按照阿光的项目做出了学习笔记,pytorch深度学习实战项目100例
基于LSTM实现春联上联对下联
基于LSTM(长短期记忆网络)实现春联上联对下联是一种有趣且具有挑战性的任务,它涉及到自然语言处理(NLP)中的序列到序列(seq2seq)模型。LSTM是处理序列数据的理想选择,因为它能够记住长期的依赖信息,这对于生成符合语境和文化习俗的春联下联至关重要。
数据
https://github.com/wb14123/couplet-dataset
感谢大佬的分享的对联数据集
对数据集的处理
def data_generator(data):
# 计算每个对联长度的权重
data_probability = [float(len(x)) for wordcount, [x, y] in data.items()] # [每个字数key对应对联list中上联数据的个数]
data_probability = np.array(data_probability) / sum(data_probability) # 标准化至[0,1],这是每个字数的权重
# 随机选择字数,然后随机选择字数对应的上联样本,生成batch
for idx in range(15):
# 随机选字数id,概率为上面计算的字数权重
idx = idx + 1
size = min(batch_size, len(data[idx][0])) # batch_size=64,len(data[idx][0])随机选择的字数key对应的上联个数
# 从上联列表下标list中随机选出大小为size的list
idxs = np.random.choice(len(data[idx][0]), size=size)
# 返回选出的上联X与下联y, 将原本1-d array维度扩展为(row,col,1)
yield data[idx][0][idxs], np.expand_dims(data[idx][1][idxs], axis=2)
# 加载文本数据
def load_data(input_path, output_path):
# 数据读取与切分
def read_data(file_path):
txt = codecs.open(file_path, encoding='utf-8').readlines()
txt = [line.strip().split(' ') for line in txt] # 每行按空格切分
txt = [line for line in txt if len(line) < 16] # 过滤掉字数超过maxlen的对联
return txt
# 产生数据字典
def generate_count_dict(result_dict, x, y):
for i, idx in enumerate(x):
j = len(idx)
if j not in result_dict:
result_dict[j] = [[], []] # [样本数据list,类别标记list]
result_dict[j][0].append(idx)
result_dict[j][1].append(y[i])
return result_dict
# 将字典数据转为numpy
def to_numpy_array(dict):
for count, [x, y] in dict.items():
dict[count][0] = np.array(x)
dict[count][1] = np.array(y)
return dict
x = read_data(input_path)
y = read_data(output_path)
# 获取词表
vocabulary = x + y
# 构造字符级别的特征
string = ''
for words in vocabulary:
for word in words:
string += word
# 所有的词汇表
vocabulary = set(string)
word2idx = {word: i for i, word in enumerate(vocabulary)}
idx2word = {i: word for i, word in enumerate(vocabulary)}
# 训练数据中所有词的个数
vocab_size = len(word2idx.keys()) # 词汇表大小
# 将x和y转为数值
x = [[word2idx[word] for word in sent] for sent in x]
y = [[word2idx[word] for word in sent] for sent in y]
train_dict = {}
train_dict = generate_count_dict(train_dict, x, y)
train_dict = to_numpy_array(train_dict)
return train_dict, vocab_size, idx2word, word2idx
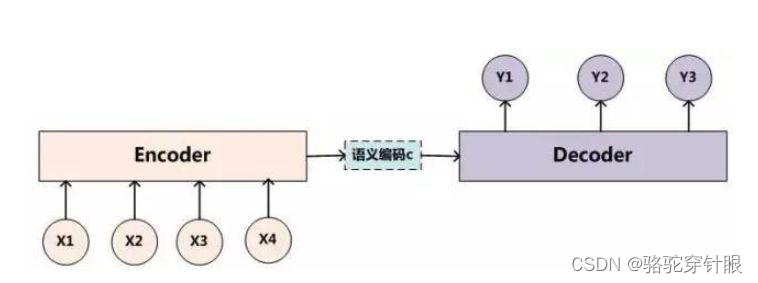
基本想法:
这种场景是典型的 Encoder-Decoder 框架应用问题。
在这个框架中:
- Encoder 负责读取输入序列(上联)并将其转换成一个固定长度的内部表示形式,通常是最后一个时间步的隐藏状态。这个内部表示被视为输入序列的“上下文”或“意义”,包含了生成输出序列所需的所有信息。
- Decoder 接收这个内部表示并开始生成输出序列(下联),一步一步地生成,直到产生序列结束标记或达到特定长度。
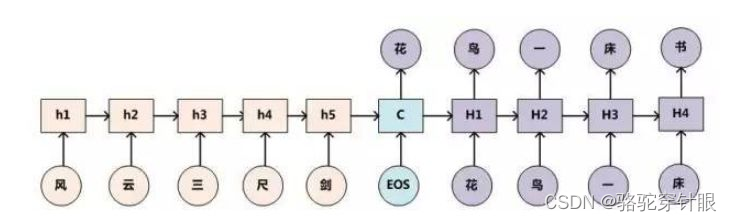
构建模型
模型架构:使用seq2seq模型,该模型一般包括一个编码器(encoder)和一个解码器(decoder),两者都可以是LSTM网络。编码器负责处理上联,而解码器则生成下联。
嵌入层:通常在模型的第一层使用嵌入层,将每个字符或词转换为固定大小的向量,这有助于模型更好地理解语言中的语义信息。
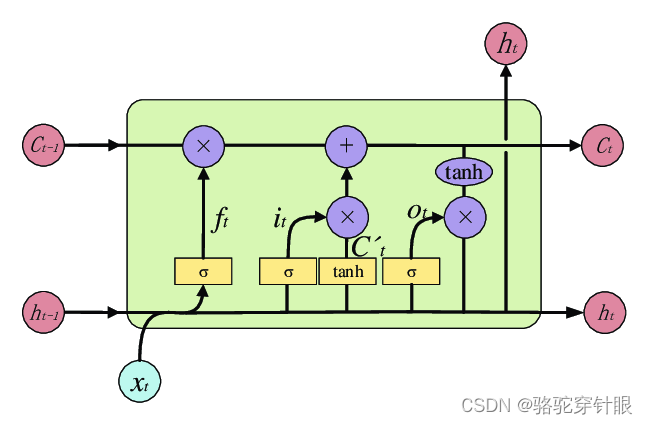
