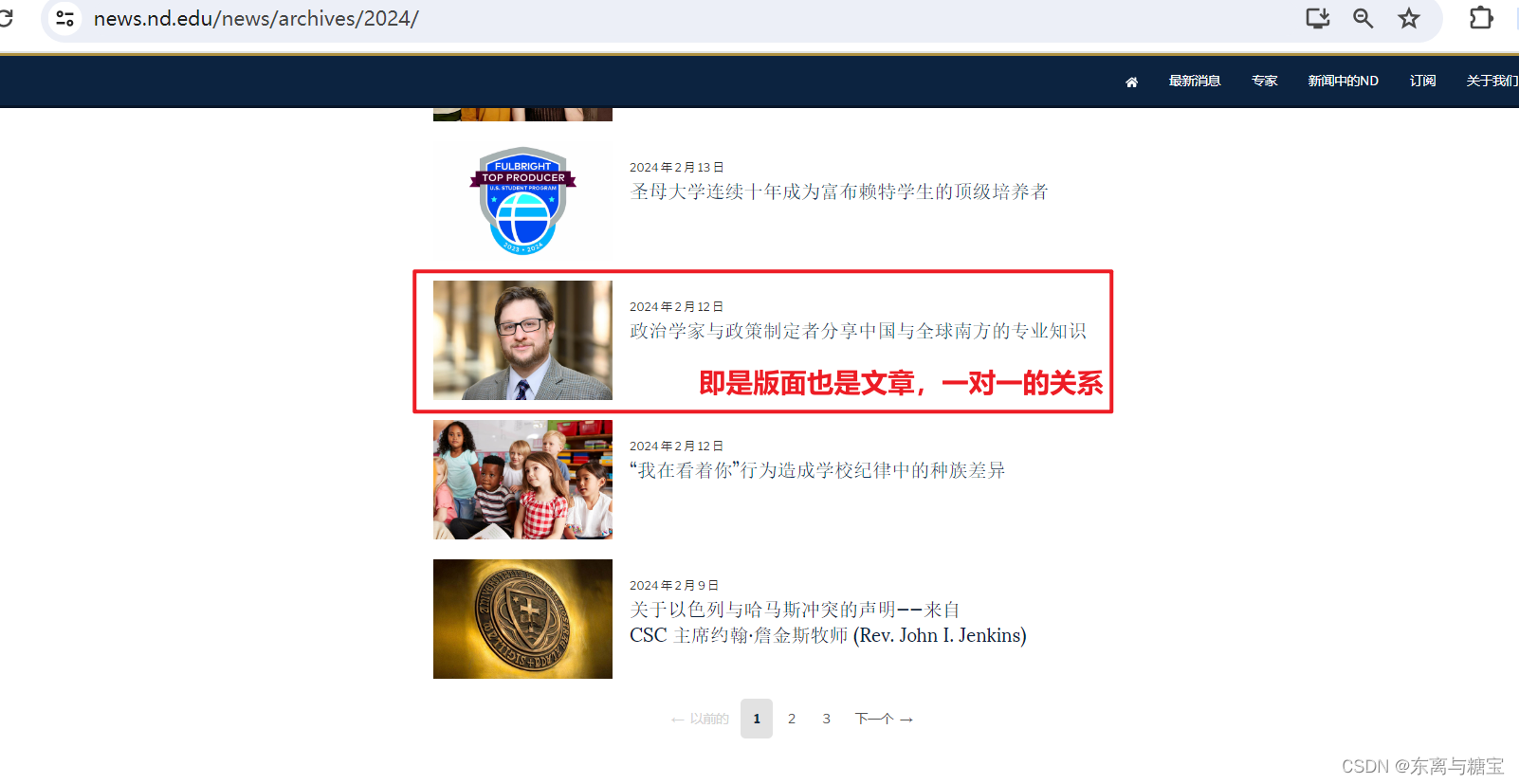
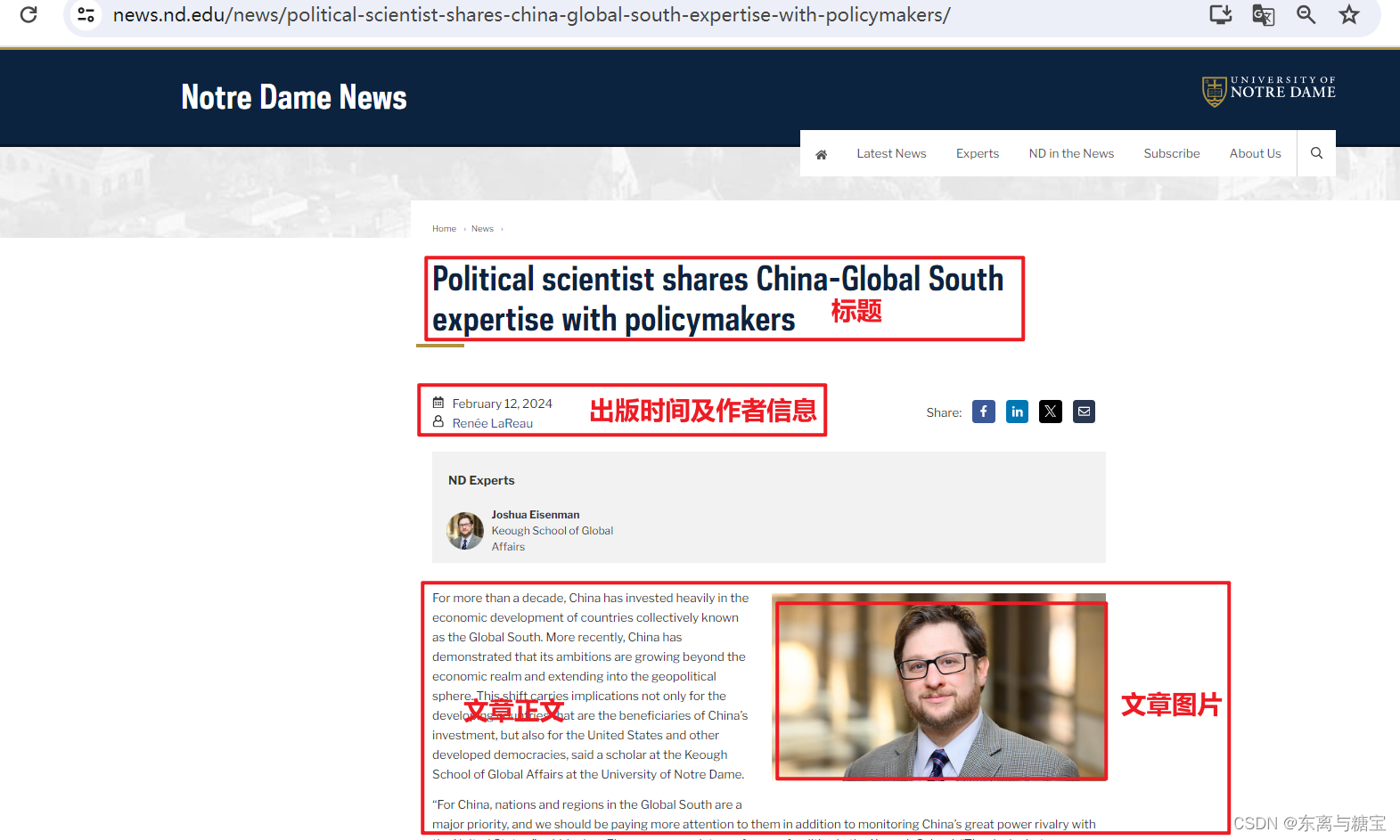
- 一篇文章有标题、出版时间和作者信息、文章正文和文章图片等信息
三、爬取新闻
1. 爬取模块
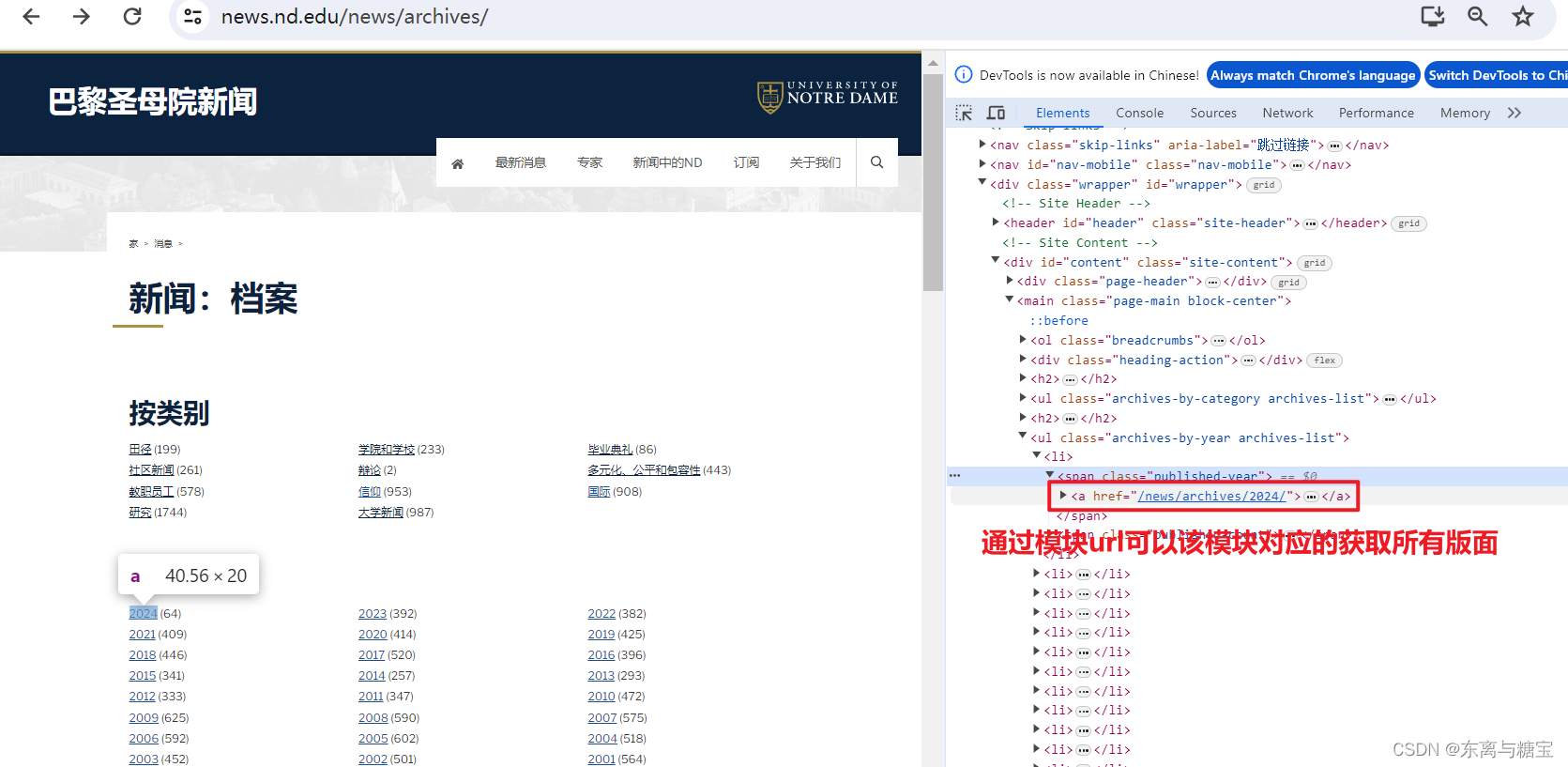
- 按照如下步骤找到包含模块的dom结构并发送request请求并用bs4库去解析
class MitnewsScraper:
def __init__(self, root_url, model_url, img_output_dir):
self.root_url = root_url
self.model_url = model_url
self.img_output_dir = img_output_dir
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/122.0.0.0 Safari/537.36',
'Cookie': '替换成你自己的',
}
...
