配置文件
# 表示该配置文件是基于另一个配置文件BaseRetina.yaml进行扩展和覆盖的
_BASE_: "../BaseRetina.yaml"
# 指定输出目录,训练过程中的日志、模型权重和评估结果将保存在该目录下。
OUTPUT_DIR: "work_dirs/visdrone_querydet"
# 指定了模型的相关配置项,包括模型架构、预训练权重、锚点生成器、RetinaNet参数等
MODEL:
# 指定使用的目标检测模型架构为 RetinaNetQueryDet。
META_ARCHITECTURE: "RetinaNetQueryDet"
# 指定使用的预训练权重,这里使用了 ImageNet 上 MSRA 提供的 R-50 预训练模型。
WEIGHTS: "detectron2://ImageNetPretrained/MSRA/R-50.pkl"
# 指定 ResNet 的相关配置,如深度和输出特征图的名称。
RESNETS:
DEPTH: 50
# 指定锚点生成器的名称和尺寸。
ANCHOR_GENERATOR:
NAME: "AnchorGeneratorWithCenter"
SIZES: !!python/object/apply:eval ["[[x, x * 2**(1.0/3), x * 2**(2.0/3)] for
x in [16, 32, 64, 128, 256, 512]]"]
# 指定 RetinaNet 的相关配置,如 IoU 阈值、类别数和输入特征图的名称。
RETINANET:
IOU_THRESHOLDS: [0.4, 0.5]
IOU_LABELS: [0, -1, 1]
NUM_CLASSES: 10
IN_FEATURES: ["p2", "p3", "p4", "p5", "p6", "p7"]
RESNETS:
OUT_FEATURES: ["res2", "res3", "res4", "res5"]
# 指定 FPN 的相关配置,如输入特征图的名称。
FPN:
IN_FEATURES: ["res2", "res3", "res4", "res5"]
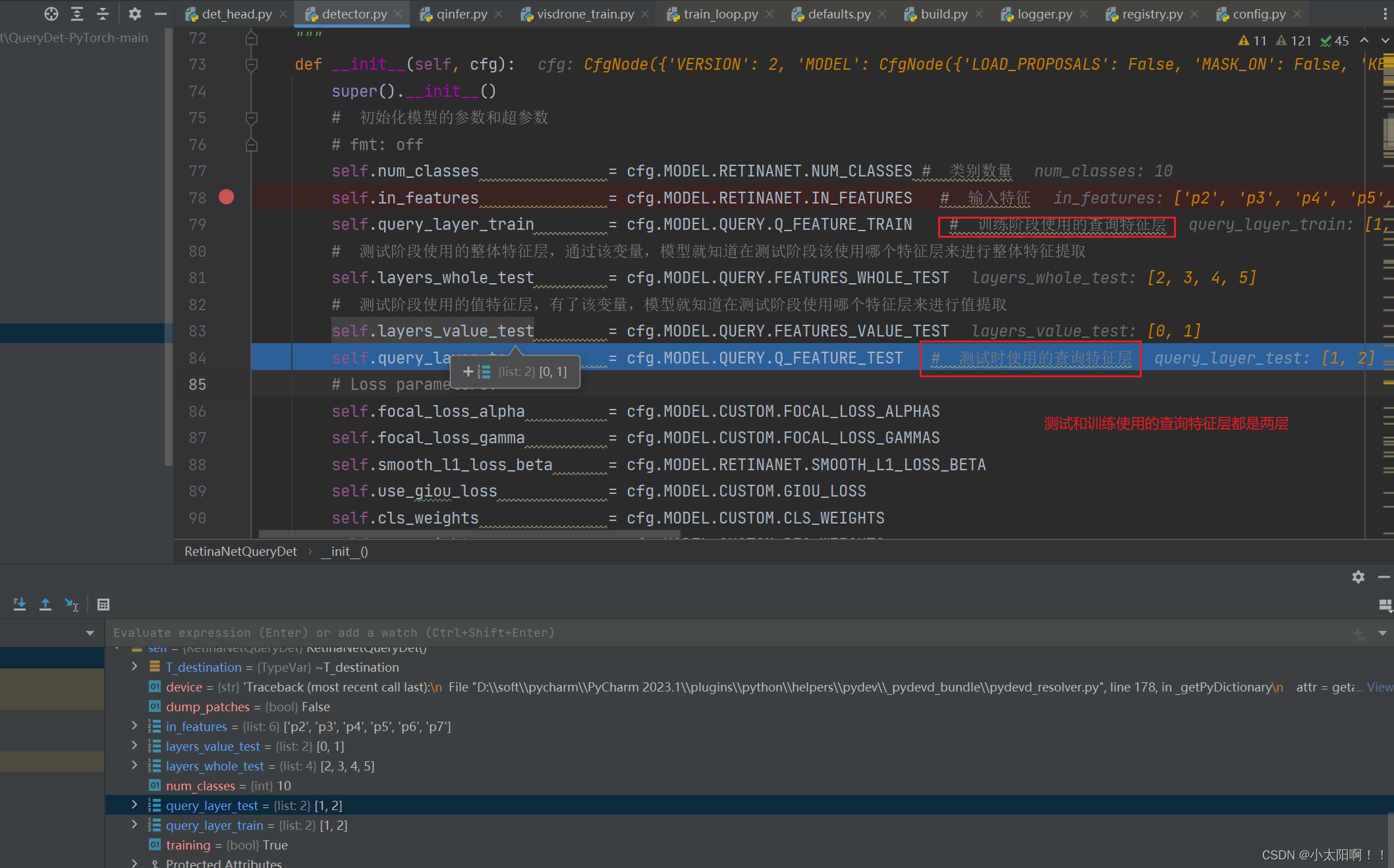
# 指定了查询部分的相关配置,包括训练和测试时的查询特征、查询损失的权重、编码参数等
QUERY:
Q_FEATURE_TRAIN: [1, 2]
FEATURES_WHOLE_TEST: [2, 3, 4, 5]
FEATURES_VALUE_TEST: [0, 1]
Q_FEATURE_TEST: [1, 2]
QUERY_LOSS_WEIGHT: [10., 10.]
QUERY_LOSS_GAMMA: [1.3, 1.3]
ENCODE_CENTER_DIS_COEFF: [1., 1.]
ENCODE_SMALL_OBJ_SCALE: [[0, 32], [0, 64]]
QUERY_INFER: False
# 指定了一些自定义的配置项,如梯度检查点、是否使用循环匹配器、Focal Loss 的 alpha 和 gamma
值、类别权重和回归权重
CUSTOM:
GRADIENT_CHECKPOINT: False
USE_LOOP_MATCHER: True
FOCAL_LOSS_ALPHAS: [0.25, 0.25, 0.25, 0.25, 0.25, 0.25]
单GPU训练
进入start_train()函数
FOCAL_LOSS_GAMMAS: [2.0, 2.0, 2.0, 2.0, 2.0, 2.0]
CLS_WEIGHTS: [1.0, 1.4, 1.8, 2.2, 2.6, 2.6]
REG_WEIGHTS: [1.0, 1.4, 1.8, 2.2, 2.6, 2.6]
# 指定了训练过程中的优化器、学习率调整策略和其他训练参数。
SOLVER:
BASE_LR: 0.01
STEPS: (30000, 40000)
MAX_ITER: 50000
IMS_PER_BATCH: 1
AMP:
ENABLED: True
CLIP_GRADIENTS:
ENABLED: True
CLIP_TYPE: value
CLIP_VALUE: 35.0
NORM_TYPE: 2.0
# 指定了用于训练和测试的图像的尺寸范围。
VISDRONE:
SHORT_LENGTH: [1200]
MAX_LENGTH: 1999
# :指定了测试过程中的一些配置,如评估间隔、每张图像的最大检测数等。
TEST:
EVAL_PERIOD: 0
DETECTIONS_PER_IMAGE: 500
# 指定了一些额外的元信息,如是否评估 GP时间U
META_INFO:
EVAL_GPU_TIME: True
# 指定了可视化的周期,0 表示禁用可视化
VIS_PERIOD: 0
单
GPU
训练

