ClickHouse 是2016年开源的用于实时数据分析的一款高性能列式分布式数据库,支持向量化计算引擎、多核并行计算、高压缩比等功能,在分析型数据库中单表查询速度是最快的。2020年开始在滴滴内部大规模地推广和应用,服务网约车和日志检索等核心平台和业务。本文主要介绍滴滴日志检索场景从 ES 迁移到 CK 的技术探索。
背景
此前,滴滴日志主要存储于 ES 中。然而,ES 的分词、倒排和正排等功能导致其写入吞吐量存在明显瓶颈。此外,ES 需要存储原始文本、倒排索引和正排索引,这增加了存储成本,并对内存有较高要求。随着滴滴数据量的不断增长,ES 的性能已无法满足当前需求。
在追求降低成本和提高效率的背景下,我们开始寻求新的存储解决方案。经过研究,我们决定采用 CK 作为滴滴内部日志的存储支持。据了解,京东、携程、B站等多家公司在业界的实践中也在尝试用 CK 构建日志存储系统。
挑战
面临的挑战主要来自下面三个方面:
数据量大:每天会产生 PB 级别的日志数据,存储系统需要稳定地支撑 PB 级数据的实时写入和存储。
查询场景多:在一个时间段内的等值查询、模糊查询及排序场景等,查询需要扫描的数据量较大且查询都需要在秒级返回。
QPS 高:在 PB 级的数据量下,对 Trace 查询同时要满足高 QPS 的要求。
为什么选 Clickhouse
大数据量:CK 的分布式架构支持动态扩缩容,可支撑海量数据存储。
写入性能:CK 的 MergeTree 表的写入速度在200MB/s,具有很高吞吐,写入基本没有瓶颈。
查询性能:CK 支持分区索引和排序索引,具有很高的检索效率,单机每秒可扫描数百万行的数据。
存储成本:CK 基于列式存储,数据压缩比很高,同时基于HDFS做冷热分离,能够进一步地降低存储成本。
架构升级
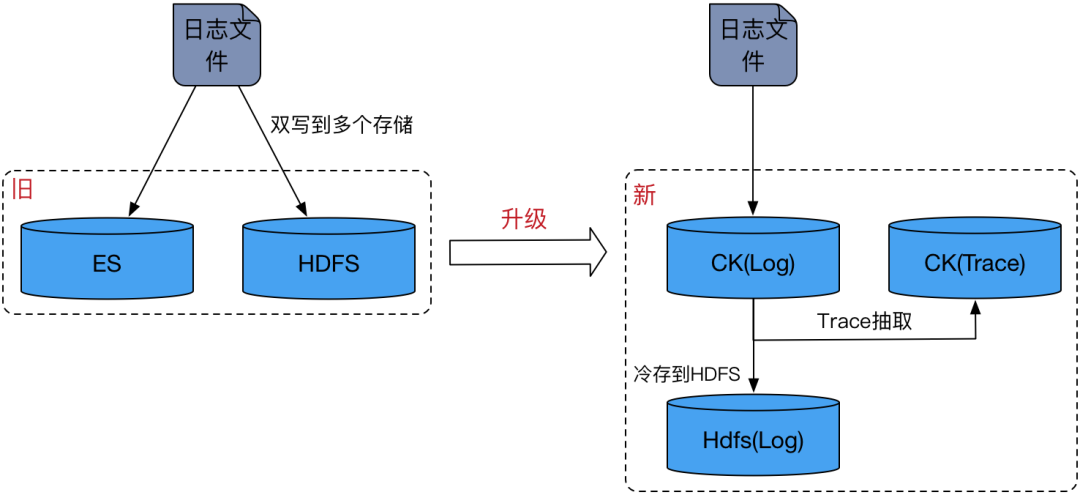
旧的存储架构下需要将日志数据双写到 ES 和 HDFS 两个存储上,由ES提供实时的查询,Spark 来分析 HDFS 上的数据。这种设计要求用户维护两条独立的写入链路,导致资源消耗翻倍,且操作复杂性增加。
在新升级的存储架构中,CK 取代了 ES 的角色,分别设有 Log 集群和 Trace 集群。Log 集群专门存储明细日志数据,而 Trace 集群则专注于存储 trace 数据。这两个集群在物理上相互隔离,有效避免了 log 的高消耗查询(如 like 查询)对 trace 的高 QPS 查询产生干扰。此外,独立的 Trace 集群有助于防止trace数据过度分散。
日志数据通过 Flink 直接写入 Log 集群,并通过 Trace 物化视图从 log 中提取 trace 数据,然后利用分布式表的异步写入功能同步至 Trace 集群。这一过程不仅实现了 log 与 trace 数据的分离,还允许 Log 集群的后台线程定期将冷数据同步到 HDFS 中。
新架构仅涉及单一写入链路,所有关于 log 数据冷存储至 HDFS 以及 log 与 trace 分离的处理均由 CK 完成,从而为用户屏蔽了底层细节,简化了操作流程。