def run():
# 网站根路径
root_url = 'https://news.nd.edu/'
# 文章图片保存路径
output_dir = 'D://imgs//nd-news'
response = requests.get('https://news.nd.edu/news/archives/')
soup = BeautifulSoup(response.text, 'html.parser')
# 模块地址数组
model_urls = []
model_url_array = soup.find('ul', 'archives-by-year archives-list').find_all('li')
for item in model_url_array:
model_url = root_url + item.find('a').get('href')
model_urls.append(model_url)
for model_url in model_urls:
# 初始化类
scraper = MitnewsScraper(root_url, model_url, output_dir)
# 遍历版面
scraper.catalogue_all_pages()
if __name__ == "__main__":
run()
2. 爬取版面
- 首先我们确认模块下版面切页相关的参数传递,通过切换页面我们不难发现切换页面是通过在路径加上 /page/页数 来实现的
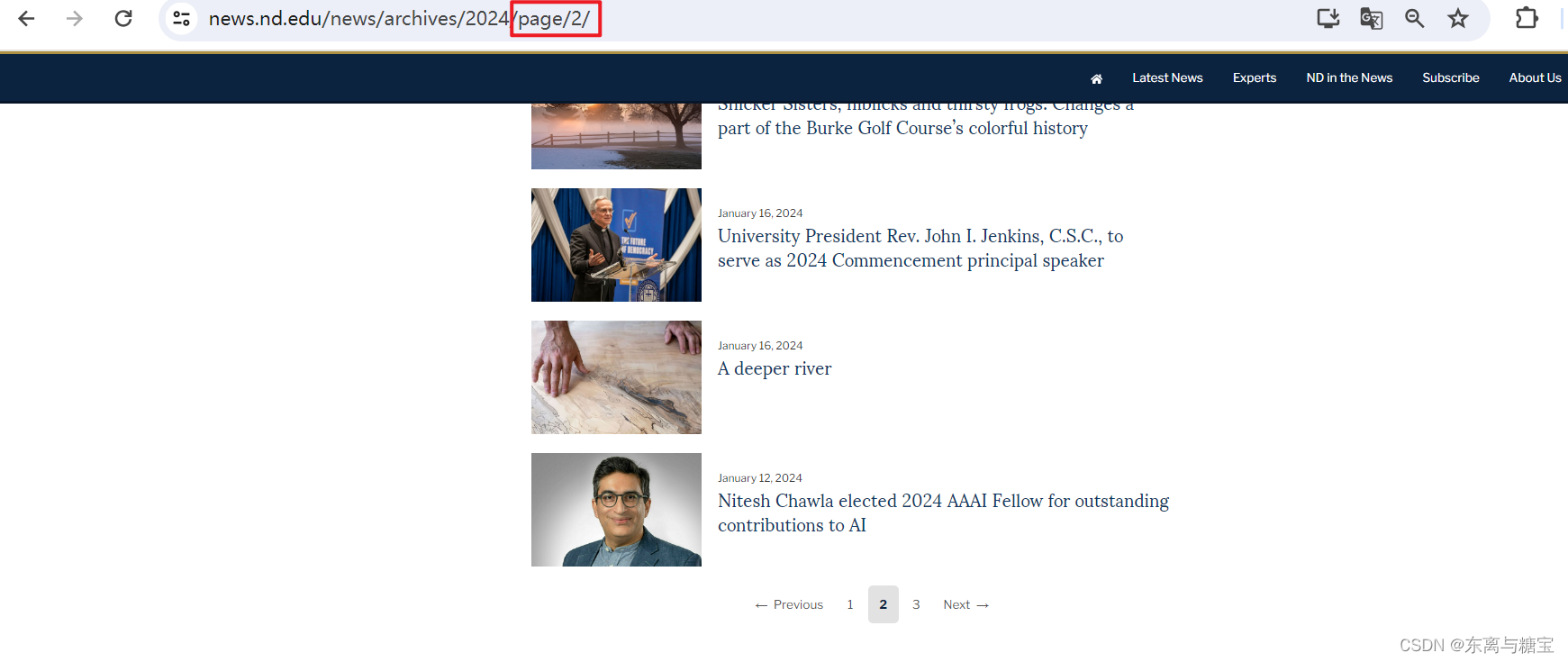
- 于是我们接着寻找模块下有多少页版面,通过观察控制台我们发现最后一页是在 类名为 pagination 的 div 标签里的倒数第二个 a 标签文本里
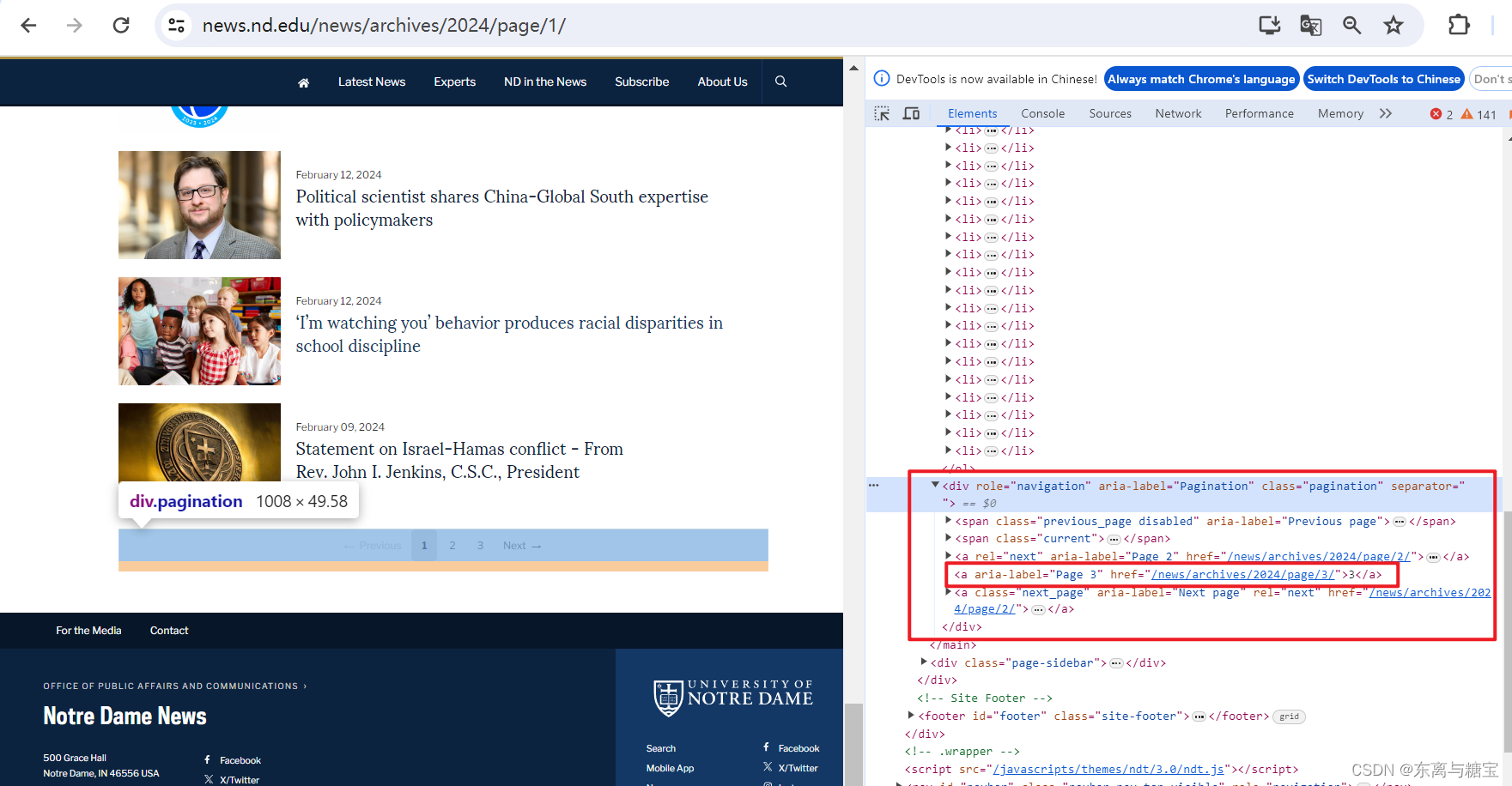
# 获取一个模块有多少版面
def catalogue_all_pages(self):
response = requests.get(self.model_url, headers=self.headers)
soup = BeautifulSoup(response.text, 'html.parser')
try:
model_name = self.model_url
len_catalogues_page = len(soup.find('div', 'pagination').find_all('a'))
list_catalogues_page = soup.find('div', 'pagination').find_all('a')
num_pages = list_catalogues_page[len_catalogues_page - 2].get_text()
print(self.model_url + ' 模块一共有' + num_pages + '页版面')
for page in range(1, num_pages + 1):
print(f"========start catalogues page {page}" + "/" + str(num_pages) + "========")
