导语
在探索LLM在解决Text-to-SQL任务中的潜能时,本文提出了一种创新的‘问题分解’Prompt格式,结合每个子问题的表列信息,实现了与顶尖微调模型(RASAT+PICARD)相媲美的性能。
- 会议:EMNLP 2023
- 链接:https://arxiv.org/abs/2305.14215
- 机构:The Ohio State University
1 引言
在探索大型语言模型(LLMs)处理文本到SQL解析任务的研究中,少数示例学习(in-context learning)的潜力引人注目。虽然这种方法在许多NLP任务上展现了出色的性能,但在文本到SQL解析上,它还有很大的提升空间。研究表明,提升LLMs在此任务上的性能关键在于增强其多步推理能力。即使是简单问题,LLMs也需要理解与数据库模式的联系,并构造正确的SQL子句。
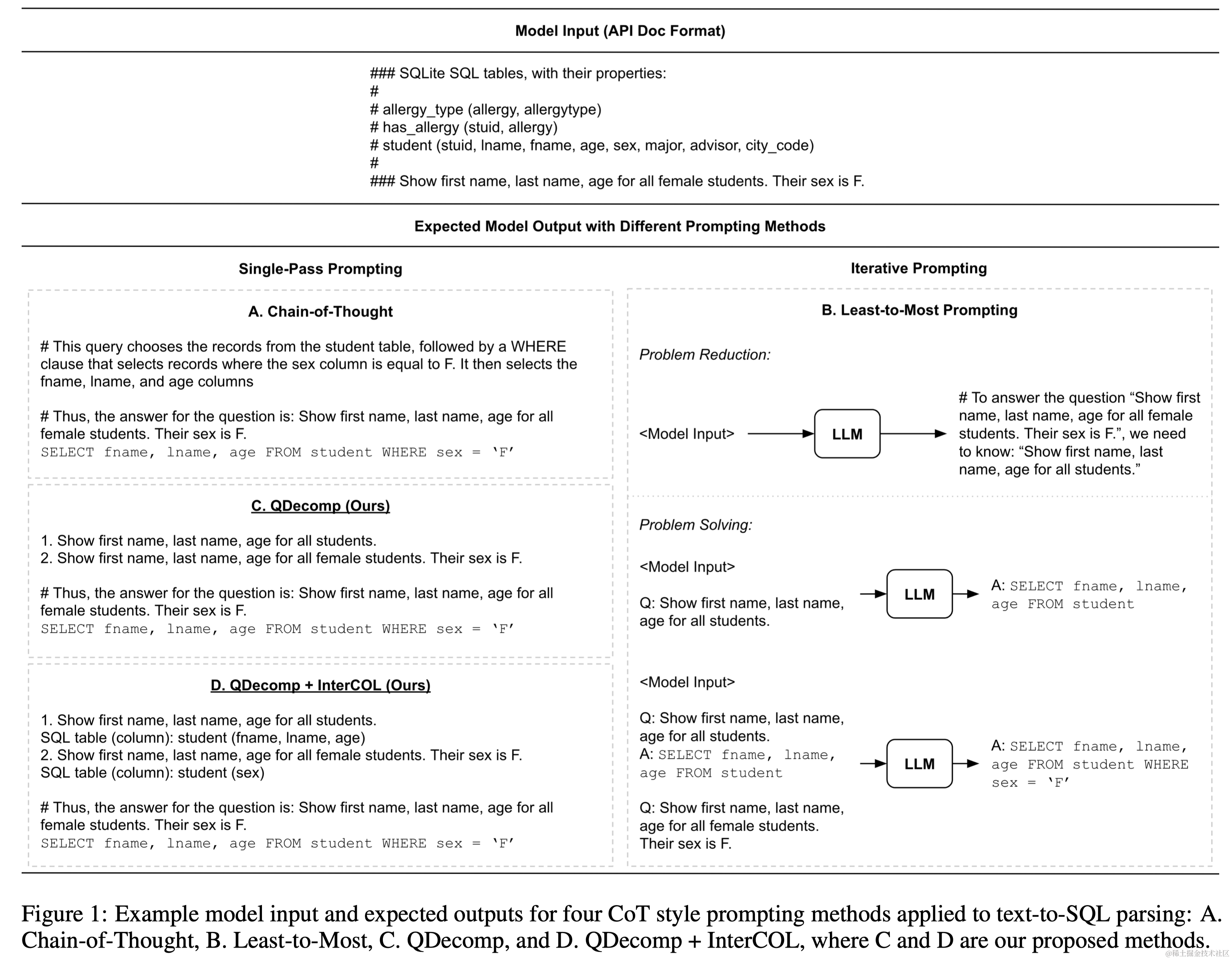
本文聚焦于如何通过思维链(CoT)风格的提示来提升LLMs的多步推理能力。作者特别探索了两种CoT风格提示方法:
- 直接提供所有推理步骤的思维链提示(Chain-of-thought prompting),
- 分阶段逐步解决问题的从简到繁提示(Least-to-most prompting)。
通过对比这两种方法,作者发现直接应用它们在文本到SQL解析中容易产生错误传播,并且从简到繁的方法在计算上更加昂贵。因此,本文提出了一种新的CoT风格提示方法:问题分解提示(QDecomp)。与思维链提示相似,QDecomp一次性生成一系列推理步骤和问题,但避免了产生中间执行步骤。作者还提出了QDecomp的一个变体(QDecomp+InterCOL),它在每个子问题中逐步引入表和列名,以帮助LLMs更好地理解数据库模式。
