目录
一、流的概念
二、字节流代码演示
1、InputStream
read方法
第一个没有参数的版本:
第二个带有byte数组的版本:
第三个版本
搭配Scanner的使用
2、OutputStream
write方法
第一个版本:
第二个写入整个数组版本:
第三个版本:
三、字符流代码演示
1、Reader
read方法
2、Writer
write方法
四、三个小练习
1、查找硬盘上文件的位置
2、实现文件复制
3、在目录中搜索,但是按照文件内容的方式搜索(1和2的小结合)
一、流的概念
流是操作系统的概念,但是Java / C对其进行了封装;流类似水流,连绵不断、生生不息。
水流的特点:有100ml的水,我们可以每次接10ml,分10次接完,也可以分5ml,分20次接完,或者直接一次性100ml全部接完。
数据流的特点:类似水流,假设要读写100字节的数据,可以每次读写10字节的数据,分10次读写完,也可以每次读写5字节,分20次读写完,或者一次性读写完100字节的数据。
文件流:读写文件内容,读写文件内容在各种编程语言中,都是“固定套路”的。
1、打开文件
2、读/写文件
3、关闭文件
Java对流进行了一系列封装,提供了一组类来负责这些工作;针对这么多类,大体可以风味两种类
字节流:以字节为单位,每次最少读写一个字节。
字符流:以字符为单位,每次读写一个字符,比如 utf8 中的汉字,3个字节就是一个字符,每次最少都得读写3个字符。不能一次读写半个字符。
二、字节流代码演示
1、InputStream
从InputStream内部看,我们可以发现InputStream是抽象类,被abstract修饰,如图:
所以,不能实例化InputStream类,但我们可以创建FileInputStream对象,它是InputStream的子类,如图:

InputStream用完要记得关闭文件,可以理解成释放文件的相关资源,如图:
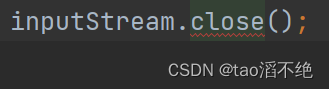
在进程中,PCB里面有文件描述符表,记录了当前进程都打开了哪些文件,这个文件描述符表是由数组 / 顺序表组成的,数组里面的每一个元素都代表着是一个结构体,里面包含了文件的一些属性,每打开一个文件,在文件描述符表就会被多占一个位置,而文件描述符表的资源是有限的,如果不关闭,当它被耗尽了,后续再打开文件就会失败,从而引发其他的逻辑出问题;而为啥不给文件描述符表满了就进行扩容操作?原因是这操作付出的代价很大:对于操作系统内核来说,要求的性能是很高的,内核任务也很重,而扩容本质也就是创造出新的更大规模的数组,把旧数组的数据移动到新数组中,其中工作量很大,如果进行扩容,对操作系统的来说,在内核任务很重的情况下,又要进行其他任务,就可能会导致操作系统卡顿现象,如果发生这种情况,就得不偿失了。
使用finally代码:
public class IODemo1 {
public static void main(String[] args) throws IOException {
InputStream inputStream = null;
try {
inputStream = new FileInputStream("./test.txt");
} catch (FileNotFoundException e) {
throw new RuntimeException(e);
}finally {
inputStream.close();
}
}
}可以看到把inputStream放在try代码块外,其中因为finally最后要得到InputStream引用,要将其设为全局变量才能调用close方法;如果在try内代码块new对象,就是局部变量了,finally里找不到有inputStream的引用。
在java中,所以我们可以使用finally,但try还提供了另一个版本:try with resources,用法如下:
public class IODemo1 {
public static void main(String[] args) throws FileNotFoundException {
try(InputStream inputStream = new FileInputStream("./test.txt")){
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}也是和finally作用一样,无论咋样,都会执行InputStream.close。其中创建FileInputStream可能会有FileNotFoundException异常,因为IOException是FileNotFoundException的父类,所以可以直接像上面那样写,不用像下面这样写

read方法
read有三个不同参数的版本,如图:

第一个没有参数的版本:
每次只读一个字节,并且有返回值,上面显示的是int类型,其实是byte类型,返回的值是读到的该字节的值,范围是0~255,还有一个特殊的情况,如果返回值是-1,则说明读取到文本的末尾了,没有其他内容了。
以下是代码案例:
public class IODemo2 {
public static void main(String[] args) {
try(InputStream inputStream = new FileInputStream("./test.txt")) {
while (true) {
int n = inputStream.read();
if(n == -1) {
break;
}
System.out.printf("%x ", n);
}
} catch (IOException e) {
throw new RuntimeException(e);
}
}
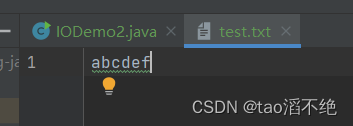
}test.txt的内容是abcdef,如图
代码运行结果如下:

而abcdef的ascll表16进制分别是以上结果。
第二个带有byte数组的版本:

如图,该数组是 “输出型参数”,byte[] 是引用类型,在方法内对数组进行修改,方法结束后,在方法外部仍然生效,本质是看针对 “引用类型修改”,还是针对 “解引用修改对象本体”。
以下是代码演示:
public class IODemo1 {
public static void main(String[] args) {
try(InputStream inputStream = new FileInputStream("./test.txt")){
byte[] buffer = new byte[1024];
while (true) {
int n = inputStream.read(buffer);
if(n == -1) {
break;
}
for (int i = 0; i < n; i++) {
System.out.printf("%x ", buffer[i]);
}
}
}catch (IOException e) {
throw new RuntimeException(e);
}
}
}上面代码是按照若干个字节读,而不是一个一个字节读,效率比第一个版本强,因为读文件本质是读硬盘,这个操作是比较耗时的,如果我们读若干个字节,放在内存了,然后要显示出来其内容的时候,是直接在内存访问已经读的若干个字节,要比读硬盘快。
而返回值是读了多少个字节,它读的时候,会尽可能把数组填满,但实际情况可能填不满,那就能填多少是多少。
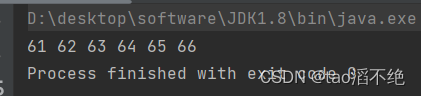
执行结果如下:

如果我们想显示中文字符,如果像上面那样读,会读出中文字符的 utf8 的16进制值,要怎么搞,以下是代码演示:
public class IODemo2 {
public static void main(String[] args) {
try(InputStream inputStream = new FileInputStream("./test.txt")){
while (true) {
byte[] buffer = new byte[1024];
int n = inputStream.read(buffer);
if (n == -1) {
break;
}
String s = new String(buffer, 0, n);
System.out.print(s);
}
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}
执行结果如下:


第三个版本
是写数组的一部分,其中off是偏移量,而不是开 关,如图:

搭配Scanner的使用
我们想读文件的内容,也可以使用Scanner搭配InputStream使用。
Scanner(System.in),括号里面我们肯定都不陌生,这里的System.in本质就是InputStream,我们可以把System.in换成InputStream,下面是代码演示:
public class IODemo8 {
public static void main(String[] args) {
try(InputStream inputStream = new FileInputStream("./test.txt")) {
Scanner scanner = new Scanner(inputStream);
while (scanner.hasNext()) {
String s = scanner.next();
System.out.println(s);
}
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}执行结果:

2、OutputStream
write方法
如图,下面是三个不同参数版本
第一个版本是一次写一个字节,第二个版本是一次写整个数组,第三个版本是写数组的一部分,它们的返回值都是void,返回空。
第一个版本:
代码如下:
public class IODemo4 {
public static void main(String[] args) {
try(OutputStream outputStream = new FileOutputStream("./test.txt")) {
outputStream.write(97);
outputStream.write(98);
outputStream.write(99);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}
执行结果: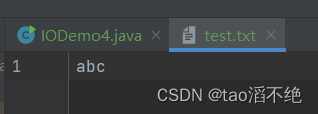
因为一次写一个字节,97 98 99是abc的ASCII值,会把原来文件的内容删除,重新写入新的内容。
注意:就算没有调用write方法,执行代码后,也会删除指定文件的内容,除非创建FileOutputStream是,参数加true,才能追加写,如图:
执行下面代码:
public class IODemo4 {
public static void main(String[] args) {
try(OutputStream outputStream = new FileOutputStream("./test.txt", true)) {
outputStream.write(97);
outputStream.write(98);
outputStream.write(99);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}结果如下:

之前原本有的abc还在,又追加写了abc。
第二个写入整个数组版本:
代码演示:
public class IODemo5 {
public static void main(String[] args) {
try(OutputStream outputStream = new FileOutputStream("./test.txt")) {
byte[] buffer = {97, 98, 99, 100, 101, 102};
outputStream.write(buffer);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}执行结果:
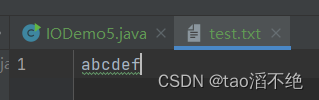
byte数组里面放的元素ASCII值是abcdef,放入数组就是写入数组里的内容,也可以追加写,加个true就行了。
第三个版本:
写数组的一部分,off是偏移量,不是开关。
三、字符流代码演示
Reader和Writer的使用方法,和字节流的InputStream和OutputStream基本差不多。
1、Reader
read方法
如图,下面是read方法几个不同参数的版本
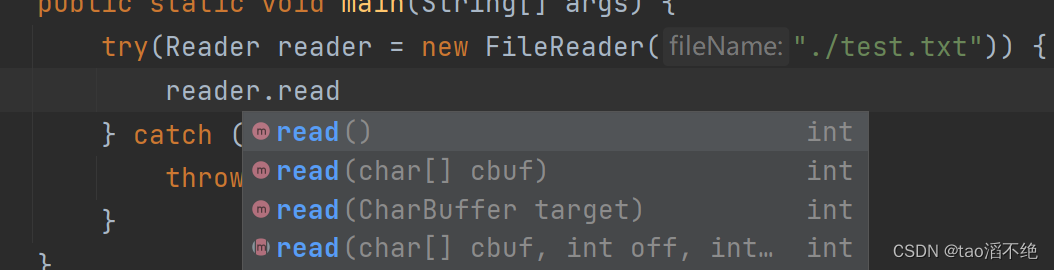
和字节流读的不同,它是以char为单位进行读的,下面用带数组参数的版本演示,代码如下:
public class IODemo6 {
public static void main(String[] args) {
try(Reader reader = new FileReader("./test.txt")) {
while (true) {
char[] buffer = new char[1024];
int n = reader.read(buffer);
if(n == -1) {
break;
}
String s = new String(buffer, 0, n);
System.out.println(s);
}
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}
执行结果:

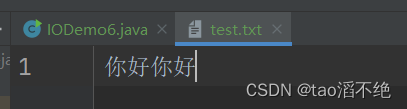
这里有个细节问题,一个char类型有2个字节,而在utf8中,一个中文字符符占3个字节,存在char数组的值怎么打印出中文字符?
原因:在read的时候,每次读到的内容都会存进数组中,存进数组时,读到的内容是按unicode的值存进数组的,当这个数组放进String的构造方法时,会把unicode的值转回utf的值,这个过程是在java内部封装好了的,我们人为感知不到。
如果我们把数组内容一个一个读出来,代码如下:
public class IODemo6 {
public static void main(String[] args) {
try(Reader reader = new FileReader("./test.txt")) {
while (true) {
char[] buffer = new char[1024];
int n = reader.read(buffer);
if(n == -1) {
break;
}
// String s = new String(buffer, 0, n);
// System.out.println(s);
for(int i = 0; i < n; i++) {
System.out.print(buffer[i]);
System.out.print(" ");
}
}
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}执行结果:
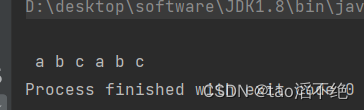
“你好你好”这一行就打印不出来了。
2、Writer
write方法
如果要追加写,就加个true
如图是write方法的几个版本:
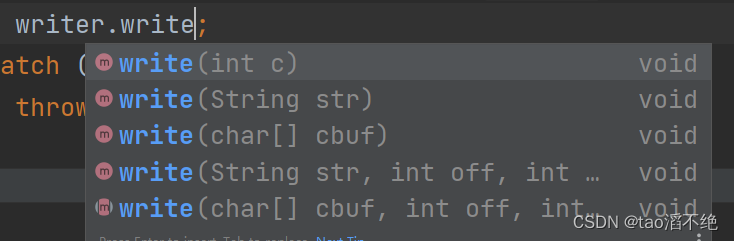
主要使用带有String参数的版本,构造一个字符串,直接把字符串作为参数放进write方法中就可以写入那个字符串进文件中。以下是代码演示:
public class IODemo7 {
public static void main(String[] args) {
try(Writer writer = new FileWriter("./test.txt")) {
String s = "你好";
writer.write(s);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}执行结果:把你好写进文件中了。
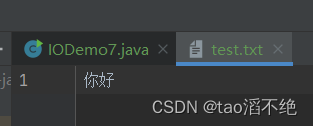
四、三个小练习
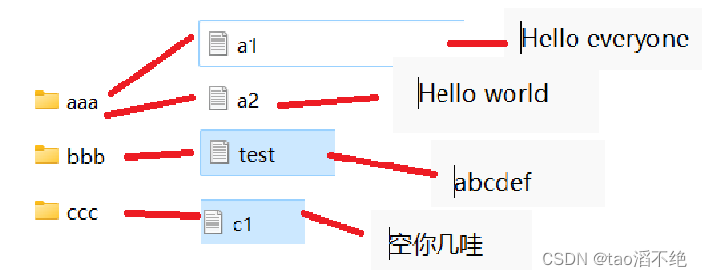
以下是文件路径相关信息