self.parse_catalogues(page)
print(f"========Finished catalogues page {page}" + "/" + str(num_pages) + "========")
except Exception as e:
print(f'Error: {e}')
traceback.print_exc()
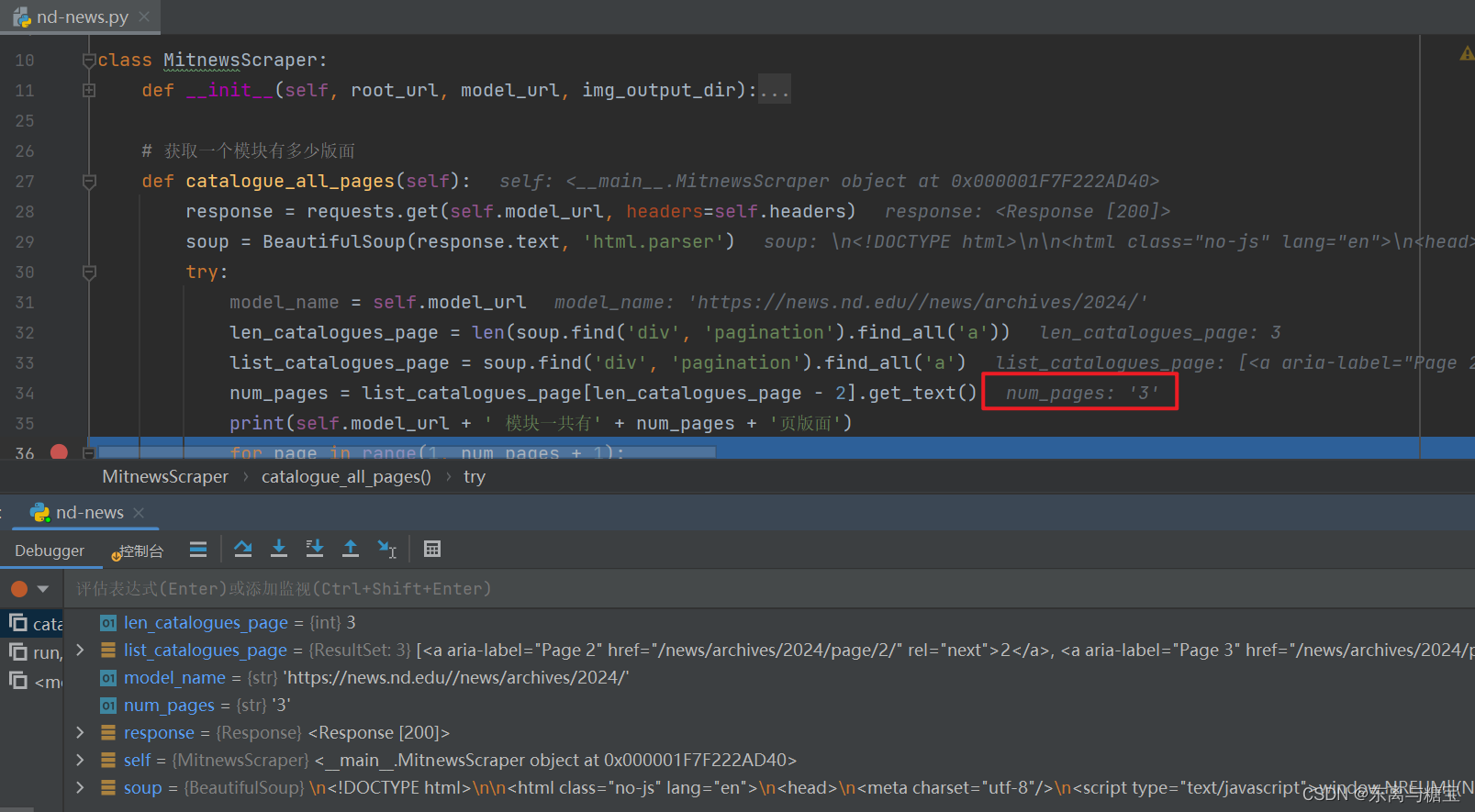
- 根据模块地址和page参数拼接完整版面地址,访问并解析找到对应的版面列表
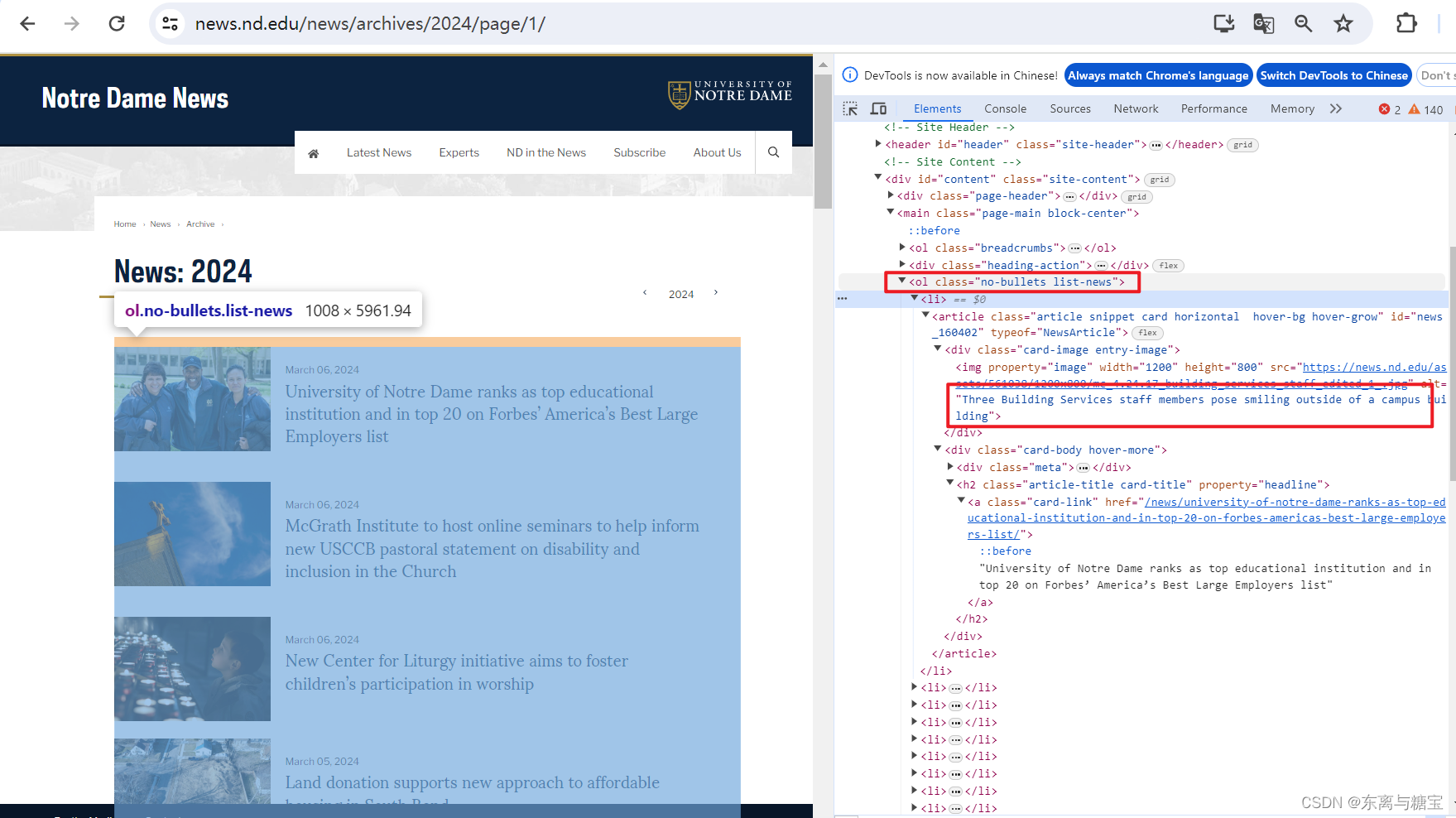
# 解析版面列表里的版面
def parse_catalogues(self, page):
url = self.model_url + '/page/' + str(page)
response = requests.get(url, headers=self.headers)
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'html.parser')
catalogue_list = soup.find('ol', 'no-bullets list-news')
catalogues_list = catalogue_list.find_all('li')
for index, catalogue in enumerate(catalogues_list):
print(f"========start catalogue {index+1}" + "/" + "30========")
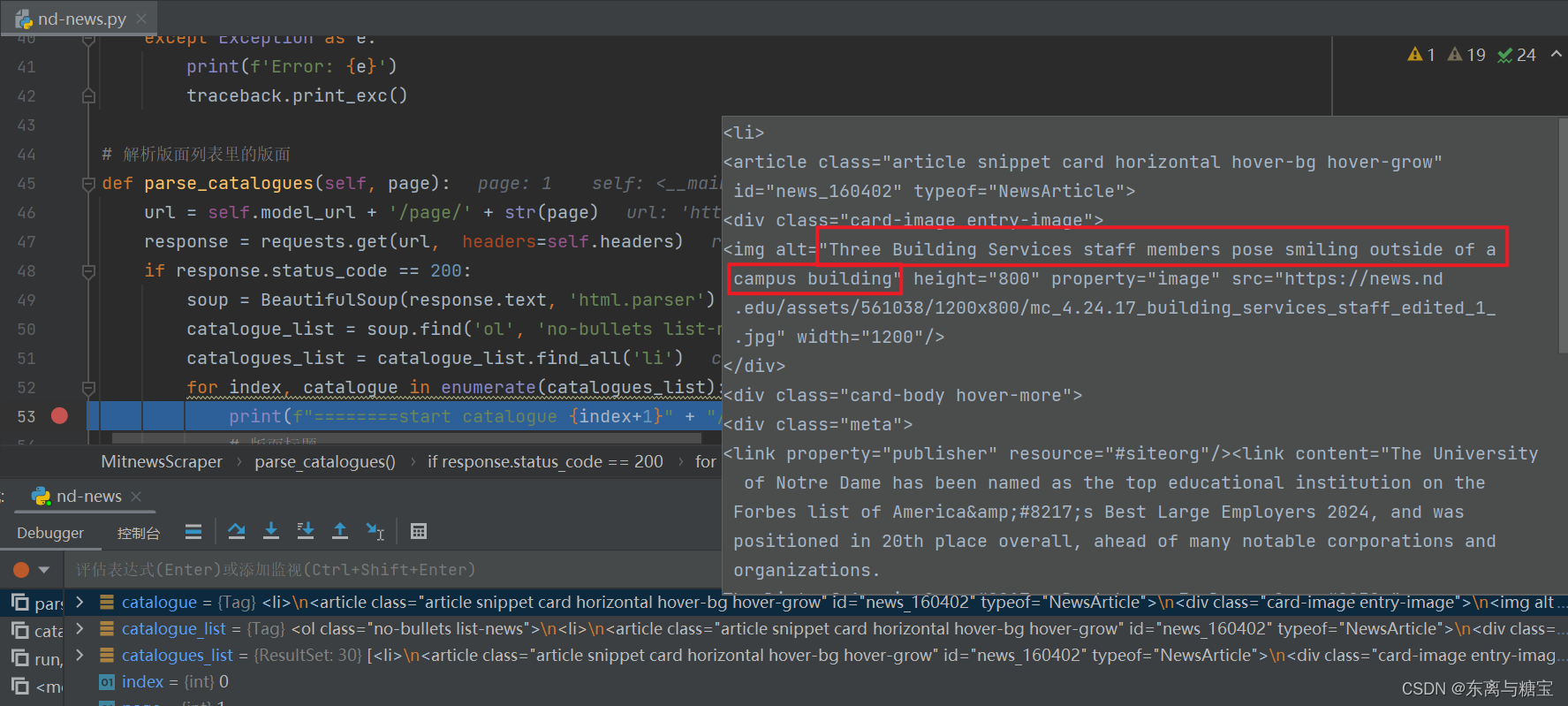
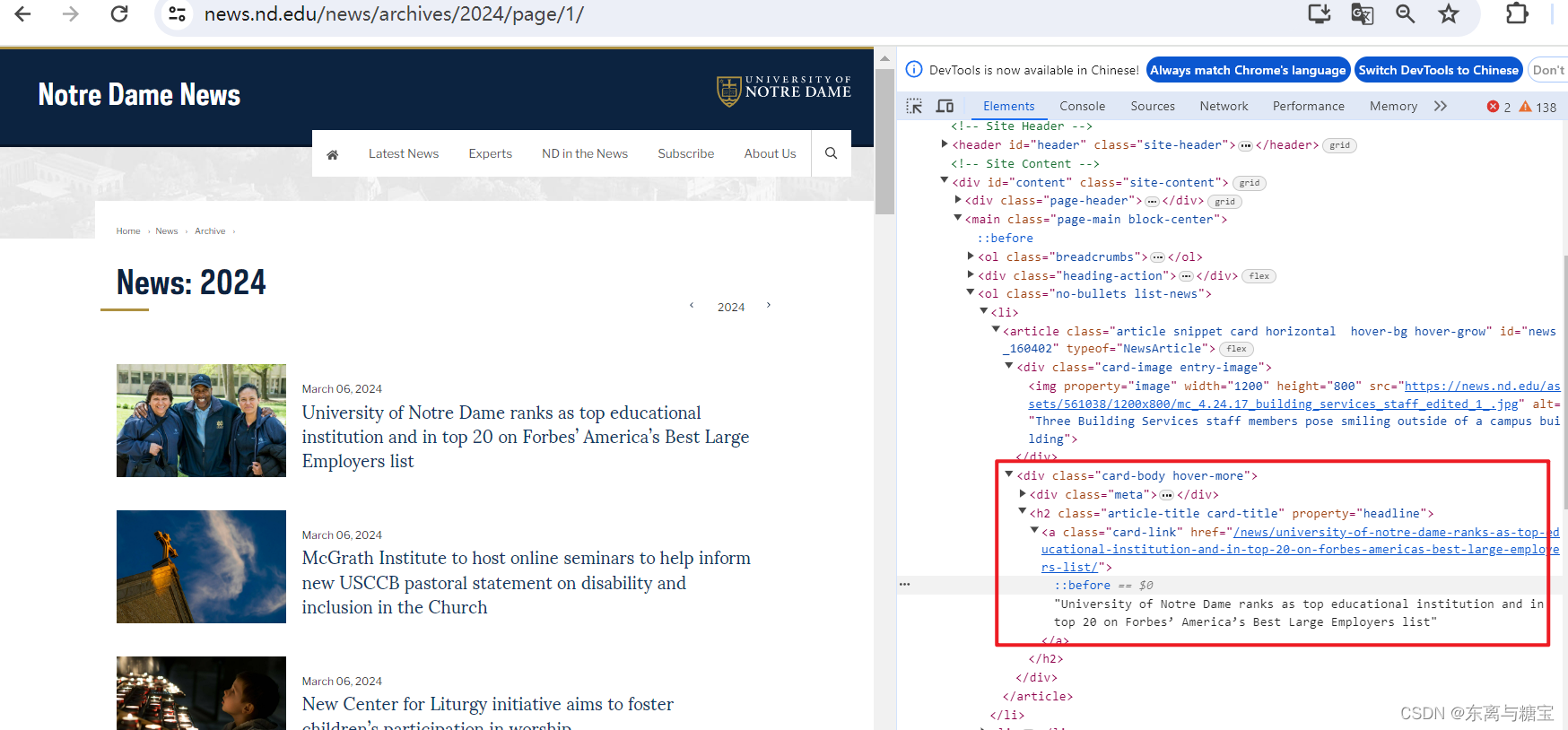
- 遍历版面列表,获取版面标题
# 版面标题
catalogue_title = catalogue.find('div', 'card-body hover-more').find('h2').find('a').get_text(strip=True)
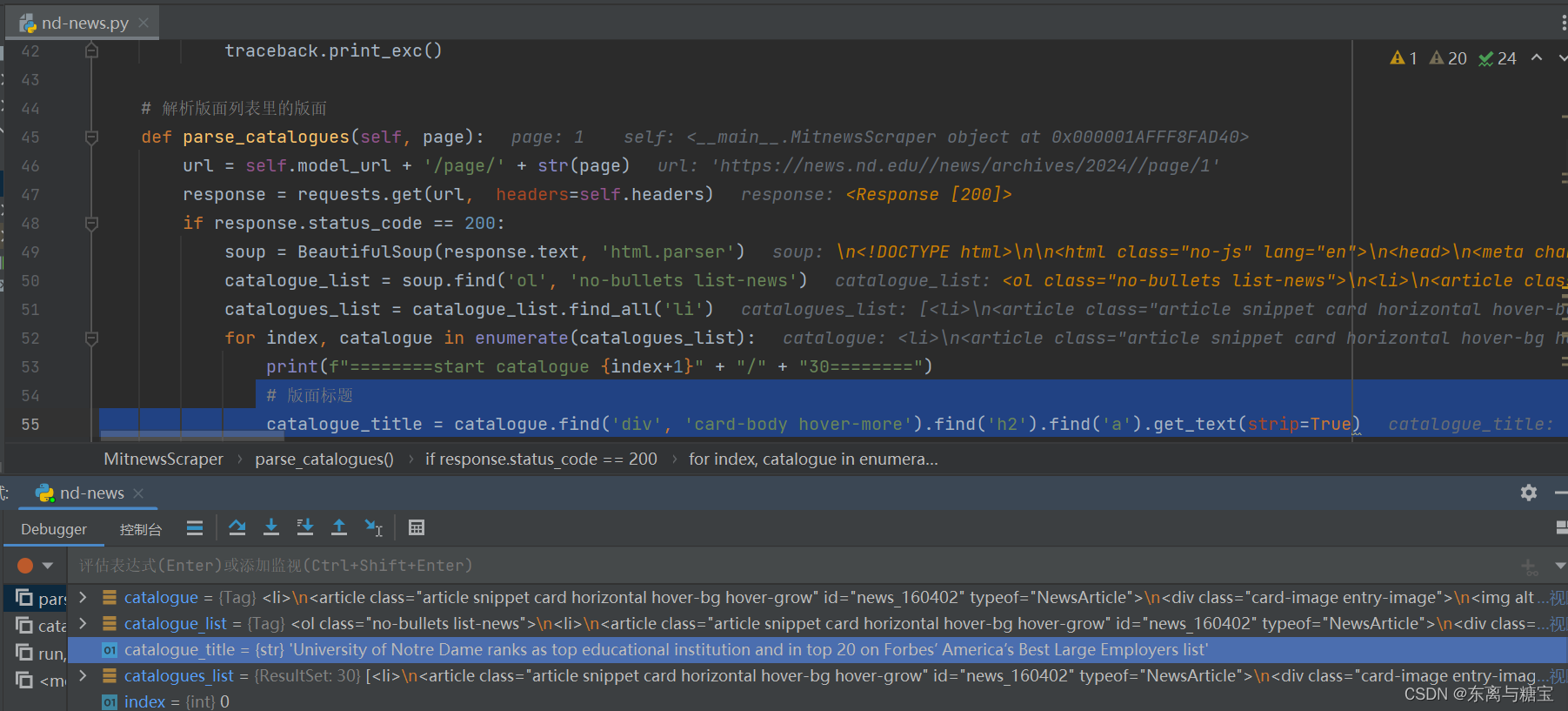
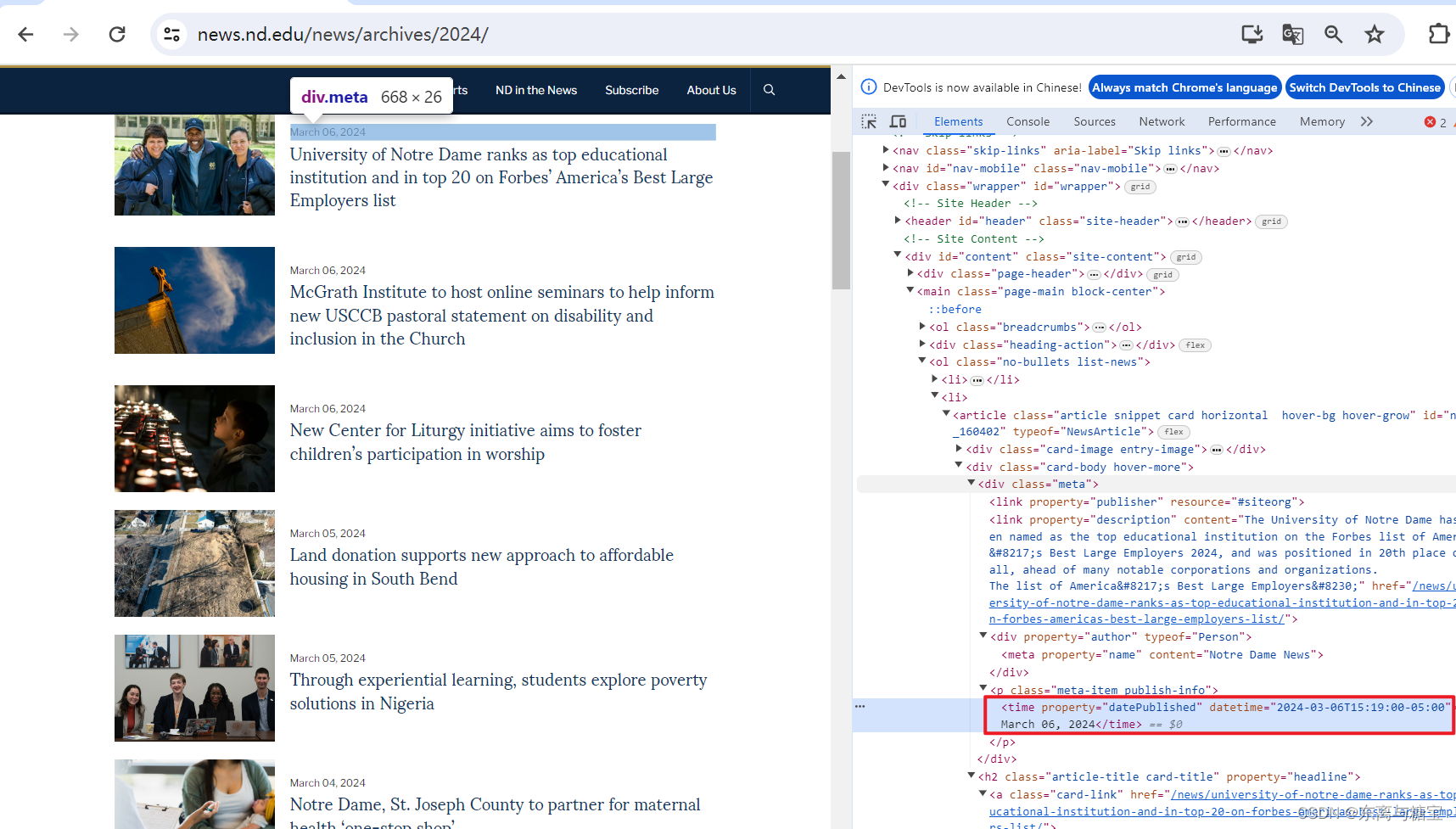
- 获取出版时间
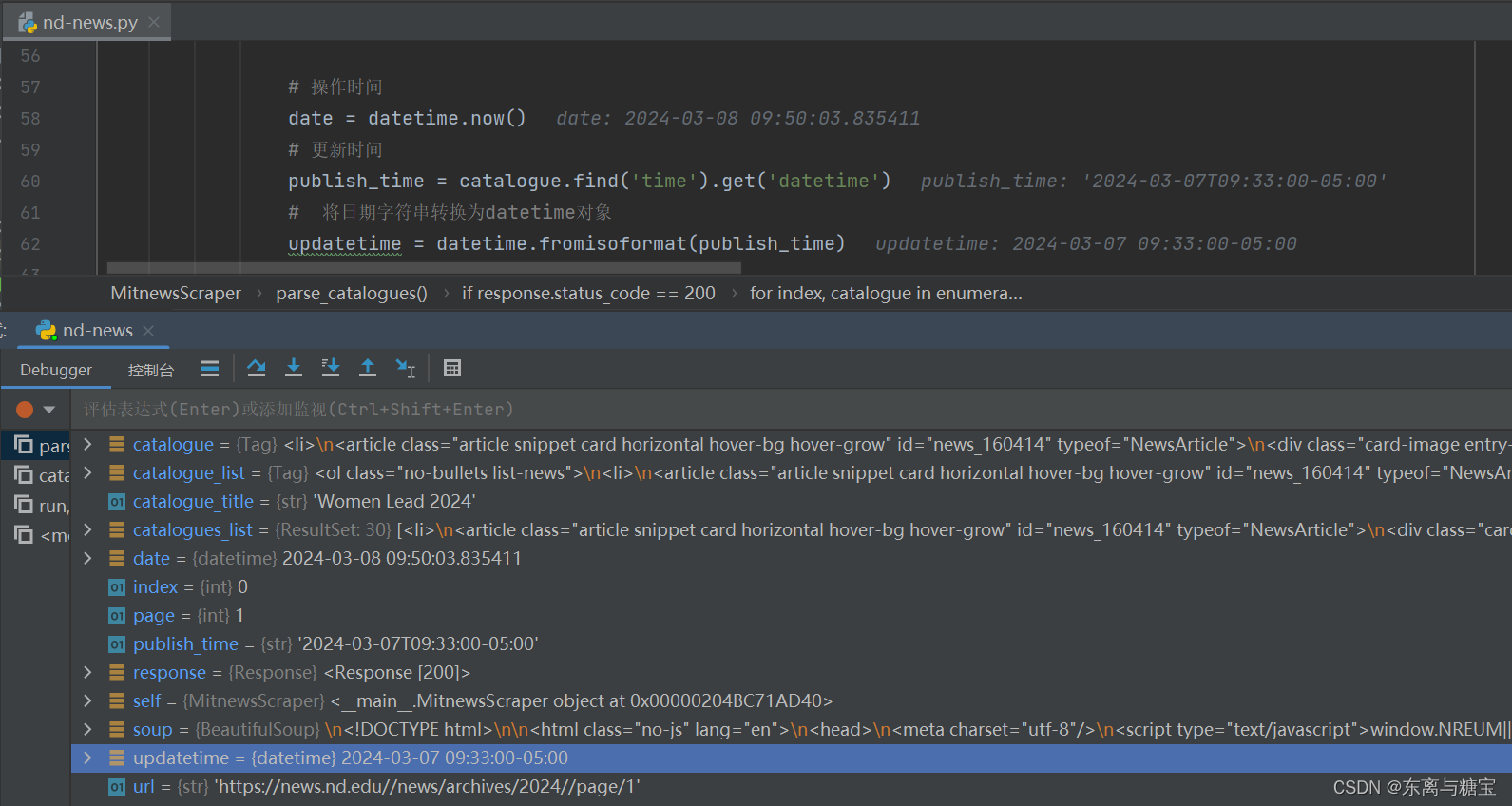
# 操作时间
date = datetime.now()
# 更新时间
publish_time = catalogue.find('time').get('datetime')
# 将日期字符串转换为datetime对象
updatetime = datetime.fromisoformat(publish_time)
- 保存版面url和版面id, 由于该新闻是一个版面对应一篇文章,所以版面url和文章url是一样的,而且文章没有明显的标识,我们把地址后缀作为文章id,版面id则是文章id后面加上个01
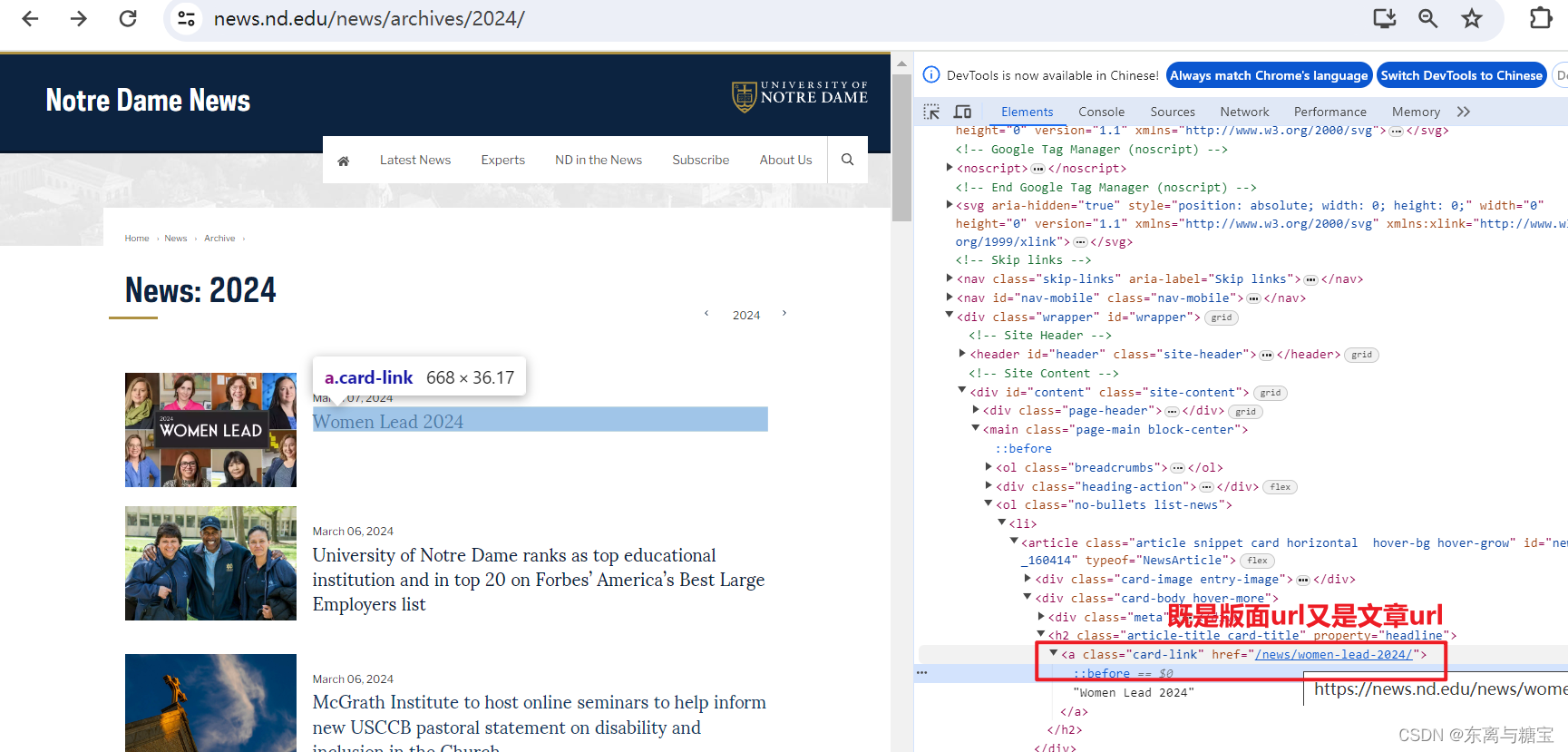

# 版面url
catalogue_href = catalogue.find('h2').find('a').get('href')
