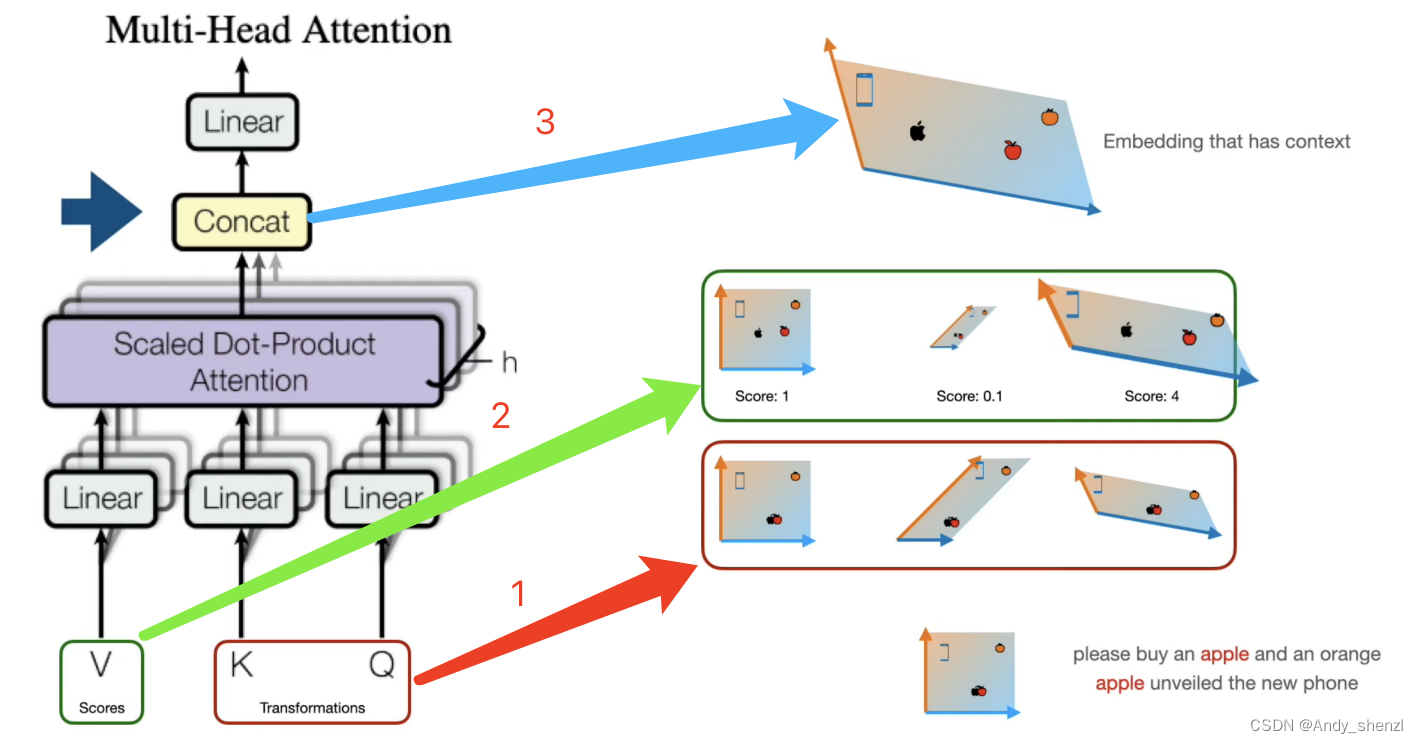
上篇文章给出了RNN-中文多分类的代码实现,本次主要是对RNN的架构进行一个详细的解析
1、主代码
class RNN(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_dim, output_dim, n_layers, bidirectional, dropout):
super().__init__()
# 初始化函数,接收模型参数作为输入。
# 调用父类 nn.Module 的 __init__ 方法。
self.embedding = nn.Embedding(vocab_size, embedding_dim)
# 创建一个嵌入层,用于将单词的索引转换为密集的向量表示。
self.rnn = nn.RNN(embedding_dim, hidden_dim, num_layers=n_layers, bidirectional=bidirectional, dropout=dropout, batch_first=True)
# 创建一个 LSTM 层,num_layers 指定层数,bidirectional 指定是否使用双向 LSTM,dropout 指定 dropout 比率,batch_first 指定输入数据的维度顺序。
self.fc = nn.Linear(hidden_dim * 2 if bidirectional else hidden_dim, output_dim)
# 创建一个全连接层,如果使用双向 LSTM,则输入维度是 hidden_dim * 2,否则是 hidden_dim。输出维度是 output_dim,即分类任务的类别数。
self.dropout = nn.Dropout(dropout)
# 创建一个 dropout 层,用于防止过拟合。
def forward(self, text):
# 定义前向传播函数。
embedded = self.dropout(self.embedding(text))
# 将输入文本通过嵌入层和 dropout 层。
output, hidden = self.rnn(embedded)
# 将嵌入后的文本输入到 LSTM 层,output 是所有时间步的输出,hidden 是最后一个时间步的隐藏状态,cell 是最后一个时间步的细胞状态。
if self.rnn.bidirectional:
# 如果使用双向 LSTM,则将最后一个时间步的前向和后向隐藏状态拼接起来。
hidden = self.dropout(torch.cat((hidden[-2,:,:], hidden[-1,:,:]), dim=1))
else:
# 如果使用单向 LSTM,则直接使用最后一个时间步的隐藏状态。
hidden = self.dropout(hidden[-1,:,:])
return self.fc(hidden)
# 将处理后的隐藏状态输入到全连接层,并返回输出。
# 创建 RNN 模型的实例。
代码中给出了非常详细的注释说明,所以这里主要看一下RNN代码的数据流,当然LSTM也是一样的,虽然其架构不一样,但是代码的写法几乎一致,只有返回结果LSTM多了个cell状态。
2、 解析
2.1 输入数据结构
我们先看下数据的输入结构
# 检查数据加载器
next(iter(train_loader))
[tensor([[ 1, 9222, 177, ..., 3, 9226, 2],
[ 1, 722, 3, ..., 0, 0, 0],
[ 1, 9047, 2233, ..., 1698, 143, 2],
...,
[ 1, 1398, 1277, ..., 0, 0, 0],
[ 1, 975, 7288, ..., 0, 0, 0],
[ 1, 4421, 3620, ..., 0, 0, 0]]),
