文章目录
- P57-P60:序列化模块
- Varint(编码)
- Zigzag(压缩)
- class ByteArray
- Node(链表结构)
- 成员变量
- 构造函数
- 写入
- 读取
- setPosition
- addCapacity
- 测试
P57-P60:序列化模块
序列化模块通常用于将数据转换为可以在网络上传输的格式,或者将接收到的网络数据反序列化为程序内部可用的格式。这个模块可以帮助简化网络通信的数据处理过程,提高服务器的性能和可维护性。
sylar设计的的序列化模块底层使用链表的形式存储数据,这样可以节省内存,管理内存碎片。该模块支持所有基本类型数据的写入和读取,可以选择固定字节长度或可变字节长度写入,使用可变字节长度时,使用Zigzag将有符号整型压缩后再进行Varint编码,这样能够节省大量内存空间。再写入数据时,将数据写入链表的最后一个节点中,若写不下时,创建新的节点继续写入数据。
Varint(编码)
Varint是一种使用一个或多个字节序列化整数的方法,会把整数编码为变长字节。对于32位整型数据经过Varint编码后需要10个字节。在实际场景中小数字的使用率远远多于大数字,因此通过Varint编码对于大部分场景都可以起到很好的压缩效果。
Varint 的编码规则如下:
- 对于一个整数,用 7 位来存储整数的数值,最高位用来表示是否还有后续字节,1 表示还有,0 表示结束。
- 如果整数的数值小于 128,那么只需要一个字节就可以存储,直接将整数的数值存储在最低的 7 位中,最高位为 0。
- 如果整数的数值大于等于 128,那么需要多个字节来存储,每个字节的最高位都为 1,其余 7 位用来存储整数的数值。除了最后一个字节,其他字节的最高位为 1,表示还有后续字节。
举个例子
- 整数300 --二进制–> 100101100
- 从最低位(右边开始)按7位分组 10 0101100
- 第一个字节:10101100
- 第二个字节:0000010
- 结果:0xAC 0x02
实现代码
void EncodeVarint(uint32_t value) {
// 32位的数据类型最多需要5个字节,如果是64位则需要10个字节
uint8_t temp[5];
uint8_t i = 0;
while(value > 127) {
// 取低7位保持不变 将最高位设置为1,表示后续还有字节
temp[i++] = (value & 0x7f) | 0x80;
// 右移7位
value >>= 7;
}
// 存储最后一个小于127的剩余值
temp[i] = value;
write(tmp, i);
}
(value & 0x7f):取低7位保持不变
| 0x80:将最高位设置为1,表示后续还有字节
// value & 0x7f
10101101 (173)
& 01111111 (0x7f)
-----------
00101101
// | 0x80
00101101
| 10000000 (0x80)
-----------
10101101
Zigzag(压缩)
Zigzag算法将有符号负整数转为正数,这样能够节省字节,因为负数的二进制位几乎全为1。
Zigzag编码将正数映射到偶数,负数映射到奇数。这种映射的目的是为了利用无符号整数的变长编码特性,使得负数和正数都能够通过相同的编码方式进行存储和传输。
编码
static uint64_t EncodeZigzag64(const uint64_t& v) {
if(v < 0) {
return ((uint64_t)(-v)) * 2 - 1;
} else {
return v * 2;
}
}
解码
static int64_t DecodeZigzag64(const uint64_t& v) {
return (v >> 1) ^ -(v & 1);
}
class ByteArray
Node(链表结构)
所有的数据都存在这个链表结构中,在堆区开辟内存存储在ptr中;size为一个节点大小,一般设置为一个页面大小4KB;next指向下一个节点。
struct Node {
Node(size_t s);
Node();
~Node();
char* ptr;
Node* next;
size_t size;
};
成员变量
// 内存块的大小
size_t m_baseSize;
// 当前操作的位置
size_t m_position;
// 总容量