考虑到成本和日志数据特点,Log 集群和 Trace 集群均采用单副本部署模式。其中,最大的 Log 集群有300多个节点,Trace 集群有40多个节点。
存储设计
存储设计是提升性能最关键的部分,只有经过优化的存储设计才能充分发挥 CK 强大的检索性能。借鉴时序数据库的理念,我们将 logTime 调整为以小时为单位进行取整,并在存储过程中按照小时顺序排列数据。这样,在进行其他排序键查询时,可以快速定位到所需的数据块。例如,查询一个小时内数据时,最多只需读取两个索引块,这对于处理海量日志检索至关重要。
以下是我们根据日志查询特性和 CK 执行逻辑制定的存储设计方案,包括 Log 表、Trace 表和 Trace 索引表:
Log 表
Log 表旨在为明细日志提供存储和查询服务,它位于 Log 集群中,并由 Flink 直接从 Pulsar 消费数据后写入。每个日志服务都对应一张 Log 表,因此整个 Log 集群可能包含数千张 Log 表。其中,最大的表每天可能会生成 PB 级别的数据。鉴于 Log 集群面临表数量众多、单表数据量大以及需要进行冷热数据分离等挑战,以下是针对 Log 表的设计思路:
CREATE TABLE ck_bamai_stream.cn_bmauto_local
(
`logTime` Int64 DEFAULT 0, -- log打印的时间
`logTimeHour` DateTime MATERIALIZED toStartOfHour(toDateTime(logTime / 1000)), -- 将logTime向小时取整
`odinLeaf` String DEFAULT '',
`uri` LowCardinality(String) DEFAULT '',
`traceid` String DEFAULT '',
`cspanid` String DEFAULT '',
`dltag` String DEFAULT '',
`spanid` String DEFAULT '',
`message` String DEFAULT '',
`otherColumn` Map<String,String>,
`_sys_insert_time` DateTime MATERIALIZED now()
)
ENGINE = MergeTree
PARTITION BY toYYYYMMDD(logTimeHour)
ORDER BY (logTimeHour,odinLeaf,uri,traceid)
TTL _sys_insert_time + toIntervalDay(7),_sys_insert_time + toIntervalDay(3) TO VOLUME 'hdfs'
SETTINGS index_granularity = 8192,min_bytes_for_wide_part=31457280分区键:根据查询特点,几乎所有的 sql 都只会查1小时的数据,但这里只能按天分区,小时分区导致 Part 过多及 HDFS 小文件过多的问题。
