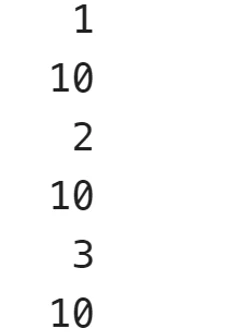文章目录
- 1 :peach:为什么需要智能指针?:peach:
- 2 :peach:内存泄漏:peach:
- 2.1 :apple:什么是内存泄漏:apple:
- 2.2 :apple:内存泄漏分类:apple:
- 2.3 :apple:如何检测内存泄漏:apple:
- 2.4:apple:如何避免内存泄漏:apple:
- 3 :peach:智能指针的使用及原理:peach:
- 3.1 :apple:RAII:apple:
- 3.2 :apple:auto_ptr 和 unique_ptr:apple:
- 3.3 :apple:shared_ptr 和 weak_ptr:apple:
- 3.4 :apple:定制删除器:apple:
- 3.5 :apple:C++11和boost中智能指针的关系:apple:
1 🍑为什么需要智能指针?🍑
首先我们来看下面这样的一种场景:
int Div(int x, int y)
{
if (y == 0)
throw("除0错误");
else
return x / y;
}
void Func(int x, int y)
{
int* p1 = new int;
int* p2 = new int;
Div(x, y);
delete p1;
delete p2;
}
int main()
{
int x, y;
cin >> x >> y;
try
{
Func(x,y);
}
catch (const char* errmsg)
{
cout << errmsg << endl;
}
catch (...)
{
cout << "未知异常" << endl;
}
return 0;
}
我们思考下面的问题:
1. 如果p1这里new 抛异常会如何?
2. 如果p2这里new 抛异常会如何?
3. 如果Div调用这里又会抛异常会如何?
通过分析我们不难得知,当new p1这里抛了异常后,程序是没啥问题的,因为对象都还没有被new出来的;当new p2这里抛了异常后,是存在内存泄漏的,p1的资源没有被释放;当Div抛了异常后,同理p1和p2的资源都没有被释放。我们可以在Func函数中自行捕获一下,但是这样做是不是有点麻烦呢?如果抛出的异常有更多又应该咋办?所以引出了解决这种场景的利器:智能指针。
2 🍑内存泄漏🍑
在讲解智能指针前我们先来了解下什么是内存泄漏?
2.1 🍎什么是内存泄漏🍎
内存泄漏:内存泄漏指因为疏忽或错误造成程序未能释放已经不再使用的内存。内存泄漏并不是指内存在物理上的消失,而是应用程序分配某段内存后,因为设计错误,失去了对该段内存的控制,因而造成了内存的浪费。
内存泄漏的危害:长期运行的程序出现内存泄漏,影响很大,如操作系统、后台服务等等,出现内存泄漏会导致响应越来越慢,最终卡死。
2.2 🍎内存泄漏分类🍎
C/C++程序中一般我们关心两种方面的内存泄漏:
- 堆内存泄漏(Heap leak):
堆内存指的是程序执行中依据须要分配通过malloc / calloc / realloc / new等从堆中分配的一块内存,用完后必须通过调用相应的 free/delete 删掉。假设程序的设计错误导致这部分内存没有被释放,那么以后这部分空间将无法再被使用,就会产生Heap Leak。
- 系统资源泄漏:
指程序使用系统分配的资源,比方套接字、文件描述符、管道等没有使用对应的函数释放掉,导致系统资源的浪费,严重可导致系统效能减少,系统执行不稳定。
2.3 🍎如何检测内存泄漏🍎
-
在linux下内存泄漏检测:👉【Linux下几种内存泄漏检测工具】👈
-
在windows下使用第三方工具:👉【VLD工具说明】👈
-
其他工具:👉【其他内存泄漏检测工具】👈
2.4🍎如何避免内存泄漏🍎
- 工程前期良好的设计规范,养成良好的编码规范,申请的内存空间记着匹配的去释放。ps:这个理想状态。但是如果碰上异常时,就算注意释放了,还是可能会出问题。需要下一条智能指针来管理才有保证。
- 采用
RAII思想或者智能指针来管理资源。 - 有些公司内部规范使用内部实现的私有内存管理库,这套库自带内存泄漏检测的功能选项。
- 出问题了使用内存泄漏工具检测。ps:不过很多工具都不够靠谱,或者收费昂贵。
内存泄漏非常常见,解决方案分为两种:
- 1️⃣事前预防型,如智能指针等。
- 2️⃣事后查错型,如内存泄漏检测工具。
3 🍑智能指针的使用及原理🍑
3.1 🍎RAII🍎
RAII(Resource Acquisition Is Initialization)是一种利用对象生命周期来控制程序资源(如内存、文件句柄、网络连接、互斥量等等)的简单技术。
在对象构造时获取资源,接着控制对资源的访问使之在对象的生命周期内始终保持有效,最后在对象析构的时候释放资源。借此,我们实际上把管理一份资源的责任托管给了一个对象。
使用库中智能指针要引入头文件memory。
这种用法其实我们在讲解mutex时就已经浅浅的谈了一下,我们利用对象的构造和析构来帮助我们资源的获取和释放。那我们就可以自己实现一份简易版本的智能指针了:
namespace grm
{
template <class T>
class smart_point
{
public:
smart_point(T* ptr)
:_ptr(ptr)
{}
~smart_point()
{
cout << "delete:" << _ptr << endl;
delete _ptr;
}
T& operator*()
{
return *_ptr;
}
T* operator->()
{
return _ptr;
}
T* get()
{
return _ptr;
}
private:
T* _ptr;
};
}
我们使用时只需要这样使用即可:
grm::smart_point<int> p1 = new int(10);
grm::smart_point<int> p2 = new int(20);
是不是方便了很多,为了方便看出是否析构了资源我们在析构时专门打印了一句话,所以当我们运行时:
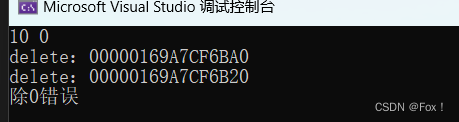
这样我们便实现了一份简易版本的智能指针了,但是智能指针的难点现在才开始。
3.2 🍎auto_ptr 和 unique_ptr🍎
大家思考我们上面写的代码中,有什么是还没有被考虑到的点?我们是不是还没有写拷贝构造和拷贝赋值?这两个可是一个重点和难点。当我们没有实现拷贝构造和拷贝赋值的时候编译器会默认给我们生成了一份,但是生成的是一份浅拷贝,我们析构时肯定会重复析构多次而导致程序崩溃。
那有什么解决办法吗?有人或许会想到:实现一份深拷贝的拷贝构造不就好了吗?
大家想想:实现深拷贝这种方式合适吗?
答案是坚决不行的,因为我们要的就是浅拷贝呀,我们拷贝构造的目的就是让两个智能指针对象管理同一块资源,那么既然要管理同一份资源,我们的指针肯定要是同一个才行。深拷贝了那还能管理同一份资源吗?所以这种解决思路是不行的。这里最好的解决方式是利用引用计数。
但是C++大佬最先在设计时并没有想到得这么全面,而是采用了另外一种方式,资源转移。这种方式被吐槽得很厉害,为什么呢?我们接下来看看:
auto_ptr(auto_ptr<T>& ap)
:_ptr(ap._ptr)
{
ap._ptr = nullptr;
}
auto_ptr<T>& operator=(const auto_ptr<T>& ap)
{
if (&ap != this)
{
delete _ptr;
_ptr = ap._ptr;
ap._ptr = nullptr;
}
return *this;
}
auto_ptr的实现拷贝构造和拷贝赋值代码如上,我们可以分析分析上面的代码问题在哪里?
拷贝构造时我们将资源转移走了,那我们还拷贝个啥,不如不拷贝。最要命的是假如使用者不熟悉底层原理,用了之前的悬空指针,不就成了空指针访问了吗。
所以上面的设计是不太合理的,有很多公司都会明令禁止使用auto_ptr。
设计C++的大佬们发现了这样的问题后,又设计了一个unique_ptr,直接禁止了使用拷贝构造和拷贝赋值。
关于禁止使用拷贝构造和拷贝赋值在C98的时候我们可以采取:
将拷贝构造和拷贝赋值设置为私有,并且只声明,不实现。
在C++11我们可以直接使用delete关键字。建议大家使用C++11的方式因为比较方便。
3.3 🍎shared_ptr 和 weak_ptr🍎
为了解决上面的问题,大佬们又想到了一种方式:使用引用计数来解决问题。我们可以使用一个计数器来帮助我们计数,当计数减到了0,我们才会去释放空间,那现在问题来了:我们应该选择怎样的数据进行计数呢?
直接使用一个整形变量肯定不行,因为指向同一份资源的计数器应该相等。那我们可以用静态成员变量吗?大家好好想想,这种方式究竟可取不可取?
答案是不可取的,为啥捏?因为静态成员变量是所有同类成员共享同一份,但是我们这里的计数是所有成员都应该共享的吗?显然不是,只有指向同一份资源的对象才会共享同一份计数器。那么我们应该使用什么类型的数据呢?
我们可以采用指针的方式,每个对象里面都存放着一个指针,让指向同一份资源的对象的指针相同不就好了吗?有了上面的思路我们就可以来手撸一个shared_ptr了:
namespace grm
{
template <class T>
class shared_ptr
{
public:
shared_ptr(T* ptr)
:_ptr(ptr)
,_pcnt(new int(1))
{}
~shared_ptr()
{
if (--(*_pcnt) == 0)
{
cout << "delete:" << _ptr << endl;
delete _ptr;
delete _pcnt;
}
}
shared_ptr(shared_ptr<T>& sp)
:_ptr(sp._ptr)
,_pcnt(sp._pcnt)
{
++(*_pcnt);
}
shared_ptr<T>& operator=(const shared_ptr<T>& sp)
{
//if (&ap != this)
if(_pcnt!= sp._pcnt)//建议下面这种方式
{
if (--(*_pcnt) == 0 && _ptr)
{
delete _ptr;
delete _pcnt;//别忘了计数器也要销毁
}
_ptr = sp._ptr;
_pcnt = sp._pcnt;
++(*_pcnt);
}
return *this;
}
T& operator*()
{
return *_ptr;
}
T* operator->()
{
return _ptr;
}
T* get()
{
return _ptr;
}
private:
T* _ptr;
int* _pcnt;
};
}
这样我们就完成了使用引用计数的方式维护计数器,但是大家再思考一下,上面代码中可能还会出现什么问题?
在多线程并发访问的情况上面代码有问题吗?答案肯定是有的,因为我们计数器的++与- -操作有可能多个线程共同在执行,那么就一定会出现安全问题,比如下面这种场景:
struct Date
{
int _year = 0;
int _month = 0;
int _day = 0;
};
void SharePtrFunc(grm::shared_ptr<Date>& sp, size_t n, mutex& mtx)
{
cout << sp.get() << endl;
for (size_t i = 0; i < n; ++i)
{
grm::shared_ptr<Date> copy(sp);
{
unique_lock<mutex> lk(mtx);
copy->_year++;
copy->_month++;
copy->_day++;
}
}
}
int main()
{
grm::shared_ptr<Date> p(new Date);
cout << p.get() << endl;
const size_t n = 100;
mutex mtx;
thread t1(SharePtrFunc, std::ref(p), n, std::ref(mtx));
thread t2(SharePtrFunc, std::ref(p), n, std::ref(mtx));
t1.join();
t2.join();
cout << p->_year << endl;
cout << p->_month << endl;
cout << p->_day << endl;
cout << p.use_cnt() << endl;
return 0;
}
当我们测试时:
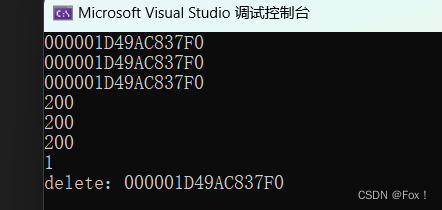
咦,我们发现程序居然没事儿,但是这个只是一个偶然性,当我们将数据范围扩大时:
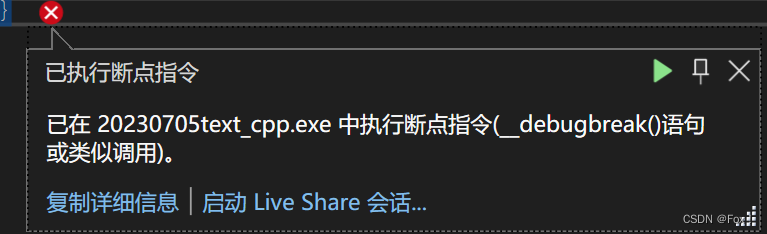 我们发现程序直接挂掉了,这其实也符合我们的预期,因为我们在将计数器++和- -操作时并没有加锁,所以有可能崩溃。
我们发现程序直接挂掉了,这其实也符合我们的预期,因为我们在将计数器++和- -操作时并没有加锁,所以有可能崩溃。
所以我们可以通过加锁策略来处理。
为了方便加锁与解锁,我们可以将++和- -操作独立放在一个函数中,如下:
void add_cnt()
{
_mtu->lock();
++(*_pcnt);
_mtu->unlock();
}
void release()
{
_mtu->lock();
bool del = false;
if (--(*_pcnt) == 0)
{
cout << "delete:" << _ptr << endl;
delete _ptr;
delete _pcnt;
del = true;
}
_mtu->unlock();
if (del)
delete _mtu;
}
整个修改的代码就如下所示:
template <class T>
class shared_ptr
{
public:
shared_ptr(T* ptr)
:_ptr(ptr)
,_pcnt(new int(1))
,_mtu(new mutex)
{}
void add_cnt()
{
_mtu->lock();
++(*_pcnt);
_mtu->unlock();
}
void release()
{
_mtu->lock();
bool del = false;
if (--(*_pcnt) == 0)
{
cout << "delete:" << _ptr << endl;
delete _ptr;
delete _pcnt;
del = true;
}
_mtu->unlock();
if (del)
delete _mtu;
}
~shared_ptr()
{
release();
}
shared_ptr(shared_ptr<T>& sp)
:_ptr(sp._ptr)
,_pcnt(sp._pcnt)
,_mtu(sp._mtu)
{
add_cnt();
}
shared_ptr<T>& operator=(const shared_ptr<T>& sp)
{
//if (&ap != this)
if(_pcnt!= sp._pcnt)//建议下面这种方式
{
//if (--(*_pcnt) == 0 && _ptr)
//{
// delete _ptr;
// delete _pcnt;//别忘了计数器也要销毁
//}
release();
_ptr = sp._ptr;
_pcnt = sp._pcnt;
_mtu = sp._mtu;
add_cnt();
}
return *this;
}
T& operator*()
{
return *_ptr;
}
T* operator->()
{
return _ptr;
}
T* get()
{
return _ptr;
}
int use_cnt()
{
return (*_pcnt);
}
private:
T* _ptr;
int* _pcnt;
mutex* _mtu;
};
这时我们再来运行时:
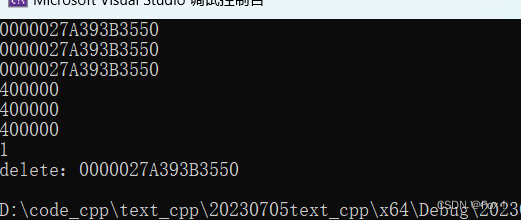
此时便能够得到正确的结果了。
到目前为止,shared_ptr大部分场景我们都能够很好的利用了,但是假如出现下面场景时:
struct ListNode
{
int _data;
grm::shared_ptr<ListNode> _prev;
grm::shared_ptr<ListNode> _next;
~ListNode() { cout << "~ListNode()" << endl; }
};
int main()
{
grm::shared_ptr<ListNode> node1(new ListNode);
grm::shared_ptr<ListNode> node2(new ListNode);
cout << node1.use_cnt() << endl;
cout << node2.use_cnt() << endl;
node1->_next = node2;
node2->_prev = node1;
cout << node1.use_cnt() << endl;
cout << node2.use_cnt() << endl;
return 0;
}
当我们编译时会爆出下面的错误信息:
 这时由于我们在实现shared_ptr的构造函数时没有给出默认构造,所以会编译错误,我们加上就好了:
这时由于我们在实现shared_ptr的构造函数时没有给出默认构造,所以会编译错误,我们加上就好了:
shared_ptr(T* ptr=nullptr)
:_ptr(ptr)
,_pcnt(new int(1))
,_mtu(new mutex)
{}
然后我们运行:

咦,为啥这里没有调用析构函数呀?(我们自己写的析构是加上了打印语句的),可是当我们屏蔽了一行代码后,就成功的打印出来了:
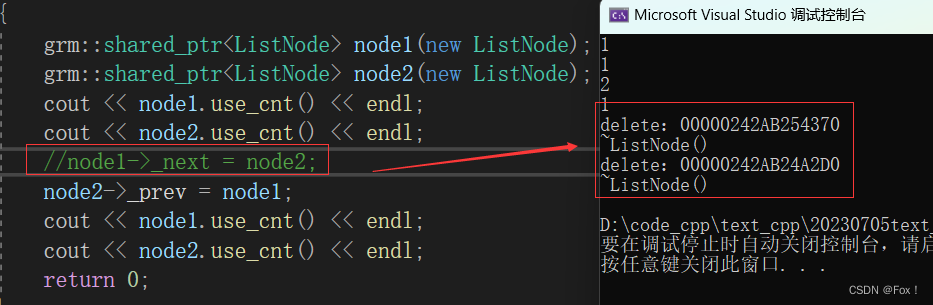 这是为啥捏?
这是为啥捏?
这里其实就是shared_ptr中的一个比较经典的问题:循环引用。
我们先来分析分析在这种情况下究竟是怎么一回儿事:我们先分析最先那种情况,为啥使用了下面的语句后会造成node1和node2没有被释放呢?
node1->_next = node2;
node2->_prev = node1;
当创建了两个智能指针对象时node1和node2的引用计数都变成了1,然后执行上面两句代码,使得node1和node2的引用计数都变成了2,当出了作用域时先析构node2(此时并不会真正析构node2,只会- -引用计数),node2的引用计数都变成了1;再析构node1(此时并不会真正析构node1,只会- -引用计数),node1的引用计数都变成了1。但是现在问题来了,要先析构node2对象,就要先析构node1,因为node1对象中的_next和node2共同管理同一块资源,只有node1对象析构了,成员变量_next才析构;但是node1对象和node2的_prev共同管理同一块资源,只有node2对象析构了,成员变量_prev才有析构;但是node2的析构又依赖着node1对象的析构,而导致形成这种闭环方式,谁都不会析构,那自然就造成内存泄漏了。
这里的关系有一点绕,建议大家可以画画图多理解一下。
那为什么我们刚才屏蔽了一段代码后就不会了呢,因为此时并没有造成闭环,我们来分析分析:我们只让 node2->_prev = node1;所以此时node1的引用计数为2,node2的引用计数为1,当出了作用域后,先析构node2,由于node2的引用计数为1,所以可以直接析构,当node2析构了后,也会析构他的成员变量_prev,由于node2的_prev与node1共同管理同一块资源,所以此时node1的引用计数–变为了1;然在出了作用域在析构node1,由于引用计数为1,所以就能够直接析构了,此时node1和node2都会正常析构,自然不会造成循环引用的问题了。同理只使用 node1->_next = node2;也是同理。
那我们究竟应该如何处理这种场景呀?其实我们想想:只要让拷贝赋值时引用计数不再++就行了。而这就是weak_ptr的基本原理。
所以我们可以实现一份简易的weak_ptr出来了:
template <class T>
class weak_ptr
{
public:
weak_ptr()
:_ptr(nullptr)
{}
weak_ptr(const shared_ptr<T>& sp)
:_ptr(sp.get())
{}
weak_ptr<T>& operator=(const shared_ptr<T>& sp)
{
_ptr = sp.get();
return *this;
}
T& operator*()
{
return *_ptr;
}
T* operator->()
{
return _ptr;
}
T* get()
{
return _ptr;
}
private:
T* _ptr;
};
这里面值得注意的细节有:
- weak_ptr是一种特殊的智能指针,不支持RAII,可以像指针一样指向资源,但是不参与资源的管理。
- 上述的weak_ptr是实现出的一份简易版本,实际上库中的实现比这个复杂得多(因为库中考虑得因素非常多),shared_ptr库里面得实现也比我们之前实现的复杂得多。
所以上面我们就可以使用shared_ptr+weak_ptr来解决循环引用问题:
struct ListNode
{
int _data;
grm::weak_ptr<ListNode> _prev;
grm::weak_ptr<ListNode> _next;
~ListNode() { cout << "~ListNode()" << endl; }
};
大家有兴趣可以直接看看官网上的所有智能指针👉【智能指针】👈
3.4 🍎定制删除器🍎
通过上面的讲解我们还发现了一个问题:如果不是new出来的对象如何通过智能指针管理呢?比如是malloc出来的,或者是以文件方式打开的,又或者是通过new[] 创建对象。其实shared_ptr设计了一个删除器来解决这个问题,我们可以先看看官网:
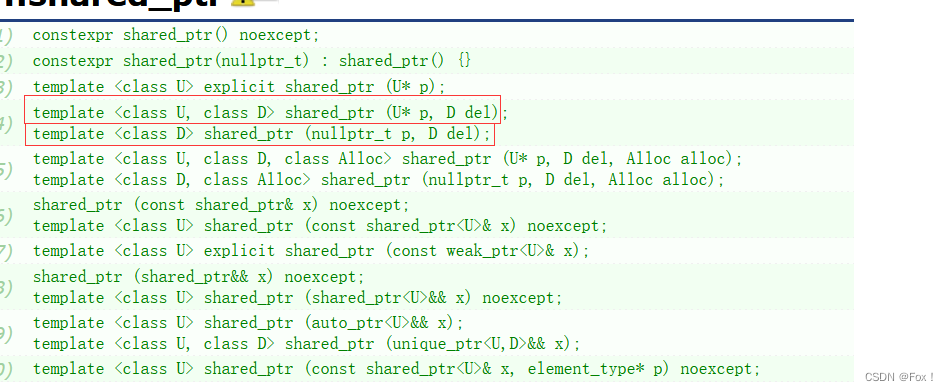 我们主要看看上面圈了的两种方式:一种是直接将删除器放在了模板参数中,另外一种是将删除器对象作为参数传给构造函数,我们下来看看这种不使用删除器的情况:
我们主要看看上面圈了的两种方式:一种是直接将删除器放在了模板参数中,另外一种是将删除器对象作为参数传给构造函数,我们下来看看这种不使用删除器的情况:
std::shared_ptr<Date> ps1(new Date[10]);
此时程序会直接挂掉:
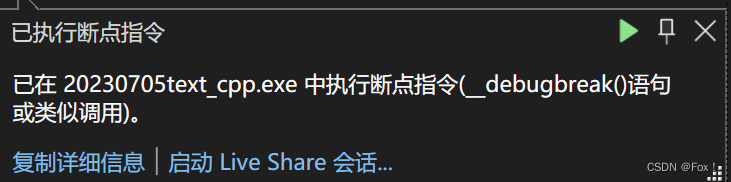 这是由于VS使用new[]创建对象时会在头四个字节用一个整形记录大小,所以如果我们使用delete时会直接报错,要使用delete[]才行,所以在这里我们可以给一个仿函数对象或者lambda,这里我给了一个lambda:
这是由于VS使用new[]创建对象时会在头四个字节用一个整形记录大小,所以如果我们使用delete时会直接报错,要使用delete[]才行,所以在这里我们可以给一个仿函数对象或者lambda,这里我给了一个lambda:
std::shared_ptr<Date> ps1(new Date[10], [](Date* ptr) {
cout << "lambda:delete" << endl;
delete [] ptr;
});
那假如我们想要将参数器对象传给构造函数,我们应该怎样修改我们自己实现的shared_ptr呢?
我们可以用包装器来接受lambda/仿函数对象:
template <class T>
class shared_ptr
{
public:
shared_ptr(T* ptr=nullptr)
:_ptr(ptr)
,_pcnt(new int(1))
,_mtu(new mutex)
{}
template<class D>
shared_ptr(T* ptr ,D del)
: _ptr(ptr)
, _pcnt(new int(1))
, _mtu(new mutex)
,_del(del)
{}
void add_cnt()
{
_mtu->lock();
++(*_pcnt);
_mtu->unlock();
}
void release()
{
_mtu->lock();
bool del = false;
if (--(*_pcnt) == 0)
{
if(_ptr)
cout << "delete:" << _ptr << endl;
//delete _ptr;
_del(_ptr);
delete _pcnt;
del = true;
}
_mtu->unlock();
if (del)
delete _mtu;
}
~shared_ptr()
{
release();
}
shared_ptr(shared_ptr<T>& sp)
:_ptr(sp._ptr)
,_pcnt(sp._pcnt)
,_mtu(sp._mtu)
{
add_cnt();
}
shared_ptr<T>& operator=(const shared_ptr<T>& sp)
{
//if (&ap != this)
if(_pcnt!= sp._pcnt)//建议下面这种方式
{
//if (--(*_pcnt) == 0 && _ptr)
//{
// delete _ptr;
// delete _pcnt;//别忘了计数器也要销毁
//}
release();
_ptr = sp._ptr;
_pcnt = sp._pcnt;
_mtu = sp._mtu;
add_cnt();
}
return *this;
}
T& operator*()
{
return *_ptr;
}
T* operator->()
{
return _ptr;
}
T* get()const
{
return _ptr;
}
int use_cnt()const
{
return (*_pcnt);
}
private:
T* _ptr;
int* _pcnt;
mutex* _mtu;
function<void(T*)> _del = [](T* ptr) {
cout << "lambda:delete" << endl;//这句话可加可不加,这里加上是为了看着方便
delete ptr;
};
};
当我们使用自己实现的:
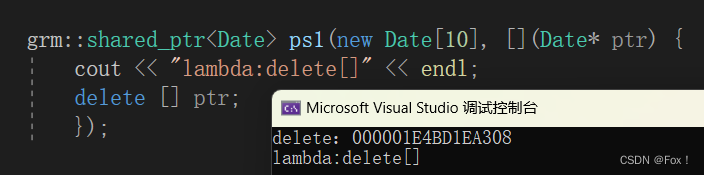
这里可以看见没啥问题。
3.5 🍎C++11和boost中智能指针的关系🍎
- 1️⃣ C++ 98 中产生了第一个智能指针auto_ptr.
- 2️⃣ C++ boost给出了更实用的scoped_ptr和shared_ptr和weak_ptr.
- 3️⃣ C++ TR1,引入了shared_ptr等。不过注意的是TR1并不是标准版。
- 4️⃣ C++ 11,引入了unique_ptr和shared_ptr和weak_ptr。需要注意的是unique_ptr对应boost的scoped_ptr。并且这些智能指针的实现原理是参考boost中的实现的。