大规模语料是模型训练的基础
大模型的训练,大规模的语料是很重要的
大型语言模型在许多自然语言处理任务上取得了显著进展,研究人员正在转向越来越大的文本语料库进行训练
大多数基于Transformer的大型语言模型 (LLM) 都依赖于英文维基百科和Common Crawl、C4、Github的4个大型数据集。这几个数据集是最常用的,基本上大部分大模型训练过程都会使用到,其中CommonCrawl的数据集比较大,而wiki Pedia的数据集比较规整相对来说比较少
目前Hugging Face上包含中文的语料数据集有954个
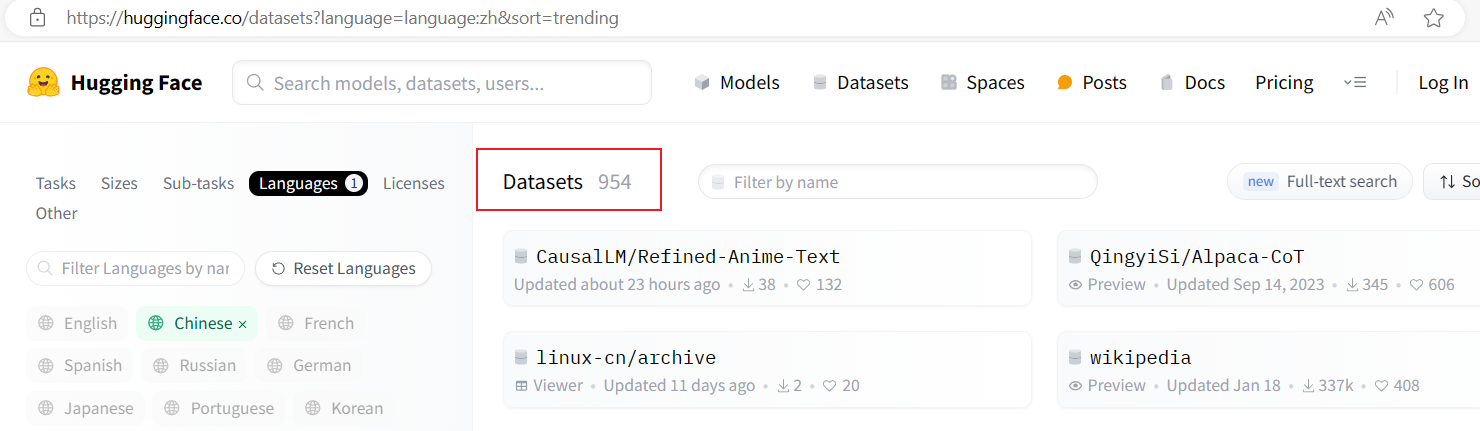
已经处理好的语料信息
1. C4(Common Crawl Cleaned Corpus)
- 数据来源:C4 是由 Common Crawl 爬虫数据经过清洗后得到的语料库。Common Crawl 是一个从互联网上爬取大量文本的项目。
- 数据规模:C4 包含来自互联网上超过 3.65 亿个域的超过 1560 亿个 token。
- 清洗方式:C4 是通过获取 Common Crawl 的 2019 年 4 月快照并应用多个过滤器来创建的,旨在删除非自然英语的文本。过滤器包括去除不以终端标点符号结尾或少于三个单词的行,丢弃少于五个句子或包含 Lorem ipsum 占位符文本的文档,以及删除包含“Dirty,Naughty,Obscene 或 Otherwise Bad Words 清单”上任何单词的文档。此外,还使用 langdetect 删除未被分类为英语且概率至少为 0.99 的文档,因此 C4 主要由英文文本组成。
- 数据下载:C4 GitHub Repository
2. ROOTS(Responsible Open-science Open-collaboration Text Sources)
- 数据来源:ROOTS 是一个跨越 59 种语言(46 种自然语言和 13 种编程语言)的 1.6TB 数据集,用于训练拥有 1760 亿个参数的 BigScience 大型公开科学多语言开放访问(BLOOM)语言模型。
- ROOTS (Responsible Open-science Open-collaboration Text Sources) 这个数据集是一个由 huggingface datasets, dataset collections, pseudo-crawl dataset, Github Code, OSCAR 这几个数据构成的
- 数据构建:ROOTS 主要包括三个来源:已整理好的数据集、伪爬虫数据集(部分志愿者提交的网站,但还没包括内容,需要利用 URL 去 Common Crawl 的快照中解析对应的内容)、经过预处理的网络爬取数据集 OSCAR。
- 数据清洗:清洗过程包括去除重复内容、过滤页面代码或爬行工件、过滤 SEO 页面、过滤色情垃圾等。
- 数据下载:https://huggingface.co/bigscience-data
3. Pile(Public Instructive Language Dataset)
- 数据来源:Pile 是一个面向训练大规模语言模型的 825 GiB 英语文本语料库。它由 22 个多样化的高质量子集构成,包括现有的和新构建的子集,许多子集来自学术或专业来源。
- 数据构建:Pile-CC 使用 jusText 提取 Common Crawl,而 OpenWebText2 是 Pile 提出的信数据集,从 Reddit 提交中提取了 URL 及其相关的元数据。
- 数据清洗:清洗过程包括去除重复内容、过滤页面代码、过滤 SEO 页面、去除个人信息等。
- 论文:Pile GitHub Repository
- 数据下载:https://github.com/leogao2/commoncrawl_downloader
4. WuDaoCorpora
