最大汇聚运算(Max Pooling Operation)是深度学习领域卷积神经网络常用的一种汇聚运算方式。在卷积神经网络中,经过一系列卷积层和激活函数层后,数据在空间尺寸上逐渐减小,特征图的深度也逐渐增加。为了降低数据尺寸并提取最重要的特征,我们需要对特征图进行汇聚运算。
最大汇聚运算的原理是在一个固定大小的滑动窗口内找到最大的数值作为输出。具体操作步骤如下:
- 将特征图划分成不重叠的区域,这些区域称为汇聚窗口(pooling window)。
- 在每个汇聚窗口内,找到最大的数值作为该窗口的输出。
- 将所有汇聚窗口的输出组成汇聚特征图(pooled feature map)。
最大汇聚运算具有以下特点:
- 参数少:最大汇聚运算没有需要学习的参数,因此可以有效地减少模型的参数量。
- 位置不变性:最大汇聚运算不考虑特征在特征图上的位置,因此对输入的小变化具有一定的鲁棒性,使得模型对平移、旋转等变换具有一定的不变性。
- 特征不变性:最大汇聚运算只保留最重要的特征,对于噪音、冗余的特征具有一定的抑制作用,提取出更加鲁棒的特征。
最大汇聚运算在深度学习领域卷积神经网络中广泛应用,能够有效地降低特征图的尺寸并提取重要的特征,从而在模型训练和特征提取中发挥关键作用。
政安晨的个人主页:政安晨
欢迎 👍点赞✍评论⭐收藏
收录专栏: 政安晨的机器学习笔记
希望政安晨的博客能够对您有所裨益,如有不足之处,欢迎在评论区提出指正!

开始
在咱们上一篇的文章中:
政安晨:【深度学习处理实践】(一)—— 卷积神经网络入门![]() https://blog.csdn.net/snowdenkeke/article/details/136495239你可能已经注意到,在卷积神经网络示例的每个MaxPooling2D层之后,特征图的尺寸都会减半。例如,在第一个MaxPooling2D层之前,特征图的尺寸是26×26,最大汇聚运算将其减半为13×13。这就是最大汇聚的作用:主动对特征图进行下采样,与步进卷积类似。
https://blog.csdn.net/snowdenkeke/article/details/136495239你可能已经注意到,在卷积神经网络示例的每个MaxPooling2D层之后,特征图的尺寸都会减半。例如,在第一个MaxPooling2D层之前,特征图的尺寸是26×26,最大汇聚运算将其减半为13×13。这就是最大汇聚的作用:主动对特征图进行下采样,与步进卷积类似。
最大汇聚是指从输入特征图中提取窗口,并输出每个通道的最大值。
它的概念与卷积类似,但是最大汇聚使用硬编码的max张量运算对局部图块进行变换,而不是使用学到的线性变换(卷积核)来进行变换。
最大汇聚与卷积的一大区别在于,最大汇聚通常使用2×2的窗口和步幅2,其目的是对特征图进行2倍下采样;与此相对,卷积通常使用3×3的窗口和步幅1。
为什么要用这种方法对特征图进行下采样?为什么不删除最大汇聚层,一直保留较大的特征图呢?我们来这样试一下,模型代码如下所示:
(一个没有最大汇聚层、结构错误的卷积神经网络)
from tensorflow import keras
from tensorflow.keras import layers
inputs = keras.Input(shape=(28, 28, 1))
x = layers.Conv2D(filters=32, kernel_size=3, activation="relu")(inputs)
x = layers.Conv2D(filters=64, kernel_size=3, activation="relu")(x)
