🌈 博客个人主页:Chris在Coding
🎥 本文所属专栏:[高并发内存池]
❤️ 前置学习专栏:[Linux学习]
⏰ 我们仍在旅途

目录
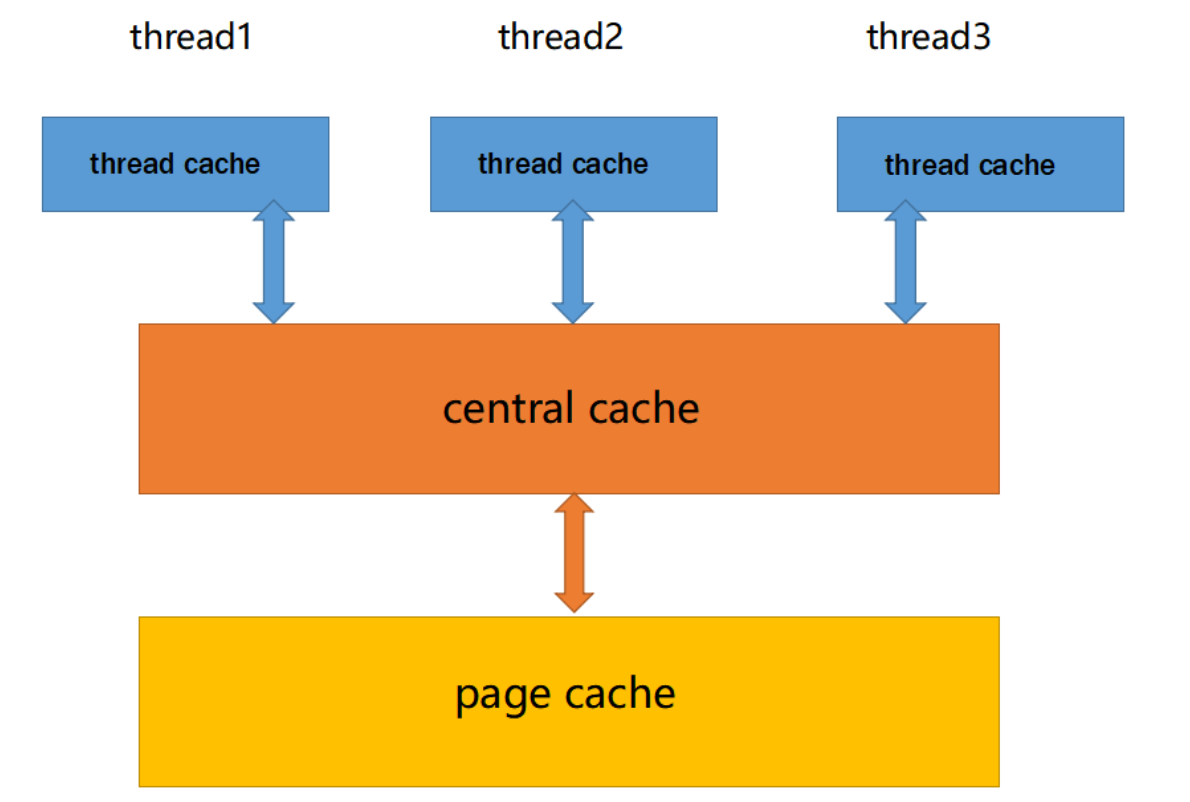
6.内存回收
6.1 ThreadCache回收内存
6.2 CentralCache回收内存
ReleaseListToSpans
MapObjToSpan
6.3 PageCache回收内存
ReleaseSpanToPageCache
回收内存测试
7.解决大内存申请释放
7.1 申请内存
RoundUp
ConcurrentAlloc
NewSpan
7.2 释放内存
ConcurrentFree
ReleaseSpanToPageCache
大内存测试
6.内存回收
6.1 ThreadCache回收内存
这是之前我们deallocate的代码:
//void ThreadCache::deallocate(void* ptr, size_t size)
//{
// assert(ptr);
// assert(size <= MAXSIZE);
// // 找对映射的空闲链表桶,对象插入进入
// size_t index = SizeTable::Index(size);
// _freelists[index].push(ptr);
//}这样可能潜在着这样的问题 : 随着线程不断的释放,对应自由链表的长度也会越来越长,这些内存堆积在一个ThreadCache中如果不去使用那么其实就是一种浪费,因此我们应该将这些内存还给CentralCache。这样一来,这些内存对其他线程来说也是可申请的,因此当ThreadCache某个桶当中的自由链表太长时我们应该做更多处理。
于是我们在原来的基础上加入下面的判断:
inline void _FreeListTooLong(FreeList& list, size_t size)
{
//我们从_FreeList中抽回MaxSize,返还给CentralCache
void* start = nullptr;
list.pop_range(start,list.MaxSize());
CentralCache::GetInstance().ReleaseListToSpans(start, size);
}
void ThreadCache::deallocate(void* ptr, size_t size)
{
assert(ptr);
assert(size <= MAXSIZE);
// 找对映射的自由链表桶,对象插入进入
size_t index = SizeTable::Index(size);
_freelists[index].push(ptr);
if (_freelists[index].size() > _freelists[index].MaxSize())
{
//_FreeList过长了
_FreeListTooLong(_freelists[index],size);
}
}这里我们选择认为,当该空闲链表的内存块数量大于该链表可以向CentralCache申请的数量时,我们就执行_FreeListTooLong的逻辑归还
因为空闲链ReleaseListToSpans表用到内存块数量,这里我们就得对之前的FreeList类进行一些改造以适应需求
class FreeList
{
public:
void push(void* obj)
{
// ...
++_size;
}
void push_range(void* start, void* end,size_t n)
{
// ...
_size += n;
}
void* pop() //头删
{
// ...
--_size;
return obj;
}
// ...
size_t size()
{
return _size;
}
void pop_range(void*& start,size_t n)
{
assert(n <= _size);
start = _FreeList;
void* end = start;
for (int i = 0; i < n - 1; i++)
{
end = *(void**)end;
}
_FreeList = *(void**)end;
*(void**)end = nullptr;
_size-=n;
}
private:
// ...
size_t _size = 0;
};
因为这里我们改动了push_range接口,那么当时ThreadCache从CentralCache获取了actual_num个对象,剩下的actual_num-1个挂到了ThreadCache对应的桶当中的代码也会随之修改
_freelists[index].push_range(*(void**)start, end,actual_num-1);6.2 CentralCache回收内存
ReleaseListToSpans
void CentralCache::ReleaseListToSpans(void* start, size_t size)
{
//先找到派发出_FreeList的span类
//该过程中会改动span类需要加锁
size_t index = SizeTable::Index(size);
_spanlists[index]._mtx.lock();
while (start)
{
void* next = *(void**)start;
Span* span=PageCache::GetInstance().MapObjToSpan(start);
*(void**)start = span->_freeList;
span->_freeList = start;
span->_used--;
if (span->_used == 0)
{
_spanlists->erase(span);
span->_next = nullptr;
span->_prv = nullptr;
span->_freeList = nullptr;
_spanlists[index]._mtx.unlock();
PageCache::GetInstance()._pagemtx.lock();
PageCache::GetInstance().ReleaseSpanToPageCache(span);
PageCache::GetInstance()._pagemtx.unlock();
_spanlists[index]._mtx.lock();
}
start = next;
}
_spanlists[index]._mtx.unlock();
}- SizeTable::Index(size):根据对象大小确定在大小表中的索引,用于找到对应的 span 列表。
- 锁操作:在对 span 列表进行操作时,先对其加锁 _mtx,以确保线程安全。
- 遍历释放对象:通过循环遍历释放对象,首先获取下一个对象的指针 next,然后根据对象的地址找到其对应的 span,将当前对象插入到 span 的空闲列表 _freeList 中,并更新 span 的使用计数 _used。
- 判断 span 是否完全空闲:如果 span 的使用计数 _used 减为 0,表示这个 span 分配出去的对象全部都已经回收回来了。在这种情况下,需要将该 span 从 span 列表 _spanlists[index] 中移除,并将其自身的指针 _next、_prev、_freeList 置空。
- 回收 span:一旦确定要回收 span,就需要将其释放回页缓存(PageCache)中。这一步涉及到了两个锁的操作,首先释放 span 需要持有 _pagemtx 锁,以确保对页缓存的操作线程安全;同时,也需要确保释放 span 的过程是原子的,因此在释放前后都需要释放掉 _spanlists[index]._mtx 锁。
MapObjToSpan
通过内存块地址怎么找到原先的Sapn
在实现ReleaseListToSpans时,我们是默认通过MapObjToSpan()实现从内存块地址找到Span。
首先我们必须理解的是,某个页当中的所有地址除以页的大小都等该页的页号。比如我们这里假设一页的大小是100,那么地址0~99都属于第0页,它们除以100都等于0,而地址100~199都属于第1页,它们除以100都等于1。
虽然我们现在可以通过对象的地址得到其所在的页号,但是我们还是不能知道这个对象到底属于哪一个span。因为一个span管理的可能是多个页。为了解决这个问题,我们可以建立页号和span之间的映射。这里可以用C++当中的unordered_map进行实现,并且添加一个函数接口,用于让central cache获取这里的映射关系。
class PageCache
{
public:
// ...
