一、原油种类的聚类分析
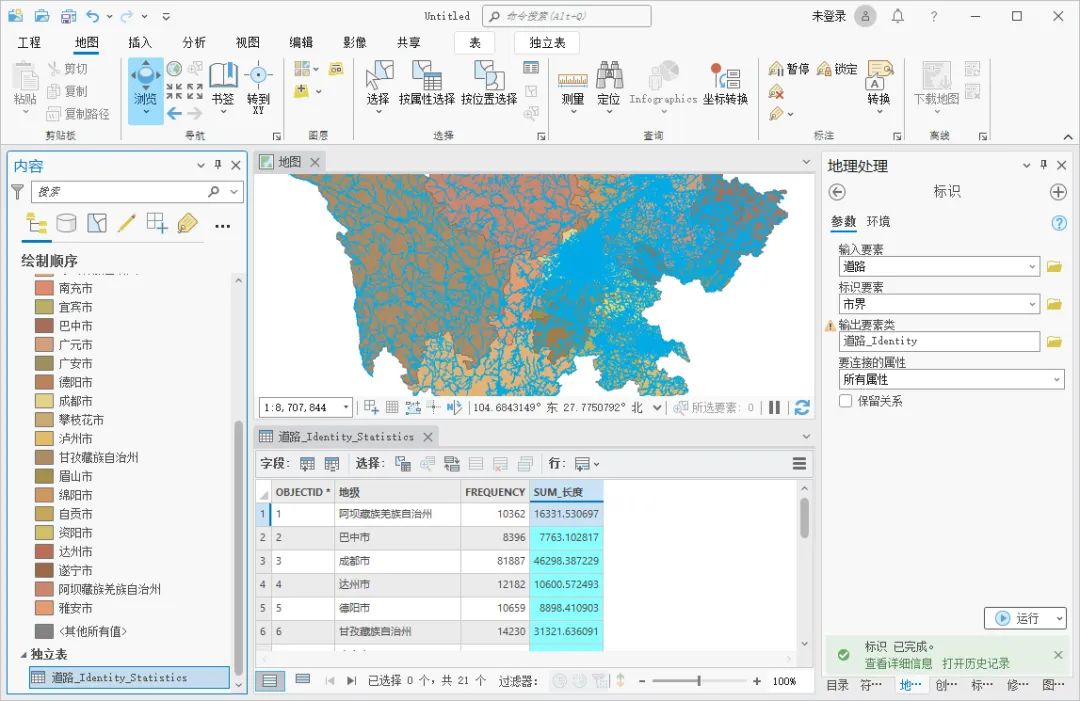
在塔里木盆地塔河油田的原油处理过程中,需要对原油进行地球化学特征研究,以了解其成因和特征。根据地球化学手段的综合研究结果,塔河油田奥陶系原油属于海相沉积环境,成熟度较高,正构烷烃分布较完整,具有UCM(Unresolved Complex Mixture)鼓包现象,25-降藿烷普遍存在,伽马蜡烷含量较低,C29藿烷丰度高,规则甾烷(αββ构型)丰度高于ααα构型。这些特征表明塔河油田的原油经历了较强的微生物降解作用,并存在至少两个期次的原油充注。
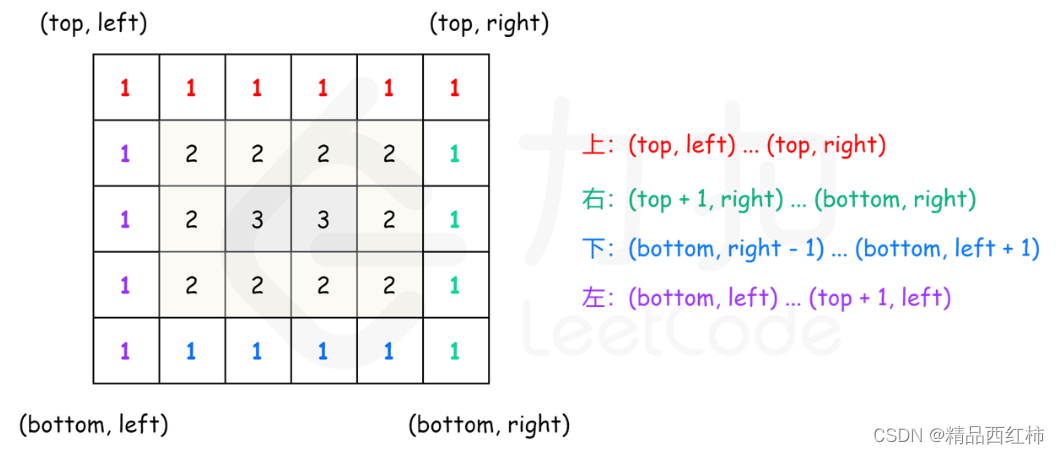
我们不妨假设将塔河油田原油划分为三类:I类原油具有多期充注特征,但主要表现出早期生物降解原油的特征,早期生物降解原油的贡献高于后期充注正常原油的贡献;II类原油可能经历过强烈的微生物降解,部分样品正构烷烃缺失,UCM鼓包明显;III类原油受热成熟度影响较大,正构烷烃热裂解导致低碳数正构烷烃相对富集,代表混合原油但正常原油的贡献较大。
首先,我们生成三个特征('三环萜烷/五环萜烷'、'Ts/17αC30藿烷'、'重排甾烷/规则甾烷')的随机数值作为原油样本数据,生成了100个样本。接着,通过导入的sklearn.cluster库中的KMeans类,创建了一个KMeans对象,并设定聚类数目为3。然后,调用fit方法对样本数据进行聚类分析。
完整代码如下:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
from sklearn.cluster import KMeans
from matplotlib.font_manager import FontProperties
# 设置字体
font = FontProperties(fname=r'C:\Users\Lenovo\PycharmProjects\allModels0119\Draw\wordcloud\fonts\msyh.ttc', size=12)
# 模拟原油样本数据
data = {
'三环萜烷/五环萜烷': np.random.uniform(0.5, 7.82, size=100),
'Ts/17αC30藿烷': np.random.uniform(0.33, 2.01, size=100),
'重排甾烷/规则甾烷': np.random.uniform(0.25, 2.11, size=100)
}
df = pd.DataFrame(data)
# 使用KMeans算法进行聚类分析
kmeans = KMeans(n_clusters=3)
kmeans.fit(df)
# 获取聚类结果
labels = kmeans.labels_
# 将聚类结果添加到数据框中
df['label'] = labels
# 绘制三维散点图
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
scatter = ax.scatter(df['三环萜烷/五环萜烷'], df['Ts/17αC30藿烷'], df['重排甾烷/规则甾烷'], c=df['label'])
# 添加图例,并设置中文显示
handles, labels = scatter.legend_elements()
plt.legend(handles, labels, loc='best', prop=font)
