深度学习的卷积神经网络(Convolutional Neural Network,简称CNN)是一种广泛应用于图像识别、计算机视觉和自然语言处理等领域的深度学习模型。
CNN的主要特点是它能够自动从原始数据中学习特征表示,而无需手动特征工程。这是通过使用卷积层、池化层和全连接层来实现的。
卷积层是CNN的核心,它使用一系列可学习的滤波器(也称为卷积核)来对输入数据进行卷积运算。这种卷积运算可以捕捉到数据中的局部空间关系,从而提取出不同的特征,例如边缘、纹理和形状。
池化层用于减少特征图的空间维度,并且在一定程度上保持重要的特征。最常用的池化操作是最大池化,它选取每个池化窗口中的最大值作为输出。
全连接层将上一层的特征图展平为一个向量,并将其连接到最终的输出层或分类层。全连接层使用线性变换和非线性激活函数来建模数据的复杂关系。
CNN的训练过程通常使用反向传播算法,通过最小化损失函数来调整网络的参数,使得网络能够更好地拟合训练数据。
总的来说,CNN是一种在深度学习中广泛应用的神经网络模型,它通过卷积层和池化层来学习图像和文本数据中的特征表示,从而实现高效的模式识别和数据分析。
政安晨的个人主页:政安晨
欢迎 👍点赞✍评论⭐收藏
收录专栏: 政安晨的机器学习笔记
希望政安晨的博客能够对您有所裨益,如有不足之处,欢迎在评论区提出指正!

起源
2011年~2015年,深度学习就是在计算机视觉领域兴起的。当时,一类叫作卷积神经网络(convolutional neural network,简称convnet)的深度学习模型开始在图像分类比赛中取得非常好的成绩,首先是Dan Ciresan赢得了两个小众比赛(2011年ICDAR汉字识别比赛和2011年IJCNN德国交通标志识别比赛),然后更引人注目的是在2012年秋季,Hinton小组赢得了著名的ImageNet大规模视觉识别挑战赛。在其他计算机视觉任务上,很快也出现了许多非常好的结果。
有趣的是,这些早期的成功案例还不足以让深度学习成为当时的主流。过了几年时间,深度学习才成为主流。多年来,计算机视觉研究人员一直在研究神经网络以外的方法,他们还没有准备好仅仅因为出现一种新方法就放弃旧方法。在2013年和2014年,深度学习仍被许多资深计算机视觉研究人员强烈质疑。直到2016年,深度学习才终于成为主流。
接下来,咱们以计算机视觉为例,来深入理解卷积神经网络的原理。
入门
我们先来看一个简单的卷积神经网络示例,它用于对MNIST数字进行分类。这个任务在咱们以前的文章中用密集连接网络做过,当时的测试精度约为97.8%。虽然这个卷积神经网络很简单,但其精度会超过咱们以前用到的密集连接模型。