Span* MapObjToSpan(void* obj);
private:
// ...
std::unordered_map<PAGEID,Span*> _IdToSpan;
};Span* PageCache::MapObjToSpan(void* obj)
{
PAGEID id = ((PAGEID)obj >> PAGESHIFT);
std::unique_lock<std::mutex> lock(_pagemtx);
auto ret = _IdToSpan.find(id);
if (ret != _IdToSpan.end())
{
return ret->second;
}
else
{
assert(false);
return nullptr;
}
}建立映射关系
在 PageCache 类中,当分配 Span 给 CentralCache 时,需要记录下分配的 span 的页号和 span 之间的映射关系。因此,在 NewSpan 函数中,分配完 Span 后,我们会遍历该 Span 的所有页,将每个页号与该 Span 建立映射关系。
Span* PageCache::NewSpan(size_t k)
{
if (!_Spanlists[k].empty())
{
Span* kspan = _Spanlists[k].pop_front();
for (PAGEID i = 0; i < kspan->_n; i++)
{
_IdToSpan[kspan->_pageId + i] = kspan;
}
return kspan;
}
for (size_t n = k + 1; n < NPAGES; n++)
{
if (!_Spanlists[n].empty())
{
Span* nspan = _Spanlists[n].pop_front();
Span* kspan = new Span;
kspan->_pageId = nspan->_pageId;
kspan->_n = k;
nspan->_pageId += k;
nspan->_n -= k;
_Spanlists[nspan->_n].push_front(nspan);
for (PAGEID i = 0; i < kspan->_n; i++)
{
_IdToSpan[kspan->_pageId + i] = kspan;
}
return kspan;
}
}
Span* maxspan = new Span;
void* ptr = SystemAlloc(NPAGES - 1);
maxspan->_pageId = (PAGEID)ptr >> PAGESHIFT;
maxspan->_n = NPAGES - 1;
_Spanlists[maxspan->_n].push_front(maxspan);
return NewSpan(k);
}6.3 PageCache回收内存
Page Cache 回收内存的过程是为了释放已经被 Central Cache 使用过的 Span,并尝试将这些 Span 与其他空闲的 Span 进行合并,从而缓解内存碎片问题。
这个过程涉及以下几个关键步骤:
判断 Span 是否可以合并: 首先,需要判断回收的 Span 周围是否有空闲的 Span 可以合并。这包括向前合并和向后合并两种情况。如果回收的 Span 的前后页号对应的 Span 存在且未被使用,则可以进行合并。
向前合并和向后合并: 如果条件允许,就可以进行向前和向后的合并操作。向前合并就是将回收的 Span 与前一个未使用的 Span 进行合并,向后合并则是将回收的 Span 与后一个未使用的 Span 进行合并。合并的过程包括更新 Span 的起始页号和页数,并从 Page Cache 的对应双链表中移除被合并的 Span。
建立映射关系: 在合并结束后,需要重新建立 Span 的页号与 Span 之间的映射关系,以便后续操作能够快速定位到对应的 Span。这包括更新合并后 Span 的首尾页号与 Span 之间的映射关系,并将合并后的 Span 挂到对应的双链表中。
更新 Span 的状态: 最后,需要将合并后的 Span 标记为未被使用的状态,以便之后的分配过程能够正确识别并使用这些 Span。
通过以上步骤,Page Cache 在回收内存时不仅释放了被使用过的 Span,还尝试将空闲的 Span 进行合并,以优化内存的利用效率,并且通过建立映射关系,确保后续操作能够快速定位到对应的 Span,提高了内存回收的效率和性能。
如何判断Span是否正在使用
由于PageCache回收内存的步骤中涉及到了Span内存块的合并,在这一过程中判断Span内存块是否正在使用将很重要。但是我们不能通过Span结构当中的_used成员,来判断某个Span到底是在CentralCache还是在PageCache。因为当CentralCache刚向PageCache申请到一个Span时,这个span的_used就是等于0的,这时可能当我们正在对该Span进行切分的时候,PageCache就把这个Span拿去进行合并了。
为了避免这些问题,我们直接在最初就给Span类中新增一个成员变量用来标记这个Span内存块是否正在使用的过程中。
struct Span
{
// ...
