案例背景
偶然之间找到了CSFP(中国家庭追踪调查)的数据集,一个很全的家庭调查数据集。所以就想对大家现在最关心的工资和其影响因素做一点分析。
得到的结论还挺有价值的,有符合逻辑的,也有反直觉的。
数据来源
CFPS由北京大学中国社会科学调查中心(ISSS)实施。项目采用计算机辅助调查技术开展访问,以满足多样化的设计需求,提高访问效率,保证数据质量,是北京大学和国家自然基金委资助的重大项目。
中国家庭追踪调查(China Family Panel Studies,CFPS)旨在通过跟踪收集个体、家庭、社区三个层次的数据,反映中国社会、经济、人口、教育和健康的变迁,为学术研究和公共政策分析提供数据基础。
CFPS重点关注中国居民的经济与非经济福利,以及包括经济活动、教育成果、家庭关系与家庭动态、人口迁移、健康等在内的诸多研究主题,是一项全国性、大规模、多学科的社会跟踪调查项目。CFPS样本覆盖25个省/市/自治区,目标样本规模为16000户,调查对象包含样本家户中的全部家庭成员。CFPS在2008、2009两年在北京、上海、广东三地分别开展了初访与追访的测试调查,并于2010年正式开展访问。经2010年基线调查界定出来的所有基线家庭成员及其今后的血缘/领养子女将作为CFPS的基因成员,成为永久追踪对象。CFPS调查问卷共有社区问卷、家庭问卷、成人问卷和少儿问卷四种主体问卷类型,并在此基础上不断发展出针对不同性质家庭成员的长问卷、短问卷、代答问卷、电访问卷等多种问卷类型。
当然这个数据集是经典的经管类的计量软件stata的文件,所以没装stata还不好打不开看它长什么样.....而且数据集没有清洗过,很难直接使用。如图:
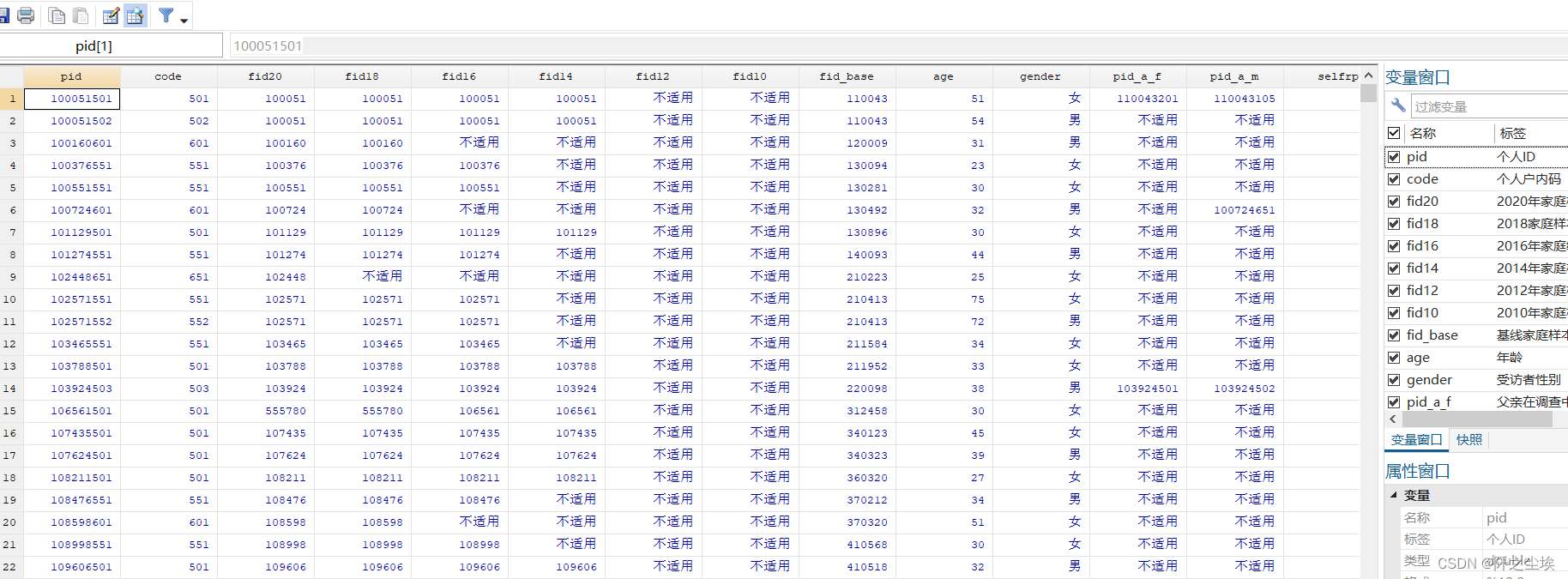
1312多个变量,而且很多有缺失值,想从中选择需要的变量还是很困难的。
当然本文会带大家从清洗到整理到分析全流程,都是用python完成的,excel都不需要。python可以直接读取stata、spss等数据软件常用的文件。
需要本文全部代码和CSFP的数据集,还有清洗出来的数据可以参考:CSFP工资收入数据集
代码实现
数据读取
开始还是先导入数据分析常用的四件套
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
plt.rcParams ['font.sans-serif'] ='SimHei' #显示中文
plt.rcParams ['axes.unicode_minus']=False #显示负号读取stata文件,直接pandas读取:
# 读取Stata文件的元数据
metadata = pd.io.stata.StataReader('cfps2020person_202306.dta')
# 获取变量标签的字典
variable_labels = metadata.variable_labels()
for var, label in variable_labels.items():
print(f"Variable '{var}' has label '{label}'")
这样就打印出来的所有的数据变量和其对应的中文标签。
为什么要打印中文....因为只看英文简称我也不知道这个变量代表什么意思....需要从中文来看,然后选择需要的变量标签和对应的名称。
我们需要从中选择自己需要的变量,我大概选了这几种:
a=['工作总收入(元/年)','每周工作时间(小时/周)','雇主性质','雇主是个体工商户','是否有编制','工作地点','工作收入满意度',
'工作时间满意度','一般工作7的单位/雇主性质','加载变量:受访者性别','加载变量:最近一次调查最高学历','年龄',
'上哪类初中','上哪类高中','上哪类大专','上哪类本科','读硕士是脱产还是在职'
,'读博士是脱产还是在职','是否小学毕业','是否初中毕业'
,'是否高中毕业','是否大专毕业','是否本科毕业','是否硕士毕业','是否博士毕业','当前婚姻状态',]然后过滤一下:
filtered_labels = {key: value for key, value in variable_labels.items() if value in a}读取正式数据
df=pd.read_stata('cfps2020person_202306.dta',convert_categoricals=False).replace('不适用',np.nan)\
.replace(-8,np.nan).replace(-1,np.nan).replace(77,np.nan).replace(-2,np.nan)
df.head()
只展示了前五行,有1312个变量。
自定义一个过滤缺失值的函数,如果某个变量这一列的缺失值达到90%的比例,就删除这个变量。
def remove_columns_with_missing_values(df, threshold):
"""
删除缺失值达到指定比例的列
参数:
df: pandas DataFrame
threshold: float, 缺失值比例阈值
"""
# 计算每列的缺失值比例
missing_ratio = df.isnull().sum() / len(df)
# 找到缺失比例大于或等于阈值的列
columns_to_drop = missing_ratio[missing_ratio >= threshold].index
# 删除这些列
df_dropped = df.drop(columns=columns_to_drop)
return df_dropped过滤选择的变量,删除缺失值的变量。查看信息:
df=df[filtered_labels.keys()]
df1=remove_columns_with_missing_values(df, threshold=0.9)
df1.info(0)
有很多还是有缺失值的,例如qg12,我们看看对应的中文名称:
### 查看对应的中文标签
{key: value for key, value in variable_labels.items() if key in df1.columns} 
修改一下名称:
df1=df1.set_axis(['年龄','性别','最高学历','婚姻状态','雇主性质','工作地点','工作收入满意度','工作时间满意度','每周工作时间(小时/周)','工作总收入(元/年)'],axis=1)### 查看每个变量的变量信息
### 查看每个变量的变量信息
for col in df1.columns:
print(df1[col].value_counts(),end='\n=====================================\n')
对应的是数值,所以我去官网查了每一个数据对应的含义:
受访者性别
- (1=男;0=女)
最高学历
- 0.文盲/半文盲 3.小学 4.初中 5.高中/中专/技校/职 6.大专 7.大学本科 8.硕士 9.博士
婚姻状态
- 1.未婚 2. 有配偶(在婚)3.同居 4.离婚 5.丧偶
雇主性质
-
- 政府部门/党政机关/人民团体 2. 事业单位 3. 国有企业 4. 私营企业/个体工商户 5. 外商/港澳台商企业
- 6.其他类型企业 7.个人/家庭 8. 民办非企业组织/协会/行会/基金会/村居委会 9. 无法判断
工作地点
-
- 当前居住村/居 2. 当前居住乡/镇/街道的其他村/居 3. 当前居住县/市的其他乡/镇/街道 4. 当前居住市/区的其他县/市
-
- 当前居住省份的其他市/区 6. 境内的其他省份 7. 境外(含港、澳、台) 8. 无固定工作地点
工作收入满意度
-
- 非常不满意 2. 不太满意 3. 一般【不读出】 4. 比较满意 5. 非常满意
工作时间满意度
-
- 非常不满意 2. 不太满意 3. 一般【不读出】 4. 比较满意 5. 非常满意
数据清洗
简单清洗一下,清洗逻辑是行,如果一行的数据缺失比例达到30%,就删除这一行。
def remove_rows_with_missing_values(df, threshold):
"""
删除缺失值达到指定比例的行
参数:
df: pandas DataFrame
threshold: float, 缺失值比例阈值
"""
# 计算每行的缺失值比例
missing_ratio_per_row = df.isnull().mean(axis=1)
# 找到缺失比例小于阈值的行
rows_to_keep = missing_ratio_per_row < threshold
df_filtered = df[rows_to_keep]
return df_filtered
df2=remove_rows_with_missing_values(df1,0.3)df2.info()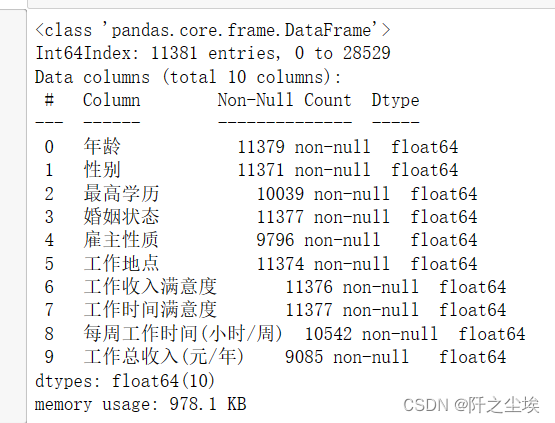
数据删除到了只有11381行。
缺失值填充一下:年龄用均值填充,其他类别变量用众数填充。
# 对'年龄'使用均值进行填充
df2['年龄'].fillna(df2['年龄'].mean(), inplace=True)
# 对其他字段使用众数进行填充
for column in ['性别', '最高学历', '婚姻状态', '雇主性质', '工作地点', '工作收入满意度', '工作时间满意度']:
mode_value = df2[column].mode()[0] # 取众数的第一个值,因为众数可能返回多个结果
df2[column].fillna(mode_value, inplace=True)对于每周工作时间(小时/周)和 工作总收入(元/年)填充要仔细一点,因为是后面要用的因变量。
填充策略是相似的进行填充,即对于有缺失值的就用 ['性别', '最高学历', '婚姻状态', '雇主性质']一样的组的变量均值进行填充。
def fill_missing_with_group_mean(df, target_column, group_columns):
"""
使用分组均值填充目标列的缺失值
参数:
df: pandas DataFrame
target_column: str, 要填充缺失值的列名
group_columns: list, 用于分组的列名列表
"""
def fill_with_mean(x):
mean = x.mean()
if pd.isna(mean): # 如果均值是NaN,则不进行填充
return x
return x.fillna(mean)
# 计算每个组的均值,并用这个均值填充相应组内的缺失值
filled_df = df.copy()
filled_df[target_column] = filled_df.groupby(group_columns)[target_column].transform(fill_with_mean)
return filled_df
# 应用函数到你的DataFrame
df3= fill_missing_with_group_mean(df2, '工作总收入(元/年)', ['性别', '最高学历', '婚姻状态', '雇主性质'])
df3= fill_missing_with_group_mean(df3, '每周工作时间(小时/周)', [ '性别', '最高学历', '婚姻状态', '雇主性质']).dropna()
df3.info()
现在没有缺失值了。
数据备份一下:data用于分析,df3用于画图。
data=df3.copy()数据分析
描述性统计画图
由于里面都是数值变量,我们不能直观的查看其中文含义,所以要映射一下:
gender_map = {1: '男', 0: '女'}
education_map = {1: '文盲', 2: '半文盲', 3: '小学', 4: '初中', 5: '高中/中专/技校/职',
6: '大专', 7: '大学本科', 8: '硕士', 9: '博士'}
marital_status_map = {1: '未婚', 2: '有配偶(在婚)', 3: '同居', 4: '离婚', 5: '丧偶'}
employer_nature_map = {1: '政府部门/党政机关/人民团体', 2: '事业单位', 3: '国有企业',
