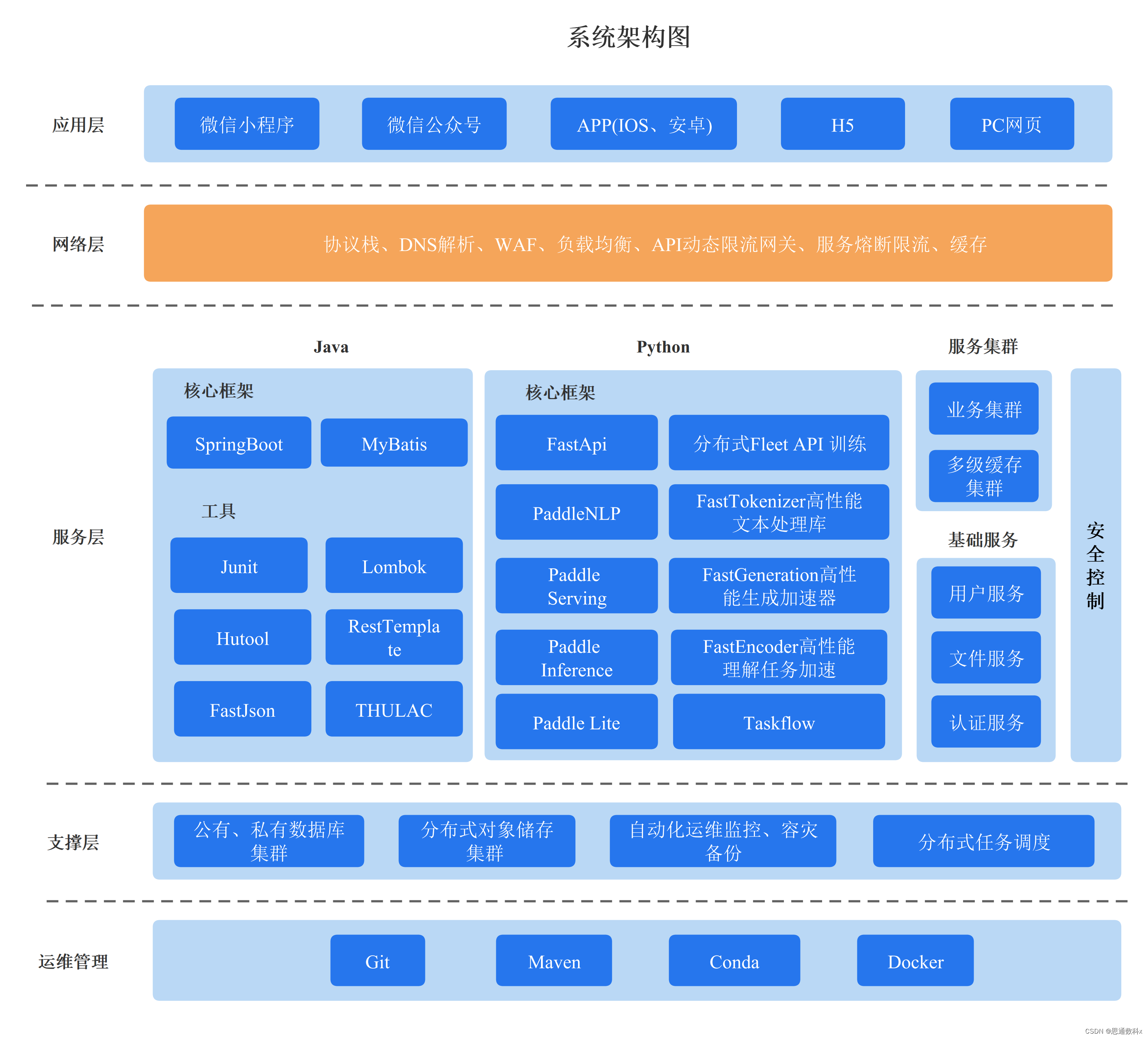
edge-tts是github上的一个开源项目,可以免费将文本转为语音,别看它只有2.8k star,替代科大讯飞的收费TTS服务完全没问题,因为这个项目实际是调用的微软edge的在线语音合成服务,支持40多种语言,300多种声音,效果毋容置疑。
下面开始实战。edge-tts项目地址:https://github.com/rany2/edge-tts
1.安装部署
在cmd中运行以下命令安装edge-tts
pip install edge-tts速度非常快,几秒钟就安装完成了。

2.文本转语音
输入以下命令,将一段英文转为音频。
edge-tts --text "Hello, welcome to subscribe my wechat official account: AI technology practice" --write-media hello.mp3--text 参数为要转换的文本。
--write-media 参数为转换后要保存的音频文件名。
如下图所示:

转换完成后,在运行命令的目录中(上面例子中的运行目录为c:/Users/liliang)会多出一个hello.mp3,这个mp3就是转换后的音频。
3.支持的语言和音色
edge-tts支持英语、汉语、日语、韩语、法语等40多种语言,共300多种可选声音,执行以下命令查询:
edge-tts --list-voices如下图所示:

查询结果中的Gender为声音的性别,Name为声音的名字,如zh-CN-YunjianNeural,其中zh表示语言,CN表示国家或地区,可以根据需求选择不同的声音。
使用--voice参数来指定声音名称,下面我使用zh-CN-YunyangNeural声音来合成一个中文音频。
edge-tts --voice zh-CN-YunyangNeural --text "大家好,欢迎关注我的微信公众号:AI技术实战,我会在这里分享各种AI技术、AI教程、AI开源项目。" --write-media hello_in_cn.mp3合成陕西方言的女声
edge-tts --voice zh-CN-shaanxi-XiaoniNeural --text "大家好,欢迎关注我的微信公众号:AI技术实战,我会在 这里分享各种AI技术、AI教程、AI开源项目。" --write-media hello_in_cn.mp3合成台湾口音
edge-tts --voice zh-TW-HsiaoYuNeural --text "大家好,欢迎关注我的微信公众号:AI技术实战,我会在这里分享各种AI技术、AI教程、AI开源项目。" --write-media hello_in_cn.mp3合成东北口音
edge-tts --voice zh-CN-liaoning-XiaobeiNeural --text "大家好,欢迎关注我的微信公众号:AI技术实战,我会在这里分享各种AI技术、AI教程、AI开源项目。" --write-media hello_in_cn.mp3合成粤语
edge-tts --voice zh-HK-WanLungNeural --text "大家好,欢迎关注我的微信公众号:AI技术实战,我会在这里分享各种AI技术、AI教程、AI开源项目。" --write-media hello_in_cn.mp34.修改语速、音量、频率
4.1 使用--rate参数修改语速
将速度减慢30%
edge-tts --rate=-30% --voice zh-CN-YunyangNeural --text "大家好,欢迎关注我的微信公众号:AI技术实战,我会在这里分享各种AI技术、AI教程、AI开源项目。" --write-media hello_in_cn.mp3将速度加快30%
edge-tts --rate=+30% --voice zh-CN-YunyangNeural --text "大家好,欢迎关注我的微信公众号:AI技术实战,我会在这里分享各种AI技术、AI教程、AI开源项目。" --write-media hello_in_cn.mp34.2 使用--volume参数修改音量
将音量降低70%
edge-tts --volume=-70% --voice zh-CN-YunyangNeural --text "大家好,欢迎关注我的微信公众号:AI技术实战,我会在这里分享各种AI技术、AI教程、AI开源项目。" --write-media hello_in_cn.mp3将音量调高70%
edge-tts --volume=+70% --voice zh-CN-YunyangNeural --text "大家好,欢迎关注我的微信公众号:AI技术实战,我会在这里分享各种AI技术、AI教程、AI开源项目。" --write-media hello_in_cn.mp34.3 使用--pitch参数修改频率
频率减少50hz
edge-tts --pitch=-50Hz --voice zh-CN-YunyangNeural --text "大家好,欢迎关注我的微信公众号:AI技术实战,我会在这里分享各种AI技术、AI教程、AI开源项目。" --write-media hello_in_cn.mp3频率增加50hz
edge-tts --pitch=+50Hz --voice zh-CN-YunyangNeural --text "大家好,欢迎关注我的微信公众号:AI技术实战,我会在这里分享各种AI技术、AI教程、AI开源项目。" --write-media hello_in_cn.mp35.使用代码转换
上面都是用命令转换,我们也可以写代码调用,开发http接口来提供语音合成服务。
以下是一个代码示例,将代码保存到一个文件中,如tts.py。
#!/usr/bin/env python3
"""
Basic example of edge_tts usage.
"""
import asyncio
import edge_tts
TEXT = "大家好,欢迎关注我的微信公众号:AI技术实战,我会在这里分享各种AI技术、AI教程、AI开源项目。"
VOICE = "zh-CN-YunyangNeural"
OUTPUT_FILE = "d:/test.mp3"
async def amain() -> None:
"""Main function"""
communicate = edge_tts.Communicate(TEXT, VOICE)
await communicate.save(OUTPUT_FILE)
if __name__ == "__main__":
loop = asyncio.get_event_loop_policy().get_event_loop()
try:
loop.run_until_complete(amain())
finally:
loop.close()运行python tts.py,稍等即可在d盘生成合成后的音频test.mp3。

6.实现原理
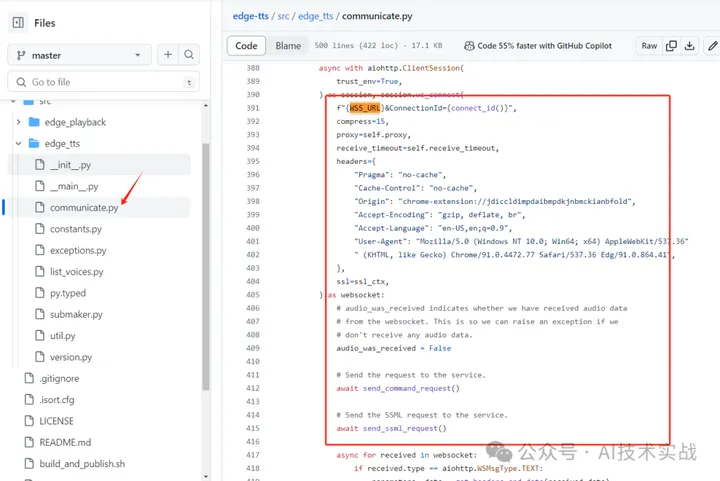
原理非常简单,就是调用了微软的在线语音合成服务,看一下源码中的constants.py和communicate.py便可猜出大概,语音合成是用的websocket服务,获取声音列表是用的https接口,但是作者不知道这个TrustedClientToken是怎样得到的,也没有搜到官方的api文档,猜测是抓包edge浏览器中的朗读所选内容得到的,应该算是免费薅羊毛。
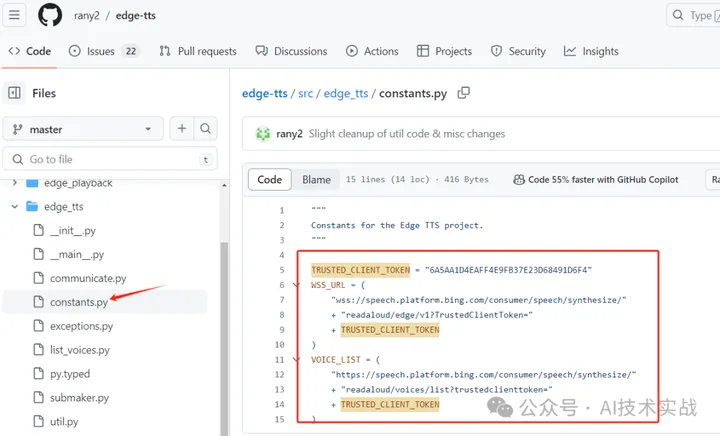
communicate.py,建立websocket连接,收发数据。
文章来源于AI技术实战 ,作者AI李良