- 数据来源:WuDaoCorpora是北京智源人工智能研究院(智源研究院)构建的大规模、高质量数据集,用于支撑大模型训练研究。目前由文本、对话、图文对、视频文本对四部分组成,分别致力于构建微型语言世界、提炼对话核心规律、打破图文模态壁垒、建立视频文字关联,为大模型训练提供坚实的数据支撑。自2021年3月20日WuDaoCorpora首次发布后,获业界瞩目。目前已有450+"产、学、研"单位的研发团队下载使用。
- 数据构建: 采用20多种规则从100TB原始网页数据中清洗得出最终数据集,注重隐私数据信息的去除,源头上避免GPT-3存在的隐私泄露风险;包含教育、科技等50+个行业数据标签,可以支持多领域预训练模型的训练。
1、数据总量:5TB;2、数据格式:json;3、开源数量:200GB;
中文语料
1 中文文本分类数据集THUCNews
THUCNews是根据新浪新闻RSS订阅频道2005~2011年间的历史数据筛选过滤生成,包含74万篇新闻文档,划分出 14 个候选分类。
http://thuctc.thunlp.org/
2 清华大学NLP实验室开放数据集
这是一个由清华大学[自然语言处理]与社会人文计算实验室维护的中文自然语言处理共享平台,提供了大量的中文文本数据集,包括新闻、论坛、微博、问答等。
http://thuocl.thunlp.org/
https://www.chinesenlp.com/
thuctc.thunlp.org/
3 wiki百科中文
[中文维基百科]是维基百科协作计划的中文*版本,自2002年10月24日正式成立,由非营利组织──维基媒体基金会负责维持,截至2010年6月30日14:47,中文维基百科已拥有314,167条条目。
https://zh.wikipedia.org
4. WuDaoCorpora
WuDaoCorpora是北京智源研究院最新构建的高质量数据集,由全球最大的纯文本数据集、全球最大的多模态图文数据集和全球最大的中文对话数据集三部分构成。
https://openi.pcl.ac.cn/BAAI/WuDao-Data/
5 Chinese book
包含13.3万余册中文图书的数据集。包含书名、作者、出版社、关键词、摘要、图书分类号、出版年月等7个字段。提供[百度网盘]下载。可用于机器学习、数据挖掘、自然语言处理等领域。
https://github.com/JiangYanting/Chinese_book_dataset
6 千言
百度联合中国计算机学会自然语言处理专委会、[中国中文信息学会]评测工作委员会共同发起的,由来自国内多家高校和企业的数据资源研发者共同建设的中文开源*数据集。*如果是追求规模,可以关注下。
https://www.luge.ai/
7 天池
天池数据集是阿里集团对外开放的科研数据平台,由阿里巴巴集团业务团队和外部研究机构联合提供,覆盖了电商、娱乐、物流、医疗健康、交通、工业、自然科学、能源等十多个行业。*。*如果是追求规模,同样可以关注下。
https://tianchi.aliyun.com/dataset
8 中华古诗词数据库
最全中华古诗词数据集,唐宋两朝近一万四千古诗人, 接近5.5万首唐诗加26万宋诗. 两宋时期1564位词人,21050首词。
github.com/chinese-poetry/chinese-poetry
GPT 生成的语料总结
下面的语料信息总结是ChatGPT根据如下提示词生成的:
你作为一个资深的LLM专家,请写一专题,给出目前主流 大语言模型使用的语料,并给出每一种具体语料的以下内容:数据规模、语料来源、清洗方式、用于的大模型、下载链接、介绍网站等信息,语料信息不少于20个
- 维基百科数据集:
- 数据规模: 数百GB至数TB级别。
- 语料来源: 维基百科是由全球用户编辑的在线百科全书。
- 清洗方式: 通常不需要太多的清洗,但会去除特殊符号、处理链接等。
- 用于的大模型: GPT系列、BERT等。
- 下载链接: 维基百科数据下载
- 介绍网站: 维基百科
- Common Crawl数据集:
- 数据规模: 数万亿个网页的数据集。
- 语料来源: Common Crawl定期对互联网进行爬取而得到。
- 清洗方式: 去除重复内容、垃圾信息、不相关网页等。