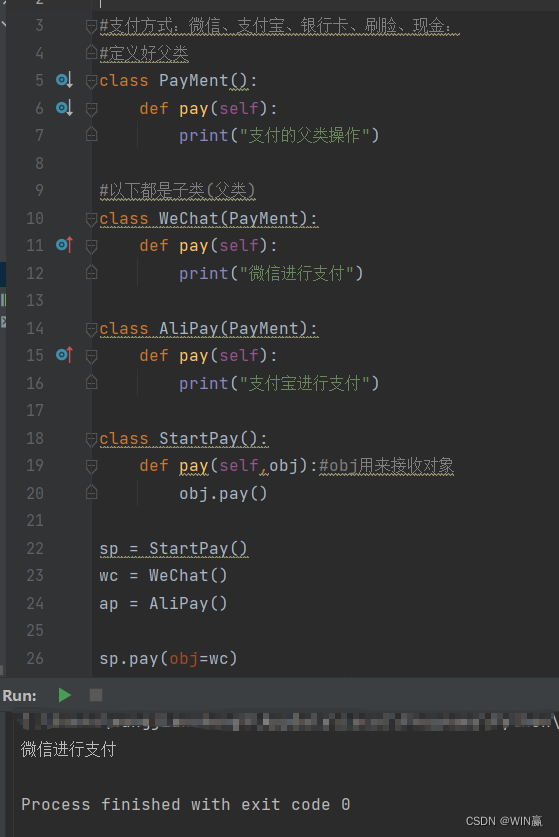
下述代码给出了一个简单的卷积神经网络。它是Conv2D层和MaxPooling2D层的堆叠,您逐渐就会知道这些层的作用。
如果您第一次接触这个,可以参照我以前的文章里搭建环境的部分,把机器学习的环境先建立起来:
政安晨的机器学习笔记——跟着演练快速理解TensorFlow(适合新手入门)![]() https://blog.csdn.net/snowdenkeke/article/details/135950931
https://blog.csdn.net/snowdenkeke/article/details/135950931
(实例化一个小型卷积神经网络)
from tensorflow import keras
from tensorflow.keras import layers
inputs = keras.Input(shape=(28, 28, 1))
x = layers.Conv2D(filters=32, kernel_size=3, activation="relu")(inputs)
x = layers.MaxPooling2D(pool_size=2)(x)
x = layers.Conv2D(filters=64, kernel_size=3, activation="relu")(x)
x = layers.MaxPooling2D(pool_size=2)(x)
x = layers.Conv2D(filters=128, kernel_size=3, activation="relu")(x)
x = layers.Flatten()(x)
outputs = layers.Dense(10, activation="softmax")(x)
model = keras.Model(inputs=inputs, outputs=outputs)可以看到:
卷积神经网络接收的输入张量的形状为(image_height,image_width, image_channels)(不包括批量维度)。
本例中,我们设置卷积神经网络处理大小为(28, 28, 1)的输入,这正是MNIST图像的格式。我们来看一下这个卷积神经网络的架构,如下所示:
(显示模型的概述信息)

可以看到,每个Conv2D层和MaxPooling2D层的输出都是一个形状为(height,width, channels)的3阶张量。
