原文:Learn Python the Hard Way, 5th Edition (Early Release)
译者:飞龙
协议:CC BY-NC-SA 4.0
练习 19:函数和变量
现在你将把函数与你从之前练习中了解到的变量结合起来。如你所知,变量给数据片段一个名称,这样你就可以在程序中使用它。如果你有这段代码:
1 x = 10
然后你创建了一个名为x的数据片段,它等于数字 10。
你还知道你可以像这样带参数调用函数:
1 def print_one(arg1):
2 print(f"arg1: {arg1}")
参数arg1是类似于之前的x的变量,只是当你像这样调用函数时为你创建:
1 print_one("First!")
在练习 18 中,你学习了当你调用函数时 Python 如何运行它们,但如果你这样做会发生什么:
1 y = "First!"
2 print_one(y)
不直接使用"First!"调用print_one,而是将"First!"赋给y,然后将y传递给print_one。这样会起作用吗?这里有一小段代码示例,你可以在 Jupyter 中测试一下:
1 def print_one(arg1):
2 print(f"arg1: {arg1}")
3
4 y = "First!"
5 print_one(y)
这展示了如何将变量的概念y = "First!"与调用使用这些变量的函数相结合。在进行这个较长的练习之前,研究这个并尝试自己的变化,但首先给一点建议:
-
这个很长,如果你在 Jupyter 中觉得难以管理,那么尝试将其输入到一个
ex19.py文件中在终端中运行。 -
通常情况下,你应该一次只输入几行代码,但如果你只输入函数的第一行,你会遇到问题。你可以使用
pass关键字来解决这个问题,像这样:def some_func(some_arg): pass。pass关键字是用来创建一个空函数而不会引发错误的方法。 -
如果你想看到每个函数在做什么,你可以使用“调试打印”像这样:
print(">>>> 我在这里", something)。这将打印出一条消息,帮助你“跟踪”代码并查看每个函数中的something是什么。
列表 19.1:ex19.py
1 def cheese_and_crackers(cheese_count, boxes_of_crackers):
2 print(f"You have {cheese_count} cheeses!")
3 print(f"You have {boxes_of_crackers} boxes of crackers!")
4 print("Man that's enough for a party!")
5 print("Get a blanket.\n")
6
7
8 print("We can just give the function numbers directly:")
9 cheese_and_crackers(20, 30)
10
11
12 print("OR, we can use variables from our script:")
13 amount_of_cheese = 10
14 amount_of_crackers = 50
15
16 cheese_and_crackers(amount_of_cheese, amount_of_crackers)
17
18
19 print("We can even do math inside too:")
20 cheese_and_crackers(10 + 20, 5 + 6)
21
22
23 print("And we can combine the two, variables and math:")
24 cheese_and_crackers(amount_of_cheese + 100, amount_of_crackers + 1000)
你应该看到的内容
1 We can just give the function numbers directly:
2 You have 20 cheeses!
3 You have 30 boxes of crackers!
4 Man that's enough for a party!
5 Get a blanket.
6
7 OR, we can use variables from our script:
8 You have 10 cheeses!
9 You have 50 boxes of crackers!
10 Man that's enough for a party!
11 Get a blanket.
12
13 We can even do math inside too:
14 You have 30 cheeses!
15 You have 11 boxes of crackers!
16 Man that's enough for a party!
17 Get a blanket.
18
19 And we can combine the two, variables and math:
20 You have 110 cheeses!
21 You have 1050 boxes of crackers!
22 Man that's enough for a party!
23 Get a blanket.
学习练习
-
你记得一次只输入几行代码吗?在填充之前使用
pass创建一个空函数了吗?如果没有,删除你的代码然后重新做一遍。 -
将
cheese_and_crackers的名称拼错,然后查看错误消息。现在修复它。 -
删除数学中的一个
+符号,看看你会得到什么错误。 -
修改数学内容,然后尝试预测你将得到什么输出。
-
更改变量并尝试猜测这些更改后的输出。
常见学生问题
这个练习目前还没有问题,但你可以通过 help@learncodethehardway.org 向我提问以获取帮助。也许你的问题会出现在这里。
练习 20:函数和文件
记住函数的清单,然后在这个练习中要特别注意函数和文件如何一起工作以制作有用的东西。你还应该继续在运行代码之前只输入几行。如果发现自己输入了太多行,请删除它们然后重新输入。这样做可以使用python来训练你对 Python 的理解。
这是这个练习的代码。再次强调,如果你觉得 Jupyter 难以使用,那么写一个ex20.py文件并以这种方式运行它。
列表 20.1: ex20.py
1 from sys import argv
2
3 script, input_file = argv
4
5 def print_all(f):
6 print(f.read())
7
8 def rewind(f):
9 f.seek(0)
10
11 def print_a_line(line_count, f):
12 print(line_count, f.readline())
13
14 current_file = open(input_file)
15
16 print("First let's print the whole file:\n")
17
18 print_all(current_file)
19
20 print("Now let's rewind, kind of like a tape.")
21
22 rewind(current_file)
23
24 print("Let's print three lines:")
25
26 current_line = 1
27 print_a_line(current_line, current_file)
28
29 current_line = current_line + 1
30 print_a_line(current_line, current_file)
31
32 current_line = current_line + 1
33 print_a_line(current_line, current_file)
注意每次运行print_a_line时我们如何传入当前行号。在这个练习中没有什么新的。它有函数,你知道那些。它有文件,你也知道那些。只要花点时间,你就能理解。
你应该看到的内容
1 First let's print the whole file:
2
3 This is line 1
4 This is line 2
5 This is line 3
6
7 Now let's rewind, kind of like a tape.
8 Let's print three lines:
9 1 This is line 1
10
11 2 This is line 2
12
13 3 This is line 3
学习扩展
-
为每一行写英文注释以理解该行的作用。
-
每次运行
print_a_line时,你都会传入一个变量current_line。写出每个函数调用中current_line等于什么,并跟踪它如何变成print_a_line中的line_count。 -
找到每个函数被使用的地方,并检查其
def以确保你给出了正确的参数。 -
在线研究
file的seek函数是做什么的。尝试pydoc file,看看能否从中弄清楚。然后尝试pydoc file.seek来查看seek的作用。 -
研究
+=的简写表示法,并重写脚本以使用+=。
常见学生问题
print_all和其他函数中的f是什么? f就像你在练习 18 中的其他函数中一样,只是这次它是一个文件。在 Python 中,文件有点像主机上的旧磁带驱动器或者可能是 DVD 播放器。它有一个“读头”,你可以“寻找”这个读头在文件中的位置,然后在那里进行操作。每次你执行f.seek(0)时,你都在移动到文件的开头。每次你执行f.readline()时,你都在从文件中读取一行,并将读头移动到结束该行的\n之后。随着你的学习,这将会有更多解释。
为什么seek(0)不会将current_line设置为 0? 首先,seek()函数处理的是字节,而不是行。代码seek(0)将文件移动到文件中的第 0 字节(第一个字节)。其次,current_line只是一个变量,与文件没有真正的连接。我们是手动递增它。
+=是什么? 你知道在英语中我可以将“it is”重写为“it’s”吗?或者我可以将“you are”重写为“you’re”吗?在英语中,这被称为“缩略形式”,这有点像=和+两个操作的缩写。这意味着x = x + y与x += y是相同的。
readline() 如何知道每行在哪里?在 readline() 内部有代码扫描文件的每个字节,直到找到一个 \n 字符,然后停止读取文件并返回到目前为止找到的内容。文件 f 负责在每次 readline() 调用后维护文件中的当前位置,以便继续读取每一行。
文件中的行之间为什么有空行?readline() 函数返回文件中该行末尾的 \n。在 print 函数调用的末尾添加 end = "" 可以避免在每行末尾添加双重 \n。
练习 21:函数可以返回值
你一直在使用=字符来命名变量并将它们设置为数字或字符串。现在我们将再次让你大开眼界,向你展示如何使用=和一个新的 Python 词return来将变量设置为来自函数的值。有一件事要特别注意,但首先输入这个:
代码清单 21.1: ex21.py
1 def add(a, b):
2 print(f"ADDING {a} + {b}")
3 return a + b
4
5 def subtract(a, b):
6 print(f"SUBTRACTING {a} - {b}")
7 return a - b
8
9 def multiply(a, b):
10 print(f"MULTIPLYING {a} * {b}")
11 return a * b
12
13 def divide(a, b):
14 print(f"DIVIDING {a} / {b}")
15 return a / b
16
17
18 print("Let's do some math with just functions!")
19
20 age = add(30, 5)
21 height = subtract(78, 4)
22 weight = multiply(90, 2)
23 iq = divide(100, 2)
24
25 print(f"Age: {age}, Height: {height}, Weight: {weight}, IQ: {iq}")
26
27
28 # A puzzle for the extra credit, type it in anyway.
29 print("Here is a puzzle.")
30
31 what = add(age, subtract(height, multiply(weight, divide(iq, 2))))
32
33 print("That becomes: ", what, "Can you do it by hand?")
