摘要
计算机视觉中,常采用基于不变性和基于生成的方法进行自监督学习。对比学习(CL)是典型的基于不变性的方法,通过预训练方法优化编码器,使其能生成同一图像的两个或多个视图的相似嵌入,其中图像视图通常由一组手工设计的数据增强来构建,如随机缩放、裁剪和颜色抖动等。尽管基于不变性的预训练方法可以生成高语义级别的表示,但其特定于手工设计的数据增强方法会引入特定偏差,以至于对具有不同数据分布的预训练任务有害,这限制了其应用于不同下游任务和模态的推广。
掩码图像建模(MIM)可定义为生成式自监督方法,其通过从输入图像中重建随机mask的patches来学习表示,可以在像素级别或token级别上进行。相比CL,生成式自监督方法在先验知识需求上和跨模态应用方面都具有优势,但其学习到的表示通常具有较低的语义级别,在某些评估(线性探测)和迁移(语义分类任务)设置中表现不如基于视图不变性的预训练方法,故对于下游任务还需要微调才能发挥其优势。
本文探索如何不依赖于图像变换编码的额外先验知识的前提下,提高自监督表示的语义级别。通过引入一种用于图像的联合嵌入预测架构,设计了一种通过在表示空间中预测mask表示来学习嵌入的方法,I-JEPA。与生成方法相比,I-JEPA以表示空间作为预测目标空间,消除了不必要的像素级细节,从而使模型可以学习更多的语义特征。更多改进有:

- I-JEPA无需使用手工设计的数据增强即可学习强大的表示。在ImageNet-1K线性检测、半监督1% ImageNet-1K(如上图)和语义迁移任务上优于MAE等像素重建方法
- I-JEPA在语义任务上与视图不变性的预训练方法具有竞争力,在低层次视觉任务(如对象计数和深度预测)上实现了更好的性能。因为使用了更简单的模型和更少的刚性归纳偏差,I-JEPA能适用于更广泛的任务集
- I-JEPA具有更好的扩展性和高效性,在ImageNet上预训练ViT-h/14只需不到1200个GPU小时,比用iBOT预训练的ViT-s/16快2.5倍以上,比用MAE预训练的ViT-h/14快10倍以上。在表示空间中进行预测,大大减少了自监督预训练所需的总计算量
背景
自监督学习是一种表示学习的方法,在这种方法中,系统会学习捕捉其输入之间的关系。这一目标可以使用能量模型(energy-basedModels,EBMs)描述,能量函数可以写作
E
(
x
,
y
)
E(x,y)
E(x,y) ,用于衡量输入对
x
,
y
x,y
x,y是否匹配,能量越小匹配度越高。自监督学习的目标是给不匹配的输入对分配高能量,并给匹配输入对分配低能量。