进入start_train()函数

训练
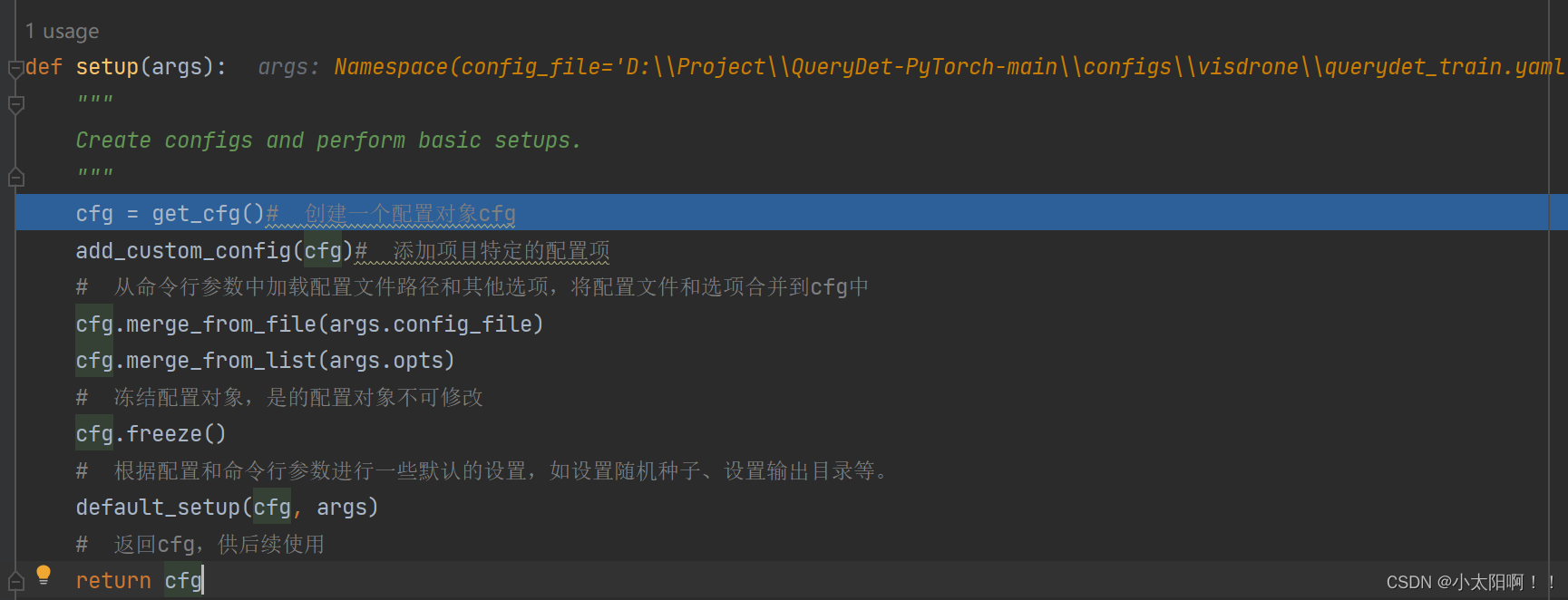
def start_train(args):
# args参数:包含了训练所需的各种配置信息
# 调用setup函数,根据传入的参数配置初始化训练所需的配置文件
cfg = setup(args)
# 为true表示不进行训练,进行评估
if args.eval_only:
model = Trainer.build_model(cfg) # 构建网络模型
DetectionCheckpointer(model, save_dir=cfg.OUTPUT_DIR).resume_or_load(
cfg.MODEL.WEIGHTS, resume=args.resume
) # 恢复模型权重
res = Trainer.test(cfg, model) # 进行模型评估
# 验证评估结果
if comm.is_main_process():
verify_results(cfg, res)
return res # 返回评估结果
# if为False时执行,进行训练
trainer = Trainer(cfg, resume=args.resume, reuse_ckpt=args.no_pretrain)
return trainer.train()- 创建一个 Trainer 对象,传入训练所需的配置文件( cfg ),并指定是否从检查点恢复训练 ( args.resume )以及是否重用预训练模型( args.no_pretrain )。
- 调用 trainer.train() 开始训练过程。
- 返回训练结果。
setup(args)函数
Trainer类:自定义的训练器类
先是继承自
DefaultTrainer
类
但是
DefaultTrainer
类继承自
TrainerBase
类
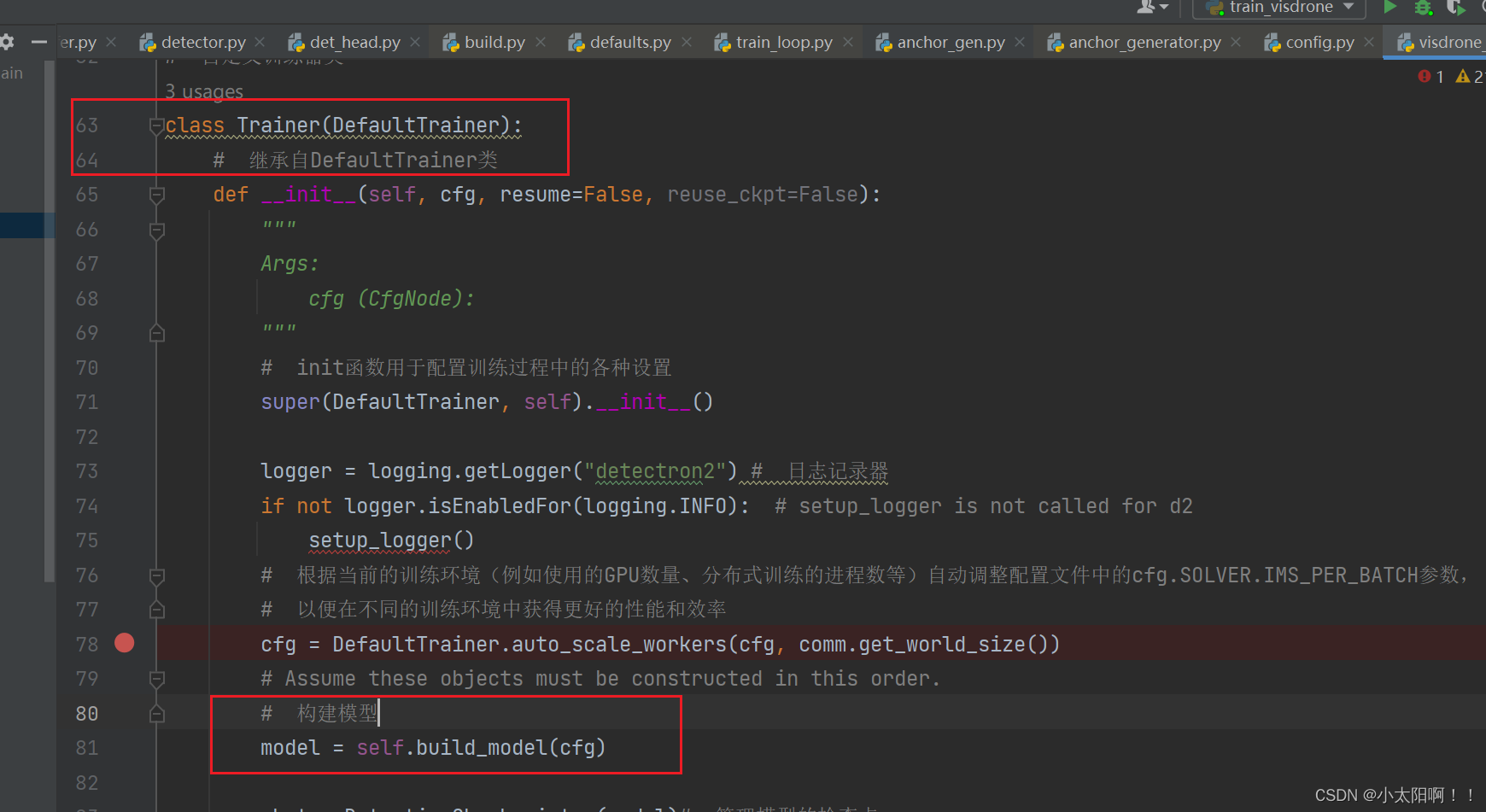
class Trainer(DefaultTrainer):
# 继承自DefaultTrainer类
def __init__(self, cfg, resume=False, reuse_ckpt=False):
"""
Args:
cfg (CfgNode):
"""
# init函数用于配置训练过程中的各种设置
super(DefaultTrainer, self).__init__()
logger = logging.getLogger("detectron2") # 日志记录器
if not logger.isEnabledFor(logging.INFO): # setup_logger is not called
for d2
setup_logger()
# 根据当前的训练环境(例如使用的GPU数量、分布式训练的进程数等)自动调整配置文件中的
cfg.SOLVER.IMS_PER_BATCH参数,
# 以便在不同的训练环境中获得更好的性能和效率
cfg = DefaultTrainer.auto_scale_workers(cfg, comm.get_world_size())
# Assume these objects must be constructed in this order.
# 构建模型
model = self.build_model(cfg)
ckpt = DetectionCheckpointer(model)# 管理模型的检查点
self.start_iter = 0
self.start_iter = ckpt.resume_or_load(cfg.MODEL.WEIGHTS,
resume=resume).get("iteration", -1) + 1
self.iter =self.start_iter
# 优化器
optimizer = self.build_optimizer(cfg, model)
# 数据加载器
data_loader = self.build_train_loader(cfg)
# For training, wrap with DDP. But don't need this for inference.
# 用于多Gpu或分布式训练
if comm.get_world_size() > 1:
model = DistributedDataParallel(
model, device_ids=[comm.get_local_rank()],
broadcast_buffers=False
)
# 根据参数cfg选择合适的训练器trainer
self._trainer = (AMPTrainer if cfg.SOLVER.AMP.ENABLED else
SimpleTrainer)(
model, data_loader, optimizer
)
# 构建学习率调度器
self.scheduler = self.build_lr_scheduler(cfg, optimizer)
# 管理检查点
self.checkpointer = DetectionCheckpointer(
model,
cfg.OUTPUT_DIR,
optimizer=optimizer,
scheduler=self.scheduler,
)
self.start_iter = 0
self.max_iter = cfg.SOLVER.MAX_ITER
self.cfg = cfg
self.register_hooks(self.build_hooks())