# 定义网络结构
class LSTM(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_dim, num_layers):
super(LSTM, self).__init__()
self.hidden_dim = hidden_dim
self.embeddings = nn.Embedding(vocab_size + 1, embedding_dim)
self.lstm = nn.LSTM(embedding_dim, hidden_dim, num_layers)
self.linear = nn.Linear(hidden_dim, vocab_size)
def forward(self, x):
time_step, batch_size = x.size() # 124, 16
embeds = self.embeddings(x)
output, (h_n, c_n) = self.lstm(embeds)
output = self.linear(output.reshape(time_step * batch_size, -1))
# 要返回所有时间点的数据,每个时间点对应一个字,也就是vocab_size维度的向量
return output
训练模型
# 加载数据
train_dict, vocab_size, idx2word, word2idx = load_data(input_path, output_path)
# 模型训练
model = LSTM(vocab_size=vocab_size, hidden_dim=hidden_dim,
embedding_dim=embedding_dim, num_layers=num_layers)
Configimizer = optim.Adam(model.parameters(), lr=lr) # 优化器
criterion = nn.CrossEntropyLoss() # 多分类损失函数
model.to(device)
loss_meter = meter.AverageValueMeter()
best_loss = 999 # 保存loss
best_model = None # 保存对应最好准确率的模型参数
for epoch in range(epochs):
model.train() # 开启训练模式
loss_meter.reset()
for x, y in data_generator(train_dict):
x = torch.from_numpy(x).long().transpose(1, 0).contiguous()
x = x.to(device)
y = torch.from_numpy(y).long().transpose(1, 0).contiguous()
y = y.to(device)
Configimizer.zero_grad()
# 形成预测结果
output_ = model(x)
# 计算损失
loss = criterion(output_, y.long().view(-1))
loss.backward()
Configimizer.step()
loss_meter.add(loss.item())
# 打印信息
print("【EPOCH: 】%s" % str(epoch + 1))
print("训练损失为%s" % (str(loss_meter.mean)))
# 保存模型及相关信息
if loss_meter.mean < best_loss:
best_loss = loss_meter.mean
best_model = model.state_dict()
# 在训练结束保存最优的模型参数
if epoch == epochs - 1:
# 保存模型
torch.save(best_model, './best_model.pkl')
测试
import codecs
import numpy as np
import torch
from torch import nn
from torch import optim
from torchnet import meter
# 模型输入参数,需要自己根据需要调整
input_path = 'C:\\Users\\kaai\\AppData\\Local\\Temp\\BNZ.65e95f542f0fca6f\\train\\in.txt'
output_path = 'C:\\Users\\kaai\\AppData\\Local\\Temp\\BNZ.65e95f542f0fca6f\\train\\out.txt'
num_layers = 1 # LSTM层数
hidden_dim = 100 # LSTM中的隐层大小
epochs = 50 # 迭代次数
batch_size = 128 # 每个批次样本大小
embedding_dim = 15 # 每个字形成的嵌入向量大小
lr = 0.01 # 学习率
device = 'cpu' # 设备
# 用于生成训练数据
def data_generator(data):
# 计算每个对联长度的权重
data_probability = [float(len(x)) for wordcount, [x, y] in data.items()] # [每个字数key对应对联list中上联数据的个数]
data_probability = np.array(data_probability) / sum(data_probability) # 标准化至[0,1],这是每个字数的权重
# 随机选择字数,然后随机选择字数对应的上联样本,生成batch
for idx in range(15):
# 随机选字数id,概率为上面计算的字数权重
idx = idx + 1
size = min(batch_size, len(data[idx][0])) # batch_size=64,len(data[idx][0])随机选择的字数key对应的上联个数