size_t m_capacity;
// 当前数据的大小
size_t m_size;
// 字节序,默认大端
int8_t m_endian;
// 当一个内存块指针
Node* m_root;
// 当前操作的内存块指针
Node* m_cur;
构造函数
ByteArray::ByteArray(size_t base_size)
: m_baseSize(base_size)
, m_position(0)
, m_capacity(base_size)
, m_size(0)
, m_endian(SYLAR_BIG_ENDIAN)
, m_root(new Node(base_size))
, m_cur(m_root) {
}
写入
在一个ByteArray对象中,数据都是存储在独立的节点中,当一个节点存满时让指针指向下一个节点继续存储需要写入的数据。所以写入数据我们只需要知道
- 写入数据大小
- 当前节点中剩余可写入的容量
void ByteArray::write(const void* buf, size_t size) {
// 如果写入数据为0,直接返回
if(size == 0) {
return;
}
// 根据传入的size设置写入这些数据需要的容量
addCapacity(size);
// 记录当前节点已经写入的大小
size_t npos = m_position % m_baseSize;
// 计算当前节点剩余的可写入空间大小。
size_t ncap = m_cur->size - npos;
// 记录当前要写入数据的偏移量
size_t bpos = 0;
// 只要还有数据待写入
while(size > 0) {
// 剩余容量足够
if(ncap >= size) {
// 将要写入的数据拷贝到当前节点中的缓冲区中。
memcpy(m_cur->ptr + npos, (const char*)buf + bpos, size);
// 如果当前节点已经写满了(当前节点的偏移量加上写入的数据大小等于当前节点的容量大小)
if(m_cur->size == (npos + size)) {
// 移向下一个节点
m_cur = m_cur->next;
}
// 更新当前位置
m_position += size;
// 更新缓冲区的偏移量
bpos += size;
// 将剩余要写入的数据大小置为0,表示所有数据已经写入完毕
size = 0;
// 如果当前节点剩余的可写入空间小于要写入的数据大小
} else {
// 将当前节点剩余的可写入空间大小的数据拷贝到当前节点的缓冲区中
memcpy(m_cur->ptr + npos, (const char*)buf + bpos, ncap);
// 更新当前位置
m_position += ncap;
// 更新缓冲区的偏移量
bpos += ncap;
// 更新剩余要写入的数据大小
size -= ncap;
// 当前节点已经满了,移动到下一个节点
m_cur = m_cur->next;
// 更新当前节点剩余的可写入空间大小
ncap = m_cur->size;
// 新的起点,起始为0
npos = 0;
}
}
// 更新 ByteArray 对象的大小 m_size,如果当前位置大于原来的大小,则更新为当前位置
if(m_position > m_size) {
m_size = m_position;
}
}
举个例子
假设我们要往一个ByteArray对象中写入下列数据
void* buf = "Hello,World!";
size_t size = 12;
- 首先判断写入数据不为空
- 调用
addCapacity函数确保对象有足够的容量存储要写入的数据 - 假设当前节点还未写入过数据,那么几个变量如下
- npos = 0
- ncap = 8 (假设一个节点8字节,意思我这个节点还可以写入8字节的数据)
- bpos = 0,记录当前写入数据的偏移量,我们要写入的数据是存放在缓冲区中,它的作用就是告诉我们从缓冲区哪里开始把数据拿出来,一开始肯定从头开始读,所以初始化为0
- ncap = 0 < size = 12,所以进入else分支,因为一个节点只有8个字节容量,我们要写入的数据有12字节
- 从buf中获得8个字节的数据,更新当前节点中最后写入的位置