x = layers.Conv2D(filters=128, kernel_size=3, activation="relu")(x)
x = layers.Flatten()(x)
outputs = layers.Dense(10, activation="softmax")(x)
model_no_max_pool = keras.Model(inputs=inputs, outputs=outputs)该模型的概述信息如下:
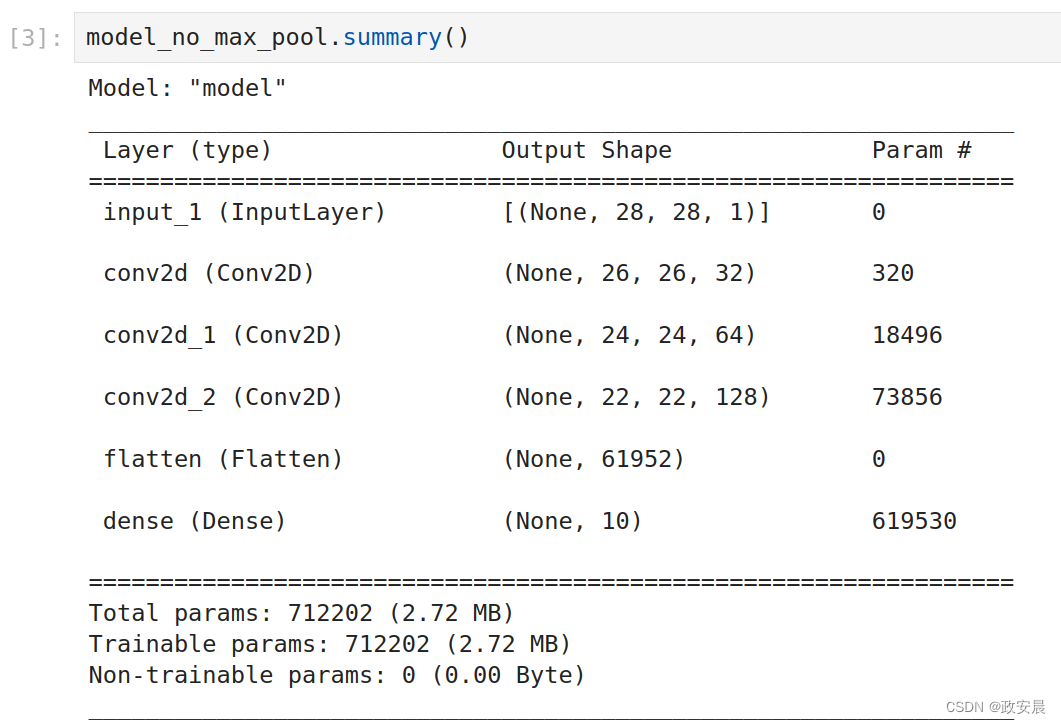
这种架构有以下两个问题:
这种架构不利于学习特征的空间层级结构。
第三层的3×3窗口只包含初始输入中7×7窗口所包含的信息。卷积神经网络学到的高级模式相对于初始输入来说仍然很小,这可能不足以学会对数字进行分类(你可以试试仅通过7像素×7像素的窗口来观察图像并识别其中的数字)。我们需要让最后一个卷积层的特征包含输入的全部信息。
最后一个特征图对每个样本都有61 952个元素(22×22×128=61 952)。
这太多了!如果你将特征图展平并在后面添加一个大小为10的Dense层,那么该层将有超过50万个参数。对于这样的小模型来说,这实在是太多了,会导致严重的过拟合。简而言之,使用下采样的原因,一是减少需要处理的特征图的元素个数,二是通过让连续卷积层的观察窗口越来越大(窗口覆盖原始输入的比例越来越大),从而引入空间滤波器的层级结构。
请注意,最大汇聚不是实现这种下采样的唯一方法。
你已经知道,还可以在前一个卷积层中使用步幅来实现。
此外,你还可以使用平均汇聚来代替最大汇聚,方法是对每个局部输入图块取各通道的均值,而不是最大值。
但最大汇聚的效果往往比这些替代方法更好,原因在于:特征中往往编码了某种模式或概念在特征图的不同位置是否存在(因此得名特征图),观察不同特征的最大值而不是均值能够给出更多的信息。最合理的子采样策略是,首先生成密集的特征图(利用无步进卷积),然后观察特征在每个小图块上的最大激活值,而不是通过稀疏的窗口观察输入(利用步进卷积)或对输入图块取均值,因为后两种方法可能导致错过或淡化特征是否存在的信息。
现在你应该已经理解了卷积神经网络的基本概念:特征图、卷积和最大汇聚,并且也知道如何构建一个小型卷积神经网络来解决MNIST数字分类等简单问题。
下面我们将介绍更有用的实际应用:
在小型数据集上从头开始训练一个卷积神经网络
利用少量数据来训练图像分类模型,这是一种很常见的情况。
如果你从事与计算机视觉相关的职业,那么很可能会在实践中遇到这种情况。“少量”样本既可能是几百张图片,也可能是上万张图片。我们来看一个实例——猫狗图片分类,数据集包含5000张猫和狗的图片(2500张猫的图片,2500张狗的图片)。我们将2000张图片用于训练,1000张用于验证,2000张用于测试。
咱们这篇文章,将介绍解决这个问题的基本方法:使用已有的少量数据从头开始训练一个新模型。首先,我们在2000个训练样本上训练一个简单的小型卷积神经网络,不做任何正则化,为模型改进设定一个基准。我们得到的分类精度约为70%。这时的主要问题是过拟合。
然后,我们会使用数据增强(data augmentation),它是计算机视觉领域中非常强大的降低过拟合的方法。使用数据增强之后,模型的分类精度将提高到80%~85%。
咱们今后会介绍将深度学习应用于小型数据集的另外两个重要方法:使用预训练模型做特征提取(得到的精度为97.5%)、微调预训练模型(最终精度为98.5%)。
总而言之,这三种方法——从头开始训练一个小模型、使用预训练模型做特征提取、微调预训练模型——构成了你的工具箱,可用于解决小型数据集的图像分类问题。
深度学习对数据量很小的问题的适用性