catalogue_url = self.root_url + catalogue_href
# 正则表达式
pattern = r'/news/(.+?)/$'
# 使用 re.search() 来搜索匹配项
match = re.search(pattern, catalogue_url)
# 版面id
catalogue_id = match.group(1)
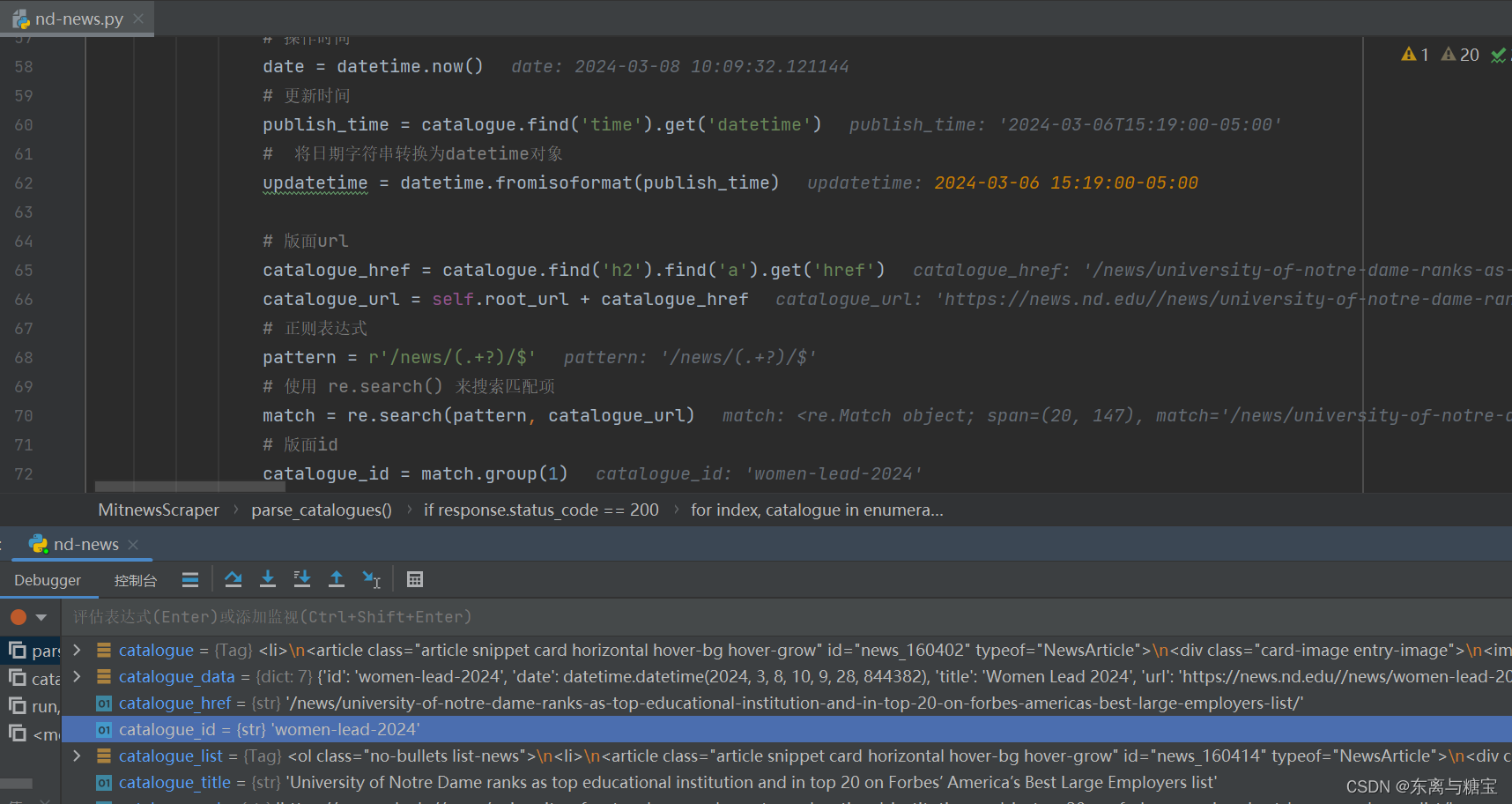
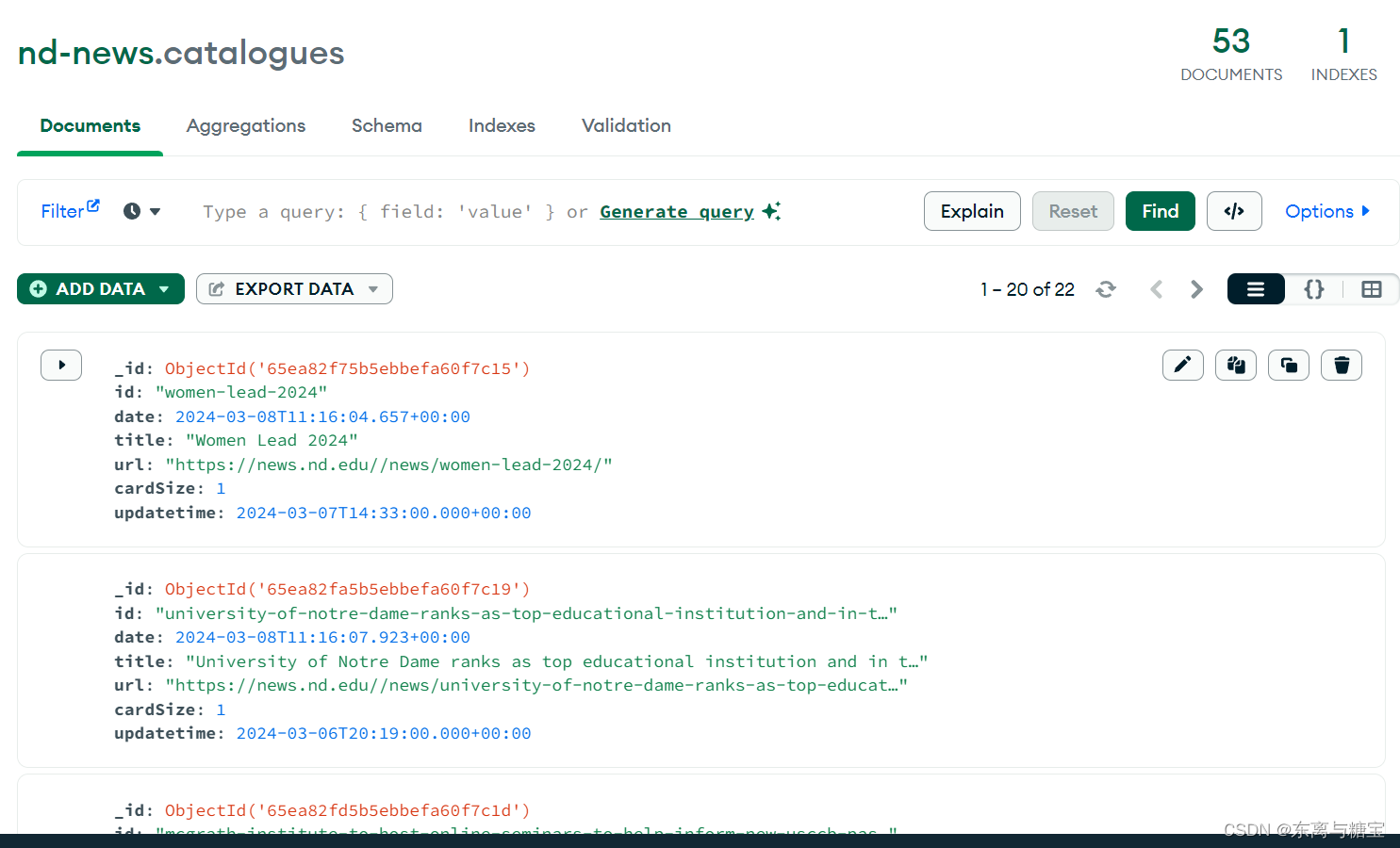
- 保存版面信息到mogodb数据库(由于每个版面只有一篇文章,所以版面文章数量cardsize的值赋为1)
# 连接 MongoDB 数据库服务器
client = MongoClient('mongodb://localhost:27017/')
# 创建或选择数据库
db = client['nd-news']
# 创建或选择集合
catalogues_collection = db['catalogues']
# 插入示例数据到 catalogues 集合
catalogue_data = {
'id': catalogue_id,
'date': date,
'title': catalogue_title,
'url': catalogue_url,
'cardSize': 1,
'updatetime': updatetime
}
# 在插入前检查是否存在相同id的文档
existing_document = catalogues_collection.find_one({'id': catalogue_id})
# 如果不存在相同id的文档,则插入新文档
if existing_document is None:
catalogues_collection.insert_one(catalogue_data)
print("[爬取版面]版面 " + catalogue_url + " 已成功插入!")
else:
print("[爬取版面]版面 " + catalogue_url + " 已存在!")
print(f"========finsh catalogue {index+1}" + "/" + "10========")
return True
else:
raise Exception(f"Failed to fetch page {page}. Status code: {response.status_code}")
3. 爬取文章
-
由于一个版面对应一篇文章,所以版面url 、更新时间、标题和文章是一样的,并且按照设计版面id和文章id的区别只是差了个01,所以可以传递版面url、版面id、更新时间和标题四个参数到解析文章的函数里面
-
获取文章id,文章url,文章更新时间和当下操作时间
# 解析版面列表里的版面
def parse_catalogues(self, page):
...
self.parse_cards_list(catalogue_url, catalogue_id, updatetime, catalogue_title)
...