Joint-Embedding Architectures
基于不变性的方法可以用上图a的联合嵌入架构(Joint-Embedding Architectures,JEA)来描述。该架构通过为同一输入图像随机应用手工设计的数据增强方法来构建输入对,并采用能量函数学习,为匹配的 x , y x,y x,y输入对输出相似的嵌入,为不匹配的输入对输出不相似的嵌入。
Generative Architectures
基于重构的生成式方法可以用上图b的生成架构(Generative Architectures)来描述。生成架构直接从兼容信号 x x x重建信号 y y y,并以附加变量 z z z为条件,使用decoder来促进重建。通常使用掩码来生成匹配的 x , y x,y x,y对,其中 y y y是输入图像 x x x的掩码视图。条件变量 z z z对应于一组掩码和位置tokens,用于指定给decoder要重建哪些图像块。
Joint-Embedding Predictive Architectures
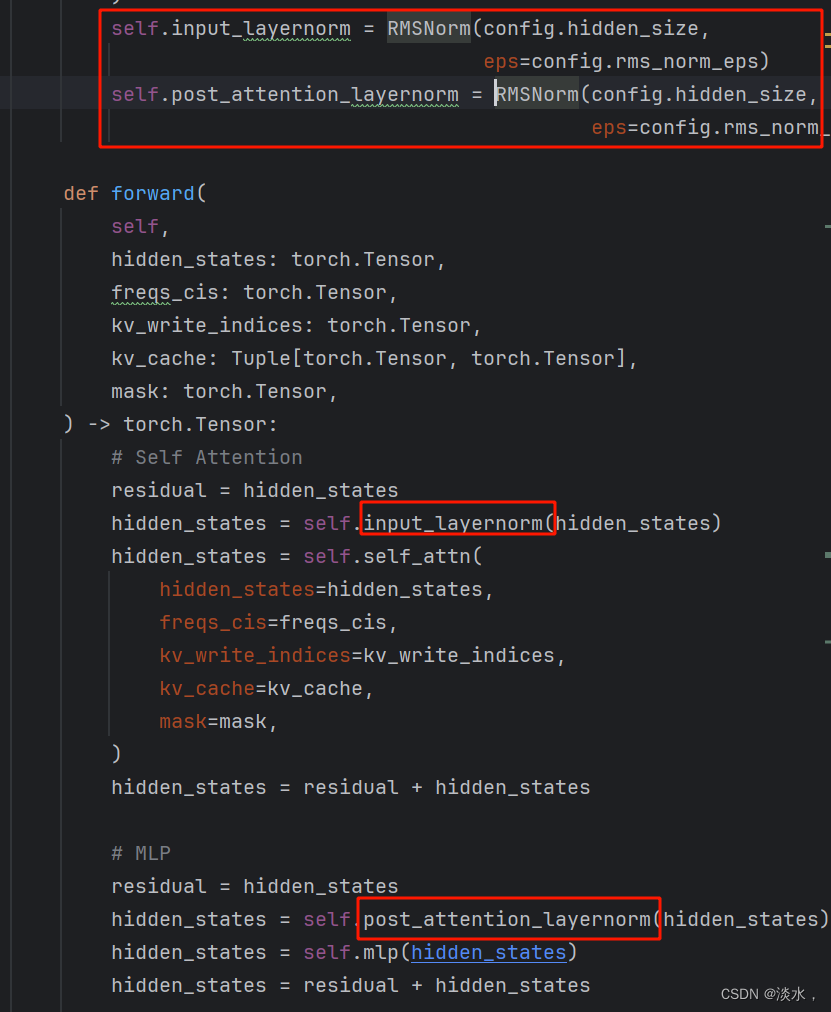
本文在上述两种架构的基础上提出了联合嵌入预测架构(Joint-Embedding Predictive Architecture,JEPA),如上图c。JEPA 与生成架构在概念上类似,但关键区别在于其损失函数被应用于嵌入空间而不是输入空间。JEPAs从兼容信号 x x x中预测信号 y y y的嵌入,并使用附加变量 z z z为条件的predictor来促进预测。 x x x编码器和 y y y编码器之间采用非对称架构来避免表示坍缩。
框架

I-JEPA结构如上图,给定的一个context block,以非生成式的方法预测同一图像中多个target blocks的表示。其中,context encoder、predictor和target encoder都采用ViT架构。
Targets
I-JEPA的预测目标为对应图像块的表示,给定一个输入图像 y y y,将其转换为N个不重叠的patches序列,并将其作为target encoder f θ ^ f_{\hat θ} fθ^的输入,得到相应的patches表示 s y = { s y 1 , … , s y N } s_y=\{ s_{y_1},\dots,s_{y_N}\} sy={sy1,…,syN},其中 s y k s_{y_k} syk为第 k k k个patch的表示。随后从目标表示 s y s_y sy中随机抽取 M M M个(可能重叠)target block,设 B i B_i Bi为第 i i i个块对应的mask, s y ( i ) = { s y j } j ∈ B i s_y(i)=\{ s_{y_j}\}_{j∈B_i} sy(i)={syj}j∈Bi为第 i i i个块的表示。M一般设为4,采样的target block的长宽比的取值区间为 ( 0.75 , 1.5 ) (0.75,1.5) (0.75,1.5),target block的面积占图像面积的取值区间为 ( 0.15 , 0.2 ) (0.15,0.2) (0.15,0.2)。
Context
I-JEPA的目标是从单个context block中预测target blocks的表示。context block为从图像中裁剪一块占总图像面积的取值区间为
(
0.85
,
1.0
)
(0.85,1.0)
(0.85,1.0)和高宽比固定为1的随机采样单个图像块
x
x
x,并设
B
x
B_x
Bx为与context block
x
x
x相关联的mask。为了保证任务的难度,会从context block中mask与target blocks重叠的区域。