要训练模型,“样本足够”是相对的,也就是说,“样本足够”是相对于待训练模型的大小和深度而言的。
只用几十个样本训练卷积神经网络来解决复杂问题是不可能的,但如果模型很小,并且做了很好的正则化,同时任务非常简单,那么几百个样本可能就足够了。由于卷积神经网络学到的是局部、平移不变的特征,因此它在感知问题上可以高效地利用数据。虽然数据量相对较少,但在非常小的图像数据集上从头开始训练一个卷积神经网络,仍然可以得到不错的结果,而且无须任何自定义的特征工程。咱们这篇文章中您能看到这种方法的效果。
此外,深度学习模型本质上具有很强的可复用性。
比如,已有一个在大规模数据集上训练好的图像分类模型或语音转文本模型,只需稍作修改就能将其复用于完全不同的问题。特别是在计算机视觉领域,许多预训练模型(通常都是在ImageNet数据集上训练得到的)现在都可以公开下载,并可用于在数据量很少的情况下构建强大的视觉模型。特征复用是深度学习的一大优势,咱们以后将介绍这一点。
下载数据
咱们这篇文章中用到的猫狗分类数据集不包含在Keras中。它由Kaggle提供,在2013年底作为一项计算机视觉竞赛的一部分,当时卷积神经网络还不是主流算法。你可以从Kaggle网站下载原始数据集Dogs vs. Cats(如果没有Kaggle账户,你需要注册一个。别担心,注册过程很简单)。此外,你也可以在Colab中使用Kaggle API来下载数据集(详见下方文本框“在Google Colaboratory中下载Kaggle数据集”)。
在Google Colaboratory中下载Kaggle数据集
Kaggle提供了一个易于使用的API,可以编写代码下载Kaggle托管的数据集。你可以用它将猫狗数据集下载到Colab笔记本中。这个API包含在kaggle包中,kaggle包已经预先安装在Colab上。下载这个数据集非常简单,只需在Colab单元格中运行下面这条命令。
!kaggle competitions download -c dogs-vs-cats为了顺利进行演绎,咱们现在转移到Colab上继续执行:
(这个API的访问仅限于Kaggle用户,所以要想运行上述命令,首先需要进行身份验证。kaggle包会在一个JSON文件(位于~/.kaggle/kaggle.json)中查找你的登录凭证。我们来创建这个文件。)
首先,你需要创建一个Kaggle API密钥,并将其下载到本地计算机。只需在浏览器中访问Kaggle网站,登录,然后进入My Account页面。在账户设置中,找到API,单击Create New API Token按钮将生成一个kaggle.json密钥文件,然后将其下载到计算机中。
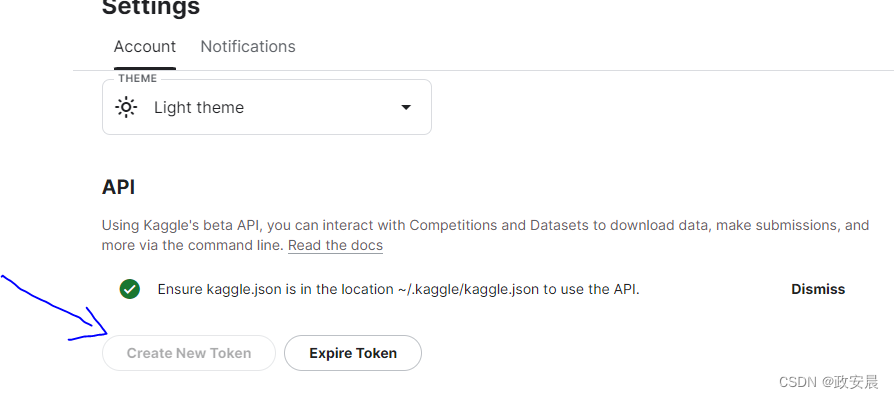
然后,打开Colab笔记本,在笔记本单元格中运行下列代码,将API密钥的JSON文件上传到Colab会话中。
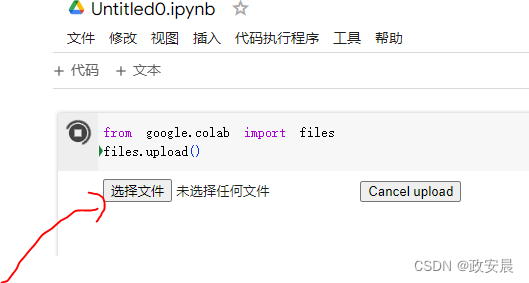
运行这个单元格时,会出现Choose Files按钮。单击按钮并选择刚刚下载的kaggle.json文件。这样就把文件上传到Colab本地运行时。
上传好文件后:
创建~/.kaggle文件夹(mkdir ~/.kaggle),并将密钥文件复制过去(cp kaggle.json ~/.kaggle/)。作为最佳安全实践,你还应该确保该文件只能由当前用户(也就是你自己)读取(chmod 600)
!mkdir ~/.kaggle
!cp kaggle.json ~/.kaggle/
!chmod 600 ~/.kaggle/kaggle.json现在再执行上面的指令下载数据:
!kaggle competitions download -c dogs-vs-cats第一次尝试下载数据时,你可能会遇到403 Forbidden错误。这是因为在下载数据集之前,你需要接受与数据集相关的条款。你需要登录Kaggle账户并访问该数据集对应的Rules页面,然后单击I Understand and Accept按钮。该操作只需完成一次即可。

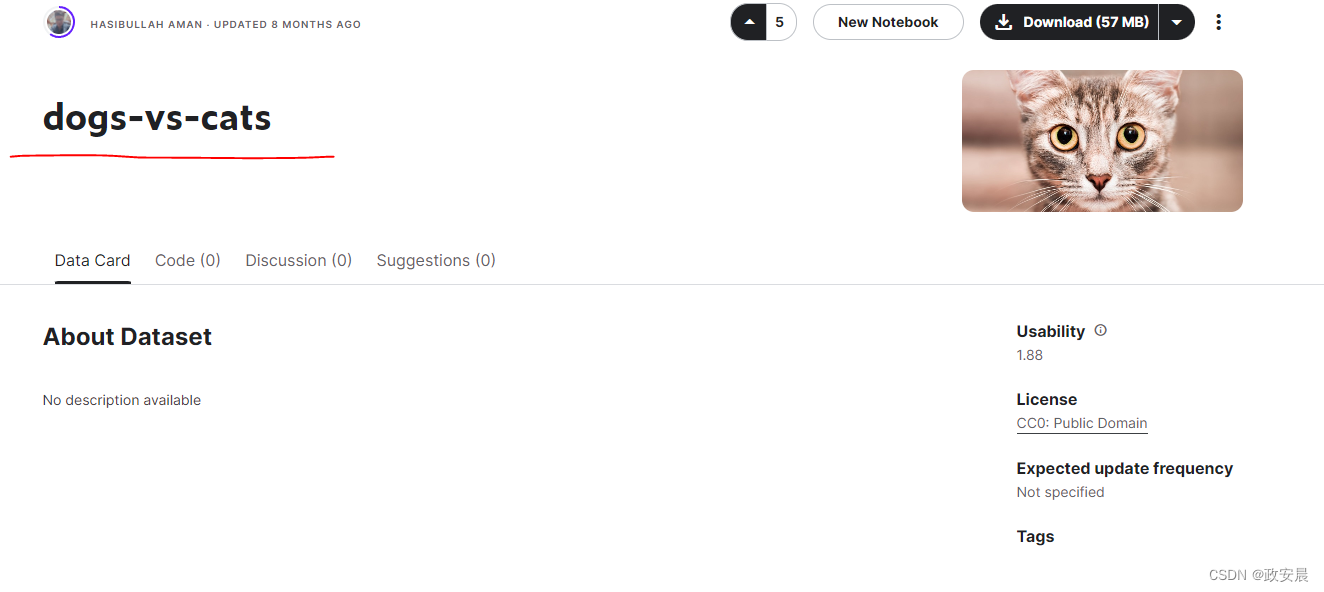
上面那个错误在这个地址接受:
Dogs vs. Cats | KaggleCreate an algorithm to distinguish dogs from cats![]() https://www.kaggle.com/c/dogs-vs-cats/rules现在可以下载数据了。
https://www.kaggle.com/c/dogs-vs-cats/rules现在可以下载数据了。
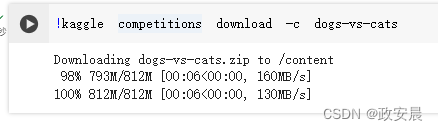
最后,训练数据是一个名为dogs-vs-cats.zip的压缩文件。请使用静默方式(-qq)解压缩(unzip)。
!unzip -qq dogs-vs-cats.zip这个数据集中的图片都是中等分辨率的彩色JPEG图片。下图给出了一些样本示例。

不出所料,2013年猫狗分类Kaggle竞赛的优胜者使用的就是卷积神经网络。最佳结果达到了95%的精度。
本例中,虽然训练模型的数据量不到参赛选手所用数据量的10%,但结果与这个精度相当接近。
这个数据集包含25 000张猫和狗的图像(每个类别各有12 500张),压缩后的大小为543 MB。
下载数据并解压后,我们将创建一个新数据集,其中包含3个子集:
训练集,每个类别各1000个样本;
验证集,每个类别各500个样本;
测试集,每个类别各1000个样本。
之所以要这样做,是因为在你的职业生涯中,你遇到的许多图像数据集只包含几千个样本,而不是几万个。拥有更多的数据,可以让问题更容易解决,所以使用小型数据集进行学习是很好的做法。
我们要使用的子数据集的目录结构如下所示:
cats_vs_dogs_small/
...train/
......cat/ ←----包含1000张猫的图像
......dog/ ←----包含1000张狗的图像
...validation/
......cat/ ←----包含500张猫的图像
......dog/ ←----包含500张狗的图像
...test/
......cat/ ←----包含1000张猫的图像
......dog/ ←----包含1000张狗的图像我们通过调用几次shutil来创建这个子数据集,如代码如下所示:
(将图像复制到训练目录、验证目录和测试目录)
import os, shutil, pathlib
# ←----原始数据集的解压目录
original_dir = pathlib.Path("train")
# ←----保存较小数据集的目录
new_base_dir = pathlib.Path("cats_vs_dogs_small")
# ←----一个实用函数,将索引从start_index到end_index的猫/狗图像复制到子目录new_base_dir/{subset_name}/cat(或/dog)下。subset_name可以是"train"、"validation"或"test"
def make_subset(subset_name, start_index, end_index):
for category in ("cat", "dog"):
dir = new_base_dir / subset_name / category
