🤵♂️ 个人主页:@艾派森的个人主页
✍🏻作者简介:Python学习者
🐋 希望大家多多支持,我们一起进步!😄
如果文章对你有帮助的话,
欢迎评论 💬点赞👍🏻 收藏 📂加关注+
目录
1.项目背景
2.数据集介绍
3.技术工具
4.实验过程
4.1导入数据
4.2数据预处理
4.3探索性分析
4.4特征工程
4.5构建模型
1.项目背景
评估航空公司的运输量和运输需求。因此,对航空公司 RPM 的时间序列预测具有重要的商业意义,可以帮助航空公司进行运输规划、航班安排和市场营销决策。
在航空业中,因素如季节性、节假日、燃油价格、宏观经济状况等都会对乘客需求产生影响,这些影响因素使得航空公司 RPM 的时间序列数据呈现出一定的复杂性和波动性。为了更准确地预测航空公司 RPM,传统的统计方法往往无法很好地处理这些复杂的时间序列特征,因此需要更加先进和灵活的预测模型。
ARIMA (AutoRegressive Integrated Moving Average) 模型是一种经典的时间序列分析方法,可以用于捕捉时间序列数据的自相关和趋势性。SARIMA (Seasonal AutoRegressive Integrated Moving Average) 则是在 ARIMA 模型基础上加入季节性因素的模型,能够更好地处理具有季节性变动的时间序列数据。
基于ARIMA+SARIMA的航空公司 RPM 时间序列预测模型,将结合ARIMA和SARIMA模型的优势,综合考虑航空公司 RPM 时间序列数据的趋势性和季节性变动,从而提高预测的准确性和可靠性。这种模型可以帮助航空公司更好地了解和预测未来乘客需求,有助于他们进行合理的运输资源配置和市场策略制定。
2.数据集介绍
数据集来源于Kaggle,原始数据集共有249条,17个变量。
关于此文件
2003 年 1 月至 2023 年 9 月美国所有商业航空公司的非季节性调整每月航空交通数据。
注:
收入乘客里程 = 乘客数量和飞行距离,以千 (000) 为单位
可用座位里程 = 座位数和飞行距离,以千 (000) 为单位
负载系数 = 乘客里程占可用座位的比例- 英里数百分比 (%)
3.技术工具
Python版本:3.9
代码编辑器:jupyter notebook
4.实验过程
4.1导入数据
导入第三方库并加载数据集
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
import seaborn as sns
import numpy as np
import statsmodels.api as sm
import warnings
warnings.filterwarnings("ignore")
df= pd.read_csv('air traffic.csv')
df.head()
查看数据大小

查看数据基本信息
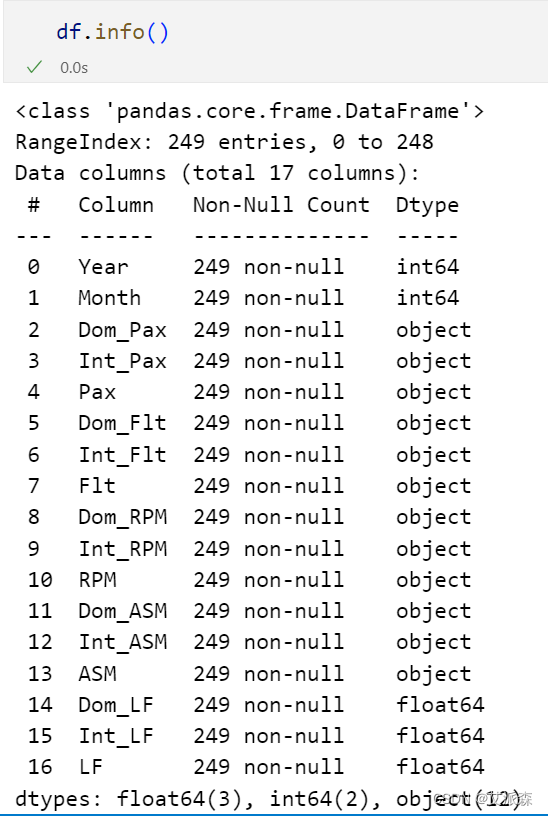
4.2数据预处理
将非数值型变量转换为数值型变量
# 数据类型转换
for col in df.columns:
if df[col].dtype == 'object':