上图为context block和target blocks的示例。随后将masked context block通过context encoder
f
θ
f_θ
fθ以获得相应的patch表示
s
x
=
{
s
x
j
}
j
∈
B
x
s_x=\{ s_{x_j}\}_{j∈B_x}
sx={sxj}j∈Bx。
Prediction
给定context encoder的输出 s x s_x sx,predictor的目标为预测 M M M个target block的表示 s y ( 1 ) , … , s y ( M ) s_y(1),\dots,s_y(M) sy(1),…,sy(M)。 故给定target block s y ( i ) s_y(i) sy(i)对应的目标掩码 B i B_i Bi ,将context encoder的输出 s x s _x sx和 B i B_i Bi 对应的mask tokens { m j } j ∈ B i \{ m_j\}_{j \in B_i} {mj}j∈Bi输入predictor g ϕ ( ⋅ , ⋅ ) g_{\phi}(\cdot , \cdot) gϕ(⋅,⋅),得到预测的target block表示 s ^ y ( i ) = { s ^ y j } j ∈ B i = g ϕ ( s x , { m j } j ∈ B i ) \hat s_y(i)=\{ \hat s_{y_j}\}_{j \in B_i}=g_{\phi}(s_x,\{ m_j\}_{j \in B_i}) s^y(i)={s^yj}j∈Bi=gϕ(sx,{mj}j∈Bi)。mask tokens由一个共享的可学习向量参数化,并加入了position encoding。由于是对 M M M个target block进行预测,故应用predictor M M M次,每次以 B i B_i Bi 对应的mask tokens为条件,得到最终预测结果 s ^ y ( 1 ) , … , s ^ y ( M ) \hat s_y(1),\dots,\hat s_y(M) s^y(1),…,s^y(M)。
Loss
Loss是预测表示
s
^
y
(
i
)
\hat s_y(i)
s^y(i)和目标表示
s
y
(
i
)
s_y(i)
sy(i)之间的平均L2距离:
1
M
∑
i
=
1
M
D
(
s
^
y
(
i
)
,
s
y
(
i
)
)
=
1
M
∑
i
=
1
M
∑
j
∈
B
i
∣
∣
s
^
y
(
i
)
−
s
y
(
i
)
∣
∣
2
2
\frac 1 M \sum ^M_{i=1} D(\hat s_y(i),s_y(i))=\frac 1 M \sum ^M_{i=1} \sum_{j \in B_i} || \hat s_y(i) - s_y(i)||^2_2
M1i=1∑MD(s^y(i),sy(i))=M1i=1∑Mj∈Bi∑∣∣s^y(i)−sy(i)∣∣22
Predictor g ϕ ( ⋅ , ⋅ ) g_{\phi}(\cdot , \cdot) gϕ(⋅,⋅)和context encoder f θ f_θ fθ通过梯度下降优化学习,target encoder f θ ^ f_{\hat θ} fθ^通过 f θ f_θ fθ的权重进行EMA更新。
实验
Image Classification
本节实验的模型为在ImageNet-1K数据集上进行预训练的自监督模型。除非另有说明,所有I-JEPA模型都以分辨率224×224像素进行训练。
ImageNet-1K

上表为ImageNet-1K数据集上进行的线性检测性能。本节使用的模型在自监督预训练后,模型权值被冻结,并在完整的ImageNet-1K训练集上训练一个线性分类器进行使用。观察到,与MAE、CAE和data2vec等生成式方法相比,I-JEPA显著提高了线性检测性能,同时使用更少的计算量。利用I-JEPA的高效率,还可以在更小的计算量下训练出性能优于最佳CAE模型的更大模型。
Low-Shot ImageNet-1K

上表为在1%的ImageNet数据集基准测试的性能。即只使用ImageNet的1%的标签,大约对应于每个类12或13个图像,基于此使用预训练模型适应ImageNet分类。观察到,当使用类似的编码器架构时,I-JEPA优于MAE,同时只需要更少的预训练epoch。在计算量显著降低的情况下,使用ViT-h/14架构的I-JEPA与使用ViT-l/16的data2vec的性能相匹配。当输入图像分辨率提高时,I-JEPA优于以往的CL方法,如MSN、DINO和iBOT。
Transfer learning

