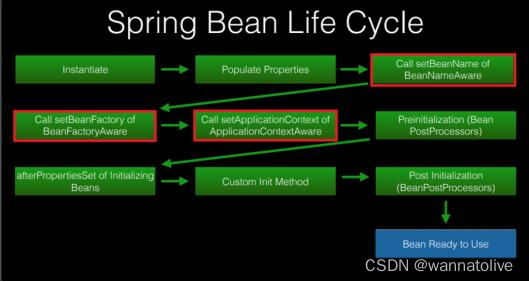
youtube课程地址:(实时更新)
https://www.youtube.com/playlist?list=PLJV_el3uVTsMhtt7_Y6sgTHGHp1Vb2P2Jwww.youtube.com/playlist?list=PLJV_el3uVTsMhtt7_Y6sgTHGHp1Vb2P2J
B站课程地址:
李宏毅2021机器学习【week3】:卷积神经网络_哔哩哔哩 (゜-゜)つロ 干杯~-bilibiliwww.bilibili.com/video/BV16p4y1h7FB

目录:
第一节 机器学习&深度学习介绍
第二节 机器学习攻略
一、机器学习的框架
二、模型训练攻略
三、针对Optimization Issue的优化,类神经网络训练不起来怎么办
(一) 局部最优点和鞍点
(二) 批处理和momentum
(三) 自动调节学习率Learning rate
(四) 损失函数带来的影响
第三节 CNN & Self-Attention
一、卷积神经网络
二、自注意力模型
待更新.......
本章主要介绍CNN & Self-Attention的内容
一、卷积神经网络(Convolution Neural Network,CNN)
如果现在有一个图像分类的任务,我们用全连接对图片做特征提取时,我们来计算一下,一层全连接所需要的模型参数量,假如输入一张 100×100×3 的3D-tensor的照片,则首先我们需要将它展开成 100×100×3 的1D-tensor,并用一个nn.Linear( 100×100×3 , 100×100×3 )线性层做特征提取,这个时候该层模型的模型参数量就是 3×108 多个,显然一层的神经网络就有很多参数量了,如果再多加几层的话,参数量就成倍的增加了,显然这不适合模型训练和存储。
(1) CNN的由来
观察 1
问题:模型参数量太多
那对于类似于图像辨识这样的问题,我们不需要隐层的每个neural都需要对input的每个dimension都有weight,往往我们只需要neural识别出图像中某些重要的特征即可。举例来说,我们希望隐层的某些neural具有识别鸟嘴的能力,某些neural具有识别鸟眼的能力,某些neural具有识别鸟脚的能力等等...只要能识别出这些具有明显辨识度的内容,基本就能判断出这张图中有鸟类,这个想法和人类识别鸟类是一个道理。那也就是说,我们并不需要每个neural都要看到整张图的特征,只要看到想看的部分就可以了,或者说这些neural并不需要把整张图片当做输入,只需要输入一小部分图片内容并获得其中的特征即可。

解决方案:
简化 1
我们会想到第一个可能的简化版本,就是隐层的每个neural只看一小部分区域,比如 3×3×3 这个小区域,而这个看的部分就是感受野(Receptive field)(下图中带激活函数的那个部分就是一个neural,其前面是Receptive field的展开),至于你要设计多少个隐层的neural去看,这就决定于你的网络设计,每个neural的感受野(注意这里指的是感受野,不是conv kernel)可以完全不一样,也可以部分重叠,也可以完全不一样,这样每个neural从之前的全连接可以缩短到只有 3×3×3 这么大小的区域了。

再简化一些,我们可以针对每个neural设计不同大小的Receptive field,或者不同channel number的Receptive field,甚至Receptive field可以不是square形状的等等,因此,理论上我们可以自定义我们想要的Receptive field。因此,有了进一步的简化:
经典的 Receptive field
虽然我们可以自定义,但是这边还是要介绍下最经典的Receptive field:
会看全部的channel
kernel size=3×3,并且每个kernel的参数不一样,也就是每个nural的侦测的东西不同
通常一个Receptive field(注意不是kernel size),可以被很多neural照顾到,比如64层隐层,那每一层都会有自己的kernel 去照顾到这个Receptive field
Receptive field之间的间隔可以由自己设定,也就是Stride,并且通常Receptive field之间是有重叠的,
这些Receptive fields需要覆盖掉完整张图
观察 2
问题:同一个特征可能出现在不同图像的不同区域
就拿下面这两张图形举例,鸟嘴部分出现在的整张图中的不同位置,那图中“蓝色”Receptive field和”红色“Receptive field其实是做的同一件事情,都是在侦测鸟嘴,只是侦测的位置不同,那既然它们做的事情是一样的,狩猎的范围不一样,那我们真的需要每个狩猎范围都去放一个侦探鸟嘴的neural吗,它们做的事情是重复的,只是狩猎的位置不一样而已。(意思是原本在卷积神经网络中一个feature map是侦测鸟嘴的,我们知道是卷积核共享的,但是这里的意思是参数不共享,每个feature map中的neural的参数是不一样的,但都是侦测鸟嘴的)

解决方案:
简化 2
每个感受野都有一组神经元(纵向),每个感受野都有具有相同参数共享的神经元(横向)。
总结:卷积神经网络的优势
通常情况下Convolutional Layer会有比较大的model bias,Fully Connceted Layer通常会导致过拟合。

两个方面对CNN的解释
第一种:从Neural Version Story角度来讲,可以认为每个neural都只考虑一个receptive field,并且具有不同receptive field的neural之间共享参数。
第二种:从Filter Version Story角度来讲,CNN具有多组检测不同特征的filters,并且每个filter都遍历了整张image。

观察3
问题:下采样图像并不会改变图像中的物体
Pooling操作能减少模型参数量,但是毕竟对图像有缩放,因此会丢失部分信息,通常情况下,Convolution layer + Pooling Layer会一起用(注意:不是全部都这样的,在Alpha Go设计的网络架构中不设有Pooling,理由是对于棋盘这样的图像,少一行,多一行会直接对判断产生影响),在最后往往会有一个flatten的操作,并街上FC层+Softmax做分类,图2是完整的一张CNN流程图。


补充:CNN不能处理图像缩放和旋转的问题,因此,我们通常会对图像做Augmentation。
二、自注意力机制(Self-Attention)
直接上图,Self-Attention顾名思义,输入文本的每个word都会考虑文本全局的信息。

attention的运作方式如下,输入可以是一个embedding的input,或者是hidden layer,比如下面的每个 bi 的输出都考虑了每个输入 ai 的信息,同时对于每个 ai 需要考虑它们各自的重要程度,因此会有一个权重 α ,对于 α 的计算方式有很多,比如下面图中,红色框框内的计算方式就是transformer中self-attention的计算方式,右边黑色框框内的 α 是通过两个vector的和,再一层激活函数和一层线性层得到。在接下来讨论的self-attention中,我们都考虑左边红色框内的那种。(最常用,也是用在transformer中的)

下面讲讲self-attention的计算方式, α 的计算方式就是前面说的那样,当前的 q 和其它词下的 k 做点乘,并过soft-max层做归一化,然后得到的每个 α 和每个词下的 v 做乘积并全部加起来,得到新的向量表示 b 。

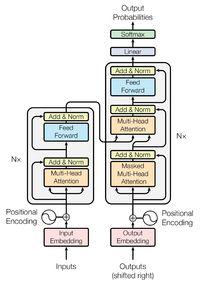
下面这张图是transformer中是关于Self-Attention的流程图(图中只描述了单头的流程图):

所谓的Multi-head Self-attention其实就是对输入进行多个上面这样的Self-attention操作(head的个数也是一个超参数),然后在最后一层concat起来,再过一层linear层做变换即可。

