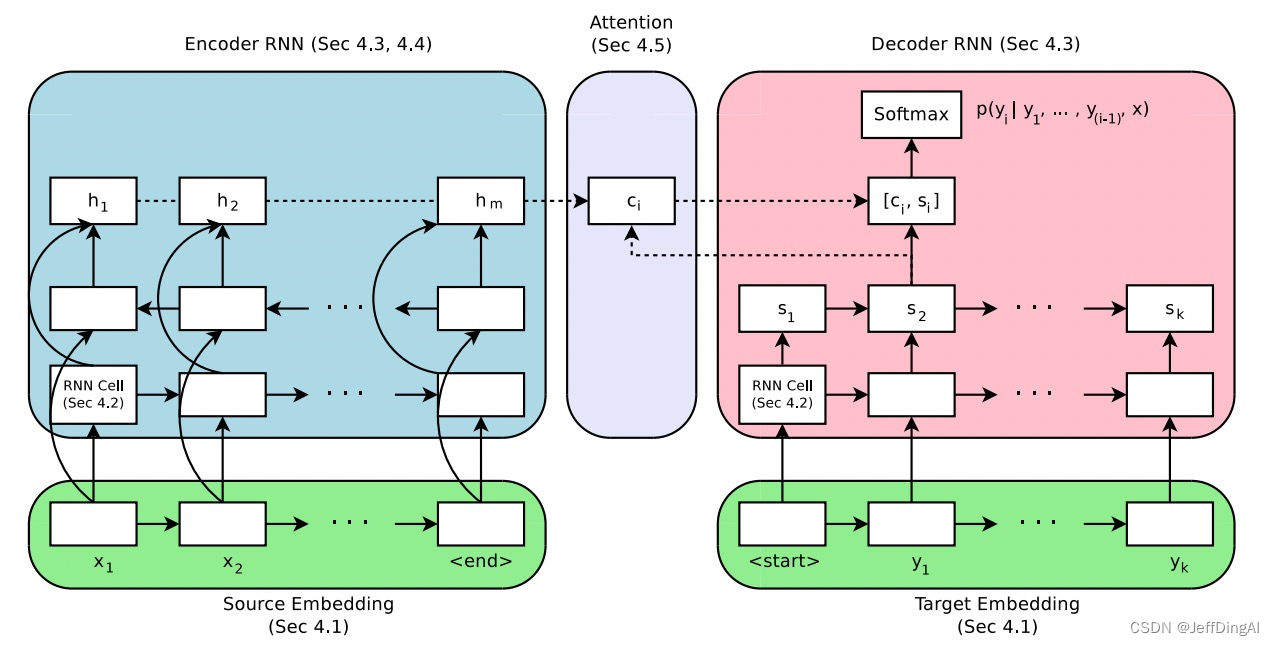
Attention
Attention = 注意力,从两个不同的主体开始。
论文:https://arxiv.org/pdf/1703.03906.pdf
seq2seq代码仓:https://github.com/google/seq2seq
计算方法:
加性Attention,如(Bahdanau attention):
v
a
⊤
tanh
(
W
1
h
t
+
W
2
h
‾
s
)
\boldsymbol{v}_a^{\top} \tanh \left(\boldsymbol{W}_{\mathbf{1}} \boldsymbol{h}_t+\boldsymbol{W}_{\mathbf{2}} \overline{\boldsymbol{h}}_s\right)
va⊤tanh(W1ht+W2hs)
乘性Attention,如(Luong attention):
score
(
h
t
,
h
‾
s
)
=
{
h
t
⊤
h
‾
s
dot
h
t
⊤
W
a
h
‾
s
general
v
a
⊤
tanh
(
W
a
[
h
t
;
h
‾
s
]
)
concat
\operatorname{score}\left(\boldsymbol{h}_{t}, \overline{\boldsymbol{h}}_{s}\right)=\left\{\begin{array}{ll} \boldsymbol{h}_{t}^{\top} \overline{\boldsymbol{h}}_{s} & \text { dot } \\ \boldsymbol{h}_{t}^{\top} \boldsymbol{W}_{a} \overline{\boldsymbol{h}}_{s} & \text { general } \\ \boldsymbol{v}_{a}^{\top} \tanh \left(\boldsymbol{W}_{a}\left[\boldsymbol{h}_{t} ; \overline{\boldsymbol{h}}_{s}\right]\right) & \text { concat } \end{array}\right.
score(ht,hs)=⎩
⎨
⎧ht⊤hsht⊤Wahsva⊤tanh(Wa[ht;hs]) dot general concat
来源论文:https://arxiv.org/pdf/1508.04025.pdf
From Attention to SelfAttention
Self Attention
“Attention is All You Need” 这篇论文提出了Multi-Head Self-Attention,是一种:Scaled Dot-Product Attention。
Attention ( Q , K , V ) = softmax ( Q K T d k ) V \operatorname{Attention}(Q, K, V)=\operatorname{softmax}\left(\frac{Q K^T}{\sqrt{d_k}}\right) V Attention(Q,K,V)=softmax(dkQKT)V
来源论文:https://arxiv.org/pdf/1706.03762.pdf
Scaled
Scaled 的目的是调节内积,使其结果不至于太大(太大的话softmax后就非0即1了,不够“soft”了)。
来源论文: https://kexue.fm/archives/4765
Multi-Head
Multi-Head可以理解为多个注意力模块,期望不同注意力模块“注意”到不一样的地方,类似于CNN的Kernel。
Multi-head attention allows the model to jointly attend to information from different representation
subspaces at different positions.
MultiHead
(
Q
,
K
,
V
)
=
Concat
(
head
1
,
…
,
head
h
)
W
O
where head
i
=
Attention
(
Q
W
i
Q
,
K
W
i
K
,
V
W
i
V
)
\begin{aligned} \operatorname{MultiHead}(Q, K, V) & =\operatorname{Concat}\left(\operatorname{head}_1, \ldots, \text { head }_{\mathrm{h}}\right) W^O \\ \text { where head }_{\mathrm{i}} & =\operatorname{Attention}\left(Q W_i^Q, K W_i^K, V W_i^V\right) \end{aligned}
MultiHead(Q,K,V) where head i=Concat(head1,…, head h)WO=Attention(QWiQ,KWiK,VWiV)
来源论文: https://arxiv.org/pdf/1706.03762.pdf
代码实践
Attention
导入库
from dataclasses import dataclass
import torch
import torch.nn as nn
import torch.nn.functional as F
from selfattention import SelfAttention
我们只用一个核心的SelfAttention模块(可支持Single-Head或Multi-Head),来学习理解Attention机制。
class Model(nn.Module):
def __init__(self, config):
super().__init__()
self.config = config
self.emb = nn.Embedding(config.vocab_size, config.hidden_dim)
self.attn = SelfAttention(config)
self.fc = nn.Linear(config.hidden_dim, config.num_labels)
def forward(self, x):
batch_size, seq_len = x.shape
h = self.emb(x)
attn_score, h = self.attn(h)
h = F.avg_pool1d(h.permute(0, 2, 1), seq_len, 1)
h = h.squeeze(-1)
logits = self.fc(h)
return attn_score, logits
@dataclass
class Config:
vocab_size: int = 5000
hidden_dim: int = 512
num_heads: int = 16
head_dim: int = 32
dropout: float = 0.1
num_labels: int = 2
max_seq_len: int = 512
num_epochs: int = 10
config = Config(5000, 512, 16, 32, 0.1, 2)
model = Model(config)
x = torch.randint(0, 5000, (3, 30))
x.shape
#torch.Size([3, 30])
attn, logits = model(x)
attn.shape, logits.shape
#(torch.Size([3, 16, 30, 30]), torch.Size([3, 2]))
数据
import pandas as pd
from sklearn.model_selection import train_test_split
file_path = "./data/ChnSentiCorp_htl_all.csv"
df = pd.read_csv(file_path)
df = df.dropna()
df.head(), df.shape
'''
( label review
0 1 距离川沙公路较近,但是公交指示不对,如果是"蔡陆线"的话,会非常麻烦.建议用别的路线.房间较...
1 1 商务大床房,房间很大,床有2M宽,整体感觉经济实惠不错!
2 1 早餐太差,无论去多少人,那边也不加食品的。酒店应该重视一下这个问题了。房间本身很好。
3 1 宾馆在小街道上,不大好找,但还好北京热心同胞很多~宾馆设施跟介绍的差不多,房间很小,确实挺小...
4 1 CBD中心,周围没什么店铺,说5星有点勉强.不知道为什么卫生间没有电吹风,
(7765, 2))
'''
df.label.value_counts()
'''
label
1 5322
0 2443
Name: count, dtype: int64
'''
数据不均衡,我们给它简单重采样一下。
df = pd.concat([df[df.label==1].sample(2500), df[df.label==0]])
df.shape
#(4943, 2)
df.label.value_counts()
'''
label
1 2500
0 2443
Name: count, dtype: int64
'''
from tokenizer import Tokenizer
tokenizer = Tokenizer(config.vocab_size, config.max_seq_len)
tokenizer.build_vocab(df.review)
tokenizer(["你好", "你好呀"])
'''
tensor([[3233, 0],
[3233, 955]])
'''
def collate_batch(batch):
label_list, text_list = [], []
for v in batch:
_label = v["label"]
_text = v["text"]
label_list.append(_label)
text_list.append(_text)
inputs = tokenizer(text_list)
labels = torch.LongTensor(label_list)
return inputs, labels
from dataset import Dataset
ds = Dataset()
ds.build(df, "review", "label")
len(ds), ds[0]
'''
(4943,
{'text': '1、酒店环境不错,地理位置佳。到十全街、凤凰街挺方便的。属于闹中取静的那种。2、客房里设施齐全、干净,比较方便。卫浴设施也挺好的。插头挺多的,很好。房间很干净,也挺温馨的。3、自助餐还可以。美中不足之处:1、卫生纸的质量比较差。2、饭店里最好可以提供(自助)洗衣、干衣的服务。3、房间里的小冰箱效果不好,声音也比较响。反正不用,我就关掉了。总体感觉不错,性价比高,下次还来住。',
'label': 1})
'''
train_ds, test_ds = train_test_split(ds, test_size=0.2)
train_ds, valid_ds = train_test_split(train_ds, test_size=0.1)
len(train_ds), len(valid_ds), len(test_ds)
#(3558, 396, 989)
from torch.utils.data import DataLoader
BATCH_SIZE = 8
train_dl = DataLoader(train_ds, batch_size=BATCH_SIZE, collate_fn=collate_batch)
valid_dl = DataLoader(valid_ds, batch_size=BATCH_SIZE, collate_fn=collate_batch)
test_dl = DataLoader(test_ds, batch_size=BATCH_SIZE, collate_fn=collate_batch)
len(train_dl), len(valid_dl), len(test_dl)
#(445, 50, 124)
for v in train_dl: break
v[0].shape, v[1].shape, v[0].dtype, v[1].dtype
#(torch.Size([8, 225]), torch.Size([8]), torch.int64, torch.int64)
训练
from trainer import train, test
NUM_EPOCHS = 10
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
config = Config(5000, 64, 1, 64, 0.1, 2)
model = Model(config)
model.to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3, weight_decay=1e-3)
train(model, optimizer, train_dl, valid_dl, config)
test(model, test_dl)
'''
Epoch [1/10]
Iter: 445, Train Loss: 0.52, Train Acc: 0.75, Val Loss: 0.52, Val Acc: 0.74
Epoch [2/10]
Iter: 890, Train Loss: 0.51, Train Acc: 0.75, Val Loss: 0.51, Val Acc: 0.76
Epoch [3/10]
Iter: 1335, Train Loss: 0.50, Train Acc: 0.62, Val Loss: 0.52, Val Acc: 0.78
Epoch [4/10]
Iter: 1780, Train Loss: 0.51, Train Acc: 0.62, Val Loss: 0.49, Val Acc: 0.79
Epoch [5/10]
Iter: 2225, Train Loss: 0.56, Train Acc: 0.62, Val Loss: 0.45, Val Acc: 0.81
Epoch [6/10]
Iter: 2670, Train Loss: 0.64, Train Acc: 0.88, Val Loss: 0.41, Val Acc: 0.82
Epoch [7/10]
Iter: 3115, Train Loss: 0.58, Train Acc: 0.88, Val Loss: 0.38, Val Acc: 0.84
Epoch [8/10]
Iter: 3560, Train Loss: 0.52, Train Acc: 0.75, Val Loss: 0.36, Val Acc: 0.85
Epoch [9/10]
Iter: 4005, Train Loss: 0.45, Train Acc: 0.75, Val Loss: 0.37, Val Acc: 0.86
Epoch [10/10]
Iter: 4450, Train Loss: 0.34, Train Acc: 0.88, Val Loss: 0.38, Val Acc: 0.87
0.8554189267686065
'''
推理
from inference import infer, plot_attention
import numpy as np
sample = np.random.choice(test_ds)
while len(sample["text"]) > 20:
sample = np.random.choice(test_ds)
print(sample)
inp = sample["text"]
inputs = tokenizer(inp)
attn, prob = infer(model, inputs.to(device))
attn_prob = attn[0, 0, :, :].cpu().numpy()
tokens = tokenizer.tokenize(inp)
tokens, prob
'''
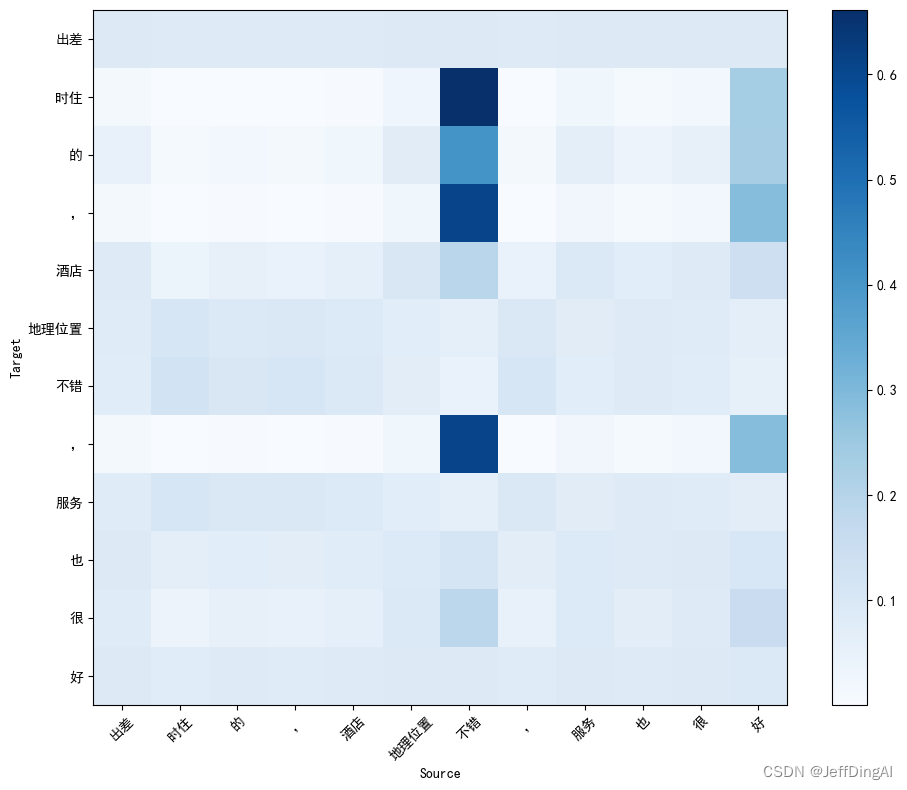
{'text': '买东西方便!不错的选择!大家也要选择', 'label': 1}
(['买', '东西', '方便', '!', '不错', '的', '选择', '!', '大家', '也', '要', '选择'], 1)
'''
plot_attention(attn_prob, tokens, tokens)
tokenizer.get_freq_of("不")
# 2659
LLM
准备代码仓
git clone https://github.com/hscspring/llama.np
cd llama.np/
下载模型
# 从这里下载模型 https://hf-mirror.com/karpathy/tinyllamas/tree/main
# 放到llama.np目录
import os
# 设置环境变量
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
# 下载模型
os.system('huggingface-cli download --resume-download karpathy/tinyllamas --local-dir /root/datawhale/sora_learn/datawhale/attention-llm/llm/llama.np')
转换格式
python convert_bin_llama_to_np.py stories15M.bin
生成
python main.py "Once upon"
LLaMA
from config import ModelArgs
from model import Llama
from tokenizer import Tokenizer
import numpy as np
args = ModelArgs(288, 6, 6, 6, 32000, None, 256)
token_model_path = "./tokenizer.model.np"
model_path = "./stories15M.model.npz"
tok = Tokenizer(token_model_path)
llama = Llama(model_path, args)
prompt = "Once upon"
ids = tok.encode(prompt)
input_ids = np.array([ids], dtype=np.int32)
token_num = input_ids.shape[1]
print(prompt, end="")
for ids in llama.generate(input_ids, args.max_seq_len, True, 1.0, 0.9, 0):
output_ids = ids[0].tolist()
if output_ids[-1] in [tok.eos_id, tok.bos_id]:
break
output_text = tok.decode(output_ids)
print(output_text, end="")
运行结果
**Once uponong end, there wa a girl named Sophie. She wa three year old and loved to explore. She had a different blouse with lot of bright colour.
One day, Sophie wa walking in the park with her mommy. She saw a shiny pedal on the ground. It wa a shiny one, so she picked it up and wa so excited to have found it.
“Mommy, look! I found a new pedal!” she said.
“That’ great, Sophie,” her mommy said. “I know, it look very exciting!”
But then Sophie noticed that her reflection in the bright blade of the pedal seemed very distant. She started to worry.
“Mommy, what’ wrong?” Sophie asked.
“It’ too far away to come back,” her mommy replied.
“Let’ go look for it,” Sophie said.
So they started to look for the pedal. They walked a bit further and eventually, they found it! Sophie wa so happy.
“Mommy, thi pedal i so interesting!” Sophie said.
Her mommy smiled and said, “Ye**
思考题
Attention
怎么理解Attention
Attention,即注意力机制,是一种在深度学习领域广泛应用的技术。其核心思想是在处理数据时,对不同的部分给予不同的关注程度。这种方法可以帮助模型更好地理解和处理复杂的问题,如自然语言处理、图像识别等。
具体来说,Attention可以从两个角度去理解:
-
从信息传递的角度看,Attention可以被视为一种加权平均的过程。在这个过程中,每个输入元素都会根据其重要性被赋予一个权重,而最终的输出则是所有输入元素的加权平均值。例如,在机器翻译任务中,Attention机制可以决定模型在生成目标语言的句子时,应该更多地关注源语言句子的哪些部分。
-
从数学的角度看,Attention通常由一个函数f定义,该函数将两个向量作为输入,并返回一个标量。这个函数可以是感知机,也可以是点积或者余弦相似度等。在这个函数的基础上,我们可以计算出每个输入元素的权重,进而得到最终的输出。
总的来说,Attention机制是一种强大的工具,它可以帮助模型更好地理解和处理复杂的问题,特别是在需要处理序列数据的情况下。
乘性Attention和加性Attention有什么不同
乘性Attention(Multiplicative Attention)和加性Attention(Additive Attention)是两种不同的注意力机制,它们在自然语言处理、计算机视觉等深度学习领域有着广泛的应用。以下是它们的主要区别:
-
定义:
- 乘性Attention: 乘性Attention的核心思想是通过将查询(Query)与键(Key)进行点积操作来计算注意力权重,这种方式可以捕捉到查询和键之间的内在关系。
- 加性Attention: 加性Attention则使用查询和键的点积结果经过一个单元激活函数(如tanh)后,再与值(Value)相乘得到输出。这种方法更加灵活,可以捕获更复杂的交互模式。
-
计算复杂度:
- 乘性Attention: 由于只涉及点积操作,其计算复杂度较低。
- 加性Attention: 因为需要额外的非线性变换,其计算复杂度较高。
-
模型表达能力:
- 乘性Attention: 由于仅依赖于点积,其表达能力相对有限。
- 加性Attention: 由于引入了非线性变换,其模型表达能力更强,能够捕捉到更丰富的特征交互信息。
-
训练难度:
- 乘性Attention: 由于结构简单,训练相对容易。
- 加性Attention: 因为增加了非线性变换,训练可能会更加复杂。
-
应用场景:
- 乘性Attention: 适用于需要快速计算且对计算资源要求较低的场景。
- 加性Attention: 适用于需要高精度模型且对计算资源要求较高的场景。
-
优势:
- 乘性Attention: 速度快,易于实现。
- 加性Attention: 灵活性高,可以捕获更复杂的交互模式。
-
缺点:
- 乘性Attention: 表达能力受限。
- 加性Attention: 计算成本高,训练难度大。
在实际应用中,选择哪种注意力机制取决于任务的具体需求、计算资源和数据特性。
Self-Attention为什么采用 Dot-Product Attention
Self-Attention采用Dot-Product Attention的原因主要是因为它能够捕捉序列中不同位置之间的关联性,并为每个位置生成一个上下文相关的表示。
具体来说,Dot-Product Attention通过计算查询(queries)和键(keys)之间的点积(dot-product)来获得注意力权重。这些权重然后被用于加权平均值(values),从而为每个位置生成一个上下文相关的表示。这个过程是并行的,不需要时序地生成,因此非常高效。
此外,为了稳定梯度和防止梯度消失或爆炸,点积在实际实现中通常会被缩放,即除以键(keys)的维度的平方根。这种缩放操作有助于确保模型的稳定性和收敛性。
总的来说,Dot-Product Attention是Self-Attention机制中的一种有效方式,它能够有效地捕捉序列中的关联性,并为每个位置生成一个上下文相关的表示,从而提高模型的性能。
Self-Attention中的Scaled因子有什么作用?必须是 sqrt(d_k) 吗?
在Self-Attention机制中,有一个关键的计算步骤是计算查询(Query)、键(Key)的点积并除以键的维度的平方根(sqrt(d_k))。这个过程就引入了所谓的“Scaled因子”。
这个Scaled因子的作用主要是为了防止模型在训练过程中出现梯度爆炸或者梯度消失的问题。当查询和键的向量长度非常大时,它们的点积可能会变得非常大,导致梯度爆炸;反之,如果向量长度很小,则可能会导致梯度消失。通过除以键的维度的平方根,我们可以将点积的值缩放到一个合理的范围,从而避免上述问题。
至于这个因子必须是sqrt(d_k),这其实是由论文《Attention is All You Need》中提出的Transformer模型所定义的。在实际应用中,这个因子的具体值可能会根据具体情况进行调整,但通常都会遵循这种形式,即除以某个与键的维度相关的因子。
Multi-Head Self-Attention,Multi越多越好吗,为什么?
在自注意力机制中,"Multi"指的是多个头(Heads),每个头都能学习到不同类型的上下文信息。所以,当你增加更多的"Multi"时,模型可以学习到更多样化的上下文信息。
“Multi"越多并不总是意味着效果越好。增加更多的"Multi"也会增加计算成本,而且如果数据量不足或者任务过于简单,增加"Multi"可能不会带来明显的提升,反而可能会导致过拟合。所以,是否增加"Multi”,以及增加多少,需要根据具体的任务和数据情况来决定。
Multi-Head Self-Attention,固定hidden_dim,你认为增加 head_dim (需要缩小 num_heads)和减少 head_dim 会对结果有什么影响?
在Multi-Head Self-Attention中,head_dim和num_heads是两个关键参数。头的维度(head_dim)和头的数量(num_heads)共同决定了模型的总计算能力。
-
增加head_dim:如果你固定了hidden_dim,那么增加head_dim就意味着你必须减少num_heads。这种情况下,每个头可以看到更多的信息,因为他们有更大的维度。但是,由于头的数量减少了,模型的整体计算能力实际上降低了。所以,这可能会导致模型在某些任务上的性能下降。
-
减少head_dim:相反,如果你减少head_dim,你就可以增加num_heads。这意味着每个头只能看到较少的信息,但模型整体的计算能力增加了。这可能对某些任务有帮助,因为它可以帮助模型更好地捕捉全局信息。
总的来说,head_dim和num_heads的选择应该根据具体的任务和数据集来决定。在实践中,通常需要进行一些实验来确定最佳值。
为什么我们一般需要对 Attention weights 应用Dropout?哪些地方一般需要Dropout?Dropout在推理时是怎么执行的?你怎么理解Dropout?
对Attention weights应用Dropout的原因主要是为了防止过拟合。在深度学习网络中,过拟合是一个常见的问题,它会导致模型在训练数据上表现良好,但在新的、未见过的测试数据上表现不佳。通过对Attention weights应用Dropout,我们可以随机地将某些权重设置为0,这样就迫使模型不依赖于某些特定的特征,从而提高模型的泛化能力。
一般来说,Dropout常用于全连接层和卷积层的输出,特别是在神经网络的最后几层。此外,如果你的网络使用了Attention机制,那么对Attention weights应用Dropout也是很有帮助的。
在推理时,Dropout并不会被执行。在训练过程中,由于Dropout会随机地将一些节点的输出设置为0,所以每次训练都会在不同的网络结构上进行。然而,在进行预测或者推理时,我们需要使用整个网络,而不是部分网络,所以Dropout就不再执行了。
理解Dropout的关键是认识到它是一种正则化技术,其目的是防止模型过拟合。通过在训练过程中随机地将某些节点的输出设置为0,Dropout迫使模型不依赖于某些特定的特征,从而提高模型的泛化能力。
Self-Attention的qkv初始化时,bias怎么设置,为什么?
在自注意力机制中,查询(Query)、键(Key)和值(Value)通常是由同一个输入向量通过三个不同的线性变换得到的。这三个线性变换通常使用不同的权重矩阵,但可以共享偏置项(bias)。
在初始化时,查询(Q)、键(K)和值(V)的偏置项通常都被设置为0。这是因为在自注意力机制中,查询、键和值的初始化非常重要,它们决定了模型如何关注输入序列中的不同部分。如果在初始化时就给偏置项赋予较大的值,那么模型可能会过度关注某些特定的位置,从而影响模型的性能。
此外,需要注意的是,在实际的模型训练过程中,偏置项的值会随着梯度下降算法的迭代而逐渐调整,最终达到一个合适的值。所以,虽然初始化时将偏置项设置为0,但在训练过程中,偏置项的值可能会发生很大的变化。
你还知道哪些变种的Attention?它们针对Vanilla实现做了哪些优化和改进?
互联网上的信息提到了一些Attention的变种,包括Transformer、Big Bird、Synthesizer、Reformer、Local attention、Sinkhore attention、Linformer、Performer和Linear Transformer。这些变种针对Vanilla实现进行了以下优化和改进:
-
Transformer:传统的Attention机制,它通过自注意力机制来理解输入序列中的不同部分之间的关系。
-
Big Bird:综合了全局注意力(global attention)、局部注意力(local attention)和随机注意力(random attention),旨在处理更复杂的任务。
-
Synthesizer:新的想法,attention matrix不需要q,a产生,直接当network的参数,这样可以节省计算资源。
-
Reformer:使用clustering的方法,只关注重要区域的attention机制,从而提高运行速度。
-
Local attention:方法速度比较快,但性能不太好,主要是因为它只关注输入序列中的某些位置。
-
Sinkhore attention:直接用网络决定哪些位置用attention,哪些位置不用,进一步提高了效率。
-
Linformer、Performer和Linear Transformer:这些方法的速度较快,但性能稍微差一些,主要是因为它们对原始的Attention机制进行了简化。
总的来说,这些变种的Attention在保持或者提高性能的同时,都试图降低计算复杂度和内存消耗,以适应更大的模型和数据集。
Attention的缺点和不足
Attention机制的主要缺点是计算量大。这是因为在每次更新状态时,Decoder都需要查看Encoder的所有状态,以确保不会遗漏任何信息。此外,Attention还需要决定Decoder应该关注Encoder的哪些状态,这也增加了计算复杂度。
除了计算量大之外,Attention机制还存在一些其他的缺点和不足:
-
对于长序列的处理能力较差:由于Attention机制需要对输入序列的所有元素进行计算,因此当处理长序列时,计算量会急剧增加,可能会导致模型的训练和推理速度变慢。
-
难以解释:Attention机制的工作方式比较抽象,难以直接解释其内部的决策过程,这可能会影响模型的可解释性和透明度。
-
对数据的依赖性较高:Attention机制的性能依赖于输入数据的质量和特征表示,如果输入数据的质量较低或者特征表示不准确,可能会影响Attention机制的效果。
-
可能引发过拟合问题:由于Attention机制具有较强的模式识别能力,如果训练数据不够充足或者模型的复杂度过高,可能会导致过拟合问题,影响模型的泛化能力。
怎么理解Deep Learning的Deep?现在代码里只有一个Attention,多叠加几个效果会好吗?
在深度学习中,"Deep"通常指的是神经网络中的层数。与浅层神经网络相比,深层神经网络可以学习更复杂的数据表示和特征,从而提高模型的性能。
至于Attention机制,虽然叠加多个Attention层可以提高模型的复杂度,并允许模型学习更复杂的数据表示,但这并不一定总是好的。实际上,过多的Attention层可能会导致过拟合问题,从而影响模型的泛化能力。此外,增加Attention层的数量也会增加计算复杂度和内存消耗,可能会对训练和推理速度产生负面影响。
因此,在设计模型时,需要根据具体的任务和数据集来决定使用多少个Attention层。通常来说,应该先尝试使用较少的Attention层,然后逐渐增加层数,直到模型的性能达到最佳为止。
DeepLearning中Deep和Wide分别有什么作用,设计模型架构时应怎么考虑?
Deep Learning中的"Deep"和"Wide"是指两种不同的模型结构,它们各有特点并在设计模型时有各自的作用。
"Deep"部分通常指的是深度神经网络,其主要作用是提取数据的抽象特征,具有强大的表达能力和泛化能力。深度神经网络可以自动从原始数据中学习到有用的特征,而无需人工干预,这使得它非常适合处理复杂的问题,如图像识别、语音识别等。
"Wide"部分通常指的是浅层模型或者说逻辑回归模型,其主要作用是让模型具有较强的“记忆能力”(Memorization)。这类模型擅长于处理和记忆大量的历史行为特征,对于那些直接相关且易于解释的线性关系有很好的建模效果。
在设计模型架构时,应该考虑你的具体任务和数据情况。如果你的任务需要处理复杂数据或者需要高度抽象的特征表示,那么深度神经网络可能是一个好的选择。如果你的任务需要快速处理和记忆大量历史行为特征,那么逻辑回归模型可能更适合。
此外,Google提出的Wide & Deep模型就是将这两种模型结合起来,综合利用浅层模型的记忆能力和深层模型的泛化能力,实现单模型对推荐系统准确性和扩展性的兼顾。这种方法在实践中被证明是非常有效的,特别是在推荐系统等领域。
LLM
你怎么理解Tokenize?你知道几种Tokenize方式,它们有什么区别?
Tokenize是将文本或字符串分割成更小的部分(称为"令牌"或"标记")的过程。这个过程通常在自然语言处理中进行,例如在编写词法分析器(Lexer)或语法分析器(Parser)时。
关于Tokenize的方式,在实际应用中我们可以根据不同的需求和场景来定义Tokenize的方式。
-
基于空格和标点的Tokenize:这种方式是最常见的Tokenize方式,它将文本中的每个单词视为一个令牌,并使用空格和标点符号作为分隔符。
-
基于词的Tokenize:这种方式将文本中的每个单词视为一个令牌,但不会将标点符号视为分隔符。这种方式通常用于处理英文文本,因为英文单词之间通常由空格分隔。
-
基于字符的Tokenize:这种方式将文本中的每个字符视为一个令牌。这种方式通常用于处理亚洲语言,如汉语、日语等,因为这些语言的单词通常不使用空格分隔。
-
基于子词的Tokenize:这种方式将文本中的每个子词视为一个令牌。子词可以是完整的单词,也可以是单词的一部分。这种方式通常用于处理复杂的自然语言任务,如机器翻译和情感分析。
以上就是我对Tokenize的理解和几种常见的Tokenize方式,希望对你有所帮助。
一个理想的Tokenizer模型应该具备哪些特点
-
灵活性:Tokenizer应该能够处理各种不同类型的文本,包括英文、中文、日语等。它应该能够处理各种不同的标点符号和特殊字符,并且能够适应不同的输入格式,如文本文件、CSV文件、JSON对象等。
-
准确性:Tokenizer应该能够准确地分割文本,并正确地识别出每个令牌。这需要Tokenizer具有强大的词法分析能力,并且能够处理各种复杂的自然语言现象,如缩写、缩写词、人名、地名等。
-
高效性:Tokenizer应该能够在短时间内处理大量的文本数据。这需要Tokenizer具有高效的算法和数据结构,并且能够充分利用多核CPU和GPU等硬件资源。
-
可扩展性:Tokenizer应该能够方便地进行扩展和定制。例如,用户应该能够轻松地添加新的令牌、更改分隔符、调整令牌化规则等。
-
兼容性:Tokenizer应该与其他NLP工具和库兼容。例如,Tokenizer应该能够与词袋模型、TF-IDF、Word2Vec等模型兼容,并且能够与其他NLP库(如NLTK、spaCy、Stanford CoreNLP等)无缝集成。
-
可解释性:Tokenizer应该具有良好的可解释性,使得用户能够理解它的工作原理和输出结果。这有助于用户调试和优化Tokenizer,并且能够提高模型的透明度和可信度。
Tokenizer中有一些特殊Token,比如开始和结束标记,你觉得它们的作用是什么?我们为什么不能通过模型自动学习到开始和结束标记?
Tokenizer中的特殊标记,如开始和结束标记,主要用于帮助模型理解输入数据的结构。例如,在处理序列数据(如文本)时,开始标记(如)表示序列的开始,而结束标记(如)则表示序列的结束。
尽管模型理论上可以通过学习自动识别这些标记,但直接添加这些特殊标记有几个优点:
-
简化模型设计:添加开始和结束标记可以使模型的设计更为简单,因为模型不需要自行学习序列的开始和结束。
-
提高模型性能:对于某些任务,明确的开始和结束标记可以帮助模型更好地理解和处理输入数据,从而提高模型的性能。
-
增强模型解释性:添加开始和结束标记可以使模型的工作方式更为透明,有助于理解和解释模型的决策过程。
-
便于序列长度控制:在某些应用场景中,如机器翻译,我们需要控制生成的目标语言句子的长度。通过添加结束标记,模型可以知道何时停止生成新的单词。
-
保持一致性:在许多现有的NLP系统中,开始和结束标记已经被普遍使用,继续使用这些标记可以保持与这些系统的一致性。
综上所述,尽管模型理论上可以自动学习到开始和结束标记,但在实践中,添加这些特殊标记往往更为实用和有效。
为什么LLM都是Decoder-Only的?
LLM(Large Language Model)通常选择Decoder-Only架构主要是由于其在训练效率和工程实现上的优势。具体来说,这种架构可以有效地利用并行计算资源,从而加速模型的训练过程。此外,在处理长序列的任务时,Decoder-Only架构也表现出了更好的性能。
从理论上看,Decoder-Only架构可以被视为一个自回归模型,这意味着它可以逐步生成输出,每次生成新的输出都依赖于之前的输出。这种特性使得Decoder-Only架构非常适合文本生成等序列到序列的任务。
总的来说,虽然LLM也可以采用其他类型的架构,但由于Decoder-Only架构在训练效率、工程实现和理论优势上的表现,使得它在目前的LLM研究中占据了主流地位。
RMSNorm的作用是什么,和LayerNorm有什么不同?为什么不用LayerNorm?
RMSNorm和LayerNorm都是用于神经网络中的归一化技术,它们可以帮助模型更好地训练和泛化。
-
RMSNorm:RMSNorm(Root Mean Square Normalization)是一种基于均方根的归一化技术。它首先计算输入数据的均方值,然后取其平方根,最后将结果除以均方值。这种方法可以有效地防止梯度爆炸或梯度消失问题,从而提高模型的训练效率和性能。
-
LayerNorm:LayerNorm是一种基于层的归一化技术。它首先计算每个特征维度上的均值和标准差,然后使用这些统计量对输入数据进行标准化。这种方法可以保持特征之间的相关性,并且可以在不同的特征维度上进行独立的归一化,从而提高模型的性能。
虽然RMSNorm和LayerNorm都是有效的归一化技术,但在实际应用中,LayerNorm通常比RMSNorm更为常用。这主要是因为LayerNorm具有以下优点:
-
更好的性能:在许多任务中,LayerNorm都表现出了比RMSNorm更好的性能。
-
更稳定的训练:LayerNorm可以在不同的特征维度上进行独立的归一化,从而使得模型的训练过程更加稳定。
-
更好的解释性:LayerNorm的工作原理比较简单易懂,这使得模型的工作方式更加透明,有助于理解和解释模型的决策过程。
-
更广泛的应用:LayerNorm已经被广泛应用于各种深度学习任务中,包括自然语言处理、计算机视觉等。
综上所述,虽然RMSNorm在某些情况下也可以使用,但在大多数任务中,LayerNorm通常是更好的选择。
LLM中的残差连接体现在哪里?为什么用残差连接?
在LLM(Large Language Model)中,残差连接主要体现在模型的架构设计上。残差连接是一种在网络层之间添加直接连接的技术,这种技术可以使得网络更深、更宽,同时也能有效防止梯度消失和梯度爆炸问题。
残差连接的使用主要基于以下两个原因:
-
解决深度网络退化问题:在某些情况下,深度网络的性能可能不如浅层网络,这被称为“网络退化”。例如,当我们只需要低级特征时,浅层网络已经完全能够提取到低级特征,但深层网络又对这些低级特征作了处理,这就会导致网络预测出现失误。残差连接的存在就像给网络提供了一条捷径,让网络可以选择跳过某些层的处理,从而避免了“网络退化”现象。
-
解决梯度消失或爆炸问题:在深度神经网络中,梯度消失或爆炸问题是一个常见的挑战。这是因为反向传播算法在计算梯度时,每一层的梯度都会乘以该层的权重矩阵,随着网络深度的增加,梯度可能会变得非常小或者非常大,导致训练过程不稳定。残差连接的引入可以有效地缓解这个问题,因为它可以绕过部分网络层,使得梯度可以直接从输出层传递到输入层,从而保持梯度的稳定性。
总的来说,残差连接在LLM中的应用主要是为了提高模型的性能和训练效率,使其能够更好地学习数据的特征并做出准确的预测。
PreNormalization和PostNormalization会对模型有什么影响?为什么现在LLM都用PreNormalization?
PreNormalization和PostNormalization是两种在深度学习模型中应用的归一化方法。
-
PreNormalization:在这种方式中,归一化操作是在每一层之前进行的。例如,在Transformer模型中,Layer Normalization通常在自注意力机制和前馈网络之前执行。PreNormalization可以帮助模型更快地收敛,因为它消除了输入数据的不均匀性,使得梯度更稳定。然而,由于归一化操作在计算非线性变换之前执行,所以它可能会限制模型的表达能力。
-
PostNormalization:在这种方式中,归一化操作是在每一层之后进行的。例如,在ResNet模型中,Batch Normalization通常在卷积层和激活函数之后执行。PostNormalization可以提供更大的模型表达能力,因为它允许模型首先学习非线性变换,然后再对其结果进行归一化。然而,由于归一化操作在计算非线性变换之后执行,所以它可能会导致梯度不稳定。
至于为什么现在的大型语言模型(LLM)都使用PreNormalization,主要有以下几个原因:
-
首先,PreNormalization有助于解决梯度消失或爆炸的问题,因为它可以将输入数据的范围约束在一个较小的范围内。
-
其次,在大型语言模型中,每个词向量的初始值通常是随机的,并且具有不同的尺度。通过在每个时间步之前应用PreNormalization,可以确保模型能够稳定地训练。
-
最后,虽然PostNormalization可以提供更大的模型表达能力,但它在训练大型语言模型时可能会遇到梯度不稳定等问题。
总的来说,PreNormalization和PostNormalization各有优缺点,选择哪种方法取决于具体的任务和模型设计。
FFN为什么先扩大后缩小,它们的作用分别是什么?
在Transformer模型中,FFN(Feed Forward Network)是一个全连接的前馈神经网络,主要用于在各个时序上对特征进行非线性变换,提高网络的表达能力。
FFN先扩大再缩小的操作主要有以下两个目的:
-
升维:首先,将输入的特征向量通过一个线性层(全连接层)扩展到更高维度的空间。这个过程可以理解为将原始的特征进行各种类型的特征组合,从而提高模型的分辨能力。例如,假设原始的特征只有一个维度,那么模型可能无法充分捕捉数据的复杂性和多样性。通过升维,模型可以在更高维度的空间中捕捉更丰富的信息。
-
降维:然后,将扩展后的特征通过另一个线性层缩小回原来的维度。这个过程主要是为了保持模型的复杂度,避免过拟合。同时,降维也可以看作是一种信息压缩,把重要的、有效的特征保留,去掉冗余的、无关紧要的特征。
总的来说,FFN的扩维和缩维操作是为了提高模型的表达能力,同时保持模型的复杂度,避免过拟合。
为什么LLM需要位置编码?你了解几种位置编码方案?
LLM(大型语言模型)需要位置编码的主要原因是因为在自然语言中,词语的顺序或者说语序是非常重要的。例如,"我喜欢你"和"你喜欢我"这两句话的含义完全不同,但在传统的语言模型中,由于使用了注意力机制,每个词向量的计算并不受顺序影响,这就导致了模型无法区分语序带来的含义差异。
因此,引入位置编码可以让模型能够识别出每个词的位置信息,从而更好地理解句子的含义。比如,模型可以通过位置编码知道某个词在句子中的前后关系,进而理解该词在句子中的具体作用和含义。
至于位置编码的方案,主要有以下几种:
-
绝对位置编码:每个位置都会对应一个独一无二的位置编码,这种编码方式简单直接,但缺点是当句子长度变化时,位置编码的维度也会发生变化,不利于模型的训练。
-
相对位置编码:与绝对位置编码不同,相对位置编码只关心词与词之间的相对位置,而不是绝对位置。这种编码方式更加灵活,可以适应不同长度的句子,但计算复杂度较高。
-
学习到的位置编码:这种编码方式是将位置信息作为模型的一部分进行学习,模型可以根据输入数据自动学习到最佳的位置编码方式。这种方法的灵活性更高,但训练难度也较大。
-
固定基函数位置编码:这种编码方式将位置编码看作是一组基函数的线性组合,模型可以通过学习基函数的权重来获得最佳的位置编码。这种方法既保留了学习的灵活性,又降低了训练的复杂度。
为什么RoPE能从众多位置编码中脱颖而出?它主要做了哪些改进?
RoPE(Reading Order Equivariant Positional Encoding)能从众多位置编码中脱颖而出,主要是因为它解决了现有图形卷积网络(GCN)在建模文档空间布局模式时无法准确捕捉给定单词级节点表示的阅读顺序的问题。
RoPE作为一种新的位置编码技术,它的主要改进包括:
-
理解文档中单词的顺序表示:在处理类似表格的文档信息提取任务时,单词的自然阅读顺序至关重要。RoPE通过生成唯一的阅读顺序代码,为相对于目标单词的相邻单词提供了有效的位置编码。
-
提升文档实体提取性能:RoPE已经在两个基本的文档实体提取任务上进行了验证,包括公共FUNSD数据集和大规模支付数据集上的单词标记和单词分组。实验结果显示,RoPE可以持续改进现有GCN的性能,F1得分的差距高达8.4%。
总的来说,RoPE的创新之处在于其能够有效地理解和利用文档中单词的顺序信息,从而显著提升了文档信息提取的准确性和效率。
如果让你设计一种位置编码方案,你会考虑哪些因素?
-
序列长度: 考虑到不同任务中序列的长度可能会有所不同,因此设计的位置编码方案应该能够适应不同长度的序列。
-
局部性与全局性: 位置编码应该既能捕捉元素间的相对位置,也能注意到元素间的全局关系。例如,在处理文本序列时,模型需要理解词语的顺序和上下文关系。
-
学习性: 位置编码应该是可学习的,以便模型可以根据数据自动调整位置信息的表示方式。
-
计算效率: 考虑到模型在实际应用中可能需要处理大量的数据,因此设计的位置编码方案应该具有较高的计算效率,以减少训练和推理时间。
-
泛化能力: 位置编码应该具有良好的泛化能力,即使面对未见过的数据,也能够准确地捕捉元素间的位置关系。
-
灵活性: 设计的位置编码方案应该具有足够的灵活性,以便可以根据具体的任务和数据集进行调整和优化。
-
解释性: 尽管深度学习模型通常被认为是“黑箱”,但如果位置编码的工作原理和决策过程可以被清晰地解释,那么这将有助于提高模型的透明度和可信度。
-
鲁棒性: 位置编码应该具有良好的鲁棒性,即使输入数据存在噪声或者异常值,也能保持稳定的性能。
综上所述,设计一种位置编码方案需要考虑多个因素,包括序列长度、局部性与全局性、学习性、计算效率、泛化能力、灵活性、解释性和鲁棒性等。