m_position + 8,缓冲区的偏移量bpos + 8,剩余要写入的数据为12 - 8 = 4,(已写入[Hello,Wo]) - 当前节点已经满了,移动下一个节点,更新ncap剩余写入空间为8,新的写入起点npos = 0
- 然后才是进入if分支,把剩余的4个字节写入([rld!]),跳出循环
- 检查当前位置是否大于
m_size,显然是,因为当前位置为12,而原来的m_size为0,所以更新m_size为12。这个m_size就是整个Bytearray对象含有数据的总大小。
读取
上面写入看懂了,读取也是差不多的。
两个read版本的区别在于读取完毕后是否改变m_position的值,比如第一个read,如果当前位置在第3个节点,读完后可能就在第5个节点了,而第二个read就不会改变。
会改变m_position
void ByteArray::read(void* buf, size_t size) {
// size是我们想要读取的数据长度,getReadSize()返回m_size - m_position,也就是在当期操作位置后面还有多少数据能读
// 如果要读的数据长度已经超出了ByteArray对象剩余可读的数据长度,抛出错误
if(size > getReadSize()) {
throw std::out_of_range("not enough len");
}
// 获取当前节点的位置,m_position是一直累加的,所以要对每一个节点的大小取余才能获取在当前节点中的位置
size_t npos = m_position % m_baseSize;
// 剩余可读容量
size_t ncap = m_cur->size - npos;
// buf偏移量
size_t bpos = 0;
while(size > 0) {
// 该节点剩余的位置比要读的数据多
if(ncap >= size) {
// 将剩余的数据都读到buf中
memcpy((char*)buf + bpos, m_cur->ptr + npos, size);
// 若正好读完这个节点,则跳到下一个节点,不做这一步也可以,下一次再读可以在else分支里面跳
if(m_cur->size == (npos + size)) {
m_cur = m_cur->next;
}
m_position += size;
bpos += size;
size = 0;
// 该节点不够读的
} else {
// 有多少就读多少
memcpy((char*)buf + bpos, m_cur->ptr + npos, ncap);
m_position += ncap;
bpos += ncap;
size -= ncap;
m_cur = m_cur->next;
ncap = m_cur->size;
npos = 0;
}
}
}
不改变m_position
void ByteArray::read(void* buf, size_t size, size_t position) const{
if(size > getReadSize()) {
throw std::out_of_range("not enough len");
}
size_t npos = position % m_baseSize;
size_t ncap = m_cur->size - npos;
size_t bpos = 0;
Node* cur = m_cur;
while(size > 0) {
if(ncap >= size) {
memcpy((char*)buf + bpos, cur->ptr + npos, size);
if(cur->size == (npos + size)) {
cur = cur->next;
}
position += size;
bpos += size;
size = 0;
} else {
memcpy((char*)buf + bpos, cur->ptr + npos, ncap);
position += ncap;
bpos += ncap;
size -= ncap;
cur = cur->next;
ncap = cur->size;
npos = 0;
}
}
}
setPosition
void ByteArray::setPosition(size_t v) {
// 如果超出总大小,抛出异常
if(v > m_size) {
throw std::out_of_range("set_position out of range");