排序键:为了快速定位到某一个小时的数据,基于 logTime 向小时取整物化了一个新的字段 logTimeHour,将 logTimeHour 作为第一排序键,这样就能将数据范围锁定在小时级别,由于大部分查询都会指定上 odinLeaf、uri、traceid,依据基数从小到大分别将其作为第二、三、四排序键,这样查询某个 traceid 的数据只需要读取少量的索引块,经过上述的设计所有的等值查询都能达到毫秒级。
Map 列:引入了 Map 类型,实现动态的 Scheme,将不需要用来过滤的列统统放入 Map 中,这样能有效减少 Part 的文件数,避免 HDFS 上出现大量小文件。
Trace 表
Trace 表是用来提供 trace 相关的查询,这类查询对 QPS 要求很高,创建在 Trace 集群。数据来源于从 Log 表中提取的 trace 记录。Trace 表只会有一张,所有的 Log 表都会将 trace 记录提取到这张 Trace 表,实现的方式是 Log 表通过物化视图触发器跨集群将数据写到 Trace 表中。
Trace 表的难点在于查询速度快且 QPS 高,以下是 Trace 表的设计思路:
CREATE TABLE ck_bamai_stream.trace_view
(
`traceid` String,
`spanid` String,
`clientHost` String,
`logTimeHour` DateTime,
`cspanid` AggregateFunction(groupUniqArray, String),
`appName` SimpleAggregateFunction(any, String),
`logTimeMin` SimpleAggregateFunction(min, Int64),
`logTimeMax` SimpleAggregateFunction(max, Int64),
`dltag` AggregateFunction(groupUniqArray, String),
`uri` AggregateFunction(groupUniqArray, String),
`errno` AggregateFunction(groupUniqArray, String),
`odinLeaf` SimpleAggregateFunction(any, String),
`extractLevel` SimpleAggregateFunction(any, String)
)
ENGINE = AggregatingMergeTree
PARTITION BY toYYYYMMDD(logTimeHour)
ORDER BY (logTimeHour, traceid, spanid, clientHost)
TTL logTimeHour + toIntervalDay(7)