ax.set_xlabel('三环萜烷/五环萜烷', fontproperties=font)
ax.set_ylabel('Ts/17αC30藿烷', fontproperties=font)
ax.set_zlabel('重排甾烷/规则甾烷', fontproperties=font)
plt.show()
记得把字体地址改为你的电脑上字体所在地址,或者直接注释掉,用英文图例
运行结果如下:
二、基于X射线荧光光谱的盐含量测定
原油中的无机盐含量对设备腐蚀、管线结垢堵塞、加热设备效率以及最终产品质量等方面有影响。为了分析原油中的盐含量,目前常用的方法有电量法、电位滴定法和电导法等。然而,这些方法存在一些问题,如对仪器和环境要求高、操作复杂等。因此,为了解决这些问题,提出了一种新的方法,即单波长色散X射线荧光光谱法。该方法通过将原油中的无机盐萃取至乙醇水溶液中,然后利用已做好的标准曲线来快速测定无机氯含量,从而计算出原油中的盐含量。这种方法具有准确性高、重复性好、分析速度快、仪器维护简单等优点,可以作为传统方法的替代方法。
当X射线与原子相互作用时,会发生散射和荧光现象。在荧光现象中,X射线会激发原子中的电子,使其跃迁到更高能级,然后再从高能级跃迁回到较低能级时放出能量。这些放出的能量形成了荧光光谱,可以用来分析样品中的元素。盐类元素在荧光光谱中具有特定的特征峰,不同元素对应着不同的特征峰。通过测量荧光光谱中这些特征峰的强度和位置,可以确定样品中各种元素的含量。对于原油中的盐含量分析,主要关注氯元素。实验中,使用X射线源发出的X射线经入射光单色器衍射形成一束能够激发氯元素K层电子的单色激发光束。将这束光照射到原油样品上,样品中的氯元素会发出特定波长为0.473nm的Ka特征X射线荧光。这个波长的X射线荧光由一固定通道单色器收集并聚集到探测器上,从而得到原油样品的X射线荧光强度(计数/s)。通过使用事先制备好的标准溶液进行校准,可以将样品X射线荧光强度转换为样品中氯的含量(以毫克/千克计)。根据氯的含量,可以计算出相应的氯化钠含量(以毫克/千克计)。
在实验中,需要制备标准溶液,选择干燥的NaCl作为溶质,用超纯水溶解。通过称取适量的NaCl溶解后,稀释并混合均匀,以制备出所需浓度的标准溶液。
完整代码如下:
import numpy as np
import matplotlib.pyplot as plt
# 生成原油样品的荧光光谱数据
def generate_fluorescence_spectrum():
# 生成荧光光谱的波长范围和强度
wavelength = np.linspace(0.4, 1.0, 100) # 波长范围0.4到1.0
intensity = np.random.rand(100) # 荧光强度随机生成
return wavelength, intensity
# 计算样品中的盐含量
def calculate_salt_content(fl_spectrum):
# 假设荧光光谱中的特征峰对应盐类元素的含量
salt_peak_intensity = np.max(fl_spectrum[1]) # 荧光光谱的最大强度
salt_content = salt_peak_intensity * 10 # 假设强度和盐含量的线性关系
return salt_content
# 生成标准溶液的荧光光谱数据
def generate_standard_fluorescence_spectrum(salt_content):