# 根据配置文件的设置决定是恢复训练(resume)还是重新开始训练
def resume_or_load(self, resume=True):
"""
If `resume==True` and `cfg.OUTPUT_DIR` contains the last checkpoint
(defined by
a `last_checkpoint` file), resume from the file. Resuming means loading
all
available states (eg. optimizer and scheduler) and update iteration
counter
from the checkpoint. ``cfg.MODEL.WEIGHTS`` will not be used.
Otherwise, this is considered as an independent training. The method will
load model
weights from the file `cfg.MODEL.WEIGHTS` (but will not load other
states) and start
from iteration 0.
Args:
resume (bool): whether to do resume or not
"""
checkpoint = self.checkpointer.resume_or_load(self.cfg.MODEL.WEIGHTS,
resume=resume)
print(self.cfg.MODEL.WEIGHTS)
exit()
if resume and self.checkpointer.has_checkpoint():
self.start_iter = checkpoint.get("iteration", -1) + 1
# The checkpoint stores the training iteration that just finished,
thus we start
# at the next iteration (or iter zero if there's no checkpoint).
if isinstance(self.model, DistributedDataParallel):
# broadcast loaded data/model from the first rank, because other
# machines may not have access to the checkpoint file
if TORCH_VERSION >= (1, 7):
self.model._sync_params_and_buffers()
self.start_iter = comm.all_gather(self.start_iter)[0]
# 用于构建评估器,在测试阶段用于评估模型性能
@classmethod
TrainerBase类
TrainerBase类是一个抽象类,提供了Hooks函数的注册和执行机制。它提供了一些基本的属性和方法,
以及一个训练循环的框架,但没有对数据加载器、优化器、模型等的存在做出任何假设。
TrainerBase中的train()函数
def build_evaluator(cls, cfg, dataset_name, output_folder=None):
if output_folder is None:
output_folder = os.path.join(cfg.OUTPUT_DIR, "inference")
evaluator_list = []
evaluator_list.append(JsonEvaluator(os.path.join(cfg.OUTPUT_DIR,
'visdrone_infer.json')))
if cfg.META_INFO.EVAL_GPU_TIME:
evaluator_list.append(GPUTimeEvaluator(True, 'minisecond'))
return DatasetEvaluators(evaluator_list)
# 构建训练数据加载器
@classmethod
def build_train_loader(cls, cfg):
return build_train_loader(cfg)
# 构建测试数据加载器
@classmethod
def build_test_loader(cls, cfg, dataset_name):
return build_test_loader(cfg)
# 用于执行测试过程
@classmethod
def test(cls, cfg, model, evaluators=None):
logger = logging.getLogger(__name__)
dataset_name = 'VisDrone2018'
data_loader = cls.build_test_loader(cfg, dataset_name)
evaluator = cls.build_evaluator(cfg, dataset_name)
result = inference_on_dataset(model, data_loader, evaluator)
return []TrainerBase类
TrainerBase
类是一个抽象类,提供了
Hooks
函数的注册和执行机制。它提供了一些基本的属性和方法,以及一个训练循环的框架,但没有对数据加载器、优化器、模型等的存在做出任何假设。