os.makedirs(dir)
fnames = [f"{category}.{i}.jpg"
for i in range(start_index, end_index)]
for fname in fnames:
shutil.copyfile(src=original_dir / fname,
dst=dir / fname)
# ←----用每个类别的前1000张图像创建训练子集
make_subset("train", start_index=0, end_index=1000)
# ←----用每个类别接下来的500张图像创建验证子集
make_subset("validation", start_index=1000, end_index=1500)
# ←----用每个类别接下来的1000张图像创建测试子集
make_subset("test", start_index=1500, end_index=2500)现在我们有2000张训练图像、1000张验证图像和2000张测试图像。在这3个集合中,两个类别的样本数相同,所以这是一个均衡的二分类问题,分类精度可作为衡量成功的指标。
构建模型
模型的大致结构与前面第一个示例相同,卷积神经网络由Conv2D层(使用relu激活函数)和MaxPooling2D层交替堆叠而成,如代码如下所示。
但因为这里要处理更大的图像和更复杂的问题,所以需要相应地增大模型,增加两个Conv2D+MaxPooling2D的组合。这样做既可以增大模型容量,又可以进一步缩小特征图尺寸,使其在进入Flatten层时尺寸不会太大。本例初始输入的尺寸为180像素×180像素(这是一个随意的选择),最后在Flatten层之前的特征图尺寸为7×7。
注意 在模型中,特征图的深度逐渐增大(从32增大到128),而特征图的尺寸则逐渐缩小(从180×180缩小到7×7)。几乎所有卷积神经网络都是这种模式。
因为这是一个二分类问题,所以模型的最后一层是使用sigmoid激活函数的单个单元(大小为1的Dense层)。这个单元表示的是模型认为样本属于某个类别的概率。
最后还有一个小区别:模型最开始是一个Rescaling层,它将图像输入(初始取值范围是[0, 255]区间)的取值范围缩放到[0, 1]区间。
为猫狗分类问题实例化一个小型卷积神经网络
from tensorflow import keras
from tensorflow.keras import layers
# ←----模型输入应该是尺寸为180×180的RGB图像
inputs = keras.Input(shape=(180, 180, 3))
# ←----将输入除以255,使其缩放至[0, 1]区间
x = layers.Rescaling(1./255)(inputs)
x = layers.Conv2D(filters=32, kernel_size=3, activation="relu")(x)
x = layers.MaxPooling2D(pool_size=2)(x)
x = layers.Conv2D(filters=64, kernel_size=3, activation="relu")(x)
x = layers.MaxPooling2D(pool_size=2)(x)
x = layers.Conv2D(filters=128, kernel_size=3, activation="relu")(x)
x = layers.MaxPooling2D(pool_size=2)(x)
x = layers.Conv2D(filters=256, kernel_size=3, activation="relu")(x)
