软件安装
概述
-
在Linux中,软件安装分为3种方式:绿色安装(压缩包解压之后就能直接使用),rpm安装(类似于Windows中的exe或者msi文件),yum安装
-
RPM(Red Hat Package Manager):红帽提供的软件包的管理工具。可以通过rpm命令来安装软件
-
rpm包的命名格式:
软件名称-版本号-能够运行的平台.rpm -
基本命令
-
已经安装了哪些rpm
rpm -qa # -q,query,查询 # -a,all,所有 -
确定是否安装了具体的软件,例如MySQL
rpm -qa | grep -i mysql -
卸载软件
# 查询这个软件 rpm -qa | grep -i nmap # 卸载软件 # -e,establish,卸载 # -v,verbose,详细信息 # --nodeps,忽略依赖 rpm -ev --nodeps nmap-ncat-6.40-16.el7.x86_64 -
安装rpm包
# -i,install,安装 # -v,verbose,详细过程 # -h,hash,校验哈希码 rpm -ivh nc-1.84-22.el6.x86_64.rpm
-
-
YUM
-
YUM(yellow dog updater Modifier):Red Hat提供的一款软件管理工具,基于rpm来进行的安装
-
在进行rpm安装的时候,有时候会碰到非常多的依赖,所以红帽公司就提供了YUM用于解决依赖问题。在进行yum安装的时候,自动将需要的依赖按照规定顺序来下载和安装
-
基本命令
-
查看已经安装所有的软件
# -y,yes,确认 yum -y list -
查看是否已经安装了具体的软件
yum -y list | grep -i mysql -
卸载软件
yum -y remove firefox -
安装软件
yum -y install firefox -
清理缓存
yum -y clean
-
-
yum源:默认情况下,YUM源是国外Apache的源,也因此下载效率相对较低。当国外源无法连接的时候,自动的切换到国内的yum源。本机yum源由
/etc/yum.repos.d/CentOS-Base.repo决定 -
实际过程中,一般会将yun源替换为国内的yum源,比较常用的是阿里、华为、网易、腾讯等
补充
上传/下载
-
安装工具
yum -y install lrzsz -
下载命令
sz 文件名 -
上传
rz
Shell
概述
-
Shell是一个命令解释器,接收用户/程序的操作/指令,然后将指令解析之后交给操作系统的内核来执行
-
Shell本身也可以看作是一门编程语言,相对易于书写,灵活性很强
-
Linux中提供了Shell解析器
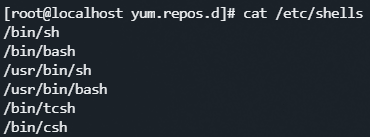
sh是bash的软链接,所以执行sh和使用bash的效果是相同的
-
Centos中默认使用的是
/bin/bash
入门脚本
-
默认情况下,脚本是以
.sh作为结尾 -
规定:所有的Shell脚本的第一行必须是
#!/bin/bash,指定这个Shell脚本的解析器 -
步骤
-
创建空文件
cd /opt mkdir shelldemo cd shelldemo touch demo.sh -
编辑脚本
vim demo.sh -
定义脚本
#!/bin/bash echo 'Hello world! -
赋权
chmod u+x demo.sh
-
-
执行脚本
# 方式一:bash/sh 相对路径 sh demo.sh bash demo.sh sh ./demo.sh bash ./demo.sh # 方式二:bash/sh 绝对路径 sh /opt/shelldemo/demo.sh # 方式三:. 相对路径 . demo.sh . ./demo.sh -
案例
-
定义脚本
touch demo2.sh -
编辑脚本
vim demo2.sh -
添加内容
#!/bin/bash a=2 echo $a -
执行脚本
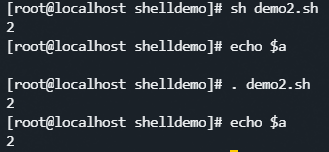
-
sh和
.的区别:- sh在当前系统解析器中开启了一个新的子解析器来执行这个脚本,当脚本执行完成之后,这个子解析器会一起关闭
.表示直接在当前的解析器中解析这个脚本
-
变量
-
定义变量:
变量名=变量值 # 注意:在Linux中,空格表示隔断,所以定义变量的时候不要写空格!!! a=2 # a = 2是错误的 -