在Spider和Spider Realistic这两个跨领域文本到SQL数据集上的评估显示,与标准提示方法相比,QDecomp+InterCOL在Spider开发集上带来了5.2点,而在Spider Realistic集上带来了6.5点的绝对提升。这一发现表明,迭代式提示可能不是必需的,而且提供关键模式信息的较少详细的推理步骤在减少错误传播方面更有效。
2 相关工作
大型语言模型(LLMs)和思维链(CoT)风格提示在自然语言处理中显示出巨大潜力,特别是在需要多步推理的任务上。虽然LLMs在少数示例学习中表现出色,但它们在处理需要多步推理的任务,如文本到SQL解析时,仍面临挑战。为了提升LLMs在这一领域的性能,思维链提示方法被提出,通过在提示中明确描述中间推理步骤来改善LLMs的准确性。此外,从简到繁提示也被提出来解决复杂问题,它通过先生成问题的子问题列表,再逐个解决子问题来得出正确答案。然而,如何有效地将这些CoT风格提示方法应用于文本到SQL解析尚未被充分探索。
3 Prompting for Multi-Step Reasoning in Text-to-SQL、
3.1 思维链提示
思维链提示旨在通过生成一系列中间步骤来提升LLMs的推理能力,进而预测最终答案。对于文本到SQL解析,这意味着需要构建出预测SQL查询的推理步骤。本研究中,每个SQL子句都被用来构成思维链的一个推理步骤,通过自然语言模板描述每个SQL子句,并按照SQL查询的逻辑执行顺序串联起来。
3.2 从简到繁提示
与思维链提示不同,从简到繁提示通过两阶段来处理复杂问题:问题简化和问题解决。在问题简化阶段,提示LLM从原始复杂问题中生成一系列子问题。在问题解决阶段,LLM逐个处理每个子问题,逐步构建最终解决方案。通过这种方法,LLM能够专注于解析每个子问题,从而降低原始问题的复杂度。
3.3 问题分解提示
本研究提出了一种新的提示方法:问题分解提示(QDecomp)。与思维链相似,QDecomp一次性生成中间推理步骤和最终SQL查询。不同的是,QDecomp不使用SQL的逻辑执行过程,而是遵循从简到繁提示中的问题简化阶段,指导LLM将原始复杂问题分解为推理步骤。此外,还提出了QDecomp的一个变体QDecomp+InterCOL,以缓解文本到SQL解析中众所周知的表/列链接问题。在这个变体中,增加了上下文示例,提示LLM在生成每个子问题时识别任何相应的表/列名称。
