目录
前言
一、文件上传
二、Cookies
三、会话维持
四、SSL证书验证
五、代理设置
六、超时设置
七、身份认证
八、Prepared Request
前言
上一节,我们认识了requests库的基本用法,像发起GET、POST请求,以及了解Response对象是什么。这一节,咱们接着讲讲requests库的一些高级用法,比如怎么上传文件,如何设置Cookies和代理 。
一、文件上传
用requests,不光能模拟提交普通数据,实现文件上传也不在话下,而且操作起来很容易。
示例代码如下:
import requests
files = {'file': open('favicon.ico', 'rb')}
r = requests.post("http://httpbin.org/post", files=files)
print(r.text)要是之前保存过favicon.ico文件,这段代码就能拿它模拟文件上传。其中 httpbin.org 是一个基于 Python 和 Flask 开发的 HTTP 请求与响应服务网站。得注意,favicon.ico得和运行的脚本放在同一个文件夹里。要是想用其他文件模拟,改改代码就行。
运行上述代码,得到类似如下结果:
{
"args": {},
"data": "",
"files": {
"file": "data:application/octet-stream;base64,AAABAAEAgIAAAAAAIAAoCAEA......
},
"form": {},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Content-Length": "67793",
"Content-Type": "multipart/form-data; boundary=80503f6283733c2f23804bb45111c889",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.31.0",
"X-Amzn-Trace-Id": "Root=1-67f481ae-65a8a7c32119664b07375e48"
},
"json": null,
"origin": "14.18.236.76",
"url": "http://httpbin.org/post"
}
上面展示的结果,省略了一些内容。网站给出的响应里有files字段,form字段却是空的。这就说明,在文件上传时,会通过专门的files字段来标记上传的文件。
二、Cookies
以前用urllib处理Cookies,代码写起来挺麻烦。但requests不一样,获取和设置Cookies简单多了,操作一步就能搞定。下面通过实例,看看怎么用requests获取Cookies:
import requests
r = requests.get("https://www.baidu.com")
print(r.cookies)
for key, value in r.cookies.items():
print(key + '=' + value)运行代码,结果如下:
<RequestsCookieJar[<Cookie BD0RZ=27315 for .baidu.com/>, <Cookie bsi=135335943568134141940014NN20303C0FNNNforw.baidu.com/>]>
BDORZ=27315
bsi=135335943568134141940014NN2030302FNNNO
先调用cookies属性,就能得到Cookies,它的数据类型是RequestCookieJar。然后用items()方法把它转成由元组组成的列表,一个个遍历输出每个Cookie的名称和值,这样就完成了Cookie的遍历解析。
用Cookie能维持登录状态。就拿知乎来说,登录知乎后,把Headers里的Cookie内容复制出来(也可以换成你自己的Cookie),设置到Headers里再发送请求,下面是示例代码:
cookie = "_zap=5852a467-84d5-48cd-b719-20cd08603c31; d_c0=a9CTVTvcRBqPTm6b5PunENpMjXLxX-7IGgk=|1744077733; captcha_session_v2=2|1:0|10:1744077734|18:captcha_session_v2|88:QkNNRGpaLzFMQ3NncGFVRXIxb1pSTXZlb3Axb3pCaGNibzlPRFI4cHhEUlpsU3ZyVUF5b0xGL2haSE1oS0xlZw==|d22291e8cfbad9e62e3ecf5b5879bd681e0dc56a87772f4b0a1bd674bfb6dc53; __snaker__id=1aUlWy7fvUjwSn3n; gdxidpyhxdE=%2BtQHnNHABo%2BnC7cQZNp5uprsnqVoGdyWn2QbuZGkZQ4K0Nio4pOnXNCRdPPZGh%2BOAJ8CYYhNxL%2B9bl%5CMngU%5Cb16zCg3nm9eIK%5C6dD0g%2BwE6q%2BUlwgi0dAj6TOMH5%2FqRH%5CYay%2BezxLU01dKTr4k9QPsXGtdRZ%2BkD6xU%5CxS6RKyHTSXxlh%3A1744078635509; q_c