上表为在各种下游图像分类任务上使用线性检测的性能。观察到,I-JEPA显著优于以往的生成式方法(MAE和data2vec)。缩小了与CL方法之间的差距,甚至超过了CIFAR100和Place205上的DINO。
Local Prediction Tasks

上表为在各种低级任务上使用线性检测的性能。本实验在预训练后,编码器权重会被冻结,在其上训练一个线性模型,并在Clevr数据集上进行对象计数和深度估计。观察到,与DINO和iBOT等CL方法相比,I-JEPA方法在预训练期间有效地捕获了低级图像特征,并在目标计数(Clevr/Count)和深度估计(Clevr/Dist)任务上取得了更优的性能。
Scalability
Model Efficiency

与以往的方法相比,I-JEPA具有高度可扩展性。上图为在1%ImageNet-1K上的半监督评估任务上,top 1%作为预训练消耗的GPU小时数的函数的报告。观察到,相比以前的方法,在达到相同的精度的情况下,I-JEPA只需要更少的计算量。与生成式方法(MAE)相比,因为I-JEPA会在表示空间中计算目标从而引入了额外的开销(每次运行时间约慢7%),然而,由于I-JEPA在训练过程中的收敛速度更快,故仍然可以节省显著的计算量。与基于CL方法(iBOT)相比,I-JEPA的运行速度也要快得多。特别的,同等性能下,一个巨大的I-JEPA模型(ViT-h/14)比一个小的iBOT模型(ViT-s/16)所需的计算量还少。
Scaling data size

用更大数据集的预训练可使I-JEPA取得更高的性能。如上表为增加预训练数据集的大小(IN1K与IN22K)时,I-JEPA在语义和低级任务上的性能。当在更大更多样化的数据集上进行预训练时,这些概念上不同的迁移学习任务上的性能会得到提高。
Scaling model size
上表还显示,采用更大模型尺寸的I-JEPA在IN22K上进行预训练可取得更高的性能。与ViT-h/14模型相比,预训练ViT-g/16显著提高了Place205和INat18等图像分类任务的下游性能,但并没有提高低级下游任务的性能,可能因为ViT-g/16使用了更大的输入patch,这可能不利于局部预测任务。
Predictor Visualizations
Predictor在I-JEPA中的作用是获取context encoder的输出,并以添加了position encoding的mask tokens为条件,在mask tokens指定的位置预测目标的表示。一个很自然的问题是,以position mask tokens为条件的predictor是否正在学习正确捕获目标中的位置不确定性,基于此,本实验将predictor的输出可视化。为了进行可视化,本实验在预训练后冻结了context encoder和predictor的权重,训练一个遵循RCDM框架的decoder,其可将predictor输出映射回像素空间。

上图显示了不同随机种子设置下的decoder输出。观察到,I-JEPA的predictor可以正确捕获位置的不确定性,并生成了具有正确姿态的高级对象部件(如鸟背和车顶)。
Ablations
Predicting in representation space
本文推测I-JEPA的一个关键组成部分是其loss完全在表示空间中计算,从而使target encoder能够产生抽象的预测目标,消除不相关的像素级细节。故本实验通过在像素空间和表示空间分别计算损失,来观察1%ImageNet-1K上的线性检测性能,以进行消融。

结果如上表,观察到在像素空间中进行预测会导致线性探测性能的显著下降。
Masking strategy
本实验消融target mask策略。实验对比了I-JEPA使用的multi mask与其他mask策略下的top 1%性能,如rasterized mask(图像被分成四个大象限,目标是使用一个象限作为context来预测其他三个象限)、block mask以及random mask。