除了上述提示方法外,实验中还包括标准提示方法作为基线。这种方法使用问题-SQL对作为上下文示例,直接提示LLM将自然语言问题解析为其对应的SQL查询,而不生成任何中间推理步骤。
4 实验
- 数据集
- Spider(Yu et al., 2018):
- Spider Realistic(Deng et al., 2021)
- 上下文示例选择:为了展示问题分解提示的鲁棒性,考虑了两种选择上下文示例的方式:
- 随机选择;
- 基于难度的选择,一共设计了3种选取策略:
- G1:各个难度(Easy、Medium、Hard、Extra Hard)平均选择;
- G2:Hard、Extra Hard平均选择;
- G3:只选取Extra Hard。
- 提示格式:探索了Rajkumar等人(2022)引入的两种提示格式(如下图):
- API文档格式;
- Create Table + Select 3。
- 评估指标:使用执行准确性来评估。

5 结果分析
5.1 主要结果
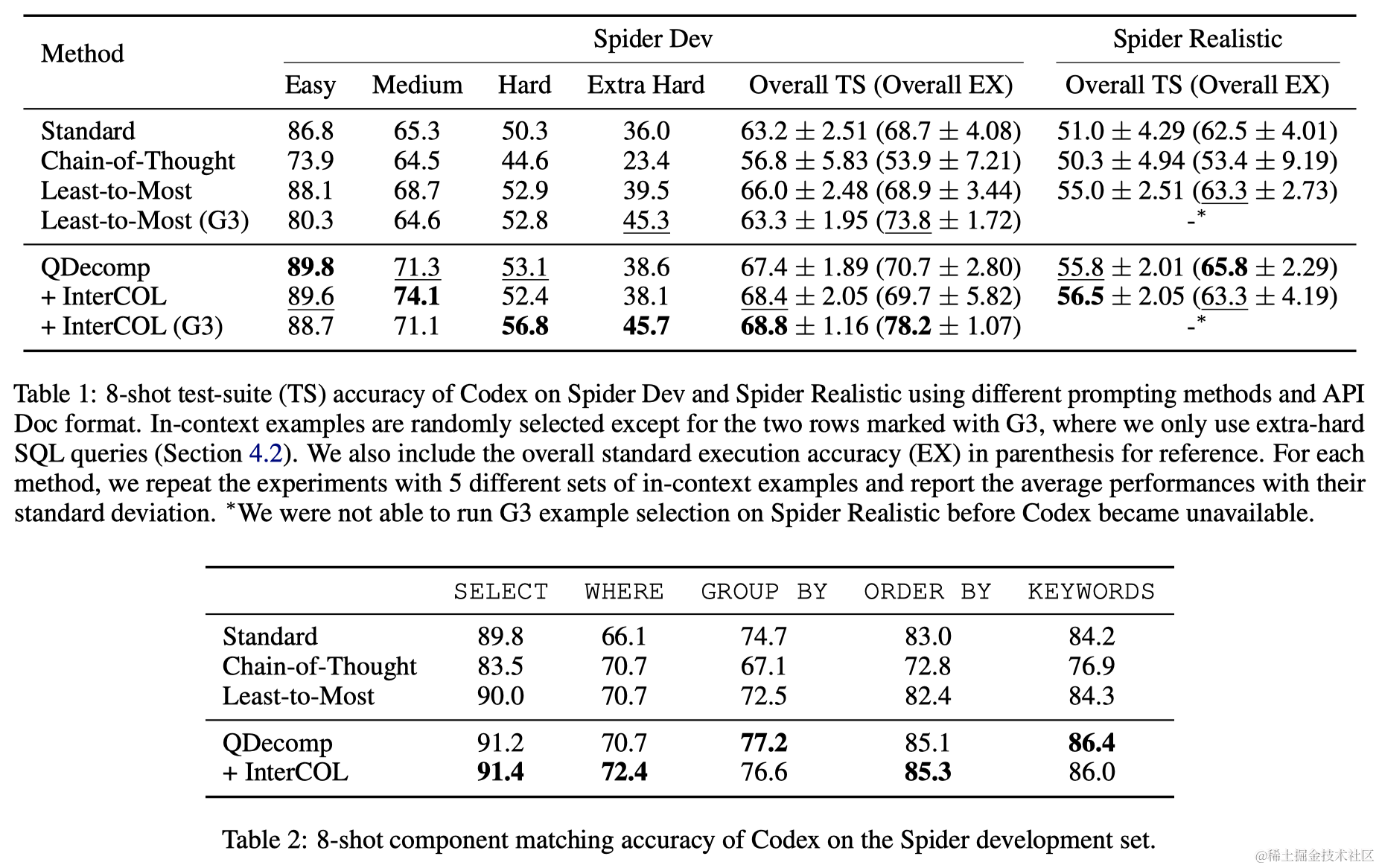
在Spider开发集和Spider Realistic上的综合实验表明,作者提出的问题分解(QDecomp)提示方法及其变体(QDecomp+InterCOL)一致地优于思维链和从简到繁提示。QDecomp+InterCOL在Spider开发集上达到68.4%的测试套件准确率,而在Spider Realistic集上达到56.5%。相比标准提示,分别带来了5.2%和6.5%的绝对增益。此外,使用极难(G3)上下文示例时,可以将QDecomp+InterCOL提示的执行准确率提高到78.2%,与强大的微调文本到SQL解析器RASAT+PICARD相当。