}
// 更新当前操作位置
m_position = v;
// 链表遍历到当前位置
m_cur = m_root;
while(v >= m_cur->size) {
v -= m_cur->size;
m_cur = m_cur->next;
}
// 如果在循环中找到了指定位置 v 的节点,并且指定位置 v 恰好等于当前节点的大小,
// 则表示指定位置 v 在当前节点的末尾,需要将当前节点指针移动到下一个节点。
if(v == m_cur->size) {
m_cur = m_cur->next;
}
}
addCapacity
void ByteArray::addCapacity(size_t size) {
if(size == 0) {
return;
}
// 剩余容量
size_t old_cap = getCapacity();
// 如果剩余容量足够则不需要增加
if(old_cap >= size) {
return;
}
// 需要扩充的数据大小
size = size - old_cap;
// 根据数据大小求得需要增加的节点大小
size_t count = (size / m_baseSize) + (((size % m_baseSize) > old_cap) ? 1 : 0);
// 遍历链表到末尾
Node* tmp = m_root;
while(tmp->next) {
tmp = tmp->next;
}
// 第一个扩展的节点
Node* first = NULL;
for(size_t i = 0; i < count; ++ i) {
tmp->next = new Node(m_baseSize);
if(first == NULL) {
first = tmp->next;
}
// tmp一直指向末尾
tmp = tmp->next;
// 扩大容量
m_capacity += m_baseSize;
}
// 若剩余容量为0,则跳到下一个节点,才扩展的,什么数据都没有
if(old_cap == 0) {
m_cur = first;
}
}
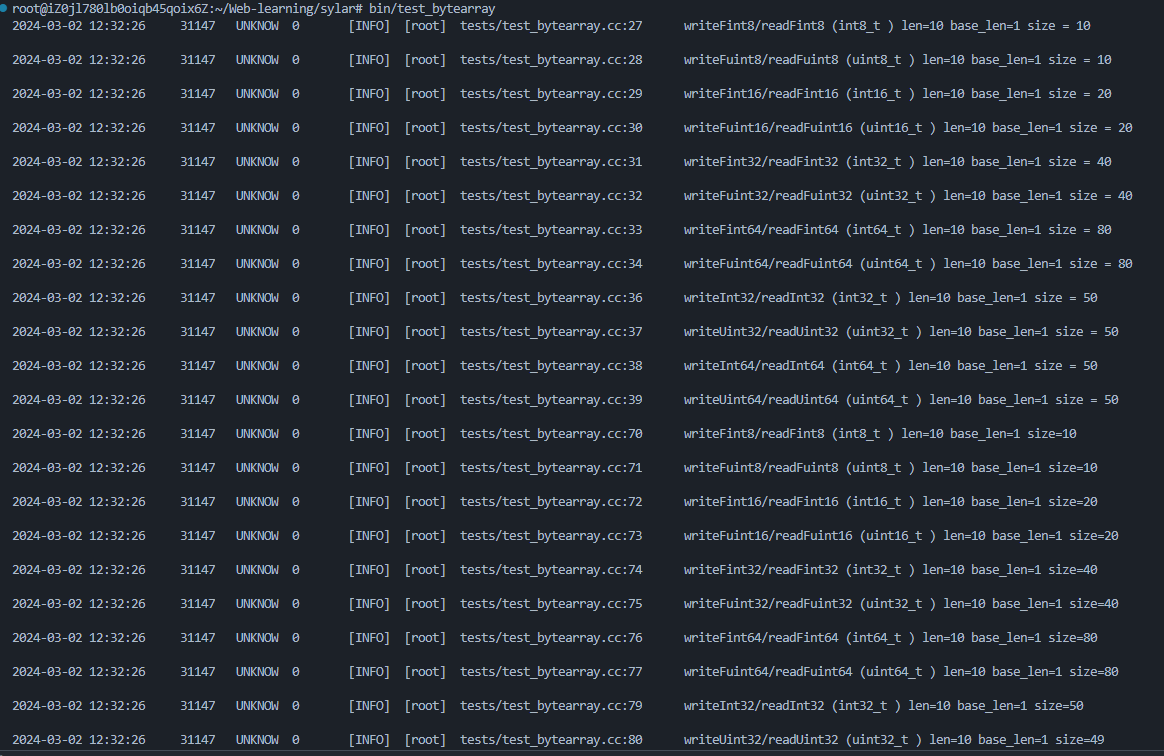
测试
代码
#include "../sylar/bytearray.h"
#include "../sylar/sylar.h"
static sylar::Logger::ptr g_logger = SYLAR_LOG_ROOT();
void test() {
#define XX(type, len, write_fun, read_fun, base_len) {\
std::vector<type> vec; \
for(int i = 0; i < len; ++i) { \
vec.push_back(rand()); \
} \
sylar::ByteArray::ptr ba(new sylar::ByteArray(base_len)); \
for(auto& i : vec) { \
ba->write_fun(i); \
} \
ba->setPosition(0); \
for(size_t i = 0; i < vec.size(); ++i) { \
type v = ba->read_fun(); \
SYLAR_ASSERT(v == vec[i]); \
} \
SYLAR_ASSERT(ba->getReadSize() == 0); \
SYLAR_LOG_INFO(g_logger) << #write_fun "/" #read_fun \
" (" #type " ) len=" << len \
<< " base_len=" << base_len \
<< " size = " << ba->getSize(); \
}
XX(int8_t, 10, writeFint8, readFint8, 1);
XX(uint8_t, 10, writeFuint8, readFuint8, 1);
XX(int16_t, 10, writeFint16, readFint16, 1);
XX(uint16_t, 10, writeFuint16, readFuint16, 1);
XX(int32_t, 10, writeFint32, readFint32, 1);
