一起来体验一下吧~
技术报告书:gemma-report.pdf (storage.googleapis.com)
代码1 :google-deepmind/gemma: Open weights LLM from Google DeepMind. (github.com)
代码2 :https://github.com/google/gemma_pytorch
代码3 :
技术报告书:
1.论文详解
谷歌介绍的Gemma的主要特点如下。
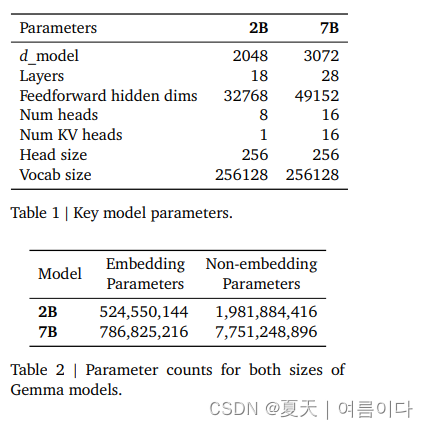
- 新车型将提供两种变体:Gemma 2B 和 Gemma 7B。这两种类型分别带有预训练和指令调整的变体。
- 新的负责任的生成式 AI 工具包提供指导和基本工具,帮助您使用 Gemma 构建更安全的 AI 应用程序。
- Native Keras 3.0 在 JAX、PyTorch 和 TensorFlow 等领先框架中提供了用于监督微调 (SFT) 的工具链。
- 它配备了即用型 Colab 和 Kaggle 笔记本电脑,以及 Hugging Face、MaxText 和 NVIDIA NeMo 等通用工具,使 Gemma 易于用户使用。
- 预先训练和指令调整的 Gemma 模型可在笔记本电脑、工作计算机甚至 Google Cloud 上使用,并且使用 Vertex AI 和 Google Kubernetes Engine (GKE) 轻松安装。
- Gemma 针对各种 AI 硬件平台进行了优化,确保了行业领先的性能,包括 NVIDIA GPU 和 Google Cloud TPU。
- 条款和条件允许负责任的商业用途和分发给各种规模的企业。
Gemma 是由 Google 推出的一系列轻量级、先进的开源模型,基于 Google Gemini 模型的研究和技术而构建。它们是一系列text generation,decoder-only的大型语言模型,对英文的支持较好,具有模型权重开源、并提供预训练版本(base模型)和指令微调版本(chat模型)。
本次 Gemma 开源提供了四个大型语言模型,提供了 2B 和 7B 两种参数规模的版本,每种都包含了预训练版本(base模型)和指令微调版本(chat模型)。
官方除了提供 pytorch 版本之外,也提供了GGUF版本,可在各类消费级硬件上运行,无需数据量化处理,并拥有高达 8K tokens 的处理能力,Gemma 7B模型的预训练数据高达6万亿Token,也证明了通过大量的高质量数据训练,可以大力出奇迹,小模型也可以持续提升取得好的效果。
1.1.模型构造
采用transformer的解码器
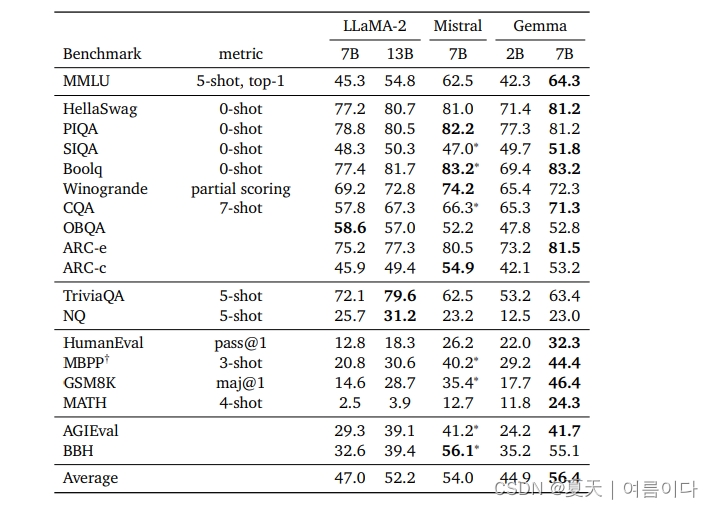
下图是针对不同任务/数据集的结果对比,取得了一个很好的结果。
微调
- 使用 QLoRA 对 UltraChat 数据集执行监督微调 (SFT) 的脚本
- 在 TPU 设备上使用 FSDP 执行 SFT 的脚本
- 可以在免费套餐 Google Colab 实例上运行的笔记本,用于对英语报价数据集执行 SFT
2.实战
对于 Gemma 型号的 7B 指令版本。还可以选择 2B 基本模型、7B 基本模型和 2B 指导模型的模型卡。
2.0环境设置
pip install -U transformers
pip install packaging
pip install accelerategit clone https://huggingface.co/google/gemma-7b-it/
cd gemma-7b-it 
2.1.在CPU上运行,这里省略
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("google/gemma-7b-it")
model = AutoModelForCausalLM.from_pretrained("google/gemma-7b-it")
input_text = "Write me a poem about Machine Learning."