1=6573efe200e34e6e9cb0469042bfafde|1744077773000|1744077773000; z_c0=2|1:0|10:1744077775|4:z_c0|92:Mi4xUHZCWVJnQUFBQUJyMEpOVk85eEVHaGNBQUFCZ0FsVk56ZEhoYUFCU1V6WFFiOURmc3VsUnoyd0NtYUdYdTl6N1dB|29591bd5fc696067e49e9509e5fac6fd4663498734ece22be113ccb401123931; _xsrf=ee0ea1ed-31f9-45ab-a923-fc97da5d7663; Hm_lvt_98beee57fd2ef70ccdd5ca52b9740c49=1744077734,1744104477; HMACCOUNT=29A6B844A9199C82; SESSIONID=alwM2PqMj7oxC3sRO72GFRwFMAnqV5ntSfBTuVLEheH; JOID=UV0WC0NgDf9xcWbsRRC3LEFGsaVfB2eDPEgwmwMBPJYCMl6ZEX3sAB18ZuFOibPgrBwBunupBMfuYiuxq0TeVS8=; osd=UVoSBkxgCvt8fmbrQR24LEZCvKpfAGOOM0g3nw4OPJEGP1GZFnnhDx17YuxBibTkoRMBvX-kC8fpZia-q0PaWCA=; Hm_lpvt_98beee57fd2ef70ccdd5ca52b9740c49=1744104666; tst=v; BEC=8b4a1b0a664dd5d88434ef53342ae417; unlock_ticket=AOBXjeH6uhYXAAAAYAJVTeLz9Gd8qlW4_xKazEBGBzAktCSlnf9y0w=="
import requests
headers = {
'Cookie': cookie,
'Host': 'www.zhihu.com',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac 0sX10 11 4)AppleWebKit/537.36(KHTML, like Gecko)Chrome/53.0.2785.116 Safari/537.36'
}
r = requests.get('https://www.zhihu.com/zvideo', headers=headers)
print(r.text)
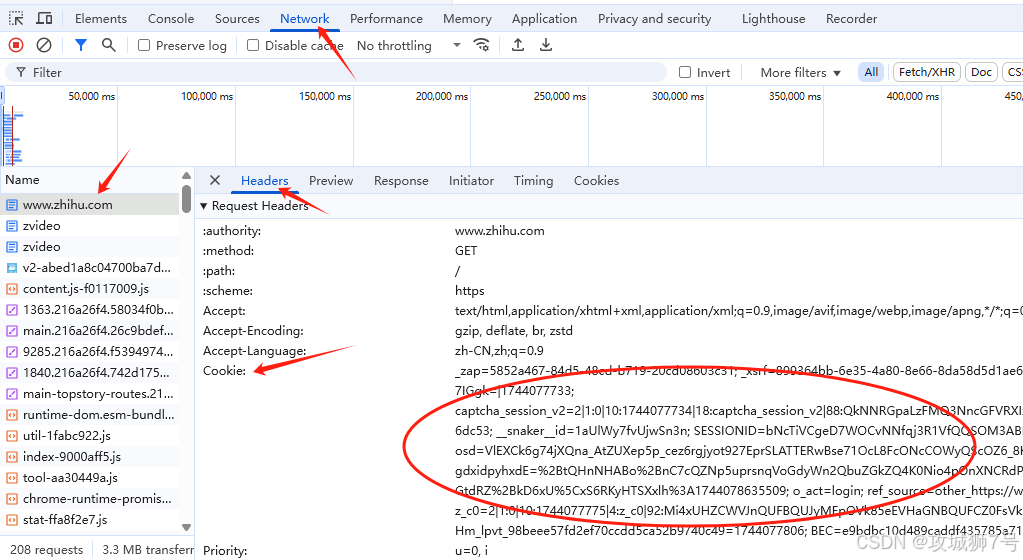
程序运行后,得到的结果里有登录后的页面内容,这就说明成功登录了。
除了前面的方法,我们还能通过cookies参数来设置Cookie。不过,这种方式得先构造RequestsCookieJar对象,还要对获取到的cookies进行分割,操作相对麻烦。下面来看示例:
import requests
cookie = "_zap=5852a467-84d5-48cd-b719-20cd08603c31; d_c0=a9CTVTvcRBqPTm6b5PunENpMjXLxX-7IGgk=|1744077733; captcha_session_v2=2|1:0|10:1744077734|18:captcha_session_v2|88:QkNNRGpaLzFMQ3NncGFVRXIxb1pSTXZlb3Axb3pCaGNibzlPRFI4cHhEUlpsU3ZyVUF5b0xGL2haSE1oS0xlZw==|d22291e8cfbad9e62e3ecf5b5879bd681e0dc56a87772f4b0a1bd674bfb6dc53; __snaker__id=1aUlWy7fvUjwSn3n; gdxidpyhxdE=%2BtQHnNHABo%2BnC7cQZNp5uprsnqVoGdyWn2QbuZGkZQ4K0Nio4pOnXNCRdPPZGh%2BOAJ8CYYhNxL%2B9bl%5CMngU%5Cb16zCg3nm9eIK%5C6dD0g%2BwE6q%2BUlwgi0dAj6TOMH5%2FqRH%5CYay%2BezxLU01dKTr4k9QPsXGtdRZ%2BkD6xU%5CxS6RKyHTSXxlh%3A1744078635509; q_c1=6573efe200e34e6e9cb0469042bfafde|1744077773000|1744077773000; z_c0=2|1:0|10:1744077775|4:z_c0|92:Mi4xUHZCWVJnQUFBQUJyMEpOVk85eEVHaGNBQUFCZ0FsVk56ZEhoYUFCU1V6WFFiOURmc3VsUnoyd0NtYUdYdTl6N1dB|29591bd5fc696067e49e9509e5fac6fd4663498734ece22be113ccb401123931; _xsrf=ee0ea1ed-31f9-45ab-a923-fc97da5d7663; Hm_lvt_98beee57fd2ef70ccdd5ca52b9740c49=1744077734,1744104477; HMACCOUNT=29A6B844A9199C82; SESSIONID=alwM2PqMj7oxC3sRO72GFRwFMAnqV5ntSfBTuVLEheH; JOID=UV0WC0NgDf9xcWbsRRC3LEFGsaVfB2eDPEgwmwMBPJYCMl6ZEX3sAB18ZuFOibPgrBwBunupBMfuYiuxq0TeVS8=; osd=UVoSBkxgCvt8fmbrQR24LEZCvKpfAGOOM0g3nw4OPJEGP1GZFnnhDx17YuxBibTkoRMBvX-kC8fpZia-q0PaWCA=; Hm_lpvt_98beee57fd2ef70ccdd5ca52b9740c49=1744104666; tst=v; BEC=8b4a1b0a664dd5d88434ef53342ae417; unlock_ticket=AOBXjeH6uhYXAAAAYAJVTeLz9Gd8qlW4_xKazEBGBzAktCSlnf9y0w=="