宽度和高度这两个维度的尺寸通常会随着模型加深而减小。通道数对应传入Conv2D层的第一个参数(32、64或128)。
在最后一个Conv2D层之后,我们得到了形状为(3, 3, 128)的输出,即通道数为128的3×3特征图。下一步是将这个输出传入密集连接分类器中,即Dense层的堆叠,相信您已经很熟悉了。这些分类器可以处理1阶的向量,而当前输出是3阶张量。为了让二者匹配,我们先用Flatten层将三维输出展平为一维,然后再添加Dense层。
最后,我们进行十类别分类,所以最后一层使用带有10个输出的softmax激活函数。
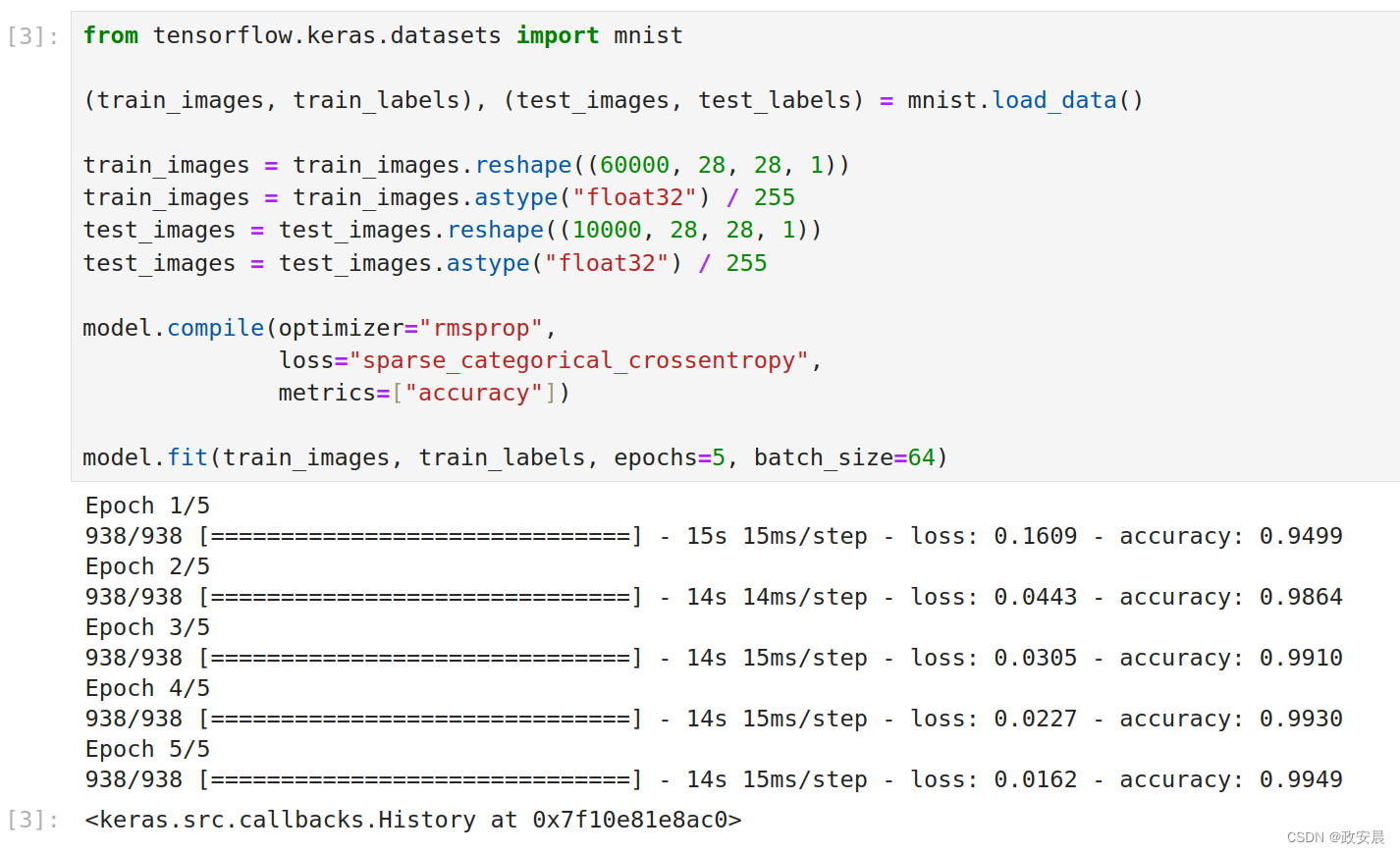
下面我们在MNIST数字上训练这个卷积神经网络。我们将重复使用以前文章中演绎过的MNIST示例中的很多代码。由于我们要做的是带有softmax输出的十类别分类,因此要使用分类交叉熵损失,而且由于标签是整数,因此要使用稀疏分类交叉熵损失sparse_categorical_crossentropy,如下代码所示:
(在MNIST图像上训练卷积神经网络)
from tensorflow.keras.datasets import mnist
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
train_images = train_images.reshape((60000, 28, 28, 1))
train_images = train_images.astype("float32") / 255
test_images = test_images.reshape((10000, 28, 28, 1))
test_images = test_images.astype("float32") / 255
model.compile(optimizer="rmsprop",
loss="sparse_categorical_crossentropy",
metrics=["accuracy"])
model.fit(train_images, train_labels, epochs=5, batch_size=64)演绎如下:
现在咱们评估卷积神经网络:

密集连接模型的测试精度约为97.93% (看我的这篇文章)