TrainerBase中的train()函数

此处使用的就是
TranerBase
类中的
train()
函数
实例化
Trainer
类时,在
init
函数中,按照:模型、优化器、数据加载器等过程进行初始化
构建模型
使用
detectron2
中封装的构建模型的方法
进入
build_model
函数
build_model函数
在
build_modle
函数中使用装饰器实现了
RetinaNetQueryDet
类的实例化。


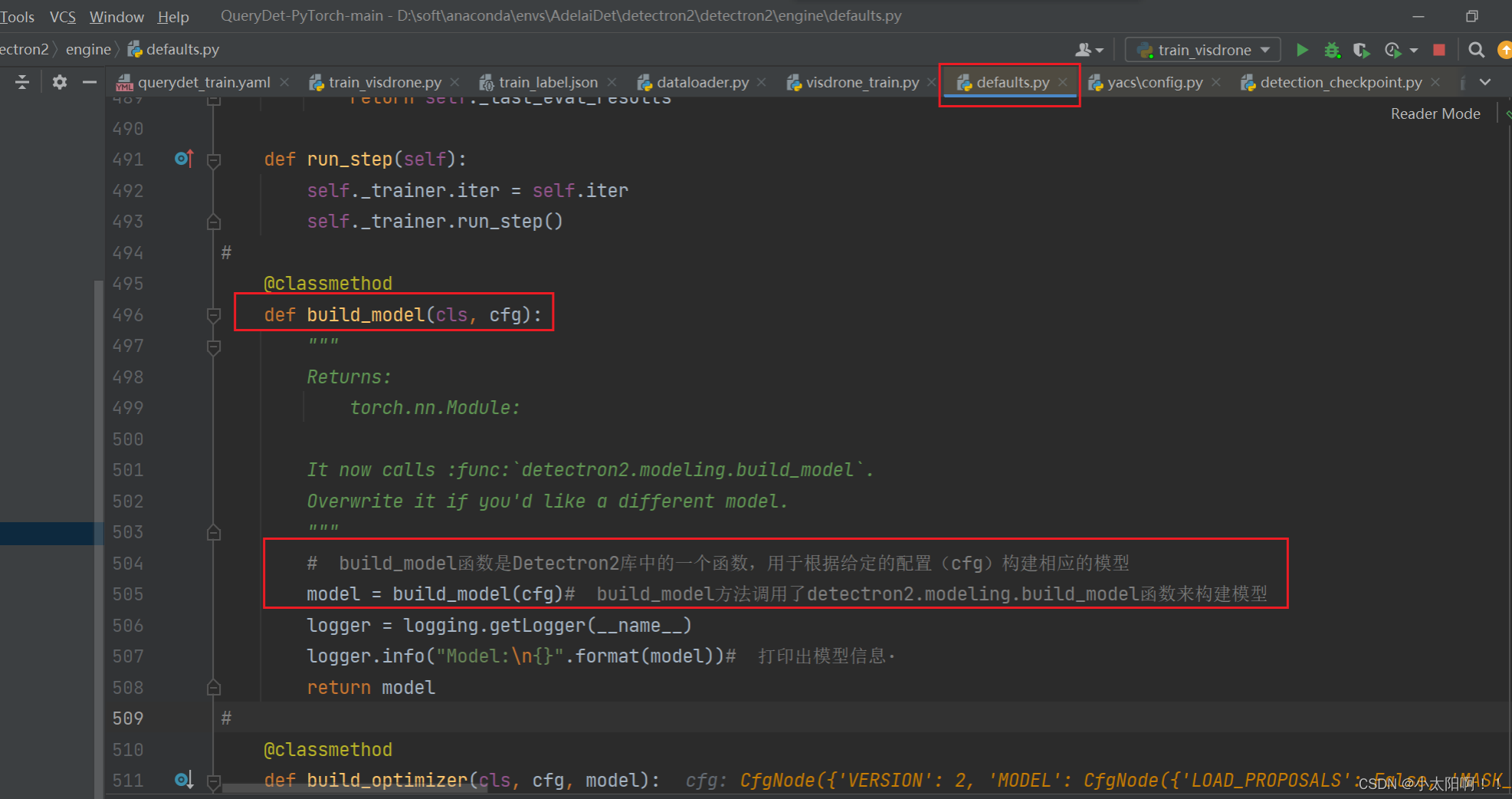
def build_model(cfg):
"""
Build the whole model architecture, defined by
``cfg.MODEL.META_ARCHITECTURE``.
Note that it does not load any weights from ``cfg``.
"""
# 从配置文件中获取参数MODEL.META_ARCHITECTURE,是定义模型架构的元模型(metaarchitecture)的名称,这里是Retina。
meta_arch = cfg.MODEL.META_ARCHITECTURE
model = META_ARCH_REGISTRY.get(meta_arch)(cfg)# 从元元模型注册表
(META_ARCH_REGISTRY)中获取对应的元模型类,并传入配置文件 cfg 来实例化模型对象。
model.to(torch.device(cfg.MODEL.DEVICE))# 将模型对象移动到配置文件中指定的设备
(cfg.MODEL.DEVICE)上,以便在该设备上进行训练和推理
_log_api_usage("modeling.meta_arch." + meta_arch)
return model# 从配置文件中获取参数MODEL.META_ARCHITECTURE,是定义模型架构的元模型(metaarchitecture)的名称,这里是Retina。
meta_arch = cfg.MODEL.META_ARCHITECTURE
model = META_ARCH_REGISTRY.get(meta_arch)(cfg)# 从元元模型注册表
(META_ARCH_REGISTRY)中获取对应的元模型类,并传入配置文件 cfg 来实例化模型对象。
这两行代码实际上就是调用了
RetinaNetQueryDet
类,并根据配置文件初始化了该类的实例,得到了模型对象 model

RetinaNetQueryDet类




上述都是在配置文件中得到的
。

初始化backbone
根据配置文件
cfg
构建和初始化一个特征提取网络(
backbone network
)。这个特征提取网络通常用于从输入数据中提取有用的特征表示,以供后续的任务或模型使用 。

通过注册表创建
backbone



RetinaNetQueryDet类继续初始化
构建网络的头部
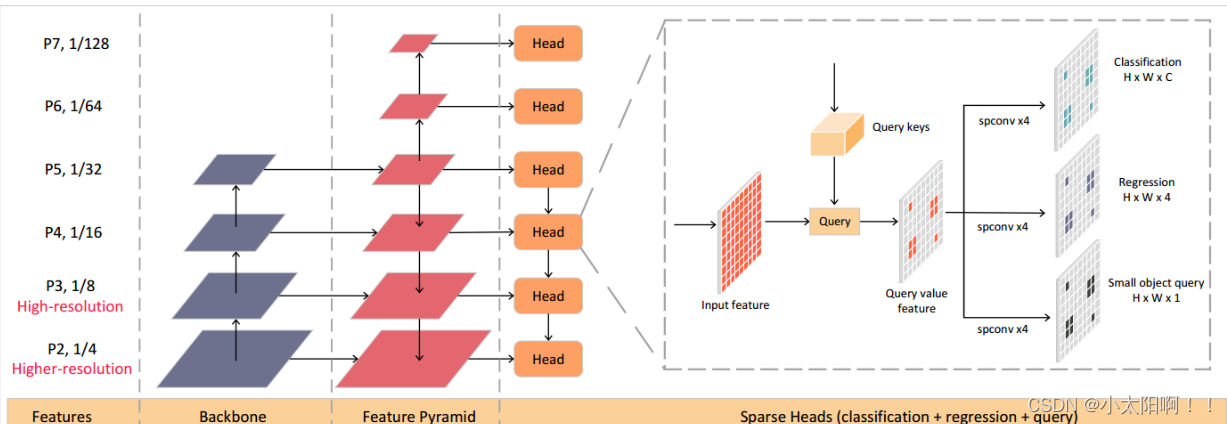

RetinaNeHead_3x3
类实现分类和回归头
# RetinaNet 检测器的头部部分,用于预测分类概率和边界框回归
class RetinaNetHead_3x3(nn.Module):
def __init__(self, cfg, in_channels, conv_channels, num_convs, num_anchors):
# 接收配置信息 cfg、输入通道数 in_channels、卷积通道数 conv_channels、卷积层数
num_convs 和锚点数量 num_anchors
super().__init__()
# fmt: off
num_classes = cfg.MODEL.RETINANET.NUM_CLASSES
prior_prob = cfg.MODEL.RETINANET.PRIOR_PROB
self.num_convs = num_convs
# fmt: on
self.cls_subnet = []
self.bbox_subnet = []
channels = in_channels
# 构建分类子网络和边界框子网络的卷积层,并将其添加到模型的子模块中
for i in range(self.num_convs):
cls_layer = nn.Conv2d(channels, conv_channels, kernel_size=3,
stride=1, padding=1)
bbox_layer = nn.Conv2d(channels, conv_channels, kernel_size=3,
stride=1, padding=1)
# 对这两个卷积层的权重进行正态分布的随机初始化,均值为 0,标准差为 0.01
torch.nn.init.normal_(cls_layer.weight, mean=0, std=0.01)
torch.nn.init.normal_(bbox_layer.weight, mean=0, std=0.01)
# 将这两个卷积层的偏置项初始化为常数 0
torch.nn.init.constant_(cls_layer.bias, 0)
torch.nn.init.constant_(bbox_layer.bias, 0)
self.add_module('cls_layer_{}'.format(i), cls_layer)
self.add_module('bbox_layer_{}'.format(i), bbox_layer)
# 将这两个卷积层分别添加到 self.cls_subnet 和 self.bbox_subnet 列表中,以
便后续在前向传播中使用
self.cls_subnet.append(cls_layer)
self.bbox_subnet.append(bbox_layer)
# 更新 channels 的值为 conv_channels,以便下一次迭代时作为下一层卷积的输入通
道数
channels = conv_channels
# 上面是分类和回归的子网络
# 定义分类得分和边界框预测的卷积层
# 卷积层的作用是生成每个锚框对应的类别得分。
self.cls_score = nn.Conv2d(channels, num_anchors * num_classes,
kernel_size=3, stride=1, padding=1)
# 卷积层用于生成每个锚框的边界框预测
self.bbox_pred = nn.Conv2d(channels, num_anchors * 4, kernel_size=3,
stride=1, padding=1)
# 对分类得分和边界框预测卷积层的权重进行初始化
torch.nn.init.normal_(self.cls_score.weight, mean=0, std=0.01)
torch.nn.init.normal_(self.bbox_pred.weight, mean=0, std=0.01)
# 对分类得分卷积层的偏置项进行初始化
bias_value = -(math.log((1 - prior_prob) / prior_prob))
torch.nn.init.constant_(self.cls_score.bias, bias_value)
def forward(self, features):
# 分别存储分类分数和边界框回归结果
logits = []
bbox_reg = []
# 循环遍历每个特征图
for feature in features:
# 初始化 cls_f 和 bbox_f,并将它们都设置为当前的特征图 feature
cls_f = feature
bbox_f = feature
# 对于num_convs次循环
for i in range(self.num_convs):
# 使用第 i 个卷积层对 cls_f 进行卷积操作,并使用 ReLU 激活函数进行非线性
变换
cls_f = F.relu(self.cls_subnet[i](cls_f))
# 使用第 i 个卷积层对 bbox_f 进行卷积操作,并使用 ReLU 激活函数进行非线性
变换
bbox_f = F.relu(self.bbox_subnet[i](bbox_f))
# 将结果添加到logits列表中
logits.append(self.cls_score(cls_f))
# 将结果添加到bbox_reg列表中
bbox_reg.append(self.bbox_pred(bbox_f))
# 返回分类分数列表 logits 和边界框回归结果列表 bbox_reg
return logits, bbox_reg
对输入的特征图列表
features
进行处理,并通过分类子网络
cls_score
和边界框回归子网络
bbox_pred
生成分类分数和边界框回归结果。这些结果将用于计算损失和进行推理过程。