带目前为止,我们会发现,Self-attention少了一个位置的信息,目前来着,所以词的attention的操作都是一模一样的,不能分清词的先后顺序,对它来说每个词的距离都是一样的,此时可以认为是全连接的图(上图只是为了便于展示所以有了这个先后顺序,其实这里边每个词都是一样的)。因此,我们需要引入一个Position Encoding的信息进来,每个位置都会有不用的向量 e ,同时,把这个 e 加在输入端 a 上即可。
补充知识
下面关于Transformer中position encoding的方式的介绍(参考下面两篇博文):
如何理解Transformer论文中的positional encoding,和三角函数有什么关系?944 赞同 · 48 评论回答
蛐蛐xjtu:对Transformer中的Positional Encoding一点解释和理解88 赞同 · 16 评论文章
总的来说,如果单纯的采用一个PE=pos/(T−1)(归一化处理)去编码的话,会使得不同长度文本,短文本中相邻两个字的位置编码差异,和在长文本中隔数个字的两个字之间的位置编码差异一致。这显然是不合适的,我们关注的位置信息,最核心的就是相对次序关系,尤其是上下文中的次序关系,如果使用这种方法,那么在长文本中相对次序关系会被「稀释」。
sin和cos的目的是为了能够提供一个有界的周期性函数PE(pos)=sin(posα),使得编码不依赖于文本的长度,编码具有一定的不变性,也就是说在某个周期内位置编码会有差异,超出这个周期之后差异会变小,这样的做法还是有一些简陋,周期函数的引入是为了复用位置编码函数的值域,但是这种Z→[−1,1]的映射,还是太单调:如果α比较大,相邻字符之间的位置差异体现得不明显;如果α比较小,在长文本中还是可能会有一些不同位置的字符的编码一样,这是因为[−1,1]空间的表现范围有限。既然字嵌入的维度是dmodel,自然也可以使用一个dmodel维向量来表示某个位置编码——[−1,1]dmodel(即有 dmodel 维,每一维值限定在 [−1,1] 内)的表示范围要远大于[−1,1]。因此,有了Transformer中的位置编码(sinusoidal position encoding),如下所示:
PE(pos,2i)=sin(pos/100002i/dmodel)
PE(pos,2i+1)=cos(pos/100002i/dmodel)
稍微解释一下:pos表示token在sequence中的位置,例如第一个token就是0。i ,或者准确意义上是 2i 和 2i+1 表示了Positional Encoding的维度,i 的取值范围是[0,…,dmodel/2) 。所以当pos为1时,对应的Positional Encoding可以写成:
PE(1)=[sin(1/100000/512),cos(1/100000/512),sin(1/100002/512),cos(1/100002/512),…]
显然,在不同维度上应该用不同的函数(周期不同,这样的话在不同维度在相同的两个相对位置处的编码也会不同,增加位置编码的多样性)操纵位置编码,这使得每一维度上都包含了一定的位置信息,而各个位置字符的位置编码又各不相同。
问:Bert为什么采用Position Embedding而不是Position Encoding?
对于 NMT 任务,encoder 的核心任务是提取完整的句子语义信息,它其实并不特别关注某个词的具体位置是什么。比如“Dropped the boy the ball”这句话,就算我不说有一个词被调序了,你也能猜出整句话的意思。对于模型也是这样。Positon Encode 的功能,只是将每个位置区分开(当然三角函数对相对位置有帮助),对于高度关注局部语序的翻译任务来说,它更合适。
BERT 则完全不同,它的 encoder 需要建模完整的 word order。尤其是对于序列标注类的下游任务,模型需要给出每个位置的预测结果。这种时候,完全训练得来的 Postion Embedding,就比按公式赋值的 Position Encode 要好。
总结:Position Encoding更关注相对位置信息,而Postion Embedding则更注重完整的word order。
Self-attention的应用


在RNN中信息传递是串行的,而在Self-attention中信息传递是并行的。

还有就是在GNN中的应用,主要是GAT网络。