政安晨的机器学习笔记——基于Anaconda安装TensorFlow并尝试一个神经网络小实例![]() https://blog.csdn.net/snowdenkeke/article/details/135841281而这个简单的卷积神经网络的测试精度达到了99.2%,错误率降低了约60%(相对比例)。这相当不错!但是,与密集连接模型相比,这个简单卷积神经网络的效果为什么这么好?要回答这个问题,我们来深入了解Conv2D层和MaxPooling2D层的作用。
https://blog.csdn.net/snowdenkeke/article/details/135841281而这个简单的卷积神经网络的测试精度达到了99.2%,错误率降低了约60%(相对比例)。这相当不错!但是,与密集连接模型相比,这个简单卷积神经网络的效果为什么这么好?要回答这个问题,我们来深入了解Conv2D层和MaxPooling2D层的作用。
卷积运算
Dense层与卷积层的根本区别在于,Dense层从输入特征空间中学到的是全局模式(比如对于MNIST数字,全局模式就是涉及所有像素的模式),而卷积层学到的是局部模式(对于图像来说,局部模式就是在输入图像的二维小窗口中发现的模式),如下图所示:在上面的示例中,窗口尺寸都是3×3。

这个重要特性使卷积神经网络具有以下两个有趣的性质:
卷积神经网络学到的模式具有平移不变性(translation invariant)。
在图片右下角学到某个模式之后,卷积神经网络可以在任何位置(比如左上角)识别出这个模式。对于密集连接模型来说,如果模式出现在新的位置,它就需要重新学习这个模式。这使得卷积神经网络在处理图像时可以高效地利用数据(因为视觉世界本质上具有平移不变性),它只需要更少的训练样本就可以学到具有泛化能力的数据表示。
卷积神经网络可以学到模式的空间层次结构(spatial hierarchies of patterns)。
第一个卷积层学习较小的局部模式(比如边缘),第二个卷积层学习由第一层特征组成的更大的模式,以此类推,如下图所示。这使得卷积神经网络能够有效地学习越来越复杂、越来越抽象的视觉概念,因为视觉世界本质上具有空间层次结构。
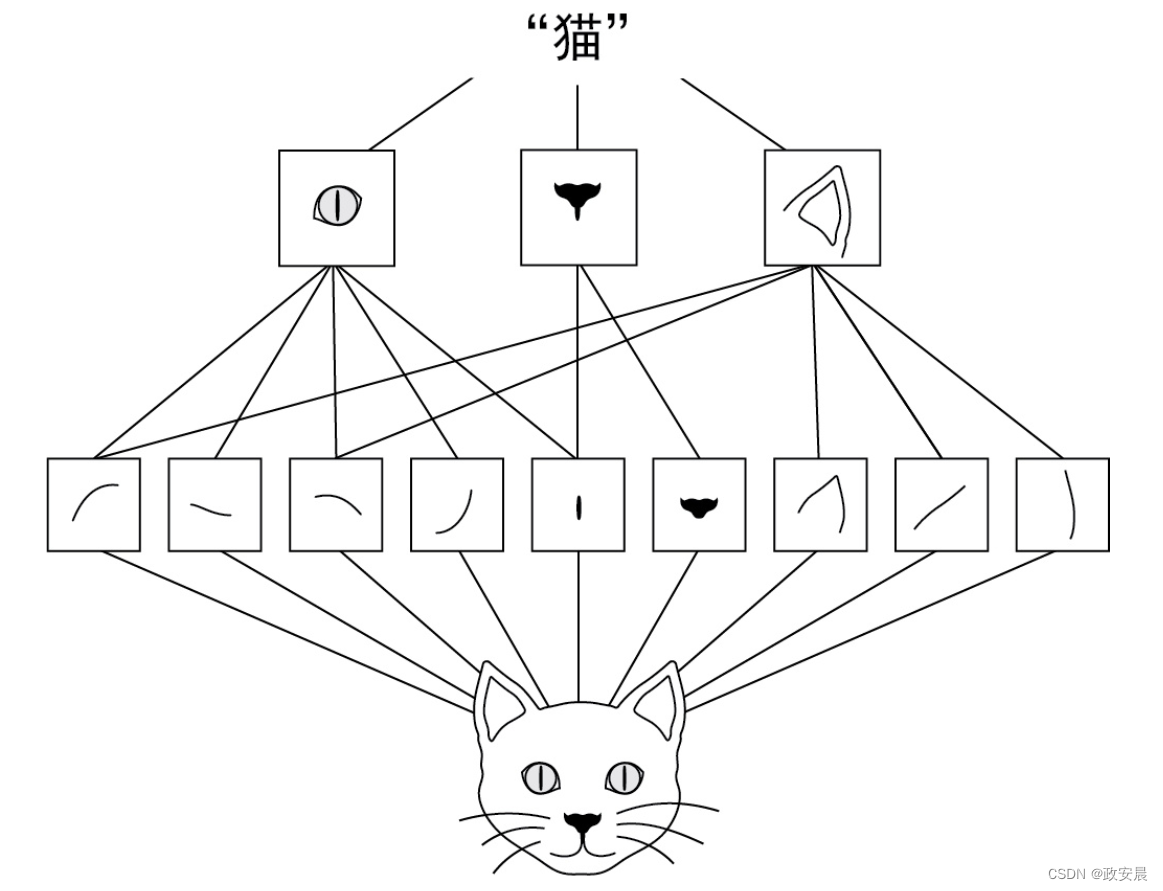
视觉世界形成了视觉模块的空间层次结构:基本的线条和纹理组合成简单对象,比如眼睛或耳朵。这些简单对象又组合成高级概念,比如“猫”
卷积运算作用于被称为特征图(feature map)的3阶张量,它有2个空间轴(高度和宽度)和1个深度轴(也叫通道轴)。
对于RGB图像,深度轴的维度大小为3,因为图像有3个颜色通道:红色、绿色和蓝色。对于黑白图像(比如MNIST数字图像),深度为1(表示灰度值)。卷积运算从输入特征图中提取图块,并对所有这些图块应用相同的变换,生成输出特征图。