df[col] = pd.to_numeric(df[col].str.replace(',', ''), errors='coerce')
df.info()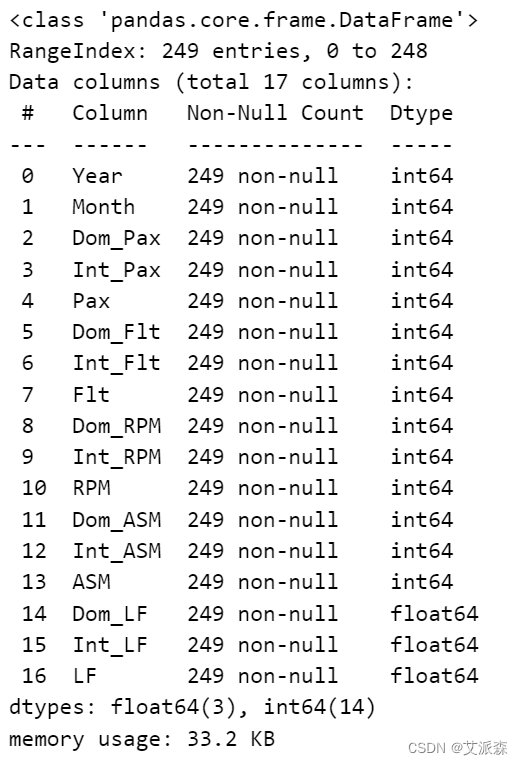
# 由于我们正在做时间序列预测,现在让我们处理月份和年份列
# 这里我们将合并月份和年份,同时将日期设置为每月的第一天
df['Date'] = pd.to_datetime({'year': df['Year'], 'month': df['Month'], 'day': 1})
# 我们把日期设为索引
df.set_index('Date')
4.3探索性分析
# 让我们看看所有变量相对于日期的趋势
all_columns = [col for col in df.columns if col != 'Date']
for column in all_columns:
plt.figure(figsize=(10, 4))
sns.lineplot(data=df, x='Date', y=column)
plt.title(column)
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()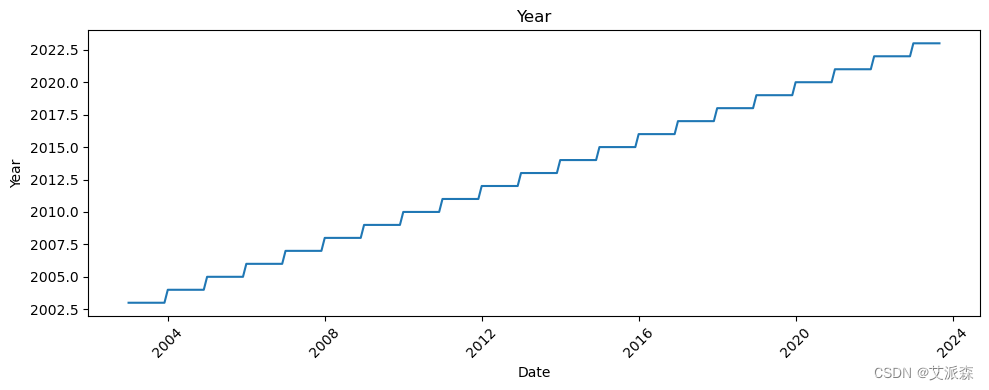
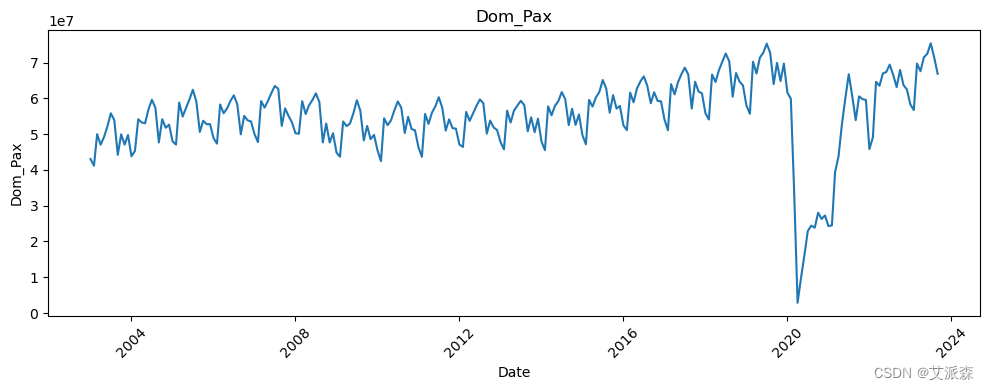
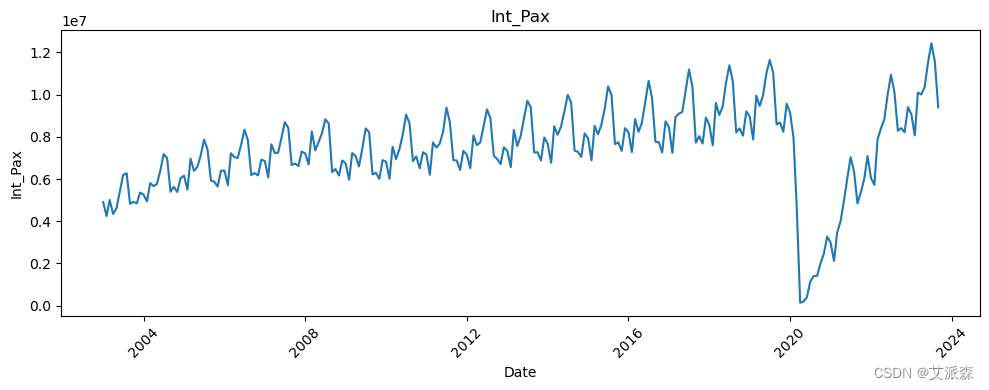
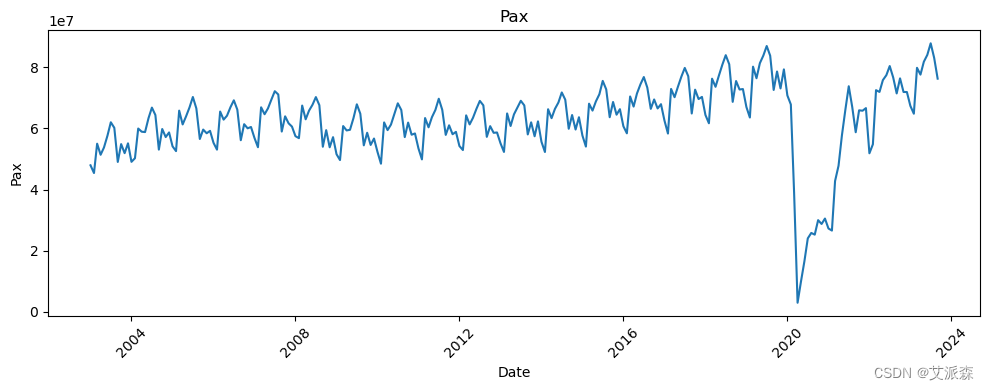
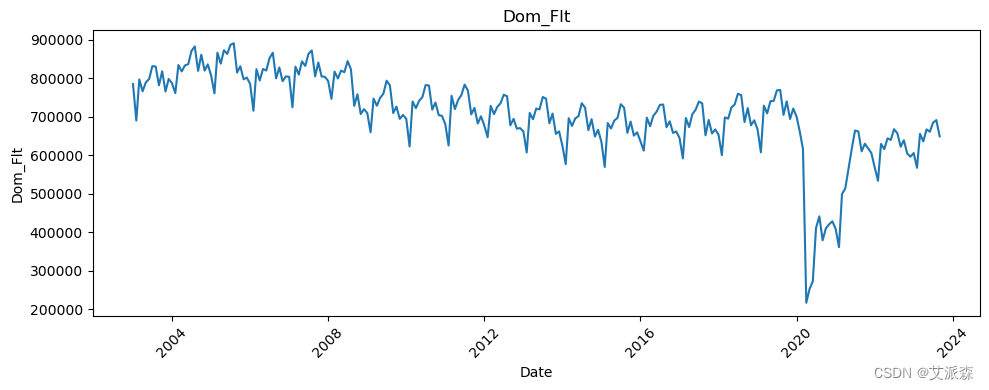
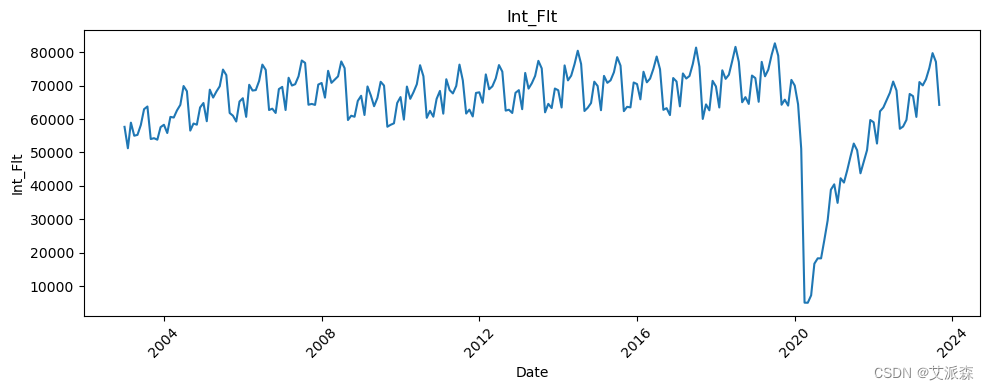
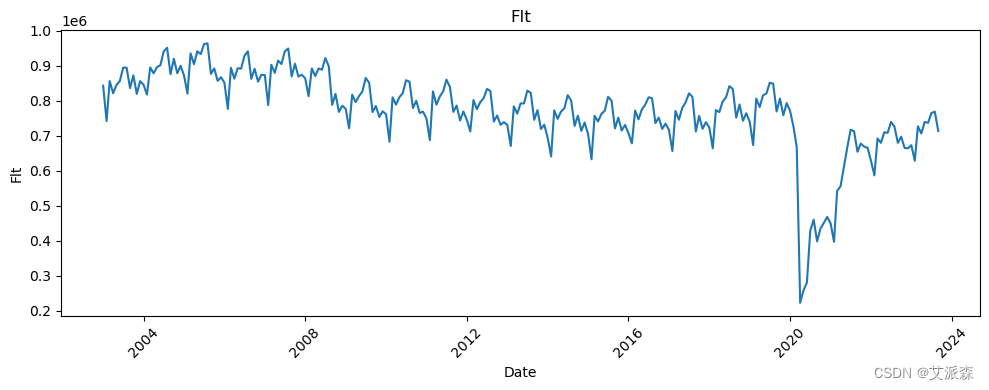
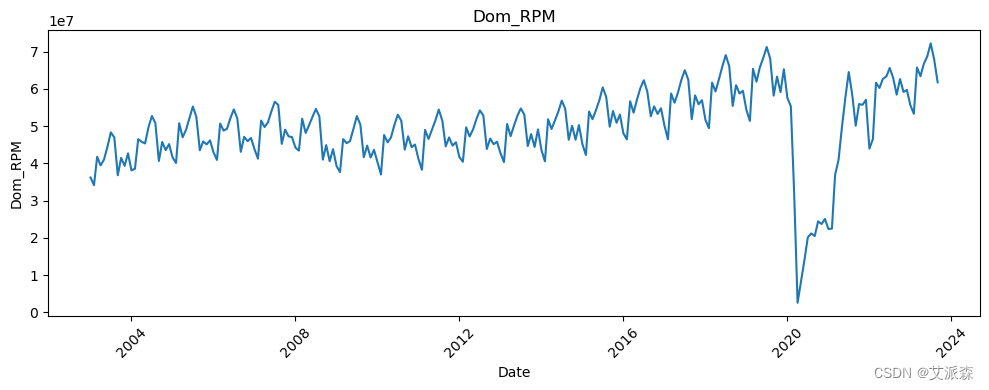
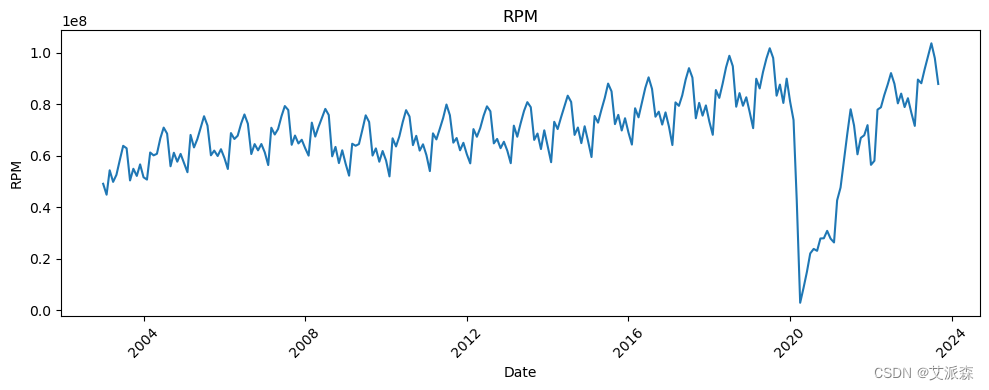
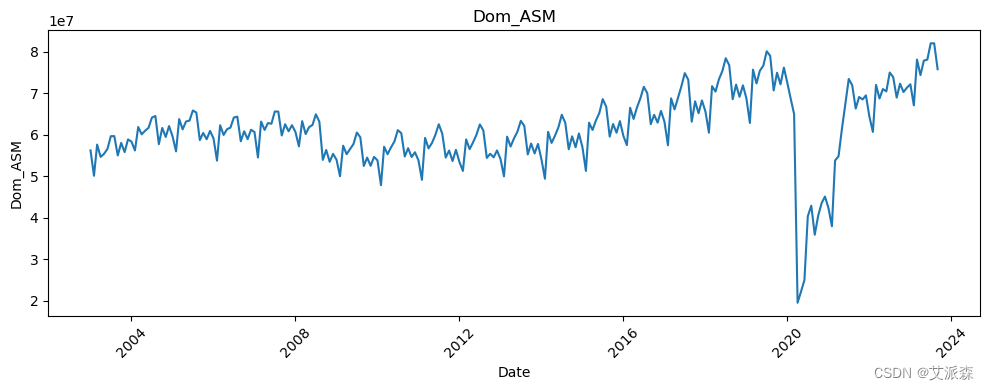
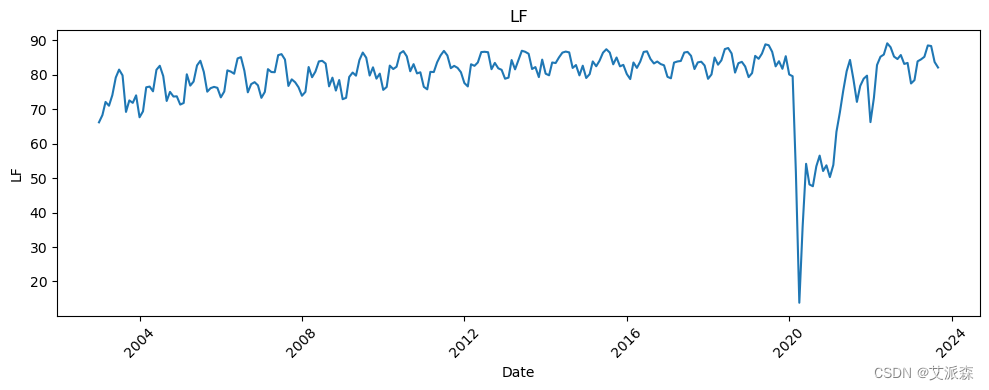
新冠疫情的影响非常明显。
对于这个时间序列项目,我们将预测Dom_RPM:国内收入乘客里程数,这是航空公司流量的度量,计算付费乘客在国内航班上飞行的里程数。这是航空公司的一项关键绩效指标,显示了国内付费旅客的数量。
4.4特征工程
拆分数据集为训练集和测试集
# 我们来做一个新的更简单的df
new_df = df[['Date', 'Dom_RPM']].copy()
new_df['Date'] = pd.to_datetime(new_df['Date'])
new_df.set_index('Date', inplace=True)
# 将数据分成训练集和测试集
split_date = pd.to_datetime('2023-01-01')
train = new_df.loc[:split_date]
test = new_df.loc[split_date:] plt.figure(figsize=(12,6))