查询头的设定
Head_3x3
类实现
# 通用的卷积头
class Head_3x3(nn.Module):
def __init__(self, in_channels, conv_channels, num_convs, pred_channels,
pred_prior=None):
super().__init__()
self.num_convs = num_convs
# 创建了一个列表 subnet 用于存储卷积层
self.subnet = []
# 初始化输入通道数 in_channels
channels = in_channels
# 通过循环创建了 num_convs 个卷积层,每个卷积层具有输入通道数 channels 和输出通道
数 conv_channels,
# 并对权重进行 Xavier 初始化,偏置项初始化为常数 0。
for i in range(self.num_convs):
layer = nn.Conv2d(channels, conv_channels, kernel_size=3, stride=1,
padding=1)
torch.nn.init.xavier_normal_(layer.weight)
torch.nn.init.constant_(layer.bias, 0)
# 将每个卷积层添加到模块中,并存储到 subnet 列表中
self.add_module('layer_{}'.format(i), layer)
self.subnet.append(layer)
# 同时更新输入通道数为 conv_channels
channels = conv_channels
# 创建一个最后的预测层 pred_net,该层具有输入通道数 channels 和输出通道数
pred_channels,
self.pred_net = nn.Conv2d(channels, pred_channels, kernel_size=3,
stride=1, padding=1)
# 并对权重进行 Xavier 初始化
torch.nn.init.xavier_normal_(self.pred_net.weight)
if pred_prior is not None:
bias_value = -(math.log((1 - prior_prob) / prior_prob))
torch.nn.init.constant_(self.pred_net.bias, bias_value)
else:
torch.nn.init.constant_(self.pred_net.bias, 0)
def forward(self, features):
# preds用于存储预测结果
preds = []
for feature in features:
# 对于每个特征图,初始化变量x为当前特征图
x = feature
#
for i in range(self.num_convs):
# 使用第 i 个卷积层对 x 进行卷积操作,并使用 ReLU 激活函数进行非线性变换
x = F.relu(self.subnet[i](x))
通过多个卷积层和一个最后的预测层对特征图进行处理,生成预测结果。这个类可以被用于不同的目标
检测任务,只需根据需要调整输入参数。
RetinaNetQueryDet类继续初始化
QueryInfer类
# 将经过卷积和激活函数的特征图 x 传入最后的预测层 pred_net,并将结果添加到
preds 列表中。
preds.append(self.pred_net(x))
return preds
通过多个卷积层和一个最后的预测层对特征图进行处理,生成预测结果。这个类可以被用于不同的目标检测任务,只需根据需要调整输入参数。