SETTINGS index_granularity = 1024AggregatingMergeTree:Trace 表采用了聚合表引擎,会按 traceid 进行聚合,能很大程度的聚合 trace 数据,压缩比在5:1,能极大地提升 Trace 表的检索速度。
分区键和排序键:与 Log 的设计类似。
index_granularity:这个参数是用来控制稀疏索引的粒度,默认是8192,减小这个参数是为了减少数据块中无效的数据扫描,加快 traceid 的检索速度。
Trace 索引表
Trace 索引表的主要作用是加快 order_id、driver_id、driver_phone 等字段查询 traceid 的速度。为此,我们给需要加速的字段创建了一个聚合物化视图,以提高查询速度。数据则是通过为 Log 表创建相应的物化视图触发器,将数据提取到 Trace 索引表中。
以下是建立 Trace 索引表的语句:
CREATE TABLE orderid_traceid_index_view
(
`order_id` String,
`traceid` String,
`logTimeHour` DateTime
)
ENGINE = AggregatingMergeTree
PARTITION BY logTimeHour
ORDER BY (order_id, traceid)
TTL logTimeHour + toIntervalDay(7)
SETTINGS index_granularity = 1024存储设计的核心目标是提升查询性能。接下来,我将介绍从 ES 迁移至 CK 过程中,在这一架构下所面临的稳定性问题及其解决方法。
稳定性之路
支撑日志场景对 CK 来说是非常大的挑战,面临庞大的写入流量及超大集群规模,经过一年的建设,我们能够稳定的支撑重点节假日的流量高峰,下面的篇幅主要是介绍了在支撑日志场景过程中,遇到的一些问题。
大集群小表数据碎片化问题
在 Log 集群中,90%的 Log 表流量低于10MB/s。若将所有表的数据都写入数百个节点,会导致大量小表数据碎片化问题。这不仅影响查询性能,还会对整个集群性能产生负面影响,并为冷数据存储到 HDFS 带来大量小文件问题。
为解决大规模集群带来的问题,我们根据表的流量大小动态分配写入节点。每个表分配的写入节点数量介于2到集群最大节点数之间,均匀分布在整个集群中。Flink 通过接口获取表的写入节点列表,并将数据写入相应的 CK 节点,有效解决了大规模集群数据分散的问题。
写入限流及写入性能提升
在滴滴日志场景中,晚高峰和节假日的流量往往会大幅增加。为避免高峰期流量过大导致集群崩溃,我们在 Flink 上实现了写入限流功能。该功能可动态调整每张表写入集群的流量大小。当流量超过集群上限时,我们可以迅速降低非关键表的写入流量,减轻集群压力,确保重保表的写入和查询不受影响。