tensor([6, 6, 3, 4, 2, 5, 9, 6, 0, 6, 8, 4, 4, 7, 7, 6, 6, 4, 8, 5, 9, 3, 0, 6,
5, 2, 6, 4, 4, 0, 2, 5, 6, 3, 1, 8, 8, 2, 8, 2, 4, 5, 4, 1, 1, 7, 4, 4,
9, 2, 4, 0, 9, 8, 6, 6, 4, 0, 5, 2, 7, 6, 5, 8])]
输出结果我们可以看到主要是X和Y两部分
我们看一下数据的结构
next(iter(train_loader))[0].shape, next(iter(train_loader))[1].shape
(torch.Size([64, 256]), torch.Size([64]))
64是我们设置的batch size,256是我们设置的最大长度,
也就是说,我们目前的一个数据流是有64个样本(记录),也就是有64条数据;每条数据都被填充或者截断为包含256个词组的数据。
这个是我们的输入
2.2 模型结构
接下来我们看下数据的梳理过程
主要是模型的主代码,我们为了能够看清楚数据是如何一步一步进行处理的,我们把代码修改下,打印每个过程的数据结构。
def __init__(self, vocab_size, embedding_dim, hidden_dim, output_dim, n_layers, bidirectional, dropout):
super().__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim)
print("self.embedding: ",self.embedding)
self.rnn = nn.RNN(embedding_dim, hidden_dim, num_layers=n_layers, bidirectional=bidirectional, dropout=dropout, batch_first=True)
print("self.rnn: ",self.rnn)
self.fc = nn.Linear(hidden_dim * 2 if bidirectional else hidden_dim, output_dim)
print("self.fc: ",self.fc)
self.dropout = nn.Dropout(dropout)
self.embedding: Embedding(9592, 100)
self.rnn: RNN(100, 256, num_layers=2, batch_first=True, dropout=0.5)
self.fc: Linear(in_features=256, out_features=10, bias=True)
-
__init__函数的第一个定义是embedding,nn.Embedding是创建一个嵌入层,用于将单词的索引转换为密集的向量表示,我们在前面的代码中创建了一个单词表vocab,其长度是
len(vocab.stoi) = 9592;也就是我们一共有9592个词组,想在我们需要将每一个词组转换为一个向量,因为在vocab中只是为了创建一个字典,并记录每一个词组的index,现在我们需要将所有的词组转化为向量,每个词组都转化为embedding_dim大小的向量。创建好之后,后面就是在每次计算时,根据每条记录中包含词组的索引在self.embedding 中查找他的响亮表示,就是在9592个字典中,查找当前记录中256个词组相应的向量表示。比如下面我们把第一条记录的256个词组的索引打印出来,就是将打印中list全部的index,在self.embedding 中查找到其对应的向量表示并返回,有点类似于excel的vlookup。最终返回的就是256 * 100的向量矩阵了(我们假设embedding_dim = 100)print(vocab.numericalize(data[“segmented_text”][0])),