结果如上表,观察到multi mask有助于指导I-JEPA学习语义表示。
Appendix
Pretraining Details
Architectures
I-JEPA的context encoder、target encoder和predictor都使用VisionTransformer(ViT)架构。其中context encoder和target encoder使用标准的ViT,predictor为轻量级ViT。predictor的嵌入维度固定为384,自注意力头的数量与context encoder的相等。
对于context encoder-ViT-B/16,对应的predictor的深度为6。对于context encoder-ViT-l/16、ViT-h/16和ViT-h/14,对应的predictor的深度为12,context encoder-ViT-G/16使用深度16的predictor。I-JEPA没有预训练[cls] token。最后,使用target-encoder进行评估,并平均池化其输出以产生全局图像表示。
Optimization
本文使用AdamW优化context encoder和predictor的权重,默认的batch-size为2048,在预训练的前15个epoch中,学习率从 1 0 − 4 10^{−4} 10−4线性增加到 1 0 − 3 10^{−3} 10−3,此后按照余弦退火衰减到 1 0 − 6 10^{−6} 10−6。整个预训练期间,权重衰减从0.04线性增加到0.4。
Target encoder权重在初始化时与context encoder权重相同,此后通过EMA进行更新。使用的动量值为0.996,并在整个预训练期间线性增加到1.0。
Additional Ablations
Multiblock masking strategy



本实验对multi mask策略进行了扩展消融,改变了target尺度(表8)、context尺度(表9)和target数量(表10),基于此使用I-JEPA训练了多个ViT-B/16,epoch为300,并使用线性检测在1%ImageNet-1K基准上比较了性能。发现使用相对较大的target和信息量充足的(空间分布的)context很重要。
Masking at the output of the target-encoder

在I-JEPA中,一个重要的设计是通过masked target encoder的输出而不是输入来获得target blocks。上表为使用I-JEPA预训练300个epoch的ViT-h/16时,这种设计选择对学习表征的语义水平的影响。观察到,在预训练期间对target encoder的输出进行mask,会产生更语义化的预测目标,并提高线性检测性能。
Predictor depth

上表实验predictor的深度对下游low-shot性能的影响,本实验使用了6层predictor或12层predictor预训练500个epoch的ViT-L/16。观察到,与使用较浅的predictor相比,使用较深的predictor在下游low-shot性能显示出显著的提高。
Weight decay

上表评估了预训练期间权重衰减策略的影响。实验了两种权重衰减策略,将权重衰减从0.04线性增加到0.4以及权重衰减固定为0.05。观察到,在预训练期间使用较小的权重衰减,在微调时可以提高ImageNet-1%的下游性能。然而,这也导致了在线性评估的性能下降。本文使用第一种权重衰减策略,因为其提高了线性评估下游任务的性能。
Predictor width

上表实验了predictor 宽度的影响。对比了使用386通道的predictor和使用1024通道的predictor的I-JEPA的线性评估性能。观察到,限制predictor的宽度可以将ImageNet的下游任务性能提高1%。
Finetuning on the full ImageNet
本节报告了对完整ImageNet数据集进行微调时I-JEPA的性能,模型主要采用 V i T − H / 1 6 448 ViT-H/16_{448} ViT−H/16448,因为该架构通过MAE实现了最先进的性能。
具体,使用AdamW和余弦学习率计划对I-JEPA进行50个epoch的微调,基础学习率设置为
1
0
−
4
10^{−4}
10−4,batch size为528,另外使用了0.8的mixup设置,1.0的cutmix,0.25的drop path,0.04的权重衰减和0.75的layer decay,以及使用了与MAE相同的rand-augment数据增强方法。

微调结果如上表。尽管I-JEPA的训练次数比MAE少5.3倍,但I-JEPA达到87.1的top-1精度,其性能与最佳MAE模型相差不到1%。这个结果表明,在对整个ImageNet数据集进行微调时,I-JEPA具有竞争力。
Encoder Visualization

上图可视化了target encoder-ViT-h/14的输出。第一列为原始图像,后续列为将图像的平均池化表示与多种随机噪声向量输入decoder获得的生成样本。观察到,I-JEPA的target encoder能够正确捕获有关物体及其姿态的高级信息,同时丢弃图像的低级细节和背景信息。

上图为类似的可视化效果,但使用了MSN预训练的target encoder-ViT-L/7计算图像表示。观察到,虽然MSN预训练网络能够捕获关于原始图像的高级语义信息,但它在生成的样本中也表现出更高的可变性,例如,对象姿态、对象规模和实例数量的可变性。简而言之,MSN预训练丢弃了图像中的大部分局部结构,而I-JEPA可保留输入图像大部分局部结构的信息。
reference
Mahmoud, A. , Quentin, D. , Ishan, M. , Piotr, B. , Pascal, V. , Michael, R. , Yann, L. , & Nicolas, B. . (2023). Self-Supervised Learning from Images with a Joint-Embedding Predictive Architecture.