4: '私营企业/个体工商户', 5: '外商/港澳台商企业', 6: '其他类型企业',
7: '个人/家庭', 8: '民办非企业组织/协会/村居委会', 9: '无法判断'}
work_location_map = {1: '当前居住村/居', 2: '当前居住乡/镇/街道的其他村/居',
3: '当前居住县/市的其他乡/镇/街道', 4: '当前居住市/区的其他县/市',
5: '当前居住省份的其他市/区', 6: '境内的其他省份', 7: '境外(含港、澳、台)',
8: '无固定工作地点'}
satisfaction_map = {1: '非常不满意', 2: '不太满意', 3: '一般', 4: '比较满意', 5: '非常满意'}
# 映射标签
df3['性别'] = df3['性别'].map(gender_map)
df3['最高学历'] = df3['最高学历'].map(education_map)
df3['婚姻状态'] = df3['婚姻状态'].map(marital_status_map)
df3['雇主性质'] = df3['雇主性质'].map(employer_nature_map)
df3['工作地点'] = df3['工作地点'].map(work_location_map)
df3['工作收入满意度'] = df3['工作收入满意度'].map(satisfaction_map)
df3['工作时间满意度'] = df3['工作时间满意度'].map(satisfaction_map)然后对年龄,收入,时间,这三个数字变量画箱线图:
# 1*3的箱线图
plt.figure(figsize=(12,5),dpi=128) # 设置画布大小
plt.subplot(1, 3, 1) # 第一个子图
sns.boxplot(y=df3['年龄'])
plt.title('年龄分布')
plt.subplot(1, 3, 2) # 第二个子图
sns.boxplot(y=df3['每周工作时间(小时/周)'])
plt.title('每周工作时间分布')
plt.subplot(1, 3, 3) # 第三个子图
sns.boxplot(y=df3['工作总收入(元/年)'])
plt.title('工作总收入分布')
plt.tight_layout()
plt.show() 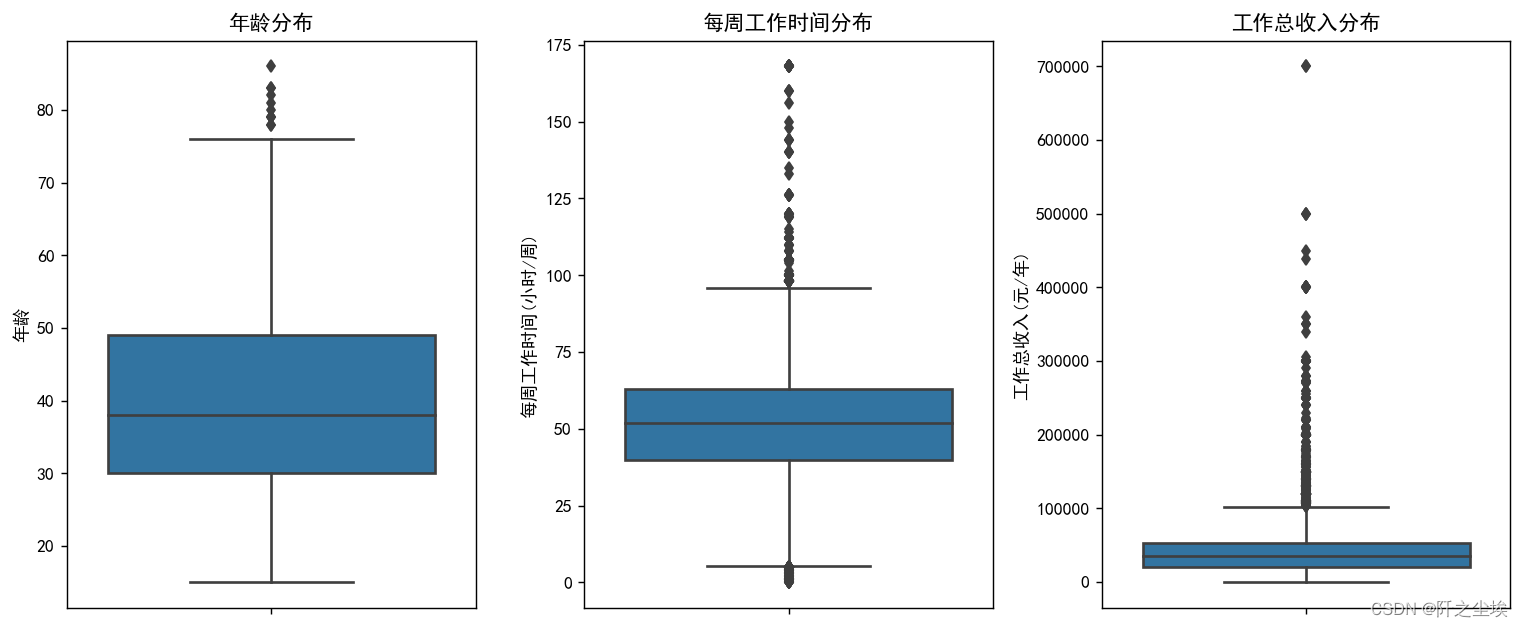
可以看到年龄中位数大概在38左右(中国人不再年轻),有一些极大值,说明问卷调查了很多老人。
工作时间也是,中位数在51小时附近。(这和韩国不是一模一样吗....) 中国人每周工作时间还是太长了,而且也有很多异常值在100小时以上的。。那不是每天要工作15小时以上??.........
工作总收入分布,中位数在3.6w附近。说明绝大多数中国人月收入不足3000, 并且也有很多异常值,年收入到10W以上的已经可以说超越了很多人了,但是收入分布明显极大值很多,典型的右偏分布,贫富差异较大。
对性别,最高学历,婚烟状况画饼图:
gender_counts = df3['性别'].value_counts()
education_counts = df3['最高学历'].value_counts()
marital_status_counts = df3['婚姻状态'].value_counts()
# Create subplots
fig, axes = plt.subplots(1, 3, figsize=(12,5),dpi=128)
# Gender distribution pie chart
axes[0].pie(gender_counts, labels=gender_counts.index, autopct='%1.1f%%', startangle=90)
axes[0].set_title('性别分布')
axes[0].axis('equal') # Equal aspect ratio ensures that pie is drawn as a circle.