XX(uint32_t, 10, writeFuint32, readFuint32, 1);
XX(int64_t, 10, writeFint64, readFint64, 1);
XX(uint64_t, 10, writeFuint64, readFuint64, 1);
XX(int32_t, 10, writeInt32, readInt32, 1);
XX(uint32_t, 10, writeUint32, readUint32, 1);
XX(int64_t, 10, writeInt64, readInt64, 1);
XX(uint64_t, 10, writeUint64, readUint64, 1);
#undef XX
#define XX(type, len, write_fun, read_fun, base_len) {\
std::vector<type> vec; \
for(int i = 0; i < len; ++i) { \
vec.push_back(rand()); \
} \
sylar::ByteArray::ptr ba(new sylar::ByteArray(base_len)); \
for(auto& i : vec) { \
ba->write_fun(i); \
} \
ba->setPosition(0); \
for(size_t i = 0; i < vec.size(); ++i) { \
type v = ba->read_fun(); \
SYLAR_ASSERT(v == vec[i]); \
} \
SYLAR_ASSERT(ba->getReadSize() == 0); \
SYLAR_LOG_INFO(g_logger) << #write_fun "/" #read_fun \
" (" #type " ) len=" << len \
<< " base_len=" << base_len \
<< " size=" << ba->getSize(); \
ba->setPosition(0); \
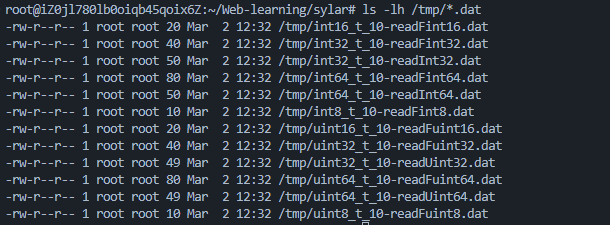
SYLAR_ASSERT(ba->writeToFile("/tmp/" #type "_" #len "-" #read_fun ".dat")); \
sylar::ByteArray::ptr ba2(new sylar::ByteArray(base_len * 2)); \
SYLAR_ASSERT(ba2->readFromFile("/tmp/" #type "_" #len "-" #read_fun ".dat")); \
ba2->setPosition(0); \
SYLAR_ASSERT(ba->toString() == ba2->toString()); \
SYLAR_ASSERT(ba->getPosition() == 0); \
SYLAR_ASSERT(ba2->getPosition() == 0); \
}
XX(int8_t, 10, writeFint8, readFint8, 1);
XX(uint8_t, 10, writeFuint8, readFuint8, 1);
XX(int16_t, 10, writeFint16, readFint16, 1);
XX(uint16_t, 10, writeFuint16, readFuint16, 1);
XX(int32_t, 10, writeFint32, readFint32, 1);
XX(uint32_t, 10, writeFuint32, readFuint32, 1);
XX(int64_t, 10, writeFint64, readFint64, 1);
XX(uint64_t, 10, writeFuint64, readFuint64, 1);
XX(int32_t, 10, writeInt32, readInt32, 1);
XX(uint32_t, 10, writeUint32, readUint32, 1);
XX(int64_t, 10, writeInt64, readInt64, 1);
XX(uint64_t, 10, writeUint64, readUint64, 1);
#undef XX
}
int main(int argc, char** argv) {
test();
return 0;
}
结果