plt.plot(new_df.index, new_df['Dom_RPM'], label='Dom_RPM')
plt.axvline(x=split_date, color='red', linestyle='--', label='Train-Test Split')
plt.legend()
plt.show()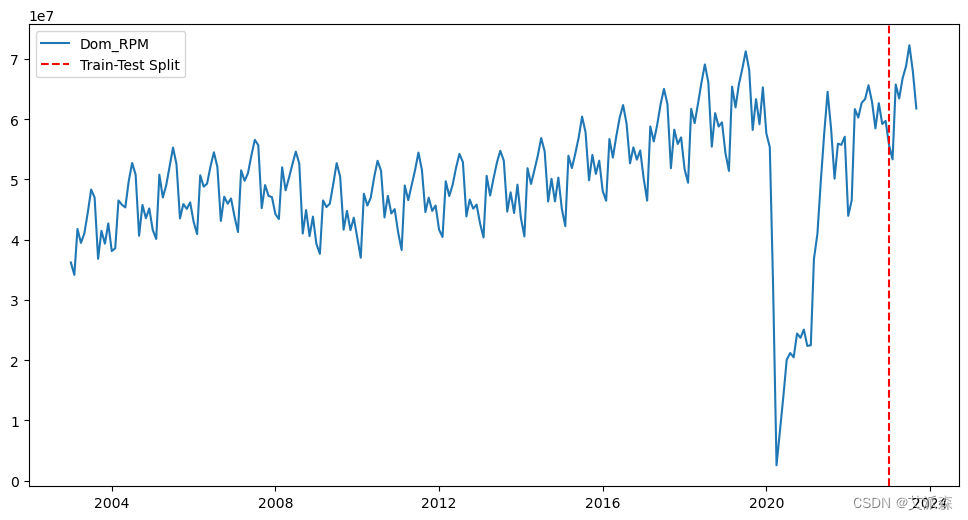
平稳性检验
# 平稳性检验
from statsmodels.tsa.stattools import adfuller
st_train= adfuller(train['Dom_RPM'], autolag='AIC')
print(st_train)
预差分结果表明,在5%显著性水平下,时间序列可能是平稳的,因为ADF统计量(-3.4227)更接近5%临界值(-2.8744),p值(0.0102)小于0.05,表明在该水平下可以拒绝单位根的原假设。
plt.figure(figsize=(12, 6))
plt.subplot(2, 1, 1)
pd.plotting.autocorrelation_plot(train['Dom_RPM'])
plt.title(f"Autocorrelation Plot for 'Training Set'")
plt.show()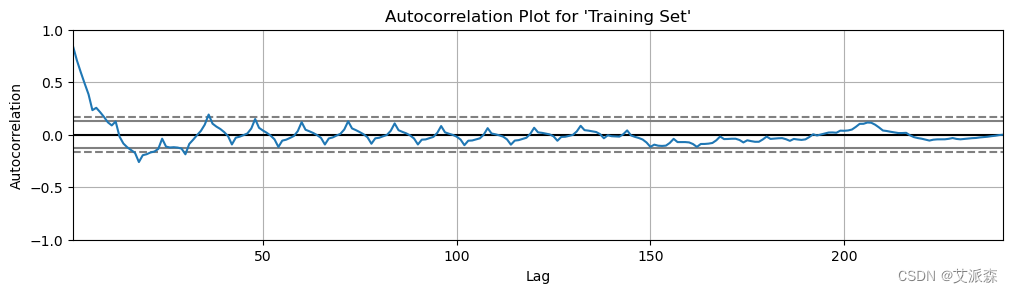
# 差分训练数据
train['Dom_RPM_diff'] = train['Dom_RPM'].diff().shift(-1)
train.dropna(inplace=True)
# 检查差分后的ADF结果
diff_st_train= adfuller(train['Dom_RPM'], autolag='AIC')
print(diff_st_train)
差异后,ADF统计量略负(-3.5346),p值进一步下降至0.0071,增强了非平稳性原假设的证据。差异后的ADF统计量仍然比5%临界值更负,并且非常接近1%临界值,这表明即使在更严格的显著性水平下,也有更强的平稳性证据。
from statsmodels.tsa.arima.model import ARIMA
import statsmodels.api as sm
plt.plot(train.index, train['Dom_RPM_diff'])
plt.xlabel('Date')
plt.ylabel('Domestic RPM')
plt.xticks(rotation=45)
plt.show()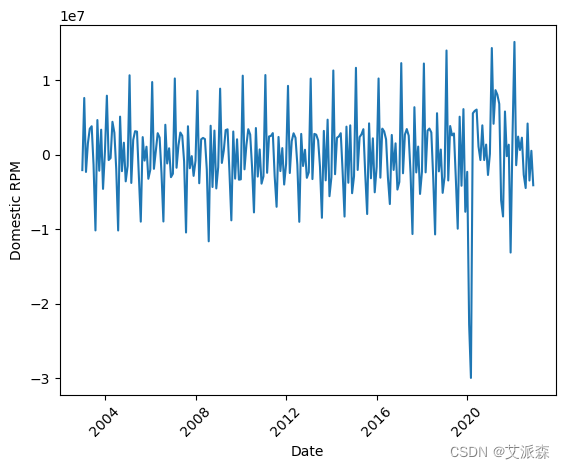
4.5构建模型
这里我做了一个基本的ARIMA模型
order = (1, 1, 1)
arima_model = sm.tsa.arima.ARIMA(train['Dom_RPM_diff'].dropna(), order=order)
fitted = arima_model.fit()
