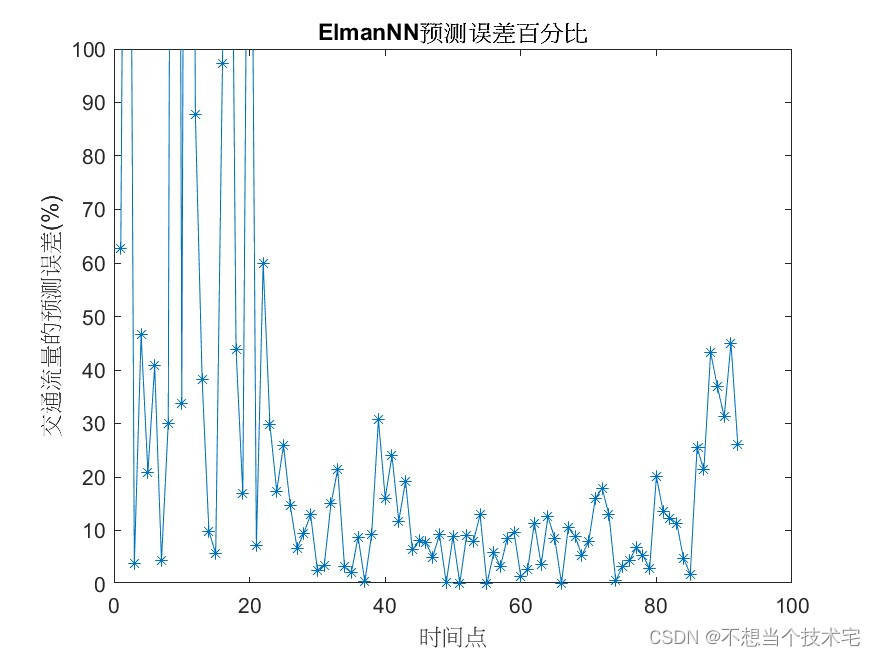
在做前端上传时,会遇到上传大文件,大文件就要进行分片上传,我们整理下思路,实现一个分片上传,最终我们要拿到每一个分片的hash值,index 分片索引,以及分片blob,如下:
一、实现切片
index.html: 我们先创建一个html文件,用于处理选择文件,进而分片,这里利用spark-md5获取文件hash值
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>文件分片</title>
</head>
<body>
<input type="file" id="input"></input>
<script type="module">
import { createChunk } from './main.js'
document.getElementById('input').onchange = event => {
let files = event.target.files
if (files.length) {
// 进行分片
createChunk(files[0])
}
}
</script>
</body>
</html>
main.js: 默认一个分片5M,这里要向上取整,计算出分片数量
import SparkMD5 from 'https://esm.sh/spark-md5@3.0.2'
const CHUNK_SIZE = 1024 * 1024 * 5 // 分片大小5M
/**
* @description 进行分片
* @param {Object} file: 当前要处理的任务对象
*/
function createChunk(file) {
// 计算分片数量
let count = Math.ceil(file.size / CHUNK_SIZE)
console.log(count)
}

然后循环处理
/**
* @description 进行分片
* @param {Object} file: 当前要处理的任务对象
*/
function createChunk(file) {
// 计算分片数量
let count = Math.ceil(file.size / CHUNK_SIZE)
for (let i = 0; i < count; i++) {
// 分片
splitChunk(file, i, CHUNK_SIZE)
}
}
对文件进行切片,利用file.slice(start, end)对文件进行切片处理
/**
* @description 切片
* @param {Object} file: file对象
* @param {Number} i: 当前处理的第几个任务
* @param {Number} size: 一个切片的大小
*/
function splitChunk(file, i, size) {
let start = i * size
let end = (i + 1) * size
let blob = file.slice(start, end)
console.log(blob)
}
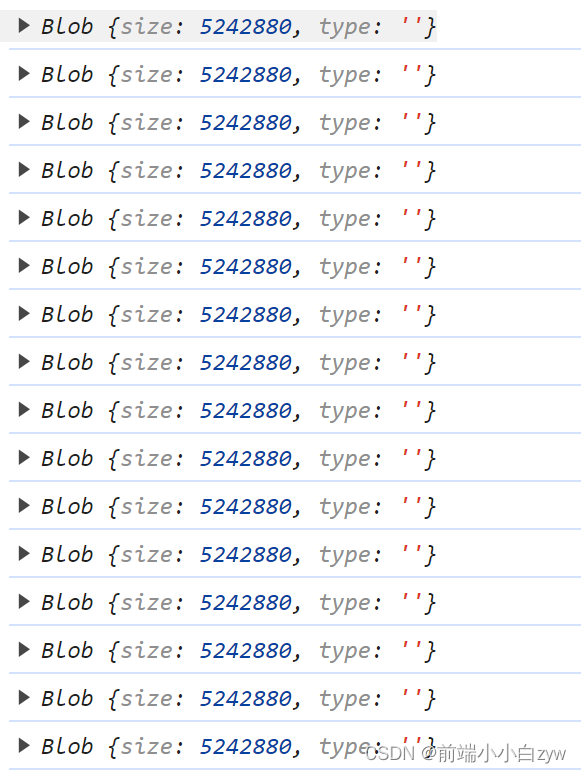
可以看到,切为若干份
然后获取切片的hash值,并且记录切片的起始/结束位置和切片索引index,最终返回promise
/**
* @description 切片
* @param {Object} file: file对象
* @param {Number} i: 当前处理的第几个任务
* @param {Number} size: 一个切片的大小
*/
function splitChunk(file, i, size) {
return new Promise((resolve, reject) => {
let start = i * size
let end = (i + 1) * size
let blob = file.slice(start, end)
// 获取文件hash值
getFileHash(blob)
.then(res => {
