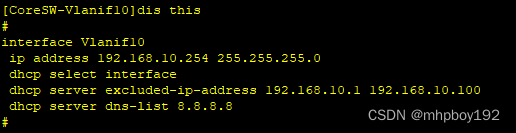
1. 在本节的估计问题中使用λ的值进行实验。绘制训练和测试精度关于λ的函数。观察到了什么?
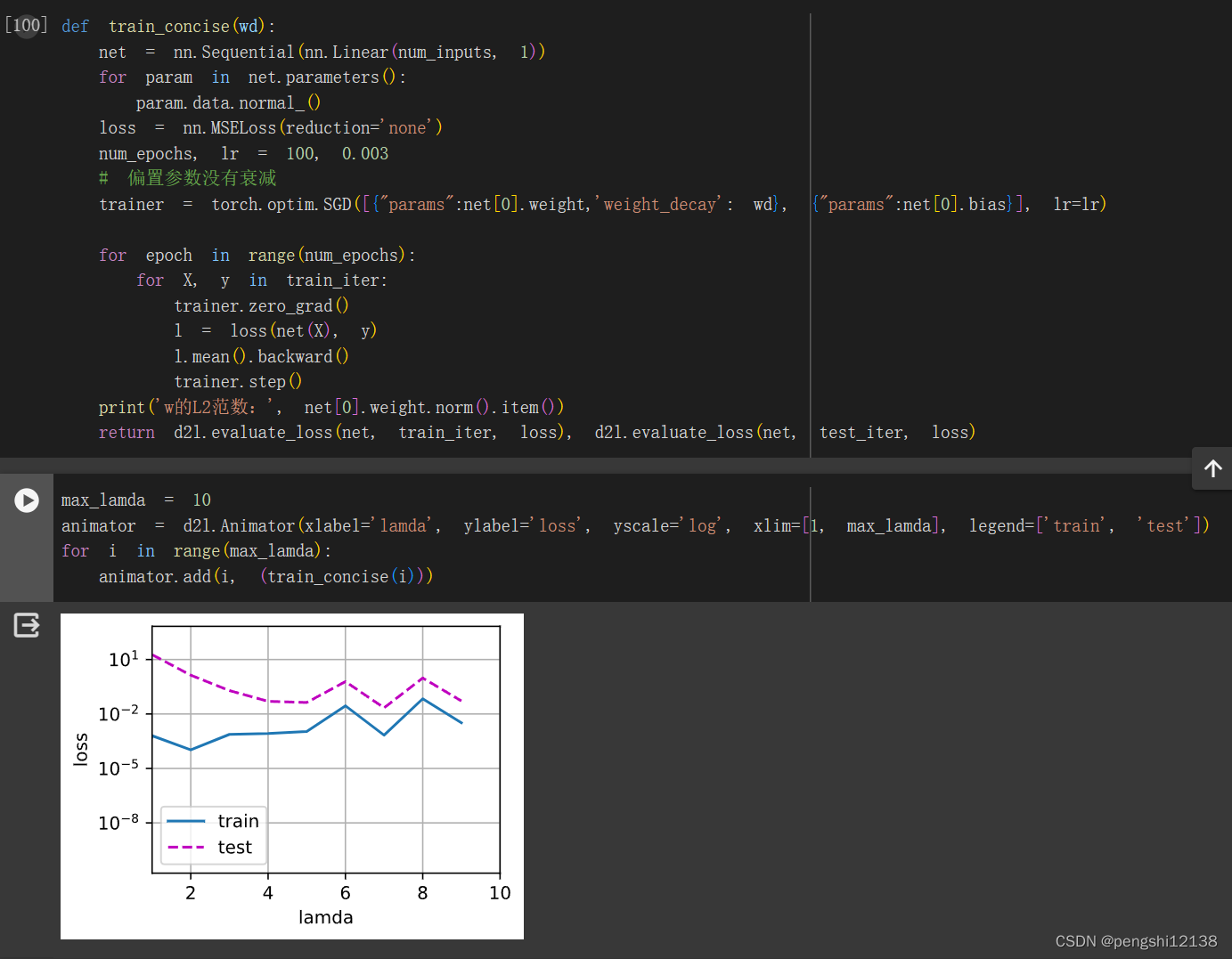
修改代码运行如图所示,可以发现对于lamda值的变化而言,对于训练loss和测试loss的影响不大。但是如果λ 太大后,train和test的loss会变得很大,太小后,train的loss会低,但是test的loss会很高。
2. 使用验证集来找到最佳值λ。它真的是最优值吗?这有关系吗?
不是,因为验证集上数据与其他数据集的数据可能不同,lamda只是对于验证数据集的最优值,而不是泛化情况下的最优值。关系上,只是划分数据降低超参数之间的影响,实现事件发生的独立而已,能够提高模型泛化能力。
3. 解答
L ( w , b ) = 1 n ∑ i = 1 n 1 2 ( w T x ( i ) + b − y i ) 2 + λ 2 ∣ w ∣ δ ∑ i ∣ w i ∣ δ ∣ w i ∣ = s g n ( w i ) w ← w − η λ s g n ( w i ) − η ∣ B ∣ ∑ i ∈ B x ( i ) ( w T x ( i ) + b − y ( i ) ) \begin{split} L(w, b)&=\frac{1}{n}\sum_{i=1}^{n} \frac{1}{2}(w^{T}x^{(i)} +b-y^{i})^{2}+\frac{\lambda }{2}|w|\\ \frac{\delta\textstyle \sum_{i}^{}|w_{i}| }{\delta|w_{i}|} &= sgn(w_{i})\\ w& \gets w-\eta \lambda sgn(w_{i}) - \frac{\eta}{|\mathrm{B}|}\sum_{i\in \mathrm{B}}x^{(i)}(w^{T}x^{(i)}+b-y^{(i)}) \end{split} L(w,b)δ∣wi∣δ∑i∣wi∣w=n1i=1∑n21(wTx(i)+b−yi)2+2λ∣w∣=sgn(wi)←w−ηλsgn(wi)−∣B∣ηi∈B∑x(i)(wTx(i)+b−y(i))
4. 解答
Frobenius 本质上就是 ||w||2
5. 解答
dropout层处理过拟合问题
6. 解答