说明
最近想重新上RabbitMQ,主要目的还是为了分布式任务调度。在Kafka和RabbitMQ两者犹豫了一下,还是觉得RabbitMQ好一些。
在20年的时候有搞过一阵子的RabbitMQ,看了下当时的几篇文章,觉得其实想法一直没变过。
Python - 装机系列24 消息工具 RabbitMQ详细了解介绍了丢包的问题,这个估计是我当时放弃使用这个的直接原因。现在想来挺逗的,完全是因为测试服务器ubuntu使用wifi连接不稳定导致的。
文章参考RMQ官网,总结了7种队列工作模式。文章内还有使用pika进行测试的部分,我最主要使用模式2。
文章还提到了原来部署时的一些问题,之后可以参考。
【Python 全栈系列49 - Pika连接RabbitMQ的封装】这篇当时没有继续写,按照现在的风格,应该是封装为RabbitAgent。
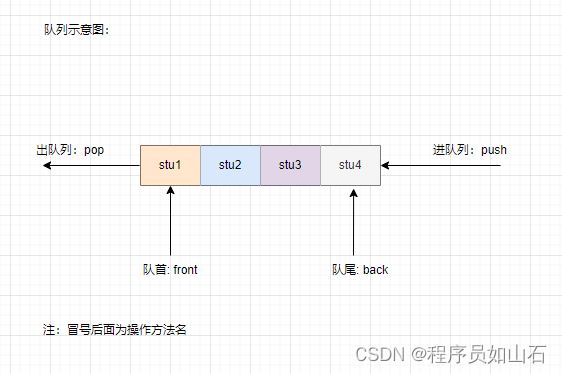
Python 全栈系列6 -消息通信(RabbitMQ、Pika)介绍了RabbitMQ最基本的使用,包括消息的格式等。
建模杂谈系列38- 基于celery、rabbitmq、redis和asyncio的分布并行处理(概述)介绍了io并行和cpu并行的特点,以及使用celery+rabbitmq+flower进行分布式任务的样例。
本篇仅介绍RabbitMQ的(再次)搭建。
内容
1 变化
现在和几年之前,我的infrastructure还是变了很多。
- 我用Redis Stream实现了一个简化版的消息队列(同时也实现了简单的分布式任务)
- 实现了多种数据库的Agent: 所以应该基于Pika封装一个微服务(RabbitAgent)
- 自己搭建了镜像仓库 :规范命名并上传保存
- 建立了数据的存储规范(分片、分区、分块):可以用于任务的同步
- 可以方便的进行文件同步:这样大数据不必放在消息队列,而是由worker执行远程同步拉取(这样也避免了worker没有多余公网端口的问题)
基于此,本次的实现将参考过去一些好的实践进行部署,之后也会借鉴RabbitMQ和Celery来完善自己的分布式任务。
2 搭建
拉取镜像

官网介绍的
# latest RabbitMQ 3.13
docker run -it --rm --name rabbitmq -p 5672:5672 -p 15672:15672 rabbitmq:3.13-management
在本地创建文件夹,并分配两个端口给这个服务。
然后就可以启动服务了,输入默认用户密码 guest/guest就可以进行访问了。
我想起来,最初的时候我是直接在ubuntu系统上面装rabbitmq的,依稀记得装erlang的过程。那真是烦死了,还好有docker。
在rabbitmq的官网页面有介绍配置用户密码的启动方式,暂时就先这样。
docker run -d --hostname my-rabbit --name some-rabbit -e RABBITMQ_DEFAULT_USER=user -e RABBITMQ_DEFAULT_PASS=password rabbitmq:3-management
本地化的一些改造
首先将镜像本地化,这样以后锁定本地的版本就可以了
docker tag rabbitmq:3.13-management myregistry.domain.com:24052/tool.rabbitmq_3.13_management:v100
docker push myregistry.domain.com:24052/tool.rabbitmq_3.13_management:v100
一个较为完整的启动命令为
docker run -d\
--restart=always \
--name=rabbitmq \
--hostname my-rabbit \
-v /etc/localtime:/etc/localtime \
-v /etc/timezone:/etc/timezone\
-v /etc/hostname:/etc/hostname \
-e "LANG=C.UTF-8"\
-e RABBITMQ_DEFAULT_USER=YOURS \
-e RABBITMQ_DEFAULT_PASS=YOURS \
-p 24091:5672\
-p 24092:15672 \
myregistry.domain.com:24052/tool.rabbitmq_3.13_management:v100
3 Next
开发RabbitAgent微服务,对RabbitMQ的操作进行简化。
借用RabbitMQ的队列模式,实现分布式任务。
使用celery+rabbitmq实现分布式任务。