RetinaNetQueryDet类继续初始化

QueryInfer
类

_make_sparse_tensor()
用于生成稀疏张量,并返回相应的结果
# 根据查询的逻辑回归结果、上一层的稀疏坐标、当前层的锚框信息和特征值来生成稀疏张量
def _make_sparse_tensor(self, query_logits, last_ys, last_xs, anchors,
feature_value):
# 如果last_ys为None,则表示这是第一次生成稀疏张量
# 用于生成稀疏张量的坐标索引,需要根据阈值对query_logits进行筛选
if last_ys is None:
# 获取query_logits的尺寸信息,其中N表示批量大小,qh和qw表示特征图的高度和宽度
N, _, qh, qw = query_logits.size()
assert N == 1
# 通过对query_logits应用torch.sigmoid_函数并调用view(-1)将其转换为一维张量
prob = torch.sigmoid_(query_logits).view(-1)
# 使用torch.where函数找到大于阈值score_th的元素的索引,并存储在pidxs中,这里
大于阈值的索引是具有较高置信度的索引,也就是
# 存在物体的索引
pidxs = torch.where(prob > self.score_th)[0]# .float()
# 通过除法操作torch.div(pidxs, qw)和取余操作torch.remainder(pidxs, qw)计
算出相应的坐标索引y和x
y = torch.div(pidxs, qw).int()
x = torch.remainder(pidxs, qw).int()
else:
# 表示已经进行过一次稀疏张量生成,并且根据上一次的结果last_ys和last_xs来生成新
的坐标索引。
# 也就是说只有第一次才创建稀疏张量,后面的都是根据第一次的坐标更新得来的
# 通过对query_logits应用torch.sigmoid_函数并调用view(-1)将其转换为一维张量
prob = torch.sigmoid_(query_logits).view(-1)
# 使用prob > score_th得到一个布尔类型的张量pidxs,表示大于阈值的元素的位置
pidxs = prob > self.score_th
# 通过索引操作last_ys[pidxs]和last_xs[pidxs]获取相应的坐标索引y和x
y = last_ys[pidxs]
x = last_xs[pidxs]
# 表示没有符合条件的稀疏张量坐标,则返回None
if y.size(0) == 0:
return None, None, None, None, None, None
# fc表示通道数,fh 表示特征图的高度(height),fw 表示特征图的宽度(width)
_, fc, fh, fw = feature_value.shape
# 生成查询特征点的相邻位置,为了扩展目标检测的感受野范围
ys, xs = [], []
# 使用两层嵌套的循环,循环变量 i 和 j 遍历了 0 到 1 的取值范围
for i in range(2):
for j in range(2):
# 在每次循环中,将查询特征点的 y 坐标乘以 2(y * 2)加上 i,得到相邻位置的
y 坐标
ys.append(y * 2 + i)
# 将查询特征点的 x 坐标乘以 2(x * 2)加上 j,得到相邻位置的 x 坐标
xs.append(x * 2 + j)
# 列表 ys 和 xs 中存储了查询特征点的相邻位置的 y 坐标和 x 坐标
# 用于计算稀疏张量的索引
# 将列表 ys 中的所有相邻位置的 y 坐标在纵向(维度0)上进行拼接,得到一个一维张量
ys,其中存储了所有相邻位置的 y 坐标
ys = torch.cat(ys, dim=0)
# 将列表 xs 中的所有相邻位置的 x 坐标在纵向上进行拼接,得到一个一维张量 xs,其中存储
了所有相邻位置的 x 坐标
xs = torch.cat(xs, dim=0)
# 计算出每个相邻位置的索引值
inds = (ys * fw + xs).long()
sparse_ys = []
sparse_xs = []
# 用于生成稀疏张量的坐标偏移值
for i in range(-1*self.context, self.context+1):
for j in range(-1*self.context, self.context+1):
# 使用 ys + i 和 xs + j,将相邻位置的 y 坐标和 x 坐标与当前的偏移值进行
相加。
# 这样可以得到以当前位置为中心的一系列相邻位置的 y 坐标和 x 坐标
sparse_ys.append(ys+i)
sparse_xs.append(xs+j)
# 将这些偏移值连接起来,生成两个一维张量。
sparse_ys = torch.cat(sparse_ys, dim=0)
sparse_xs = torch.cat(sparse_xs, dim=0)
# 筛选出符合条件的稀疏张量坐标
# 得到一个布尔类型的张量 good_idx,其中对应位置上的元素为 True 表示该位置的坐标符合
筛选条件,为 False 则不符合
good_idx = (sparse_ys >= 0) & (sparse_ys < fh) & (sparse_xs >= 0) &
(sparse_xs < fw)
# 通过使用布尔索引,将 sparse_ys 和 sparse_xs 中对应 good_idx 为 True 的元素筛
选出来,
# 生成经过条件筛选后的稀疏张量的坐标 sparse_ys 和 sparse_xs。
sparse_ys = sparse_ys[good_idx]
sparse_xs = sparse_xs[good_idx]
# 通过 torch.stack 函数将 sparse_ys 和 sparse_xs 按列堆叠起来,
# 得到一个形状为 [2, num_coords] 的张量 sparse_yx,其中每一列代表一个坐标点的 y
和 x 值
sparse_yx = torch.stack((sparse_ys, sparse_xs), dim=0).t()
# torch.unique 函数对 sparse_yx 进行去重操作,保留不重复的坐标点
sparse_yx = torch.unique(sparse_yx, sorted=False, dim=0)
# 取 sparse_yx 张量的第一列,即稀疏张量的 y 坐标值
sparse_ys = sparse_yx[:, 0]
# 取 sparse_yx 张量的第二列,即稀疏张量的 x 坐标值
sparse_xs = sparse_yx[:, 1]
# 计算稀疏坐标在特征图上的索引值
sparse_inds = (sparse_ys * fw + sparse_xs).long()
# 使用稀疏张量的索引和特征值,创建稀疏张量对象 sparse_tensor
sparse_features = feature_value.view(fc, -1).transpose(0, 1)
[sparse_inds].view(-1, fc)
sparse_indices = torch.stack((torch.zeros_like(sparse_ys), sparse_ys,
sparse_xs), dim=-1)
sparse_tensor = spconv.SparseConvTensor(sparse_features,
sparse_indices.int(), (fh, fw), 1)
# 对输入的锚框张量进行处理,获取与稀疏张量相对应的锚框
anchors = anchors.tensor.view(-1, self.anchor_num, 4)
selected_anchors = anchors[inds].view(1, -1, 4)
# 返回稀疏张量、y 坐标、x 坐标、索引、选定的锚框以及稀疏张量的数量
_make_spconv函数
run_qinfer函数
return sparse_tensor, ys, xs, inds, selected_anchors,
sparse_indices.size(0)
_make_spconv
函数
def _make_spconv(self, weights, biases):
nets = []
# 通过weights的维度来创建多个稀疏卷积层
for i in range(len(weights)):
# 对于每个卷积层,它会根据权重张量的形状来确定输入通道数、输出通道数和卷积核大
小,并创建一个对应的稀疏卷积层对象
in_channel = weights[i].shape[1]
out_channel = weights[i].shape[0]
k_size = weights[i].shape[2]
# 创建一个对应的稀疏卷积对象
filter = spconv.SubMConv2d(in_channel, out_channel, k_size, 1,
padding=k_size//2, indice_key="asd",
algo=spconv.ConvAlgo.Native).to(device=weights[i].device)
# 将权重数据和偏置数据分别赋值给相应的稀疏卷积层对象的权重和偏置属性
# 使用了 permute 函数来调整权重张量的维度顺序,以适应稀疏卷积层的要求
filter.weight.data[:] = weights[i].permute(2,3,1,0).contiguous()[:]
# transpose(1,2).transpose(0,1).transpose(2,3).transpose(1,2).transpose(2,3)
filter.bias.data = biases[i]
nets.append(filter)
if i != len(weights) - 1:
nets.append(torch.nn.ReLU(inplace=True))
# 函数使用 spconv.SparseSequential 将创建的稀疏卷积层和激活函数组合成一个序列网
络,并返回该网络
return spconv.SparseSequential(*nets)
run_qinfer
函数
def run_qinfer(self, model_params, features_key, features_value,
anchors_value):
# 先检查模型是否已经初始化
if not self.initialized:
# 将提供的模型参数用于创建卷积和稀疏卷积层,并将模型标记为已初始化状态
cls_weights, cls_biases, bbox_weights, bbox_biases, qcls_weights,
qcls_biases = model_params
assert len(cls_weights) == len(qcls_weights)
self.n_conv = len(cls_weights)
self.cls_spconv = self._make_spconv(cls_weights, cls_biases) # 分
类任务的稀疏卷积网络
self.bbox_spconv = self._make_spconv(bbox_weights, bbox_biases) # 边
界框回归任务的稀疏卷积网络
self.qcls_spconv = self._make_spconv(qcls_weights, qcls_biases) #
查询分类任务的稀疏卷积网络
self.qcls_conv = self._make_conv(qcls_weights, qcls_biases) # 处
理查询分类任务的特征图
self.initialized = True
# 用于存储上一层的稀疏坐标
last_ys, last_xs = None, None
# 使用最后一层特征图 features_key[-1] 作为查询特征,通过卷积层 self.qcls_conv
进行卷积操作,
# 得到查询的逻辑回归结果query_logits,这里其实就是把最后一层特征图放入
self.qcls_conv卷积列表中进行卷积,从而得到query_logits
query_logits = self._run_convs(features_key[-1], self.qcls_conv)
RetinaNetQueryDet类继续初始化
# 定义存储分类结果、边界框结果和锚框信息的列表
det_cls_query, det_bbox_query, query_anchors = [], [], []
n_inds_all = []
# 从最后一层特征图开始,依次向前进行推理
for i in range(len(features_value)-1, -1, -1):
# 根据查询的逻辑回归结果、上一层的稀疏坐标、当前层的锚框信息和特征值,
# 生成稀疏张量x、更新的稀疏坐标 last_ys 和 last_xs,以及相关的索引信息,其实
得到的就是
# 原特征图上可能存在物体的像素点组成的张量
x, last_ys, last_xs, inds, selected_anchors, n_inds =
self._make_sparse_tensor(query_logits, last_ys, last_xs, anchors_value[i],
features_value[i])
n_inds_all.append(n_inds)
# 如果稀疏张量 x 为 None,表示已经没有满足条件的稀疏坐标,推理结束,跳出循环。
if x == None:
break
# 将稀疏张量经过分类稀疏卷积,表示在这些已经分好可能存在物体的特征图上进行分类、
边界框和查询,因为这里的查询还要给下一个使用
cls_result = self._run_spconvs(x, self.cls_spconv).view(-1,
self.anchor_num*self.num_classes)[inds]
# 经过边界框稀疏卷积,
bbox_result = self._run_spconvs(x, self.bbox_spconv).view(-1,
self.anchor_num*4)[inds]
# 经过查询分类稀疏卷积层,
query_logits = self._run_spconvs(x, self.qcls_spconv).view(-1)[inds]
# 上述得到分类结果、边界框结果和下一次查询的逻辑回归结果 query_logits
# 将选择的锚框、分类结果、边界框结果添加到列表中
query_anchors.append(selected_anchors)
det_cls_query.append(torch.unsqueeze(cls_result, 0))
det_bbox_query.append(torch.unsqueeze(bbox_result, 0))
# 获取最终的分类结果、边界框结果和锚框信息
return det_cls_query, det_bbox_query, query_anchorsRetinaNetQueryDet类继续初始化