现在我们正在为add、subtract、multiply和divide做我们自己的数学函数。需要注意的重要一点是我们说的最后一行return a + b(在add中)。这样做的效果如下:
-
我们的函数被调用时带有两个参数:
a和b。 -
我们打印出我们的函数正在做的事情,在这种情况下是“ADDING”。
-
然后我们告诉 Python 做一些有点反向的事情:我们返回
a + b的加法。你可以这样说,“我将a和b相加然后返回它们。” -
Python 将这两个数字相加。然后当函数结束时,运行它的任何行都可以将
a + b的结果赋给一个变量。
就像本书中的许多其他内容一样,你应该慢慢来,分解问题,并尝试追踪发生了什么。为了帮助,有额外的练习来解决一个谜题并学到一些有趣的东西。
你应该看到的结果
1 Let's do some math with just functions!
2 ADDING 30 + 5
3 SUBTRACTING 78 - 4
4 MULTIPLYING 90 * 2
5 DIVIDING 100 / 2
6 Age: 35, Height: 74, Weight: 180, IQ: 50.0
7 Here is a puzzle.
8 DIVIDING 50.0 / 2
9 MULTIPLYING 180 * 25.0
10 SUBTRACTING 74 - 4500.0
11 ADDING 35 + -4426.0
12 That becomes: -4391.0 Can you do it by hand?
学习扩展
-
如果你不确定
return的作用,尝试编写一些自己的函数,并让它们返回一些值。你可以返回任何可以放在=右侧的东西。 -
脚本的结尾是一个谜题。我正在将一个函数的返回值作为另一个函数的参数。我正在以链式方式执行这个操作,所以我有点像使用函数创建一个公式。看起来很奇怪,但如果你运行脚本,你会看到结果。你应该尝试找出能够重新创建相同操作集的正常公式。
-
一旦你为谜题找到了公式,就深入其中,看看当你修改函数的部分时会发生什么。试着故意改变它以生成另一个值。
-
做相反的操作。编写一个简单的公式,并以相同的方式使用函数来计算它。
这个练习可能会让你的大脑混乱,但慢慢来,把它当作一个小游戏。像这样解决谜题是编程变得有趣的地方,所以在我们继续进行时,我会给你更多类似的小问题。
常见学生问题
为什么 Python 打印公式或函数“反向”? 它实际上不是反向的,而是“里外相反”。当你开始将函数分解为单独的公式和函数时,你会看到它是如何工作的。试着理解我所说的“里外相反”而不是“反向”。
我如何使用 input() 输入自己的值? 还记得int(input())吗?问题在于你无法输入浮点数,所以也尝试使用float(input())。
“写出一个公式”是什么意思? 尝试以24 + 34 / 100 - 1023为起点。将其转换为使用函数。现在想出你自己类似的数学方程,并使用变量使其更像一个公式。
练习 22:字符串、字节和字符编码
要完成这个练习,你需要下载一个我写的名为languages.txt的文本文件。这个文件是用人类语言列表创建的,以演示一些有趣的概念:
-
现代计算机如何存储人类语言以供显示和处理,以及 Python 3 如何称呼这些
字符串 -
你必须将 Python 的字符串“编码”和“解码”为一种称为
bytes的类型 -
如何处理字符串和字节处理中的错误
-
如何阅读代码并找出其含义,即使你以前从未见过它
你可以通过用鼠标右键单击并选择“下载”来可靠地下载这个文件。使用链接learnpythonthehardway.org/python3/languages.txt来下载这个文件。
此外,你将简要了解 Python 3 中的if 语句和列表,用于处理一系列事物。你不必立即掌握这段代码或理解这些概念。你将在后续练习中有足够的练习。现在你的任务是尝试未来并学习前述列表中的四个主题。
警告!
这个练习很难!里面有很多你需要理解的信息,而且这些信息深入到计算机内部。这个练习很复杂,因为 Python 的字符串很复杂且难以使用。我建议你慢慢来完成这个练习。写下你不理解的每个词,然后查找或研究它。如果必要,一段一段地进行。你可以在学习这个练习的同时继续进行其他练习,所以不要在这里卡住。只要花费足够长的时间逐步解决它。
初始研究
你将创建一个名为ex22.py的文件,并在 shell 中运行它以完成这个练习。确保你知道如何做到这一点,如果不知道,可以回顾练习 0 中学习如何从终端运行 Python 代码。
我将教你如何研究一段代码以揭示其秘密。你需要[languages](https://learnpythonthehardway.org/python3/languages.txt). ↪ [txt](https://learnpythonthehardway.org/python3/languages.txt)文件才能使这段代码工作,所以确保你首先下载它。languages.txt文件简单地包含了一些以 UTF-8 编码的人类语言名称。
列表 22.1:ex22.py
1 import sys
2 script, input_encoding, error = sys.argv
3
4
5 def main(language_file, encoding, errors):
6 line = language_file.readline()
7
8 if line:
9 print_line(line, encoding, errors)
10 return main(language_file, encoding, errors)
11
12
13 def print_line(line, encoding, errors):
14 next_lang = line.strip()
15 raw_bytes = next_lang.encode(encoding, errors=errors)
16 cooked_string = raw_bytes.decode(encoding, errors=errors)
17
18 print(raw_bytes, "<===>", cooked_string)
19
20
21 languages = open("languages.txt", encoding="utf-8")
22
23 main(languages, input_encoding, error)
尝试通过写下你不认识的每一样东西来研究这段代码,然后用通常的python THING site:python.org搜索它。例如,如果你不知道encode()是什么意思,那么搜索python encode site:python.org。一旦你阅读了所有你不了解的东西的文档,继续进行这个练习。
一旦你拥有了这个文件,你会想要在你的 shell 中运行这个 Python 脚本来测试它。以下是我用来测试它的一些示例命令:
1 python ex22.py "utf-8" "strict"
2 python ex22.py "utf-8" "ignore"
3 python ex22.py "utf-8" "replace"
查看[str.encode()](https://docs.python.org/3/library/stdtypes.xhtml#str.encode)函数的文档以获取更多选项。
警告!
你会注意到我在这里使用图片来展示你应该看到的内容。经过广泛测试,结果表明很多人的计算机配置为不显示 utf-8,所以我不得不使用图片,这样你就知道可以期待什么。甚至我的排版系统(LaTeX)也无法处理这些编码,迫使我使用图片。如果你看不到这个,那么你的终端很可能无法显示 utf-8,你应该尝试解决这个问题。
这些示例使用utf-8、utf-16和big5编码来演示转换和可能出现的错误类型。在 Python 3 中,这些名称中的每一个被称为“编解码器”,但你使用参数“encoding”。在这个练习的结尾,有一个可用编码的列表,如果你想尝试更多的话。我很快会解释这些输出的含义。你只是试图了解这是如何工作的,这样我们就可以讨论它。
在运行几次之后,浏览一下你的符号列表,猜一下它们的作用。当你写下你的猜测时,尝试在线查找这些符号,看看你是否能够确认你的假设。如果你不知道如何搜索它们,不要担心。试一试。
开关、约定和编码
在我解释这段代码的含义之前,你需要了解一些关于计算机中数据存储的基础知识。现代计算机非常复杂,但在它们的核心,它们就像一个巨大的光开关阵列。计算机使用电力来开关打开或关闭。这些开关可以表示 1 为开,0 为关。在过去,有各种奇怪的计算机不仅仅是 1 或 0,但如今只有 1 和 0。一个代表能量、电力、开、电源、物质。零代表关闭、完成、消失、关机、能量的缺乏。我们称这些 1 和 0 为“比特”。
现在,一台只能使用 1 和 0 来工作的计算机既效率低下又令人讨厌。计算机使用这些 1 和 0 来编码更大的数字。在较小的范围内,计算机将使用 8 个这些 1 和 0 来编码 256 个数字(0-255)。但“编码”是什么意思呢?这不过是一种约定俗成的标准,规定了一系列位应该如何表示一个数字。这是人类选择或偶然发现的一种约定,它说00000000将是 0,11111111将是 255,而00001111将是 15。甚至在计算机早期历史上,甚至有关于这些位的顺序的巨大战争,因为它们只是我们都必须同意的约定。
今天我们将“字节”称为 8 位(1 和 0 的序列)。在旧时代,每个人都有自己的字节约定,所以你仍然会遇到认为这个术语应该灵活处理 9 位、7 位、6 位序列的人,但现在我们只说它是 8 位。这是我们的约定,这个约定定义了我们对字节的编码。对于使用 16、32、64 甚至更多位的大数字进行编码还有进一步的约定,如果你涉及到非常大的数学,会有整个标准组织专门讨论这些约定,然后将它们实现为最终打开和关闭开关的编码。
一旦你有了字节,你就可以开始通过决定另一种约定来将数字映射到字母来存储和显示文本。在计算机早期,有许多约定将 8 位或 7 位(或更少或更多)映射到计算机内部保存的字符列表上。最流行的约定最终成为了美国信息交换标准代码,即 ASCII。这个标准将一个数字映射到一个字母。数字 90 是 Z,在位上是1011010,这被映射到计算机内部的 ASCII 表中。
你现在可以在 Python 中尝试这个:
1 >>> 0b1011010
2 90
3 >>> ord('Z')
4 90
5 >>> chr(90)
6 'Z'
7 >>>
首先,我将数字 90 写成二进制,然后根据字母 Z 得到数字,最后将数字转换为字母 Z。不过不用担心需要记住这个过程。我想我在使用 Python 的整个时间里只不过做过两次。
一旦我们有了使用 8 位(一个字节)编码字符的 ASCII 约定,我们就可以将它们“串”在一起形成一个单词。如果我想写我的名字“Zed A. Shaw”,我只需使用一个字节序列[90, 101, 100, 32, 65, 46, 32, 83, 104, 97, 119]。计算机早期的大部分文本只不过是存储在内存中的字节序列,计算机用来向人显示文本。同样,这只是一系列约定,用来打开和关闭开关。
ASCII 的问题在于它只编码英语和可能还有一些其他类似的语言。记住一个字节可以存储 256 个数字(0-255,或 00000000-11111111)。事实证明,世界上的语言中使用的字符远远超过 256 个。不同国家为他们的语言创建了自己的编码约定,这在大多数情况下是有效的,但许多编码只能处理一种语言。这意味着,如果你想在泰语句子中间放置一本美国英语书的标题,你可能会遇到麻烦。你需要一个编码用于泰语,另一个用于英语。
为了解决这个问题,一群人创造了 Unicode。它听起来像“编码”,旨在成为所有人类语言的“通用编码”。Unicode 提供的解决方案类似于 ASCII 表,但相比之下要庞大得多。你可以使用 32 位来编码一个 Unicode 字符,这比我们可能找到的字符还要多。32 位数字意味着我们可以存储 4,294,967,295 个字符(2³²),这足够容纳每种可能的人类语言,也可能包括很多外星语言。现在我们利用额外的空间来存储重要的事物,比如粑粑和笑脸表情符号。
现在我们有了一个编码任何字符的约定,但 32 位等于 4 字节(32/8 == 4),这意味着在我们想要编码的大多数文本中有很多浪费的空间。我们也可以使用 16 位(2 字节),但大多数文本仍然会有浪费的空间。解决方案是使用一个巧妙的约定,使用 8 位来编码大多数常见字符,然后在需要编码更多字符时“转义”为更大的数字。这意味着我们有了一个不过是压缩编码的约定,使得大多数常见字符可以使用 8 位,然后根据需要转换为 16 或 32 位。
在 Python 中编码文本的约定称为“utf-8”,意思是“Unicode 转换格式 8 位”。这是一种将 Unicode 字符编码为字节序列(即位序列(将开关序列打开和关闭))的约定。你也可以使用其他约定(编码),但 utf-8 是当前的标准。
解析输出
现在我们可以看一下之前命令的输出。让我们仅看一下第一个命令和输出的前几行:

ex22.py 脚本将写在 b''(字节字符串)内的字节转换为你指定的 UTF-8(或其他)编码。左侧是每个 utf-8 字节的数字(以十六进制显示),右侧是实际的 utf-8 字符输出。这样想,<===> 的左侧是 Python 的数字字节,或者 Python 用来存储字符串的“原始”字节。你使用 b'' 来告诉 Python 这是“字节”。然后这些原始字节会在右侧“烹饪”显示,这样你就可以在终端中看到真实的字符。
解析代码
我们已经了解了字符串和字节序列。在 Python 中,string 是一个 UTF-8 编码的字符序列,用于显示或处理文本。然后字节是 Python 用来存储这个 UTF-8 string 的“原始”字节序列,并以 b' 开头告诉 Python 你正在处理原始字节。这一切都基于 Python 处理文本的约定。这里是一个 Python 会话,展示了我如何编码字符串和解码字节:
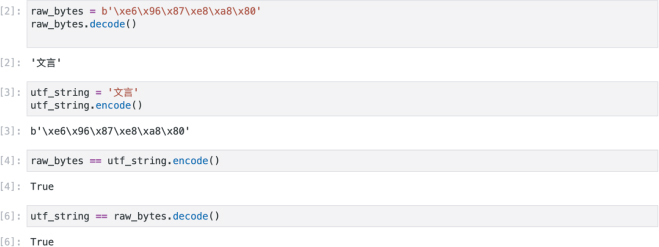
你需要记住的是,如果你有原始字节,那么你必须使用.decode()来获取string。原始bytes没有约定。它们只是一系列没有其他含义的字节,所以你必须告诉 Python“将其解码为 utf 字符串”。如果你有一个字符串并想要发送、存储、共享或执行其他操作,通常它会工作,但有时 Python 会抛出一个错误,说它不知道如何“编码”它。再次强调,Python 知道它的内部约定,但不知道你需要什么约定。在这种情况下,你必须使用.encode()来获取你需要的字节。
要记住这一点(尽管我几乎每次都要查找),方法是记住“DBES”这个记忆口诀,它代表“Decode Bytes Encode Strings”。当我需要转换字节和字符串时,我会在脑海中说“dee bess”。当你有bytes并需要一个string时,“Decode Bytes”。当你有一个字符串并需要字节时,“Encode Strings”。
有了这个想法,让我们逐行分解ex22.py中的代码:
1-2 我从你已经了解的常规命令行参数处理开始。
5 我在一个方便命名为main的函数中开始这段代码的主要部分。这将在脚本末尾调用以启动事务。
6 这个函数的第一件事是从给定的语言文件中读取一行。你以前做过这个,所以这里没有什么新东西。处理文本文件时,就像以前一样只需readline。
8 现在我使用了一些新的东西。你将在本书的后半部分了解到这一点,所以把它看作是即将发生的有趣事情的一个预告。这是一个if语句,它让你在 Python 代码中做出决策。你可以“测试”一个变量的真实性,并根据这个真实性运行一段代码或不运行它。在这种情况下,我正在测试line是否有内容。当readline到达文件末尾时,readline函数将返回一个空字符串,而if line只是测试这个空字符串。只要readline给我们一些东西,这将是真的,代码在(缩进,第 9-10 行)将运行。当这是假的时候,Python 将跳过 9-10 行。
9 然后我调用一个单独的函数来实际打印这一行。这简化了我的代码,使我更容易理解它。如果我想了解这个函数的作用,我可以跳转到它并进行研究。一旦我知道print_line做什么,我就可以将我的记忆与名称print_line联系起来,然后忘记细节。
10 我在这里写了一小段强大的魔法。我在main函数内部再次调用main。实际上,这并不是魔法,因为在编程中没有什么是真正神奇的。所有你需要的信息都在那里。这看起来像是我在函数内部调用它自己,这似乎应该是不合法的。问问自己,为什么这应该是不合法的?从技术上讲,我可以在那里调用任何函数,甚至是这个main函数,没有任何技术上的理由不允许这样做。如果一个函数只是一个跳转到我命名为main的顶部的地方,那么在函数末尾调用这个函数会……跳回到顶部并再次运行它。这将使它循环。现在回顾一下第 8 行,你会看到if 语句阻止了这个函数无限循环。仔细研究这一点,因为这是一个重要的概念,但如果你不能立刻理解也不要担心。
13 我现在开始定义print_line函数,该函数实际上对languages.txt文件中的每一行进行编码。
14 这只是简单地去除line字符串末尾的\n。
15 现在我终于拿到了从languages.txt文件中收到的语言,并将其“编码”为原始字节。记住“DBES”这个助记符。“解码字节,编码字符串。”next_lang变量是一个字符串,所以为了获得原始字节,我必须在其上调用.encode()来“编码字符串”。我传递给encode()我想要的编码以及如何处理错误。
16 然后我通过从raw_bytes创建一个cooked_string变量来展示第 15 行的反向操作。记住,“DBES”告诉我“解码字节”,而raw_bytes是bytes,所以我在其上调用.decode()来获得一个 Pythonstring。这个字符串应该与next_lang变量相同。
18 然后我简单地将它们都打印出来,以展示它们的样子。
21 我已经定义完函数,现在我想打开languages.txt文件。
23 脚本的结尾简单地运行main函数,带上所有正确的参数来启动一切并启动循环。记住,这会跳转到第 5 行定义main函数的地方,然后在第 10 行再次调用main,导致这个循环继续进行。第 8 行的if line:将阻止我们的循环永远进行下去。
深入探讨编码
现在我们可以使用我们的小脚本来探索其他编码。这是我尝试不同编码并看如何破解它们的过程:
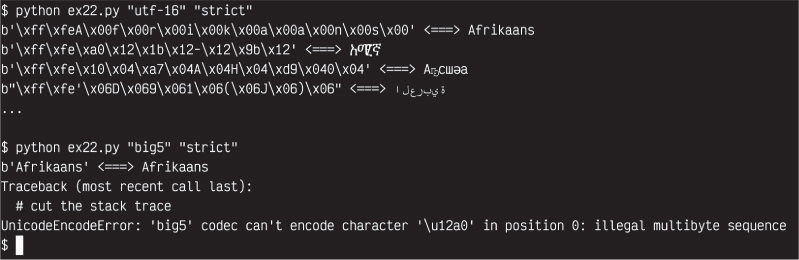
首先,我正在做一个简单的 UTF-16 编码,这样你就可以看到它与 UTF-8 相比是如何变化的。你也可以使用“utf-32”来看看它更大,以及用 UTF-8 节省的空间的概念。之后我尝试 Big5,你会发现 Python一点也不喜欢那个。它会抛出一个错误,说“big5”无法对位置 0 的一些字符进行编码(这非常有帮助)。一个解决方案是告诉 Python 用“replace”替换任何 Big5 编码系统中不匹配的字符。尝试一下,你会看到它在发现一个不符合 Big5 编码系统的字符时会放置一个?字符。
破坏它
粗略的想法包括以下内容:
-
找到用其他编码编码的文本字符串,并将它们放入
ex22.py文件中,看看会发生什么。 -
找出当你提供一个不存在的编码时会发生什么。
-
额外挑战:使用
b''字节来重写这个脚本,而不是使用 UTF-8 字符串,有效地颠倒脚本。 -
如果你能做到这一点,那么你也可以通过删除一些字节来破坏这些字节,看看会发生什么。你需要删除多少才能让 Python 崩溃?你可以删除多少来损坏字符串输出但通过 Python 的解码系统吗?
-
利用从第 4 步学到的知识,看看是否可以搞乱文件。你会得到什么错误?你能造成多大破坏并让文件通过 Python 的解码系统吗?
练习 23:入门列表
大多数编程语言都有一种将数据存储在计算机内部的方法。一些语言只有原始内存位置,但当情况如此时,程序员很容易犯错误。在现代语言中,你会得到一些核心的存储数据的方式,称为“数据结构”。数据结构将数据片段(整数、字符串,甚至其他数据结构)组织在一些有用的方式中。在这个练习中,我们将学习一种称为“list”或“Array”的序列式数据结构,具体取决于语言。
Python 最简单的序列数据结构是list,它是一组有序的事物。你可以随机访问list的元素,按顺序访问,扩展它,缩小它,以及对实际生活中的一系列事物做的几乎任何其他操作。
制作list的方法如下:
1 fruit = ["apples", "oranges", "grapes"];
就是这样。只需在要放入list的事物周围加上[(左方括号)和](右方括号),并用逗号分隔它们。你甚至可以将任何东西放入list中,甚至其他lists:
1 inventory = [ ["Buick", 10], ["Corvette", 1], ["Toyota", 4]];
在这段代码中,我有一个list,而且这个list里面有三个lists。每个list里面都有一个汽车类型的名称和库存数量。仔细研究这个并确保你能够在阅读时将其分解。在其他数据结构中存储lists在lists内部是非常常见的。
访问列表的元素
如果你想要inventory list的第一个元素怎么办?那么你库存中有多少辆别克汽车呢?你可以这样做:
1 # get the buick record
2 buicks = inventory[0]
3 buick_count = buicks[1]
4 # or in one move
5 count_of_buicks = inventory[0][1]
在注释之后的前两行代码中,我进行了一个两步过程。我使用inventory[0]代码来获取第一个元素。如果你不熟悉编程语言,大多数语言从 0 开始,而不是 1,因为在大多数情况下这样数学运算更好。在变量名后面紧跟[]告诉 Python 这是一个“容器”,并表示我们要“用这个值索引到这个东西中”,在这种情况下是 0。在下一行中,我取出buicks[1]元素,并从中获取10。
你不必这样做,因为你可以将[]的用法链接在一起,以便在进行深入研究list时逐步深入。在代码的最后一行中,我用inventory[0][1]来实现这一点,它的意思是“获取第 0 个元素,然后获取那个元素”。
这里是你可能会犯错误的地方。第二个[1]并不意味着获取整个["Buick", [rcurvearrowse] 10]。它不是线性的,而是“递归”的,意味着它深入到结构中。你正在获取["Buick", [rcurvearrowse] 10]中的10。更准确地说,它只是前两行代码的组合。
练习列表
列表足够简单,但你需要练习访问非常复杂lists的不同部分。重要的是,你能够正确地理解如何索引到嵌套list中的元素。最好的方法是在 Jupyter 中使用这样的list进行练习。
这段代码中我有一系列的lists。你需要像平常一样输入这段代码,然后使用 Python 访问元素,以便得到与我相同的答案。
代码
要完成这个挑战,你需要这段代码:
代码清单 23.1:ex23.py
1 fruit = [
2 ['Apples', 12, 'AAA'], ['Oranges', 1, 'B'],
3 ['Pears', 2, 'A'], ['Grapes', 14, 'UR']]
4
5 cars = [
6 ['Cadillac', ['Black', 'Big', 34500]],
7 ['Corvette', ['Red', 'Little', 1000000]],
8 ['Ford', ['Blue', 'Medium', 1234]],
9 ['BMW', ['White', 'Baby', 7890]]
10 ]
11
12 languages = [
13 ['Python', ['Slow', ['Terrible', 'Mush']]],
14 ['JavaSCript', ['Moderate', ['Alright', 'Bizarre']]],
15 ['Perl6', ['Moderate', ['Fun', 'Weird']]],
16 ['C', ['Fast', ['Annoying', 'Dangerous']]],
17 ['Forth', ['Fast', ['Fun', 'Difficult']]],
18 ]
可以复制粘贴这段代码,因为这个练习的重点是学习如何访问数据,但如果你想要额外练习输入 Python 代码,那么可以手动输入。
挑战
我会给你一个名为list的列表和列表中的一段数据。你的任务是找出你需要获取该信息的索引。例如,如果我告诉你fruit 'AAA',那么你的答案是fruit[0][2]。你应该试着在脑海中通过查看代码来完成这个任务,然后在 Jupyter 中测试你的猜测。
水果挑战
你需要从fruit变量中获取所有这些元素:
-
12
-
‘AAA’
-
2
-
‘橙子’
-
‘葡萄’
-
14
-
‘苹果’
汽车挑战
你需要从cars变量中获取所有这些元素:
-
‘大’
-
‘红色’
-
1234
-
‘白色’
-
7890
-
‘黑色’
-
34500
-
‘蓝色’
语言挑战
你需要从languages变量中获取所有这些元素:
-
‘缓慢’
-
‘好的’
-
‘危险’
-
‘快速’
-
‘困难’
-
‘有趣’
-
‘烦人’
-
‘奇怪’
-
‘适中’
最终挑战
现在你需要弄清楚这段代码拼出了什么:
1 cars[1][1][1]
2 cars[1][1][0]
3 cars[1][0]
4 cars[3][1][1]
5 fruit[3][2]
6 languages[0][1][1][1]
7 fruit[2][1]
8 languages[3][1][0]
不要首先在 Jupyter 中运行这段代码。相反,尝试手动计算每行将拼出什么,然后在 Jupyter 中测试。
练习 24:初级字典
在这个练习中,我们将使用前一个练习中的相同数据来学习字典或 dicts。
键/值结构
你经常在不知不觉中使用key=value数据。当你阅读一封电子邮件时,你可能会有:
1 From: j.smith@example.com
2 To: zed.shaw@example.com
3 Subject: I HAVE AN AMAZING INVESTMENT FOR YOU!!!
左边是键(From,To,Subject),它们与右边的:后的内容映射在一起。程序员说键被“映射”到值,但他们也可以说“设置为”,比如,“我将From设置为j.smith@example.com”。在 Python 中,我可能会使用一个数据对象来写这封电子邮件:
1 email = {
2 "From": "j.smith@example.com",
3 "To": "zed.shaw@example.com",
4 "Subject": "I HAVE AN AMAZING INVESTMENT FOR YOU!!!"
5 };
通过以下方式创建数据对象:
-
用
{(大括号)打开它 -
写入键,这里是一个字符串,但可以是数字,或几乎任何东西
-
写入一个
:(冒号) -
写入值,可以是 Python 中有效的任何内容
一旦你这样做,你可以像这样访问这封 Python 电子邮件:
1 email["From"]
2 'j.smith@example.com'
3
4 email["To"]
5 'zed.shaw@example.com'
6
7 email["Subject"]
8 'I HAVE AN AMAZING INVESTMENT FOR YOU!!!'
你会注意到这与你访问模块中的变量和函数的方式非常相似,你需要require。使用.(点)是你可以访问 Python 中许多数据结构部分的主要方式。你也可以使用前一个练习中的[]语法来访问这些数据:
1 email['To']
2 'zed.shaw@example.com'
3
4 email['From']
5 'j.smith@example.com'
与list索引的唯一区别是你使用字符串(‘From’)而不是整数。但是,如果你愿意,你也可以使用整数作为键(后面会详细介绍)。
将列表与数据对象结合
编程中的一个常见主题是将组件组合以获得令人惊讶的结果。有时惊喜是崩溃或错误。其他时候,惊喜是一种新颖的完成某项任务的方式。无论如何,当你进行新颖的组合时发生了什么并不是真正的惊喜或秘密。对于你来说可能是惊喜的,但语言规范中通常会有一个解释(即使这个原因绝对愚蠢)。你的计算机中没有魔法,只有你不理解的复杂性。
将数据对象放入lists中的一个很好的例子。你可以这样做:
1 messages = [
2 {to: 'Sun', from: 'Moon', message: 'Hi!'},
3 {to: 'Moon', from: 'Sun', message: 'What do you want Sun?'},
4 {to: 'Sun', from: 'Moon', message: "I'm awake!"},
5 {to: 'Moon', from: 'Sun', message: 'I can see that Sun.'}
6 ];
一旦我这样做了,我现在可以使用list语法来访问数据对象,就像这样:
1 messages[0].to
2 'Sun'
3
4 messages[0].from
5 'Moon'
6 messages[0].message
7 'Hi!'
8
9 messages[1]['to']
10 'Moon'
11
12 messages[1]['from']
13 'Sun'
14
15 messages[1]['message']
16 'What do you want Sun?'
注意我在messages[0]后面立即使用.(点)语法的方式?再次尝试结合功能,看看它们是否有效,如果有效,找出原因,因为总会有一个原因(即使它很愚蠢)。
代码
现在,你将重复使用lists的练习,并写出我精心制作的三个数据对象。然后,你将把它们输入到 Python 中,并尝试访问我给你的数据。记得尝试在脑海中完成这个任务,然后用 Python 检查你的工作。你还应该练习对list和dict结构进行这样的操作,直到你有信心可以访问内容。你会意识到数据是相同的,只是被重新构造了。
列表 24.1: ex24.py
1 fruit = [
2 {kind: 'Apples', count: 12, rating: 'AAA'},
3 {kind: 'Oranges', count: 1, rating: 'B'},
4 {kind: 'Pears', count: 2, rating: 'A'},
5 {kind: 'Grapes', count: 14, rating: 'UR'}
6 ];
7
8 cars = [
9 {type: 'Cadillac', color: 'Black', size: 'Big', miles: 34500},
10 {type: 'Corvette', color: 'Red', size: 'Little', miles: 1000000},
11 {type: 'Ford', color: 'Blue', size: 'Medium', miles: 1234},
12 {type: 'BMW', color: 'White', size: 'Baby', miles: 7890}
13 ];
14
15 languages = [
16 {name: 'Python', speed: 'Slow', opinion: ['Terrible', 'Mush']},
17 {name: 'JavaScript', speed: 'Moderate', opinion: ['Alright', 'Bizarre'
↪] ]},
18 {name: 'Perl6', speed: 'Moderate', opinion: ['Fun', 'Weird']},
19 {name: 'C', speed: 'Fast', opinion: ['Annoying', 'Dangerous']},
20 {name: 'Forth', speed: 'Fast', opinion: ['Fun', 'Difficult']},
21 ];
你应该看到的结果
请记住,你在这里进行了一些复杂的数据访问操作,所以要慢慢来。你必须遍历你分配给模块的data变量,然后访问lists,接着是数据对象,有时还有另一个list。
挑战
我会给你完全相同的数据元素集,你需要找出获取这些信息所需的索引。例如,如果我告诉你fruit 'AAA',那么你的答案是fruit[0].rating。你应该试着在脑海中通过查看代码来做到这一点,然后在python shell 中测试你的猜测。
水果挑战
你需要从fruit变量中取出所有这些元素:
-
12
-
‘AAA’
-
2
-
‘橙子’
-
‘葡萄’
-
14
-
‘苹果’
汽车挑战
你需要从cars变量中取出所有这些元素:
-
‘大的’
-
‘红色的’
-
1234
-
‘白色的’
-
7890
-
‘黑色的’
-
34500
-
‘蓝色的’
语言挑战
你需要从languages变量中取出所有这些元素:
-
‘慢的’
-
‘好的’
-
‘危险的’
-
‘快的’
-
‘困难的’
-
‘有趣的’
-
‘烦人的’
-
‘奇怪的’
-
‘适度的’
最终挑战
你的最终挑战是编写出写出与练习 23 中相同歌词的 Python 代码。再次慢慢来,试着在脑海中完成再看看你是否做对了。如果你做错了,花时间理解为什么错了。作为对比,我在脑海中一次性写出了歌词,没有出错。我也比你有更多经验,所以你可能会犯一些错误,那也没关系。
你不知道这些是歌词吗?这是一首由王子演唱的歌曲叫做“Little Red Corvette”。在继续阅读本书之前,你现在被命令听 10 首王子的歌曲,否则我们就不能再做朋友了。再也不能!
练习 25:字典和函数
在这个练习中,我们将通过将函数与dict结合起来做一些有趣的事情。这个练习的目的是确认你可以在 Python 中组合不同的东西。组合是编程的关键方面,你会发现许多“复杂”的概念实际上只是更简单概念的组合。
第一步:函数名称是变量
为了做好准备,我们首先要确认函数的名称就像其他变量一样。看看这段代码:
1 def print_number(x):
2 print("NUMBER IS", x)
3
4 rename_print = print_number
5 rename_print(100)
6 print_number(100)
如果你运行这段代码,你会发现rename_print和print_number做的事情完全相同,这是因为它们是相同的。函数的名称与变量的名称相同,你可以将名称重新分配给另一个变量。这就像这样做一样:
1 x = 10
2 y = x
玩弄这个,直到你明白。创建自己的函数,然后将它们分配给新名称,直到你理解这个概念。
第二步:带有变量的字典
这可能很明显,但以防你还没有建立联系,你可以将一个变量放入dict中:
1 color = "Red"
2
3 corvette = {
4 "color": color
5 }
6
7 print("LITTLE", corvette["color"], "CORVETTE")
接下来的拼图部分是有意义的,因为你可以将数字和字符串等值放入dict中。你也可以将这些相同的值分配给变量,因此将它们组合起来并将变量放入dict中是有意义的。
第三步:带有函数的字典
你应该看到这是怎么回事了,但现在我们可以将这些概念结合起来,将一个函数放入dict中:
1 def run():
2 print("VROOM")
3
4 corvette = {
5 "color": "Red",
6 "run": run
7 }
8
9 print("My", corvette["color"], "can go")
10 corvette["run"]()
我从前面的color变量中取出,并将其直接放入corvette的dict中。然后我创建了一个名为run的函数,并将其放入corvette中。最棘手的部分是最后一行corvette ["run"](),但看看你是否可以根据你所知道的来弄清楚它。在继续之前,花些时间写出这行代码正在做什么的描述。
第四步:解密最后一行
解密最后一行corvette["run"]()的技巧是将其分解成每个部分。人们对这样的代码行感到困惑的原因是他们看到了一个单一的东西,“运行 corvette”。事实上,这行代码由许多东西组合在一起共同工作。如果我们将其拆分开来,我们可以得到这段代码:
1 # get the run fuction out of the corvette dict
2 myrun = corvette["run"]
3 # run it
4 myrun()
即使这两行并不是整个故事,但这向你展示了这至少是一行上的两个操作:使用["run"]获取函数,然后使用()运行函数。为了进一步分解这个,我们可以写成:
-
corvette告诉 Python 加载dict -
[告诉 Python 开始索引到corvette -
"run"告诉 Python 使用"run"作为键来搜索dict -
]告诉 Python 你已经完成索引,它应该完成索引 -
Python 然后返回与键
"run"匹配的corvette内容,这是之前的run()函数 -
Python 现在有了
run函数,所以()告诉 Python 像调用任何其他函数一样调用它
花些时间理解这是如何工作的,并在corvette上编写自己的函数以使其执行更多操作。
学习练习
现在你有一段控制汽车的好代码。在这个练习中,你将创建一个新的函数,创建任何汽车。你的创建函数应满足以下要求:
-
它应接受参数来设置颜色、速度或其他你的汽车可以做的任何事情。
-
它应创建一个包含正确设置并已包含你创建的所有函数的
dict。 -
它应返回这个
dict,这样人们可以将结果分配给任何他们想要的东西,并以后使用。 -
它应该被编写成这样,以便某人可以创建任意数量的不同汽车,每个他们制造的汽车都是独立的。
-
你的代码应通过改变几辆不同汽车的设置来测试#4,然后确认它们没有改变其他汽车的设置。
这个挑战不同,因为我会在后面的练习中向你展示挑战的答案。如果你在这个挑战中遇到困难,那么暂时搁置它,继续前进。你很快会再次看到它。
练习 26:字典和模块
在这个练习中,你将探索dict如何与模块一起工作。每当你使用import将“功能”添加到你自己的 Python 源代码时,你都在使用模块。你在练习 17 中使用得最多,所以在开始这个练习之前,最好回顾一下那个练习。
步骤 1: import的回顾
第一步是回顾import的工作方式并进一步发展这方面的知识。花点时间将这段代码输入到一个名为ex26.py的 Python 文件中。你可以在 Jupyter 中通过创建一个文件(左侧,蓝色[+]按钮)来做到这一点:
列表 26.1: ex26.py
1 name = "Zed"
2 height = 74
创建了这个文件后,你可以用这个导入它:
列表 26.2: ex26_code.py
1 import ex26
这将把ex26.py的内容带入你的 Jupyter lab 中,这样你就可以像这样访问它们:
列表 26.3: ex26_code.py
1 print("name", ex26.name)
2 print("height", ex26.height)
尽可能多地尝试玩这个。尝试添加新变量并再次导入以查看其工作原理。
步骤 2: 找到__dict__
一旦你理解了import是将ex26.py的内容导入到你的 lab 中,你就可以开始像这样调查__dict__变量:
列表 26.4: ex26_code.py
1 from pprint import pprint
2
3 pprint(ex26.__dict__)
pprint函数是一个“漂亮打印机”,将以更好的格式打印__dict__。
使用pprint,你会突然发现ex26有一个名为__dict__的“隐藏”变量,它实际上是一个包含模块中所有内容的dict。你会在 Python 中的各个地方找到这个__dict__和许多其他秘密变量。__dict__的内容包含了许多不是你的代码的东西,但这只是 Python 需要处理模块的东西。
这些变量是如此隐藏,以至于即使顶级专业人员也会忘记它们的存在。许多这样的程序员认为模块与dict完全不同,而实际上模块使用了__dict__,这意味着它与dict相同。唯一的区别是 Python 有一些语法,让你使用.运算符而不是dict语法来访问模块,但你仍然可以像访问dict一样访问内容:
列表 26.5: ex26_code.py
1 print("height is", ex26.height)
2 print("height is also", ex26\. dict ['height'])
对于这两种语法,你会得到相同的输出,但.模块语法肯定更容易。
步骤 3: 改变__dict__
如果一个模块确实是内部的dict,那么这意味着改变__dict__的内容也应该改变模块中的变量。让我们试一试:
列表 26.6: ex26_code.py
1 print(f"I am currently {ex26.height} inches tall.")
2
3 ex26\. dict ['height'] = 1000
4 print(f"I am now {ex26.height} inches tall.")
5
6 ex26.height = 12
7 print(f"Oops, now I'm {ex26\. dict ['height']} inches tall.")
正如你所看到的,当你改变ex26.__dict__['height']时,变量ex26.height也会改变,这证明了模块确实是__dict__。
这意味着.运算符被转换为__dict__[]访问操作。我希望你记住这一点,因为很多初学者看到ex26.height时,他们认为这是一个单独的代码单元。实际上,这实际上是三个或四个单独的操作:
-
找到
ex26。 -
找到
ex26.__dict__。 -
使用
"height"索引到__dict__。 -
返回该值。
一旦你建立了这种联系,你就会开始理解.是如何工作的。
学习练习:找到“Dunders”
__dict__ 变量通常被称为“双下划线”变量,但程序员们很懒,所以我们只是称它们为“dunder 变量”。在学习关于 dunder 变量的最后一步中,你将访问 Python 文档中描述数据模型的部分,其中描述了许多这些 dunder 的用法。
这是一个很大的文档,其写作风格非常枯燥,所以最好的学习方法是搜索__(双下划线),然后根据其描述找到访问这个变量的方法。例如,你可以尝试在几乎任何地方访问__doc__:
列表 26.7: ex26_code.py
1 from pprint import pprint
2 print(pprint. doc )
这将为你提供与pprint函数相关联的一点文档。你可以使用help函数访问相同的信息:
列表 26.8: ex26_code.py
1 help(pprint)
尝试用你能找到的所有其他 dunder 进行这些实验。你很可能不会直接使用它们,但了解 Python 内部工作原理是很有好处的。
练习 27:编程游戏的五个简单规则
信息
这个练习旨在在你学习下一个练习时定期学习。你应该慢慢来,将其与其他解释混合在一起,直到最终理解。如果在这个练习中迷失了方向,休息一下,然后进行下一个练习。然后,如果在后面的练习中感到困惑,回来学习我在这里描述的细节。一直坚持下去,直到“豁然开朗”。记住,你不会失败,所以继续努力直到理解为止。
如果你玩围棋或国际象棋这样的游戏,你会知道规则相当简单,但它们所启用的游戏却极其复杂。真正好的游戏具有简单规则和复杂互动的独特品质。编程也是一个具有少量简单规则的游戏,这些规则创造了复杂的互动,在这个练习中,我们将学习这些规则是什么。
在我们做这个之前,我需要强调的是,当你编写代码时,你很可能不会直接使用这些规则。有些语言确实直接利用这些规则,你的 CPU 也使用它们,但在日常编程中你很少会使用它们。如果是这样,那么为什么要学习这些规则呢?
因为这些规则无处不在,理解它们将帮助你理解你编写的代码。当代码出错时,它将帮助你调试代码。如果你想知道代码是如何工作的,你将能够将其“分解”到基本规则,真正看到它是如何工作的。这些规则就像是一个秘密的代码。完全是故意的双关语。
我还要警告你不要期望立即完全理解这一点。把这个练习看作是为本模块中其余练习做准备。你应该深入研究这个练习,当遇到困难时,继续进行下一个练习作为休息。你应该在这个练习和下一个练习之间来回跳动,直到概念“豁然开朗”并开始变得有意义。你也应该尽可能深入地研究这些规则,但不要在这里卡住。挣扎几天,继续前进,回来,继续努力。只要你继续努力,你实际上不可能“失败”。
规则 1:一切都是一系列指令
所有程序都是一系列指令,告诉计算机做某事。当你输入这样的代码时,你已经看到 Python 在做这个了:
1 x = 10
2 y = 20
3 z = x + y
这段代码从第 1 行开始,到第 2 行,依此类推直到结束。这是一系列指令,但在 Python 中,这三行被转换为另一系列指令,看起来像这样:
1 LOAD_CONST 0 (10) # load the number 10
2 STORE_NAME 0 (x) # store that in x
3
4 LOAD_CONST 1 (20) # load the number 20
5 STORE_NAME 1 (y) # store that in y
6
7 LOAD_NAME 0 (x) # loads x (which is 10)
8 LOAD_NAME 1 (y) # loads y (which is 20)
9 BINARY_ADD # adds those
10 STORE_NAME 2 (z) # store the result in z
这看起来与 Python 版本完全不同,但我敢打赌你可能能够猜出这一系列指令在做什么。我已经添加了注释来解释每个指令,你应该能够将其与之前的 Python 代码联系起来。
我不是在开玩笑。现在花点时间将 Python 代码的每一行与这个“字节码”的行联系起来。使用我提供的注释,我相信你可以弄清楚,这样做可能会在你的脑海中点亮一盏灯,让你更好地理解 Python 代码。
不需要记住这些指令,甚至不需要理解每一条指令。你应该意识到的是,你的 Python 代码被翻译成了一系列简单的指令,告诉计算机做什么。这个指令序列被称为“字节码”,因为它通常以一系列计算机理解的数字的形式存储在文件中。你在上面看到的输出通常被称为“汇编语言”,因为它是这些字节的人类“可读”(勉强)版本。
这些简单的指令从顶部开始处理,一次执行一个小操作,当程序退出时到达末尾。这就像你的 Python 代码,但语法更简单,是INSTRUCTION OPTIONS的形式。另一种看待这个问题的方式是,x = 10的每个部分可能会在这个“字节码”中成为自己的指令。
这是《编码游戏》的第一条规则:你写的每一行最终都会成为一系列字节,作为计算机的指令输入,告诉计算机应该做什么。
我怎样才能得到这个输出?
要自己得到这个输出,你可以使用一个名为[dis](https://docs.python.org/3/library/dis.xhtml)的模块,它代表“disassemble”。这种代码传统上被称为“字节码”或“汇编语言”,所以dis的意思是“反汇编”。要使用dis,你可以导入它并像这样使用dis()函数:
1 # import the dis function
2 from dis import dis
3
4 # pass code to dis() as a string
5 dis('''
6 x = 10
7 y = 20
8 z = x + y
9 ''')
在这个 Python 代码中,我正在做以下事情:
-
我从
dis模块中导入dis()函数 -
我运行
dis()函数,但使用'''给它一个多行字符串 -
我接着将想要反汇编的 Python 代码写入这个多行字符串中
-
最后,我用
''')结束多行字符串和dis()函数
当你在 Jupyter 中运行这个代码时,你会看到它像我上面展示的那样输出字节码,但也许会有一些我们马上会讨论的额外内容。
这些字节存储在哪里?
当你运行 Python(版本 3)时,这些字节会存储在一个名为__pycache__的目录中。如果你将这段代码放入一个名为ex19.py的文件中,然后用python ex19.py运行它,你应该会看到这个目录。
在这个目录中,你应该会看到一堆以.pyc结尾的文件,名称类似于生成它们的代码。这些.pyc文件包含了你编译后的 Python 代码的字节。
当你运行dis()时,你正在打印.pyc文件中数字的人类可读版本。
规则 2:跳转使序列变得非线性
像LOAD_CONST 10这样的一系列简单指令并不是很有用。耶!你可以加载数字 10!太棒了!代码开始变得有用的地方是当你添加“跳转”概念使这个序列非线性。让我们看一个新的 Python 代码片段:
1 while True:
2 x = 10
要理解这段代码,我们必须预示一个稍后的练习,你将学习关于 while-loop。代码 while True: 简单地表示“在 True 为 True 时继续运行我的代码 x = 10。”由于 True 将始终为 True,这将永远循环。如果在 Jupyter 中运行,它永远不会结束。
当你 dis() 这段代码时会发生什么?你会看到新的指令 JUMP_ABSOLUTE:
1 dis("while True: x = 10")
2
3 0 LOAD_CONST 1 (10)
4 2 STORE_NAME 0 (x)
5 4 JUMP_ABSOLUTE 0 (to 0)
当我们讨论 x = 10 代码时,你看到了前两个指令,但现在在结尾我们有 JUMP_ABSOLUTE 0。注意这些指令左边有数字 0、2 和 4?在之前的代码中我把它们剪掉了,这样你就不会被分心,但在这里它们很重要,因为它们代表每个指令所在位置的序列。所有 JUMP_ABSOLUTE 0 做的就是告诉 Python “跳转到位置 0 处的指令”,即 LOAD_CONST 1 (10)。
通过这个简单的指令,我们现在已经将无聊的直线代码转变成了一个更复杂的循环,不再是直线了。稍后我们将看到跳转如何与测试结合,允许更复杂的移动通过字节序列。
为什么是反向的?
你可能已经注意到 Python 代码读起来像“当 True 为 True 时将 x 设置为 10”,但 dis() 输出更像是“将 x 设置为 10,跳转以再次执行”。这是因为规则 #1,它说我们只能生成一个 字节序列。不允许有嵌套结构,或任何比 INSTRUCTION OPTIONS 更复杂的语法。
为了遵循这个规则,Python 必须找出如何将其代码转换为产生所需输出的字节序列。这意味着将实际的重复部分移动到序列的末尾,以便它在一个序列中。当查看字节码和汇编语言时,你会经常发现这种“反向”的特性。
一个 JUMP 能前进吗?
是的,技术上,JUMP 指令只是告诉计算机在序列中处理不同的指令。它可以是下一个,前一个,或未来的一个。这是计算机跟踪当前指令“索引”的方式,它简单地递增该索引。
当你 JUMP 时,你在告诉计算机将这个索引更改到代码中的一个新位置。在我们的 while 循环代码中(下面),JUMP_ABSOLUTE 在索引 4 处(看左边的 4)。运行后,索引会更改为 0,在那里是 LOAD_CONST 的位置,所以计算机再次运行该指令。这将永远循环。
1 0 LOAD_CONST 1 (10)
2 2 STORE_NAME 0 (x)
3 4 JUMP_ABSOLUTE 0 (to 0)
规则 3:测试控制跳转
JUMP 对于循环很有用,但是如何做决策呢?编程中的一个常见问题是提出类似的问题:
“如果 x 大于 0,则将 y 设置为 10。”
如果我们用简单的 Python 代码写出来,可能会像这样:
1 if x > 0:
2 y = 10
再次,这是预示你将来会学到的东西,但这足够简单可以理解:
-
Python 将 测试
x是否大于>0 -
如果是,那么 Python 将运行行
y = 10 -
你看到那行缩进在
if x > 0:下面了吗?这被称为“块”,Python 使用缩进来表示“这个缩进的代码是上面代码的一部分” -
如果
x不大于0,那么 Python 将跳过y = 10行以跳过它
要使用我们的 Python 字节码来实现测试部分,我们需要一个实现测试部分的新指令。我们有 JUMP。我们有变量。我们只需要一种方法来比较两个东西,然后根据比较跳转。
让我们拿这段代码并用dis()来看看 Python 是如何做到这一点的:
1 dis('''
2 x = 1
3 if x > 0:
4 y = 10
5 ''')
6
7 0 LOAD_CONST 0 (1) # load 1
8 2 STORE_NAME 0 (x) # x = 1
9
10 4 LOAD_NAME 0 (x) # load x
11 6 LOAD_CONST 1 (0) # load 0
12 8 COMPARE_OP 4 (>) # compare x > 0
13 10 POP_JUMP_IF_FALSE 10 (to 20) # jump if false
14
15 12 LOAD_CONST 2 (10) # not false, load 10
16 14 STORE_NAME 1 (y) # y = 10
17 16 LOAD_CONST 3 (None) # done, load None
18 18 RETURN_VALUE # exit
19
20 # jump here if false
21 20 LOAD_CONST 3 (None) # load none
22 22 RETURN_VALUE # exit
这段代码的关键部分是COMPARE_OP和POP_JUMP_IF_FALSE:
1 4 LOAD_NAME 0 (x) # load x
2 6 LOAD_CONST 1 (0) # load 0
3 8 COMPARE_OP 4 (>) # compare x > 0
4 10 POP_JUMP_IF_FALSE 10 (to 20) # jump if false
这段代码的作用是:
-
使用
LOAD_NAME加载x变量 -
使用
LOAD_CONST加载常量0 -
使用
COMPARE_OP,进行>比较并留下True或False结果供以后使用 -
最后,
POP_JUMP_IF_FALSE使if x > 0起作用。它“弹出”True或False值以获取它,如果读取到False,它将JUMP到指令 20 -
这将跳过设置
y的代码,如果比较结果是False,但是如果比较结果是True,那么 Python 将运行下一条指令,从而开始y = 10序列
花点时间仔细研究一下这个问题。如果你有打印机,尝试打印出来并手动设置x为不同的值,然后跟踪代码的运行过程。当你设置x = -1时会发生什么?
你说的“pop”是什么意思?
在前面的代码中,我跳过了 Python 如何“弹出”值来读取它的部分,但它将其存储在一个称为“堆栈”的东西中。现在只需将其视为一个临时存储位置,你可以将值“推入”其中,然后将其“弹出”。在你的学习阶段,你真的不需要深入了解更多。只需了解其效果是获取最后一条指令的结果。
等等,像*COMPARE_OP*这样的测试也在循环中使用吗?
是的,基于你现在所知道的,你可能可以立即弄清楚它是如何工作的。尝试编写一个while-loop,看看你是否可以根据你现在所知道的知识使其工作。如果你不能,不要担心,因为我们将在后续练习中涵盖这个内容。
规则 4:存储控制测试
在代码运行时,你需要一种方式来跟踪数据的变化,这通过“存储”来实现。通常这种存储是在计算机的内存中,你为存储在内存中的数据创建名称。当你编写这样的代码时,你一直在这样做:
1 x = 10
2 y = 20
3 z = x + y
在前面的每一行中,我们都在创建一个新的数据片段并将其存储在内存中。我们还为这些内存片段赋予了名称x、y和z。然后我们可以使用这些名称从内存中“召回”这些值,这就是我们在z = x + y中所做的。我们只是从内存中召回x和y的值然后将它们相加。
这就是这个小规则的大部分内容,但这个小规则的重要部分是你几乎总是使用内存来控制测试。
当然,你可以编写这样的代码:
1 if 1 < 2:
2 print("but...why?")
不过这是毫无意义的,因为它只是在一个毫无意义的测试之后运行第二行。1始终小于2,所以这是无用的。
当您使用变量进行测试以使测试基于计算动态化时,像COMPARE_OP这样的测试就会发挥作用。这就是为什么我认为这是“代码游戏”的一条规则,因为没有变量的代码实际上并不在玩游戏。
仔细回顾以前的示例,并确定在哪些地方使用LOAD指令加载值,以及使用STORE指令将值存储到内存中。
规则 5:输入/输出控制存储
“代码游戏”的最后一条规则是您的代码如何与外部世界互动。拥有变量很好,但一个只包含您在源文件中键入的数据的程序并不是很有用。您需要的是输入和输出。
输入是您从文件、键盘或网络等地方将数据输入到代码中的方式。在上一个模块中,您已经使用open()和input()来做到这一点。每次打开文件、读取内容并对其执行操作时,您都会访问输入。当您使用input()向用户提问时,您也使用了输入。
输出是如何保存或传输程序结果的。输出可以是通过print()输出到屏幕,通过file.write()输出到文件,甚至通过网络传输。
让我们对input('Yes? ')的简单使用运行dis(),看看它做了什么:
1 from dis import dis
2 dis("input('Yes? ')")
3
4 0 LOAD_NAME 0 (input)
5 2 LOAD_CONST 0 ('Yes? ')
6 4 CALL_FUNCTION 1
7 6 RETURN_VALUE
你可以看到现在有一个新的指令CALL_FUNCTION,它实现了你在练习 18 中学到的函数调用。当 Python 看到CALL_FUNCTION时,它会找到用LOAD_NAME加载的函数,然后跳转到该函数以运行该函数的代码。函数如何工作背后有很多东西,但你可以将CALL_FUNCTION看作类似于JUMP_ABSOLUTE,但是跳转到指令中的一个命名位置。
将所有内容整合在一起
根据这五条规则,我们有以下代码游戏:
-
您将数据作为程序的输入读取(规则#5)
-
您将这些数据存储在存储器中(变量)(规则#4)
-
您使用这些变量执行测试…(规则#3)
-
… 这样您就可以在各处跳转…(规则#2)
-
… 指令序列…(规则#1)
-
… 将数据转换为新变量(规则#4)…
-
… 然后将其写入输出以进行存储或显示(规则#5)
尽管这看起来很简单,但这些小规则创造了非常复杂的软件。视频游戏是一个很好的例子,非常复杂的软件就是这样做的。视频游戏会读取您的控制器或键盘作为输入,更新控制场景中模型的变量,并使用高级指令将场景呈现到屏幕上作为输出。
现在花点时间回顾你已经完成的练习,看看你是否更好地理解它们。在你不理解的代码上使用dis()是否有帮助,还是更加困惑?如果有帮助,那就尝试在所有代码上使用它以获得新的见解。如果没有帮助,那就记住它以备以后使用。当你在练习 26 上这样做时,这将会特别有趣。
字节码列表
随着你继续练习,我会让你在一些代码上运行dis()来分析它在做什么。你需要完整的 Python 字节码列表来学习,可以在文档的末尾找到[dis()](https://docs.python.org/3/library/dis.xhtml#python-bytecode-instructions)。
dis()是一个支线任务
后续练习将包含一些短小的部分,要求你在代码上运行dis()来研究字节码。这些部分是你教育过程中的“支线任务”。这意味着它们不是理解 Python 必不可少的,但如果你完成它们,可能会在以后有所帮助。如果它们太难了,那就跳过它们,继续进行课程的其他部分。
dis()最重要的一点是它直接让你了解Python认为你的代码在做什么。如果你对代码的工作原理感到困惑,或者只是好奇 Python 实际在做什么,这会对你有所帮助。
练习 28:记忆逻辑
今天是你开始学习逻辑的一天。到目前为止,你已经尽可能地阅读和写入文件,使用终端,并且已经学会了 Python 的许多数学功能。
从现在开始,你将学习逻辑。你不会学习学术界喜欢研究的复杂理论,而只会学习使真实程序运行并且真正的程序员每天都需要的简单基本逻辑。
学习逻辑必须在你进行一些记忆工作之后进行。我希望你能坚持做这个练习整整一个星期。即使你感到无聊透顶,也要坚持下去。这个练习有一组逻辑表格,你必须记住它们,以便让你更容易完成后面的练习。
我警告你,一开始这可能不会很有趣。这将会非常无聊和乏味,但这会教会你作为程序员所需要的一项非常重要的技能。你将需要能够记忆生活中重要的概念。一旦你掌握了这些概念,大多数都会变得令人兴奋。你将与之奋斗,就像与章鱼搏斗一样,然后有一天你会理解它。所有记忆基础知识的工作以后会有很大的回报。
以下是一个提示,如何在不发疯的情况下记忆某些内容:每天分散一点时间进行学习,并记录下你最需要重点学习的内容。不要试图连续坐下两个小时来记忆这些表格。这样做是不会奏效的。你的大脑只会记住你最开始学习的 15 或 30 分钟的内容。相反,创建一堆索引卡,每一列在正面(True 或 False),背面是对应的列。然后拿出来,看到“True 或 False”立即说“True!”不断练习直到能够做到这一点。
一旦你能做到这一点,每天晚上开始在笔记本上写下自己的真值表。不要只是复制它们。尝试从记忆中完成。当遇到困难时,快速瞥一眼我这里的表格以刷新记忆。这样做将训练你的大脑记住整个表格。
不要花费超过一周的时间在这上面,因为你将在学习过程中应用它。
真值术语
在 Python 中,我们有以下术语(字符和短语)来确定某些东西在程序中是否为“True”或“False”。计算机上的逻辑完全是关于查看这些字符和一些变量的组合在程序的某一点是否为 True。
-
and -
or -
not -
!=(不等于) -
==(等于) -
>=(大于等于) -
<=(小于等于) -
True -
False
你实际上之前已经遇到过这些字符,只是可能不是这些术语。这些术语(and、or、not)实际上的工作方式与你期望的一样,就像英语中一样。
真值表
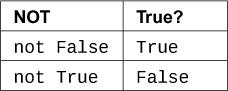
现在我们将使用这些字符制作你需要记忆的真值表。首先是not X的表:
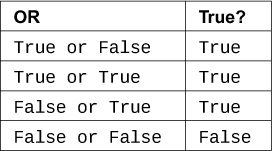
这是X or Y的表格:
现在是X and Y的表格:
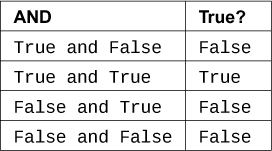
接下来是not与or组合的表格,即not (X or Y):

你应该将这些表格与or和and的表格进行比较,看看是否注意到了模式。这是not (X and Y)的表格。如果你能找出模式,也许就不需要记忆它们了。

现在我们来讨论等式,即以各种方式测试一件事是否等于另一件事。首先是X != Y:
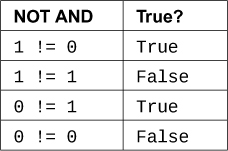
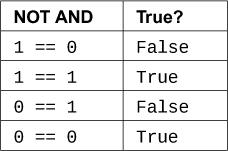
最后是X == Y:
现在使用这些表格编写你自己的卡片,并花一周时间记忆它们。请记住,这本书中没有失败,只有每天尽力而为,然后再多努力一点。
常见学生问题
我不能只学习布尔代数背后的概念而不记忆这些吗? 当然可以,但那样的话,你在编码时就必须不断查阅布尔代数的规则。如果你先记忆这些,不仅可以提高你的记忆能力,而且使这些操作变得自然。之后,布尔代数的概念就很容易了。但请按照适合你的方式去做。
练习 29:布尔练习
你从上一个练习中学到的逻辑组合被称为“布尔”逻辑表达式。布尔逻辑在编程中被广泛使用。它是计算的基本部分,熟练掌握这些逻辑表达式就相当于熟练掌握音乐中的音阶。
在这个练习中,你将把你记住的逻辑练习放入 Python 中尝试。拿出每个逻辑问题,并写下你认为答案会是什么。在每种情况下,答案将是
True 或 False。一旦你把答案写下来,你将在终端中启动 Python 并输入每个逻辑问题以确认你的答案。
1\. True and True
2\. False and True
3\. 1 == 1 and 2 == 1
4\. "test" == "test"
5\. 1 == 1 or 2 != 1
6\. True and 1 == 1
7\. False and 0 != 0
8\. True or 1 == 1
9\. "test" == "testing"
10. 1 != 0 and 2 == 1
11. "test" != "testing"
12. "test" == 1
13. not (True and False)
14. not (1 == 1 and 0 != 1)
15. not (10 == 1 or 1000 == 1000)
16. not (1 != 10 or 3 == 4)
17. not ("testing" == "testing" and "Zed" == "Cool Guy")
18. 1 == 1 and (not ("testing" == 1 or 1 == 0))
19. "chunky" == "bacon" and (not (3 == 4 or 3 == 3))
20. 3 != 3 and (not ("testing" == "testing" or "Python" == "Fun"))
我还会给你一个技巧,帮助你解决更复杂的问题。
每当你看到这些布尔逻辑语句,你都可以通过这个简单的过程轻松解决它们:
-
找到一个相等测试(== 或 !=)并用其真值替换
-
找到括号中的每个
and/or并首先解决它们 -
找到每个
not并反转它 -
找到任何剩余的
and/or并解决它 -
完成后,你应该有 True 或 False
我将演示一个对 #20 的变体:
1 3 != 4 and not ("testing" != "test" or "Python" == "Python")
这是我逐步进行每个步骤并展示翻译的过程,直到将其简化为一个结果:
- 解决每个相等测试:
-
3 != 4是True,所以用True替换得到True and not ("testing" != "test"or "Python" == "Python") -
"testing" != "test"是True,所以用True替换 that 得到True and not (Trueor "Python" == "Python") -
"Python" == "Python"是 True,所以用True替换,得到True andnot (True or True)
- 找到括号中的每个
and/or:
(True or True)是True,所以替换得到True and not (True)
- 找到每个
not并反转它:
not (True)是False,所以替换得到True and False
- 找到任何剩余的
and/or并解决它们:
True and False是False,你完成了
有了这个,我们就完成了,知道结果是 False。
警告!
更复杂的可能一开始看起来很难。你应该能够很好地尝试解决它们,但不要灰心。我只是让你为更多这些“逻辑体操”做好准备,这样以后更酷的东西会更容易。坚持下去,记录下你做错的地方,但不要担心它还没有完全进入你的脑海。它会的。
你应该看到的结果
在你尝试猜测这些之后,你的 Jupyter 单元格可能会是这样的:
1 >>> True and True
2 True
3 >>> 1 == 1 and 2 == 2
4 True
学习练习
-
Python 中有很多类似于
!=和==的运算符。尽量找到尽可能多的“相等运算符”。它们应该类似于<或<=。 -
写出每个相等运算符的名称。例如,我称
!=为“不等于”。 -
通过键入新的布尔运算符来玩 Python,在按下回车键之前,试着大声说出它是什么。不要思考。大声说出脑海中首先出现的东西。写下来,然后按下回车,并记录你答对和答错的次数。
-
丢掉第 3 个学习练习中的纸张,这样你就不会在以后不小心尝试使用它。
常见学生问题
为什么 "test" and "test" 返回 "test" 或 1 and 1 返回 1 而不是 True? Python 和许多其他语言喜欢返回其布尔表达式的操作数之一,而不仅仅是 True 或 False。这意味着如果你执行 False and 1,你会得到第一个操作数(False),但如果你执行 True and 1,你会得到第二个操作数(1)。试着玩弄一下这个。
!= 和 <> 之间有什么区别吗?Python 已经弃用了 <>,请使用 !=。除此之外,应该没有任何区别。
有没有捷径? 有。任何具有 False 的 and 表达式立即为 False,所以你可以在那里停止。任何具有 True 的 or 表达式立即为 True,所以你可以在那里停止。但确保你能处理整个表达式,因为以后这会变得有用。