print(fitted.summary())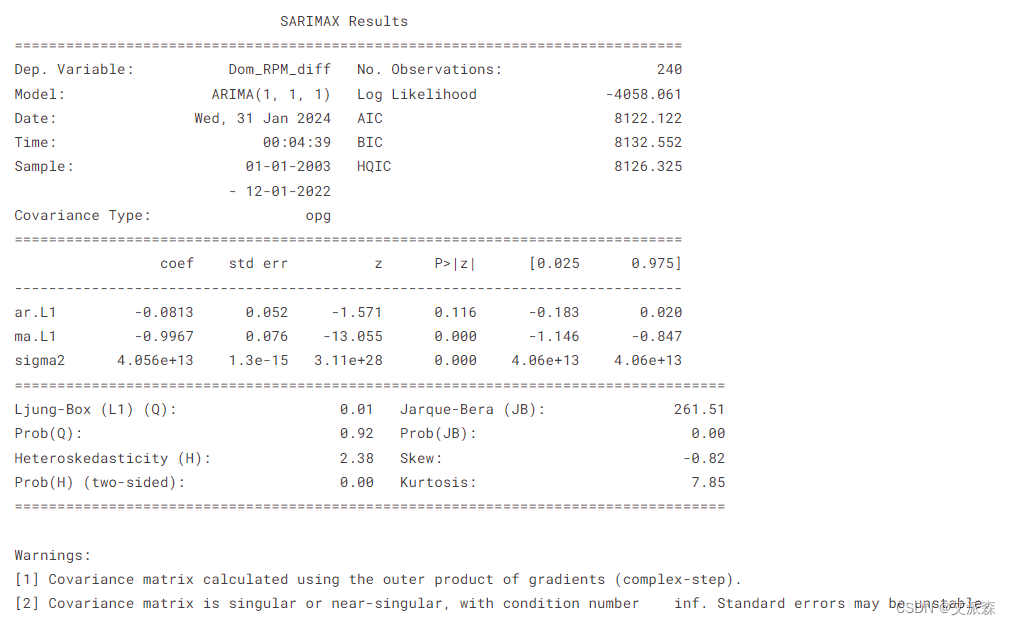
-4058.061的对数似然和AIC(8122.122)、BIC(8132.552)和HQIC(8126.325)等选择标准表明,该模型在捕获动态方面相对有效。自回归项(ar.L1)在-0.0813处没有统计学意义(p值:0.116),这意味着它可能对模型没有意义,而移动平均项(ma.L1)在-0.9967处非常显著(p值:0.000),表明对模型有很强的影响。误差方差(sigma2)很大,为4.056e+13,表明存在大量无法解释的变异。
Ljung-Box检验(p值:0.92)表明不存在自相关问题,但Jarque-Bera检验表明残差不遵循正态分布(p值:0.00),异方差检验指向不同的残差方差(p值:0.00),表明潜在的模型规范问题。此外,残差的偏度(-0.82)和高峰度(7.85)进一步质疑了模型的假设。
# 分解时间序列以观察季节模式
decomposition = sm.tsa.seasonal_decompose(train['Dom_RPM'], model='additive', period=12)
decomposition.plot()
plt.show()
# ACF和PACF图
fig, (ax1, ax2) = plt.subplots(2,1, figsize=(12,8))
sm.graphics.tsa.plot_acf(train['Dom_RPM'], lags=40, ax=ax1)
sm.graphics.tsa.plot_pacf(train['Dom_RPM'], lags=40, ax=ax2)
plt.show()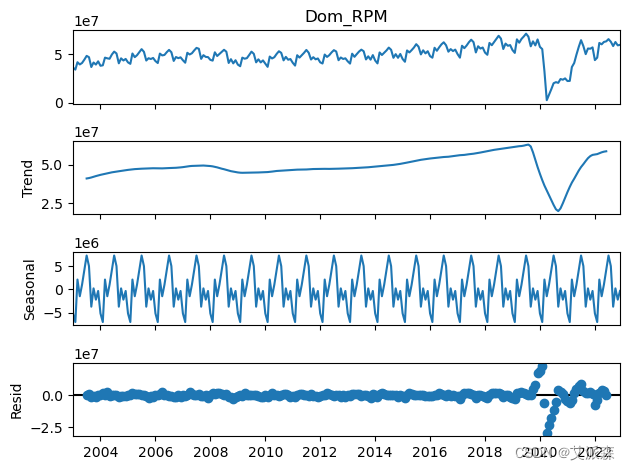
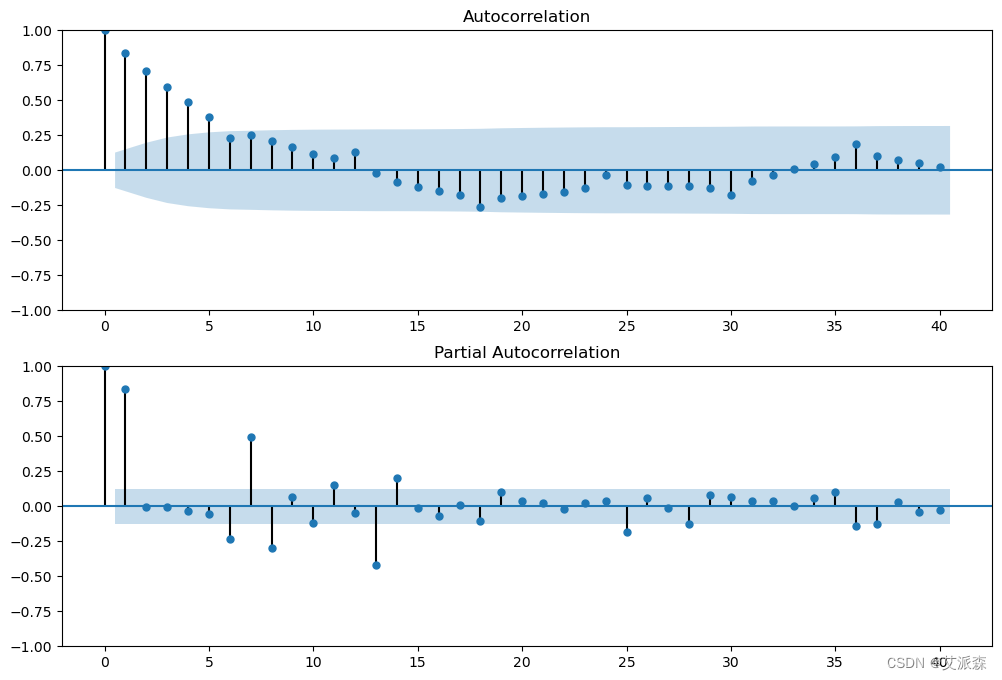
现在准备好运行SARIMA模型,我们必须指定季节性和非季节性组件。
# 非季节性组件
p = 1 # number of lag observations in the model (AR term)
d = 1 # the number of times that the raw observations are differenced (I term)
q = 0 # the size of the moving average window (MA term)
# 季节性组件
P = 0 # seasonal autoregressive order
D = 1 # essasonal differencing order
Q = 1 # seasonal moving average order
s = 12 # the number of periods in a season
seasonal_order = (P, D, Q, s)
sarima_model = sm.tsa.statespace.SARIMAX(train['Dom_RPM'],
order=(p, d, q),
seasonal_order=seasonal_order,
enforce_stationarity=False,