# 解析文章列表里的文章
def parse_cards_list(self, url, catalogue_id, cardupdatetime, cardtitle):
card_response = requests.get(url, headers=self.headers)
soup = BeautifulSoup(card_response.text, 'html.parser')
# 对应的版面id
card_id = catalogue_id
# 文章标题
card_title = cardtitle
# 文章更新时间
updateTime = cardupdatetime
# 操作时间
date = datetime.now()
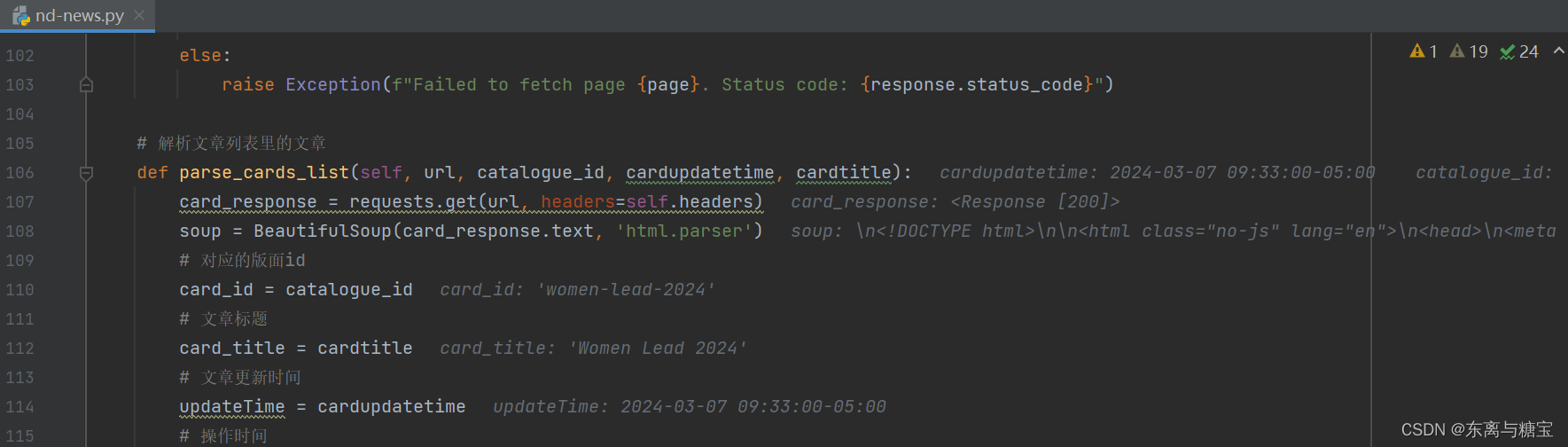
- 获取文章作者
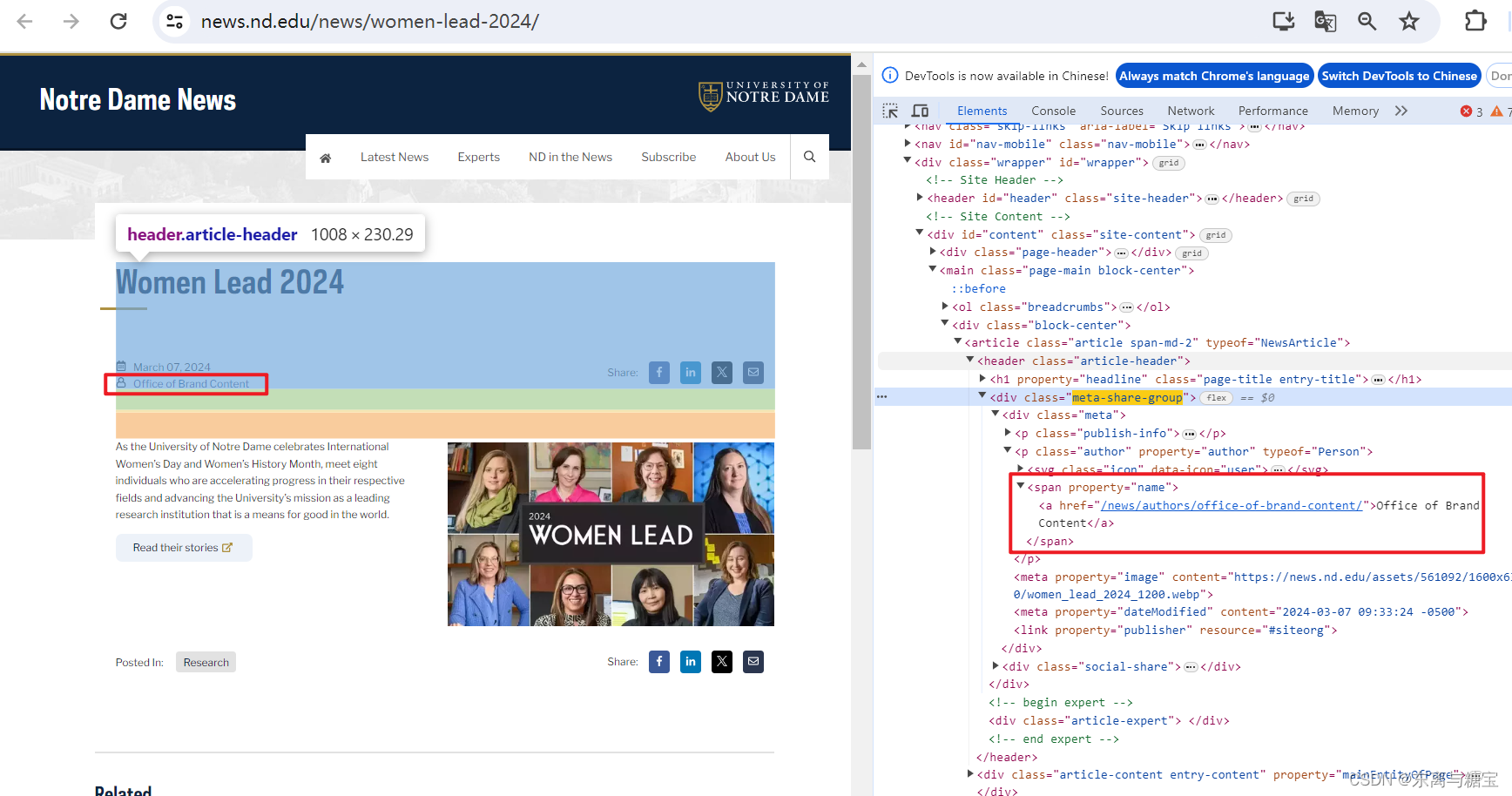
# 文章作者
author = soup.find('article', 'article span-md-2').find('p', 'author').find('span', property='name').get_text()
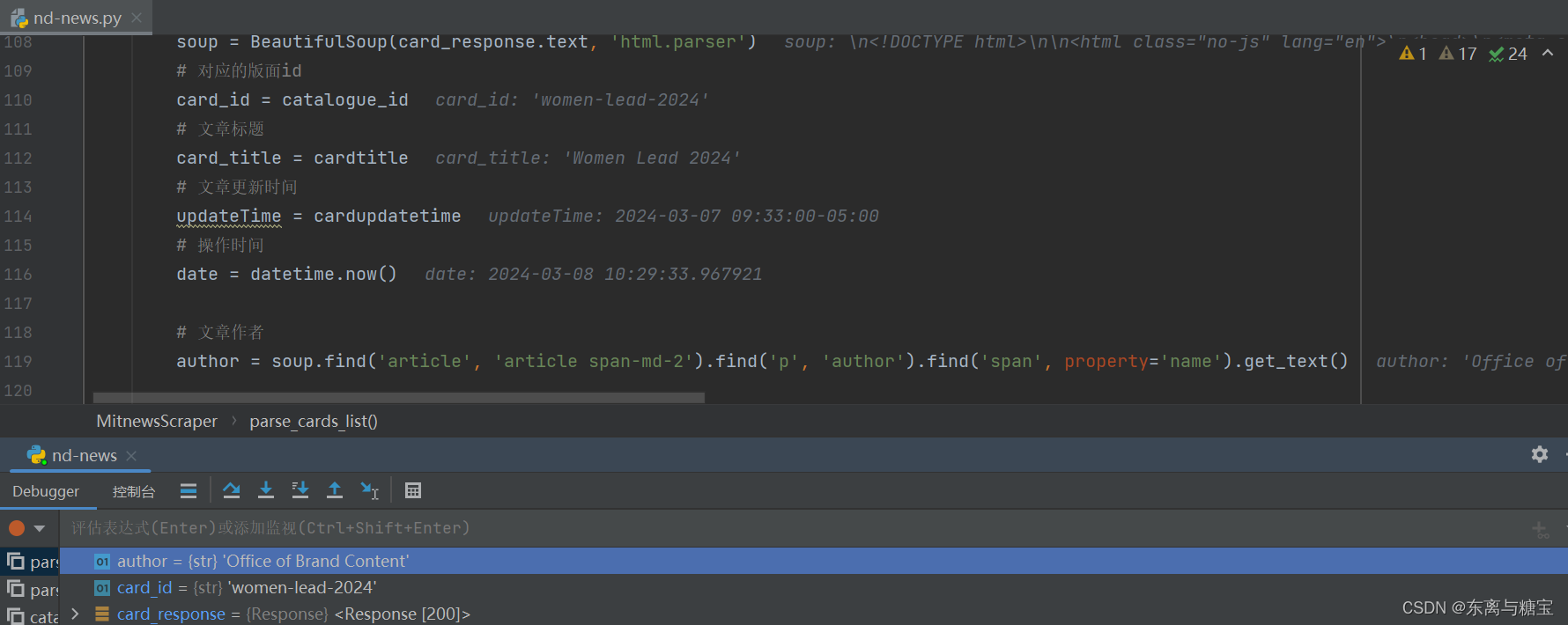
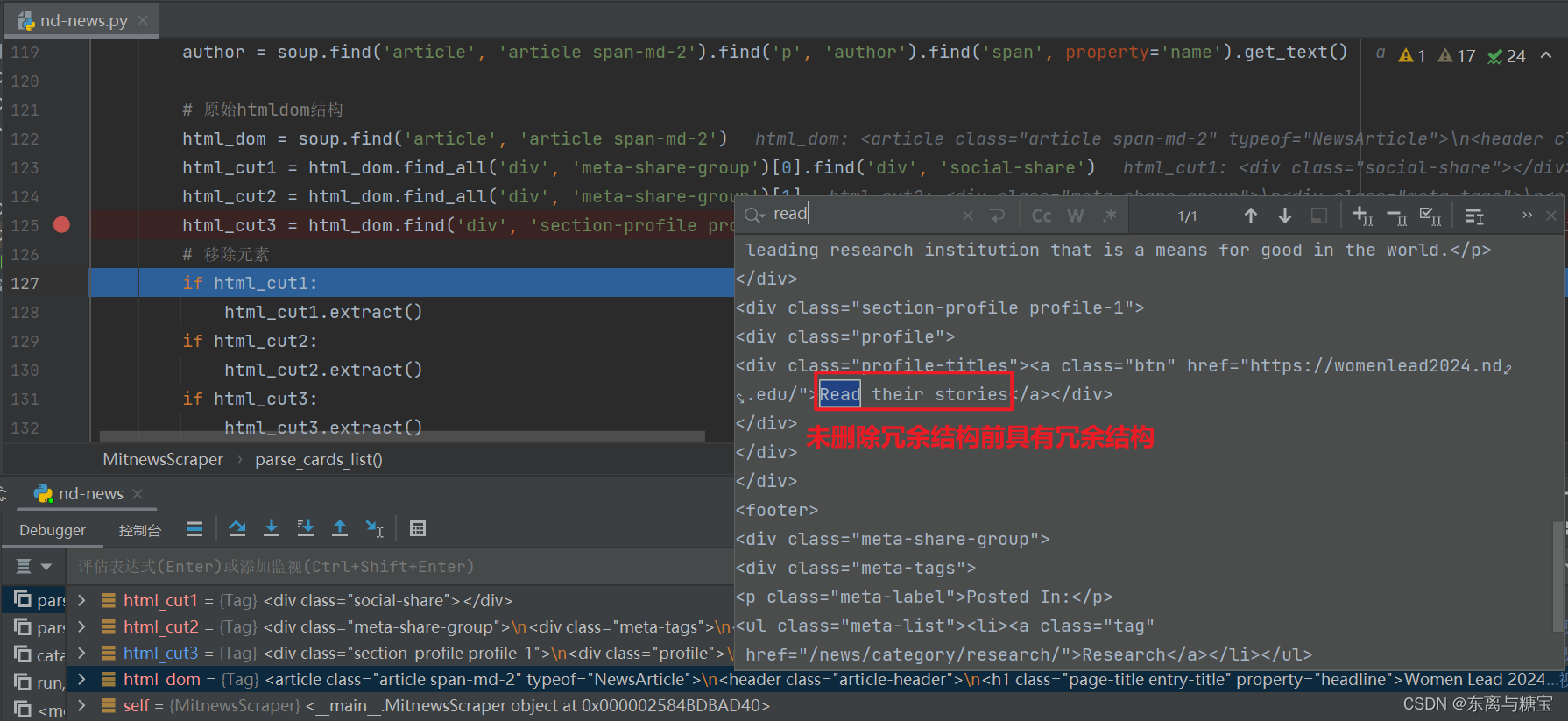
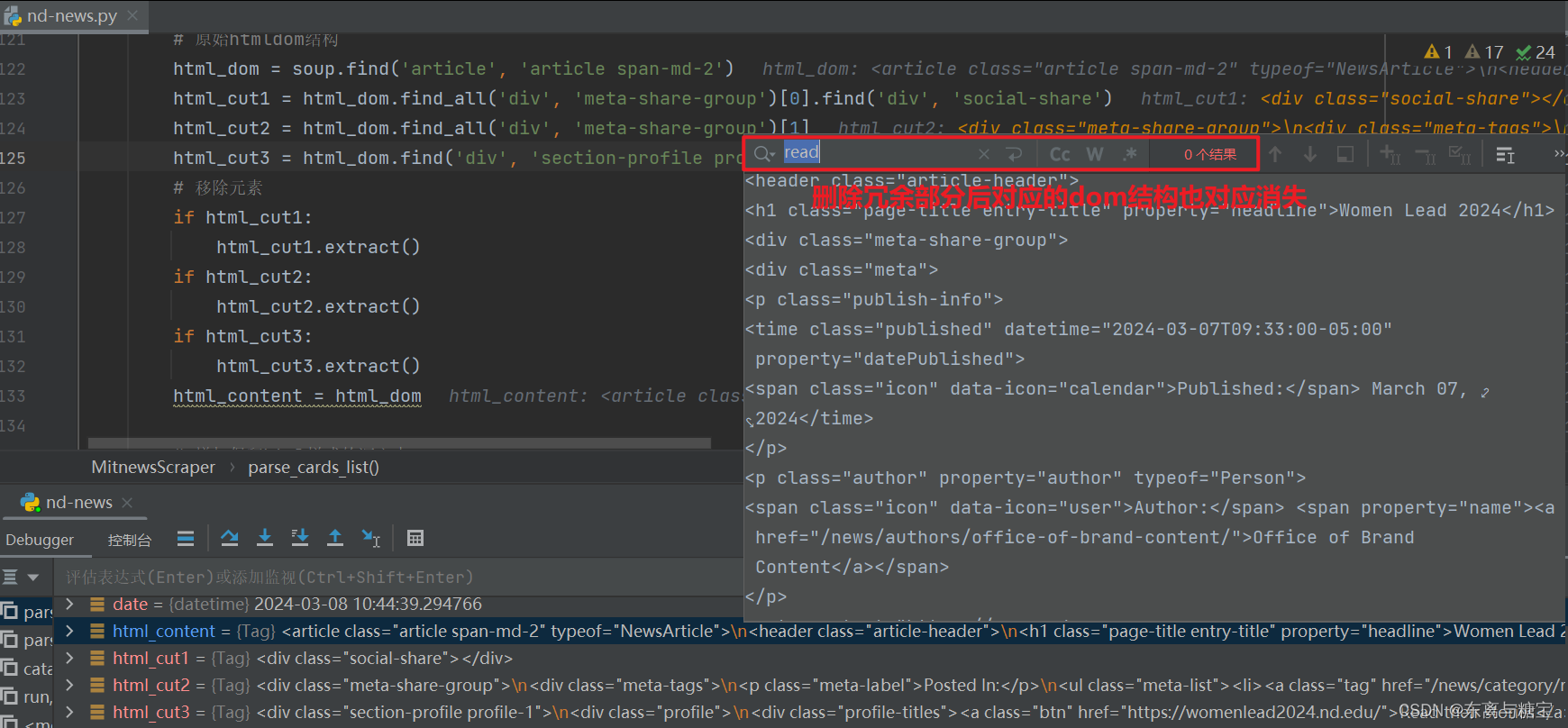
- 获取文章原始htmldom结构,并删除无用的部分(以下仅是部分举例),用html_content字段保留原始dom结构

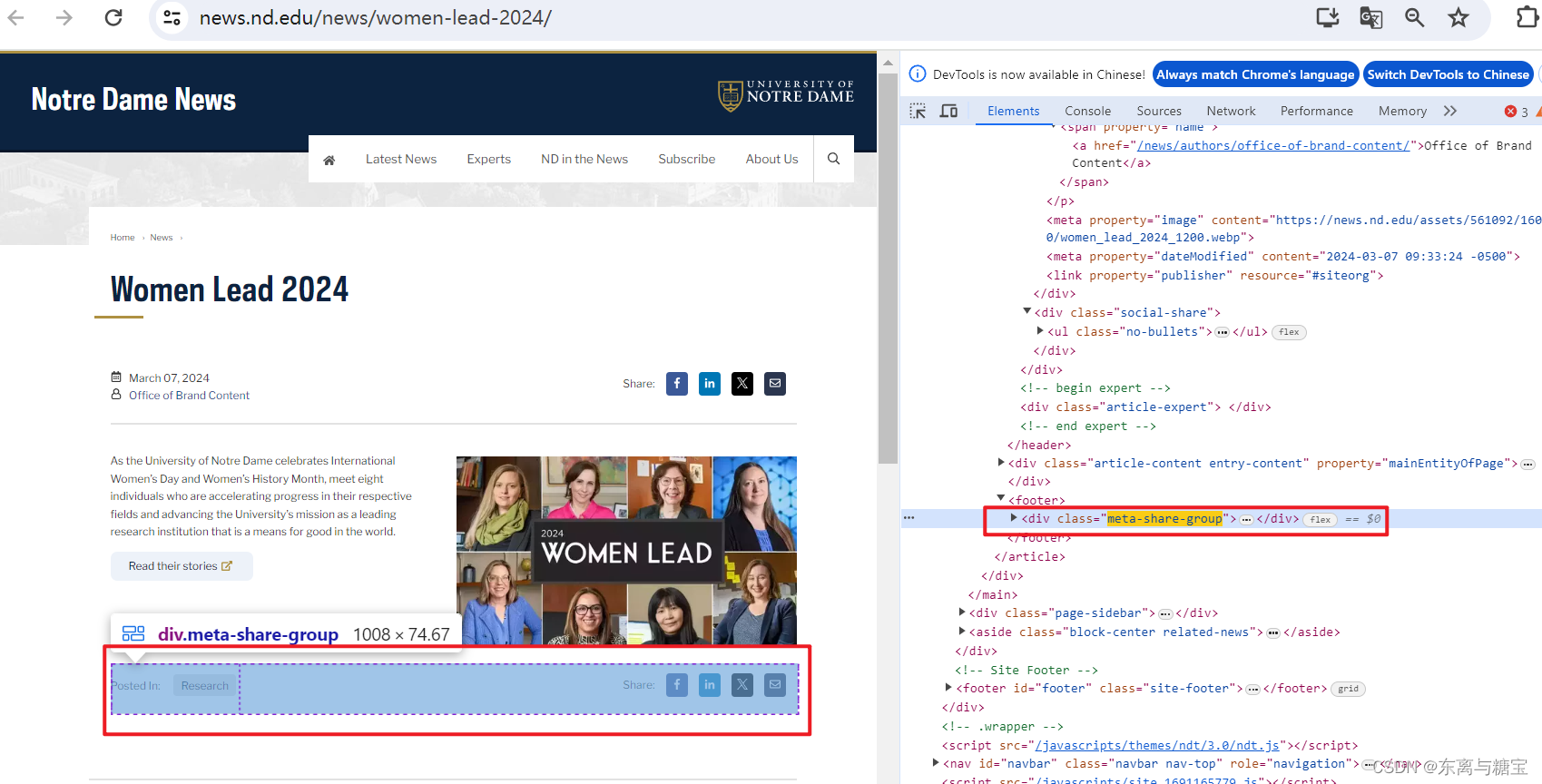
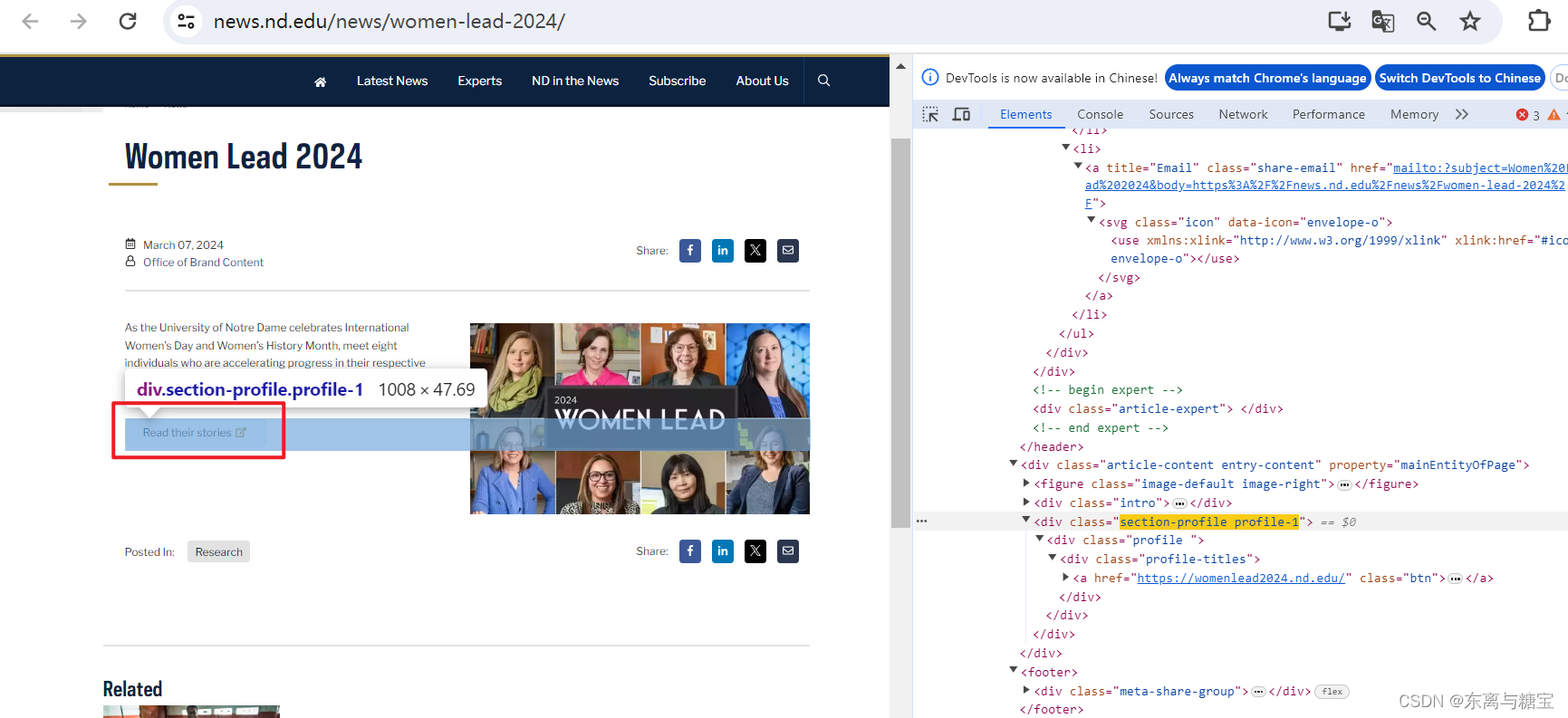
# 原始htmldom结构
html_dom = soup.find('article', 'article span-md-2')
html_cut1 = html_dom.find_all('div', 'meta-share-group')[0].find('div', 'social-share')
html_cut2 = html_dom.find_all('div', 'meta-share-group')[1]
html_cut3 = html_dom.find('div', 'section-profile profile-1')
# 移除元素
if html_cut1:
html_cut1.extract()
if html_cut2:
html_cut2.extract()
if html_cut3:
html_cut3.extract()
html_content = html_dom
- 进行文章清洗,保留文本,去除标签,用content保留清洗后的文本
# 解析文章列表里的文章
def parse_cards_list(self, url, catalogue_id, cardupdatetime, cardtitle):
...
# 增加保留html样式的源文本
origin_html = html_dom.prettify() # String
# 转义网页中的图片标签
str_html = self.transcoding_tags(origin_html)