[1153, 238, 180, 206, 4659, 42, 607, 5, 6, 7, 1363, 8238, 201, 13, 77, 3, 180, 2718, 3, 8, 12, 238, 215, 296, 602, 3, 3, 3, 3590, 3, 223, 9, 3, 1221, 3, 11, 180, 3, 1067, 2687, 3235, 3, 65, 18, 439, 602, 1555, 3, 5097, 3, 42, 607, 5, 8, 6, 7, 2393, 1213, 3, 455, 710, 4, 10, 238, 8, 12, 1518, 93, 190, 5014, 181, 627, 4, 10, 602, 1757, 3, 554, 939, 932, 1526, 248, 300, 3, 185, 4, 227, 3, 745, 523, 761, 30, 3, 698, 4404, 5774, 4, 10, 46, 1162, 1674, 613, 5097, 223, 2824, 2215, 2095, 731, 181, 2762, 45, 715, 721, 4, 613, 45, 227, 4, 3224, 3, 8, 3, 3, 3, 775, 238, 180, 223, 5, 6, 7, 3127, 5961, 3401, 3401, 1999, 2591, 696, 3, 5069, 3, 2687, 3, 3348, 4, 206, 3, 813, 3, 3, 3529, 5711, 3, 5, 6, 7, 3, 9, 6726, 3, 100, 3560, 10, 2215, 181, 3, 100, 5, 6, 7, 5569, 42, 607, 30, 9, 3, 4757, 5997, 42, 2687, 3, 256, 898, 940, 4268, 5, 6, 7, 3, 4397, 3, 2690, 3, 3, 174, 11, 3, 9, 6566, 12, 511, 278, 132, 8, 11, 296, 181, 1358, 9, 3, 590, 8, 9, 590, 10, 2687, 6810, 45, 483, 6, 9, 81, 1449, 523, 761, 10, 2591, 5099, 8, 3, 3, 3759, 4139, 8707, 3, 30, 8, 1651, 81, 5770, 3783, 7974, 3, 3, 315, 1436, 8137, 3, 824, 81, 872, 715, 721, 2215, 3, 1555, 6088, 170, 529, 824, 1194, 7335, 3, 6812, 81, 18, 304, 2572, 2441, 2628, 1949, 2628, 3, 3, 30, 8, 11, 3, 3, 3, 3, 3, 394, 2690, 1926, 3, 2095, 5617, 877, 3, 2112, 100, 3, 4318, 2531, 174, 590, 4346, 11, 3, 9, 6566, 8183, 12, 3, 278, 132, 3] -
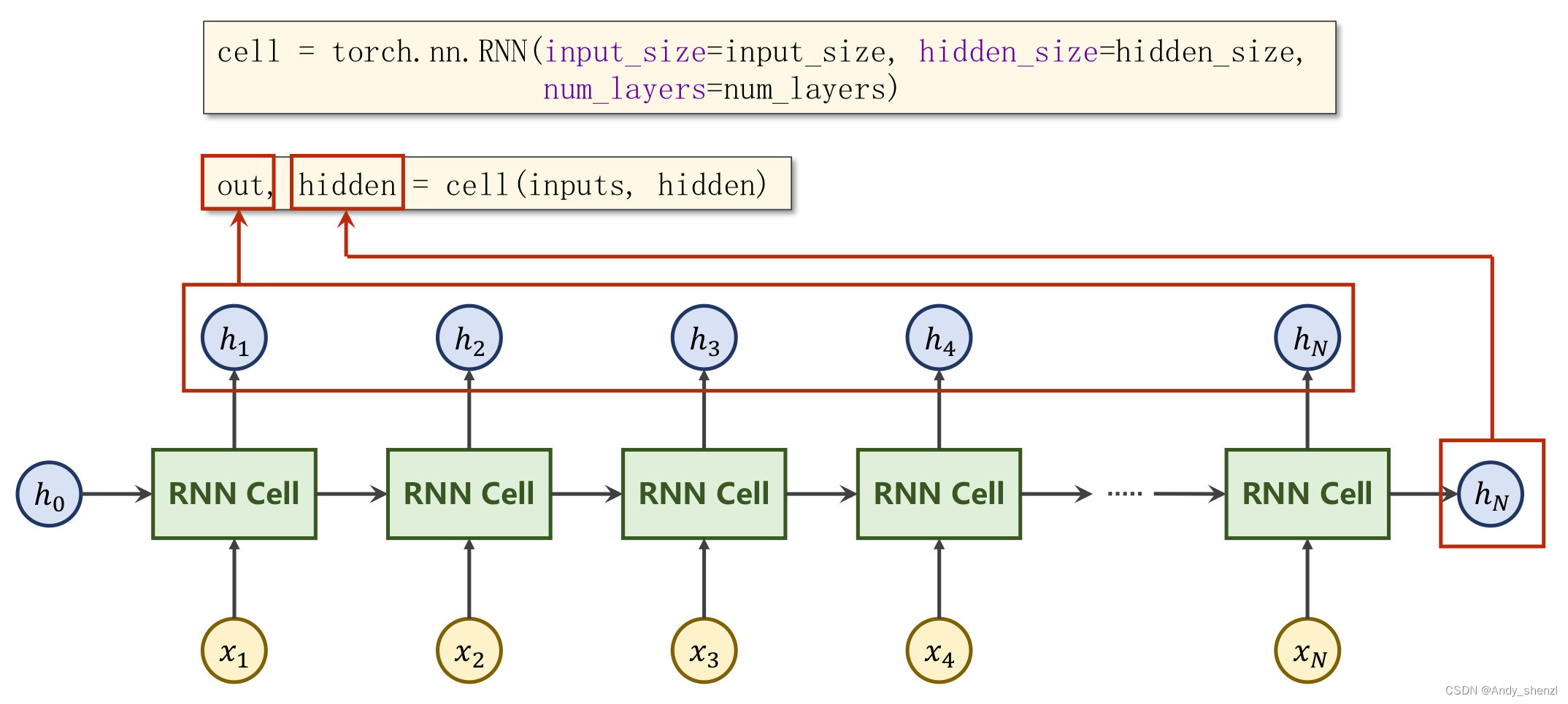