该输出特征图仍是一个3阶张量,它有宽度和高度,深度可以任意取值,因为输出深度是该层的参数。深度轴的不同通道不再像RGB那样代表某种颜色,而是代表滤波器(filter)。滤波器对输入数据的某一方面进行编码。
比如,某个层级较高的滤波器可能编码这样一个概念:“输入中包含一张人脸。”
在MNIST示例中,第一个卷积层接收尺寸为(28, 28, 1)的特征图,并输出尺寸为(26, 26, 32)的特征图,也就是说,它在输入上计算了32个滤波器。对于这32个输出通道,每个通道都包含一个26×26的数值网格,它是滤波器对输入的响应图(response map),表示这个滤波器模式在输入中不同位置的响应。
如下图所示:
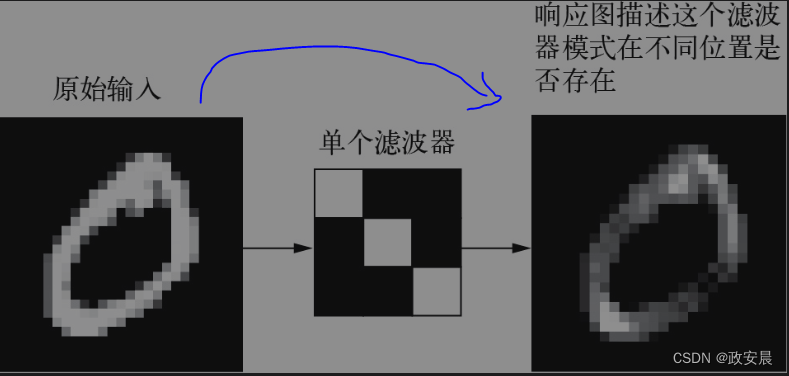
(响应图的概念:表示某个模式在输入中不同位置是否存在的二维图)
这就是特征图这一术语的含义:深度轴上的每个维度都是一个特征(滤波器),而2阶张量output[:, :, n]是这个滤波器在输入上的响应的二维图。
卷积由以下两个关键参数定义。
从输入中提取的图块尺寸:这些图块尺寸通常是3×3或5×5。
本例采用3×3,这是很常见的选择。
输出特征图的深度:卷积所计算的滤波器的数量。
本例第一层的深度为32,最后一层的深度为128。对于Keras的Conv2D层,这些参数就是向层传入的前几个参数:Conv2D(output_depth, (window_height, window_width))。
卷积的工作原理是这样的:在3维输入特征图上滑动(slide)这些3×3或5×5的窗口,在每个可能的位置停下来并提取周围特征的3维图块[形状为(window_height, window_width, input_depth)]。然后将每个这样的3维图块与学到的权重矩阵[叫作卷积核(convolution kernel),对所有图块都重复使用同一个卷积核]做张量积,使其转换成形状为(output_depth,)的1维向量。每个图块得到一个向量,然后对所有这些向量进行空间重组,将其转换成形状为(height, width, output_depth)的3维输出特征图。输出特征图中的每个空间位置都对应输入特征图中的相同位置(比如输出的右下角包含输入右下角的信息)。举个例子,利用3×3的窗口,向量output[i, j, :]来自于3维图块input[i-1:i+1, j-1:j+1, :]。整个过程如下图所示。