如果要引用变量,是通过
$变量名来使用 -
在Linux中,所有的数据默认都是字符串。如果数据中有空格,那么需要使用单引号或者双引号来标记
# echo hello world 是错误的 echo 'hello world' echo "hello world" -
销毁变量
# unset 变量名 unset a -
在Linux中,预定义了大量的变量,例如
PATH,USER等 -
只读变量
readonly 变量名=变量值 # 定义好只能读不能改,类似于Java中的常量 # readonly定义的变量不能被销毁 -
export:提升变量,将变量提升为全局变量,在整个系统中可用。一般环境变量都会使用export -
运算
# 方式一:$[ 运算 ] echo $[ 2+3 ] # 方式二: $(( 运算 )) echo $(( 2+3 )) # 案例 a=4 b=5 echo $[ $a+$b ] echo $(( $a+$b )) -
$n:n是一个数字。n=0,表示获取当前脚本文件的名字;n=1~9表示获取第1-9个参数,如果n≥10,表示第10个及以上的参数,此时需要写成${n},例如${10},${11}vim vardemo1.sh # 在文件中添加 #!/bin/bash echo '文件名:'$0 echo '参数1:'$1 echo '参数2:'$2 echo '和:'$[ $1+$2 ] # 保存退出,执行脚本 sh vardemo1.sh 3 6 -
其他
vim vardemo2.sh # 添加内容 #!/bin/bash echo '参数个数:'$# echo '所有参数:'$* echo '所有参数:'$@ # 保存退出,执行脚本 sh vardemo2.sh 2 8 5 8 1 2 5 1 26 748
条件判断
-
格式
# 格式一:test 条件 test 4 -gt 3 # 格式二:[ 条件 ] [ 4 -gt 3 ] # []中如果不是条件,那么只要不是空的就成立 [ fesco ] # 成立 [ ] # 不成立 -
如果需要获取判断结果,需要通过
$?。如果上一条命令正确执行,那么返回0 -
条件符号(数字)
符号 解释 -gtgreater than,大于 -gegreater than or equal,大于等于 -eqequal,等于 -leless than or equal,小于等于 -ltless than,小于 -nenot equal,不等 -
如果是字符,可以通过
=或者!=来判断 -
文件
# -r 判断文件是否可读 [ -r demo.sh ] # -w 判断文件是否可写 [ -w demo.sh ] # -x 判断文件是否可执行 [ -x demo.sh ] # -f 判断是否是一个文件 [ -f demo.sh ] # -d 判断是否是一个目录 [ -d demo.sh ] # -e 判断文件是否存在 [ -e demo.sh ]
流程控制
if结构
-
基本格式
# 格式一 if [ 条件 ];then 逻辑 fi 或者 if [ 条件 ] then 逻辑 fi # 格式二 if [ 条件 ] then 逻辑1 else 逻辑2 fi # 格式三 if [ 条件 ] then 逻辑1 elif [ 条件 ] then 逻辑2 ... else 逻辑 fi -
案例
vim ifdemo.sh # 添加内容 #!/bin/bash if [ $(( $1 % 2)) -eq 1 ] then echo $1'是一个奇数' else echo $1'是一个偶数' fi # 保存退出,执行脚本 sh ifdemo.sh 5
case结构
-
case结构类似于Java中的
switch-casecase 变量 in "值1") 逻辑 ;; "值2") 逻辑 ;; ... *) 逻辑 ;; esac -
case结构实际过程中经常用于脚本的集群命令
vim casedemo.sh # 在文件中添加 #!/bin/bash case $1 in "start") echo '启动xxx' ;; "stop") echo '停止xxx' ;; "restart") echo '重启xxx' ;; *) echo '未知的操作' ;; esac # 保存退出,执行脚本 sh casedemo.sh start
for结构
-
基本结构
