目录
一、ts文件的由来
二、下载ts文件
1.下载index.m3u8,并做相应处理
2.下载ts文件
三、合并ts文件
一、ts文件的由来
ts文件,ts即"Transport Stream"的缩写,特点就是要求从视频流的任一片段开始都是可以独立解码的,非常适合网络视频播放。
打开网址:https://www.kan35.com/play/210314-3-1.html,要怎么才能把这个视频下载到电脑上呢?
按F12发现,这些视频被切割成无数个细小的片断,如图:

上图中,用红框圈出来的部分很重要,.ts的文件就是被切割的视频文件。但是这些视频文件名字全是乱的,没有规律。它们的顺序是通过index.m3u8实现的,上图中有两个index.m3u8文件,一般是尺寸更大的那个才是存放视频播放顺序的文件。可以在浏览器中打开看下:

可以看出,这个文件里面确实保存了ts文件播放顺序,当然一些其它的网站提供的index.m3u8文件格式会有些不一样,这些都可以后期处理。
二、下载ts文件
1.下载index.m3u8,并做相应处理
这个index.m3u8很重要,直接右键“Open in new tab”就可以下载下来,但是该怎么处理呢?
首先,了解下什么是m3u8:
m3u8是苹果公司推出的视频播放标准,是m3u的一种,只是编码格式采用的是UTF-8。
m3u8准确来说是一种索引文件,使用m3u8文件实际上是通过它来解析对应的放在服务器上的视频网络地址,从而实现在线播放。使用m3u8格式文件主要因为可以实现多码率视频的适配,视频网站可以根据用户的网络带宽情况,自动为客户端匹配一个合适的码率文件进行播放,从而保证视频的流畅度。
其次,怎么解析这个文件?
最简单的方式是复制里面的内容,然后在excel中筛选包含“https”的字符串。
当然,我们可以用更专业的方法,在python中用“pip install m3u8”安装这个模块,然后就可以用代码解析了。
import m3u8
data = m3u8.load("index0.m3u8").data
data显示内容大概如下:
{'media_sequence': 0, 'is_variant': False, 'is_endlist': True, 'is_i_frames_only': False, 'is_independent_segments': False, 'playlist_type': 'vod', 'playlists': [], 'segments': [ {'duration': 2.667, 'title': '', 'uri': 'https://hey06.cjkypo.com/20211214/lIC8S3qZ1/1000kb/hls/MQJ9iKoM.ts', 'cue_in': False, 'cue_out': False, 'cue_out_start': False, 'scte35': None, 'oatcls_scte35': None, 'scte35_duration': None, 'scte35_elapsedtime': None, 'asset_metadata': None, 'discontinuity': False, 'dateranges': None, 'gap_tag': None}, {'duration': 1.667, 'title': '', 'uri': 'https://hey06.cjkypo.com/20211214/lIC83SqZ1/1000kb/hls/8LeDe7Wu.ts', 'cue_in': False, 'cue_out': False, 'cue_out_start': False, 'scte35': None, 'oatcls_scte35': None, 'scte35_duration': None, 'scte35_elapsedtime': None, 'asset_metadata': None, 'discontinuity': False, 'dateranges': None, 'gap_tag': None},........................
可以看出,显示的内容很多,但是实际上只有“https://”那个字符串有用。
我们现在要做的是先提取每一个带“https”的字符串,然后还要提取出每个https字符串中的ts文件名。代码如下:
order_ts = []
#将所有的带https的url存入order_ts
for i in data["segments"]:
order_ts.append(i["uri"])
#返回一个dict,将文件名作为key,将url作为value
def read_name_url():
name_url = {}
for url in order_ts:
name = url.split("/")[-1]
name_url[name] = url
return name_url这个dict内容大概如下:
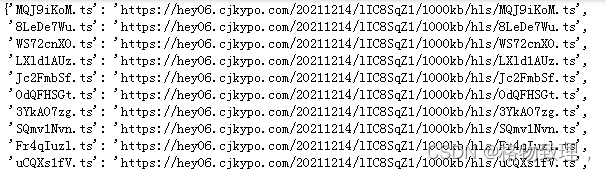
按理说,这个结果已经非常好了,但是我们还要进一步处理下,为我们最后一步的合并ts文件作准备。
list_name= read_name_url().keys()
file = open("order.m3u8", 'w')
for name in list_name:
file.write("file 'D:\\ProgramData\\study\\mov\\tsfiles\\" + name + "'")
file.write("\n")这个order.m3u8文件的内容大概如下:
file 'D:\ProgramData\study\mov\tsfiles\MQJ9iKoM.ts'
file 'D:\ProgramData\study\mov\tsfiles\8LeDe7Wu.ts'
file 'D:\ProgramData\study\mov\tsfiles\WS72cnXO.ts'
file 'D:\ProgramData\study\mov\tsfiles\LXld1AUz.ts'
file 'D:\ProgramData\study\mov\tsfiles\Jc2FmbSf.ts'...........