bool _isused = false;
};因此当central cache向page cache申请到一个span时,需要立即将该span的_isUse改为true。
span->_isused = true;而当central cache将某个span还给page cache时,也就需要将该span的_isUse改成false。
span->_isused = false;ReleaseSpanToPageCache
void PageCache::ReleaseSpanToPageCache(Span* span)
{
//先判断销毁的span类型是不是大于能维护的最大值
if (span->_n>NPAGES-1)
{
//直接调用系统接口销毁
void* ptr = (void*)(span->_pageId<<PAGESHIFT);
SystemFree(ptr);
_Spanpool.Delete(span);
return;
}
// 对span前后的页,尝试进行合并,缓解内存碎片问题
while (1)
{
PAGEID prvid = span->_pageId - 1;
Span* prvit = (Span*)_IdToSpan.get(prvid);
if (prvit == nullptr|| prvit->_isused == true||(prvit->_n+span->_n)>NPAGES-1) //前页不在或在使用或合成后超过最大值
{
break;
}
span->_pageId = prvit->_pageId;
span->_n += prvit->_n;
_Spanlists[prvit->_n].erase(prvit);
_Spanpool.Delete(prvit);
}
while (1)
{
PAGEID nxtid = span->_pageId +span->_n;
Span* nxtit = (Span*)_IdToSpan.get(nxtid);
if (nxtit == nullptr || nxtit->_isused == true || (nxtit->_n + span->_n) > NPAGES - 1) //后页不在或在使用或合成后超过最大值
{
break;
}
span->_pageId = nxtit->_pageId;
span->_n += nxtit->_n;
_Spanlists[nxtit->_n].erase(nxtit);
_Spanpool.Delete(nxtit);
}
_Spanlists[span->_n].push_front(span);
span->_isused = false;
//此时从span->_pageId到span->_pageId + span->_n - 1页的所有Id在_IdToSpan的映射关系还没有更新,但没必要现在更新,在newspan时,会覆盖原来的更新
//现在更新头尾是防止出现合成后再被别的span合成的情况(兼容我们的前后页合并接口)
_IdToSpan.set(span->_pageId,span);
_IdToSpan.set(span->_pageId + span->_n - 1, span);
}
处理大于最大值的 Span: 首先,函数检查传入的 Span 的页数是否大于 NPAGES - 1,如果是的话,说明这个 Span 超过了系统能维护的最大值,那么就直接调用系统接口销毁内存,并释放 Span 对象的内存,然后返回。这个操作是为了防止系统无法管理过大的 Span 而造成的问题。
合并相邻的 Span: 接下来,函数尝试对传入的 Span 的前后页进行合并操作,从而缓解内存碎片问题。首先,通过循环向前查找前一个 Span 是否可以合并,如果找到了合适的 Span,就进行合并操作,并在合并后将该 Span 从对应的 SpanList 中删除,并释放其内存。然后,再通过循环向后查找后一个 Span 是否可以合并,同样找到合适的 Span 后进行合并操作,并释放其内存。
更新数据结构: 在合并结束后,将合并后的 Span 插入到对应的 SpanList 中,并将其标记为未使用。然后,更新 Span 的页号与 Span 之间的映射关系,以便后续操作能够快速定位到对应的 Span。
在合并 page cache 中的 span 时,需要通过页号找到对应的 span。与 central cache 不同的是,page cache 中的 span 需要建立页号与 span 之间的映射关系。在 page cache 中,只需建立一个 span 的首尾页号与该 span 之间的映射关系即可。因为在进行合并时,只需要通过一个 span 的尾页或首页找到这个 span,无需建立每个页与 span 的映射关系。
当申请 k 页的 span 时,如果将 n 页的 span 切割为一个 k 页的 span 和一个 n-k 页的 span,除了需要建立 k 页 span 中每个页与该 span 之间的映射关系外,还需要建立剩余的 n-k 页 span 的首尾页号与其间的映射关系。
Span* PageCache::NewSpan(size_t k)
{
// ...