# 假设标准溶液的荧光光谱与盐含量成正比
intensity = salt_content * np.random.rand(100) # 荧光强度与盐含量成正比
# 假设标准溶液的波长范围与原油样品相同
wavelength = np.linspace(0.4, 1.0, 100) # 波长范围0.4到1.0
return wavelength, intensity
# 校准曲线拟合
def calibrate_curve(standard_spectrum):
# 假设标准曲线是线性拟合
salt_content = np.linspace(0, 100, 100) # 盐含量范围0到100
calibration_curve = np.polyfit(standard_spectrum[1], salt_content, 1) # 线性拟合
return calibration_curve
# 生成测试样品的荧光光谱数据
sample_fl_spectrum = generate_fluorescence_spectrum()
sample_salt_content = calculate_salt_content(sample_fl_spectrum)
# 生成标准溶液的荧光光谱数据
standard_fl_spectrum = generate_standard_fluorescence_spectrum(sample_salt_content)
# 校准曲线拟合
calibration_curve = calibrate_curve(standard_fl_spectrum)
# 转换测试样品的盐含量
sample_salt_content_converted = np.polyval(calibration_curve, sample_fl_spectrum[1])
# 绘制荧光光谱图
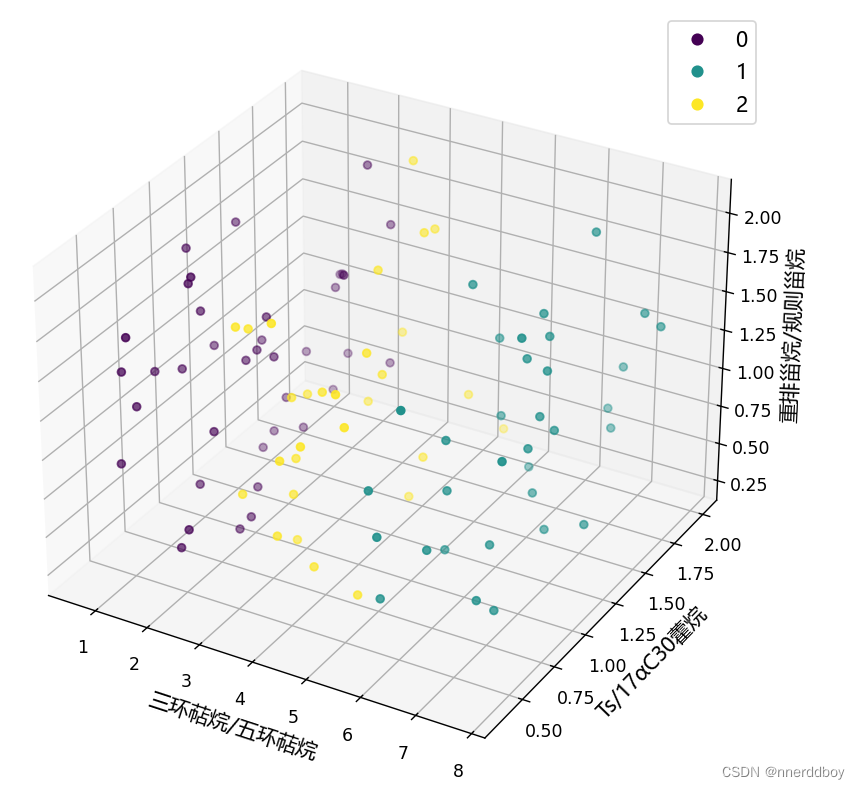
plt.figure(figsize=(8, 6))
plt.plot(sample_fl_spectrum[0], sample_fl_spectrum[1], label='Sample Fluorescence Spectrum')
plt.plot(standard_fl_spectrum[0], standard_fl_spectrum[1], label='Standard Fluorescence Spectrum')
plt.xlabel('Wavelength')
plt.ylabel('Intensity')
plt.title('Fluorescence Spectrum Comparison')
plt.legend()
plt.show()
# 打印样品盐含量和转换后的盐含量
print("测试样品的盐含量:", sample_salt_content)
print("转换后的盐含量:", sample_salt_content_converted)
运行结果:

三、近红外光谱数据库快速评估
为了解决近红外光谱数据库快速评估的问题,提高识别速度和准确性,研究人员通过将主成分分析和移动窗口相关系数技术相结合,构建了一个小数据库来快速识别与待测原油最相似的样本。针对原油性质的微小变化和采集差异引起的识别问题,他们采用蒙特卡罗方法生成了虚拟原油样本,并通过主成分分析来确定与待测原油一致的样本。通过这种方式,他们能够快速获得准确的评价数据,从而提高了近红外光谱原油识别的效率和准确性。
