目录
- 一、前言
- 二、Elasticsearch数据结构
- 三、安装
- 1.配置最大可创建文件数大小
- 2.由于ES不能以root用户运行,我们需要创建一个非root用户,此处创建一个名为es的用户
- 3.安装es
- 4.启动es服务
- 四、常用操作
- 1.创建没有结构的索引
- 2.创建有结构的索引
- 3.删除索引
- 4.文档操作
- 4.1添加或修改
- 4.2根据id查询文档
- 4.3根据id批量查询文档
- 4.4查询所有文档
- 4.5修改文档部分字段
- 4.6删除文档
- 5.域的属性
- 5.1 index
- 5.2 type 域的类型
- 5.3 store 存储
一、前言
Elasticsearch是一个全文检索服务器,全文检索是一种非结构化数据的搜索方式,通过建立倒排索引加快搜索效率;程序员Shay基于Lucene开发了开源项目 Elasticsearch,其本质上是一个java语言开发的web项目,我们可以通过RESTful风格的接口访问该项目内部的Lucene,从而让全文搜索变得简单(所有的请求都忽略ip地址:端口号)。
二、Elasticsearch数据结构
tips:Elasticsearch7以后,删除了type的概念
-
文档(Document):文档是可被查询的最小数据单元,一个Document 就是一条数据。类似于关 系型数据库中的记录(一行)的概念。
-
索引(Index):索引是多种类型文档的集合,类似于关系型数据库中的库的概念。
-
域(Filed):文档由多个域组成,类似于关系型数据库中的字段的概念。

三、安装
1.配置最大可创建文件数大小
#打开系统文件:
vim /etc/sysctl.conf
#添加以下配置:
vm.max_map_count=655360
#配置生效:
sysctl -p
2.由于ES不能以root用户运行,我们需要创建一个非root用户,此处创建一个名为es的用户
#创建用户:
useradd es
3.安装es
#解压:
tar -zxvf elasticsearch-7.17.0-linux-x86_64.tar.gz
#重命名:
mv elasticsearch-7.17.0 elasticsearch1
#移动文件夹:
mv elasticsearch1 /usr/local/
#es用户取得该文件夹权限:
chown -R es:es /usr/local/elasticsearch1
4.启动es服务
#切换为es用户:
su es
#进入ES安装文件夹:
cd /usr/local/elasticsearch1/bin/
#启动ES服务:
./elasticsearch
#查询ES服务是否启动成功
curl 127.0.0.1:9200
安装完es之后,还需要有一个kibana可视化平台,方便对es索引进行搜索和,查看,交互。该平台安装步骤在下面的链接,有兴趣可以查看。
kibana安装链接
四、常用操作
1.创建没有结构的索引
请求方式:PUT
PUT /student
*为索引添加结构
#基本格式
POST /索引名/_mapping
{
"properties":{
"域名1":{
"type":域的类型,
"store":是否存储,
"index":是否创建索引,
"analyzer":分词器
},
"域名2":{
...
}
}
}
eg:
POST /student/_mapping
{
"properties":{
"id":{
"type":"integer"
},
"name":{
"type":"text"
},
"age":{
"type":"integer"
}
}
}
2.创建有结构的索引
只有index设置为true,才能为该域的数据创建索引
mappings:映射是用来定义一个文档,和其包含的字段,是如何存储和索引的过程。
类型:1.properties /fields:一份映射类型包含字段列表或者文档的相关属性。
PUT /索引名
{
"mappings":{
"properties":{
"域名1":{
"type":域的类型,
"store":是否单独存储,
"index":是否创建索引,
"analyzer":分词器
},
"域名2":{
...
}
}
}
}
eg:
#创建有结构的索引
PUT /student1
{
"mappings": {
"properties": {
"id": {
"type": "integer"
},
"name": {
"type": "text"
},
"age": {
"type": "integer"
}
}
}
}
3.删除索引
DELETE /索引名
eg:
DELETE /student1
4.文档操作
前面的创建的索引(有结构)相当于数据库创建了一张表,这里的文档操作相当于给数据表添加了一行或几行数据
4.1添加或修改
当id值存在时就是修改,否则就是一个新增id值不写则自动生成
POST /索引/_doc/[id值]
{
"field名":field值
}
eg:
POST /student/_doc/1
{
"id":1,
"name":"itbz",
"age":10
}
4.2根据id查询文档
GET /索引/_doc/id值
eg:
#查询文档
GET /student/_doc/1
4.3根据id批量查询文档
GET /索引/_mget
{
"docs":[
{"_id":id值},
{"_id":id值}
]
}
eg:
#批量请求
GET /student/_mget
{
"docs": [
{
"_id": 1
},
{
"_id": 2
}
]
}
4.4查询所有文档
query: 在查询过程中,除了判断文档是否满足查询条件外,ES还会计算一个_score来标识匹配的程度,旨在判断目标文档和查询 条件匹配的有多好(与查询的条件有多吻合).