for (size_t n = k + 1; n < NPAGES; n++)
{
if (!_Spanlists[n].empty())
{
// ...
/*nspan->_pageId += k;
nspan->_n -= k;*/
// 存储nSpan的首位页号跟nSpan映射,方便page cache回收内存时
// 进行的合并查找
_IdToSpan[nspan->_pageId] = nspan;
_IdToSpan[nspan->_pageId + nspan->_n - 1] = nspan;
/*_Spanlists[nspan->_n].push_front(nspan);
for (PAGEID i = 0; i < kspan->_n; i++)
{
_IdToSpan[kspan->_pageId + i] = kspan;
}
return kspan;*/
}
}
// ...
}回收内存测试
void MultiThreadAlloc1()
{
std::vector<void*> v;
for (size_t i = 0; i < 1000; ++i)
{
void* ptr = ConcurrentAlloc(6);
v.push_back(ptr);
}
for (auto e : v)
{
ConcurrentFree(e, 6);
}
}
void MultiThreadAlloc2()
{
std::vector<void*> v;
for (size_t i = 0; i < 1000; ++i)
{
void* ptr = ConcurrentAlloc(16);
v.push_back(ptr);
}
for (auto e : v)
{
ConcurrentFree(e, 16);
}
}
void MultiThreadAlloc3()
{
std::vector<void*> v;
for (size_t i = 0; i < 1000; ++i)
{
void* ptr = ConcurrentAlloc(256);
v.push_back(ptr);
}
for (auto e : v)
{
ConcurrentFree(e, 256);
}
}
void MultiThreadAlloc4()
{
std::vector<void*> v;
for (size_t i = 0; i < 1000; ++i)
{
void* ptr = ConcurrentAlloc(2048);
v.push_back(ptr);
}
for (auto e : v)
{
ConcurrentFree(e, 2048);
}
}
void MultiThreadAlloc5()
{
std::vector<void*> v;
for (size_t i = 0; i < 1000; ++i)
{
void* ptr = ConcurrentAlloc(66*1024);
v.push_back(ptr);
}
for (auto e : v)
{
ConcurrentFree(e, 66 * 1024);
}
}
void TestMultiThread()
{
std::thread t1(MultiThreadAlloc1);
std::thread t2(MultiThreadAlloc2);
std::thread t3(MultiThreadAlloc3);
std::thread t4(MultiThreadAlloc4);
std::thread t5(MultiThreadAlloc5);
t1.join();
t2.join();
t3.join();
t4.join();
t5.join();
}
int main()
{
//TLSTest();
//TestAlloc();
TestMultiThread();
return 0;
}这里我们简单的跑一下程序,看一下是否能稳定运行 。
7.解决大内存申请释放
7.1 申请内存
这里我们用梳理一下之前的内存申请方式, ThreadCache是用于申请小于等于256KB的内存的,而对于大于256KB的内存,我们可以考虑直接向PageCache申请,但PageCache中最大的页也就只有128页,所以我们现在还无法实现大于128页内存的申请释放 。于是我们现在选择把大于128页的内存直接向堆上申请释放来解决这个问题。
当申请的内存大于256KB时,虽然不是从ThreadCache进行获取,但在分配内存时也是需要按页为单位向上对齐的。
RoundUp
class SizeTable
{
public:
static size_t RoundUp(size_t bytes)
{
// ...