resolve({
blob: blob,
start,
end,
index: i,
hash: res
})
})
})
}
/**
* @description 获取文件hash值
* @param {Object} file: 源文件信息
*/
function getFileHash(file) {
let spark = new SparkMD5.ArrayBuffer()
return new Promise(function (resolve, reject) {
let fileReader = new FileReader()
fileReader.onload = function (e) {
let buffer = e.target.result
if (file.size != buffer.byteLength) {
reject("获取文件hash失败,按理说不可能");
} else {
spark.append(buffer) // 解析 Buffer
resolve(spark.end())
}
};
fileReader.onerror = function () {
reject("文件初始化读取Buffer失败");
};
fileReader.readAsArrayBuffer(file);
});
}
然后对返回的结果进行批处理,这里我们可以打印下处理的时间
/**
* @description 进行分片
* @param {Object} file: 当前要处理的任务对象
*/
function createChunk(file) {
let promises = []
console.time('splitChunk')
// 计算分片数量
let count = Math.ceil(file.size / CHUNK_SIZE)
for (let i = 0; i < count; i++) {
// 分片
promises.push(splitChunk(file, i, CHUNK_SIZE))
}
Promise.all(promises)
.then(res => {
console.log(res)
console.timeEnd('splitChunk')
})
}
可以看到,处理了4秒左右,主要是花费在处理文件hash上,获取文件hash为同步任务,且占用主线程,这对于单线程的js来讲,如果文件过大,会影响当前用户的使用体验
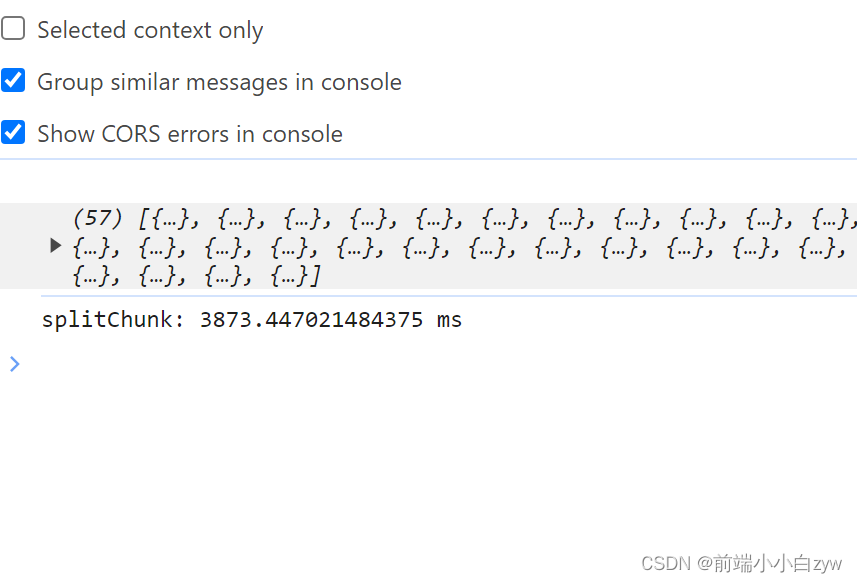
二、多线程优化
上面我们已经实现切片,但是如果文件过大,带来的影响较大,所以我们可以利用js Worker进行多线程优化,这里我们判断客户端的cpu内核数量,进而开启对应数量的线程
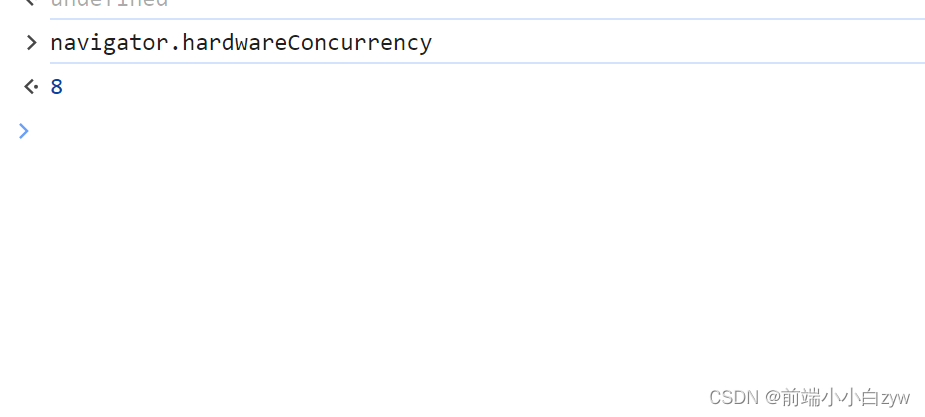
利用浏览器navigator.hardwareConcurrency获取当前cpu内核数量,可以看到,本机的内核数为8
这里处理线程的开启数量
import SparkMD5 from 'https://esm.sh/spark-md5@3.0.2'
const CHUNK_SIZE = 1024 * 1024 * 5 // 分片大小5M
const KERNEL_COUNT = navigator.hardwareConcurrency || 4 // 内核数量,如果取不到则为4
/**
* @description 进行分片
* @param {Object} file: 当前要处理的任务对象
*/
function createChunk(file) {
// 计算分片数量
let count = Math.ceil(file.size / CHUNK_SIZE)
// 计算线程开启数量
let workerCount = Math.ceil(count / KERNEL_COUNT)
// 计算线程开启数量
let workerCount = Math.ceil(count / KERNEL_COUNT)
for (let i = 0; i < workerCount; i++) {
// 创建一个线程,并且分配任务,这里要指定为module模块化
let worker = new Worker('./worker.js', { type: "module" })
// 因为线程数量是向上取整,有除不尽的情况,这里要处理下结束的chunkIndex,如果最后一个chunk大于总chunk数,则写死
let end = (i + 1) * KERNEL_COUNT
if (end > count) {
end = count
}
// 分配任务
worker.postMessage({
file,
CHUNK_SIZE,
startChunkIndex: i * KERNEL_COUNT,
endChunkIndex: end
})
// 接收处理结果
worker.onmessage = e => {
}
}
}
多线程查看接收到的任务,一共开启8个线程,进行切片
worker.js:线程worker
// 处理线程收到消息
onmessage = e => {
let {
file,
CHUNK_SIZE,
startChunkIndex,
endChunkIndex
} = e.data
console.log(file, CHUNK_SIZE, startChunkIndex, endChunkIndex)
}
worker.js:接下来,我们进行切片,然后返回切片结果
import { splitChunk } from './main'
// 处理线程收到消息
onmessage = async e => {
let {
file,
CHUNK_SIZE,
startChunkIndex,
endChunkIndex
} = e.data
let promises = []
for (let i = startChunkIndex; i < endChunkIndex; i++) {
promises.push(splitChunk(file, i, CHUNK_SIZE))
}
let chunks = await Promise.all(promises)