2.下载ts文件
ts文件很小,只有几百k,所以一个完整的视频会被分成几千个ts文件,我们可以采用多线程的方式来下载:
import urllib
from concurrent.futures import ThreadPoolExecutor
def download(url,name):
#下载ts文件到D:\ProgramData\study\mov\tsfiles文件夹
urllib.request.urlretrieve(url,'D://ProgramData//study//mov//tsfiles//'+name)
def download_tsfile():
#记录创立的线程
task_list = []
dict_name_url = read_name_url()
#线程池的创立
pool = ThreadPoolExecutor(max_workers=50)
for name in dict_name_url:
# 启动多个线程下载文件,download是函数名,后面两个是参数值
task_list.append(pool.submit(download, dict_name_url[name],name))
# 判断所有下载线程是否全部结束
while (True):
if len(task_list) == 0:
break
for i in task_list:
if i.done():
task_list.remove(i)
print("剩下任务数:{0}".format(len(task_list)))
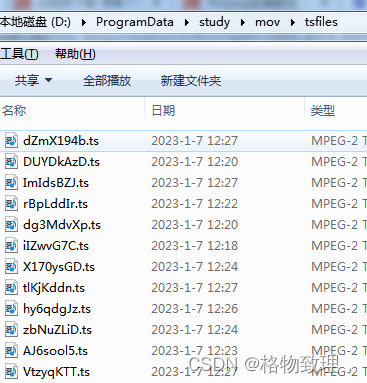
print("所有下载任务完成!")下载完成后,就可以在tsfiles文件夹找到这些细小的文件:
三、合并ts文件
有了前面两步的铺垫,现在要进行最重要的一个步骤了,那就是按order.m3u8里面的顺序,依次把这些ts文件合并起来。该怎么合并呢?
我们需要借助ffmpeg这个工具,这个工具非常强大,专门用来处理音频、视频切割、合并、编辑等,当然也非常复杂。安装这个软件,可以点击后面参考文章中的第二篇文章,这里不细说。下面来说说怎么合并这些ts文件。
代码非常简单:
import os
def mixTss(name):
#string前面加上‘r’,是为了告诉编译器这个string是个raw string,不要转义 backslash '\' 。
com = r'D:\\ffmpeg\\bin\\ffmpeg.exe -f concat -safe 0 -i D:\\ProgramData\\study\\mov\\order.m3u8 -c copy D:\\ProgramData\\study\\mov\\{}.mp4'.format(name)
os.system(com)
mixTss("hello")
print("合并完成!")可以看出上面的代码中,最重要的就是执行了一命令:
D:\ffmpeg\bin\ffmpeg.exe -f concat -safe 0 -i D:\ProgramData\study\mov\order.m3u8 -c copy D:\ProgramData\\study\\mov\\hello.mp4
ffmpeg很强大,但是也比较复杂,我也不是很懂这个,大概解释如下。
ffmpeg使用语法:
命令格式: ffmpeg -i [输入文件名] [参数选项] -f [格式] [输出文件] ffmpeg [[options][`-i' input_file]]... {[options] output_file}...
具体一点来说:
1. -f concat,-f 一般设置输出文件的格式,如-f psp(输出psp专用格式),但是如果跟concat,则表示采用concat协议,对文件进行连接合并。
2. -safe 0,用于忽略一些文件名错误,如长路径、空格、非ANSIC字符
3. -i D:\ProgramData\study\mov\order.m3u8,-i后面加输入文件名,当然也可以加输入文件名组成的文件名,即order.m3u8,但是要满足文件格式,即类似于下面这种:
file 'D:\ProgramData\study\mov\tsfiles\MQJ9iKoM.ts'
file 'D:\ProgramData\study\mov\tsfiles\8LeDe7Wu.ts'
4. -c copy D:\ProgramData\\study\\mov\\hello.mp4,-c表示输出文件采用的编码器,后面跟copy,表示不重新编码。
参考文章:ts视频下载 准备下载视频的你确定不进来看看吗_小王不头秃的博客-CSDN博客_ts视频下载
ffmpeg安装教程_小王不头秃的博客-CSDN博客_ffmpeg怎么安装