# 再包装成
temp_soup = BeautifulSoup(str_html, 'html.parser')
# 反转译文件中的插图
str_html = self.translate_tags(temp_soup.text)
# 绑定更新内容
content = self.clean_content(str_html)
...
# 工具 转义标签
def transcoding_tags(self, htmlstr):
re_img = re.compile(r'\s*<(img.*?)>\s*', re.M)
s = re_img.sub(r'\n @@##\1##@@ \n', htmlstr) # IMG 转义
return s
# 工具 转义标签
def translate_tags(self, htmlstr):
re_img = re.compile(r'@@##(img.*?)##@@', re.M)
s = re_img.sub(r'<\1>', htmlstr) # IMG 转义
return s
# 清洗文章
def clean_content(self, content):
if content is not None:
content = re.sub(r'\r', r'\n', content)
content = re.sub(r'\n{2,}', '', content)
content = re.sub(r' {6,}', '', content)
content = re.sub(r' {3,}\n', '', content)
content = re.sub(r'<img src="../../../image/zxbl.gif"/>', '', content)
content = content.replace(
'<img border="0" src="****处理标记:[Article]时, 字段 [SnapUrl] 在数据源中没有找到! ****"/> ', '')
content = content.replace(
''' <!--/enpcontent<INPUT type=checkbox value=0 name=titlecheckbox sourceid="<Source>SourcePh " style="display:none">''',
'') \
.replace(' <!--enpcontent', '').replace('<TABLE>', '')
content = content.replace('<P>', '').replace('<\P>', '').replace(' ', ' ')
return content
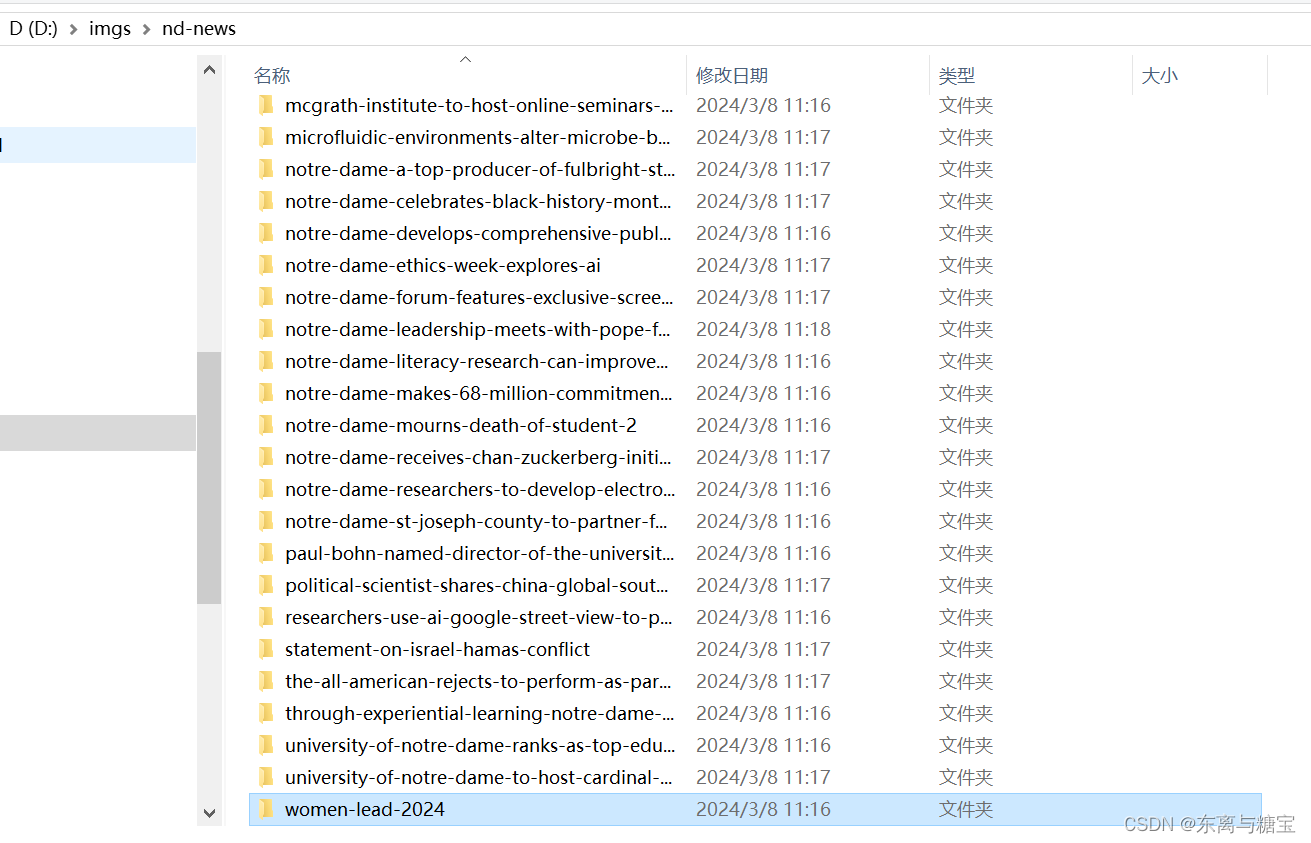
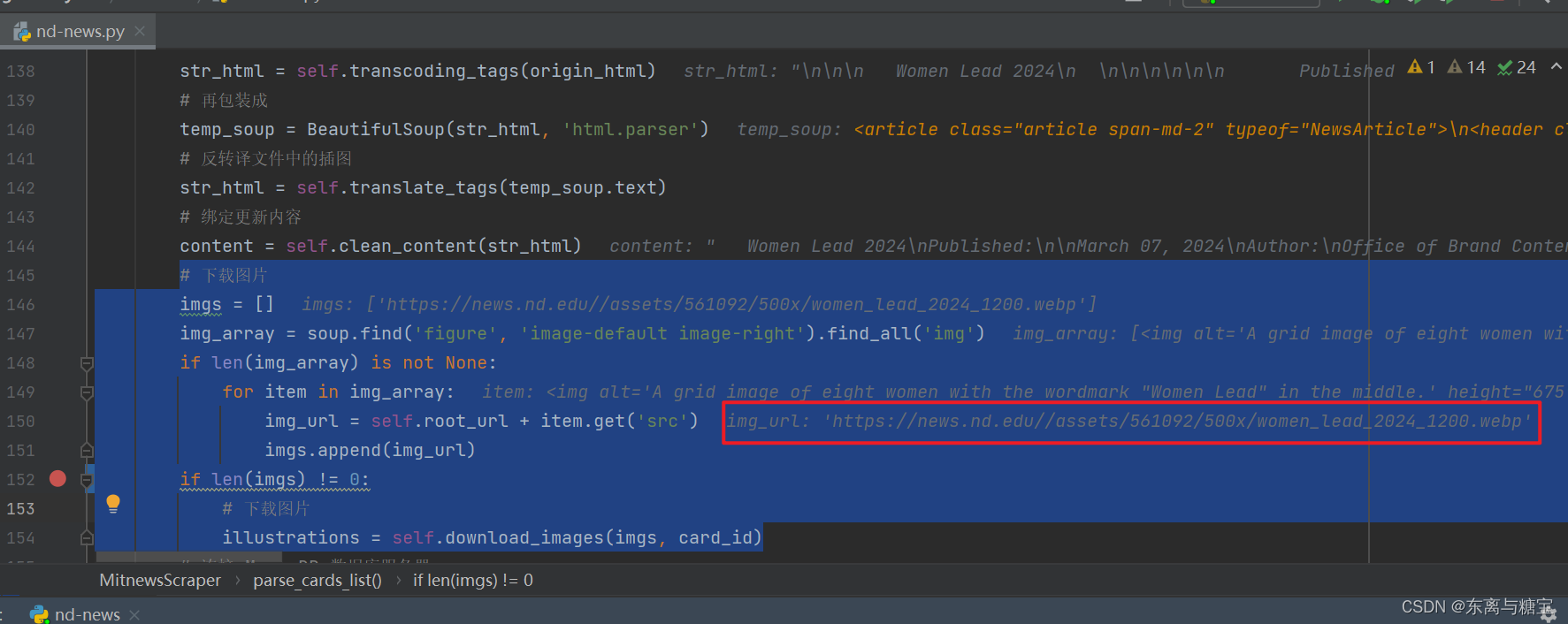
- 下载保存文章图片,保存到d盘目录下的imgs/nd-news文件夹下,每篇文章图片用一个命名为文章id的文件夹命名,并用字段illustrations保存图片的绝对路径和相对路径
# 解析文章列表里的文章
def parse_cards_list(self, url, catalogue_id, cardupdatetime, cardtitle):
...