生成anchor





RetinaNetQueryDet类继续初始化
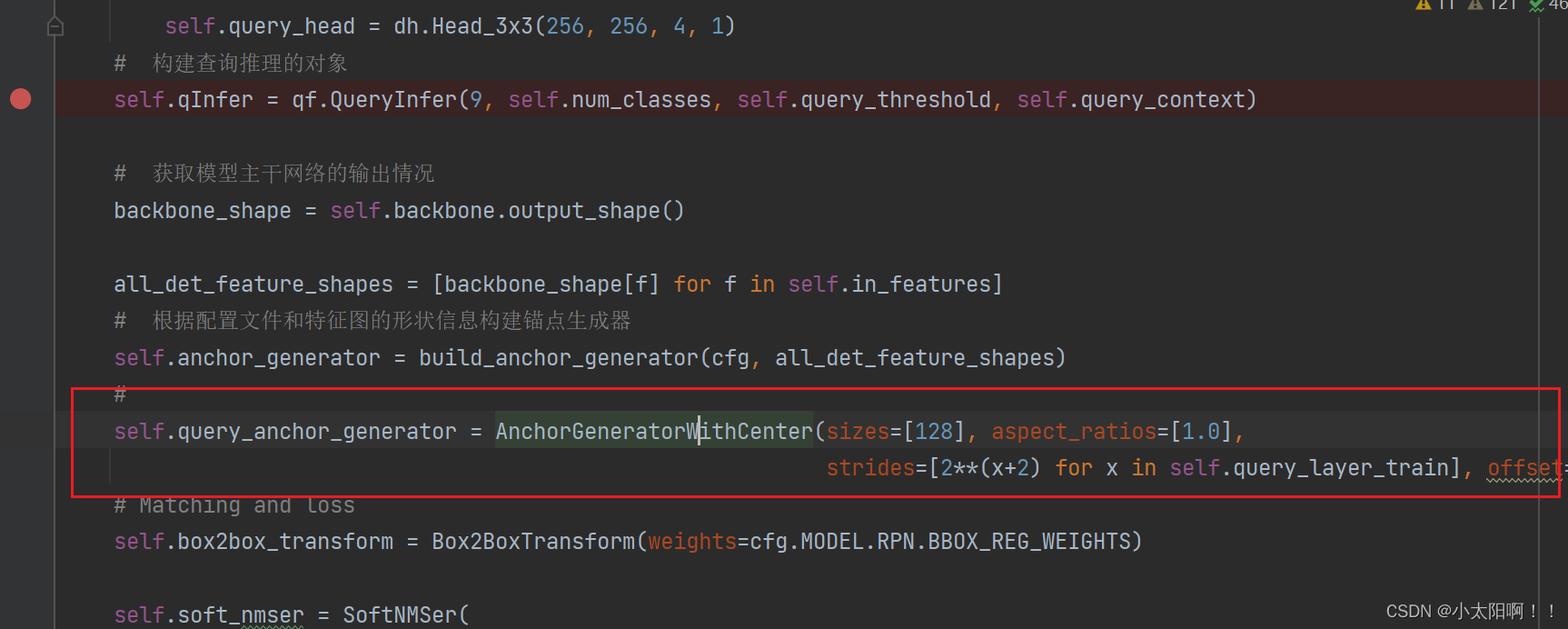
AnchorGenerator类
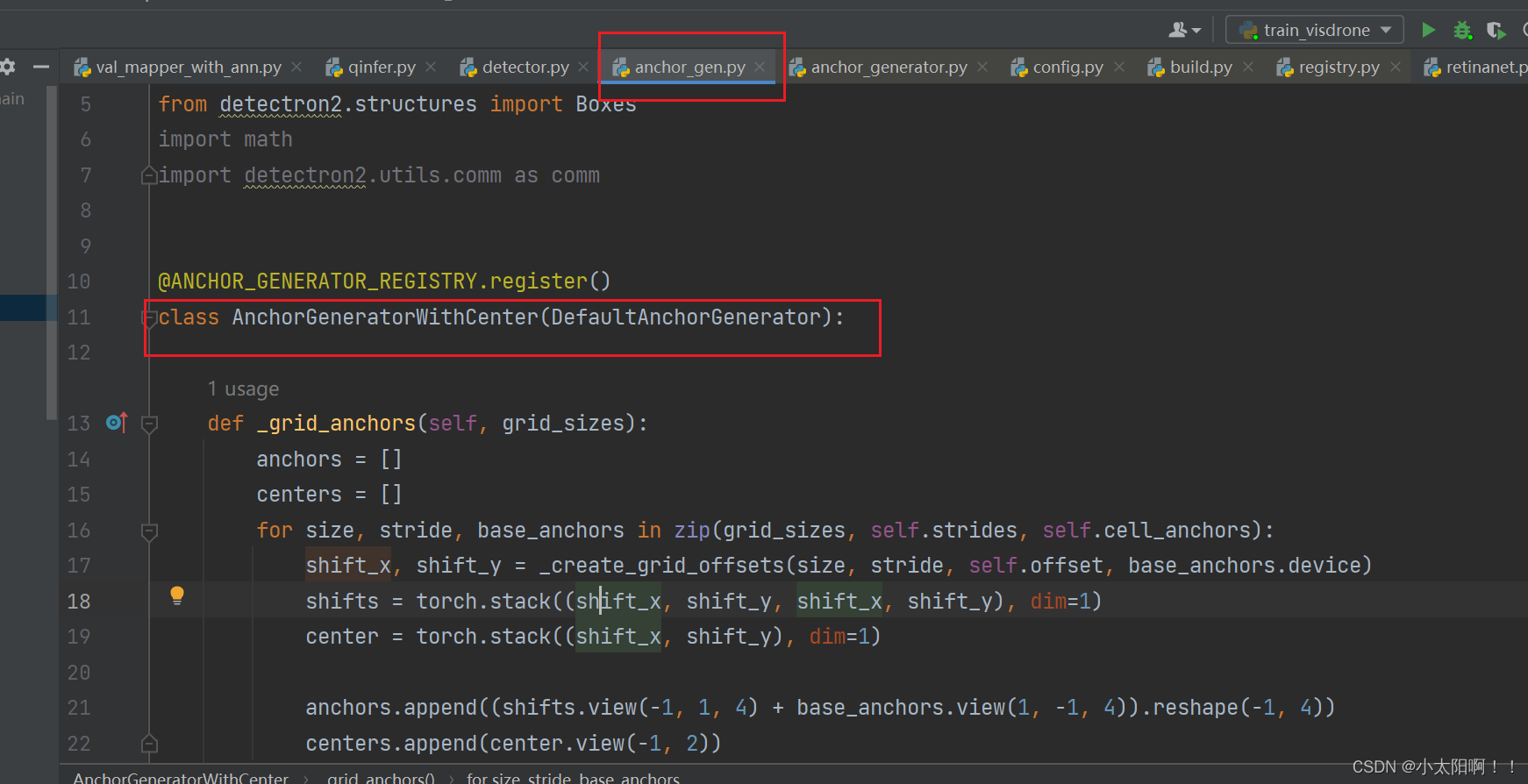
# 继承自DefaultAnchorGenerator类
@ANCHOR_GENERATOR_REGISTRY.register()
class AnchorGeneratorWithCenter(DefaultAnchorGenerator):
# 重写父类的_grid_anchors方法
def _grid_anchors(self, grid_sizes):
# grid_sizes是特征图尺寸列表
anchors = []
centers = []
# 根据特征图尺寸、步长和基础锚点生成偏移量和中心点
for size, stride, base_anchors in zip(grid_sizes, self.strides,
self.cell_anchors):
shift_x, shift_y = _create_grid_offsets(size, stride, self.offset,
base_anchors.device)
# # 生成的偏移量shifts是一个包含x和y偏移量的张量,用于根据基础锚点生成锚点
shifts = torch.stack((shift_x, shift_y, shift_x, shift_y), dim=1)
# 生成的中心点center是一个包含x和y坐标的张量,代表每个锚点的中心。
center = torch.stack((shift_x, shift_y), dim=1)
anchors.append((shifts.view(-1, 1, 4) + base_anchors.view(1, -1,
4)).reshape(-1, 4))
centers.append(center.view(-1, 2))
# 返回生成的锚点和中心点作为元组(anchors, centers)
return anchors, centers
# 接收一个特征图列表features作为输入
def forward(self, features):
grid_sizes = [feature_map.shape[-2:] for feature_map in features]
# 调用_grid_anchors方法生成锚点和中心点
anchors_over_all_feature_maps, centers_over_all_feature_maps =
self._grid_anchors(grid_sizes)
# 生成的锚点通过Boxes类封装为anchor_boxes列表
anchor_boxes = [Boxes(x) for x in anchors_over_all_feature_maps]