cookies = cookie
jar = requests.cookies.RequestsCookieJar()
headers = {
'Host': 'www.zhihu.com',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac 0sX10 11 4)AppleWebKit/537.36 (KHTML, like Gecko)Chrome/53.0.2785.116 afari/537.36'
}
for cookie in cookies.split(';'):
key, value = cookie.split('=', 1)
jar.set(key, value)
r = requests.get("http://www.zhihu.com", cookies=jar, headers=headers)
print(r.text)首先,创建一个RequestsCookieJar对象。接着,把复制来的cookies进行分割,利用set()方法,为每个Cookie设置好对应的key和value。之后,调用requests库的get()方法,将处理好的cookies作为参数传入。由于知乎网站自身的访问规则限制,headers参数是必须设置的,但不用在headers里再单独设置cookie字段。经过测试,用这种方法同样能顺利登录知乎。
三、会话维持
当我们用requests的get()或者post()方法模拟网页请求时,每次请求就相当于开启了一个新会话,这就好比用两个不同的浏览器打开不同页面。举个例子,假如我们先用post()方法登录网站,接着用get()方法去请求个人信息页面,这两次请求就像是在两个独立的浏览器中操作,所以没办法成功获取个人信息。
有的朋友可能会想,通过设置相同的cookies能不能解决这个问题呢?确实可以,不过操作起来特别麻烦。其实,更好的办法是维持同一会话,这就像在同一个浏览器里打开新的选项卡一样。要实现这一点,我们可以借助Session对象。Session对象使用起来很方便,它不仅能维护会话,还能自动帮我们处理cookies相关问题。下面来看具体示例:
import requests
requests.get('http://httpbin.org/cookies/set/number/123456789')
r = requests.get('http://httpbin.org/cookies')
print(r.text)
上述代码请求了测试网址http://httpbin.org/cookies/set/number/123456789设置cookie,名称为number,内容是123456789,随后请求http://httpbin.org/cookies获取当前Cookies。运行结果如下:
{
"cookies": {}
} 可见,直接请求无法获取设置的Cookies。使用Session对象再次尝试:
import requests
s = requests.Session()
s.get('http://httpbin.org/cookies/set/number/123456789')
r = s.get('http://httpbin.org/cookies')
print(r.text)
运行结果如下:
{
"cookies": {
"number": "123456789"
}
}这下成功获取数据了!从这就能看出,同一会话和不同会话存在明显差别。在实际应用里,Session用得特别多,尤其是模拟登录成功后,进行下一步操作的时候。比如说,模拟在同一个浏览器中,打开同一网站的不同页面。后面专门有章节,会对这部分内容进行详细讲解。
四、SSL证书验证
requests带有证书验证功能。当我们发送HTTP请求时,它会对SSL证书进行检查。通过verify参数,就能决定要不要执行这项检查。要是不设置verify参数,它默认是True,也就是会自动验证证书。
之前说过,很久以前的12306网站的证书不被官方CA机构认可,访问时就会出现证书验证错误。

下面用requests做个测试:
import requests
response = requests.get("https://www.12306.cn")
print(response.status_code)运行结果如下:
requests.exceptions.SSLError: ("bad handshake: Error([('SSL routines', 'tls process server certificate', 'certificate verify failed')],)")