# Education level distribution pie chart
axes[1].pie(education_counts, labels=education_counts.index, autopct='%1.1f%%', startangle=90)
axes[1].set_title('最高学历分布')
axes[1].axis('equal')
# Marital status distribution pie chart
axes[2].pie(marital_status_counts, labels=marital_status_counts.index, autopct='%1.1f%%', startangle=90)
axes[2].set_title('婚姻状态分布')
axes[2].axis('equal')
# Show plot
plt.tight_layout()
plt.show()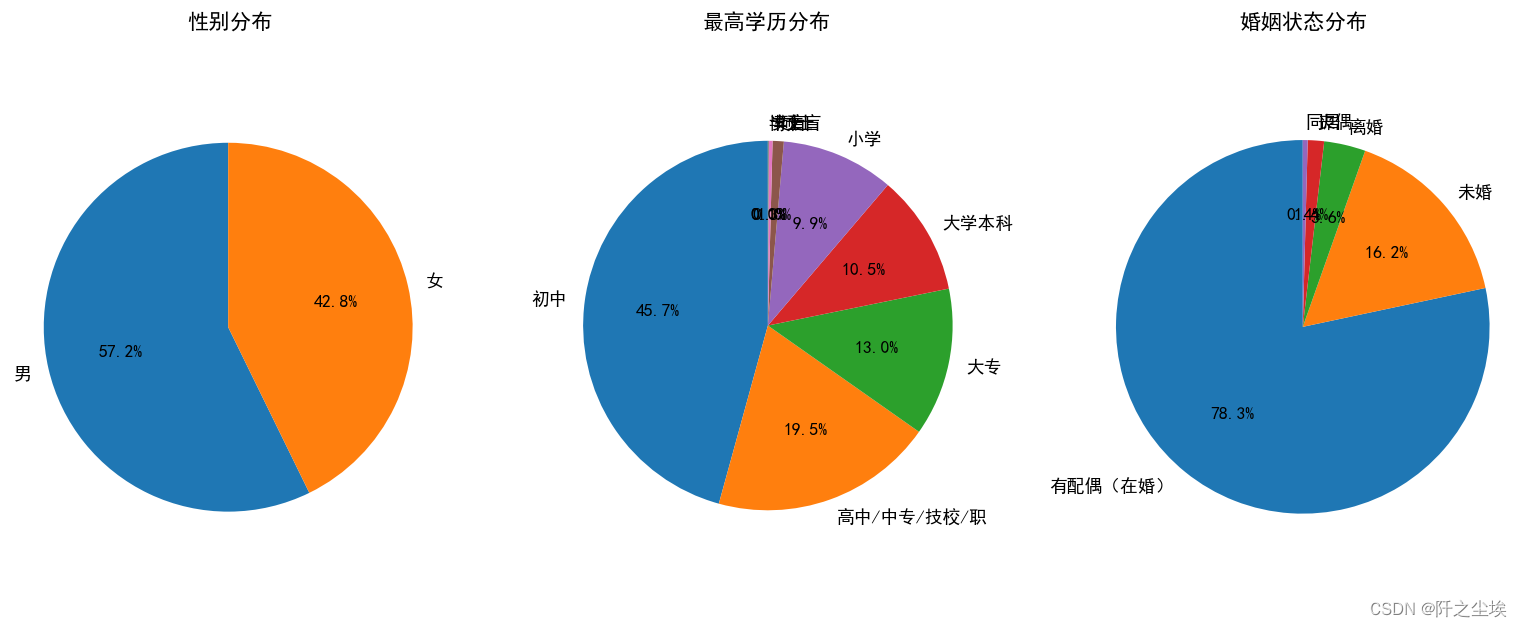
调查中的男性偏多,也可能反映了我国男女比例不平衡的问题。由于是家庭数据,所以已婚人士还是更多,在学历上,大部分人都是初中和高中,本科研究生博士太少,纯文盲也少。
其余变量画柱状图:
plt.figure(figsize=(10,7),dpi=128) # 新的画布
plt.subplot(2, 2, 1) # 第一个子图
sns.countplot(x='雇主性质', data=df3)
plt.xticks(rotation=90)
plt.title('雇主性质分布')
plt.subplot(2, 2, 2) # 第二个子图
sns.countplot(x='工作地点', data=df3)
plt.xticks(rotation=90)
plt.title('工作地点分布')
orders=['非常不满意', '不太满意', '一般', '比较满意', '非常满意']
plt.subplot(2, 2, 3) # 第三个子图
sns.countplot(x='工作收入满意度', data=df3,order=orders)
#plt.xticks(rotation=20)
plt.title('工作收入满意度')
plt.subplot(2, 2, 4) # 第四个子图
sns.countplot(x='工作时间满意度', data=df3,order=orders)
#plt.xticks(rotation=20)
plt.title('工作时间满意度')
plt.tight_layout() # 自动调整
首先是雇主单位,绝大多数人都是私企,然后从业最多的是国企。
工作地点来看,大部分人都会选择和自己附近的的市和县工作。
工作收入和时间满意度来看,大部分人还是比较满意的,一般和不太满意的人也较多。非常不满意的人较少。
我们下面分组聚合分析一下,我们来看看对收入满意程度不一样的人们的收入平均水平式怎么样的:(一行代码就能得到分析的图表的写法还是值得吹嘘一些)