console.log(chunks)
postMessage(chunks)
}
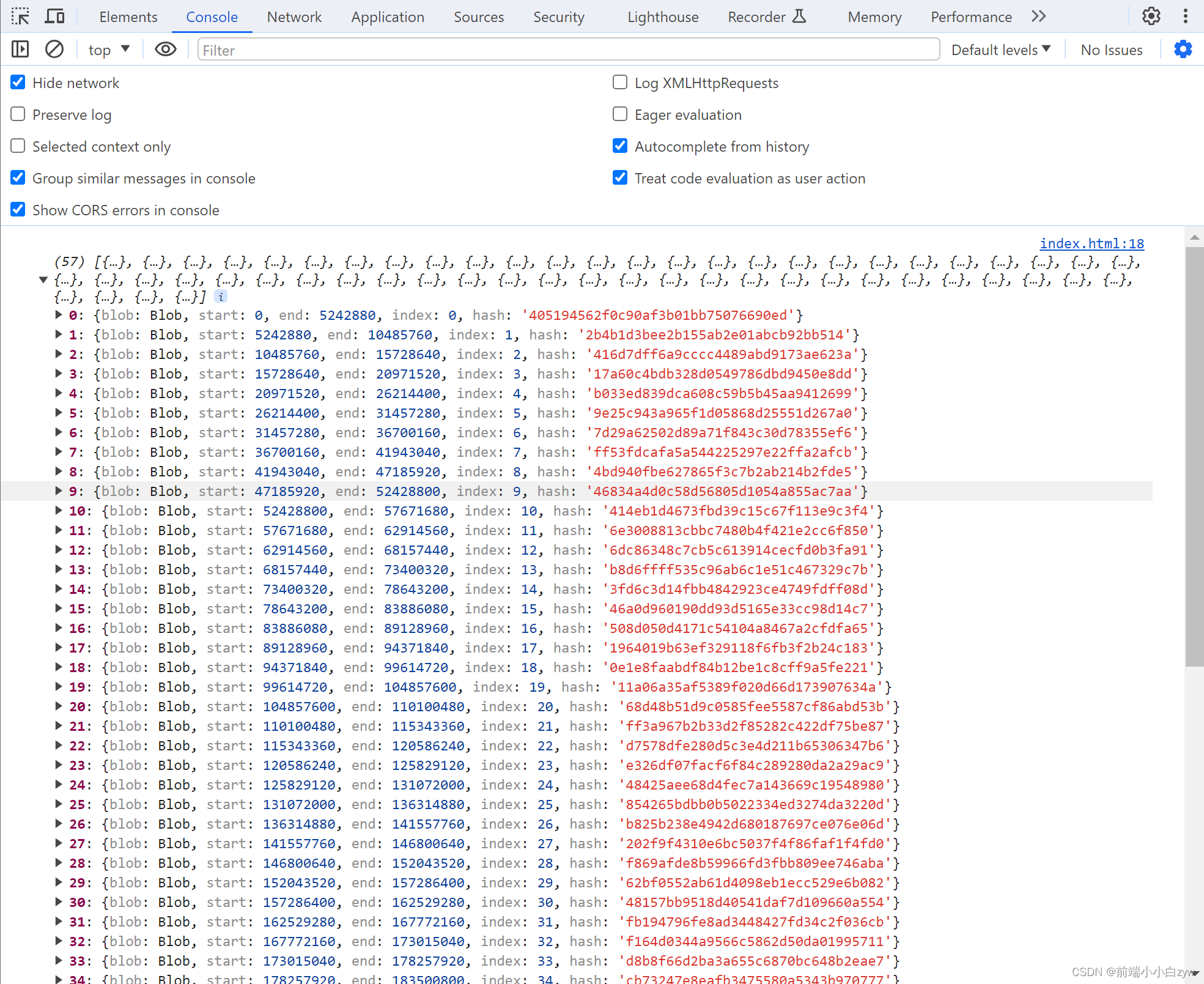
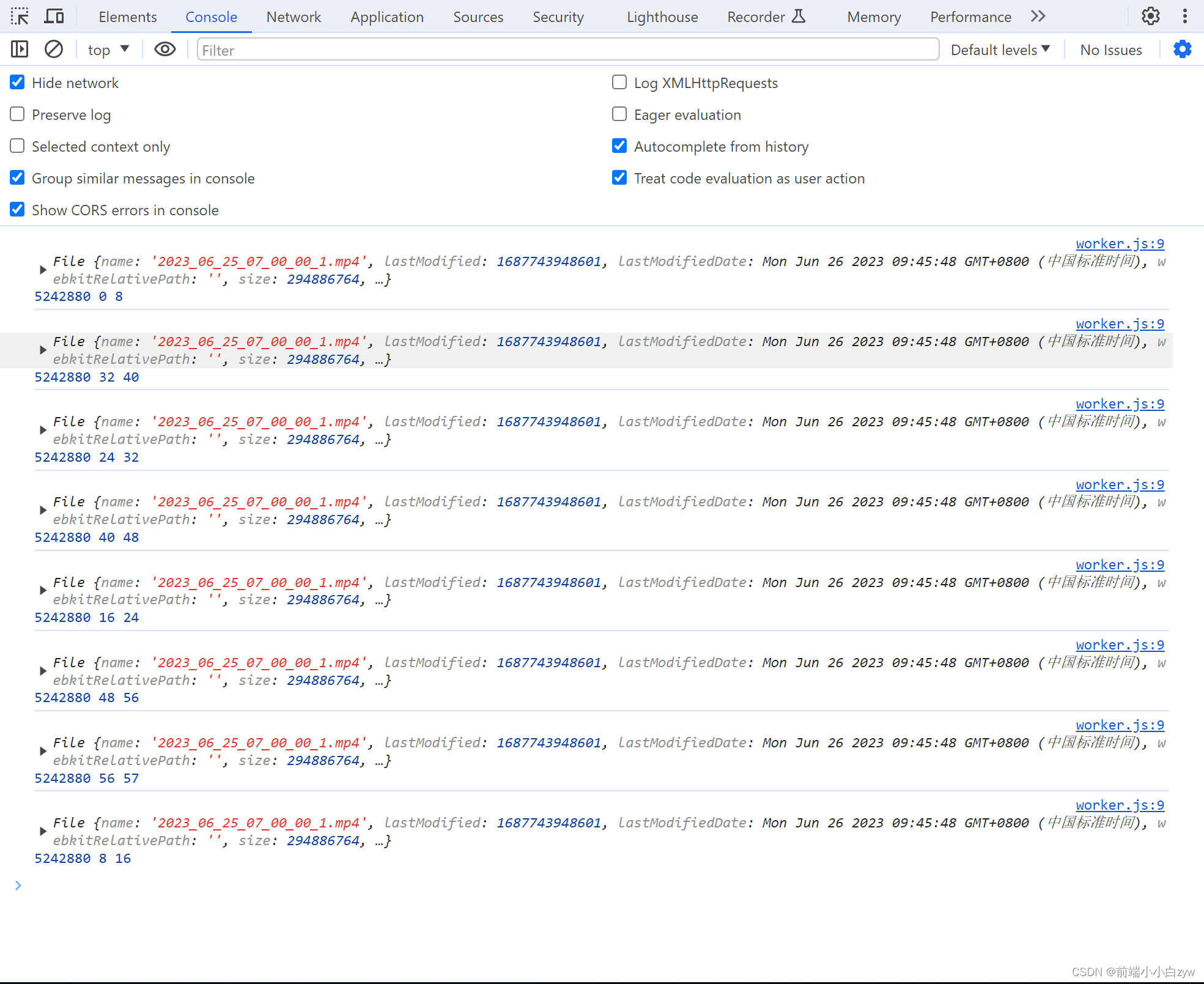
打印下,可以看到8个线程各自处理切片,一共57个切片,最后一个线程只有一个切片任务, 7 * 8 + 1 = 57
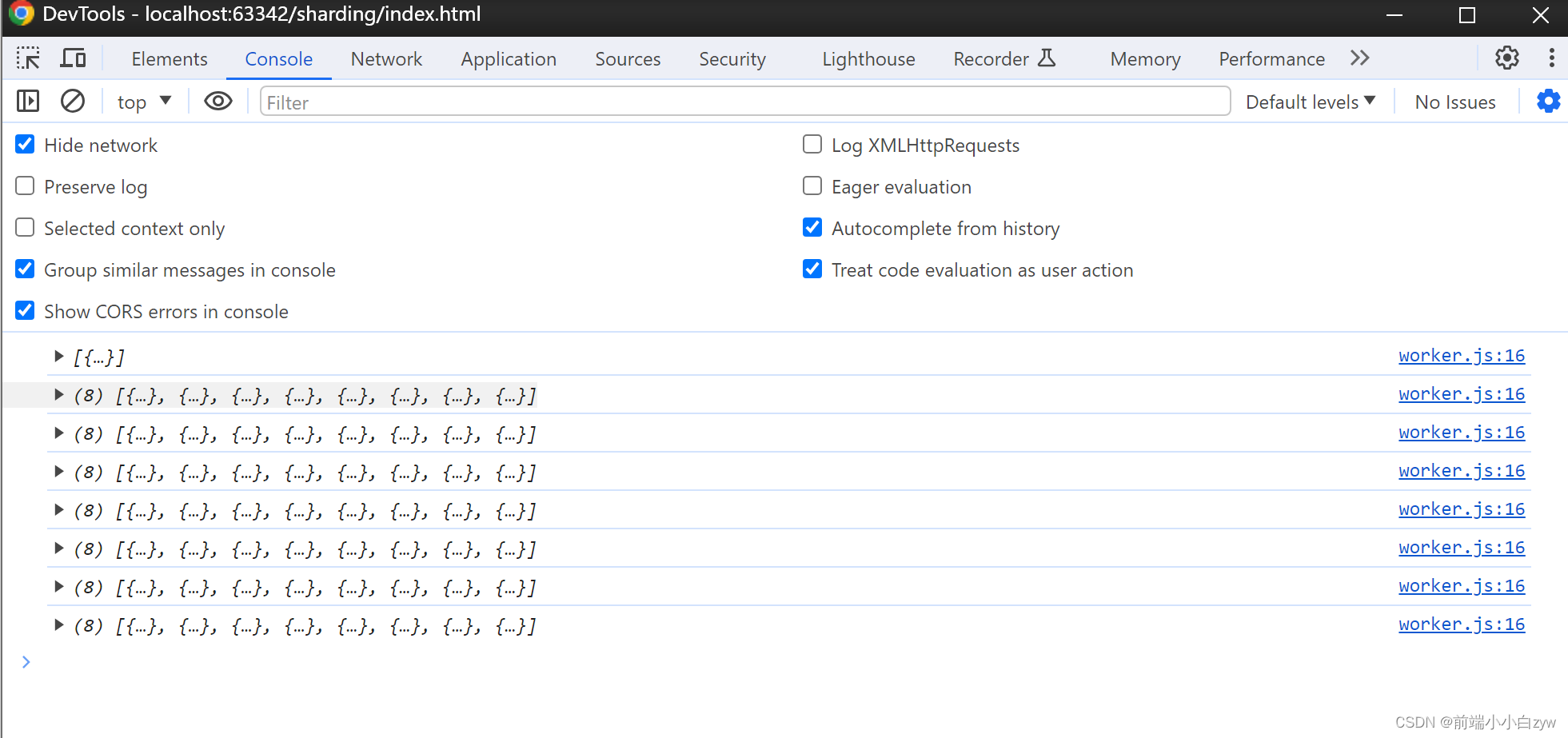
main.js:然后我们接收处理结果,然后保存起来,因为这里的线程谁先完事儿是未知数,所以需要特殊处理下:
/**
* @description 进行分片
* @param {Object} file: 当前要处理的任务对象
*/
export function createChunk(file) {
return new Promise(((resolve, reject) => {
let promises = []
// 结果
let result = []
// 计算分片数量
let count = Math.ceil(file.size / CHUNK_SIZE)
// 计算线程开启数量
let workerCount = Math.ceil(count / KERNEL_COUNT)
// 当前线程执行完毕的数量
let finishCount = 0
for (let i = 0; i < workerCount; i++) {
// 创建一个线程,并且分配任务
let worker = new Worker('./worker.js', { type: "module" })
// 开始
let start = i * KERNEL_COUNT
// 因为线程数量是向上取整,有除不尽的情况,这里要处理下结束的chunkIndex,如果最后一个chunk大于总chunk数,则写死
let end = (i + 1) * KERNEL_COUNT
if (end > count) {
end = count
}