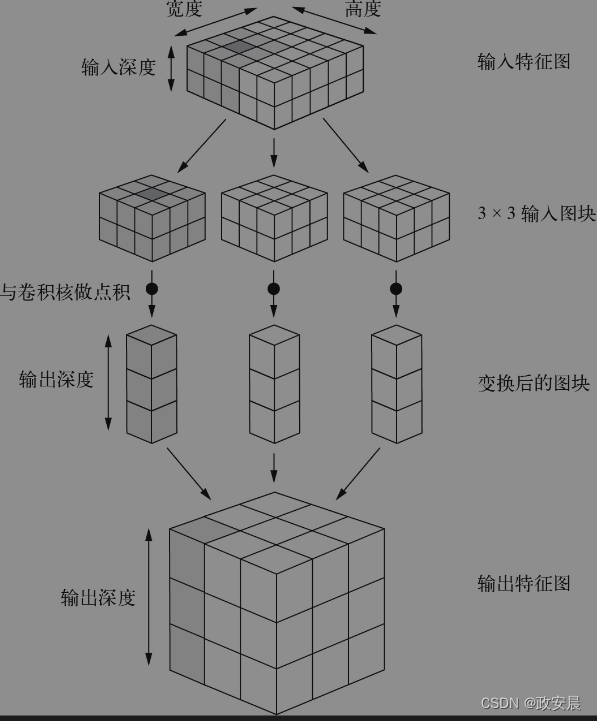
请注意,输出的宽度和高度可能与输入的宽度和高度不同,
原因有二:
边界效应,这可以通过对输入特征图进行填充来消除;
步幅,稍后会给出其定义。
我们来深入了解一下这些概念。
理解边界效应和填充
假设有一张5×5的特征图(共25个方块),其中只有9个方块可以作为中心放入一个3×3的窗口。这9个方块形成一个3×3的网格,如下图所示:
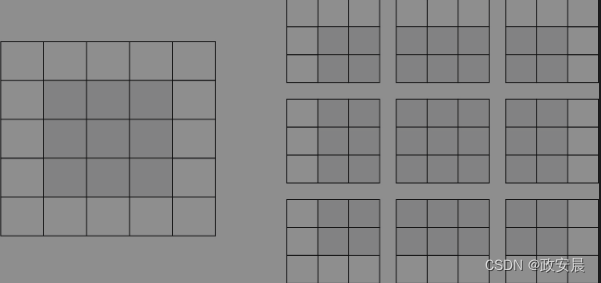
(在5×5的输入特征图中,可以提取3×3图块的有效位置)
因此,输出特征图的尺寸是3×3,它比输入缩小了一点,沿着每个维度都刚好减小了2个方块。在前面的例子中,你也可以看到这种边界效应:一开始的输入尺寸为28×28,经过第一个卷积层之后,尺寸变为26×26。
如果你希望输出特征图的空间尺寸与输入相同,那么可以使用填充(padding)。填充是指在输入特征图的每一边添加适当数量的行和列,使得每个输入方块都可以作为卷积窗口的中心。对于3×3的窗口,在左右各添加1列,在上下各添加1行。对于5×5的窗口,需要添加2行和2列,如下图所示:
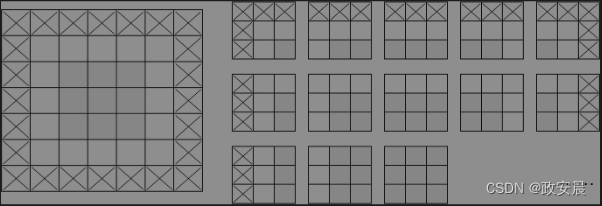
对于Conv2D层,可以通过padding参数来设置填充。这个参数可以取两个值:"valid"表示不填充(只使用有效的窗口位置);"same"表示“填充后输出的宽度和高度与输入相同”。padding参数的默认值为"valid"。
理解卷积步幅
影响输出尺寸的另一个因素是步幅(stride)。到目前为止,我们对卷积的描述假设卷积窗口的中心方块都是相邻的。但两个连续窗口之间的距离是卷积的一个参数,叫作步幅,默认值为1。也可以使用步进卷积(strided convolution),即步幅大于1的卷积。在下图中,你可以看到用步幅为2的3×3卷积从5×5输入中提取的图块(未使用填充)。

步幅为2意味着对特征图的宽度和高度都做了2倍下采样(除了边界效应引起的变化)。
步进卷积在分类模型中很少使用,但对某些类型的模型可能很有用。
对于分类模型,我们通常不使用步幅,而使用最大汇聚(max-pooling)运算来对特征图进行下采样。






![[IDE工具]Ubuntu18.04 VSCode版本升级](https://img-blog.csdnimg.cn/direct/4c5828f7a37e43ec926c9337613324e8.png)