df3.groupby(['工作收入满意度']).mean().loc[orders,:].style.bar(align='mid', color=['#d65f5f', '#5fba7d'])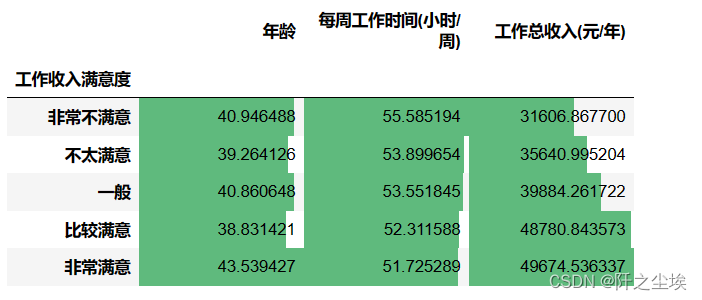
可以看到,对工资越满意的人一般工资越高。而且工作时间也越少。
df3.groupby(['工作时间满意度']).mean().loc[orders,:].style.bar(align='mid', color=['#491256', '#525a99'])
可以看到,对工作时间越满意的人一般工作时间也越少,工作收入也较多。
我们再来看看不同雇主性质下的工作收入情况:
df3.groupby(['雇主性质']).mean().sort_values('工作总收入(元/年)').style.bar(align='mid', color=['#491256', '#882288'])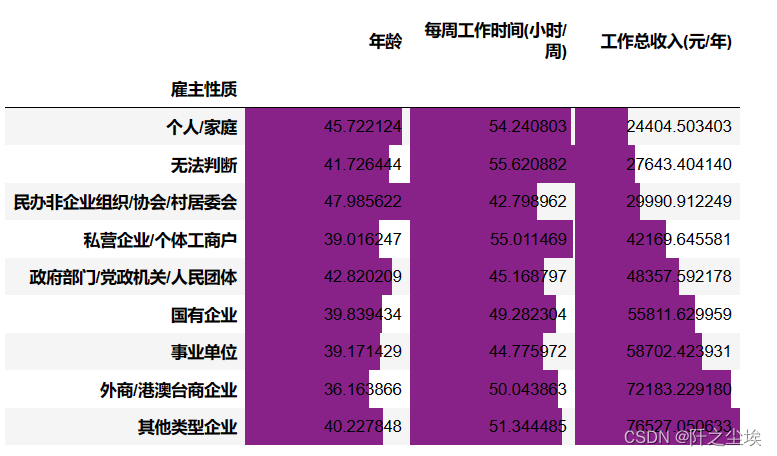
我按照工作收入高低排了个序,虽然均值方法可能会受到异常值的影响,但是它还是充分的反映了数据的信息:
工资收入角度来看,个人家庭最低,然后是民间的一些组织,再就是绝大多数人就业的私企。
后面依次是政府部门,国有企业,事业单位,然后再才是外企。其他类型企业工资收入最高,其他企业指的是啥我也不太了解,可能是自己开公司的老板吧。
很明显嘛,事业单位工资>=国企>政府部门>私企。更别说体制内还有很多隐形的工资补贴福利等。
工作时间的角度来看也是私企遥遥领先....996文化不是没道理的,工作时间:私企远大于>国企>政府部门>=事业单位。
逃离私企进入体制内是有原因的,工作时间少一些,工资还高一些,所以啊,宇宙的尽头是编制。
性别和收入的影响
df3.groupby(['性别']).mean().sort_values('工作总收入(元/年)').style.bar(align='mid', color=['#491256', 'yellow'])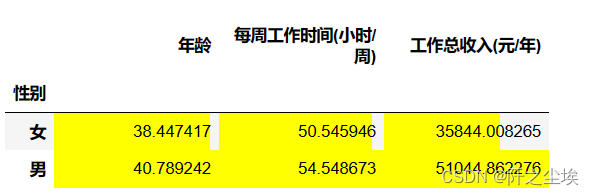
可能中国很多女性还是家庭主妇,所以男性工资普遍比女性高,工作时间也久一点。也侧面反映了文化的问题和职场可能存在的性别歧视。
学历对工资影响
df3.groupby(['最高学历']).mean().sort_values('工作总收入(元/年)').style.bar(align='mid', color=['#491256', 'tomato'])
没什么好说的,学历越高工资越高,本科平均7.8w一年,硕士平均13w一年,博士也才不到15w一年,要知道博士也起码是3年4年起步,所以从性价比来看,读博士工资增长没有读硕士那么明显。
值得一提的是学历越高,工作时间也越少,但是到博士这里有比本科生时间还长。(所以 '读博就是当牛马' 明白这句话的含义了吧.......)