// 分配任务
worker.postMessage({
file,
CHUNK_SIZE,
startChunkIndex: start,
endChunkIndex: end
})
// 接收处理结果
worker.onmessage = e => {
// 这里为了避免顺序乱,取当前的执行索引
for (let i = start; i < end; i++) {
result[i] = e.data[i - start]
}
worker.terminate() // 结束任务
finishCount ++ // 完成数量++
if (finishCount === workerCount) {
resolve(result)
}
}
}
}))
}
index.html:我们可以打印下结果
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>文件分片</title>
</head>
<body>
<input type="file" id="input"></input>
<script type="module">
import { createChunk } from './main.js'
document.getElementById('input').onchange = async event => {
let files = event.target.files
if (files.length) {
console.time('splitChunk')
// 进行分片
let res = await createChunk(files[0])
console.log(res)
console.timeEnd('splitChunk')
}
}
</script>
</body>
</html>
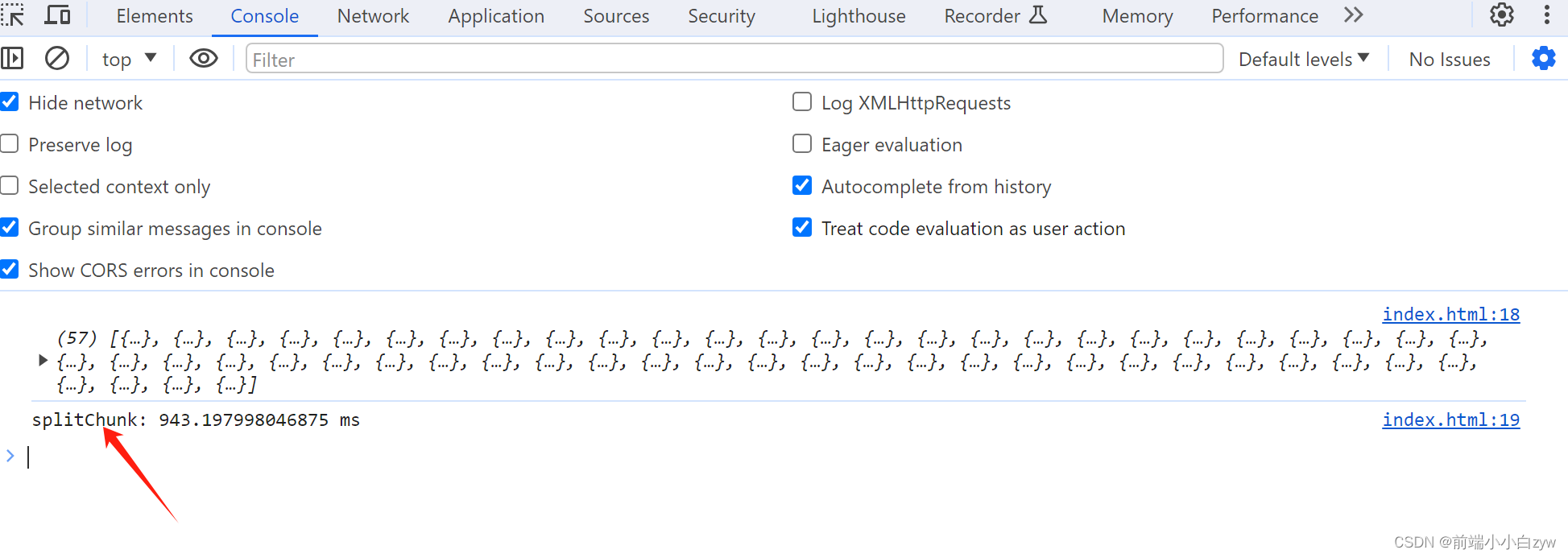
可以看到,效率极大提升,由4秒提升到1秒,最主要不影响用户体验
断点续传就更简单了,服务端记录任务进度即可,这里就不说了