enforce_invertibility=False)
fitted_sarima = sarima_model.fit()
print(fitted_sarima.summary())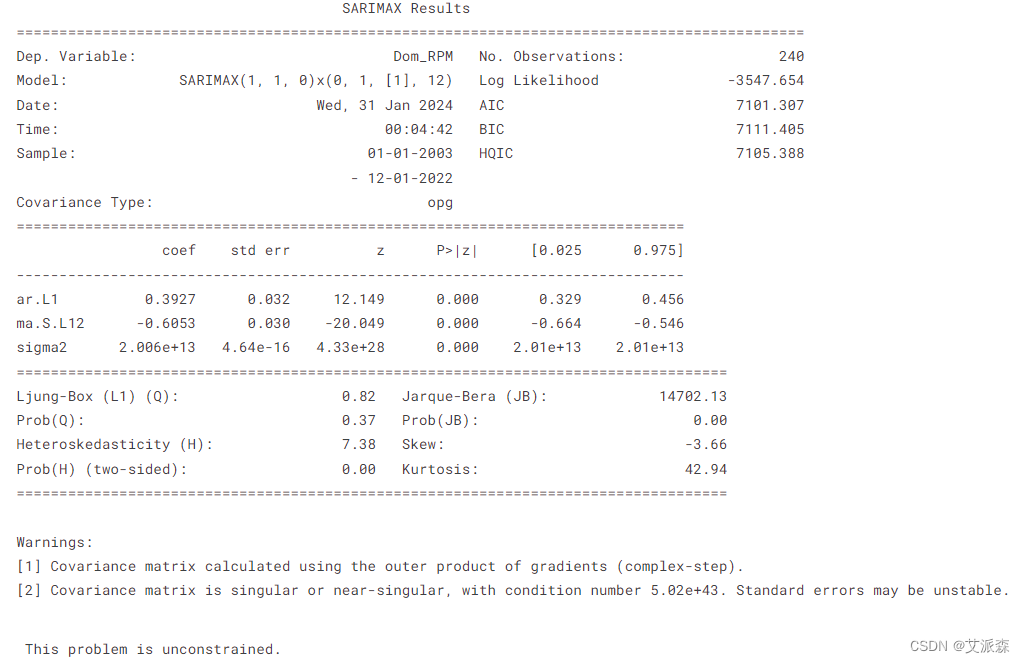
使用L-BFGS-B算法对SARIMAX模型进行了成功的优化,经过8次迭代后,模型拟合得到了显著改善,最终函数值为14.78。该SARIMAX模型突出了数据中的非季节性和季节性动态,自回归项(0.3927)和季节移动平均项(-0.6053)的系数都很显著,表明存在显著的自回归效应和强烈的季节性影响。模型的拟合良好度指标,包括对数似然值为-3547.654,以及AIC(7101.307)、BIC(7111.405)和HQIC(7105.388)等标准,为评估模型性能提供了依据,值越低通常表示拟合越好。然而,诊断试验显示残差分布的正态性和异方差的证据。
检查模型的残差
residuals = fitted_sarima.resid
# 绘制残差
plt.figure(figsize=(10,6))
plt.plot(residuals)
plt.title('Residuals from SARIMA Model')
plt.axhline(y=0, color='black', linestyle='--')
plt.show() # 绘制残差的ACF和PACF
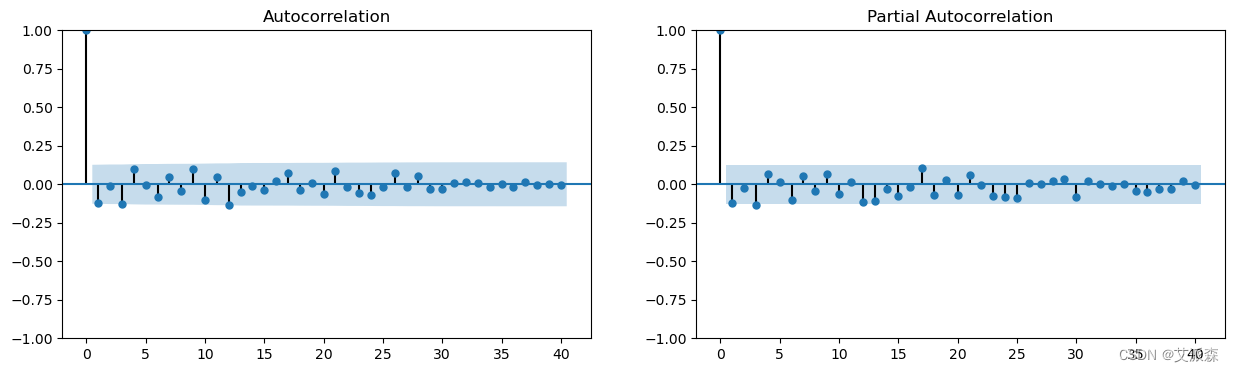
fig, ax = plt.subplots(1,2,figsize=(15,4))
sm.graphics.tsa.plot_acf(residuals, lags=40, ax=ax[0])
sm.graphics.tsa.plot_pacf(residuals, lags=40, ax=ax[1])
plt.show()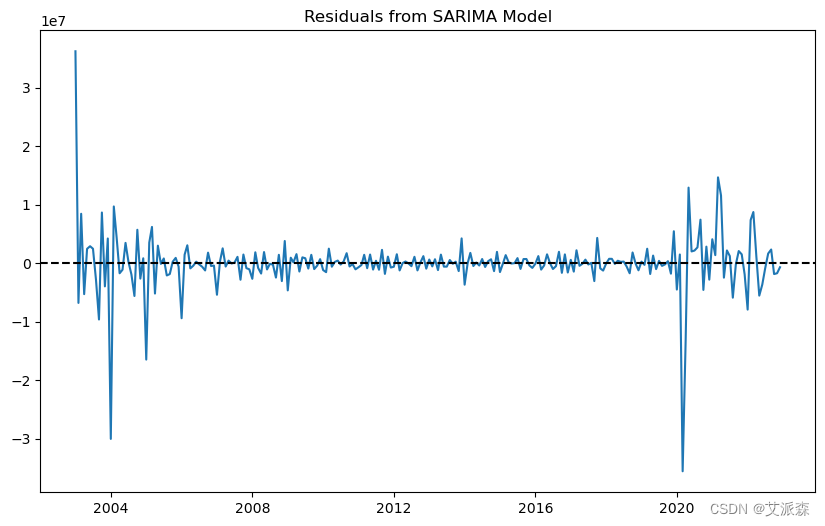
# 直方图和核密度估计
residuals.plot(kind='hist', density=True, bins=30, alpha=0.5)
residuals.plot(kind='kde')
plt.title('Histogram and Density Plot of Residuals')
plt.show()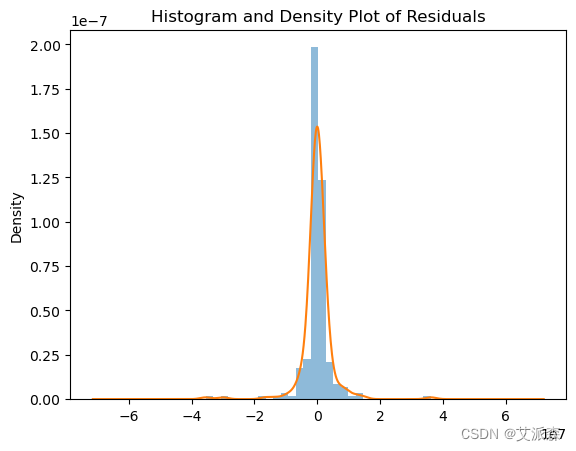
# Q-Q图检查正态性
sm.qqplot(residuals, line='s')
plt.title('Q-Q Plot of Residuals')
plt.show()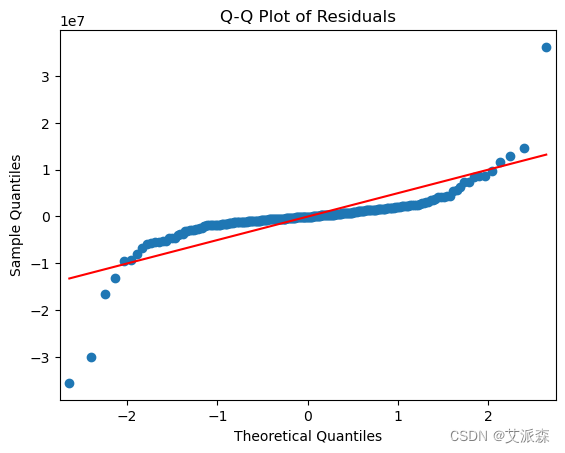
# 正态性的统计检验
from scipy import stats
jb_test = stats.jarque_bera(residuals)
print(f'Jarque-Bera test statistics: {jb_test[0]}, p-value: {jb_test[1]}')
JB检验统计量非常高,p值为0,说明数据不服从正态分布。