GET /索引/_search
{
"query": {
"match_all": {}
}
}
eg:
#查询所有文档
GET /student/_search
{
"query": {
"match_all": {}
}
}
4.5修改文档部分字段
POST /索引/_doc/id值/_update
{
"doc":{
域名:值
}
}
eg:
POST /student/_doc/1/_update
{
"doc":{
"name":"shangxuetang"
}
}
4.6删除文档
DELETE /索引/_doc/id值
eg:
#删除
DELETE /student/_doc/1
- Elasticsearch在执行删除操作时,ES先标记文档为delete为delete状态,等ES存储空间不足或者工作空闲的时候再执行物理删除
- 修改文档操作时,ES不会真的修改Document中的数据,而是标记ES中原有的文档为deleted状态,再创建一个新的文档来存储数据(先删除后修改)
5.域的属性
5.1 index
**该域是否创建索引。只有值设置为true,才能根据该域的关键词查询文档。**
eg:
PUT /student1
{
"mappings": {
"properties": {
"name": {
"type": "text",
"index":true
}
}
}
}
// 根据关键词查询文档
GET /索引名/_search
{
"query":{
"term":{
搜索字段: 关键字
}
}
}
eg:
GET /student1/_search
{
"query": {
"term": {
"name": "love"
}
}
}
5.2 type 域的类型
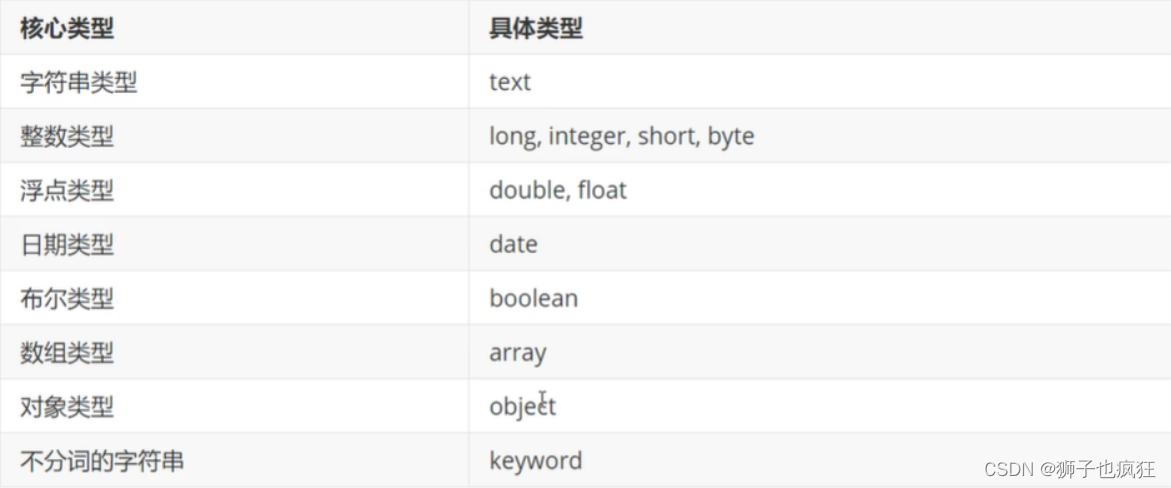
keyword类型:如果使用该类型,只能根据整体来查到
5.3 store 存储
设置是否单独存储。如果设置为true,则该域能单独查询。(本来可以字段都是存在_source,设置store属性为true,那么有一个单独的存储空间为这个字段做存储,而且这个存储是独立于source的存储的。)
// 单独查询某个域:
GET /索引名/_search
{
"stored_fields": ["域名"]
}
eg:
GET /student1/_search
{
"stored_fields": ["name"]
}
- 使用场景:该属性访问比较频繁。
- 使用store存储字段field会占用磁盘空间。如果需要从文档中提取(即在脚本中和聚合)它会帮助减少计算。在聚合时具有store属性的字段会比不具有这个属性的字段快。
这就是es的安装和常见基础操作,如果可以帮到你,希望给个一键三连。