# 方式一 for (( 初始值;条件;变化 )) do 逻辑 done # 方式二 for 变量 in 值1, 值2, 值3, ... do 逻辑 done -
案例一:求1-100的和
vim fordemo.sh # 在文件中添加 #!/bin/bash sum=0 for (( i=1;i<=100;i++ )) do sum=$[ $sum+$i ] done echo $sum # 保存退出,执行脚本 sh fordemo.sh -
案例二:求输入的所有参数的和
vim fordemo2.sh # 添加 #!/bin/bash sum=0 for i in $* do sum=$[ $sum+$i ] done echo $sum # 保存并执行 sh fordemo2.sh 5 6 4 1 7 9 2
while结构
-
基本格式
while [ 条件 ] do 逻辑 done -
案例:求1-100的和
vim whiledemo.sh # 添加内容 #!/bin/bash sum=0 i=1 while [ $i -le 100 ] do sum=$[ $sum+$i ] i=$[ $i+1 ] done echo $sum # 保存并执行 sh whiledemo.sh
函数
-
在Shell中,统一通过
function来定义函数 -
格式
function 函数名() { 逻辑 [return 返回值] } -
Shell是一门解释型语言,也就意味着,Shell是逐行解释执行,也就是说,函数必须先定义后使用
-
不同于Java的地方在于,Shell中的函数的返回值只能是整数(0~255)。如果不写return语句,那么默认函数的最后一行代码的执行结果就是返回值
-
案例:求两个整数的和
vim functiondemo.sh # 添加 #!/bin/bash function sum() { # 在函数中,$n的形式表示第几个参数 sum=$[ $1+$2 ] echo $sum } sum 3 5; -
系统自带函数:
basename:截取路径中的文件名dirname:截取路径中的目录
常用工具
-
wc:word count的缩写,可以统计文件中字节个数、字符数量、列数等# -l,line,行数 # -w,word,单词数 # -m,字符数 # -c,字节数 wc -l -w -m -c b.cfg -
cut:针对数据进行处理,可以从一行数据中剪切出指定的部分# -d,descriptor,间隔符号,默认是制表符 # -f,剪切之后要获取第几列 echo $PATH | cut -d ':' -f 4 echo $PATH | cut -d ':' -f 3-5 -
sed:是一个流式编辑器,一次处理一行内容,可以对文件进行复杂的操作-
命令格式
sed [参数] command 文件 -
追加操作
# a:在指定行之后追加 # 在a.txt第二行后追加一行hello sed '2ahello' a.txt # 在指定内容之后追加一行hi sed '/tom/ahi' a.txt # i-在指定行之前追加一行 # 在第4行之前追加一行big sed '4ibig' a.txt # 在指定数据之前追加一行big sed '/bruce/ibig' a.txt # 在最后一行追加 sed '$abig' a.txt -
修改/替换操作
# c:修改指定的内容 # 将第三行修改为aaa sed '3caaa' a.txt
-
将b开头的行修改为alex
sed '/^b/calex' a.txt
# 将最后一行替换为hello
sed '$chello' a.txt
```
-
删除操作
# d:删除 # 删除第四行 sed '4d' a.txt # 删除最后一行 sed '$d' a.txt # 删除第3~5行 sed '3,5d' a.txt # 删除奇数行 n~md从第n行开始,每m行删除一次 sed '1~2d' a.txt # 删除除了3~5行以外的其他行 sed '3,5!d' a.txt # 删除包含指定内容的行,例如删除包含m的行 sed '/m/d' a.txt # 从找到含有y的行开始,删除到最后 sed '/y/,$d' a.txt # 从找到含有y的行开始,继续往下删除2行 sed '/y/,+2d' a.txt # 删除含有m或者含有y的行 sed '/m\|y/d' a.txt # 删除第3行~第7行之间含有m的行 sed '3,7{/m/d}' a.txt # 删除空行 sed '/^$/d' a.txt -
替换操作
