目录
- 1. 堆排序
- 1.1补充:建堆的时间复杂度
- 1.2 堆排序:升序与降序
- 2. TopK问题
- 3. 二叉树的链式结构及其遍历方式
- 3.1 二叉树的链式结构
- 3.2 二叉树的前序遍历
- 2.2 二叉树的中序遍历
- 2.3 后序遍历
- 2.4 层序遍历
- 4. 二叉树OJ练习
- 4.1 单值二叉树
- 4.2 判断两棵二叉树是否相等
- 4.3 判断对称二叉树
- 4.4 另一棵二叉树的子树
- 4.5 二叉树的构建与销毁
- 4.6 判断二叉树是否为完全二叉树
- 4.7 补充练习
- 4.7.1 二叉树的节点数
- 4.7.2 二叉树的叶子节点数
- 4.7.3 二叉树的第K层结点数
- 4.7.4 查找二叉树中为x值的结点
1. 堆排序
1.1补充:建堆的时间复杂度
这里使用满二叉树近似计算,向下调整法建堆的时间复杂度:
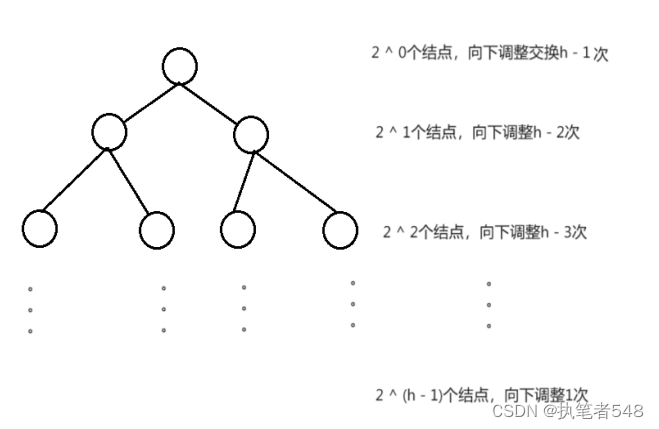
等比数列求和,得需调整n - log(n + 1),时间复杂度为O(n)
1.2 堆排序:升序与降序
思路:我们先建堆,然后将堆顶(堆顶元素总是为最大或最小)的元素与尾部元素交换,size–,然后向下调整,直至堆为空。
- 排升序,建大堆(大堆的父亲结点都大于小堆)
- 排降序,建小堆
代码实现如下:
void HeapAdjustDown(int* arr, int n, int parent)
{
//n为元素个数
int child = parent * 2 + 1;
while (child < n)
{
if (child + 1 < n && arr[child] < arr[child + 1])
{
child++;
}
if (arr[parent] < arr[child])
{
swap(&arr[parent], &arr[child]);
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}
int arr[] = { 27,15,18,28,34,65,49,25,37 };
//向下调整建堆
int n = sizeof(arr) / sizeof(arr[0]);
for (int i = (n - 1 - 1) / 2; i >= 0; i--)
{
HeapAdjustDown(arr, n, i);
}
ArrPrint(arr, n);
//交换首尾元素,size--,再向下调整
int size = n;
while (size)
{
swap(&arr[0], &arr[size - 1]);
size--;
HeapAdjustDown(arr, size, 0);
}
2. TopK问题
当数据量很大时,且为乱序,数据无法一下全部加载到内存中,所以整体排序无法得出最大或最小的前K个数,那么,如何快速得出前K个最大/最小数。
思路:
先于数据首部建一个大小为K的
- 得出最大,建小堆
- 得出最小,建大堆
然后,再将剩余的N- K个数据与堆顶元素比较
- 当需要最大的数时,若比较元素大于堆顶元素,则交换二者再进行向下调整。
- 当需要最小的数时,若比较元素小于堆顶元素,则交换二者再进行向下调整。
void HeapAdjustDown2(int* arr, int n, int parent)
{
//n为元素个数
int child = parent * 2 + 1;
while (child < n)
{
if (child + 1 < n && arr[child] > arr[child + 1])
{
child++;
}
if (arr[parent] > arr[child])
{
swap(&arr[parent], &arr[child]);
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}
void TopK(int* arr, int k, int n)
{
//筛选k个最大的数
//在数据顶部建一个大小为k的小堆
for (int i = (k - 1 - 1) / 2; i >= 0; i--)
{
HeapAdjustDown2(arr, k, i);
}
//若遍历到大于堆顶的元素,交换并向下调整
for (int j = k; j < n; j++)
{
if (arr[j] > arr[0])
{
swap(&arr[j], &arr[0]);
HeapAdjustDown2(arr, k, 0);
}
}
}
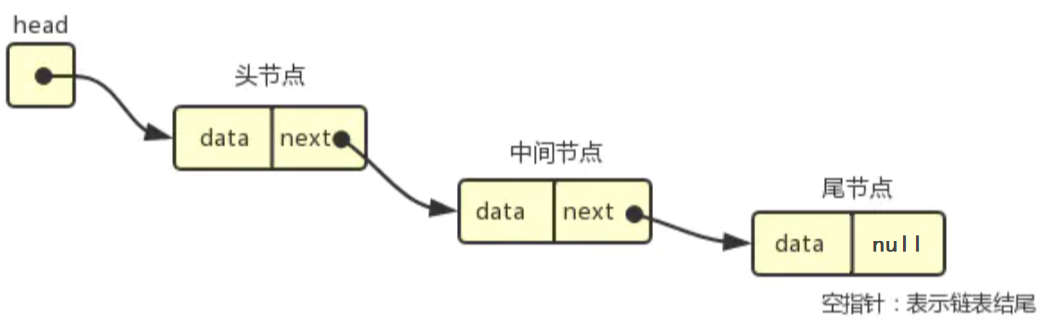
3. 二叉树的链式结构及其遍历方式
3.1 二叉树的链式结构
在前面的学习中,我们已经了解到,二叉树的结构由三部分组成根,左子树,右子树。
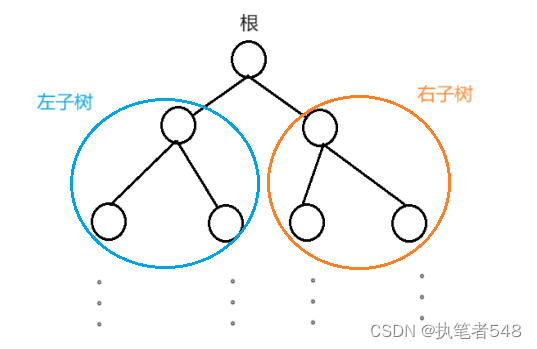
当我们使用链式存储的方式构建二叉树时,其结点的结构定义如下:
typedef struct TreeNode
{
int val;
//左子树指针
struct TreeNode* left;
//右子树指针
struct TreeNode* right;
}
根据逻辑遍历的方式顺序不同,二叉树的遍历方式分为四种:前序,中序,后序,层序
3.2 二叉树的前序遍历
- 遍历逻辑顺序:根结点,左子树,右子树(根左右)
- 题目链接:
前序遍历
void preorder_part(struct TreeNode* root, int* arr, int* size)
{
if(root == NULL)
{
return;
}
arr[*size] = root->val;
(*size)++;
preorder_part(root->left, arr, size);
preorder_part(root->right, arr, size);
}
int* preorderTraversal(struct TreeNode* root, int* returnSize)
{
//根左右
//为空树时,不反回空指针
//返回数组
*returnSize = 0;
int* arr = (int*)malloc(100 * sizeof(int));
preorder_part(root, arr, returnSize);
return arr;
}
2.2 二叉树的中序遍历
- 遍历逻辑顺序:左根右
- 题目链接:
中序遍历
void inorder_part(struct TreeNode* root, int* arr, int* size)
{
if(root == NULL)
{
return;
}
inorder_part(root->left, arr, size);
arr[*size] = root->val;
(*size)++;
inorder_part(root->right, arr, size);
}
int* inorderTraversal(struct TreeNode* root, int* returnSize)
{
*returnSize = 0;
int* arr = (int*)malloc(100 * sizeof(int));
inorder_part(root, arr, returnSize);
return arr;
}
2.3 后序遍历
- 遍历逻辑顺序:左右根
- 题目链接:
后序遍历
void postorder_part(struct TreeNode* root, int* arr, int* size)
{
if(root == NULL)
{
return;
}
postorder_part(root->left, arr, size);
postorder_part(root->right, arr, size);
arr[*size] = root->val;
(*size)++;
}
int* postorderTraversal(struct TreeNode* root, int* returnSize)
{
*returnSize = 0;
int* arr = (int*)malloc(100 * sizeof(int));
postorder_part(root, arr, returnSize);
return arr;
}
2.4 层序遍历
遍历逻辑:依次按层进行遍历(利用队列存储子节点)
void LevelOrder(TreeNode* root)
{
Queue q1;
QueueInit(&q1);
QueuePush(&q1, root);
TreeNode* top = QueueFront(&q1);
while (!QueueEmpty(&q1))
{
if (top)
{
QueuePush(&q1, top->left);
QueuePush(&q1, top->right);
}
if (top)
{
printf("%c ", top->val);
}
else
{
printf("NULL ");
}
QueuePop(&q1);
if (!QueueEmpty(&q1))
{
top = QueueFront(&q1);
}
}
}
4. 二叉树OJ练习
4.1 单值二叉树
- 题目信息:
- 题目链接:
单值二叉树- 思路:任选一种遍历方式遍历整个二叉树,同时判断左右孩子结点的值等于父亲结点的值

bool isUnivalTree(struct TreeNode* root)
{
if(root == NULL)
{
return true;
}
if(root->left && root->val != root->left->val)
{
return false;
}
if(root->right && root->val != root->right->val)
{
return false;
}
return isUnivalTree(root->left) && isUnivalTree(root->right);
}
4.2 判断两棵二叉树是否相等
- 题目信息:
- 题目链接:
判断两颗二叉树是否相等
3 . 思路:按同样顺序遍历两棵树,同时判断

bool isSameTree(struct TreeNode* p, struct TreeNode* q)
{
//调整逻辑顺序,不出现越界情况
//二者都为NULL
if(p == NULL && q == NULL)
{
return true;
}
//有一个为NULL
if(p && q == NULL)
{
return false;
}
if(q && p == NULL)
{
return false;
}
//都不为NULL
if(p->val != q->val)
{
return false;
}
return isSameTree(p->left, q->left) && isSameTree(p->right, q->right);
}
4.3 判断对称二叉树
- 题目信息:
- 题目链接:
对称二叉树- 思路:按照对称的遍历方式,遍历判断二叉树的左右子树

bool order_part(struct TreeNode* left, struct TreeNode* right)
{
if(left == NULL && right == NULL)
{
return true;
}
if(left && right == NULL)
{
return false;
}
if(right && left == NULL)
{
return false;
}
if(left->val != right->val)
{
return false;
}
return order_part(left->left, right->right) && order_part(left->right, right->left);
}
bool isSymmetric(struct TreeNode* root)
{
return order_part(root->left, root->right);
}
4.4 另一棵二叉树的子树
1.题目信息:
2. 题目链接:
另一颗树的子树
3. 思路:遇到与配对子树的根节点相同的结点即开始配对,直至遍历完整个树。
4. 注:将逻辑,语言转换(翻译)为代码

bool isSameTree(struct TreeNode* p, struct TreeNode* q)
{
//调整逻辑顺序,不出现越界情况
//二者都为NULL
if(p == NULL && q == NULL)
{
return true;
}
//有一个为NULL
if(p && q == NULL)
{
return false;
}
if(q && p == NULL)
{
return false;
}
//都不为NULL
if(p->val != q->val)
{
return false;
}
return isSameTree(p->left, q->left) && isSameTree(p->right, q->right);
}
bool isSubtree(struct TreeNode* root, struct TreeNode* subRoot)
{
if(root == NULL)
{
return false;
}
if(root->val == subRoot->val && isSameTree(root, subRoot))
{
return true;
}
return isSubtree(root->left, subRoot) || isSubtree(root->right, subRoot);
}
4.5 二叉树的构建与销毁
- 题目信息:
- 题目链接:
二叉树的构建与遍历- 先创建根结点,再依次创建左子树,右子树

typedef struct TreeNode
{
char val;
struct TreeNode* left;
struct TreeNode* right;
}TreeNode;
void inorder_part(struct TreeNode* root, char* arr, int* size)
{
if (root == NULL)
{
return;
}
inorder_part(root->left, arr, size);
arr[*size] = root->val;
(*size)++;
inorder_part(root->right, arr, size);
}
char* inorderTraversal(struct TreeNode* root, int* returnSize)
{
//根左右
//为空树时,不反回空指针
//返回数组
*returnSize = 0;
char* arr = (char*)malloc(100 * sizeof(int));
inorder_part(root, arr, returnSize);
return arr;
}
TreeNode* BuyTreeNode(char val)
{
TreeNode* newnode = (TreeNode*)malloc(sizeof(TreeNode));
newnode->val = val;
newnode->left = newnode->right = NULL;
return newnode;
}
TreeNode* BinaryTreeCreate(char* a, int n, int* pi)
{
TreeNode* root = NULL;
if (a[*pi] == '#')
{
(*pi)++;
return NULL;
}
if (a[*pi] != '#')
{
root = BuyTreeNode(a[*pi]);
}
(*pi)++;
root->left = BinaryTreeCreate(a, n, pi);
root->right = BinaryTreeCreate(a, n, pi);
return root;
}
int main()
{
char* a = (char*)malloc(100 * sizeof(char));
char str;
int count = 0;
while(scanf("%c", &str) != EOF)
{
a[count++] = str;
}
int i = 0;
TreeNode* root = BinaryTreeCreate(a, strlen(a), &i);
int returnSize = 0;
char* ret = inorderTraversal(root, &returnSize);
for (int j = 0; j < returnSize; j++)
{
printf("%c ", ret[j]);
}
return 0;
}
二叉树的销毁:
void BinaryTreeDestory(TreeNode* root)
{
//后序遍历
if (root == NULL)
{
return;
}
BinaryTreeDestory(root->left);
BinaryTreeDestory(root->right);
free(root);
}
4.6 判断二叉树是否为完全二叉树
思路:使用层序遍历,如果出现NULL后,又出现非NULL指针,那么此树就不是完全二叉树,反之,则是。
int BinaryTreeComplete(TreeNode* root)
{
//层序遍历判断是否为完全二叉树
Queue q1;
QueueInit(&q1);
QueuePush(&q1, root);
TreeNode* top = QueueFront(&q1);
//标志有NULL指针出现
int count = 0;
while (!QueueEmpty(&q1))
{
if (top)
{
QueuePush(&q1, top->left);
QueuePush(&q1, top->right);
}
if (top == NULL)
{
count++;
}
if (count && top)
{
return 0;
}
QueuePop(&q1);
if (!QueueEmpty(&q1))
{
top = QueueFront(&q1);
}
}
return 1;
}
4.7 补充练习
4.7.1 二叉树的节点数
// 二叉树节点个数
int BinaryTreeSize(TreeNode* root)
{
//根结点 + 左子树结点 + 右子树结点
if (root == NULL)
{
return 0;
}
return BinaryTreeSize(root->left) + BinaryTreeSize(root->right) + 1;
}
4.7.2 二叉树的叶子节点数
// 二叉树叶子节点个数
int BinaryTreeLeafSize(TreeNode* root)
{
if (root == NULL)
{
return 0;
}
if (root->left == NULL && root->right == NULL)
{
return 1;
}
return BinaryTreeLeafSize(root->left) + BinaryTreeLeafSize(root->right);
}
4.7.3 二叉树的第K层结点数
// 二叉树第k层节点个数
int BinaryTreeLevelKSize(TreeNode* root, int k)
{
if (k == 0)
{
return 1;
}
return BinaryTreeLevelKSize(root->left, k - 1) + BinaryTreeLevelKSize(root->right, k - 1);
}
4.7.4 查找二叉树中为x值的结点
// 二叉树查找值为x的节点
TreeNode* BinaryTreeFind(TreeNode* root, char x)
{
//没找到
if (root == NULL)
{
return NULL;
}
//找到了
if (root->val == x)
{
return root;
}
//在左侧找
TreeNode* left = BinaryTreeFind(root->left, x);
//在右侧找
TreeNode* right = BinaryTreeFind(root->right, x);
if (left)
{
return left;
}
return right;
}