程序提示SSLError错误,这说明证书验证没通过。当我们请求HTTPS网站,要是证书验证出了问题,就会弹出这个错误。要是想避开这个错误,把verify参数设为False就行。具体代码如下:
import requests
response = requests.get('https://www.12306.cn', verify=False)
print(response.status_code)运行后会打印出请求成功的状态码,但会报出警告:
/usr/local/lib/python3.6/site-packages/urllib3/connectionpool.py:852:InsecureRequestWarning: UnverifiedHTTPS request is being made, Adding certificate verification is strongly advised. See:https://urllib3.readthedocs.io/en/latest/advanced-usage.html#ssl-warningsInsecureRequestWarning)
200
可通过设置忽略警告或捕获警告到日志的方式屏蔽该警告。设置忽略警告:
import requests
from requests.packages import urllib3
urllib3.disable_warnings()
response = requests.get('https://www.12306.cn', verify=False)
print(response.status_code)捕获警告到日志:
import logging
import requests
logging.captureWarnings(True)
response = requests.get('https://www.12306.cn', verify=False)
print(response.status_code)除了上面的方法,我们还能指定本地证书当作客户端证书。这个本地证书,既可以是一个同时包含密钥和证书的文件,也能是一个包含两个文件路径的元组 :
import requests
response = requests.get('https://www.12306.cn', cert=('/path/server.crt', '/path/key'))
print(response.status_code)上面这些代码只是用来演示的。在实际使用的时候,你得有crt和key这两个文件,并且要把它们的正确路径指出来。还有一点要注意,本地私有证书的key必须处于解密状态,要是key是加密状态,程序不支持。
五、代理设置
测试某些网站时,少量请求能正常获取内容,但大规模爬取时,频繁请求可能导致网站弹出验证码、跳转到登录认证页面,甚至封禁客户端IP。为避免这种情况,需设置代理,可通过proxies参数实现,示例如下:
import requests
proxies = {
"http": "http://10.10.1.10:3128",
"https": "http://10.10.1.10:1080"
}
requests.get("https://www.taobao.com", proxies=proxies)上述代理可能无效,需替换为有效代理进行试验。若代理需要使用HTTP Basic Auth,可使用类似http://user:password@host:port的语法设置代理,示例如下:
import requests
proxies = {
"http": "http://user:password@10.10.1.10:3128/"
}
requests.get("https://www.taobao.com", proxies=proxies)除基本的HTTP代理外,requests还支持SOCKS协议的代理。使用前需安装socks库:
pip3 install 'requests[socks]'安装后即可使用SOCKS协议代理,示例如下:
import requests
proxies = {
'http':'socks5://user:password@host:port',
'https':'socks5://user:password@host:port'
}
requests.get("https://www.taobao.com", proxies=proxies)六、超时设置
要是你自己电脑的网络不好,或者服务器那边响应特别慢,甚至压根没反应,那你可能要等很久才能收到响应,弄不好最后还会报错。为了避免一直傻等,我们可以设定一个超时时间。意思就是,过了这个时间还没收到服务器的回应,程序就报错。这可以通过timeout参数来设置,例子如下:
import requests
r = requests.get("https://www.taobao.com", timeout =1)
print(r.status_code)上面代码里把超时时间设成了1秒,要是1秒内没收到响应,就会抛出异常。请求其实分两个阶段,一个是连接服务器(connect),另一个是读取数据(read)。刚才设置的timeout是这两个阶段加起来的总超时时间。要是你想分别给这两个阶段设置超时时间,可以传一个元组进去:
r = requests.get('https://www.taobao.com', timeout=(5, 11.30))若想永久等待,可将timeout设置为None,或不设置(默认值为None),用法如下:
r = requests.get('https://www.taobao.com', timeout=None)或直接不加参数:
r = requests.get('https://www.taobao.com')七、身份认证

访问网站时可能遇到认证页面,requests自带身份认证功能,示例如下:
import requests
from requests.auth import HTTPBasicAuth
r = requests.get('http://localhost:5000', auth=HTTPBasicAuth('username', 'password'))
print(r.status_code)
若用户名和密码正确,请求时自动认证成功,返回200状态码;若认证失败,返回401状态码。直接传递HTTPBasicAuth类作为参数较繁琐,requests提供了更简便的写法,直接传一个元组,它会默认使用HTTPBasicAuth类进行认证,代码可简写为:
import requests
r = requests.get('http://localhost:5000', auth=('username', 'password'))
print(r.status_code)此外,requests还提供其他认证方式,如OAuth认证。使用OAuth认证需安装oauth包,安装命令如下:
pip3 install requests_oauthlib使用OAuth1认证的方法如下:
import requests
from requests_oauthlib import OAuth1
url = 'https://api.twitter.com/1.1/account/verify_credentials.json'
auth = OAuth1('YOUR_APP_KEY', 'YOUR_APP_SECRET', 'USER_OAUTH_TOKEN', 'USER_OAUTH_TOKEN_SECRET')
requests.get(url, auth=auth)更多详细功能可参考requests_oauthlib的官方文档https://requests-oauthlib.readthedocs.org/。
八、Prepared Request
在介绍urllib时,可将请求表示为数据结构,各参数通过一个对象表示。requests中也有类似功能,对应的数据结构是Prepared Request。示例如下:
from requests import Request, Session
url = "http://httpbin.org/post"
data = {'name': 'germey'}
headers = {
'User-Agent': 'Mozilla/5.0(Macintosh; Intel Mac0sX10 11 4)AppleWebKit/537.36 (KHTML, like Gecko)Chrome/53.0.2785.116 Safari/537.36'
}
s = Session()
req = Request('POST', url, data=data, headers=headers)
prepped = s.prepare_request(req)
r = s.send(prepped)
print(r.text)引入Request后,用url、data和headers参数构造Request对象,再调用Session的prepare_request()方法将其转换为Prepared Request对象,最后调用send()方法发送请求。运行结果如下:
{
"args": {},
"data": "",
"files": {},
"form": {
"name": "germey"
},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Connection": "close",
"Content-Length": "11",
"Content-Type": "application/x-www-form-urlencoded",
"Host": "httpbin.org",
"User-Agent": "Mozilla/5.0(Macintosh; Intel Mac 0sX10 11 4)AppleWebKit/537.36 (KHTML, like Gecko)Chrome/53.0.2785.116 Safari/537.36"
},
"json": null,
"origin": "182.32.203.166",
"url": "http://httpbin.org/post"
}从结果能看出,我们通过这种方式实现了和普通POST请求一样的效果。有了Request对象后,我们可以把每个请求当成一个独立个体。这在进行队列调度时特别方便,后续我们会利用它来构建一个Request队列。
这一节给大家介绍了requests的一些高级用法,在后面实际项目中,这些用法会经常用到,大家要熟练掌握。要是还想了解更多requests的用法,可以查看它的官方文档:http://docs.python-requests.org/ 。
参考学习书籍:Python 3网络爬虫开发实战