# s:替换数据,而不是整行 # 将m替换为a sed 's/m/a/' a.txt # 等价于 -- g代表全部 sed 's/m/a/g' a.txt # i-忽略大小写 sed 's/m/a/i' a.txt # w-保存,将产生了修改的数据放到指定的文件中 sed 's/m/a/w c.txt' a.txt # -n表示保留被操作过的数据 # p表示打印匹配的内容 sed -n 's/m/a/p' a.txt -
打印操作
# p:打印匹配的内容,一般结合-n使用 # 打印文件的所有行 sed -n 'p' a.txt # 只显示第5行 sed -n '5p' a.txt # 每隔2行打印一次 sed -n '1~3p' a.txt # 打印1~3行 sed -n '1,3p' a.txt # 打印最后一行 sed -n '$p' a.txt -
读取操作
# r-从一个文件中读取写入另一个文件 # 从a.txt的第5行开始插入c.txt的内容,然后继续读取a.txt sed '5r c.txt' a.txt # 从b开头的行开始,插入c.txt的内容 sed '/^b/r c.txt' a.txt # 需要在a.txt的最后一行插入 sed '$r c.txt' a.txt -
写入操作
# w-写入另一个文件 # 将a.txt的数据覆盖到c.txt中 sed 'w c.txt' a.txt # 将a.txt的第2行数据覆盖到c.txt中 sed '2w c.txt' a.txt # 将a.txt的含有m的数据覆盖到c.txt中 sed '/m/w c.txt' a.txt -
awk:对数据进行逐行处理,可以对数据进行切分# -F 指定间隔符 # 搜索passwd文件中,以root开头的所有的行,并且打印该行的第3个字段 awk -F: '/^root/{print $3}' /etc/passwd # 第三列和第五列 awk -F: '/^root/{print $3,$5}' /etc/passwd # 获取第一列(用户)和第六列(数据目录列),并且在第一行打印"user,data_home",在末尾打印一个"end" awk -F: 'BEGIN{print "user,data_home"} {print $1,$6} END{print "end"}' /etc/passwd # awk中内置了其他命令:FILENAME-文件名,NR-已读取的行数,NF-切分完之后产生了多少列 awk -F: '{print "filename:"FILENAME",line:"NR",columns:"NF}' /etc/passwd # 查询文件中空行对应的行号 awk '/^$/{print NR}' a.txt -
sort:对文件中的数据排序,默认是按照字典序# -n:按照大小排序 sort -n a.txt # -r:逆序排序 sort -r a.txt # -k:指定排序列 # -u:不重复,unique
t
```
-
awk:对数据进行逐行处理,可以对数据进行切分# -F 指定间隔符 # 搜索passwd文件中,以root开头的所有的行,并且打印该行的第3个字段 awk -F: '/^root/{print $3}' /etc/passwd # 第三列和第五列 awk -F: '/^root/{print $3,$5}' /etc/passwd # 获取第一列(用户)和第六列(数据目录列),并且在第一行打印"user,data_home",在末尾打印一个"end" awk -F: 'BEGIN{print "user,data_home"} {print $1,$6} END{print "end"}' /etc/passwd # awk中内置了其他命令:FILENAME-文件名,NR-已读取的行数,NF-切分完之后产生了多少列 awk -F: '{print "filename:"FILENAME",line:"NR",columns:"NF}' /etc/passwd # 查询文件中空行对应的行号 awk '/^$/{print NR}' a.txt -
sort:对文件中的数据排序,默认是按照字典序# -n:按照大小排序 sort -n a.txt # -r:逆序排序 sort -r a.txt # -k:指定排序列 # -u:不重复,unique