x = layers.MaxPooling2D(pool_size=2)(x)
x = layers.Conv2D(filters=256, kernel_size=3, activation="relu")(x)
x = layers.Flatten()(x)
outputs = layers.Dense(1, activation="sigmoid")(x)
model = keras.Model(inputs=inputs, outputs=outputs)与前面一样,模型编译将使用rmsprop优化器。模型最后一层是单一的sigmoid单元,所以我们将使用二元交叉熵作为损失函数。
(配置模型,以进行训练)
model.compile(loss="binary_crossentropy",
optimizer="rmsprop",
metrics=["accuracy"])数据预处理
现在你已经知道,将数据输入模型之前,应该将数据格式化为经过预处理的浮点数张量。当前数据以JPEG文件的形式存储在硬盘上,所以数据预处理步骤大致如下:
(1)读取JPEG文件。
(2)将JPEG文件解码为RGB像素网格。
(3)将这些像素网格转换为浮点数张量。
(4)将这些张量调节为相同大小(本例为180×180)。
(5)将数据打包成批量(一个批量包含32张图像)。
这些步骤可能看起来有些复杂,但幸运的是,Keras拥有自动完成这些步骤的工具。具体地说,Keras包含实用函数image_dataset_from_directory(),它可以快速建立数据管道,自动将磁盘上的图像文件转换为预处理好的张量批量。下面我们将使用这个函数,代码如下所示。
from tensorflow.keras.utils import image_dataset_from_directory
train_dataset = image_dataset_from_directory(
new_base_dir / "train",
image_size=(180, 180),
batch_size=32)
validation_dataset = image_dataset_from_directory(
new_base_dir / "validation",
image_size=(180, 180),
batch_size=32)
test_dataset = image_dataset_from_directory(
new_base_dir / "test",
image_size=(180, 180),
batch_size=32)调用image_dataset_from_directory(directory),首先会列出directory的子目录,并假定每个子目录都包含某一个类别的图像。然后,它会为每个子目录下的图像文件建立索引。最后,它会创建并返回一个tf.data.Dataset对象,用于读取这些文件、打乱其顺序、将其调节为相同大小并打包成批量。
理解TensorFlow Dataset对象
TensorFlow提供了tf.data API,用于为机器学习模型创建高效的入管道,其中最重要的类是tf.data.Dataset。
Dataset对象是一个迭代器,你可以在for循环中使用它。它通常会返回由入数据和标签组成的批量。你可以将Dataset对象直接传入Keras模型的fit()方法中。
幸好Dataset类实现了许多重要功能,否则自己实现起来会很麻烦,特别是异步数据预取(在模型处理前一批数据时,预处理下一批数据,从而保持执行流畅而不中断)。
Dataset类还拥有一个用于修改数据集的函数式API。