5.2 错误分析
对四种提示方法进行了量化错误分析,使用Spider开发集上的组件匹配准确度作为细粒度的精确匹配度量。分析显示,思维链提示由于提供了非常详细的推理步骤,导致更多的错误传播问题。QDecomp+InterCOL提示优于这两种方法,因为它不指导Codex生成详细的推理步骤或中间SQL查询。
5.3 提示设计的鲁棒性
为了验证主要实验中的结论,作者进行了额外实验,测试了所有四种提示方法的鲁棒性。实验结果表明,QDecomp+InterCOL提示在所有设置下均表现最佳,展现了其鲁棒性。然而,从简到繁提示并没有从G1或G3示例中受益,反而显示了准确度下降。


5.4 其他文本到SQL数据集上的结果
除了Spider数据集外,作者还在其他数据集上比较了QDecomp(+InterCOL)与标准和从简到繁提示,包括GeoQuery、IMDB和Yelp。实验结果显示,QDecomp(+InterCOL)在所有三个数据集上始终实现最佳性能。
6 总结和未来工作
本文系统地探讨了CoT风格提示方法,以增强LLMs在文本到SQL解析任务中的推理能力。作者设计了推理步骤,以适用于两种现有方法——思维链和从简到繁提示,并提出了新的问题分解提示方法。通过全面的实验展示了:(1) 在文本到SQL解析中,迭代式提示可能并非必要;(2) 使用详细的推理步骤(在思维链中)或中间SQL查询(在从简到繁提示中)容易出错,从而加剧了错误传播问题。
本文的问题分解提示是减轻LLMs多步推理中错误传播问题的首次尝试之一,作者强调这个问题是一个有意义的未来研究方向。例如,可以通过将本文的方法整合到交互式语义解析框架中来进一步减少中间推理步骤中的错误。由于分解后的子问题是用自然语言表述的,这种交互式方法使数据库用户能够轻松发现每个子问题中的错误。然后,他们可以通过直接编辑子问题或提供自然语言反馈与LLMs合作,这应该会进一步提高文本到SQL解析的准确性。