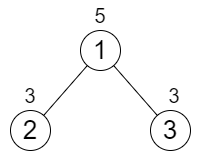
这里需要使用到递归,是遍历一遍树,也就是所有的文件都要遍历一遍,看是否符合要求,这里不存在前中后遍历的情况,因为该树是N叉树。
1、查找硬盘上文件的位置
要求:给定一个文件名,去指定的目录中进行搜索,找到文件名匹配的结果,并打印出完整的路径。
代码演示:
//D:/desktop/file/javaEE/JavaEECode/test
public class IODemo9 {
public static void main(String[] args) {
//1、输入必要信息
Scanner scanner = new Scanner(System.in);
System.out.println("请输入要查找的文件");
String fileName = scanner.next();
System.out.println("请输入要搜索的目录");
String rootPath = scanner.next();
File file = new File(rootPath);
//判断输入的目录是否合法
if(!file.isDirectory()) {
//不是目录
System.out.println("输入的目录不合法");
return;
}
//2、在目录下找我们给定文件名,看是否存在,使用递归的方式进行搜索
scanDir(file, fileName);//知道递归的起点,还需要知道要查询的文件名
}
private static void scanDir(File rootFile, String fileName) {
//1、把所有子目录都列出来
File[] files = rootFile.listFiles();
//递归结束条件
if(files == null) {
//空目录,直接返回
return;
}
//2、遍历files,判断每一个file文件是目录还是文件
for(File f : files) {
//记录日志
System.out.println("当前遍历到:" + f.getAbsolutePath());
//1、文件,判断文件名是不是要查找的文件名
if(f.isFile()) {
String name = f.getName();
if(fileName.equals(name)) {
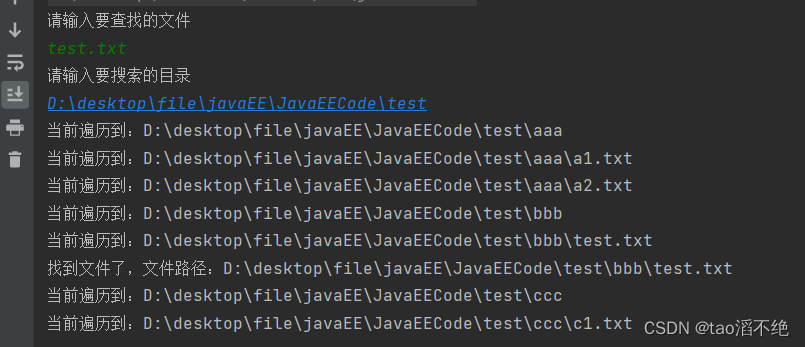
System.out.println("找到文件了,文件路径:" + f.getAbsolutePath());
}
} else if(f.isDirectory()) {
//2、目录,继续往下递归
scanDir(f, fileName);
} else {
// 这个 else 暂时不需要
}
}
}
}
执行结果:
2、实现文件复制
要求:把一个文件复制一下,成为另一个文件。
意思就是把第一个文件以读方式打开,依次读取这里的每个字节,再读到的内容,写入到另一个文件中。
现有的文件:

复制cat.jpg文件,到cat2.jpg,因为没有cat2.jpg,所以执行代码后会多出cat2.jpg文件。
代码演示:
public class IODemo11 {
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
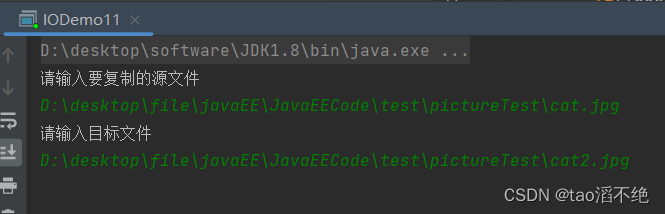
System.out.println("请输入要复制的源文件");
String srcFileName = scanner.next();
System.out.println("请输入目标文件");
String desFileName = scanner.next();
File srcFile = new File(srcFileName);
//判断源文件的合法性
if(!srcFile.isFile()) {
System.out.println("文件不合法");
return;
}
File desFile = new File(desFileName);
//判断目标文件的合法性,不要求文件存在,但要求文件路径存在
if(!desFile.getParentFile().isDirectory()) {
System.out.println("目标路径不合法");
return;
}
//读取要复制文件的每个字节,把读到的每个字节都放到新的文件中
try(InputStream srcInputStream = new FileInputStream(srcFile);
OutputStream outputStream = new FileOutputStream(desFile)) {
while (true) {
byte[] buffer = new byte[1024];
int n = srcInputStream.read(buffer);
if(n == -1) {
break;
}
outputStream.write(buffer,0 ,n);
}
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}
输入内容:
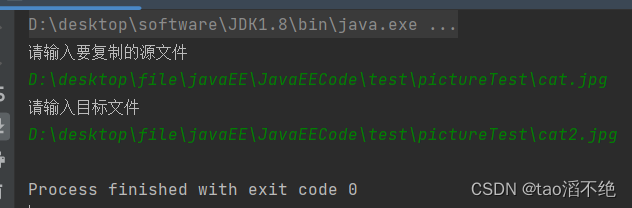
执行结果:
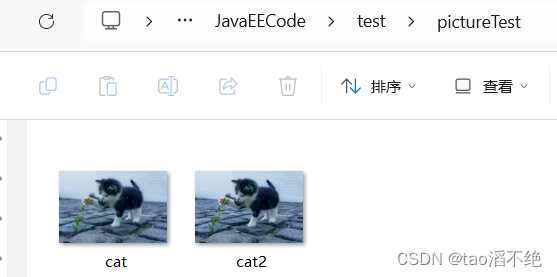
多出了cat2.jpg文件。
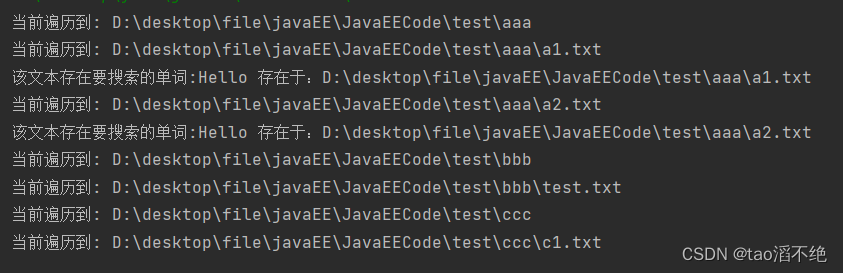
3、在目录中搜索,但是按照文件内容的方式搜索(1和2的小结合)
用户输入一个目录,一个要搜索的词,遍历文件的过程中,如果文件包含了要搜索的词,此时就把文件的路径打印出来。
代码演示:
public class IODemo13 {
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
System.out.println("请输入要搜索的词");
String word = scanner.nextLine();
System.out.println("请输入要搜索的路径");
String rootPath = scanner.nextLine();
File rootFile = new File(rootPath);
//判断搜素路径是否合法
if(!rootFile.isDirectory()) {
System.out.println("输入的搜素路径不合法");
return;
}
//遍历每一个文件,如果是普通文件,就判断文件内容里面有没有我们要搜索的词
scanDir(rootFile, word);
}
private static void scanDir(File rootFile, String word) {
//把当前目录都列出来
File[] files = rootFile.listFiles();
if(files == null) {
return;
}
for(File f : files) {
System.out.println("当前遍历到: " + f.getAbsolutePath());
//是普通文件,判断文件内容里面有没有我们要搜索的词
if(f.isFile()) {
//把文件内容一个字节一个字节的读出来,构成字符串,在判断字符串里面有没有要搜索的词
searchInFile(f, word);
} else if(f.isDirectory()) {
//是目录,继续递归
scanDir(f, word);
} else {
//这个不需要处理
}
}
}
private static void searchInFile(File f, String word) {
try(InputStream inputStream = new FileInputStream(f)) {
StringBuilder stringBuilder = new StringBuilder();
while (true) {
byte[] buffer = new byte[1024];
int n = inputStream.read(buffer);
if(n == -1) {
break;
}
String s = new String(buffer, 0, n);
stringBuilder.append(s);
}
//System.out.println("日志,当前读到文本的内容:" + stringBuilder);
if(stringBuilder.indexOf(word) == -1) {
//没有找到,直接return走
return;
}
//文本内容存在要搜索的单词,打印出路径
System.out.println("该文本存在要搜索的单词:" + word +" 存在于:" + f.getAbsolutePath());
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}
文件内容如下:
代码输入如下:
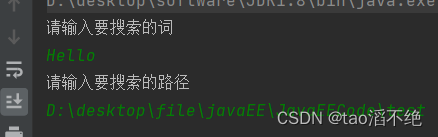
执行结果: