理论:

目前问题在于识别图片所需要的模型权重数量会比较大
一般图片像素在12M也就是一千两百万像素,要用模型对其整体识别的话,需要至少一千两百万权重,那也仅仅是线性模型,若用多层感知机的话,模型的数据权重量又会以倍数增加,这就需要庞大的算力,和巨大的模型,模型大小会破1GB +
需求:用更小的模型去识别图片
解决方法:卷积 (CNN)
卷积的识别原理

在识别上述图片的时候卷积不会将整个图片带入模型中一次性识别,而是会选取其中的某一块区域进行识别,也就是说与其看整体,卷积选择了看图片的轮廓

这样模型的大小,只要和一个轮廓的大小一致一样即可,也就是说模型的大小不会因为图片的大小改变而改变
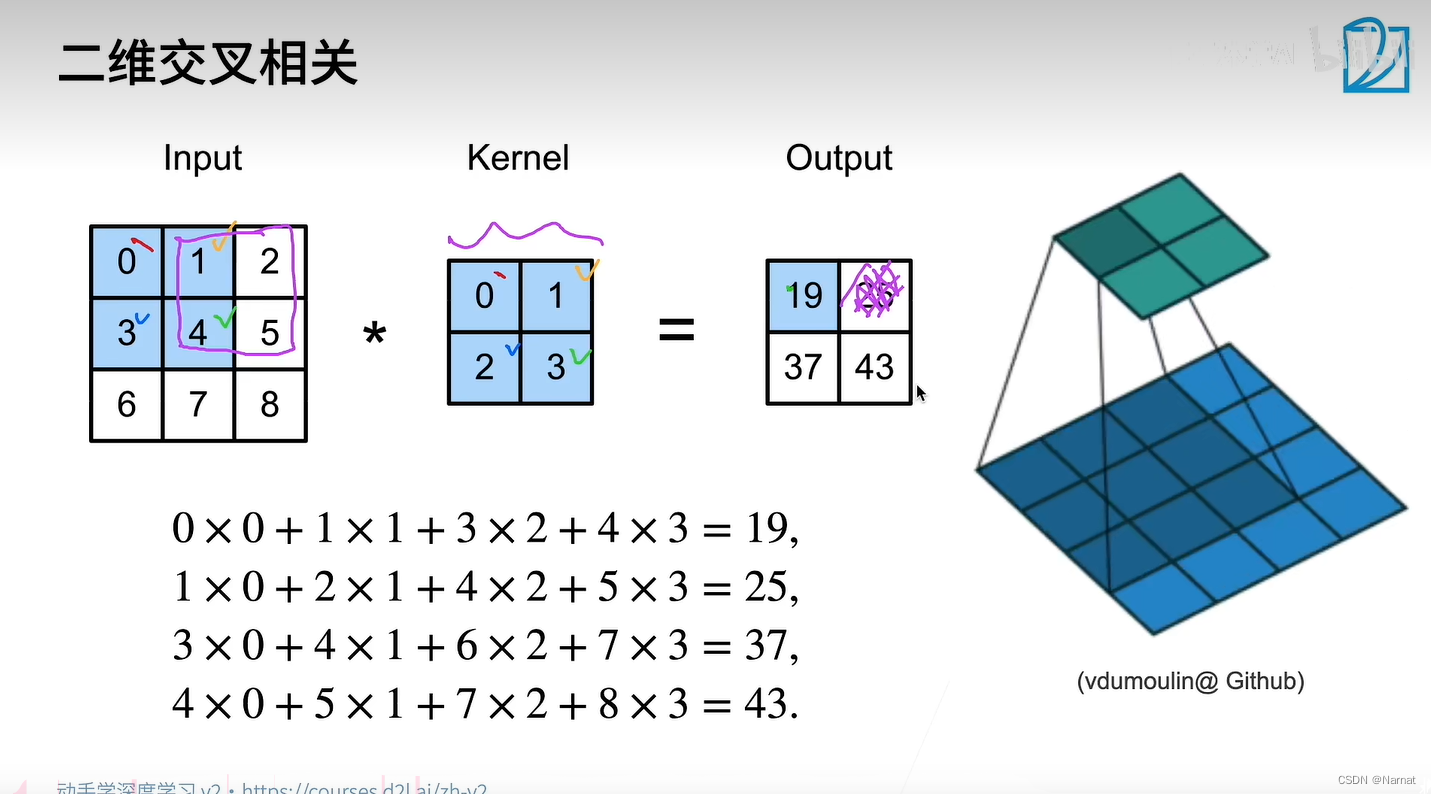
每次扫描扫描特定卷积核区域
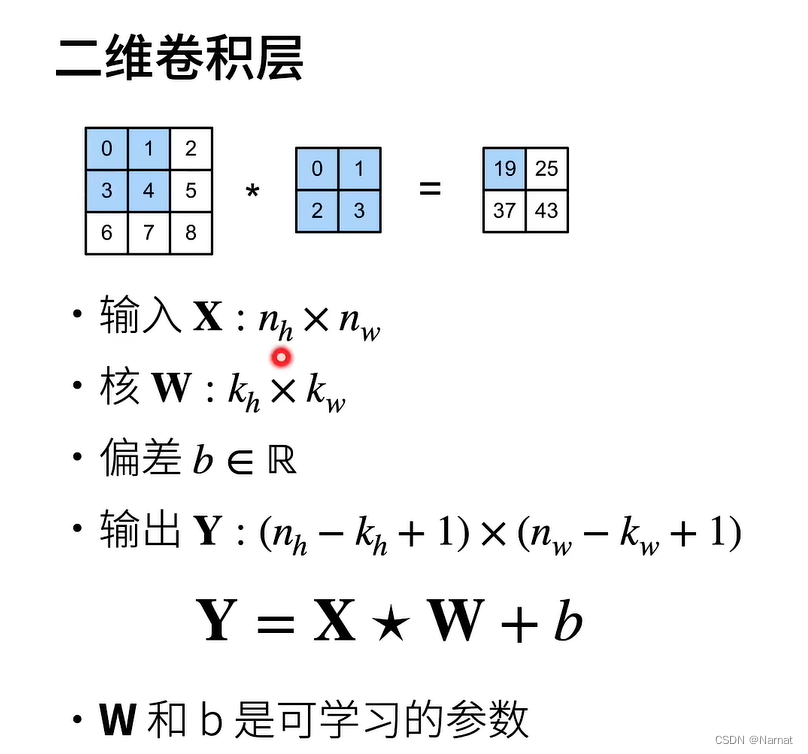
模型输出和卷积核大小,卷积图片大小有关
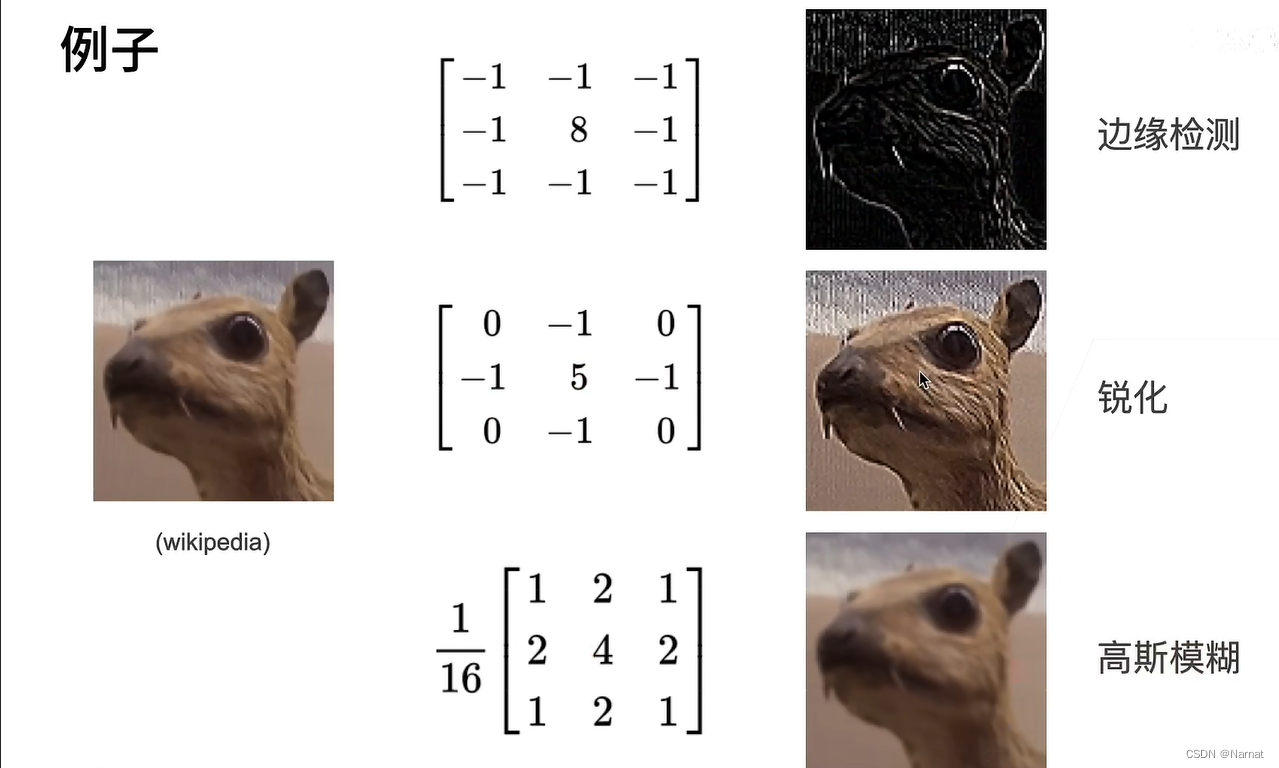
卷积通过卷积核识别,识别出整个图片的核心轮廓
实例代码:
import torch
from torch import nn
def corr2d(X, K): #@save
"""计算二维互相关运算"""
h, w = K.shape
Y = torch.zeros((X.shape[0] - h + 1, X.shape[1] - w + 1))
for i in range(Y.shape[0]):
for j in range(Y.shape[1]):
Y[i, j] = (X[i:i + h, j:j + w] * K).sum() # 卷积核,分别扫描图片
return Y
class Conv2D(nn.Module):
def __init__(self, kernel_size):
super().__init__()
self.weight = nn.Parameter(nn.rand(kernel_size))
self.bias = nn.Parameter(nn.zeros(1))
def forward(self, x):
return corr2d(x, self.weight) + self.bias
# 构造一个二维卷积层,它具有1个输出通道和形状为(1,2)的卷积核
conv2d = nn.Conv2d(1,1, kernel_size=(1, 2), bias=False) # 待训练模型
# 这个二维卷积层使用四维输入和输出格式(批量大小、通道、高度、宽度),
# 其中批量大小和通道数都为1
X = torch.ones((6, 8))
K = torch.tensor([[1.0, -1.0]]) # 真正得K
X[:, 2:6] = 0
Y = corr2d(X, K)
"模型是4维,所以维度要变化"
X = X.reshape((1, 1, 6, 8)) # 输入
Y = Y.reshape((1, 1, 6, 7)) # 由真正K得到数据集
lr = 3e-2 # 学习率
for i in range(10): # 训练10次
Y_hat = conv2d(X)
l = (Y_hat - Y) ** 2 # 方差损失函数
conv2d.zero_grad() # 清除之前梯度
l.sum().backward() # 算出新梯度
# 迭代卷积核
conv2d.weight.data[:] -= lr * conv2d.weight.grad # 手动更新权重
if (i + 1) % 2 == 0:
print(f'epoch {i+1}, loss {l.sum():.3f}')
print("真正模型:")
print(K)
print("训练的模型:")
print(conv2d.weight)
效果:
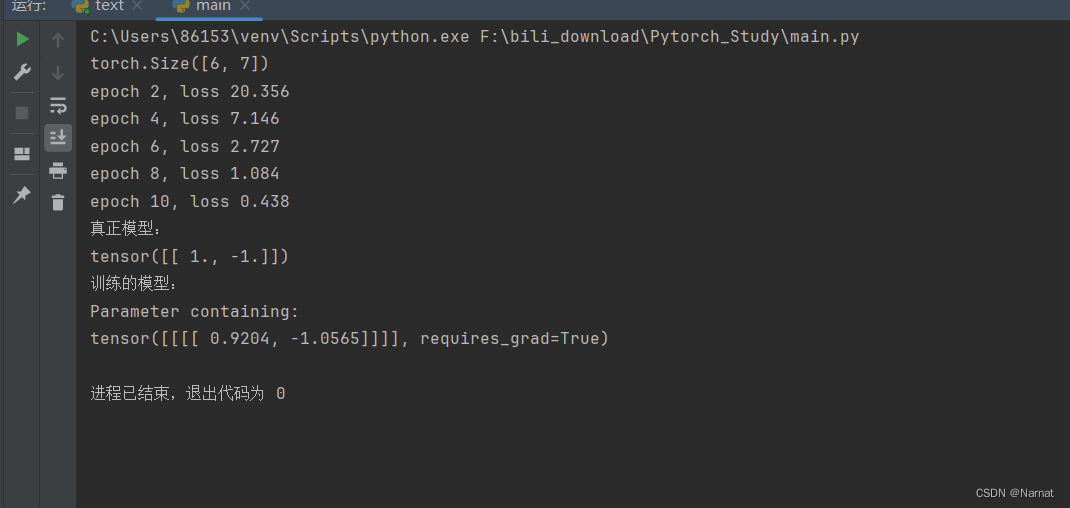
模型仅有两个权重,且训练效果很好