同时为了提升把脉的写入性能,我们基于 CK 原生 TCP 协议开发了 Native-connector。相比于 HTTP 协议,Native-connector 的网络开销更小。此外,我们还自定义了数据类型的序列化机制,使其比之前的 Parquet 类型更高效。启用 Native-connector 后,写入延迟率从之前的20%降至5%,整体写入性能提升了1.2倍。
HDFS 冷热分离的性能问题
用 HDFS 来存储冷数据,在使用的过程中出现以下问题:
服务重启变得特别慢且 Sys cpu 被打满,原因是在服务重启的过程中需要并发的加载 HDFS 上 Part 的元数据,而 libhdfs3 库并发读 HDFS 的性能非常差,每当读到文件末尾都会抛出异常打印堆栈,产生了大量的系统调用。
当写入历史分区的数据时,数据不会落盘,而是直接往 HDFS 上写,写入性能很差,并且直接写到 HDFS 的数据还需要拉回本地 merge,进一步降低了 merge 的性能。
本地的 Part 路径和 HDFS 的路径是通过 uuid 来映射的,所有表的数据都是存储在 HDFS 的同一路径下,导致达到了 HDFS 目录文件数 100w 的限制。
HDFS 上的 Part 文件路径映射关系是存储在本地的,如果出现节点故障,那么文件路径映射关系将会丢失,HDFS 上的数据丢失且无法被删除。
为此我们对 HDFS 冷热分离功能进行了比较大的改造来解决上面的问题,解决 libhdfs3 库并发读 HDFS 的问题并在本地缓存 HDFS 的 Part 元数据文件,服务的启动速度由原来的1小时到1分钟。
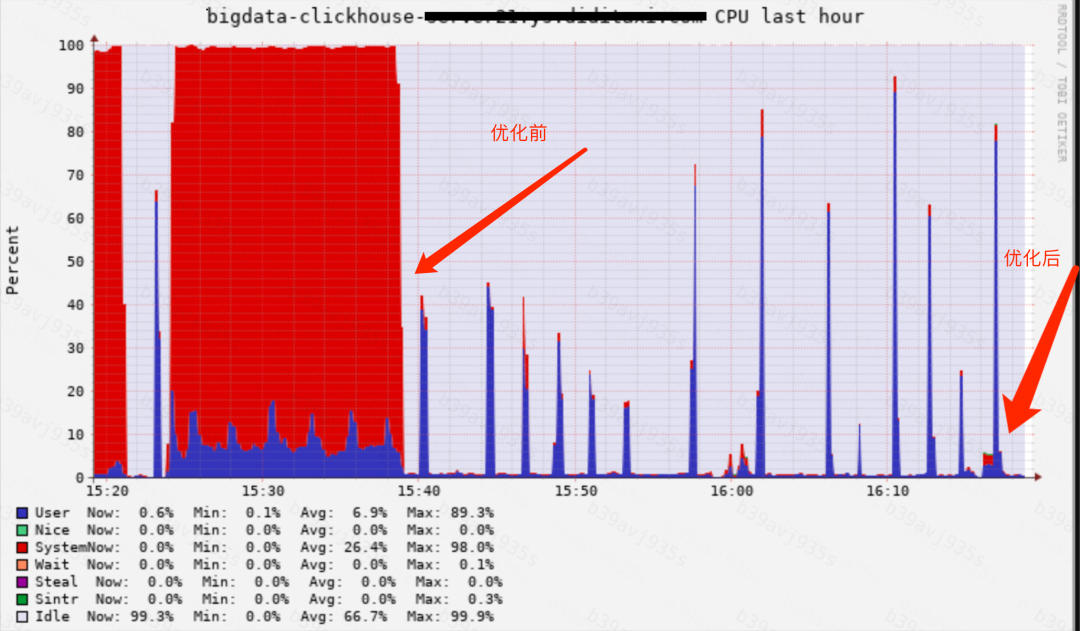
同时禁止历史数据直接写 HDFS ,必须先写本地,merge 之后再上传到 HDFS ,最后对 HDFS 的存储路径进行改造。由原来数据只存储在一个目录下改为按 cluster/shard/database/table/ 进行划分,并按表级别备份本地的路径映射关系到 HDFS。这样一来,当节点故障时,可以通过该备份恢复 HDFS 的数据。
收益
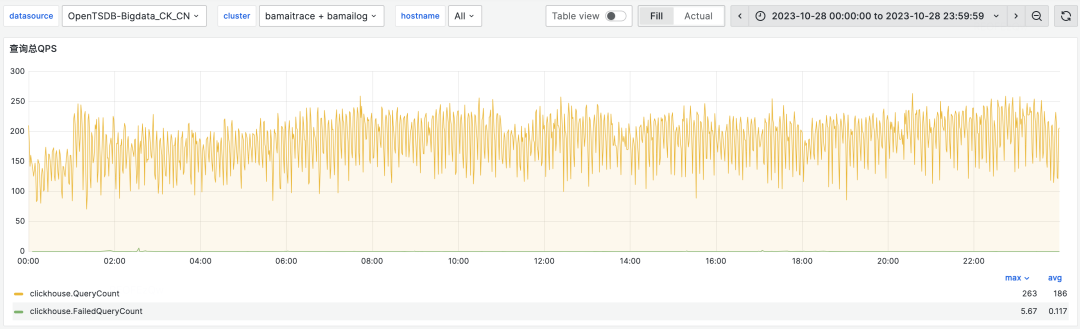
在日志场景中,我们已经成功完成了从 ES 到 CK 的迁移。目前,CK 的日志集群规模已超过400个物理节点,写入峰值流量达到40+GB/s,每日查询量约为1500万次,支持的 QPS 峰值约为200。相较于 ES,CK 的机器成本降低了30%。
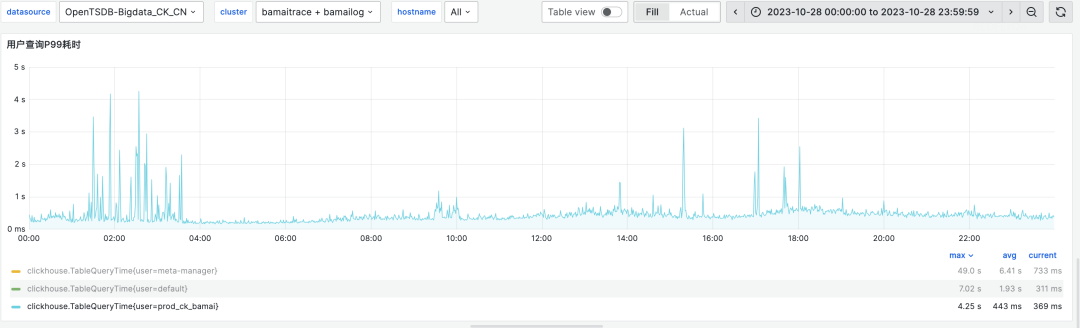
查询速度相比 ES 提高了约4倍。下图展示了 bamailog 集群和 bamaitrace 集群的 P99 查询耗时情况,基本都在1秒以内。
总结
将日志从 ES 迁移至 CK 不仅可以显著降低存储成本,还能提供更快的查询体验。经过一年多的建设和优化,系统的稳定性和性能都有了显著提升。然而,在处理模糊查询时,集群的资源消耗仍然较大。未来,我们将继续探索二级索引、zstd 压缩以及存算分离等技术手段,以进一步提升日志检索性能。