婚姻状况和工作
df3.groupby(['婚姻状态']).mean().sort_values('工作总收入(元/年)').style.bar(align='mid', color=['#491256', 'skyblue']) 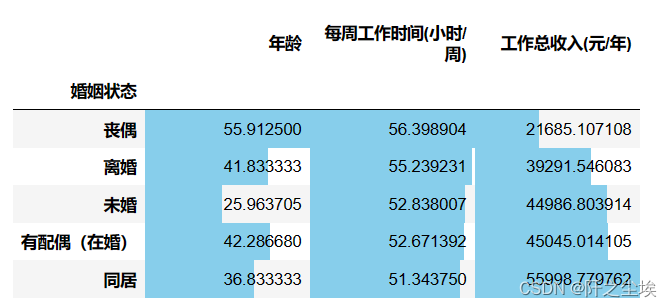
丧偶和离婚的人年龄都比较大,工资也不高。未婚平均年龄最小,25岁,已婚平均年龄42,平均工资也就比未婚多一点点。最离谱的是同居但不结婚的人群平均年龄在36,而且收入超级高。。遥遥领先结婚和没结婚的,看来有钱的单身享乐主义还是很多的....
回归分析
查看变量名称
data.columns
选择自变量X和因变量y,
我们选择 ['年龄', '性别', '最高学历', '婚姻状态', '雇主性质', '工作地点', '每周工作时间(小时/周)']作为X,研究他们对 '工作总收入(元/年)' 作为y 的影响
import statsmodels.api as sm
X = data.drop(['工作总收入(元/年)','工作收入满意度', '工作时间满意度'], axis=1)
y = data['工作总收入(元/年)']
# 因为使用的是 OLS 回归,需要添加常数项
X = sm.add_constant(X)
# 创建模型并拟合
model = sm.OLS(y, X).fit()
# 打印结果
model.summary() 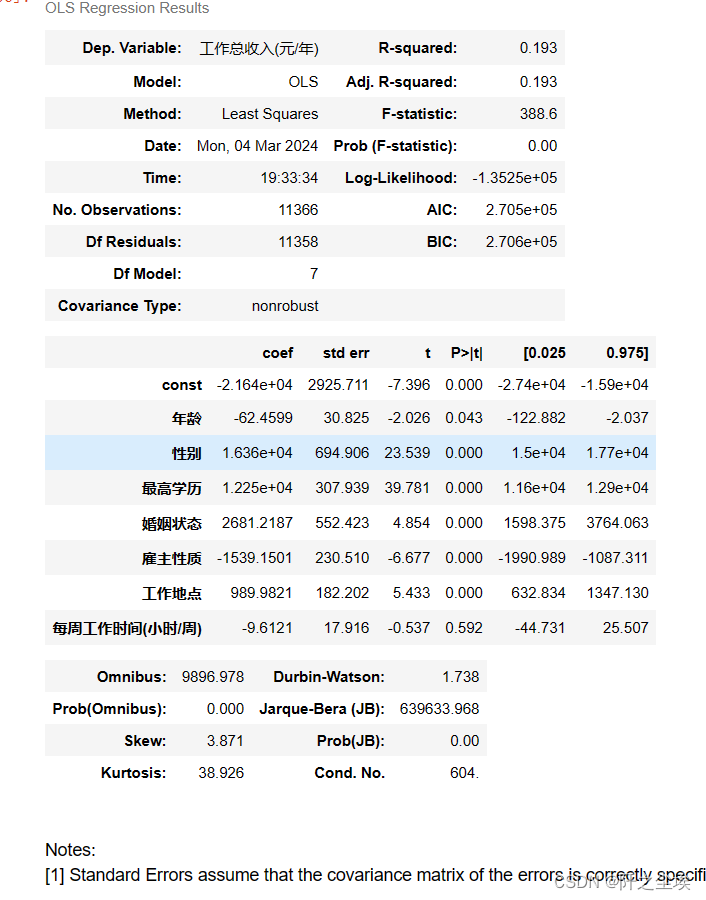
直接上分析和结论吧:(我懒得打字,就gpt写的....)