else if (bytes <= 256 * 1024)
{
// return _RoundUp(bytes, 8 * 1024);
}
else
{
return _RoundUp(bytes, 1 << PAGESHIFT);
}
};ConcurrentAlloc
我们最初申请内存时的逻辑也会随之改变,我们就不选择走向ThreadCache申请内存的流程,直接判断完后调用Newspan接口申请页。
static void* ConcurrentAlloc(size_t size)
{
if (size > MAXSIZE)
{
//超过256KB的内存,ThreadCache中已经放不下了,直接申请Span来用
size_t align_size = SizeTable::RoundUp(size);
size_t kpage = align_size >> PAGESHIFT; //计算一共要去PageCache中去拿k页Span
PageCache::GetInstance()._pagemtx.lock();
Span* span = PageCache::GetInstance().NewSpan(kpage);
PageCache::GetInstance()._pagemtx.unlock();
return (void*)(span->_pageId << PAGESHIFT);
}
// ...
}NewSpan
我们在这里实现超过128页内存的申请,并且对申请的span类建立头指针的映射关系,这样便于后续销毁工作。
Span* PageCache::NewSpan(size_t k)
{
if (k > NPAGES - 1)
{
//此时申请的内存大于了1024*1024 bytes ,即1M ,超过PageCache维护的最大限制,此时我们直接去堆上申请内存
void* ptr = SystemAlloc(k);
Span* kspan = new Span;
kspan->_n = k;
kspan->_pageId = (PAGEID)ptr >> PAGESHIFT;
//对申请的span类建立头指针的映射关系,便于后续销毁工作
_IdToSpan[kspan->_pageId] = kspan;
return kspan;
}
// ...
}7.2 释放内存
我们释放的流程总结如下:
| 释放内存的大小 | 释放方式 |
|---|---|
| x ≤ 256KB (32页) | 释放给 thread cache |
| 32页 < x ≤ 128页 | 释放给 page cache |
| x ≥ 128页 | 释放给堆 |
ConcurrentFree
因此当释放对象时,我们需要先找到该对象对应的span,但是在释放对象时我们只知道该对象的起始地址。但是我们是给申请到的内存建立了span结构,并建立起始页号与该span之间的映射关系的原因。此时我们就可以通过释放对象的起始地址计算出起始页号,进而通过页号找到该对象对应的span。
static void ConcurrentFree(void* ptr, size_t size)
{
if (size > MAXSIZE)
{
Span* span = PageCache::GetInstance().MapObjToSpan(ptr);
//超过256KB的内存,ThreadCache中无法维护,都是以Span类型储存并维护
PageCache::GetInstance()._pagemtx.lock();
PageCache::GetInstance().ReleaseSpanToPageCache(span);
PageCache::GetInstance()._pagemtx.unlock();
}
else
{
assert(pTLSThreadCache);
pTLSThreadCache->deallocate(ptr, size);
}
}ReleaseSpanToPageCache
因此Page Cache在回收Span时也需要进行判断,如果该span的大小是大于128页的,那么说明该span是直接向堆申请的,我们直接将这块内存释放给堆,然后将这个span结构进行delete就行了。
void PageCache::ReleaseSpanToPageCache(Span* span)
{
if (span->_n > NPAGES - 1)
{
void* ptr = (void*)(span->_pageId << PAGESHIFT);
SystemFree(ptr);
delete span;
return;
}
// ...
}大内存测试
void BigAlloc()
{
void* p1 = ConcurrentAlloc(257 * 1024);
ConcurrentFree(p1, 257 * 1024);
void* p2 = ConcurrentAlloc(129 * 8 * 1024);
ConcurrentFree(p2, 129 * 8 * 1024);
}
int main()
{
//TLSTest();
//TestAlloc();
//TestMultiThread();
BigAlloc();
return 0;
}![]()







![[动态规划]---part2](https://img-blog.csdnimg.cn/direct/1e899192b9a44cba86211439e4b9ecaa.png)