完整代码如下:
import numpy as np
import matplotlib.pyplot as plt
# 模拟近红外光谱数据库
database_spectrum = np.random.rand(100, 1000)
# 生成待测原油光谱
unknown_spectrum = np.random.rand(1, 1000)
# 主成分分析压缩数据库光谱
compressed_database = np.dot(database_spectrum, np.transpose(database_spectrum))
compressed_unknown_spectrum = np.dot(unknown_spectrum, np.transpose(database_spectrum))
# 寻找与待测原油最相似的4个样本
distances = np.linalg.norm(compressed_database - compressed_unknown_spectrum, axis=1)
top_4_indices = np.argsort(distances)[:4]
# 移动窗口相关系数法在小库中识别与待测原油一致的库光谱
similar_spectra = database_spectrum[top_4_indices]
# 蒙特卡罗方法生成更多的虚拟原油样本
D = 1000
virtual_samples = []
for i in range(D):
random_index = np.random.choice(top_4_indices)
virtual_samples.append(np.random.normal(database_spectrum[random_index], scale=0.1, size=(1000,)))
# 主成分分析取前两个主成分作图
virtual_samples = np.array(virtual_samples)
virtual_samples_compressed = np.dot(virtual_samples, np.transpose(database_spectrum))
pc1 = virtual_samples_compressed[:, 0]
pc2 = virtual_samples_compressed[:, 1]
# 图像绘制
fig, (ax1, ax2) = plt.subplots(2, 1)
# 绘制蒙特卡罗模拟结果
ax1.scatter(pc1, pc2)
ax1.set_xlabel('PC1')
ax1.set_ylabel('PC2')
ax1.set_title('Monte Carlo Simulation')
# 绘制主成分分析结果
pc1 = compressed_database[:, 0]
pc2 = compressed_database[:, 1]
ax2.scatter(pc1, pc2)
ax2.set_xlabel('PC1')
ax2.set_ylabel('PC2')
ax2.set_title('Principal Component Analysis')
plt.tight_layout()
plt.show()
运行结果如下:



![[两个栈实现队列]](https://img-blog.csdnimg.cn/direct/1569b7459eaa4c6f9dbc92afffc6b887.png)