# 它返回锚点和中心点作为元组(anchor_boxes, centers_over_all_feature_maps)
return anchor_boxes, centers_over_all_feature_maps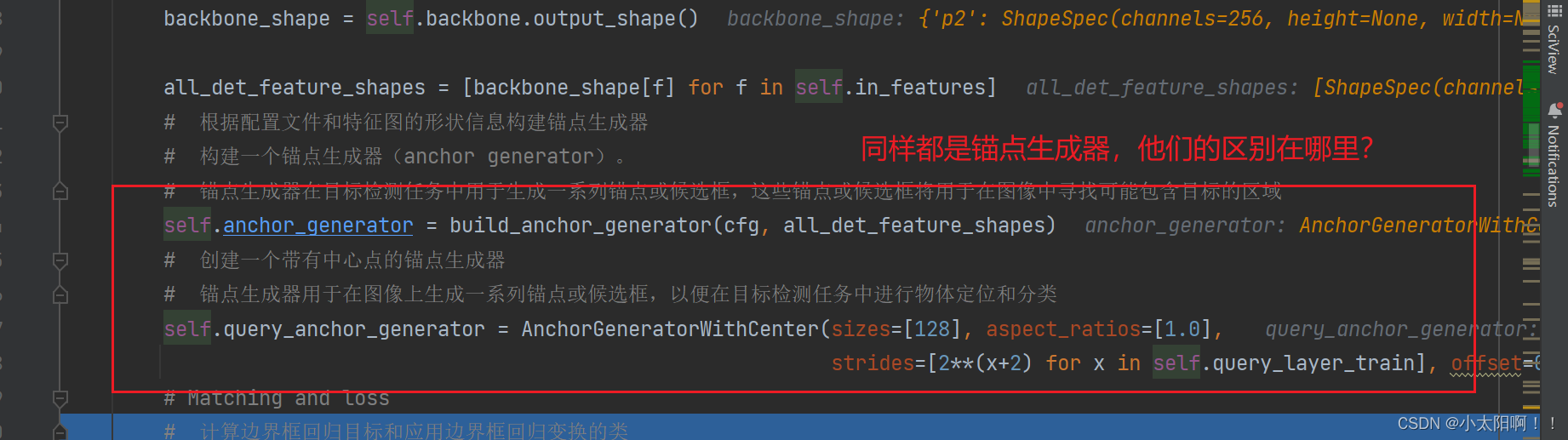
1.
self.anchor_generator = build_anchor_generator(cfg, all_det_feature_shapes)
:
这
行代码通过调用
build_anchor_generator
函数来创建一个通用的锚点生成器。函数
build_anchor_generator
接受两个参数:
cfg
和
all_det_feature_shapes
。
cfg
是一个配置
文件,用于指定锚点生成器的参数,而
all_det_feature_shapes
是用于生成锚点的特征图的形
状信息。这个函数根据参数配置和特征图形状来创建并返回一个锚点生成器对象,然后将其赋值给
self.anchor_generator
。
2.
self.query_anchor_generator = AnchorGeneratorWithCenter(sizes=[128],
aspect_ratios=[1.0], strides=[2**(x+2) for x in self.query_layer_train],
offset=0.5)
:
这行代码直接使用
AnchorGeneratorWithCenter
类创建了一个带有中心点的锚点
生成器。这个锚点生成器具体指定了生成锚点的一些属性:锚点的尺寸为
128x128
,宽高比为
1.0
,采样步长通过计算
self.query_layer_train
中的特征图索引得到,中心点偏移量为
0.5
。这
个锚点生成器被赋值给
self.query_anchor_generator
。
总结起来,区别在于第一句代码使用了一个通用的锚点生成器,其参数由 cfg 和
all_det_feature_shapes 指定;而第二句代码直接创建了一个特定属性的锚点生成器,它的尺寸、宽高比、步长和中心点偏移量都是直接指定的。
构建优化器
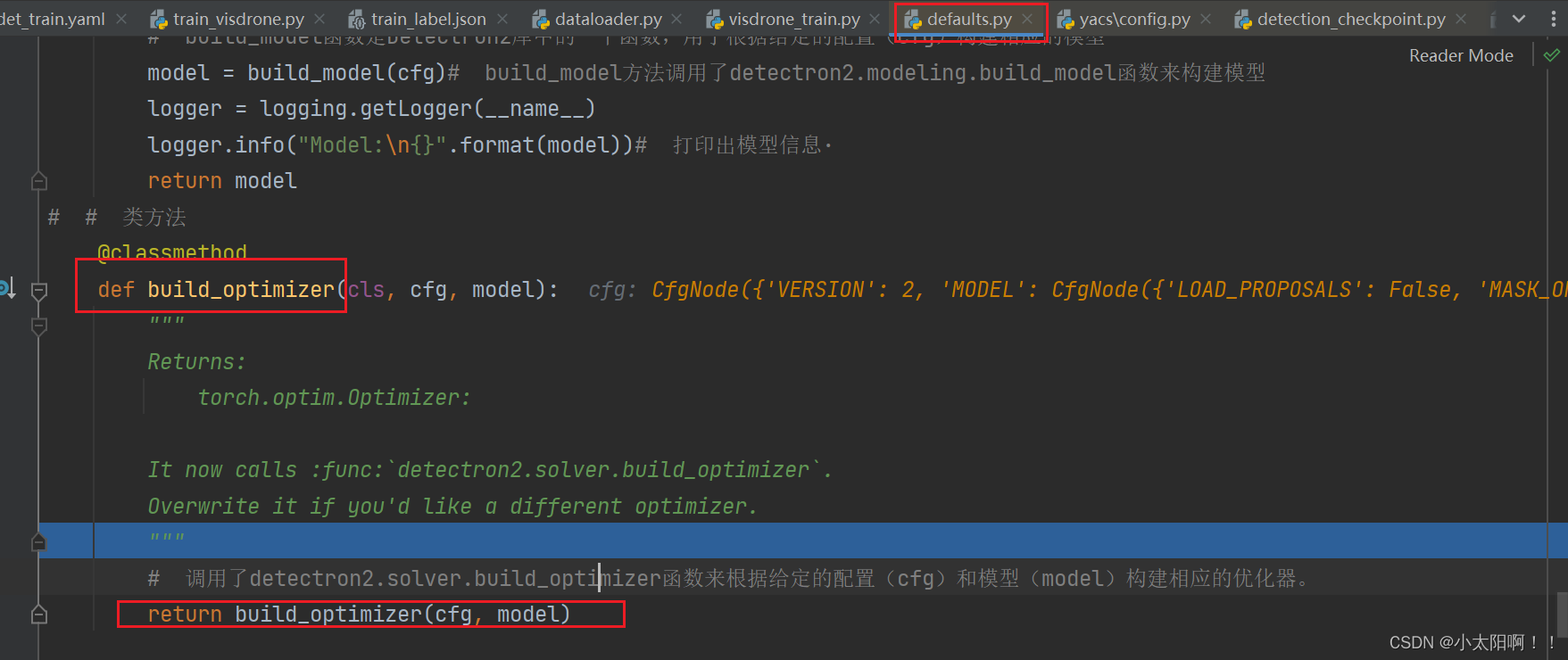
进入
build_optimizer
函数

构建数据加载器

训练

调用
trainer.train()
方法开始训练过程。在这个方法中,
Trainer
对象会根据配置和参数设置,加
载数据集、构建模型、设置优化器和学习率调度器等,并执行训练循环。训练循环包括多个迭代,每个迭代中模型会根据输入的数据进行前向传播和反向传播,并更新模型参数以最小化损失函数。在训练过程中,还会进行验证和日志记录等操作。最终,训练过程会返回训练的结果。具体返回的内容可以根据需要进行定义和修改。