模型的解释力:
R-squared 值为0.193,说明模型能解释目标变量(工作总收入)19.3%的变异性。虽然这个值不是非常高,但对于社会科学和经济学数据来说是常见的,因为人类行为和经济活动通常受到多种因素的影响。 Adj. R-squared 也是0.193,这意味着在考虑自由度(模型复杂度)之后,模型的解释力基本没有变化。
模型整体的显著性:
F-statistic 为388.6,与之对应的 Prob (F-statistic) 几乎为0(通常表示小于0.01),这表明模型整体是统计显著的,即至少有一个预测变量对目标变量有显著影响。
各个变量的影响:
- 年龄: 系数为-62.4599,p值为0.043,表明年龄与工作总收入呈负相关,且这种关系是统计显著的。这意味着随着年龄的增长,工作总收入可能会略有下降。
- 性别: 系数为16360,p值接近0,显示性别对工作总收入有显著的正影响。性别变量是以男性为1女性为0,这意味着男性的平均工作总收入比女性高。
- 最高学历: 系数为12250,p值接近0,表示最高学历水平对工作总收入有显著正影响,即教育水平越高,工作总收入越高。
- 婚姻状态: 系数为2681.2187,p值为0.000,说明婚姻状态对工作总收入有正面影响。
- 雇主性质: 系数为-1539.1501,p值接近0,表明雇主性质与工作总收入呈负相关,即某些雇主性质的工作可能比其他类型的工作收入要低。
- 工作地点: 系数为989.9821,p值接近0,显示工作地点对工作总收入有显著的正影响。
- 每周工作时间(小时/周): 系数为-9.6121,但p值为0.592,表明每周工作时间与工作总收入之间没有显著的关系。
模型诊断:
Durbin-Watson 统计量为1.738,接近2,表明残差之间没有明显的自相关。 Omnibus 和 Jarque-Bera 测试的p值接近0,表明残差不符合正态分布,这在大样本中很常见,但可能影响某些统计测试的有效性。 Skewness 和 Kurtosis 表示残差分布的偏度和峰度,这里显示有很高的偏度和峰度,说明数据可能有异常值或者分布不均。
结论
(作者补充结论)
- 这个模型揭示了性别、最高学历、婚姻状态、雇主性质和工作地点与个人的工作总收入有显著相关性。
- 值得注意的是,性别和最高学历对收入的正面影响尤为显著,这可能反映了教育程度和性别差异在职场上的重要性。
- 其中对每个变量的结论为:
- 年龄变量 刚好迈过显著性的门槛,也就是年龄增长,工作收入会略微下降。
- 男性比女性在职场上拥有更高的平均收入
- 学历更高的人工作收入越高。
- 结婚的人比没结婚的人工作收入更高(ps:没收入的人当然不敢结婚)
- 雇主性质系数为负,意味着你的工作单位如果离政府部门国企事业单位越来越远,越来越民间化,那么你的工资是越来越低的。(政府部门国企事业单位的工资是最高的(而且还没算福利什么))
- 事业单位工资>=国企>政府部门>私企。更别说体制内还有很多隐形的工资补贴福利等。工作时间的角度来看也是私企遥遥领先....996文化不是没道理的,工作时间:私企远大于>国企>政府部门>=事业单位。逃离私企进入体制内的问候潮流是有原因的,工作时间少一些,工资还高一些,所以啊,宇宙的尽头是编制。
- 工作地点为正显著性,意味着你去的地方平台越大,工资会越高。
- 工作时间是最反直觉的,居然不显著.说明工作时间长的打工人并没有得到更高的工资。而且系数还是负数(细品...)
- 并且工作时长对工资的影响居然不具备显著性,说明现在工作时长多的人得不到更高工资的回报
- 然而,模型的整体解释力相对有限,这提示我们在理解工作总收入时还有其他未考虑的因素。
- 此外,数据的偏度和峰度表明,在进行回归分析时可能需要考虑数据转换或其他方法来处理异常值和非正态分布的问题。
后记
工作的收入是大家都很关注的东西,所以我觉得本研究也具有一定的社会意义。
这只是用这个数据集做的很简单和粗糙的一个分析哈,用的是最简单的回归分析模型和一点描述性统计方法。麻烦在数据处理的部分,其实我很多位置都偷懒了.....包括结论分析也没写得很深入,(再深入了就不能说了.....),但是这个流程和结论分析发个C刊写个本科毕业论文还是没问题的。
改进的地方,例如可以对年龄或者工作时间等数值变量进行分区处理然后再分组聚合研究,婚姻状况这个变量也和数值含义不是很对应。填充缺失值的清洗策略有待商榷,还可以做得更好。回归模型的拟合优度只有19,所以肯定还有超级多的变量可以纳入模型考虑。
并且也没有对回归模型做一些检验等等,也没有探究多重共线性,残差正态性等等问题,具体可以在CSFP里面找更多的变量,做多阶段最小二乘,引入工具变量,使用因果检验等手段和高级模型进行处理和改进。
创作不易,看官觉得写得还不错的话点个关注和赞吧,本人会持续更新python数据分析领域的代码文章~