# 从上联列表下标list中随机选出大小为size的list
idxs = np.random.choice(len(data[idx][0]), size=size)
# 返回选出的上联X与下联y, 将原本1-d array维度扩展为(row,col,1)
yield data[idx][0][idxs], np.expand_dims(data[idx][1][idxs], axis=2)
# 加载文本数据
def load_data(input_path, output_path):
# 数据读取与切分
def read_data(file_path):
txt = codecs.open(file_path, encoding='utf-8').readlines()
txt = [line.strip().split(' ') for line in txt] # 每行按空格切分
txt = [line for line in txt if len(line) < 16] # 过滤掉字数超过maxlen的对联
return txt
# 产生数据字典
def generate_count_dict(result_dict, x, y):
for i, idx in enumerate(x):
j = len(idx)
if j not in result_dict:
result_dict[j] = [[], []] # [样本数据list,类别标记list]
result_dict[j][0].append(idx)
result_dict[j][1].append(y[i])
return result_dict
# 将字典数据转为numpy
def to_numpy_array(dict):
for count, [x, y] in dict.items():
dict[count][0] = np.array(x)
dict[count][1] = np.array(y)
return dict
x = read_data(input_path)
y = read_data(output_path)
# 获取词表
vocabulary = x + y
# 构造字符级别的特征
string = ''
for words in vocabulary:
for word in words:
string += word
# 所有的词汇表
vocabulary = set(string)
word2idx = {word: i for i, word in enumerate(vocabulary)}
idx2word = {i: word for i, word in enumerate(vocabulary)}
# 训练数据中所有词的个数
vocab_size = len(word2idx.keys()) # 词汇表大小
# 将x和y转为数值
x = [[word2idx[word] for word in sent] for sent in x]
y = [[word2idx[word] for word in sent] for sent in y]
train_dict = {}
train_dict = generate_count_dict(train_dict, x, y)
train_dict = to_numpy_array(train_dict)
return train_dict, vocab_size, idx2word, word2idx
# 定义网络结构
class LSTM(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_dim, num_layers):
super(LSTM, self).__init__()
self.hidden_dim = hidden_dim
self.embeddings = nn.Embedding(vocab_size + 1, embedding_dim)
self.lstm = nn.LSTM(embedding_dim, hidden_dim, num_layers)
self.linear = nn.Linear(hidden_dim, vocab_size)
def forward(self, x):
time_step, batch_size = x.size() # 124, 16
embeds = self.embeddings(x)
output, (h_n, c_n) = self.lstm(embeds)
output = self.linear(output.reshape(time_step * batch_size, -1))
# 要返回所有时间点的数据,每个时间点对应一个字,也就是vocab_size维度的向量
return output
def couplet_match(s):
# 将字符串转为数值
x = [word2idx[word] for word in s]
# 将数值向量转为tensor
x = torch.from_numpy(np.array(x).reshape(-1, 1))
# 加载模型
model_path = './best_model.pkl'
model = LSTM(vocab_size=vocab_size, hidden_dim=hidden_dim,
embedding_dim=embedding_dim, num_layers=num_layers)
model.load_state_dict(torch.load(model_path, 'cpu'))
y = model(x)
y = y.argmax(axis=1)
r = ''.join([idx2word[idx.item()] for idx in y])
print('上联:%s,下联:%s' % (s, r))
# 加载数据
train_dict, vocab_size, idx2word, word2idx = load_data(input_path, output_path)
# 测试
sentence = '恭喜发财'
couplet_match(sentence)