# 零均值的统计检验
mean_test = stats.ttest_1samp(residuals, 0)
print(f'Test Statistic: {mean_test.statistic}, p-value: {mean_test.pvalue}')
由于检验统计量非常接近于0,p值非常高(0.919),因此有强有力的证据表明残差的平均值与0没有显著差异。实际上,这意味着在模型的残差中没有显著的偏差;也就是说,模型没有系统地高估或低估观测值。
# 自相关的统计检验
ljung_box_test = sm.stats.acorr_ljungbox(residuals, lags=[40], return_df=True)
print(ljung_box_test)
Ljung-Box检验检查所有滞后至40的自相关,并检验数据中没有自相关的零假设。相对较低的统计量和较高的p值表明,在40个滞后的模型残差中没有显著的自相关证据。
将假数据纳入SARIMA模型,以考虑COVID-19大流行对时间序列数据的影响。
covid_start = '2020-03-01'
covid_end = '2021-09-01'
# 为covid周期创建虚拟变量
train['covid_dummy'] = np.where((train.index >= covid_start) & (train.index <= covid_end), 1, 0)
# 带有外生变量(哑变量)的SARIMA模型
sarimax_model1 = sm.tsa.statespace.SARIMAX(train['Dom_RPM'],
exog=train['covid_dummy'],
order=(p, d, q),
seasonal_order=(P, D, Q, s),
enforce_stationarity=False,
enforce_invertibility=False)
fitted_sarimax1 = sarimax_model1.fit()
print(fitted_sarimax1.summary())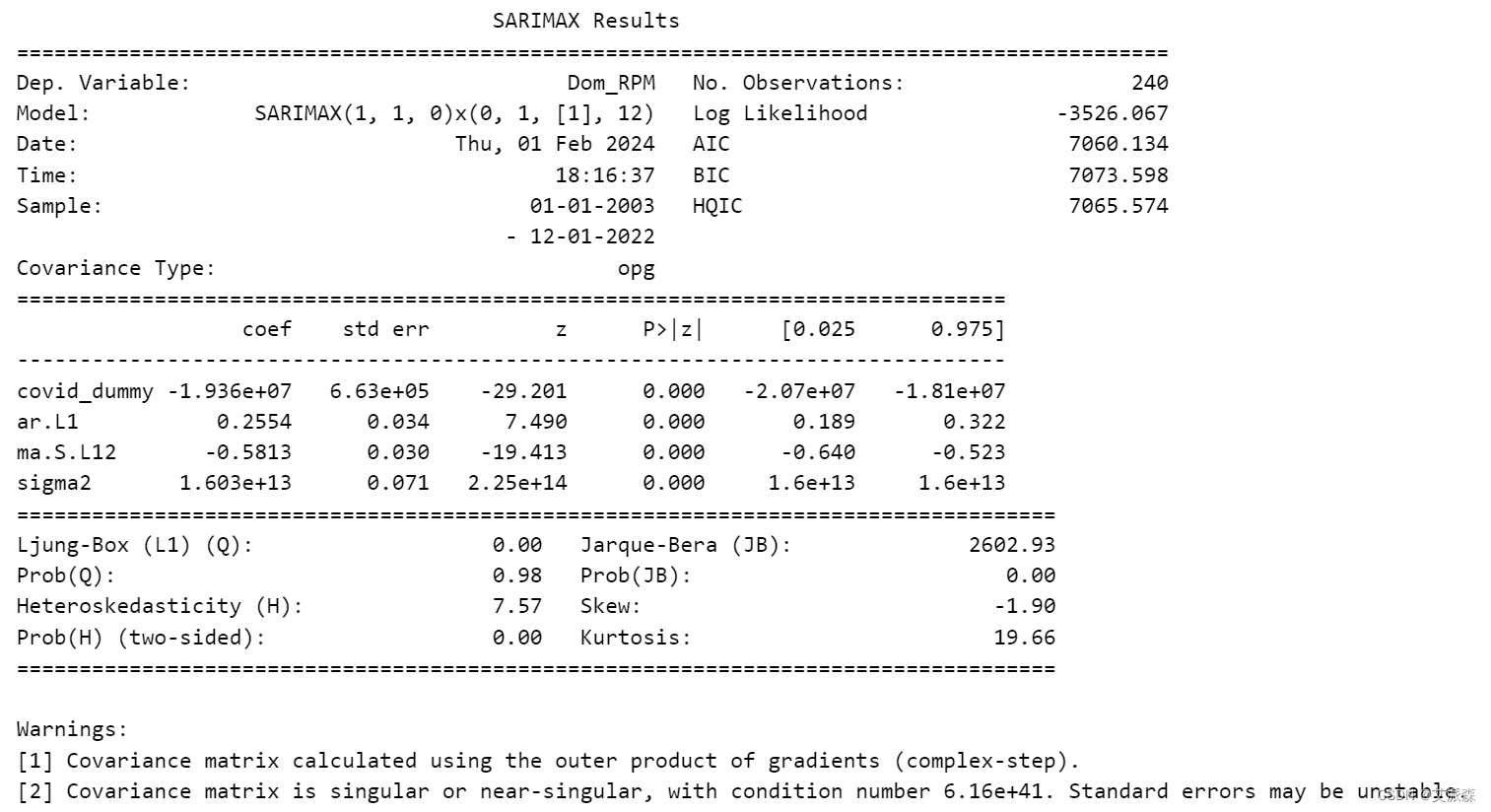
采用L-BFGS-B算法进行优化,经过9次迭代后呈现收敛性,表明疫情对数据的负面影响显著,如covid dummy系数(-1.936e+07)。自回归分量和季节移动平均分量均具有显著的统计学意义,表明存在重要的时间动态。尽管各种统计指标(如AIC、BIC和对数似然)显示了成功的拟合,但诊断显示残差中没有显著的自相关,但突出了非正态分布和异方差的问题。
这两个代码片段一起工作,构建了一种更复杂的方式来理解covid对数据的影响。在第一个代码片段中,我们计算了两件事:covid dummy,它告诉我们在特定时间是否发生了covid,以及covid impact,它衡量covid -19的影响如何随着时间的推移而减少。
然后,在第二个代码片段中,我们使用这些计算来构建SARIMAX模型。该模型不仅考虑了COVID-19是否存在,还考虑了其影响如何随时间变化。
# 让我们再试一次,但要用衰变
covid_start = pd.to_datetime('2020-03-01')
covid_end = pd.to_datetime('2021-09-01')
# 计算自COVID-19开始以来的天数,并将其除以30转换为月份
train['months_since_covid'] = ((train.index - covid_start) / np.timedelta64(1, 'D') / 30).astype(int)
# 线性衰减
duration_in_months = ((covid_end - covid_start) / np.timedelta64(1, 'D') / 30)
train['covid_impact'] = train['months_since_covid'].apply(
lambda x: max(1 - x / duration_in_months, 0) if x >= 0 else 0
)sarimax_model_with_decay = sm.tsa.statespace.SARIMAX(
train['Dom_RPM'],
exog=train[['covid_dummy', 'covid_impact']],
order=(p, d, q),
seasonal_order=(P, D, Q, s),
enforce_stationarity=False,
enforce_invertibility=False
)
fitted_sarimax_with_decay = sarimax_model_with_decay.fit()
print(fitted_sarimax_with_decay.summary())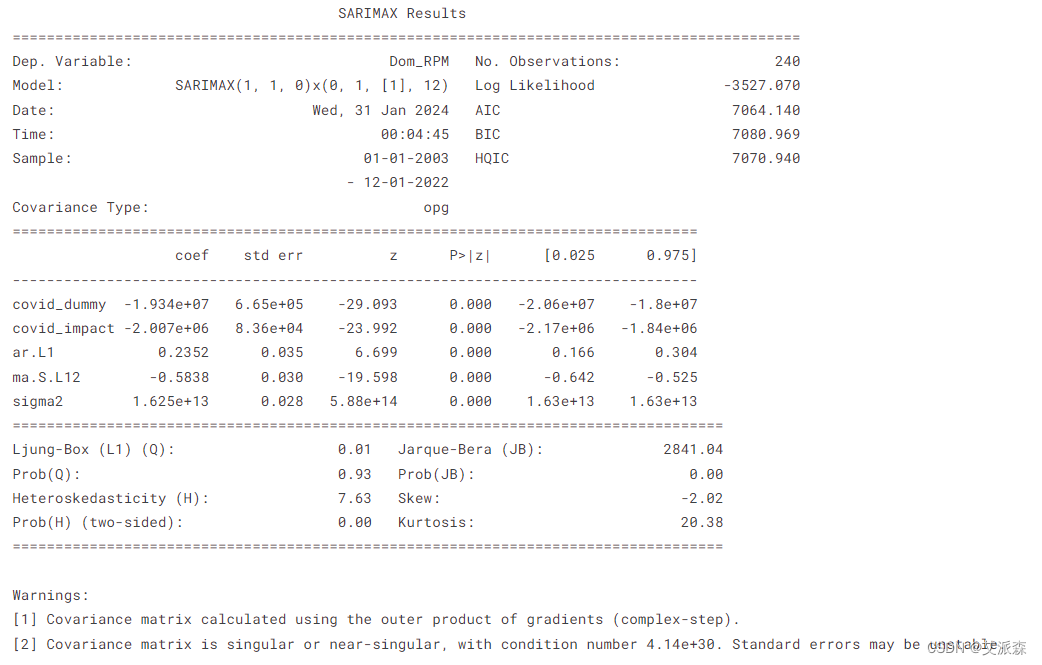
在解释中,带有这些系数的SARIMAX模型表明,covid -19时期对数据有很大的负面影响(显然……),covid - dummy表明显著降低。covid - 19影响系数表明,随着时间的推移,影响会减弱,这表明大流行的最初冲击正在逐步恢复。
这是我们对未来12个月的预测。它首先生成一组未来日期,从训练数据中的最后一个日期开始,跨越未来12个月。然后,它创建两个数组,future_covid - dummy和future_covid - impact,来表示预测的外生变量。Future_covid_dummy假设未来不会有covid影响,因此在整个预测期内将所有值设置为0。而future_covid - impact则假设COVID-19的影响逐渐减弱,在12个月的预测期内从0.5下降到0。然后将这些数组组合成df future_exog,它将在进行预测时用作外生变量。
# 预测期数(未来12个月)
n_periods = 12
future_dates = pd.date_range(train.index[-1] + pd.offsets.MonthBegin(), periods=n_periods, freq='M')
# 假设新冠病毒开始消失,那么影响将从0.5降至0
future_covid_dummy = [0] * n_periods
future_covid_impact = np.linspace(start=0.5, stop=0, num=n_periods) #
# 组合成df
future_exog = pd.DataFrame({'covid_dummy': future_covid_dummy, 'covid_impact': future_covid_impact}, index=future_dates)
n_periods = 12
forecast = fitted_sarimax_with_decay.get_forecast(steps=n_periods, exog=future_exog)
forecast_mean = forecast.predicted_mean
forecast_conf_int = forecast.conf_int()下面是预测图
# 利用历史数据绘制预测图
plt.figure(figsize=(10, 6))
plt.plot(train.index, train['Dom_RPM'], label='Historical')
plt.plot(pd.date_range(train.index[-1], periods=n_periods, freq='M'), forecast_mean, label='Forecast')
plt.fill_between(pd.date_range(train.index[-1], periods=n_periods, freq='M'), forecast_conf_int.iloc[:, 0], forecast_conf_int.iloc[:, 1], color='red', alpha=0.3)
plt.legend()
plt.show()
# 让我们把我们的预测和测试进行比较
plt.figure(figsize=(10, 6))
plt.plot(train.index, train['Dom_RPM'], label='Historical', color='blue')
plt.plot(forecast_mean.index, forecast_mean, label='Forecast', color='red')
plt.fill_between(forecast_conf_int.index, forecast_conf_int.iloc[:, 0], forecast_conf_int.iloc[:, 1], color='red', alpha=0.3)
plt.plot(test.index, test['Dom_RPM'], label='Actual Test Set', color='green')
plt.title('Comparison between the Test and Forecast')
plt.xlabel('Date')
plt.ylabel('Dom_RPM (in millions)')
plt.legend()
plt.show()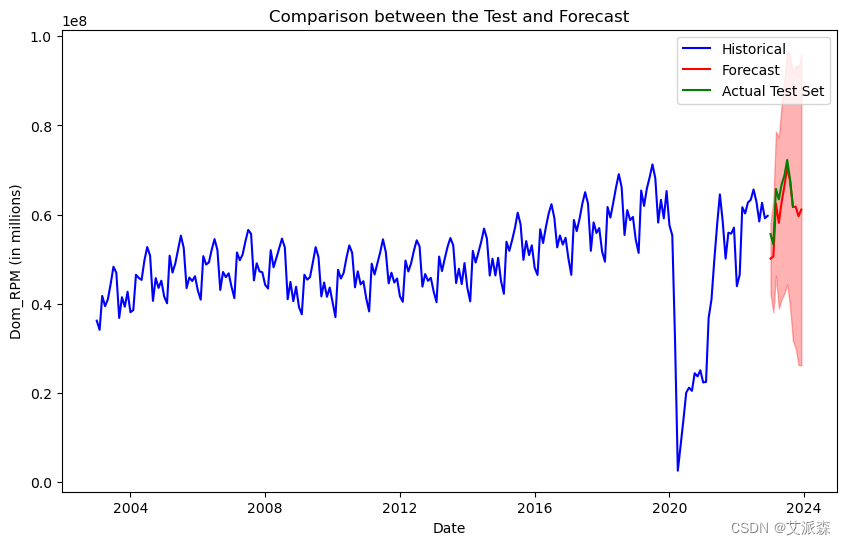
预测结果与实际测试数据有些接近。虽然与测试集相比,预测似乎被低估了。
资料获取,更多粉丝福利,关注下方公众号获取