- 用于的大模型: GPT系列、T5等。
- 下载链接: Common Crawl数据下载
- 介绍网站: Common Crawl
- BookCorpus数据集:
- 数据规模: 数十GB至百GB级别。
- 语料来源: 包含大量小说、文学作品等书籍内容。
- 清洗方式: 去除版权信息、处理特殊字符等。
- 用于的大模型: GPT系列、BERT等。
- 下载链接: BookCorpus数据下载
- 介绍网站: BookCorpus
- Reddit数据集:
- 数据规模: 数百GB至数TB级别。
- 语料来源: Reddit是包含大量用户生成内容的社交网络平台。
- 清洗方式: 去除噪音、处理表情符号、URL等。
- 用于的大模型: GPT系列、BERT等。
- 下载链接: Reddit数据下载
- 介绍网站: Reddit
- 新闻数据集:
- 数据规模: 数十GB至数百GB级别。
- 语料来源: 各种新闻网站、报纸、新闻聚合平台。
- 清洗方式: 去除特殊符号、处理标点等。
- 用于的大模型: GPT系列、BERT等。
- 下载链接: Kaggle新闻数据
- 介绍网站: Kaggle
- 医学文献数据集:
- 数据规模: 数十GB至数百GB级别。
- 语料来源: 医学期刊文章、临床研究报告、医学书籍等。
- 清洗方式: 专业清洗和预处理。
- 用于的大模型: GPT系列、BERT等。
- 下载链接: PubMed
- 介绍网站: PubMed
- 金融数据集:
- 数据规模: 数十GB至数百GB级别。
- 语料来源: 财经新闻、股市报告、公司年报等。
- 清洗方式: 清洗和预处理。
- 用于的大模型: GPT系列、BERT等。
- 下载链接: Yahoo Finance
- 介绍网站: Yahoo Finance
- 法律文件数据集:
- 数据规模: 数十GB至数百GB级别。
- 语料来源: 法律条文、法案、法庭裁决等。
- 清洗方式: 清洗和预处理。
- 用于的大模型: GPT系列、BERT等。
- 下载链接: CourtListener
- 介绍网站: CourtListener
- Twitter数据集:
- 数据规模: 数百GB至数TB级别。
- 语料来源: 用户推文、评论等。
- 清洗方式: 清洗和过滤。
- 用于的大模型: GPT系列、BERT等。
- 下载链接: Twitter数据下载
- 介绍网站: Twitter Developer
- 社交媒体内容数据集:
- 数据规模: 数百GB至数TB级别。
- 语料来源: 社交媒体平台用户生成的内容,如Facebook、Instagram等。
- 清洗方式: 清洗和过滤。
- 用于的大模型: GPT系列、BERT等。
- 下载链接: Instagram Developer
- 介绍网站: Instagram Developer
- 技术文档数据集:
- 数据规模: 数十GB至数百GB级别。
- 语料来源: 软件文档、编程教程等。
- 清洗方式: 清洗和预处理。
- 用于的大模型: GPT系列、BERT等。
- 下载链接: GitHub
- 介绍网站: GitHub
- 政府文件数据集:
- 数据规模: 数十GB至数百GB级别。
- 语料来源: 政府公告、法律文件等。
- 清洗方式: 清洗和预处理。
- 用于的大模型: GPT系列、BERT等。
- 下载链接: Data.gov
- 介绍网站: Data.gov
- 学术论文数据集:
- 数据规模: 数十GB至数百GB级别。
- 语料来源: 学术期刊文章、会议论文等。
- 清洗方式: 清洗和预处理。
- 用于的大模型: GPT系列、BERT等。
- 下载链接: arXiv
- 介绍网站: arXiv
- 语言学习数据集:
- 数据规模: 数十GB至数百GB级别。
- 语料来源: 语言学习教材、词汇表等。
- 清洗方式: 清洗和预处理。
- 用于的大模型: GPT系列、BERT等。
- 下载链接: The Linguistic Data Consortium
- 介绍网站: The Linguistic Data Consortium