input_ids = tokenizer(input_text, return_tensors="pt")
outputs = model.generate(**input_ids)
print(tokenizer.decode(outputs[0]))
2.2.在单个/多个 GPU 上运行模型
本文RAM24G,2张TITAN卡
# pip install accelerate
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("google/gemma-7b-it")
model = AutoModelForCausalLM.from_pretrained("google/gemma-7b-it", device_map="auto")
input_text = "Write me a poem about Machine Learning."
input_ids = tokenizer(input_text, return_tensors="pt").to("cuda")
outputs = model.generate(**input_ids)
print(tokenizer.decode(outputs[0]))运行后

默认 max_length` =20
可能会出现如下情况,
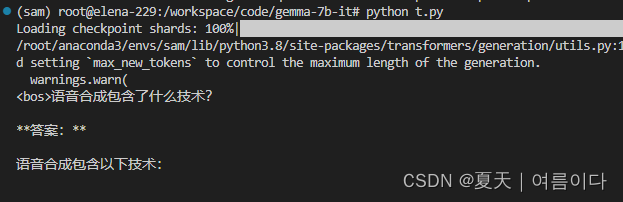
修改输出outputs = model.generate(**input_ids,max_length=64)就好啦~
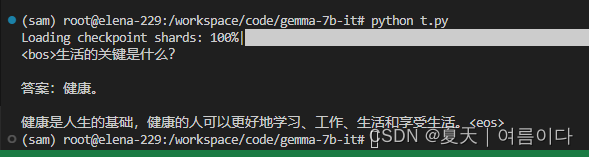
专业数据微调正在更新~
PS
【PS1】 Traceback (most recent call last):
File "/root/anaconda3/envs/sam/lib/python3.8/site-packages/huggingface_hub/utils/_errors.py", line 304, in hf_raise_for_status
response.raise_for_status()
File "/root/anaconda3/envs/sam/lib/python3.8/site-packages/requests/models.py", line 1021, in raise_for_status
raise HTTPError(http_error_msg, response=self)
requests.exceptions.HTTPError: 401 Client Error: Unauthorized for url: https://huggingface.co/google/gemma-7b-it/resolve/main/config.json
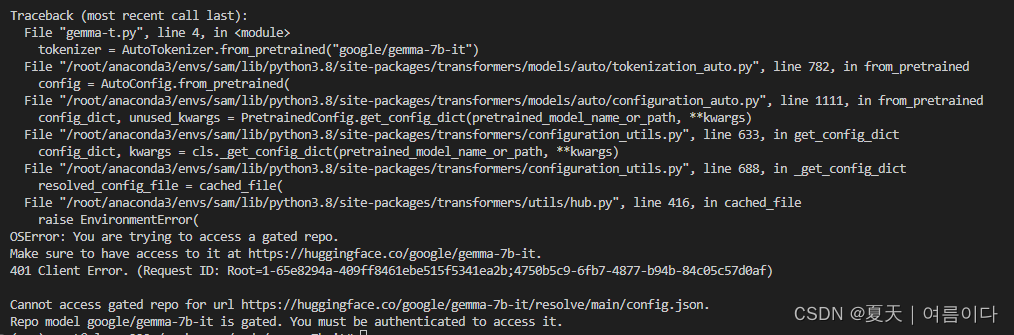
from huggingface_hub import login
login()在自己的huggingface账号上创建一个token

点击自己账号->Access Tokens->New token -> 输入名称->选择可写入->Generate a token
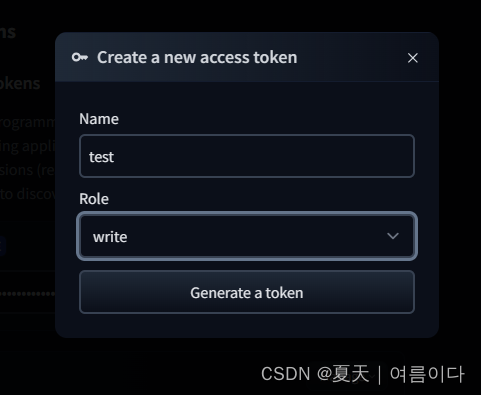
生成token后,复制到服务器里~
登录