# 下载图片
imgs = []
img_array = soup.find('div', 'article-content entry-content').find_all('img')
if len(img_array) is not None:
for item in img_array:
img_url = self.root_url + item.get('src')
imgs.append(img_url)
if len(imgs) != 0:
# 下载图片
illustrations = self.download_images(imgs, card_id)
# 下载图片
def download_images(self, img_urls, card_id):
result = re.search(r'[^/]+$', card_id)
last_word = result.group(0)
# 根据card_id创建一个新的子目录
images_dir = os.path.join(self.img_output_dir, str(last_word)) if not os.path.exists(images_dir):
os.makedirs(images_dir)
downloaded_images = []
for index, img_url in enumerate(img_urls):
try:
response = requests.get(img_url, stream=True, headers=self.headers)
if response.status_code == 200:
# 从URL中提取图片文件名
img_name_with_extension = img_url.split('/')[-1]
pattern = r'^[^?]*'
match = re.search(pattern, img_name_with_extension)
img_name = match.group(0)
# 保存图片
with open(os.path.join(images_dir, img_name), 'wb') as f:
f.write(response.content)
downloaded_images.append([img_url, os.path.join(images_dir, img_name)])
print(f'[爬取文章图片]文章id为{card_id}的图片已保存到本地')
except requests.exceptions.RequestException as e:
print(f'请求图片时发生错误:{e}')
except Exception as e:
print(f'保存图片时发生错误:{e}')
return downloaded_images
# 如果文件夹存在则跳过
else:
print(f'[爬取文章图片]文章id为{card_id}的图片文件夹已经存在')
return []
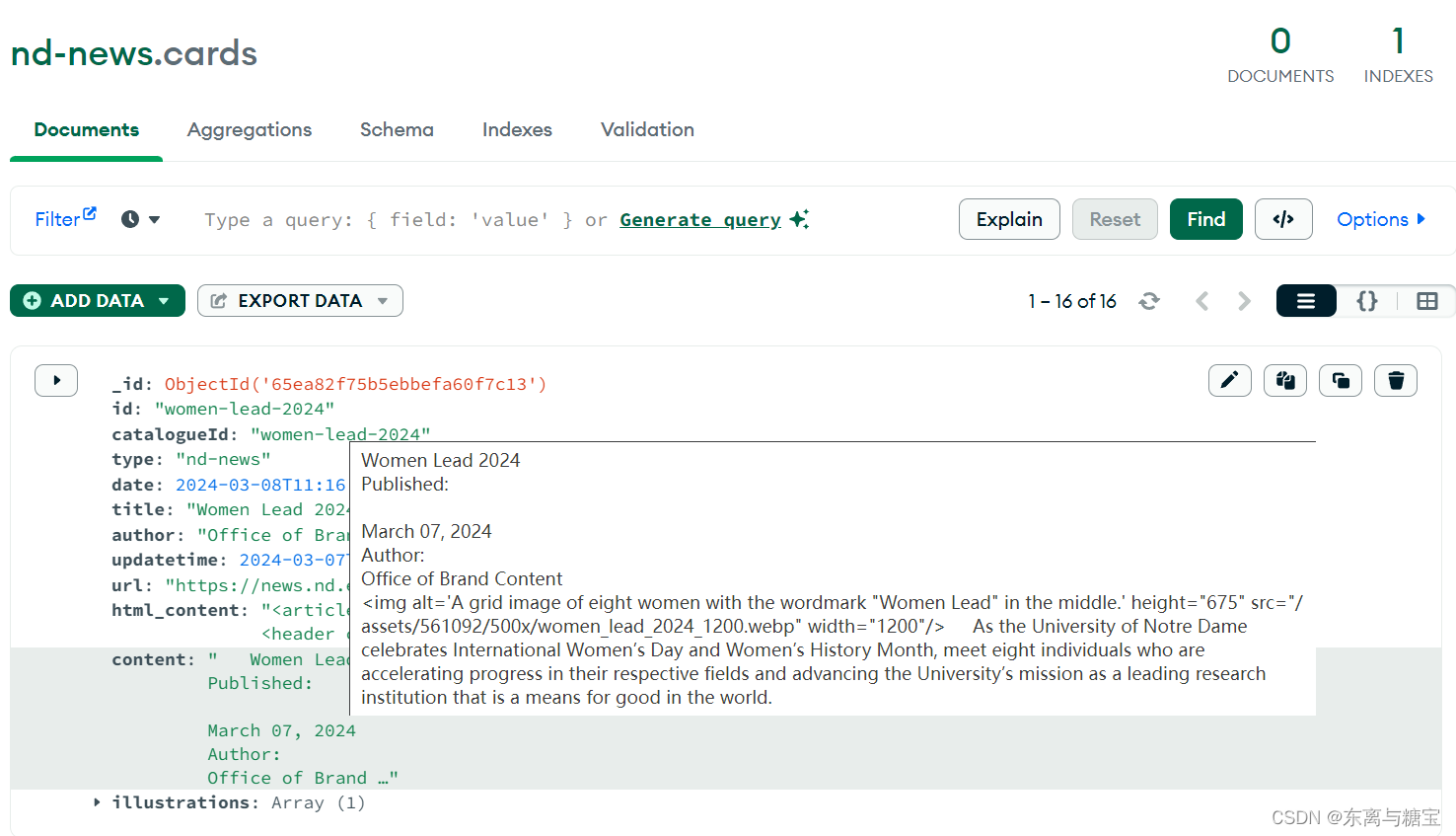
- 保存文章数据到数据库
# 连接 MongoDB 数据库服务器
client = MongoClient('mongodb://localhost:27017/')
# 创建或选择数据库
db = client['nd-news']
# 创建或选择集合
cards_collection = db['cards']
# 插入示例数据到 cards 集合
card_data = {
'id': card_id,
'catalogueId': catalogue_id,
'type': 'nd-news',
'date': date,
'title': card_title,
'author': author,
'updatetime': updateTime,
'url': url,
'html_content': str(html_content),
'content': content,
'illustrations': illustrations,
}
# 在插入前检查是否存在相同id的文档
existing_document = cards_collection.find_one({'id': card_id})
# 如果不存在相同id的文档,则插入新文档
if existing_document is None:
cards_collection.insert_one(card_data)
print("[爬取文章]文章 " + url + " 已成功插入!")
else:
print("[爬取文章]文章 " + url + " 已存在!")
四、完整代码
import os
from datetime import datetime
import requests
from bs4 import BeautifulSoup
from pymongo import MongoClient
import re
import traceback
class MitnewsScraper:
def __init__(self, root_url, model_url, img_output_dir):
self.root_url = root_url
self.model_url = model_url
self.img_output_dir = img_output_dir
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/122.0.0.0 Safari/537.36',
'Cookie': ''
}
# 获取一个模块有多少版面
def catalogue_all_pages(self):
response = requests.get(self.model_url, headers=self.headers)
soup = BeautifulSoup(response.text, 'html.parser')
try:
model_name = self.model_url
len_catalogues_page = len(soup.find('div', 'pagination').find_all('a'))
list_catalogues_page = soup.find('div', 'pagination').find_all('a')
num_pages = list_catalogues_page[len_catalogues_page - 2].get_text()
print(self.model_url + ' 模块一共有' + num_pages + '页版面')
for page in range(1, int(num_pages) + 1):
print(f"========start catalogues page {page}" + "/" + str(num_pages) + "========")
self.parse_catalogues(page)
print(f"========Finished catalogues page {page}" + "/" + str(num_pages) + "========")
except Exception as e:
print(f'Error: {e}')
traceback.print_exc()
# 解析版面列表里的版面
def parse_catalogues(self, page):
url = self.model_url + '/page/' + str(page)
response = requests.get(url, headers=self.headers)
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'html.parser')
catalogue_list = soup.find('ol', 'no-bullets list-news')
catalogues_list = catalogue_list.find_all('li')
for index, catalogue in enumerate(catalogues_list):
print(f"========start catalogue {index+1}" + "/" + "30========")
# 版面标题
catalogue_title = catalogue.find('div', 'card-body hover-more').find('h2').find('a').get_text(strip=True)
# 操作时间
date = datetime.now()
# 更新时间
publish_time = catalogue.find('time').get('datetime')
# 将日期字符串转换为datetime对象
updatetime = datetime.fromisoformat(publish_time)
# 版面url
catalogue_href = catalogue.find('h2').find('a').get('href')
catalogue_url = self.root_url + catalogue_href
# 正则表达式
pattern = r'/news/(.+?)/$'
# 使用 re.search() 来搜索匹配项
match = re.search(pattern, catalogue_url)
# 版面id
catalogue_id = match.group(1)
self.parse_cards_list(catalogue_url, catalogue_id, updatetime, catalogue_title)
# 连接 MongoDB 数据库服务器
client = MongoClient('mongodb://localhost:27017/')
# 创建或选择数据库
db = client['nd-news']
# 创建或选择集合
catalogues_collection = db['catalogues']
# 插入示例数据到 catalogues 集合
catalogue_data = {
'id': catalogue_id,
'date': date,
'title': catalogue_title,
'url': catalogue_url,
'cardSize': 1,
'updatetime': updatetime
}
# 在插入前检查是否存在相同id的文档
existing_document = catalogues_collection.find_one({'id': catalogue_id})
# 如果不存在相同id的文档,则插入新文档
if existing_document is None:
catalogues_collection.insert_one(catalogue_data)
print("[爬取版面]版面 " + catalogue_url + " 已成功插入!")
else:
print("[爬取版面]版面 " + catalogue_url + " 已存在!")
print(f"========finsh catalogue {index+1}" + "/" + "10========")
return True
else:
raise Exception(f"Failed to fetch page {page}. Status code: {response.status_code}")
# 解析文章列表里的文章
def parse_cards_list(self, url, catalogue_id, cardupdatetime, cardtitle):
card_response = requests.get(url, headers=self.headers)
soup = BeautifulSoup(card_response.text, 'html.parser')
# 对应的版面id
card_id = catalogue_id
# 文章标题
card_title = cardtitle
# 文章更新时间
updateTime = cardupdatetime
# 操作时间
date = datetime.now()
# 文章作者
author = soup.find('article', 'article span-md-2').find('p', 'author').find('span', property='name').get_text()
# 原始htmldom结构
html_dom = soup.find('article', 'article span-md-2')
html_cut1 = html_dom.find_all('div', 'meta-share-group')[0].find('div', 'social-share')
html_cut2 = html_dom.find_all('div', 'meta-share-group')[1]
html_cut3 = html_dom.find('div', 'section-profile profile-1')
# 移除元素
if html_cut1:
html_cut1.extract()
if html_cut2:
html_cut2.extract()
if html_cut3:
html_cut3.extract()
html_content = html_dom
# 增加保留html样式的源文本
origin_html = html_dom.prettify() # String
# 转义网页中的图片标签
str_html = self.transcoding_tags(origin_html)
# 再包装成
temp_soup = BeautifulSoup(str_html, 'html.parser')
# 反转译文件中的插图
str_html = self.translate_tags(temp_soup.text)
# 绑定更新内容
content = self.clean_content(str_html)
# 下载图片
imgs = []
img_array = soup.find('div', 'article-content entry-content').find_all('img')
if len(img_array) is not None:
for item in img_array:
img_url = self.root_url + item.get('src')
imgs.append(img_url)
if len(imgs) != 0:
# 下载图片
illustrations = self.download_images(imgs, card_id)
# 连接 MongoDB 数据库服务器
client = MongoClient('mongodb://localhost:27017/')
# 创建或选择数据库
db = client['nd-news']
# 创建或选择集合
cards_collection = db['cards']
# 插入示例数据到 cards 集合
card_data = {
'id': card_id,
'catalogueId': catalogue_id,
'type': 'nd-news',
'date': date,
'title': card_title,
'author': author,
'updatetime': updateTime,
'url': url,
'html_content': str(html_content),
'content': content,
'illustrations': illustrations,
}
# 在插入前检查是否存在相同id的文档
existing_document = cards_collection.find_one({'id': card_id})
# 如果不存在相同id的文档,则插入新文档
if existing_document is None:
cards_collection.insert_one(card_data)
print("[爬取文章]文章 " + url + " 已成功插入!")
else:
print("[爬取文章]文章 " + url + " 已存在!")
# 下载图片
def download_images(self, img_urls, card_id):
result = re.search(r'[^/]+$', card_id)
last_word = result.group(0)
# 根据card_id创建一个新的子目录
images_dir = os.path.join(self.img_output_dir, str(last_word))
if not os.path.exists(images_dir):
os.makedirs(images_dir)
downloaded_images = []
for index, img_url in enumerate(img_urls):
try:
response = requests.get(img_url, stream=True, headers=self.headers)
if response.status_code == 200:
# 从URL中提取图片文件名
img_name_with_extension = img_url.split('/')[-1]
pattern = r'^[^?]*'
match = re.search(pattern, img_name_with_extension)
img_name = match.group(0)
# 保存图片
with open(os.path.join(images_dir, img_name), 'wb') as f:
f.write(response.content)
downloaded_images.append([img_url, os.path.join(images_dir, img_name)])
print(f'[爬取文章图片]文章id为{card_id}的图片已保存到本地')
except requests.exceptions.RequestException as e:
print(f'请求图片时发生错误:{e}')
except Exception as e:
print(f'保存图片时发生错误:{e}')
return downloaded_images
# 如果文件夹存在则跳过
else:
print(f'[爬取文章图片]文章id为{card_id}的图片文件夹已经存在')
return []
# 工具 转义标签
def transcoding_tags(self, htmlstr):
re_img = re.compile(r'\s*<(img.*?)>\s*', re.M)
s = re_img.sub(r'\n @@##\1##@@ \n', htmlstr) # IMG 转义
return s
# 工具 转义标签
def translate_tags(self, htmlstr):
re_img = re.compile(r'@@##(img.*?)##@@', re.M)
s = re_img.sub(r'<\1>', htmlstr) # IMG 转义
return s
# 清洗文章
def clean_content(self, content):
if content is not None:
content = re.sub(r'\r', r'\n', content)
content = re.sub(r'\n{2,}', '', content)
content = re.sub(r' {6,}', '', content)
content = re.sub(r' {3,}\n', '', content)
content = re.sub(r'<img src="../../../image/zxbl.gif"/>', '', content)
content = content.replace(
'<img border="0" src="****处理标记:[Article]时, 字段 [SnapUrl] 在数据源中没有找到! ****"/> ', '')
content = content.replace(
''' <!--/enpcontent<INPUT type=checkbox value=0 name=titlecheckbox sourceid="<Source>SourcePh " style="display:none">''',
'') \
.replace(' <!--enpcontent', '').replace('<TABLE>', '')
content = content.replace('<P>', '').replace('<\P>', '').replace(' ', ' ')
return content
def run():
# 网站根路径
root_url = 'https://news.nd.edu/'
# 文章图片保存路径
output_dir = 'D://imgs//nd-news'
response = requests.get('https://news.nd.edu/news/archives/')
soup = BeautifulSoup(response.text, 'html.parser')
# 模块地址数组
model_urls = []
model_url_array = soup.find('ul', 'archives-by-year archives-list').find_all('li')
for item in model_url_array:
model_url = root_url + item.find('a').get('href')
model_urls.append(model_url)
for model_url in model_urls:
# 初始化类
scraper = MitnewsScraper(root_url, model_url, output_dir)
# 遍历版面
scraper.catalogue_all_pages()
if __name__ == "__main__":
run()
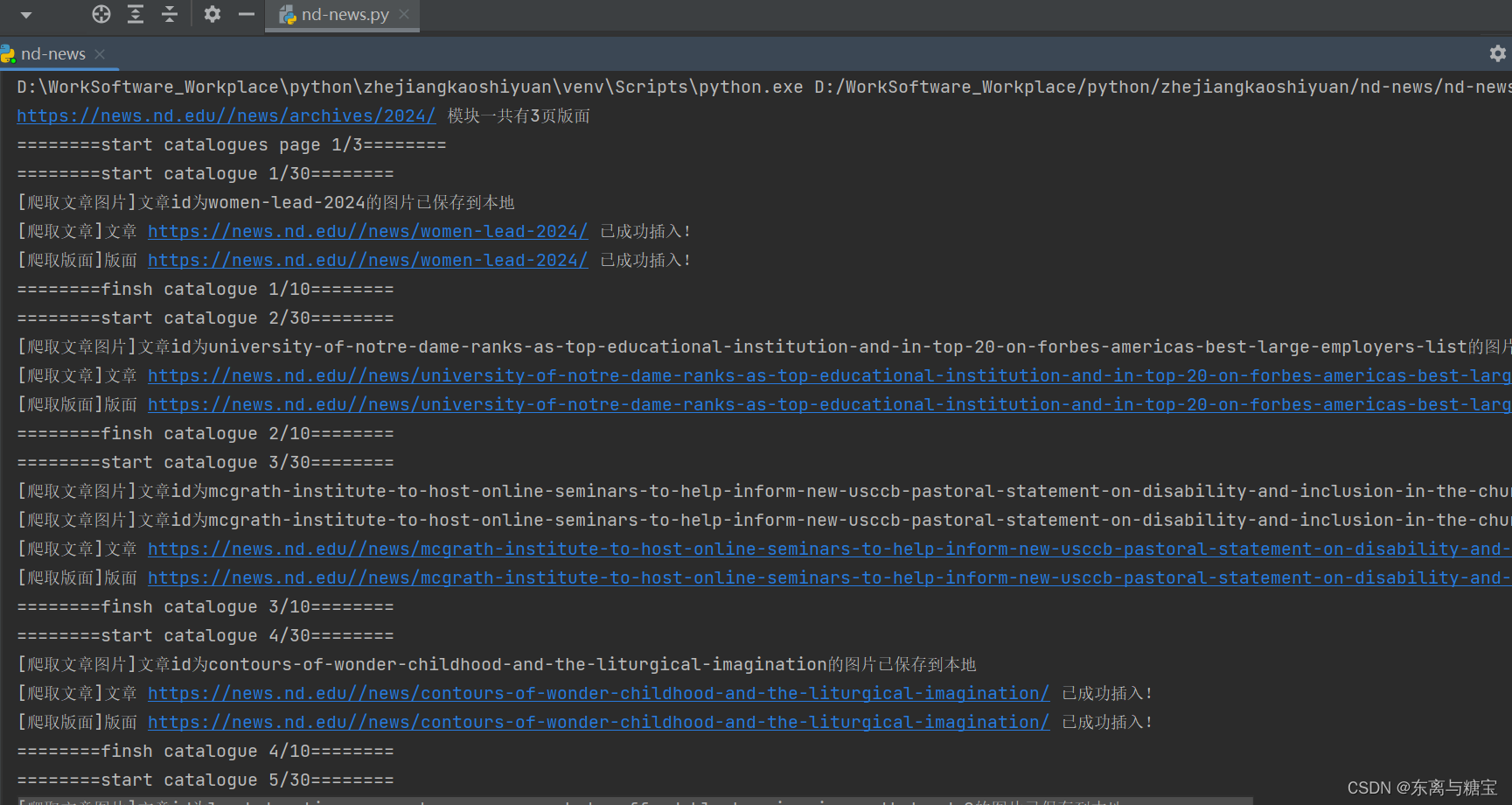
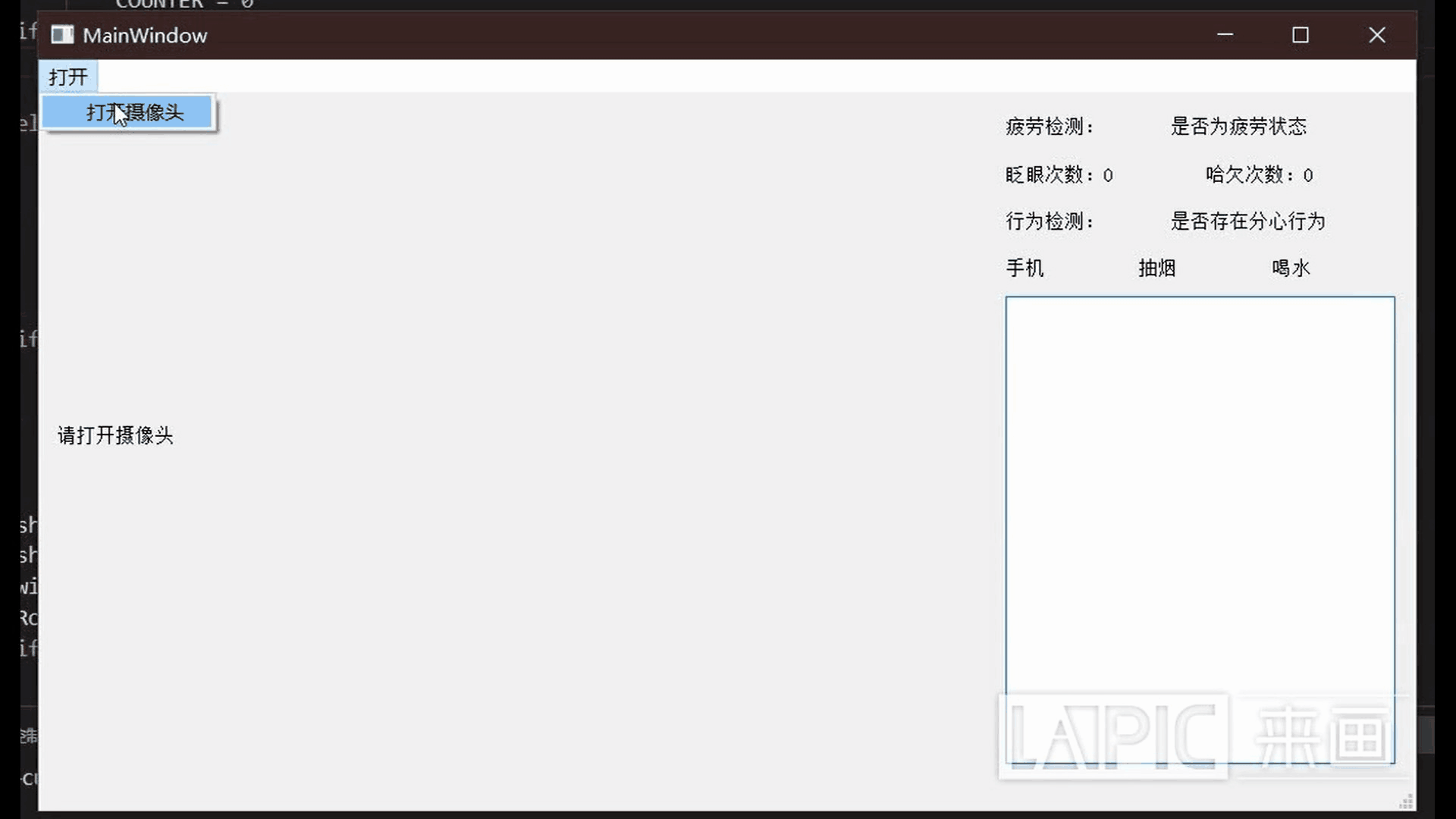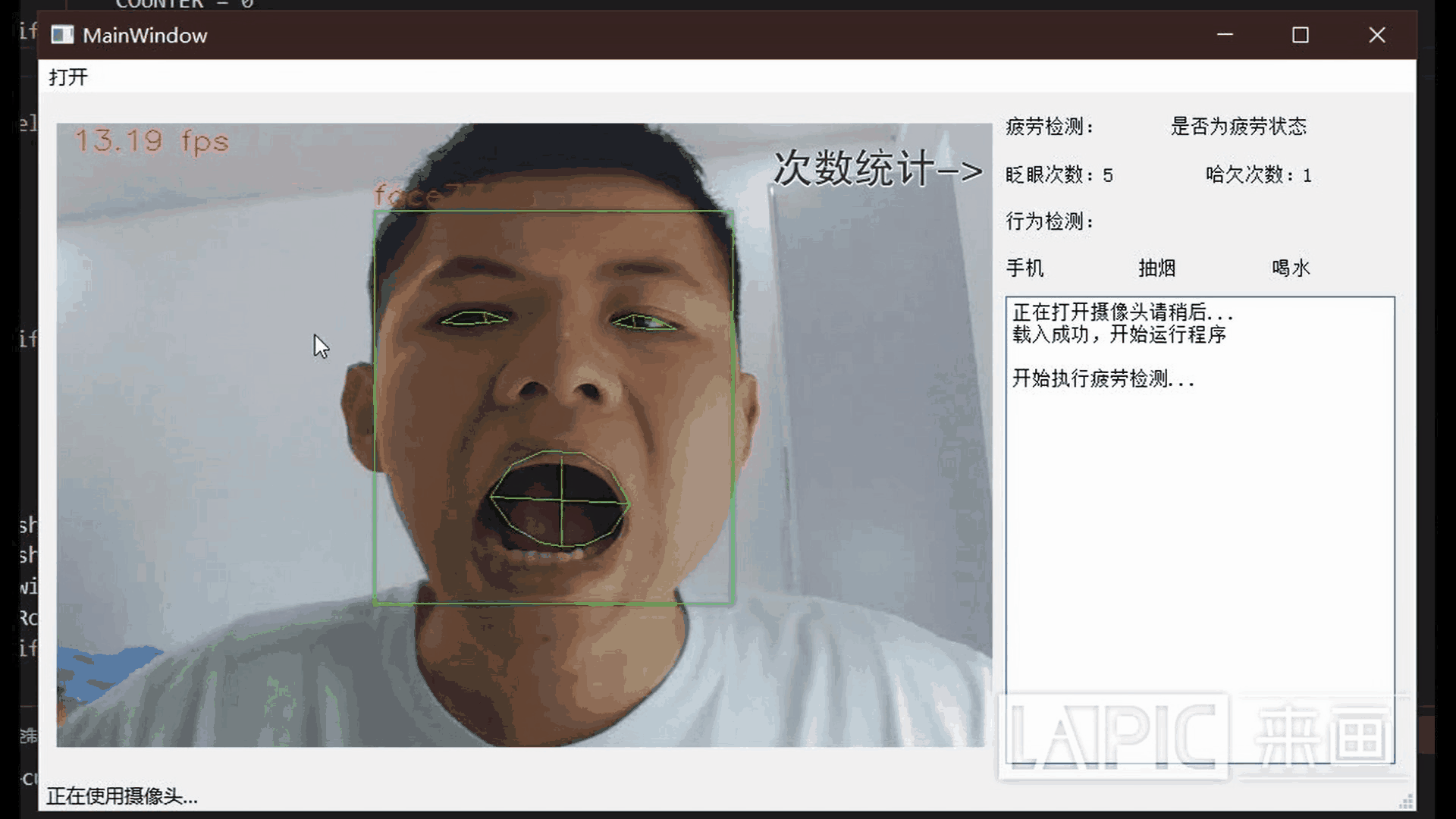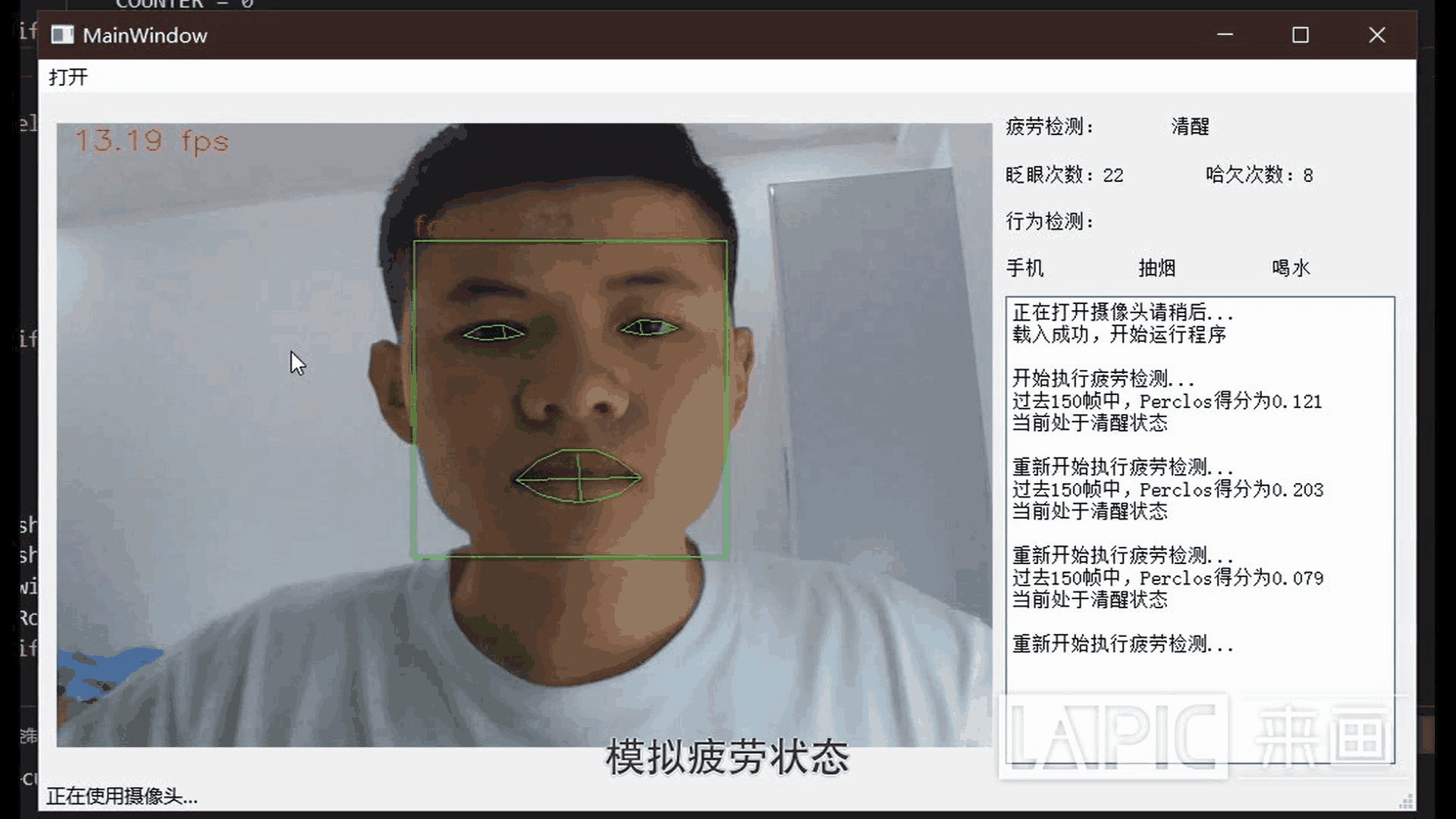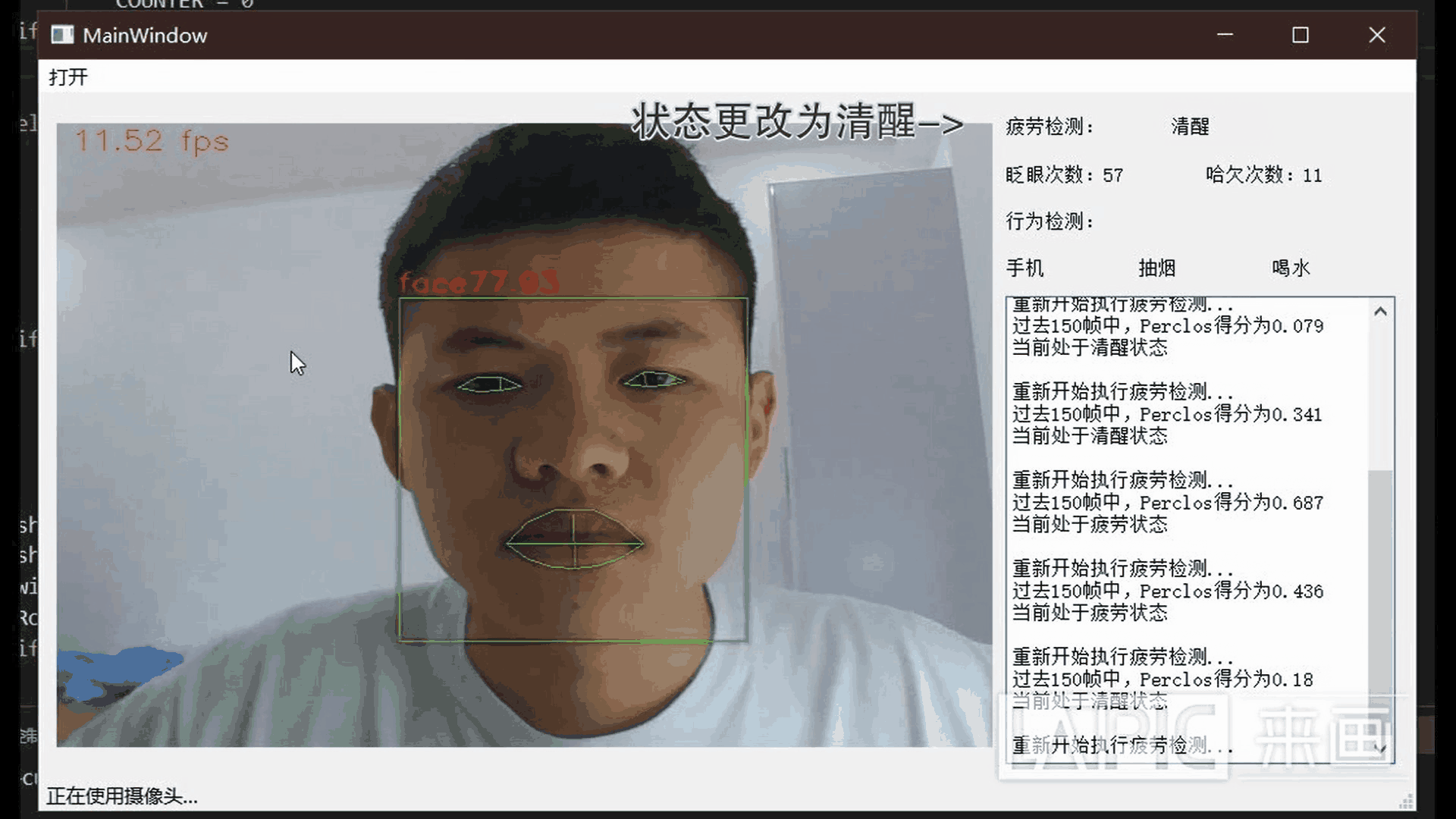
五、效果展示