self.rnn,是定义RNN网络的主体架构,其输入参数有embedding_dim, hidden_dim, num_layers=n_layers, bidirectional=bidirectional, dropout=dropout, batch_first=True;embedding_dim就是每个词组的向量维度,hidden_dim是隐藏层的神经元个数,num_layers是隐藏层的层数,这是与之前DNN类似的结构不过多阐述;bidirectional指定是否使用双向 RNN,这个就是指RNN不仅可以从前往后循环还可以支持同时从后向前循环,这样更能全面的结合上下文的信息,如果bidirectional为True,那么就是双向的,此时网络隐藏层的神经元就要*2,因为从前往后+从后往前,等于是翻倍了;batch_first是指RNN输入数据的第一位维度是不是batch_size,我们可以看到我们的输入数据形状是batch_size * max_length,所以我们设置batch_first=True;

-
self.fc,就是线性层,我们根据是否是双向的RNN,来确定线性层的输入是256还是256*2 ,输出是我们标签的个数,我们这里有10类,所以输出就是10.
def forward(self, text):
print(self.embedding(text).shape)
embedded = self.dropout(self.embedding(text))
print("embedded: ",embedded)
output, hidden = self.rnn(embedded)
print("output: ",output.shape)
print("hidden: ",hidden.shape)
if self.rnn.bidirectional:
hidden = self.dropout(torch.cat((hidden[-2,:,:], hidden[-1,:,:]), dim=1))
else:
hidden = self.dropout(hidden[-1,:,:])
print(hidden.shape)
return self.fc(hidden)
同样forward也进行打印输出来查看数据结构
-
embedded:torch.Size([64, 256, 100]),因为embedded = self.dropout(self.embedding(text)),dropout不改变数据结构,所以可以忽略,self.embedding(text)其实就是self.embedding的vocab_size, embedding_dim 与text的 batch_size * max_length 结合,max_length个词组,在vocab_size里面进行匹配得到的结果还是max_length个向量,每个向量是embedding_dim维,一个数据流有batch_size个,最后的结果就是batch_size * max_length * embedding_dim
-
output, hidden:self.rnn(embedded),就是将embedded结果进行深度学习的隐藏层传递训练权重,
[batch_size * max_length * embedding_dim]*[embedding_dim, hidden_dim],我们看一下output, hidden输出的数据结构,output: torch.Size([64, 256, 256]),hidden: torch.Size([2, 64, 256]),output里面有两个256,第一个是max_length,第二个是hidden_dim;hidden里面的256也是hidden_dim;- output的输出结果torch.Size([64, 256, 256]),64, 256其实就是跟输入一致的,batch_size * max_length,最后的256是隐藏层的神经元个数
- hidden输出结果是torch.Size([2, 64, 256]),n_layers * batch_size * hidden_dim
-
最后是,self.fc(hidden),用线性层将数据结果转化为output_dim,也就是标签的个数。
以上就是关于RNN的一些解读。。。